Comments 79
Еще один…
Два русских парня Konstantin Tretyakov и Evgeny Skvortsov за выходные написали язык который как бы «not an officially supported Google product»
Когда хабр успел скатиться до уровня пикабу и нецензурщины в комментариях?
16 standards.
SQL уже явный анахронизм
А с другой стороны — слишком низкоуровневый язык, чтобы запросы выглядели легко и в них можно было легко и быстро разобраться (сложные запросы).
и тестировать SQL сложно.
насчет тестирования наверное нужен пример. я не очень понял суть проблемы.
ПС: Если честно, полотно в 2 страницы того, что приведено в статье — еще хуже читалось бы.
docs.oracle.com/cd/B13789_01/server.101/b10752/hintsref.htm
Все это для достижения максимальной эффективности.
- Оптимизация плана запроса, все зависит от субд и вообще не задача SQL — это язык для аналитики а не оптимизации.
- Во многих базах можно написать от нативного кода до специальных процедур которые будут работать более оптимальную
- Легко/трудно это субъективная оценка. На мой взгляд SQL более простой(менее сложный) чем большинство ЯП.
- Тестировать элементарно — просто выполнить запрос на реальной или тестовой таблице(если это оп. модификации.)
SQL — это язык для аналитики а неИменно. Это язык для аналитики, а не разработки.оптимизации
Аналитика это не разработка?) На мой взгляд большая часть ПО это как раз аналичитеские инструменты где нет нужны в черезмерной оптимизации потому что и так работает приемлемо, и где основные проблемы как раз в трудозатратах, у SQL тут как раз много преимуществ — это язык в первую очередь для сокращения трудозатрат а не машинных тактов.
При этом я не соглашусь что SQL субд работают медленно.
Более того зачастую то что в таких базах идет из коробки, большинство программистов не сможет написать оптимальнее, без багов и за разумное время.
Но если вам для каких то специфических задач не нужны возможности SQL субд, не используйте.)
Аналитика это не разработка?Аналитика — это не разработка.
При этом я не соглашусь что SQL субд работают медленно.Этого я и не утверждал, в общем-то.
Более того зачастую то что в таких базах идет из коробки, большинство программистов не сможет написать оптимальнее, без багов и за разумное время.Дело не в том, может кто-то конкретный написать лучше или не может.
Руляционная СУБД — это некоторым образом вещь в себе. Она доступна нам в виде интерфейса высокого уровня, плюс несколько ручек, которые можно крутить — всякие размеры кеша и подобное. У такого подхода есть некоторые ограничения. Например, иногда программист может составить лучший план для какого-то конкретного запроса, чем это делает сама субд. Он может косвенно влиять на выбор плана — например, через создание/удаление индекса, но это именно что косвенное влияние. Соответственно, крутые спецы по базам данных из-за этого в некотором роде похожи на шаманов — если тут ударить в бубен и там станцевать, то может пойти дождь, но это не точно.
С использованием функций, CTE и всех инструментов языка — от distinct on и оконок, вплоть до хитрых группировок и собственных агрегатных функций, запросы можно писать очень даже понятными и простыми при их большом объеме. Иногда они становятся настолько большими, что отдельные cte хочется вынести в другой файлик (впрочем для этого есть вьюшки).
Писать криво можно на любом языке, для этого надо просто быть рукожопом. SQL сам по себе никак не провоцирует писать кривой и некрасивый код и это однозначно лучший из всех существующих языков для манипуляций с БД
— Условие джойна. У нас в таблицах описаны внешние ключи, и в 90% случаев джойн делается для получения данных связанной сущности, логичнее делать джойн по названию связи. FOREIGN KEY fk_user(user_id, table_user.id); table_a JOIN table_user USING(fk_user)
— Джойн для получения данных связанной сущности это вообще неоптимальная вещь. У нас есть одна статья и много комментариев, и чтобы получить статью с комментариями, надо сделать джойн с таблицей комментариев, и в результате будет куча копий строки из таблицы статей.
— Одна таблица на структуру данных. Нельзя сделать таблицу deleted_users и перемещать туда удаленных пользователей с сохранением всех связей по id с другими таблицами, надо делать поле is_deleted и учитывать его во всех запросах.
— Одна таблица на структуру данных. Нельзя сделать таблицу deleted_users и перемещать туда удаленных пользователей с сохранением всех связей по id с другими таблицами, надо делать поле is_deleted и учитывать его во всех запросах.
вот прям сейчас смотрю на проекте именно на реализацию с deleted users… и если честно, лучше б это было поле is_deleted. А зачем его учитывать? Сделайте view ActiveUsers по условию not deleted да и все? Любой из этих вариантов жизнеспособен. Какой — выбирать вам :-) Еще раз. Язык запросов тут не причем.
— Джойн для получения данных связанной сущности это вообще неоптимальная вещь. У нас есть одна статья и много комментариев, и чтобы получить статью с комментариями, надо сделать джойн с таблицей комментариев, и в результате будет куча копий строки из таблицы статей.
Можно делать и не так. Оптимально ли? Зависит от приложения.
table_a JOIN table_user USING(fk_user)
Согласен, выглядит «стильно» — но зачем? Не читаемо абсолютно. Кто его знает что там за фк у вас. а если он составной… и его название выглядит как FK_scheme_table_field1_scheme_table_field2_on_scheme_table2_field1_scheme_table2_field2 (утрировано конечно) то назвать это более читаемым что то я не могу. А сокращенное название никак не даст представление о том, что там. Откуда привычка экономить буквы? Вы же не стели бы читать статью в которой все слова написаны сокращениями? Зачем?
вот прям сейчас смотрю на проекте именно на реализацию с deleted users… и если честно, лучше б это было поле is_deleted.
Так с ограничениями SQL конечно лучше делать is_deleted. Но вот конкретные примеры недостатков было бы интересно узнать.
Можно делать и не так. Оптимально ли?
Так, как надо делать, в SQL сделать нельзя, пример далее.
Согласен, выглядит «стильно» — но зачем?
Затем же, зачем объявляются классы, выделяются функции, именуются переменные. Для семантики. В ORM например так и делают, джойн по названию связи, это выражает то, что мы хотим сделать.
Кто его знает что там за фк у вас. а если он составной
и его название выглядит как FK_scheme_table_field1_scheme_table_field2_on_scheme_table2_field1_scheme_table2_field2
Если он составной, в JOIN все равно будут эти поля.
Так не надо такие названия давать, название fk это название соответствующей связанной сущности.
А сокращенное название никак не даст представление о том, что там.
Нам не надо знать, что там, нам надо сказать движку, что мы хотим получить данные связанной сущности. Что там мы и так знаем, если работаем с этими таблицами не первый раз. А первый раз можно и посмотреть. Вы же не пишете в название функции всю ее реализацию printHelloPrintWorldPrintNewline().
Откуда привычка экономить буквы?
Тут цель не экономить буквы, а выразить то, что мы хотим выразить.
Но это было скорее о том, как надо было изначально сделать джойны, а если уж делать по-нормальному, то надо делать это более объектно-ориентировано.
SELECT id, title, text,
author(id, nickname),
comments(id, text, author(id, nickname) WHERE moderated = true)
FROM article
WHERE article.id = 123Ну так мы же про язык запросов говорим. Дублирование данных при джойне это его недостаток. Потому что это делалось в те времена, когда плоские таблицы в результате было проще реализовать, чем иерархичные объекты, да и не совсем было понятно как вообще делать.
Ну, в принципе, какая-нибудь OData (https://www.odata.org/) подходит под все ваши требования. И возвращает, обычно, JSON с деталями.
Учитывая, что задачи OData и SQL схожи — получение данных, можно сказать что OData и есть современная реализация языка запросов.
Условия джойна бывают не только по FK, не только по равенству и тд. Кроме того, дата сатанисты не указывают FK в 95% проектов. В частности по той причине, что FK в аналитических базах не работают и не вырезаны от туда совсем только для документации.
— Джойн для получения данных связанной сущности это вообще неоптимальная вещь.
Это решается довольно просто при помощи агрегатных функций
— Одна таблица на структуру данных.
«Оба хуже».
Смотря что здесь хочется оптимизировать. Если не хочется писать условия на is_deleted в запросах, но при этом удаленные нужно сохранять — то это совсем непонятно. Либо можно удалять данные, либо нельзя. Лучше второе :)
Если оптимизируется скорость:
— (в зависимости от базы) можно сделать, например, партиционирование. И тогда deleted будут физически лежать в физически отдельной таблице.
— сделать условные индексы для is_deleted = true и is_deleted = false.
Но лучше не делать булевых полей совсем, а вместо них делать даты, когда этот deleted произошел. Очень поможет в будущем :)
А есть еще такая архитектура как anchor modeling…
Условия джойна бывают не только по FK, не только по равенству и тд.
Поэтому я и написал "в 90% случаев".
Но вообще любой конкретный набор условий означает некую связь, которой можно дать название. Как блоку кода, который можно вынести в функцию.
А уж если и этого недостаточно, то для 1% случаев можно и специальный оператор предусмотреть. Это улучшит понимаемость кода — написан редкий оператор, значит тут что-то нестандартное, надо обратить внимание на это место. А то часто пропускаешь какой-нибудь дополнительный AND в условии ON, который начинается со стандартной связи по other_table_id = other_table.id.
Это решается довольно просто при помощи агрегатных функций
Каким образом с помощью агрегатных функций можно убрать дублирование строки таблицы articles в этом запросе?
SELECT articles.*, comments.*
FROM articles
INNER JOIN comments ON comments.article_id = articles.id
WHERE articles.id = 123Смотря что здесь хочется оптимизировать.
Поддержку, то есть чтение и написание кода, понимание что там происходит, упрощение модификаций при изменении требований.
Для этого существуют соответствущие инструменты. База не должна об этом думать
> Каким образом с помощью агрегатных функций можно убрать дублирование строки таблицы articles в этом запросе?
group by articles.id
а все камменты обернуть в какой-нибудь array_agg, предварительно преобразовав в json, например
> Поддержку, то есть чтение и написание кода
Тогда точно не надо уметь выносить объекты в отдельную таблицу без нарушения связей. На архитектуру такое повлияет очень «не очень».
Data vault или ancor modeling применяют в проектах с часто меняющимися требованиями
Для этого существуют соответствующие инструменты. База не должна об этом думать
Чего это не должна, когда связи между таблицами это одна из ее обязанностей?
а все камменты обернуть в какой-нибудь array_agg, предварительно преобразовав в json, например
Ага, и парсить обратно в приложении. Реализуем объектно-ориентированную БД вручную. Проще уж тогда 2 запроса сделать. Я подразумевал все-таки структурированный результат, а не одну большую строку.
На архитектуру такое повлияет очень «не очень».
Например? 2 переменных List<User> в приложении с разными названиями же не влияют на архитектуру таким образом.
а почему вы так считаете? Просто от того, что ему чуть менее 50 лет? Не стильно-модно-молодежно?Просто от того, что SQL создавался не как язык для программистов, а как язык для менеджеров. Мол, обычный человек сможет извлекать нужные ему данные по нужным критериям, без участия программистов. В итоге получился язык, сильно похожий на естественный. Манипулировать им — довольно сложно. Для машин нужен нормальный машинный или полу-машинный формат, типа json или что-то подобное.
Представьте, если бы по http-апи приходили параметры запроса не в таком виде: {id: 1, name: «Joe», ...}, а в виде обычного текста «user with id 12, name Joe, ...» и вам надо было сначала его парсить, потом что-то с ним делать, потом обратно превращать в обычный текст и отдавать обратно. Да вы бы первый сказали «вы тут что, больные все собрались?» и уволились бы оттуда.
Или разметка сайта не тегами "\<html\>...\<body\>....\</body\>\<html\>" бы делалась, а текстом типа: «Документ с заголовком: название заголовка. Содержимое документа: блок такой-то с содержимым таким-то».
Но базы данных — это сложная тема, тут не любят изменений, а на первое место выходит надежность. Плюс уже полвека так работает, все привыкли. Но это не значит, что не существует лучшего пути. В конечном счете, сами базы данных не с текстом ведь работают, они у себя внутри парсят запросы на синтаксические деревья в пригодном для машинной обработки виде.
Огромное количество ОРМ придумано потому, что люди не хотят напрямую работать с чистым sql. Но эта практика изначально порочна, потому что в конечном счете надо трансформировать запрос обратно в «человеческий» язык, перед отправкой в базу данных, со всеми его ограничениями.
ОРМ всё же придумали не из-за SQL, а из-за реляционной модели, которая плохо ложится на объектную. Есть объектные базы данных с поддержкой SQL и без ОРМ.
Так этому билдеру не всё ли равно генерить json, xml или sql?
Забавно. По форме вашего комментария можно сделать вывод, что вы со мной не согласны, тогда как по смыслу — полностью поддерживаете мои слова.
Я о том, что билдеры помогают справиться с проблемами, которые порождает строковое представления языка. Билдеры повторяют сам язык, не привносят в него ничего нового и в итоге «пишите» вы на том же самом языке, но не строками, а функциями.
Вы приводите в пример выше JSON как потенциальную альтернативу SQL, но с ним возникнут ровно такие же проблемы (отсутствие подсветки, сложность конкатенации) и для JSON тоже используют билдеры. Для XML/HTML это тоже справедливо.
Я не говорю что у SQL нет проблем и я согласен, что придуман он был «как язык для менеджеров», но билдеры здесь ни при чем.
Под database first подходе подразумевается вся бизнес-логика в виде хранимых процедур? Ну, это тоже антипаттерн.
Если нет, и вы имеете в виду куски чистого sql вперемешку с обычным кодом, то представьте следующее. Вам нужно отдать список чего-то по запросу, и в этом запросе может быть десяток различных параметров фильтрации. Представляете, насколько криво и нечитаемо будет смотреться конкатенация строк чистого sql запроса в таком контроллере?
Фронтенд как-то выживает с шаблонизаторами.
Ну покажите шаблон для построения такого запроса:
$query = Order::find();
if ($form->userName) {
$query->join('users');
$query->andWhere(['user_name' => $form->userName]);
}
if ($form->orderBy === 'orderTypeName') {
$query->join('orderTypes');
$query->orderBy('orderTypes.name');
}{#userName}, users{/userName}
{#orderTypeName}, orderTypes{/orderTypeName}
...
{#}and user_name = {userName}{/}
{#orderTypeName}order by orderTypes.names{/orderTypeName}Типа того.
Не-не, какое типа, вы весь запрос покажите. У меня же весь запрос целиком. В частности интересует раздел WHERE, который тут может быть пустым. Для полноты картины можно представить, что в первом if тоже orderBy добавляется, и раздел ORDER BY может быть пустым, на 1 поле, и на 2. Кстати, вызов join() добавляет все нужные ON, потому что берет информацию из ORM.
Задача для собеседования: как написать не пустой where, который ничего не делает.
Впрочем, пустым я его видел примерно никогда, как и сортировку.
Вы мне что доказать пытаетесь? Что билдер удобнее? Я с этим не спорил.
А с чем вы спорили? Разговор был про "разные способы управления данными, со своими преимуществами недостатками". Удобность билдера привели как преимущество, вы на это возразили.
А теперь перечитайте ветку обсуждения непредвзято.
Я перечитал ее когда писал коммент. Высказывается предложение "использовать чистый SQL", высказывается проблема "может быть десяток различных параметров фильтрации, конкатенация строк чистого sql запроса будет смотреться криво и нечитаемо", почему и предлагается использовать orm/query builder, а вы в ответ на это предлагаете вместо orm/query builder решать ее шаблонизатором.
Задача для собеседования: как написать не пустой where, который ничего не делает.
where 1=1
Это имеется в виду?
Нет, database-first это не про бизнес-логику, а про соотношение схемы данных и кода апп-сервера. Если ещё точнее — то про то, что в этом соотношении "главнее". Вот тут ещё неплохо написано, что это, и почему будет хорошей идеей: https://blog.jooq.org/tag/database-first/
Вот смотрел я на го, когда впервые увидел — все понятно.
В этом примере я не понял ничего из синтаксиса. Может, конечно, дело привычки, но на вид — это не упрощение
И что, эта белиберда понятнее SQL?
При этом содержимое таких запросов неочевидно для восприятия.
Угу, а вот из этого
Limit(Mentions, 10);
Mentions(person:, mentions? += 1) distinct :-
gdelt-bq.gdeltv2.gkg(persons:, date:),
Substr(ToString(date), 0, 4) == «2020»,
the_persons == Split(persons, ";"),
person in the_persons;очевидно что будет колонка mentions_count
Substr(ToString(date), 0, 4) == «2020»
И шанс получить по лбу сразу 2мя граблями!
1) преобразование даты в строку вычеркнет любые индексы. не думаю, что в новой системе как-то по другому это отработает.
2) преобразование даты в строку различается для разных локалей и временных зон. Попробуйте угадать результат, когда на клиенте и сервере локали будут различаться.
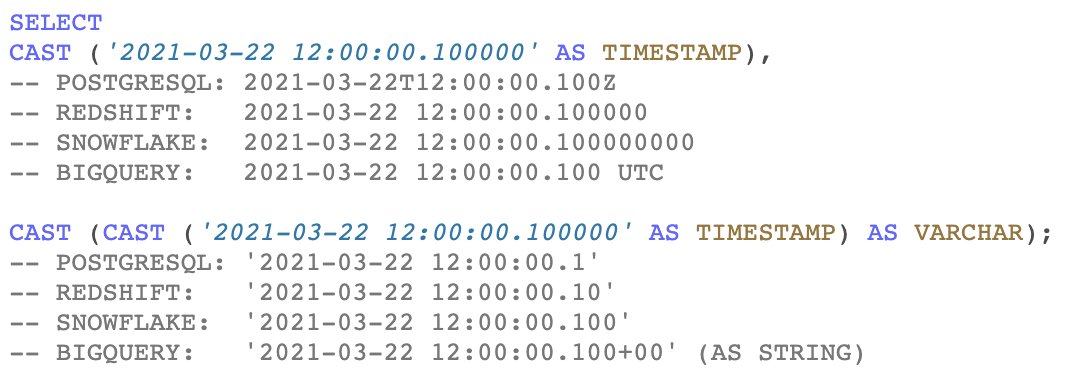
Код должен выглядеть примерно так:
@OrderBy(Mentions, "mentions desc");
@Limit(Mentions, 10);
Mentions(person:, mentions? += 1) distinct :-
gdelt-bq.gdeltv2.gkg(persons:, date:),
Substr(ToString(date), 0, 4) == "2020",
the_persons == Split(persons, ";"),
person in the_persons;":-" — это определяет тело функции (предиката), операции в ней разделены запятой.
В целом, всё понятно. Документация, кстати, тут: colab.research.google.com/github/EvgSkv/logica/blob/main/tutorial/Logica_tutorial.ipynb#scrollTo=DznTm114TvD7
tzlom
я думаю, в примере описка — должно было быть, наверно
Mentions(person:, mentions_count? += 1) distinct :-Да, точно. У них есть такой пример в документации:
AnonymizedCodeContribution(cl_lengths: [110, 220, 405], org: "ads");
AnonymizedCodeContribution(cl_lengths: [30, 51, 95], org: "ads");
AnonymizedCodeContribution(cl_lengths: [10, 20, 1000], org: "games");
HarmonicMean(x) = Sum(1) / Sum(1 / x);
OrgStats(
org:,
mean_cl_size? Avg= cl_size,
harmonic_mean_cl_size? HarmonicMean= cl_size) distinct :-
AnonymizedCodeContribution(cl_lengths:, org:),
cl_size in cl_lengths;
The following table is stored at OrgStats variable.
org mean_cl_size harmonic_mean_cl_size
0 ads 151.833333 75.402468
1 games 343.333333 19.867550
Вопросительный знак — это агрегированное поле.
В общем, это фантазия на тему Пролога.
Теперь бы еще поддержать рекурсии, наследование с полиморфизмом, сессии изменений, события, ограничения, логику представлений, и еще много чего и получится lsFusion.
При условии, что на нём будет удобно писать в большинстве случаев (мне пока это не очевидно, но вдруг) — популярность свою он всё равно найдёт. Есть множество аналогичных примеров языков, которые транслируются в C/С++ или в итоге выполняются виртуальной машиной на С/С++ — здесь принцип для меня тот же самый, и проблемы по факту того же класса.
В нем поддерживаются модули, операции импорта и возможность работы Logica прямо из интерактивной оболочки Jupyter Notebook.
Теперь Юпитер Ноутбук будет называться Льюпитер?
Здоровый консерватизм — наше всё! )
@OrderBy(Mentions, «mentions desc»);
Limit(Mentions, 10);
Mentions(person:, mentions? += 1) distinct :-
gdelt-bq.gdeltv2.gkg(persons:, date:),
Substr(ToString(date), 0, 4) == «2020»,
the_persons == Split(persons, ";"),
person in the_persons;
Это вот читабельнее SQL? Серьезно?
select * from `table`кодить так
from `table` select *дело в том что пока мы не укажем имя таблицы, SQL нам ни чем нам не поможет в плане быстрого ввода схем и таблиц.
Google представил новый язык программирования Logica