Прочитав данную заметку вы узнаете, через что пришлось пройти после неожиданно возникшей утечки памяти серверного приложения в ОС FreeBSD. Какие современные средства обнаружения подобных проблем существуют в данной среде и почему самое мощное из них может оказаться совершенно бесполезным
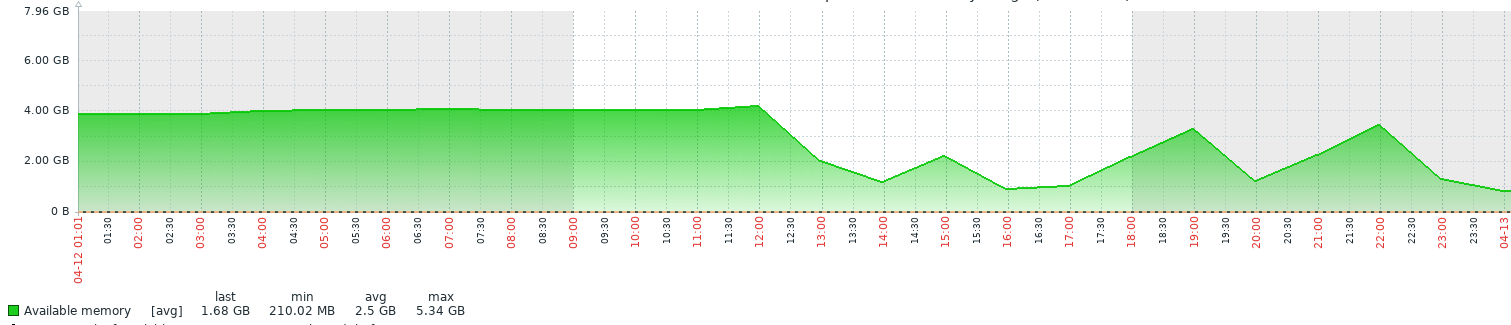
В один прекрасный полдень четверга, на 5 из 50 серверов Zabbix прислал уведомления о заканчивающемся месте на swap-разделе. График на КПДВ (свободная память) наглядно демонстрирует масштаб проблемы (холмики справа — высвобождение памяти за счет вытеснения в swap). Благо, впереди пятница, и можно спокойно все исправить за выходные. В тот момент еще никто не предполагал, что на поиски и устранение причины уйдет больше 6 суток.
О серверах. Типичные сервера поколения десятых-одиннадцатых годов с 8Гб памяти (практически полностью идентичны и даже одного бренда). Сервера поделены на группы для обслуживания разных наборов пользовательских аккаунтов.
О приложении. Ad-server, HTTP (libh2o) с логикой на C\С++, кучей сторонних библиотек и велосипедов вроде стандартных C++ контейнеров в shared memory и т.п. Принимает входящий запрос, перенаправляет на несколько вышестоящих серверов, проводит аукцион по ответам и возвращает ответ клиенту. Все крутится на FreeBSD 11.0\11.1.
Кто виноват?
Последние изменения в кодовой базе были около десяти дней назад, все эти дни с памятью не происходило ничего примечательного. Беглый анализ давал такой список наиболее вероятных причин:
- изменились качественные либо количественные характеристики входящих\исходящих запросов, что привело к ошибкам при выделении\освобождении памяти;
- велосипеды с контейнерами в shared memory. Они всегда вызывают подозрение, если что-то идет не так;
- никакой утечки нет, просто стало больше данных и они теперь перестали влазить;
- результат обновления ядра ОС \ библиотек. Но никаких авто-обновлений по умолчанию нет, это не какая-нибудь Windows которая, прости Господи, может накатить обновлений, когда вздумается и, вдобавок, перезагрузить машину. Пару месяцев назад так обвалилось много сервисов на соседнем проекте.
- кто-то проводит целенаправленную сетевую атаку, вызывающую переполнение;
- Meltdown\Spectre. Да! Ну конечно же. Не помню, чтобы мы накатывали какие-либо обновления, боясь замедления, но такой пункт сегодня просто обязан иметь место быть в любой нештатной ситуации;
Но характеристики запросов\ответов не изменились (по крайней мере, по всем собираемым метрикам). Данных больше не стало, с сетью порядок, куча свободных ресурсов, сервер отвечает быстро… Неужели изменилась внешняя среда?
Что делать?
Пару лет назад всплывало нечто подобное, но успели забыться практически все инструменты, которые помогли решить проблему тогда. Хотелось просто поскорее избавиться от всего за пару часов, поэтому первая наивная попытка — найти ответ на StackOverflow… В основном народ рекомендует Valgrind и какие-то неизвестные поделки (видимо, сами же авторы), либо плагины к VisualStudio (неактуально). Поделки падали практически все, даже не начав толком работать (memleax, ElectricFence и т.п.), останавливаться на них подробно не будем.
Попутно вспоминаем все недавно выпущенные фичи, благо, изменений за последний месяц было немного, из основных — прикручивание баз GeoIP, и так, по-мелочи…
Пытаемся поочередно отключать клиентов и вышестоящие сервера (данный метод был опробован одним из первых, но почему-то не дал никакого результата, утечка проявлялась во всех комбинациях с разной степенью интенсивности, наблюдалась лишь линейная зависимость от входящих запросов).
Тут же были предприняты попытки отката на старые версии, вплоть до ревизии двухмесячной давности. Память продолжала утекать и там. Откат на еще более ранние версии не представлялся возможным по причине несовместимости с остальными компонентами.
Главный вопрос — почему именно эти 5 серверов? Все машины практически идентичны (кроме разницы в версии ОС 11\11.1). Проблема возникает только на определенной группе аккаунтов. На остальных нет и намека на такое поведение, значит, должно быть, точно зависимость от входящих запросов…
Лирическое отступление
Неоднократно сталкиваясь с утечками в разных проектах, довелось наслушаться жутких историй про самый популярный и действенный способ лечения — периодически перезагружать ущербное приложение. Да да, оказывается, такое работает годами в весьма уважаемых компаниях. Мне это всегда казалось полной дичью, и что я никогда в жизни не опущусь до этого, какого бы масштаба не возникла проблема. Однако, уже на вторые сутки пришлось прописать позорный рестарт в cron-е, т.к. перезагружать приложение раз в несколько часов оказалось довольно утомительным занятием (особенно по ночам).
Зачем-то захотелось сделать все красиво, а именно найти место утечки универсальными средствами. Наверно, это была одна из основных ошибок, допущенных на ранней стадии.
Итак, какие же универсальные средства решения описанной проблемы существуют сегодня? В основе своей, это сторонние библиотеки, оборачивающие вызовы к malloc\free и следящие за всеми операциями с памятью.
valgrind
Прекрасное средство обнаружения проблем. Действительно, ловит практически все виды (двойное освобождение, выход за границы, утечки и т.п.). Тут бы вся эта история и закончилась, не начавшись. Но с valgrind есть одна проблема — практически полная бесполезность для высоко-нагруженных приложений. Выглядит это примерно так: программа стартует в 20-50 раз дольше обычного, потом так же работает, при этом большинство запросов, естественно, не успевают отработать и заканчиваются по таймаутам. Ядра CPU загружаются на 100%, при этом никаких полезных действий приложение не производит, тратя все ресурсы на виртуальную машину valgrind-а. В логах вы обнаружите жалкие доли процента от всех запросов, которые проходят в штатном режиме. После нажатия Ctrl+C, если повезет, через несколько минут появится лог, либо же все упадет (у меня было чаще второе, либо практически пустой лог). В общем, не взлетело.
tcmalloc
Библиотека доступна из порта google-perftools. По заявлением разработчиков:
This is the heap profiler we use at Google.Как и большинство подобных средств, подключается либо с помощью переменной окружения (LD_PRELOAD) либо вкомпиливанием самой библиотеки (-ltcmalloc). Ни тот ни другой способ не сработал. В процессе обнаружился еще один способ — вызов статического метода HeapLeakChecker::NoGlobalLeaks() из кода. Но он почему-то не экспортировался ни в одной из версий библиотеки. В последствии выяснится:
[on FreeBSD] libtcmalloc.so successfully builds, and the «advanced» tcmalloc functionality all works except for the leak-checker, which has Linux-specific code.:( Поехали дальше.
libumem
Доступна из порта umem. Шикарный способ обнаружения проблем с памятью. Особенно в сочетании с MDB. К сожалению, доступно все это только в ОС Solaris, а на FreeBSD MDB было бы неплохо портировать. Запустить с ним приложение не удалось. При старте, до вызова main, происходит вызов calloc из libthr.so, который уже перехвачен libumem-ом. В свою очередь, libumem пытается инициализировать работу с потоками у себя в коде. Рекурсия-с. В общем стек еще задолго до вызова main выглядит примерно так:
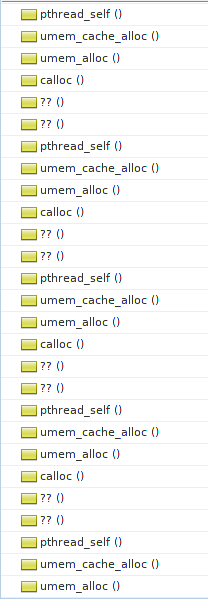
Типичная проблема яйца и курицы, которую непонятно как обойти. Идею выпилить много-поточность (благо, у нас она используется только где-то в boost-зависимостях и в обертке над getaddrinfo) было решено отложить на самый крайний случай. Ну что ж, отпишем разработчикам (если остались еще живые) в открытый кем-то похожий тикет и поедем дальше.
dmalloc
Доступна из одноименного порта. Обладает неплохой документацией. Стек при запуске удивительно напоминает предыдущий случай:
(gdb) bt
#0 0x0000000802c8783e in dmalloc_malloc ()
from /usr/local/lib/libdmallocthcxx.so.1
#1 0x0000000802c88623 in calloc () from /usr/local/lib/libdmallocthcxx.so.1
#2 0x00000008038a8594 in ?? () from /lib/libthr.so.3
#3 0x00000008038a98d4 in ?? () from /lib/libthr.so.3
#4 0x00000008038a58fa in pthread_mutex_lock () from /lib/libthr.so.3
#5 0x0000000802c87641 in ?? () from /usr/local/lib/libdmallocthcxx.so.1
#6 0x0000000802c87bb3 in ?? () from /usr/local/lib/libdmallocthcxx.so.1
#7 0x0000000802c8787a in dmalloc_malloc ()
from /usr/local/lib/libdmallocthcxx.so.1
#8 0x0000000802c88623 in calloc () from /usr/local/lib/libdmallocthcxx.so.1
#9 0x00000008038a8594 in ?? () from /lib/libthr.so.3
#10 0x00000008038a98d4 in ?? () from /lib/libthr.so.3
#11 0x00000008038a58fa in pthread_mutex_lock () from /lib/libthr.so.3
#12 0x0000000802c87641 in ?? () from /usr/local/lib/libdmallocthcxx.so.1
#13 0x0000000802c87bb3 in ?? () from /usr/local/lib/libdmallocthcxx.so.1
#14 0x0000000802c8787a in dmalloc_malloc ()
Но здесь автор в курсе проблемы и предусмотрел оригинальный способ обхода: при старте задавать параметром кол-во вызовов malloc-ов, которые нужно игнорировать (дабы избежать рекурсии):
You know its too low if your program immediately core dumps and too high if the dmalloc library says its gone recursive although with low values, you might get either problem.Мило. Подбирая заветное число, пометавшись между core-dump-ами и рекурсией всю эту затею было решено предать анафеме.
Тем временем, память на серверах стала заканчиваться еще быстрее. Если раньше было 5-6 часов до полного выедания, то сейчас память уходила за час полностью. Пришлось подкручивать cron :( К тому же, набор серверов, подверженных проблеме, стал расти. Правда, на новом наборе серверов память заканчивалась в течении суток. При этом, на большинстве машин до сих пор не было вообще никаких видимых проблем с памятью.
Параллельно, у инженеров в ДЦ запросили дополнительной памяти на один из серверов, чтобы проверить теорию о том, что «это данных стало больше» (последняя, отчаянная попытка убедиться, что это не утечка). ДЦ весьма оперативно предоставил дополнительные 8Гб, которые были благополучно выедены за ночь. Больше в наличии утечки никто не сомневался.
dtrace
В процессе беспощадного гуглежа все больше стали попадаться загадочные скрипты на не менее загадочном языке D. Оказалось, что все они предназначены для невероятно крутой системной утилиты — dtrace, эдакий IDDQD в анализе и отладке практически любого кода. Много про него слышал, но не доводилось использовать в бою.
Т.е. вы можете попросить сохранять все обращения к определенным функциям libc, например, malloc\free, поставив на них датчики (probes), попутно собирая общую статистику, и даже строить диаграммы распределения, и все это в несколько строк кода! Например, вот так:
sudo dtrace -n 'pid$target::malloc:entry { @ = quantize(arg0); }' -p 15034— вы можете узнать распределение выделяемых блоков в любом запущенном процессе (в примере — pid=15034). Вот как выглядит распределение в нашем приложении за несколько секунд мониторинга:
value ------------- Distribution ------------- count
2 | 0
4 | 1407
8 | 455
16 |@@ 35592
32 |@@@@@@@@@@@@@@@@ 239205
64 |@@@@@@@ 112358
128 |@@@@ 55813
256 |@@@@@@ 91368
512 |@ 17204
1024 |@ 19751
2048 |@@ 33310
4096 | 2082
8192 | 554
16384 | 15
32768 | 0
65536 | 3960
131072 | 0
Круто, правда? Все это на лету, без перекомпиляции! Мы, должно быть, где-то очень близко к разгадке всех тайн.
Также вы можете собирать любую статистику по любой функции, экспортируемой из вашего приложения! Правда, с опциями компиляции -O1 и выше большинство интересных функций может попросту пропасть из экспорта, компилятор «заинлайнит» их в код и вам не на чем будет ставить «пробы».
Брендан Грег (Brendan Gregg), апологет dtrace, стал учителем и наставником на все эти безумные дни:
In some cases, this [dtrace] isn’t a better tool – it’s the only tool.— заявлял он.
Вот здесь нечто похожее на то, что нам нужно, однако Брендан оставил комментарий:
FreeBSD: DTrace can be used as with Solaris. I'll share examples when I get a chance.До сегодняшнего дня случай ему, к сожалению, так и не выпал. Но по-сути там все то же самое, что и в Solaris, только вместо sbrk вызывается mmap\munmap.
Пришлось вникать в премудрости языка D. Многие области, например, приведение типов, особенно агрегированных значений, так и не удалось победить.
Вначале я решил испробовать немного переделанный скрипт отсюда:
Код
#!/usr/sbin/dtrace -s
/*#pragma D option quiet*/
/*#pragma D option cleanrate=5000hz*/
pid$1::mmap:entry
{
self->addr = arg0;
self->size = arg1;
}
pid$1::mmap:return
/self->size/
{
addresses_mmap[arg1] = 1;
printf("<__%i,%Y,mmap(0x%lx,%d)->0x%lx\n", i++, walltimestamp, self->addr, self->size, arg1);
/*ustack(2);*/
printf("__>\n\n");
@mem_mmap[arg1] = sum(1);
self->size=0;
}
pid$1::munmap:entry
/addresses_mmap[arg0]/
{
@mem_mmap[arg0] = sum(-1);
printf("<__%i,%Y,munmap(0x%lx,%d)__>\n", i++, walltimestamp, arg0, arg1);
}
pid$1::malloc:entry
{
self->size = arg0;
}
pid$1::malloc:return
/self->size > 0/
{
addresses_malloc[arg1] = 1;
/*
printf("<__%i,%Y,malloc(%d)->0x%lx\n", i++, walltimestamp, self->size, arg1);
ustack(2);
printf("__>\n\n");
*/
@mem_malloc[arg1] = sum(1);
self->size=0;
}
pid$1::free:entry
/addresses_malloc[arg0]/
{
@mem_malloc[arg0] = sum(-1);
/*printf("<__%i,%Y,free(0x%lx)__>\n", i++, walltimestamp, arg0);*/
}
END
{
printf("== REPORT ==\n\n");
printf("== MMAP ==\n\n");
printa("0x%x => %@u\n",@mem_mmap);
printf("== MALLOC ==\n\n");
printa("0x%x => %@u\n",@mem_malloc);
}
Выглядит достаточно просто: сохраняем все вызовы malloc\free, а также места их вызовов. На malloc — увеличиваем счетчик у адреса, на free — уменьшаем. Затем изучаем полученный лог и находим утечку (адреса с счетчиками > 0). Вся проблема заключается в том, что при ~150К malloc-ов в секунду, функция ustack() (сохраняющая стек, т.е. место вызова) начинает буквально хоронить весь процесс своим весом (похоже на случай с valgrind-ом). Я попытался убрать стек из вывода и просто собирать адреса и счетчики к ним, в итоге почему-то многие счетчики были глубоко в минусах (неужели испорченная куча и двойные освобождения?), а адресов с положительными значениями счетчиков практически не было… При этом dtrace часто плевался ошибками вида:
dtrace: 3507 dynamic variable drops with non-empty dirty list
dtrace: 2133 dynamic variable drops
dtrace: 120 dynamic variable drops with non-empty dirty list
dtrace: 993 dynamic variable drops
dtrace: 176 dynamic variable drops with non-empty dirty list
dtrace: 1617 dynamic variable drops
dtrace: 539 dynamic variable drops with non-empty dirty list
dtrace: 10252 dynamic variable drops
dtrace: 3830 dynamic variable drops with non-empty dirty list
dtrace: 17048 dynamic variable drops
dtrace: 39483 dynamic variable drops
dtrace: 1121 dynamic variable drops with non-empty dirty list
dtrace: 35067 dynamic variable drops
dtrace: 32592 dynamic variable drops
dtrace: 10081 dynamic variable drops with non-empty dirty list
Также часто мелькали сообщения о битых адресах в стеке.
Это наталкивало на мысль, что он просто не успевает правильно обрабатывать все события, поэтому счетчики уходят в минуса… Либо же это проблемы с кучей\стеком. Кроме того, вызовов free накручивалось в 1.5 раза больше, чем malloc-ов (значит, все-таки, двойные освобождения?)
Решил попросить помощи у участников почтовой рассылки dtrace.

Судя по архиву, некогда оживленная рассылка переживала не лучшие времена. К большому изумлению, ответ последовал в первые же минуты, хотя отреагировали всего два участника. Один посоветовал использовать аргумент, задающий кол-во кадров стека для сохранения: ustack(nframes). Это не помогло, даже ustack(1) убивал весь процесс. Еще посоветовали использовать libumem (полагая, вероятно, что я приполз с Solaris-а).
Дальше пошли бессистемные попытки, как то: сбор статистики по размерам, выделяемым malloc-ами, и попытка отфильтровать только определенные размеры, ну чтоб хоть как-то уменьшить частоту срабатывания датчиков. Безрезультатно, такое чувство, что ustack() задуман для самых минимальных нагрузок, скажем, до 100 вызовов в секунду. Или же нужно уметь его правильно готовить, сохраняя результат в какой-то бесконечный внутренний буфер, без раскручивания стека на каждом запросе. Но до этого, к сожалению, так и не дошло.
Попытался подойти к задаче с другой стороны — начать подсчет вызовов конструкторов и деструкторов всех объектов в коде, тогда мне фактически не нужно сохранить стек. Результатов это тоже не дало. Никаких расхождений выявлено не было, хотя, конечно же, я поленился «опробировать» все объекты в коде, а ограничился только лишь вызывающими подозрения.
О demangle
Для установки датчиков в вызовы своих функций, требуется произвести т.н. demangle имен. Тут, как на зло, FreeBSD подкинула очередной сюрприз. Простой:
обрушивает утилиту. Баг до сих пор не исправлен в 11.1. Пришлось запускать demangle-инг на одном из серверов с версией 11.0.
echo _ZZN7simlib318SIMLIB_create_nameEPKczE1s | /usr/bin/c++filtобрушивает утилиту. Баг до сих пор не исправлен в 11.1. Пришлось запускать demangle-инг на одном из серверов с версией 11.0.
Все стало походить на борьбу с ветряными мельницами.
Вообще, вывод dtrace уверял, что это не утечка, а испорченная куча \ двойное освобождение. Если это правда, то все очень плохо, без спец. библиотеки тут не обойтись.
Но все это оказалось полной ерундой и лишь увело от цели в сторону на несколько дней.
jemalloc
Примечательно, что в самой FreeBSD используется очень крутой и продвинутый менеджер памяти, еще аж с лохматой 7-ой версии. Вернее, я просто совершенно забыл про это… По количеству настроек и опций все остальные библиотеки-обертки даже рядом не валялись. Повозившись с доками, удалось запустить приложение с опцией:
setenv MALLOC_CONF utrace:trueПосле чего, следуя инструкции отсюда собрать (ktrace) и сгенерить (kdump) лог всех операций с памятью. В их числе оказались и realloc-и, которые в скрипте из статьи не работали, а вторая версия скрипта из комментариев (корректно обрабатывающая realloc-и) вела на несуществующую страницу (и даже «Wayback Machine» ничего не смог найти). Пришлось дописать поддержку realloc-ов, но по сути это дало лишь кучу указателей, где, возможно, происходит утечка, без какого-либо намека на то, где и кем они были выделены.
By skimming through nearby trace output, we may be able to understand a bit more about the location of the leak in the source too :-)— шутил автор статьи.
Чтобы заработали другие опции jemalloc-а (как-то: обнаружение двойных освобождений, выход за пределы массивов, расширенная статистика по обращению к памяти и т.п.), требовалась либо перекомпилляция всего ядра с доп. опциями, либо CURRENT сборка ОС (то, что удалось понять из man-а). Однако, шли шестые сутки поиска и дальнейшее копание в jemalloc было решено приостановить, хотя тема весьма интересна и я надеюсь к ней еще вернуться (надеюсь, не в похожих обстоятельствах).
Что в итоге помогло найти утечку
Поочередное отключение каждого модуля и подсистемы приложения и их комбинаций. Пойди я этим путем в самом начале — и проблема была бы решена в течении суток, но ведь сколько всего нового и интересного пришлось бы пропустить!
В каждой грустной истории должны найтись и положительные стороны.
Нотки позитива
- в процессе поиска иголки было исправлено некоторое количетсво мелких (и не очень) багов, в основном, выделения памяти, там где можно обойтись без оных;
- убран ARC ZFS (зачем он нужен на HTTP сервере, который ничего не пишет на диск, только память жрет, причем весьма существенно);
- проштудированы статьи на тему виртуальных деструкторов и прочих хитрых штук из мира C++;
- написан с десяток скриптов на D, просмотрено несчетное кол-во туториалов (по dtrace);
- погружение в разные реализации malloc\free, знакомство с понятиями arenas и slabs;
- изучены все изветсные баги, связанные с памятью во всех сторонних либах, использованных в проекте;
- узнал историю и драму, развернувшаяся вокруг ОС Solaris в последние годы ее существования;
- прокачаны \ восстановлены навыки работы с GDB.
Безумства, в которые не стоит впадать даже в моменты полного отчаяния
- послать все подальше и переехать на Linux. Думаю, эта мысль не раз посетила любого ярого приверженца FreeBSD, вызвана будь-то отсутствием полноценного Google Chrome, Skype, либо крутых самописных системных утилит. Не поддавайтесь панике, рано или поздно все проблемы решаться и вы вновь вернетесь к любимой ОС;
- попытки пролезть hex-view-ером в раздел со свопом (зачем? посмотреть что вытесняется из памяти и попробовать догадаться где утечка, хаха);
- выпилить всю многопоточность из приложения, чтобы большинство средств выше заработало;
- нанять фрилансера-профессионала, который все быстро починит.
Выводы
- Тщательное протоколирование всех изменений в релизах. Практически во всех случаях, утечка будет связана с одним из самых последних коммитов. Если вы крайне невезучи — то с коммитом за последние пару-тройку месяцев. Пробуйте откатывать все изменения, по одному и в комбинациях, перепроверяйте все по несколько раз. Малейшая оплошность — и вас унесет на несколько дней\недель не тем течением;
- Если вам дорого время — не пытайтесь использовать универсальные средства обнаружения утечек, особенно в high-load проектах;
- Не хватило виртуозности владения dtrace и можно было бы ухитриться обрабатывать только небольшой процент всех запросов. Но тут в post-mortem обработке нужно правильно отфильтровать ложные срабатывания и т.п. На освоение такого подхода, к сожалению, не хватило сил и времени.
Считаю финал этой истории крупным везением. Повезло, что утечка стабильно воспроизводилась на всем протяжении поиска. Что была возможность сколько угодно раз перезапускать заново собранное приложение на одном из релизных серверов без особого вреда пользователям. Что от релиза бага до возникновения проблемы прошло всего несколько дней, а не пол-года, когда шансы найти проблему стали бы исчезающе малы…
Вопросы и ответы
Так в чем же, все-таки, была причина утечки?
Как упоминалось выше, сервер проводит аукцион среди ответов вышестоящих серверов. Если ответов приходит больше максимального значения, то они «обрезаются» (берется top N results).
Топ хранится в std::list, где элементы — это указатели на объекты-биды. Один из коммитов привнес такой чудесный код для обрезания топа: list.resize(max_results). Как вы уже догадались, list.resize не вызывает delete на элементы-указатели. Нужно пройтись и ручками освободить память всех лишних указателей до вызова resize.
Почему такое продолжительное время после релиза версии с багом утечка не давала о себе знать?
Ответы серверов всегда влазили в top N results и ничего не обрезалось. Просто у определенных пользователей в какой-то момент ответов стало больше и они перестали влазить в топ.
Почему откат на предыдущие версии не помог сразу выявить проблему?
Здесь сыграл человеческий фактор. Дело в том, что на старте приложение начинает весьма активно отъедать память, замедляя интенсивность в течении несколько часов. Вероятно, в угаре поиска, это было воспринято как продолжающаяся утечка, и проблемное место выявить не удалось.
Почему проблема всплыла лишь на определенной части серверов?
Из-за обслуживаемых на данной группе серверов аккаунтов. У каких-то из них в аукционе стало возвращаться огромное количество бидов, не влазящих в топ. У остальных аккаунтов, обслуживаемых другими серверами, в топ аукциона попадали все ответы, либо редко превышали макс. размер списка.
Расскажите свои истории борьбы с утечками, особенно на ЯВУ. Действительно ли способ «рестартуем приложение каждые N минут» настолько популярен в качестве универсального решения? Так ли же все печально в среде ОС Linux или «tcmalloc и co.» действительно сходу помогают «найти и обезвредить»?
UPD1: Пока готовил этот текст, случайно наткнулся на возможность выявления утечек средствами clang, интересно было бы попробовать…
Спасибо всем, кто дочитал до конца!
