За 5 лет бутстрэппинга я попробовал много всего и обнаружил, что существует много способов создать себе сложности, которые отнимают время и энергию. В результате ты вынужден разбираться с ними вместо того, чтобы заниматься делом и наращивать ценность своего продукта.
Для стартапера очень важно умение не создавать себе сложности. На ранних стадиях бутстрэппинга ничего не происходит, пока ты, основатель проекта, не пошевелишься. Поэтому сохранять свое время и энергию критически важно.
Если вы хотите полностью минимизировать сложности при запуске софтверного бизнеса, то следуйте каждому из приведенных ниже правил.
Если ваш продукт может работать по подписной модели, например, как SaaS, используйте это: даже если вам потребуется немного допилить его, чтобы применить эту бизнес-модель.
Зато в этом случае ваш доход можно будет прогнозировать. Если в двух словах, то ваша месячная выручка будет равна предыдущей месячной выручке за вычетом ушедших пользователей, и с учетом вновь прибывших в этом месяце.
Запуск бизнеса с выручкой, которая в основном растет и очень редко существенно падает, раз в сто снижает уровень вашего стресса по сравнению с ситуацией, когда выручка меняется по принципу «то густо, то пусто».
Для стартапера очень важно умение не создавать себе сложности. На ранних стадиях бутстрэппинга ничего не происходит, пока ты, основатель проекта, не пошевелишься. Поэтому сохранять свое время и энергию критически важно.
Если вы хотите полностью минимизировать сложности при запуске софтверного бизнеса, то следуйте каждому из приведенных ниже правил.
Правило #1: Организуйте стабильный доход
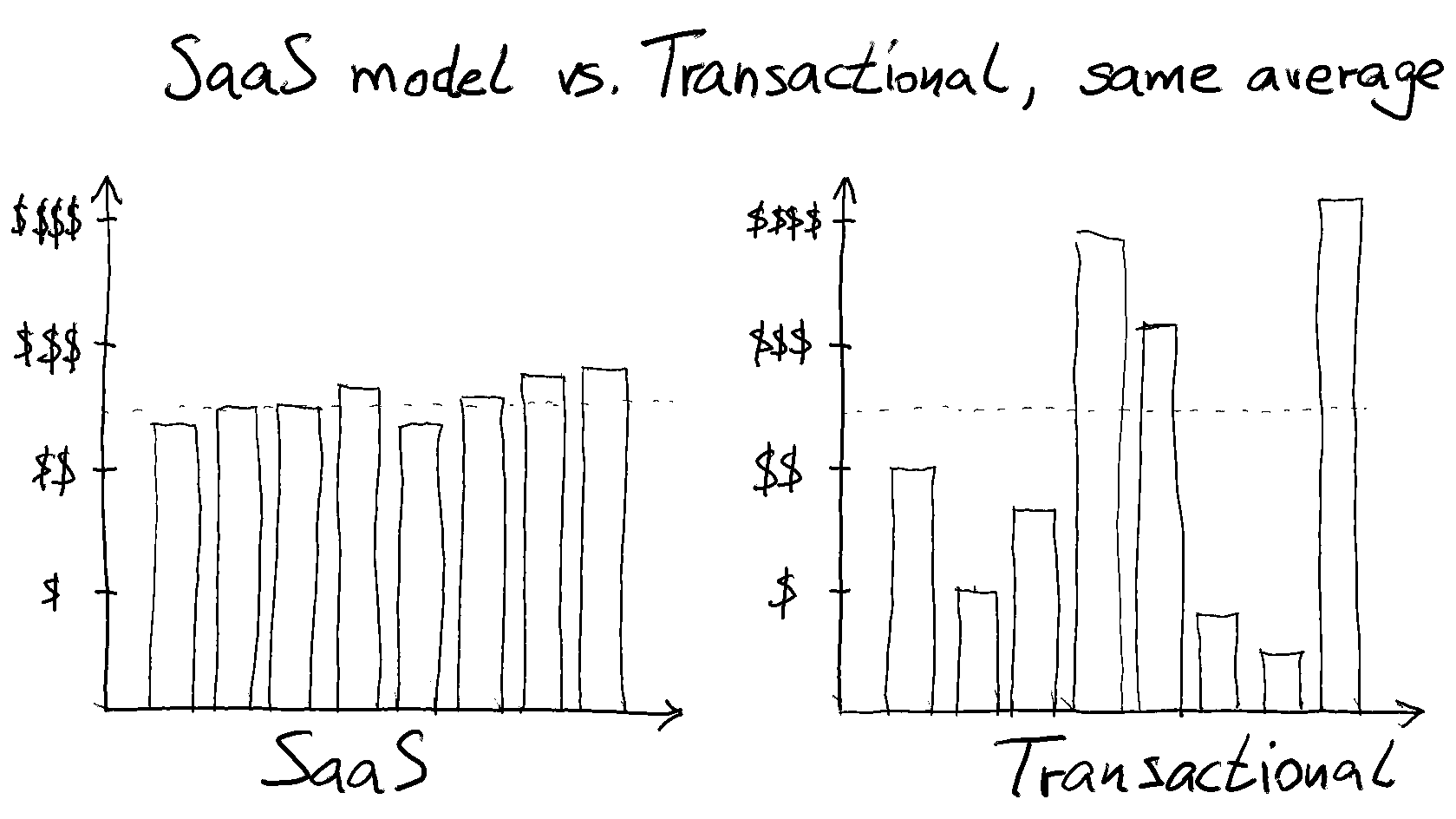
Если ваш продукт может работать по подписной модели, например, как SaaS, используйте это: даже если вам потребуется немного допилить его, чтобы применить эту бизнес-модель.
Зато в этом случае ваш доход можно будет прогнозировать. Если в двух словах, то ваша месячная выручка будет равна предыдущей месячной выручке за вычетом ушедших пользователей, и с учетом вновь прибывших в этом месяце.
Запуск бизнеса с выручкой, которая в основном растет и очень редко существенно падает, раз в сто снижает уровень вашего стресса по сравнению с ситуацией, когда выручка меняется по принципу «то густо, то пусто».