Новый поисковик Blekko начал работу полтора месяца назад и вполне естественно привлёк к себе пристальное внимание экспертов. Не только благодаря инновационному интерфейсу и слэштегам, но и в принципе, всё-таки в наше время запуск нового поисковика общего профиля — большая редкость. Мало кто осмелится тягаться с Google. Кроме всего прочего, это требует немалых финансовых вливаний.
Давайте посмотрим, что представляет из себя инфраструктура Blekko, о которой в подробностях рассказали CEO Ричард Скрента и CTO Грег Линдал.
Дата-центр Blekko насчитывает около 800 серверов, каждый с 64 ГБ RAM и восемью SATA-дисками по терабайту. Система резервирования RAID не используется совсем, потому что RAID-контроллеры сильно снижают производительность (с 800 МБ/с для восьми дисков до 300-350 МБ/с).
Чтобы избежать потери данных, разработчики используют полностью децентрализованную архитектуру и ряд необычных трюков.
Во-первых, они разработали «поисковые модули», которые одновременно сочетают в себе и функции краулинга, и анализа, и поисковой выдачи. За счёт этого в их кластере из 800 серверов сохраняется полная децентрализация. Все серверы равны между собой, нет выделенных специализированных кластеров, например, для краулинга.
Серверы в децентрализованной сети обмениваются данными, так что в каждый момент времени копия информационных блоков содержится на трёх машинах. Как только диск или сервер выходит из строя, остальные серверы сразу это замечают и начинают процесс «лечения», то есть дополнительной репликации данных с потерянной системы. Такой подход, по словам Скренты, эффективнее, чем RAID.
Если диск выходит из строя, то инженер идёт в дата-центр и меняет его. С количеством дисков около 6400 дежурным админам, наверное, не приходится много спать.
Серверы индексируют 200 млн веб-страниц в день, а всего в индексе уже 3 млрд документов. Частота обновления составляет от нескольких минут для главных страниц популярных новостных сайтов до 14 дней. Этот параметр наглядно демонстрируется в поисковой выдаче: по слэштегу /date видно, какие страницы индексировались последними и сколько секунд назад.
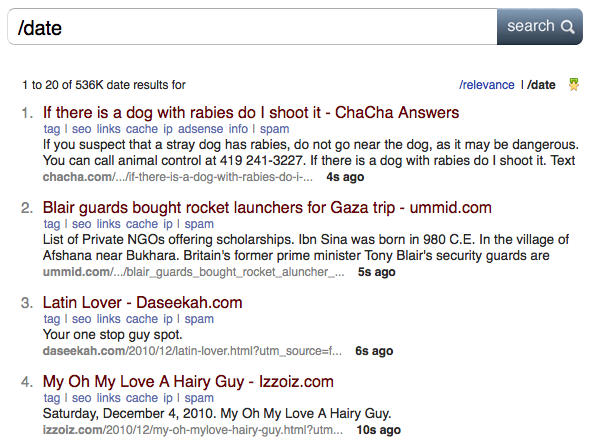
Можно обновлять страницу и наблюдать за краулером. Видно, что добавление нового контента в выдачу происходит с интервалом в считанные секунды. Даже гугловский Caffeine не обеспечивает такой скорости.
С технической точки зрения, им удалось сделать такую реализацию MapReduce, которая работает маленькими итерациями и обеспечивает мгновенное отображение каждой итерации. Это можно посмотреть, если рефрешить SEO-страничку, которая прилагается к каждому поисковому результату.
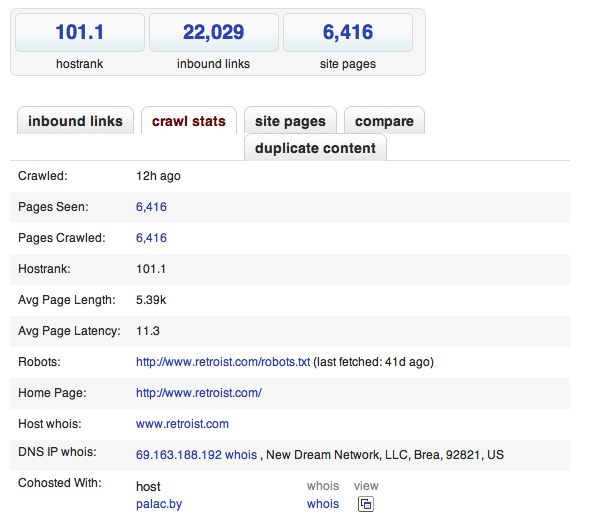
Секрет успеха такого неординарного решения — Perl. Разработчики говорят, что они чрезвычайно довольны своим выбором, в библиотеке CPAN есть модули на любой вкус, а на каждой машине установлено более 200 модулей. На серверах стоит CentOS и поскольку они все одинаковы, то можно использовать идентичный дистрибутив.
Давайте посмотрим, что представляет из себя инфраструктура Blekko, о которой в подробностях рассказали CEO Ричард Скрента и CTO Грег Линдал.
Дата-центр Blekko насчитывает около 800 серверов, каждый с 64 ГБ RAM и восемью SATA-дисками по терабайту. Система резервирования RAID не используется совсем, потому что RAID-контроллеры сильно снижают производительность (с 800 МБ/с для восьми дисков до 300-350 МБ/с).
Чтобы избежать потери данных, разработчики используют полностью децентрализованную архитектуру и ряд необычных трюков.
Во-первых, они разработали «поисковые модули», которые одновременно сочетают в себе и функции краулинга, и анализа, и поисковой выдачи. За счёт этого в их кластере из 800 серверов сохраняется полная децентрализация. Все серверы равны между собой, нет выделенных специализированных кластеров, например, для краулинга.
Серверы в децентрализованной сети обмениваются данными, так что в каждый момент времени копия информационных блоков содержится на трёх машинах. Как только диск или сервер выходит из строя, остальные серверы сразу это замечают и начинают процесс «лечения», то есть дополнительной репликации данных с потерянной системы. Такой подход, по словам Скренты, эффективнее, чем RAID.
Если диск выходит из строя, то инженер идёт в дата-центр и меняет его. С количеством дисков около 6400 дежурным админам, наверное, не приходится много спать.
Серверы индексируют 200 млн веб-страниц в день, а всего в индексе уже 3 млрд документов. Частота обновления составляет от нескольких минут для главных страниц популярных новостных сайтов до 14 дней. Этот параметр наглядно демонстрируется в поисковой выдаче: по слэштегу /date видно, какие страницы индексировались последними и сколько секунд назад.
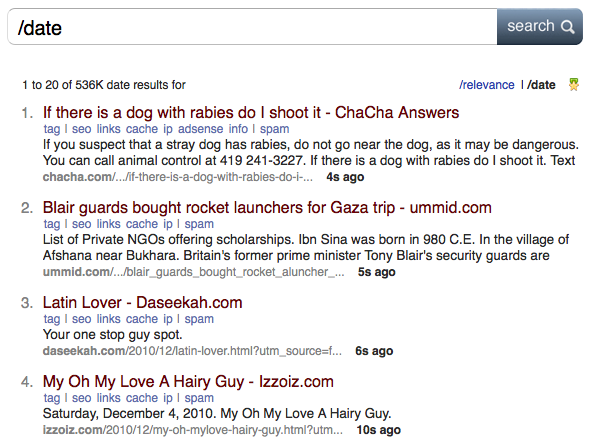
Можно обновлять страницу и наблюдать за краулером. Видно, что добавление нового контента в выдачу происходит с интервалом в считанные секунды. Даже гугловский Caffeine не обеспечивает такой скорости.
С технической точки зрения, им удалось сделать такую реализацию MapReduce, которая работает маленькими итерациями и обеспечивает мгновенное отображение каждой итерации. Это можно посмотреть, если рефрешить SEO-страничку, которая прилагается к каждому поисковому результату.
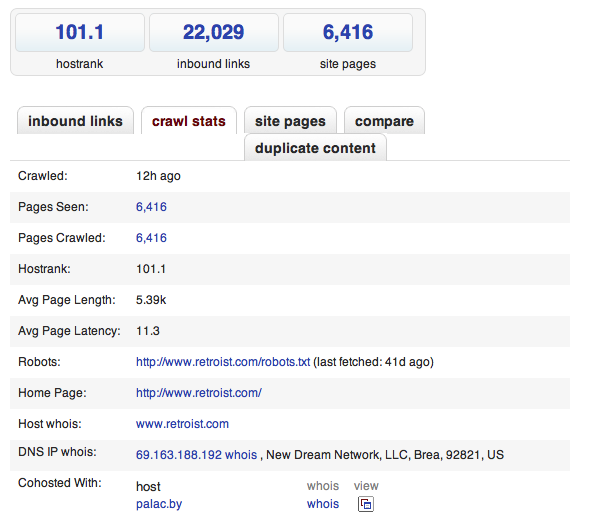
Секрет успеха такого неординарного решения — Perl. Разработчики говорят, что они чрезвычайно довольны своим выбором, в библиотеке CPAN есть модули на любой вкус, а на каждой машине установлено более 200 модулей. На серверах стоит CentOS и поскольку они все одинаковы, то можно использовать идентичный дистрибутив.
