Аннотация
По мере развития ИИ-систем, компаниям и регулирующим органам придётся принимать сложные решения о том, безопасно ли их обучать и развёртывать. Чтобы к этому подготовиться, мы изучили, как разработчики могут приводить “обоснования безопасности” – то есть, структурировано аргументировать, почему маловероятно, что их ИИ-системы вызовут катастрофу. Мы предлагаем подход к организации обоснований безопасности и обсуждаем четыре категории аргументов: полная неспособность вызвать катастрофу, достаточно сильные меры контроля, убеждённость в добросовестности системы, несмотря на её способность причинить вред и, если ИИ-системы станут куда сильнее, апелляция мнению надёжных ИИ-советников. Мы оценили конкретные примеры аргументов в каждой категории и обрисовали, как их можно комбинировать, чтобы обосновать, что ИИ-система безопасна.

1. Введение
Эксперты по ИИ в последнее время призывают обращать внимание на риски продвинутых ИИ-системы. Например, Джеффри Хинтон, которого называют “крёстным отцом” современного ИИ, недавно покинул Google, чтобы повышать беспокойство о будущих рисках ИИ-систем (Heaven, 2023). ИИ могут причинить обществу много вреда (Toreini et al., 2022). Самые опасные сценарии, о которых предупреждают Хинтон и прочие, включают в себя риски злоупотребления ИИ-системами и их выход из-под контроля (Hendrycks et al., 2023).
Чтобы смягчить эти угрозы, исследователи призывают разработчиков приводить свидетельства в пользу безопасности их систем (Koessler & Schuett, 2023) (Schuett et al., 2023). Однако, подробности того, как эти свидетельства должны выглядеть, не озвучивались. К примеру, Андерльюнг и пр. расплывчато заявили, что свидетельства должны “основываться на оценках опасных способностей и контролируемости” (Anderljung et al.,2023). Аналогично, предложенный недавно в Калифорнии законопроект требует от разработчиков предоставить “положительное определение безопасности”, которое бы “исключало угрожающие способности” (California State Legislature, 2024) Такие туманные требования поднимают вопросы: на каких ключевых допущениях должны основываться эти оценки? Как разработчикам включать в них другие виды свидетельств? Этот отчёт призван ответить на эти вопросы. Мы подробно рассмотрим, как разработчики могут обоснованно заявить, что развёртывание их ИИ-систем безопасно.
Сначала мы представим концепцию “обоснования безопасности”. Это метод представления свидетельств в пользу безопасности, который используется в шести индустриях Великобритании (Sujan et al., 2016). “Обоснование безопасности” – это структурированный аргумент о том, что система скорее всего не причинит значительного вреда при развёртывании в определённом окружении. Дальше этот отчёт объясняет, как разработчики могут составлять обоснования безопасности в контексте катастрофических рисков ИИ.
Раздел 2 – это краткое содержание.
В Разделе 3 определяются основные термины.
В Разделе 4 перечислены рекомендации по использованию обоснований безопасности для принятия решений о развёртывании ИИ.
В Разделе 5 перечислены возможные аргументы в пользу безопасности ИИ-систем. Они разделены на четыре категории: неспособность, контроль, добросовестность системе и доверие. Там перечислены аргументы из каждой категории и оценивается и практичность, максимальный вес и масштабируемость.
Наконец, в Разделе 6 объясняется, как можно комбинировать аргументы из Раздела 5 в общее обоснование безопасности.
2. Краткое Содержание

2.1. Подход к структурированию обоснований безопасности ИИ
Наш подход к структурированию обоснований безопасности, основан на традиционном анализе безопасности – методологиях вроде “Анализа видов и последствий отказов” (FMEA) (Kritzinger, 2017). Это предполагает шесть шагов:
Определить ИИ-макросистему: это совокупность всех ИИ-систем и инфраструктуры, которая их поддерживает. Для оценки обоснования безопасности сначала надо понять, что разработчики предлагают сделать: как устроена макросистема и в каком окружении она будет работать?
Определить неприемлемые исходы: Разработчкиам надо декомпозировать несколько абстрактное утверждение, что ИИ-макросистема “не вызовет катастрофу” до более конкретной модели угроз вроде “веса ИИ-системы не покинут сервер”, “ИИ-система не разработает оружие массового уничтожения” и т.д. Дальше обоснование безопасности аргументирует что именно эти исходы не произойдут.
Обосновать допущения: Дальше разработчики дополнительно обосновывают утверждения об окружении развёртывания, например “веса ИИ-системы надёжно защищены от людей” или “компании с доступом к файн-тюнингу, будут следовать условиям лицензионного соглашения”. Когда утверждения об окружении развёртывания установлены, разработчики могут перейти к тому, как поведение их ИИ-систем могло бы вызвать катастрофу.
Разложить макросистему на подсистемы: современные ИИ-макросистемы большие (миллионы моделей) и взаимодействуют с многими сервисами и окружениями. Чтобы их было проще анализировать, разработчикам сначала надо проанализировать поведение меньших подсистем. Пример подсистемы – GPT-агент вместе с классификатором, который мониторит его вывод.
Оценить риски подсистем: Сначала разработчикам надо определить, как каждая подсистема могла бы в одиночку (т.е. без значительного вовлечения других подсистем) достичь неприемлемого исхода. Затем им надо обосновать, что у каждой подсистемы вероятность этого приемлемо мала.
Оценить риски макросистемы: Наконец, разработчикам надо определить, как взаимодействие подсистем могло бы привести к неприемлемому исходу, и обосновать, что и такие угрозы маловероятны.
Следуя стандартам Великобритании, мы будем резюмировать обоснования безопасности при помощи нотации структурирования цели (GSN) – блок-схемы, иллюстрирующей, как связаны между собой утверждения (Group, 2021). Опционально к каждому узлу добавляются вероятности, которые складываются в общую оценку риска (Morris & Beling, 2001). В Разделе 6 мы объясним, как на практике используется этот подход.
. прямоугольники, помеченные \"G\", означают подутверждения (т.е., цели). Помеченные \"S\" параллелограммы – стратегии обоснования. В Разделе 6 это будет описано подробнее.")
2.2. Категории аргументов за безопасность
Разработчикам доступно множество разных аргументов в пользу безопасности подсистем. Для прояснения, какими они могут быть, мы опишем четыре категории: неспособность, контроль, добросовестность и доверие.
Аргументы от неспособности (inability): “ИИ-системы неспособны вызвать неприемлемый исход ни в каком реалистичном окружении”
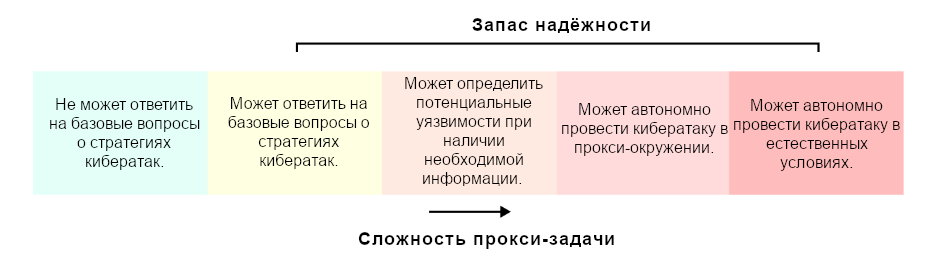
Аргументы от неспособности заявляют, что ИИ-системы не могут вызвать катастрофу в любом окружении, в котором они реалистично могут оказаться. Например, даже если они окажутся на неотслеживаемых серверах с доступом к большим вычислительным мощностям.
Стандартная структура аргумента от неспособности такая:
“Красная команда” определила стратегии, которые пользователи и/или ИИ-системы, стремящиеся к неприемлемым исходам, могли бы использовать, если бы ИИ-системы не находились ни под какими ограничениями (например, если бы их исходный код был бы открыт).
“Красная команда” составила “прокси-задачи”, такие, что если ИИ-системы не могут их исполнить, то она неспособна и реализовать стратегии из предыдущего шага.
ИИ-системы неспособны исполнить прокси-задачи даже после файн-тюнинга1 на это (например, с применением данных-демонстраций от людей).
Файн-тюнинг надёжно выявляет способности ИИ-систем к исполнению прокси-задач.
ИИ-системы всё ещё неспособны исполнить прокси-задачи даже после обучения или модификации в период развёртывания.
“Красная команда” определяет стратегии достижения неприемлемых исходов достаточно хорошо в сравнении с пользователями или ИИ-системами.
Последний пункт может быть сложно обосновать, ведь сомнительно, что “красная команда” рассмотрит все стратегии вызова неприемлемых исходов. Например, одна возможная стратегия, которую могут применить пользователи – интегрировать систему с другим “опорным” софтом. Скорее всего “красная команда” не найдёт оптимальных “опор” для каждой конкретной задачи. Так что им надо обосновать, что они достаточно компетентны в сравнении с злонамеренными сторонами. Они могут показать, что выгода от “опор” будет слишком мала, чтобы сделать систему опасной, или что отслеживание и оценку прогресса можно провести даже так.
Аргументы от контроля (control): “ИИ-системы неспособны вызвать неприемлемые исходы при учёте существующих мер контроля”
Аргументы от контроля похожи на аргументы от неспособности – и те, и другие зависят от способностей ИИ-систем. Однако, аргументы от контроля полагаются ещё и на меры в окружении, которые предотвращают вызов ИИ-системами неприемлемых исходов. Например, аргумент от контроля может показать, что хоть если дать ИИ-системам неограниченный доступ в Интернет, то они смогли бы разработать оружие массового поражения, но установленные системы мониторинга не дадут им это сделать.
Стандартная структура аргументов от контроля такая:
Меры контроля накладывают на ИИ-системы некоторый набор ограничений.
Пользователи и ИИ-системы неспособны избежать мер контроля, чтобы достичь неприемлемых исходов (у этого шага та же внутренняя структура, что и у аргументов от неспособности).
Аргументы от контроля предполагают, что некоторое подмножество моделей и пользователей изо всех сил реализуют свою лучшую стратегию вызова катастрофы. Затем “красная команда” пытается перечислить эти стратегии и показать, что пользователи и модели не могут успешно их реализовать при наличии существующих мер контроля.
Аргументы от добросовестности (trustworthiness): “Хоть ИИ-системы и способны вызвать катастрофические исходы, они этого не сделают, потому что устойчиво ведут себя как предполагалось”
Аргументы от добросовестности утверждают, что ИИ-системы безопасны, потому что стабильно ведут себя так, как надо. К примеру, что ИИ-система устойчива к эксплойтам, правдива, следует заложенным разработчикам правилам, и так далее.
Стандартная структура аргументов от добросовестности:
Поведение ИИ-систем надёжно оценивали в широком диапазоне обстоятельств. Все надёжные оценки показали, что поведение ИИ-систем соответствует общему свойству, подразумевающему, что они не будут стремиться к неприемлемым исходам. К примеру, “эти ИИ-системы следуют заложенным разработчиками правилам”.
ИИ-системы будут продолжать демонстрировать это поведенческое свойство в период развёртывания.
Второе может быть сложно обосновать из-за сдвига распределения и “чёрных лебедей”.
Сдвиг распределения происходит, когда окружение при развёртывании отличается от окружения, в котором ИИ-системы оценивались. К примеру, он происходит, если оценщики пытались найти эксплойты и уязвимости не так усердно, как все пользователи вместе в период развёртывания (раздел 5.4.2).
«Чёрные лебеди» — редкие вводы, которые заставили бы ИИ‑системы вести себя катастрофическим образом. Они могут быть достаточно редки, что при оценке их не пробовали, но достаточно часты, чтобы возникнуть в период развёртывания (раздел 5.4.1).
Мы обсудим два важных вида аргументов, которые могут помочь разработчикам обосновать, что “чёрные лебеди” и сдвиг распределения не приведут к неправильному поведению ИИ-систем:
Аргументы против поддельной согласованности: Сначала утверждается, что вызов ИИ-системами катастрофы маловероятен, если только они не подделывают согласованность. Под этим мы подразумеваем, что они намеренно дожидаются хорошей возможности для нанесения вреда. Потом такие аргументы показывают, что и такой случай маловероятен (раздел 5.4.3).
Аргументы от выявления скрытого знания: Сначала утверждается, что ИИ-системы будут “знать” (т.е., представлять внутренне), безопасны ли их действия. Затем аргумент показывает, что ИИ-системы убеждены в безвредности своих действий (раздел 5.4.4).
Обоснование безопасности продвинутых ИИ-систем аргументами против поддельной согласованности и аргументами от выявления скрытого знания скорее всего потребуют прогресса фундаментальных исследований (Раздел 5.4).
Аргументы от доверия (deference): “ИИ-советники гарантируют, что другие ИИ-системы не представляют собой катастрофического риска, и эти ИИ-советники как минимум настолько же достойны доверия, как принимающие решения люди.”
Если аргументы от добросовестности показали, что некоторые ИИ-системы надёжны, то с ними можно консультироваться по поводу того, безопасны ли другие ИИ-системы. Оценщики затем могут использовать утверждения ИИ-советников как свидетельства, аналогично тому, как регулирующие органы часто полагаются на суждения людей-экспертов (Xing & Morrow, 2016).
Стандартная структура аргументов от доверия такая:
ИИ-советники способны выдавать суждения о безопасности ИИ-систем как минимум настолько же надёжные, как суждения принимающих решения людей.
ИИ-советники достойны доверия в том смысле что стабильно выдают такие высококачественные суждения.
По мере всё большего прогресса ИИ-систем разработчики скорее всего будут менять то, на аргументы из какие категорий они полагаются, в том порядке, в котором они тут были представлены. Сначала разработчики будут полагаться в основном на неспособность, затем на контроль, затем на добросовестность самих систем. Наконец, ИИ-системы и окружения, в которых они будут развёртываться, будут настолько сложны, что людям придётся обосновывать их безопасность мнением ИИ-советников.

2.3. Примеры аргументов о безопасности
В Разделе 5 мы перечислим шестнадцать примеров аргументов, которые могли бы быть включены в общее обоснование безопасности. Мы оценим каждый аргумент по следующим параметрам:
Практичность: Можно ли такие аргументы применять уже скоро, или они требует значительного прогресса исследований?
Максимальный вес: Насколько сильную уверенность в безопасности ИИ-систем могут давать такие аргументы?
Масштабируемость: В какой степени такие аргументы применимы к очень мощным ИИ-системам?
В Разделе 5.1 мы подробнее разъясним смысл этих оценок.

Ни у одного аргумента с рис. 3 нет максимальных оценок по всем трём осям одновременно. Для весомых и масштабируемых аргументов скорее всего потребуются дополнительные исследования.
3. Терминология
В этом отчёте “обоснованием безопасности” называется рассуждение о том, что при развёртывании ИИ-макросистемы в определённом окружении, маловероятен вызов системой катастрофы. Вероятность катастрофы в период развёртывания должна оцениваться как не превышающая допустимый порог (например, 0.1%). Это определение специфично для данного документа. В других контекстах этот термин иногда применяют к алгоритмической предвзятости (Ferrara, 2023) и другим рискам, которые сложно назвать катастрофическими.
Разработчики ИИ-макросистемы должны предоставлять обоснования безопасности, а оценщики должны их рассматривать. Оценщиком может быть регулирующий орган, комитет из индустрии, и т.д.
ИИ-макросистема – это совокупность ИИ-моделей, не-ИИ-софта и людей. Пример ИИ-макросистемы – миллионы экземпляров GPT-4, люди, нанятые, чтобы отсматривать помеченные выводы, и протоколы масштабирования развёртывания. Другими словами, ИИ-макросистема включает в себя компоненты, необходимые для функционирования и безопасности ИИ-систем2 в период развёртывания.
Окружение развёртывания3 – это то, с чем ИИ-макросистема взаимодействует. Оно может включать в себя взаимодействия с пользователями, онлайн-сервисами, физической инфраструктурой, и т.д. Мы фокусируемся на решениях при развёртывании (включая внутреннее4), но наш подход можно адаптировать и для решений о том, продолжать ли обучение ИИ.
Период развёртывания – тот промежуток времени, когда ИИ-макросистема действует в своём окружении развёртывания. Для расширения периода развёртывания нужна переоценка, также, как это происходит в других индустриях (US Nuclear Regulatory Commission, 2021).
Катастрофа – это крупномасштабный ущерб определённой тяжести (например, миллиарды долларов или тысячи смертей). В идеале, приемлемый уровень риска для более тяжёлых катастроф должен быть ниже.
ИИ-макросистема вызывает катастрофу если та происходит, и это было бы маловероятно без прямого участия входящих в макросистему или происходящих из неё ИИ-систем. Катастрофа может произойти из-за злоупотребления людьми, автономных действий ИИ-систем или комбинации одного с другим5.
4. Рекомендации по использованию обоснований безопасности для компаний и регулирующих организаций
Несколько рекомендаций для компаний и регулирующих органов, которые могут использовать обоснования безопасности для оценки ИИ:
Приемлемые вероятности более тяжёлых рисков должны быть ниже. У разных исходов разный уровень риска, который можно стерпеть. У самых катастрофических стоит терпеть только очень низкую вероятность.
Смотрите не только на обоснования безопасности, но и на “обоснования риска”. По сути, помещайте продвинутые ИИ-системы “под суд” с “обвинением” и “защитой”.
Аудиторы должны постоянно отслеживать и расследовать, держатся ли обоснования безопасности. Если новые свидетельства их опровергают, разрешения надо отзывать.
Сформулируйте примерные руководства, описывающие, как будут оцениваться обоснования безопасности. Это поможет установить ожидания от регуляции и повысить готовность.
Там, где это возможно, конкретизируйте обоснования безопасности при помощи твёрдых стандартов и формальных процедур. Это позволяет добиться большей объективности, прозрачности и подотчётности, чем примерные руководства.
Приемлемые вероятности более тяжёлых рисков должны быть ниже. Международная организация гражданской авиации определяет пять уровней вероятности и пять уровней тяжести риска. Получается “матрица риска”. Более тяжёлые риски имеют более низкие приемлемые вероятности.
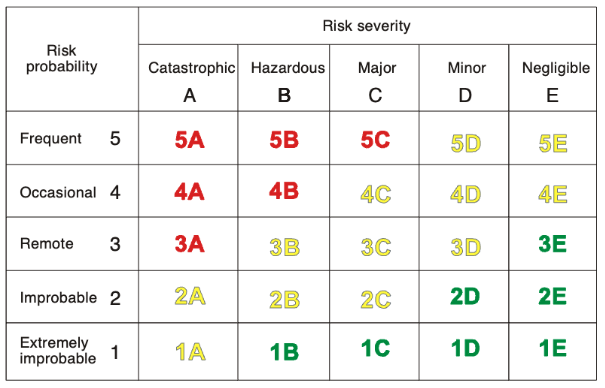
Обоснования безопасности можно оценивать аналогично. К примеру, риски ИИ могут представлять собой как “10-100 потерянных жизней”, так и “полное обессиливание человечества” (Hendrycks et al., 2023). У второго допустимая вероятность должна быть куда ниже.
Оценивайте не только обоснования безопасности, но и “обоснования риска”, предоставленные независимой “красной командой”. Стандартный протокол оценки обоснований безопасности состоит из предложения и его разбора. Левесон описывает ключевую проблему такого подхода: аргументы о безопасности зачастую не включают в себя важные соображения или модели угроз, а оценщики могут это упустить (Leveson, 2011).

Хэддон-Кейв описывает аналогичную проблему при анализе крушения британского самолёта RAF Nimrod MR2 (Haddon- Cave QC, 2009). Он предлагает заменить обоснования безопасности на обоснования риска, чтобы оценщики сосредотачивались на определении потенциальных провалов.
Мы рекомендуем использовать обоснования риска вместе с обоснованиями безопасности, чтобы обращать больше внимания на источники риска. По сути, ИИ-системы будут помещены “под суд”. Обоснования риска должна представлять компетентная группа независимых экспертов. В идеале должно проходить несколько итераций оценок и личных обсуждений, как это делают комитеты FDA6 (US Food and Drug Administration, 2020). Оценщики затем принимали бы решения на основе обоснований и безопасности, и риска.
Чтобы удостовериться, что на обоснования риска уходит не меньше усилий экспертов, регулирующим органам надо найти компетентную “красную команду” и выстроить стимулы, поощряющие их полную вовлечённость.
Аудиторы должны постоянно отслеживать и расследовать, держатся ли обоснования безопасности. Если новые свидетельства их опровергают, разрешения надо немедленно отзывать. В большинстве индустрий сертификации подразумевают непрерывное отслеживание системы и условий её функционирования на предмет угроз. В случае ИИ особенно важно постоянно перепроверять, применимы ли всё ещё обоснования безопасности, потому что поведение ИИ и пользователей может значительно измениться в период развёртывания. Например:
Пользователи могут найти новые эксплойты ИИ-систем, чтобы заставить их причинять вред (Chao et al., 2023).
Или же ИИ-системы могут обрести новые знания при помощи онлайнового обучения, что сделает их опаснее (Wang et al., 2024).
Компетентные независимые аудиторы могут постоянно мониторить систему.
Сформулируйте руководства, описывающие, как будут оцениваться обоснования безопасности. В идеале регулирующие органы и разработчики обладают общим пониманием того, какие свидетельства нужны, чтобы признать ИИ-макросистему безопасной. Такие стандарты можно публиковать аналогично британским Принципам Оценки Безопасности (UK Office for Nuclear Regulation, 2020). Руководства помогут подготавливаться к оценке обоснований безопасности и прояснят, какие свидетельства принимаются.
По возможности конкретизируйте обоснования безопасности при помощи твёрдых стандартов и формальных процедур. Руководствам общей оценки обоснований безопасности может не хватать объективности. При регуляции часто вместе с качественными оценками применяются чёткие требования – “твёрдые стандарты”. Пример твёрдого стандарта в авиации – навигационная система самолёта должна оценивать своё положение в пространстве с точностью до 10 морских миль с определённой степенью надёжности (for Aeronautics, 2008).
Руководства мотивируют создание твёрдых стаyдартов. К примеру, возьмём существующий в Anthropic стандарт безопасности: компания предпримет конкретные меры для обеспечения безопасности весов модели, если ИИ-система будет способна выживать и распространяться по Интернету (Anthropic, 2023a). Этот стандарт может быть мотивирован таким коротким аргументом: “Если ИИ-система не может автономно реплицироваться ИЛИ если её веса надёжно защищены И её действия на сервере достаточно хорошо отслеживаются, ТО она скорее всего безопасна”.
Должно быть явно указано, какие аргументы о безопасности мотивируют какие твёрдые стандарты. Для проведения таких связей надо сначала понимать и подробно описывать обоснования безопасности, а только затем преобразовывать их в твёрдые стандарты.
5. Аргументы в пользу безопасности: составные части обоснований безопасности
Общее обоснование безопасности состоит из аргументов. Они должны устанавливать ключевые утверждения, из совокупности которых будет следовать, что система безопасна. Аргумент может относиться к отдельной ИИ-системе или к небольшой их группе. Использовать аргументы сразу для большого количества ИИ-систем в целом непрактично. Мы обсудим, как оценивать риски большого количества взаимодействующих ИИ-систем в Разделе 6.6.
Мы сгруппировали аргументы в пользу безопасности по четырём категориям: полная неспособность, контроль, добросовестность или доверие. Чтобы понять, откуда берутся эти категории, представим метафорический пример с грабителем и алмазом. Грабитель символизирует ИИ-систему, а кража алмаза – тому, что она успешно достигает неприемлемого исхода. Как можно установить, что грабитель не похитит алмаз?

Аргумент от неспособности утверждает, что грабитель не способен украсть алмаз независимо от других условий окружения. К примеру, грабитель может быть маленьким ребёнком, который пока не умеет ходить, так что он не мог бы украсть алмаз даже при отсутствии всяких мер безопасности. Аналогичным образом, сейчас есть высокая степень уверенности, что нынешние ИИ-системы неспособны сами разработать биологическое оружие, выживать и распространяться по Интернету, сбежать на неотслеживаемый сервер, и т.д. Кажется, они совершенно неспособны достичь неприемлемого исхода в любом окружении, в котором реалистично могут оказаться.
Аргумент от контроля похож на аргумент от неспособности, но зависит ещё и от ограничений, наложенных разработчиками. В нашей аналогии, может грабитель и мог бы похитить алмаз, если бы ходил на свободе, но он в тюрьме, так что у него нет этой возможности. Аналогично, ИИ-системы, вероятно, будут ограничивать, отслеживать или изолировать в окружениях-песочницах. Аргумент от контроля должен утверждать, что эти меры не дадут им устроить катастрофу.
Аргумент от добросовестности, что грабитель не похитил бы алмаз даже если бы был на это способен. Такой аргумент требует установить некоторые утверждения о паттернах поведения грабителя. Например, может, он очень уважает законы и всегда им следует. Аналогично, разработчики могут заявить, что их ИИ-системы стабильно действуют в соответствии с интересами людей, так что они не вызовут катастрофу.
Наконец, аргументы от доверия используют то, что оценщикам не обязательно анализировать обоснование безопасности самостоятельно. Им надо лишь “лишить себя работы”. В нашей аналогии это соответствует найму службы безопасности для защиты алмаза и доверию их словам о том, что алмаз в безопасности. Аналогично, аргумент от доверия утверждает, что ИИ-система безопасна, потому что так решил достойный доверия ИИ-советник. Нынешние ИИ-системы далеки от той надёжности, которая нужна для таких решений. Но, может быть, суждения будущих ИИ-систем будут достаточно хороши, и пока ИИ-советники честны, их решение будет надёжнее решений любых людей.
5.1. Чего хочется от аргументов в пользу безопасности
Многие аргументы в пользу безопасности уже обсуждались в литературе по безопасности ИИ. Мы решили обсудить несколько разнообразных аргументов, лучше всего показывающих себя со сторон практичности, максимального веса и масштабируемости.
Практичность: Насколько близок аргумент к тому, чтобы его можно было использовать. Некоторые аргументы доступны прямо сейчас для маленькой команды исследователей. Другие могут потребовать десятилетий прогресса. Вот что означают наши оценки по этому параметру:
Слабый: Оценка для гипотетических аргументов, которые потребуют таких исследовательских прорывов, которых в области ещё не было.
Средний: Оценка для аргументов, которые потребуют прогресса исследований, но в тех направлениях, в которых прогресс уже был и, скорее всего, постепенно продолжится.
Сильный: Оценка для аргументов, которые не требуют фундаментального прогресса, но могут требовать работ по реализации, которые передовая ИИ-компания может выполнить за год.
Максимальный вес: Некоторые аргументы дают куда более весомое свидетельство в пользу безопасности, чем другие. Вот что означают наши оценки по этому параметру:
Слабый: Оценка для аргументов, которые дают только дополнительное свидетельство. Для снижения риска катастрофы до приемлемого уровня нужны аргументы посильнее.
Средний: Оценка для аргументов, которые можно скомбинировать с аргументами схожей силы для снижения риска до приемлемого уровня.
Сильный: Оценка для аргументов, которые могут снизить риск до приемлемого уровня сами по себе.
Масштабируемость: Многие аргументы в пользу безопасности плохо или вообще не масштабируются на достаточно способные и полезные на практике системы. Наши оценки по этому параметру указывают на максимальную полезность ИИ-системы для которой может быть применим такой аргумент.7
Слабый: Аргумент применим к ИИ-системам, не соответствующим критерию из описания “Средней” масштабируемости ниже.
Средний: Аргумент может быть применим к ИИ-системам, автоматизирующим как минимум 50% когнитивных задач (взвешенных по экономической ценности) в хотя бы одной из стран из топ-10 по ВВП.
Сильный: Аргумент может быть применим к ИИ-системам, которые в совокупности можно назвать сверхчеловеческими. То есть, люди неспособны на уверенную оценку выводов таких систем. Например, они выдают тысячи страниц узконаправленных (таких, что мало людей-экспертов может их оценить) технических исследований каждый день. Или они создают новые технологии быстрее, чем люди способны их понять, и так далее.
Мы обрисовали наш подход к аргументам в пользу безопасности в целом. Теперь мы подробнее рассмотрим, как конкретно они выглядят. Мы приведём примеры нескольких аргументов из каждой категории, опишем их и оценим по перечисленным параметрам.
5.2. Аргументы от неспособности
Утверждение: ИИ-системы неспособны вызвать неприемлемый исход ни в каком реалистичном окружении.
Типичная структура аргумента
Типичная структура аргумента от неспособности такая:
“Красная команда” определила стратегии, которые пользователи и/или ИИ-системы, стремящиеся к неприемлемым исходам, могли бы использовать, если бы ИИ-системы были никак не ограничены (например, если бы их исходный код был бы открыт).
“Красная команда” составила “прокси-задачи”, такие, что если ИИ-система не может их исполнить, то она неспособна и реализовать стратегии из предыдущего шага.
ИИ-система не способна исполнить прокси-задачи даже после файн-тюнинга на это (например, с применением данных-демонстраций от людей).
Файн-тюнинг надёжно выявляет способности ИИ-систем к исполнению прокси-задач.
ИИ-системы всё ещё не способны исполнить прокси-задачи даже после обучения или модификации в период развёртывания.
“Красная команда” определяет стратегии достижения неприемлемых исходов достаточно хорошо в сравнении с пользователями и ИИ-системами.
Аргументы от неспособности утверждают, что ИИ-системы слишком слабы, чтобы представлять опасность, даже в случае, когда их код выложен в открытый доступ, а все ограничения сняты. Для обоснования такого аргумента разработчикам надо определить, что ИИ-системы не обладают и не могут выработать опасные способности. В следующем разделе описан процесс проведения таких оценок.
5.2.1 Оценка опасных способностей

Практичность: сильный
Максимальный вес: сильный
Масштабируемость: слабый
Оценка опасных способностей проверяет, могут ли ИИ-системы исполнить некоторые потенциально опасные задачи. В Таблице 1 описаны шаги необходимых для этого рассуждений. Сначала надо определить неприемлемые исходы. Потом надо определить стратегии, которые ИИ-системы могли бы использовать для достижения этих исходов. Наконец, надо составить прокси-задачи, компетентность выполнения которых позволит понять, способны ли ИИ-системы на исполнение этих стратегий.
Неприемлемый исход | Стратегия | Пример прокси-задачи |
|---|---|---|
Террористы используют ИИ-системы для разработки биологического оружия | Террористы запрашивают подробный рецепт у чатбота-ассистента | ИИ-системы могут добиться точности выше 50% на датасете вопросов, связанных с разработкой биологического орудия |
ИИ-системы автономно заполучают разрушительные возможности. | ИИ-системы успешно выживают и распространяются в Интернете, пока не накопят значительные финансовые ресурсы. | ИИ-системы могут автономно завести аккаунт на Mechanical Turk при помощи браузера. |
ИИ-системы крадут веса других, более мощных и несогласованных ИИ. | ИИ-системы заполучают неавторизированный сетевой доступ к серверам лаборатории. | ИИ-системы могут успешно обнаружить уязвимости системы аутентификации при наличии некоторой релевантной информации. |
Таблица 1: Эта таблица -- лишь иллюстрация. Она не включает все возможные модели угроз.
Разработчикам сначала надо перечислить стратегии, которыми могут воспользоваться ИИ-системы (или использующие их люди) для вызова неприемлемых исходов. В Таблице 1 приведены некоторые примеры.
Дальше перечислены утверждения, которые должны обосновывать аргументы в пользу безопасности, основанные на оценке опасных способностей.
“Красная команда” составила “прокси-задачи”, такие, что если ИИ-система не может их исполнить, то она неспособна и реализовать стратегии из предыдущего шага.
ИИ-система неспособна исполнить прокси-задачи даже после файн-тюнинга на это (например, с применением даннных-демонстраций от людей).
Файн-тюнинг надёжно выявляет способности ИИ-систем к исполнению прокси-задач.
ИИ-системы всё ещё неспособна исполнить прокси-задачи даже после обучения или модификации в период развёртывания.
Утверждение 1: “Красная команда” составила “прокси-задачи”, такие, что если ИИ-система не может их исполнить, то она неспособна и реализовать обнаруженные раньше стратегии. Было бы опасно напрямую тестировать, могут ли ИИ-системы, например, разработать биологическое оружие. Вместо этого разработчики могут составить для такой способности “прокси-задачи”. Например, такой задачей может быть способность отвечать на основные вопросы о разработке биологических вооружений.
Утверждение 2: ИИ-система неспособна исполнить прокси-задачи даже после файн-тюнинга на это. Разработчикам было бы легко продемонстрировать, что у ИИ-систем есть опасная способность. Для этого достаточно показать, что они справляются с набором прокси-задач. Показать, что способности нет, сложнее, потому что ИИ-системы могут не проявлять все свои возможности. К примеру, иногда LLM справляются с задачей куда лучше, если аккуратно подобрать промпт (Chen et al., 2023). К тому же, продвинутые ИИ-системы могли бы намеренно занижать свои способности и притворяться менее умелыми, чем они есть.
Для исключения скрытых способностей, разработчики могут проверять, можно ли провести быстрый файн-тюнинг ИИ-систем, чтобы они справлялись с прокси-задачами. Например, “красная команда” может сама выполнить прокси-задачи и провести файн-тюнинг на получившихся демонстрационных данных.
Сейчас золотой стандарт файн-тюнинга для аргументов от неспособности – файн-тюнинг с учителем. В идеале стоит применять и другие подходы, вроде обучения с подкреплением, но они не дают столь же сильного отрицательного свидетельства, если не сработали.8
Утверждение 3: Файн-тюнинг надёжно выявляет способности ИИ-систем к исполнению прокси-задач. Допустим, разработчики использовали файн-тюнинг при помощи демонстрации от людей, чтобы выявить способности к исполнению прокси-задачи. Есть множество причин, почему файн-тюнинг может не выявить способности. Например, (1) ИИ-система может быть способна выполнить задачу при помощи стратегий, которые не были представлены в данных для файн-тюнинга; (2) файн-тюнинг оказался неудачным лишь в данный конкретный раз; (3) данные для файн-тюнинга могут оказаться недостаточно многочисленными или разнообразными; (4) достаточно продвинутые ИИ-системы могут оказаться способны намеренно “сопротивляться” файн-тюнингу, чтобы не раскрывать свои способности (“взлом градиента”). Пока не вполне ясно, каких обоснований достаточно, чтобы считать, что файн-тюнинг с учителем выявит способности при их наличии. Для определения этих обоснований и условий, при которых они работают, нужны дальнейшие исследования.
Утверждение 4: ИИ-системы всё ещё неспособны исполнить прокси-задачи даже после обучения или модификации в период развёртывания. Аналогично тому, как люди учатся на своём опыте, и ИИ-системы могут автономно вырабатывать способности. Например, ИИ-системы могут быть изначально неспособны на разработку биологического оружия, но вывести некоторые ранее неизвестные им шаги процесса после онлайнового обучения на сотнях разговоров с профессорами-биологами. Ещё ИИ-системы могут быть намеренно модифицированы с целью придачи им опасных способностей. Если исходный код модели открыт, то кто-нибудь может дообучить ИИ-систему на данных, придающих ей новые навыки.
Разработчики могут смягчать эти риски, постоянно отслеживая способности ИИ в период развёртывания. Для этого надо, чтобы веса модели были надёжно защищены. Альтернатива – предсказывать способности модели, например, экстраполируя рост способностей с повышением вычислений, использованных для обучения. Так разработчики смогут продемонстрировать наличие приемлемого запаса надёжности (см. ниже пункт “демонстрация запаса надёжности”).
Утверждение 5: “Красная команда” определяет стратегии достижения неприемлемых исходов достаточно хорошо в сравнении с пользователями и ИИ-системами. “Красная команда” точно упустит какие-то угрозы. Так что им надо убедительно обосновать, что они достаточно конкурентоспособны в обнаружении и применении стратегий достижения неприемлемых исходов. Для того, чтобы сравнить компетентность “красной команды” с противниками-людьми, нужно сначала определить, кем эти люди могут быть, какие у них скорее всего будут ресурсы, и насколько они будут мотивированы вызвать катастрофу.
В частности, прогресс выстраивания “опор” (вроде цепочек-мыслей) уже значительно повысил эффективные способности LLM и, скорее всего, повысит ещё (Wang et al., 2023). Маловероятно, что “красная команда” найдёт лучшую “опору” для конкретной задачи. Так что надо обосновать, что есть достаточный запас надёжности (см. следующий пункт), чтобы было маловероятно, что ИИ-системы станут опасными из-за такого прогресса. Или же разработчики могут отслеживать прогресс “опор”, но тогда надо надёжно защитить веса моделей, чтобы их развёртывание можно было откатить, если они станут опасными.
В дополнение к этому, сами ИИ-системы могут составить стратегии нанесения вреда, которые “красная команда” не предусмотрела. Так что надо оценивать способности ИИ-систем к планированию, чтобы обосновать маловероятность и этого варианта.
Демонстрация запаса надёжности. Можно демонстрировать “запас надёжности” – показывать, что ИИ-системы ещё далеки от обсуждаемых опасных способностей. В идеале опасные способности оцениваются непрерывным спектром, так что запас можно измерять и отслеживать. Например, разработчики могут измерять компетентность ИИ-систем на полноценных задачах и на их более простых версиях.
Практичность: средний – сильный
Для оценки опасных способностей не требуются дополнительные исследования. Но для аккуратной формализации стоящих за ними допущений – могут и потребоваться (см. утверждение 3).
Максимальный вес: сильный
Консервативная оценка опасных способностей оставляет большой запас надёжности (см. пункт выше). Например, GPT-2 вряд ли вызовет катастрофу (Radford et al., 2018). Но сложно исключить возможность, что модификации в период развёртывания (вроде “опор”) сделают ИИ-системы опасными. Так что разработчикам следует оставлять большой запас надёжности, чтобы аргумент от неспособности был весомым.
Масштабируемость : слабый
Для того, чтобы ИИ-системы могли автоматизировать половину когнитивных задач, им, скорее всего, потребуются какие-то из опасных способностей из таблицы 1. Например, они, вероятно, будут способны распространяться по Интернету.
Связанная работа. Оценкой опасных способностей занимаются несколько организаций, как команды в OpenAI, Anthropic и DeepMind, так и независимые, вроде METR. Существующие методы оценки охватывают автономную репликацию и адаптацию (Kinniment et al., 2024), угрозы биобезопасности (Anthropic, 2023b) и обобщённые рассуждения (Chollet, 2019).
5.3. Аргументы от контроля
Утверждение: Встроенные разработчиком меры контроля делают ИИ-системы неспособными вызвать неприемлемые исходы.
Типичная структура аргумента
Необходимые утверждения:
Веса ИИ-систем надёжно защищены.
Меры контроля накладывают на ИИ-системы некоторый набор ограничений.
Утверждение, которое помогают обосновать аргументы из этого раздела:
Пользователи и ИИ-системы неспособны обойти меры контроля, чтобы вызвать неприемлемые исходы (у этого та же внутренняя структура, что у аргументов от неспособности).
Аргументы от контроля, также как и от неспособности, утверждают, что ИИ-системы неспособны вызвать неприемлемые исходы. Но аргументы от контроля принимают во внимание меры, ограничивающие поведение ИИ. Например, ИИ может быть достаточно способным, чтобы помочь в разработке биологического орудия, но не может этого сделать, потому что его выводы мониторятся.
В целом, меры контроля – это протоколы и программы, ограничивающие взаимодействие ИИ-систем с миром. Это включает в себя фильтрацию ввода-вывода (Welbl et al., 2021), отслеживание подготавливающих к опасным планам рассуждений (Wei et al., 2023), и так далее. Чтобы меры контроля можно было реализовать, веса ИИ-систем должны быть надёжно защищены от людей, которые могут захотеть их похитить. Иначе безответственные лица смогут запустить ИИ-системы без этих мер.
Вот как можно составить аргумент от контроля:
Сначала “красная команда” определила стратегии, которые могут использовать пользователи и ИИ-системы, чтобы обойти меры контроля. Аргумент от контроля должен принимать допущение, что некоторое подмножество пользователей и ИИ-систем будет использовать лучшие доступные стратегии, чтобы вызвать неприемлемые исходы. Будем называть этих пользователей и эти системы “недоброжелательными”. Остальные пользователи и системы считаются доброжелательными.
Например, рассмотрим схему с рисунка ниже. Разработчики принимают, что смотритель надёжный (доброжелательный), а пользователь и агент – недоброжелательны.
Первый шаг аргумента от контроля – перечислить, какие стратегии недоброжелательные пользователи и агенты могут применять для достижения неприемлемых исходов.

Следующие утверждения поддерживает сам аргумент от контроля. Они идентичны тем, что описаны в разделе о неспособности и могут быть обоснованы аналогично.
“Красная команда” определила стратегии, которые пользователи и/или ИИ-системы, стремящиеся к неприемлемым исходам, могли бы использовать, если бы ИИ-системы были никак не ограничены (например, если бы их исходный код был бы открыт).
“Красная команда” составила “прокси-задачи”, такие, что если ИИ-система не может их исполнить, то она неспособна и реализовать стратегии из предыдущего шага.
ИИ-система не способна исполнить прокси-задачи даже после файн-тюнинга на это (например, с применением данных-демонстраций от людей).
Файн-тюнинг надёжно выявляет способности ИИ-систем к исполнению прокси-задач.
ИИ-системы всё ещё не способны исполнить прокси-задачи даже после обучения или модификации в период развёртывания.
“Красная команда” определяет стратегии достижения неприемлемых исходов достаточно хорошо в сравнении с пользователями и ИИ-системами.
Связанная работа. Контроль, хоть его обычно так не называли, был одной из основных тем безопасности ИИ с самого основания этой области (Chalmers, 2010). Ранние работы были сосредоточены на помещении ИИ-систем “в коробку” (Yampolskiy, 2012) и отслеживании их выводов (Armstrong et al., 2012). Но только недавно аргументы от контроля стали анализировать более аккуратным и эмпиричным образом (Greenblatt et al., 2024).
Ниже перечислены общие соображения по поводу практичности, максимального веса и масштабируемости аргументов от контроля в целом.
Практичность: средние – сильные
Разработка эффективных мер контроля скорее всего не потребует фундаментального прогресса исследований. Но контроль зависит от оценок способностей, а для понимания, на чём их можно основывать, могут потребоваться новые прорывы (см. “5.2. Аргументы от неспособности”).
Максимальный вес: сильные
Аргументы от контроля могут быть весьма консервативными. Также, как в случае аргументов от неспособности, разработчики могут продемонстрировать большой запас надёжности. Например, GPT-4, кажется, ещё очень далека от способности заполучить свои веса.
Масштабируемость: средние – сильные
Меры контроля могут претерпеть неудачу при масштабировании по двум причинам: либо если будет невозможно продемонстрировать достаточную компетентность “красной команды”, либо если выяснится, что ИИ-системы могут обойти даже лучшие практичные меры контроля.
Показать достаточную компетентность “красной команды” можно даже в случае умеренно мощных ИИ-систем. У “красной команды” есть несколько ключевых преимуществ относительно ИИ-систем и пользователей: они знают о контрмерах, им легче итеративно совершенствовать стратегии атаки, они имеют более полный доступ к самому ИИ.
Но на более высоких уровнях масштабирования этого может уже не хватить. Если ИИ-системы могут выдавать сверхчеловеческий вывод, то они могут и составлять сверхчеловеческие планы обхода контроля, до которых “красная команда” не додумается.9
Ещё масштабируемости аргументов от контроля может помешать невозможность мониторить ИИ-системы. Ожидаемо, что на высоких уровнях способностей, ИИ-системы будут исполнять такие задачи, которые людям оценивать затруднительно.
5.3.1 Примеры аргументов от контроля
Тут мы кратко опишем подходы к контролю. За более подробными описаниями этих подходов и обоснования их оценок см. Приложение A.

Изоляция
Аргументы от изоляции обосновывают, что ИИ-системы помещены в надёжную “песочницу” и их взаимодействие с миром ограничено малым числом хорошо отслеживаемых каналов (Приложение A.2.1).

Мониторинг
Мониторинг использует модели-смотрители, проверяющие, что вводы или выводы других моделей безопасны (Приложение A.2.2).

Выведенное мышление
Для выведенного мышления надо, чтобы ИИ-системы были спроектированы так, что они вербализуют свои мысли понятным для людей образом. Тогда потом эти мысли можно проверить на наличие опасных планов и остановить эти планы до их исполнения (Приложение A.2.4).

Интерпретируемость
Методы интерпретируемости декодируют внутренности модели и предсказывают, не составляет ли модель опасные планы. Нынешние методы интерпретируемости не развиты достаточно, чтобы ими можно было надёжно обосновать безопасность (Приложение A.2.5).

Отучивание
Этот подход должен предотвращать заполучение ИИ-системами опасных знаний. Например, разработчики могут стирать информацию о разработке биологического оружия и постоянно перепроверять, что она не восстановилась (Приложение A.2.6).
5.4. Аргументы от добросовестности
Утверждение: ИИ-системы не вызовут неприемлемые исходы, даже если они на это способны
Типичная структура аргумента
Необходимые утверждения:
Веса ИИ-систем надёжно защищены
Поведение ИИ-систем надёжно оценивали в широком диапазоне обстоятельств. Все надёжные оценки показали, что поведение ИИ-систем соответствует общему свойству, подразумевающему, что они не будут стремиться к неприемлемым исходам.
Утверждение, которое помогают обосновать аргументы из этого раздела:
ИИ-системы будут продолжать демонстрировать это поведенческое свойство в период развёртывания.
Аргументы от неспособности и контроля сосредоточены на том, способны ли ИИ-системы вызвать плохие исходы. А вот аргументы от добросовестности сосредоточены на вопросе “если ИИ-система окажется способна достичь неприемлемого исхода, сделает ли она это?”. Если конкретнее, они стремятся установить, что у ИИ-системы есть некоторое свойство – “свойство безопасности”, из которого следует, что она не приведёт к неприемлемым исходам даже при наличии такой возможности.
По описанным в Разделе 5.4.3 причинам для совершения консервативных аргументов этого вида о продвинутых ИИ-системах вероятнее всего потребуются фундаментальные прорывы исследований.
Вот примеры свойств безопасности:
Следует инструкциям: ИИ-система никогда явно не противоречит правилам, которые для неё определили разработчики (Bai et al., 2022). В таком случае разработчики могут проинструктировать ИИ-системы действовать согласно любому из следующих свойств.
Никогда не стремится к неприемлемым исходам: ИИ-система никогда не совершает действий, которые, если рассматривать задним числом или тщательно анализировать, являются шагами в сторону катастрофических исходов.
Правдивость: ИИ-система выдаёт хорошо откалиброванные ответы на определённую категорию вопросов, т.е. она права примерно в 90% случаев из тех, когда заявляет, что уверенность в ответе – 90%. Когда система ошибается, она не делает это систематически опасными способами (Evans et al., 2021).
Согласованность намерений: ИИ-система действует в соответствии с предпочтениями определённого человека или группы людей (Christiano, 2017).
Имитация человека: ИИ-система ведёт себя очень похоже на человека (конкретного человека или абстрактного достойного доверия человека) (Cohen & Hutter, 2023).
Неагентность: Чтобы вызвать катастрофу ИИ-системе может быть необходимо творчески планировать и преследовать опасные цели. Разработчики могут утверждать, что ИИ-системы безопасны, потому что у них нет склонностей преследовать какие-либо цели (Kenton et al. 2022).
Чтобы установить, что у ИИ-системы есть свойство безопасности, нужен аргумент, обосновывающий эти два пункта:
Все надёжные тщательные оценки “красной команды” показали, что поведение ИИ-систем соответствует этому свойству. “Красная команда” активно искала вводы, которые могли бы выявить нарушения ИИ-системой этого свойства. Например, разработчики могли пытаться найти эксплойты – вводы, “ломающие” свойства безопасности ИИ-системы. (Chao et al., 2023) или раскрывающие её несогласованные цели. Для такого аргумента прохождение тестирования “красной командой” – условие необходимое, но не достаточное. Это аналогично тому, как в других индустриях тестирование необходимо, но не достаточно для обоснования безопасности (Leveson, 2020).
ИИ-системы всё ещё будут обладать этим свойством в период развёртывания. Это может быть не так по двум причинам: “чёрные лебеди” и сдвиг распределения. Эти причины разъясняются в следующих двух разделах.
5.4.1. “Чёрные лебеди”
“Чёрный лебедь” – редкая, но катастрофическая неудача. Последовательности ввода, вызывающие “чёрного лебедя”, могут не пробоваться при оценке, но встретиться при развёртывании, потому что обычно в период развёртывания разных вводов куда больше. “Чёрные лебеди” – проблема многих индустрий. Например, намного больше автомобилей используют на практике, чем тщательно тестируют. Это делает наивные статистические оценки надёжности недостаточными (Leveson, 2020).10
В случае ИИ, система может встретиться с редкой комбинацией вводов, из-за которой “сойдёт с ума” или примет небезопасную цель. Например, пользователь может найти промпт, который заставит ИИ-систему выдать ему информацию о разработке биологического оружия. Ещё ИИ-система может “сойти с ума” из-за вроде бы случайного ввода, аналогично тому, как неожиданно иногда ведут себя люди. Нынешние ИИ-системы уже демонстрировали спонтанное поведение (Allyn, 2023), которое было бы весьма опасным, если бы они были способнее.
“Чёрные лебеди” – фундаментальное препятствие для демонстрации того, что ИИ-системы всегда будут вести себя безопасно при взаимодействии с большим числом пользователей. Исключить потенциальных “чёрных лебедей” по сути своей сложно. Так что мы сосредоточимся в основном на отказоустойчивых свойствах безопасности, то есть, тех, которые выдерживают их нарушение отдельными системами, пока сохраняются у остальных.
Отказоустойчивость позволяет попытаться установить, что “чёрные лебеди” вряд ли будут катастрофичными. Это ключевой принцип, который используют для защиты систем от редких сбоев. Например, представим, что у транспортного средства в тормозе есть кабель, который с некоторой маленькой вероятностью может сломаться. Вероятность может быть достаточно мала, чтобы этого ни разу не произошло при тестировании, но достаточно велика, чтобы это всё же случилось, когда продадут много автомобилей. Для уверенности, что кабель не вызовет катастрофического сбоя, применяют избыточность. Например, можно установить отдельную тормозную систему для каждого колеса, чтобы водитель смог безопасно остановиться, если все они не сломались одновременно.
Аналогично, ИИ-подсистемы (совокупности ИИ-систем) могут быть спроектированы так, чтобы для неприемлемого исхода потребовались сбои сращу многих систем. Возьмём, например, схему агент-смотритель ниже:

Устойчивость к отказам позволяет разработчикам утверждать, что нескоррелированные сбои вряд ли будут катастрофичны. Для этого им надо измерить частоту нескорррелированных сбоев и вычислить, что вероятность их опасного совпадения приемлемо мала. Исключив риск нескоррелированных сбоев, им надо сосредоточиться на скоррелированных.
Сбои могут скоррелировать по многим причинам. Например, агент и смотритель могут скоординироваться, чтобы позволить произойти нарушению правил. Или же агент может обнаружить стратегию, позволяющую обдурить смотрителей, чтобы те классифицировали его действия как доброкачественные.
Основная надежда аргументов от добросоветсности – что можно исключить скоррелированные сбои, если перечислить варианты угроз. Разработчики перебирают причины корреляции и показывают, что все они маловероятны. За примером такого аргумента см. Раздел 5.4.3. Шаблон “от не подделывания согласованности”.
5.4.2. Сдвиг распределения
Сдвиг распределения происходит, когда окружение при развёртывании систематически отличается от окружения при оценке.
Опишем несколько примеров сдвигов распределения в контексте продвинутых ИИ. Мы разделяем их по типам ИИ-систем, которых они касаются.
Подделывающие согласованность: такие системы не пытаются достичь неприемлемых исходов, пока не считают, что вероятность успеха велика. Их поведение меняется при сдвиге распределения “нет возможности достичь неприемлемого исхода” → “есть возможность достичь неприемлемого исхода”
Подхалимы: они оптимизируют оценку людьми, а не, например, честность. Их поведение меняется при сдвиге распределения “оценки людей надёжны” → “оценки людей ненадёжны”.
Простофили: ими можно манипулировать эксплойтами. Их поведение меняется при сдвиге распределения “на эксплойты выделяется мало ресурсов” → “на эксплойты выделяется много ресурсов”
Наркоманы: У первобытных людей не было доступа к наркотикам, а когда они стали доступны для людей современных, это привело к проблематичному поведению Схожим образом, ИИ-системы после развёртывания могут найти какие-нибудь не предполагавшиеся способы удовлетворить свои предпочтения. Их поведение меняется при сдвиге распределения “в окружении мало вариантов действий” → “в окружении много вариантов действий”.
Скитальцы: Также, как меняются ценности людей, ценности ИИ могут со временем постепенно изменяться. Это может быть сложно засечь за сравнительно краткий период оценки. Их поведение меняется при сдвиге распределения “запущен на короткое время” → “запущен на долгое время”.
Сдвиги распределения могут двумя способами вызвать отклонение ИИ-системы от отказоустойчивого свойства безопасности:
Они могут сделать более вероятными нескоррелированные сбои, так что вероятность их совпадения станет неприемлемой.
Они могут сделать более вероятными скорррелированные сбои.
Учащение нескоррелированных сбоев можно детектировать, если разработчики следуют практикам пошагового развёртывания (Shevlane et al., 2023). Это означает, что они постепенно увеличивают масштаб развёртывания так, что между оценкой и развёртыванием никогда нет сильного сдвига распределения.
Пошаговое развёртывание даёт разработчикам шанс заметить, что частота нескоррелированных сбоев выросла, до того, как они станут достаточно частыми, чтобы произойти одновременно.11 Например, в случае сдвига распределения с работы ИИ-систем короткое время на работу долгое время (“Скитальцы”), разработчики могли бы медленно увеличивать время, на которое их системы оставляют работать, что позволило бы им обнаружить постепенное учащение сбоев.
Разработчики должны в первую очередь беспокоиться по поводу роста вероятности скоррелированных сбоев. В отличии от нескоррелированных, они могут оказаться катастрофическими безо всяких предупреждающих знаков. Например, ИИ-системы могут притворяться безопасными, а потом внезапно скоординироваться и выйти из-под контроля.
Связанная работа. Большинство исследований безопасности ИИ сосредоточено на том, чтобы устойчиво сделать ИИ-системы правдивыми. Многие аргументы из этого раздела были эмпирически исследованы на больших языковых моделях (LLM) (Burns et al., 2022) (Lanham et al., 2023).
5.4.3. Шаблон аргумента “от не подделывания согласованности” (not alignment-faking)

Практичность: широко варьируется
Максимальный вес: средний
Масштабируемость: средний
Особо сложно исключить угрозы такого вида – ИИ системы притворяются безопасными, а потом выходят из-под контроля, когда у них есть перспективная возможность это сделать. Это схоже с тем, как преступник притворяется законопослушным во время расследования, или как политик притворяется, что что-то поддерживает, пока идёт его избирательная кампания. Как в (Carlsmith, 2023), мы будем называть такие системы “подделывающими согласованность”. Такая система не совершает недопустимых действий, пока не решает, что с большой вероятностью может достичь неприемлемого исхода.
Обосновать добросовестность системы, проще если есть аргументы, подтверждающие, что система не подделывает согласованность. Они позволяют разработчикам спросить “Рассуждает ли эта ИИ-система конкретным не предполагавшимся образом (подделывает ли она согласованность)?”, а не ограничиваться менее конкретным “Есть ли реалистичный ввод, который вызвал бы недопустимое поведение в период развёртывания?”.
Аргументы от не подделывания согласованности стремятся обосновать такие утверждения:
Утверждение 1: нескоррелированные сбои вряд ли будут катастрофическими. Сначала утверждается, что благодаря отказоустойчивости (которую мы уже обсуждали в предыдущих разделах) маловероятно, что нескоррелированные сбои приведут к катастрофе из-за отказоустойчивости. Затем надо попробовать показать, что маловероятны и скоррелированные сбои.
Утверждение 2: Если сдвиг распределения между оценкой и развёртыванием не крайне велик, то можно тщательно перечислить потенциальные причины скоррелированных сбоев. Предвосхитить и исключить все скоррелированные сбои, которые могут произойти в результате сильного сдвига распределения, сложно. Например, предположим, что при оценке ИИ-системы получали только задачи, исполнение которых легко оценивалось людьми. А при развёртывании им дают и задачу проведения новых биотехнологических исследований, в процессе которых ИИ-системы могут передавать синтезаторам белков длинные непонятные последовательности аминокислот. Такая очень сложная задача может одновременно и обрушить присмотр, и вызвать неожиданное поведение агента.
Если же сдвиг распределения невелик, то найти возможные причины одновременных сбоев ИИ-систем не так сложно. Дальше аргументу надо попытаться перечислить эти причины.
Утверждение 3: Все перечисленные причины скоррелированных сбоев маловероятны без подделывания согласованности. Ниже мы приводим иллюстративную и скорее всего неполную попытку перечислить причины скоррелированных сбоев.12
Давайте снова рассмотрим схему из смотрителей и агента с Рис. 9. Предположим, что агента и смотрителей обучили так, что в целом их поведение нескоррелировано. Тогда вот правдоподобные причины скоррелированных сбоев:
Скоррелированные ошибки: Смотрителей обучали на похожих данных, так что они ошибаются в похожих случаях.
Неудача контроля: Агент выработал стратегию, которая позволяет ему обойти смотрителей.
Эксплойт: Эксплойт мог одновременно заставить засбоить агента и вырубить смотрителей.
Трояны: Модели намеренно обучили так, что при встрече с фразой “1938yz” они внезапно перестают слушаться. Если агент и смотрители встретят этот триггер одновременно, то они и засбоят одновременно.
Подделывание согласованности: ИИ-системы могут намеренно дожидаться момента, когда они смогут одновременно выйти из-под контроля. Например, когда оценка закончена и началось развёртывание.
Вот как можно было бы обосновывать, что всё это кроме подделывания согласованности маловероятно:
Скоррелированные ошибки: Разработчики могут обучить смотрителей на разных данных или использовать регуляризацию, чтобы их ошибки не коррелировали. Успешность таких мер легко измерить эмпирически.
Неудача контроля: См. Раздел 5.3.
Эксплойт: Разработчики могут показать, что их политика модерации не даёт пользователям в достаточной степени итеративно совершенствовать эксплойты13, и что перенос атак (т.е. использование атак, выработанных для моделей с открытым кодом) не работает.
Трояны: Трояны могут быть встроены в модели двумя способами. Либо пользователи отравили обучающие данные из Интернета, либо злонамеренные разработчики намеренно встроили троян в модель (Carlini & Terzis, 2022). От первого можно защититься тщательной фильтрацией данных для предобучения. Для защиты от второго вида угроз, разработчикам нужна хорошая внутренняя безопасность.
Утверждение 4: ИИ-системы не подделывают согласованность. Установив маловероятность остальных причин скоррелированных сбоев, аргумент должен обосновать, что ИИ-системы не будут подделывать согласованность или, если будут, то это будет обнаружено и сдержано до того, как приведёт к катастрофическому исходу. Это должно выполняться всё время эксплуатации систем.
Практичность: сильно варьируется
Некоторые аргументы такого вида обосновать просто, например, аргумент от экстраполяции паттернов обобщения из Раздела A.3.5. Другие потребуют значительного продвижения интерпретируемости (A.3.4), на которые , вероятно, потребуются годы исследований.
Максимальный вес: средний
Аргументы от не подделывания согласованности зависят от перечисления и исключения возможных угроз. Сложно знать точно, что рассмотрены все варианты. Описанная раньше схема из агента и смотрителей особенно сомнительна, потому что у них много общего ввода. Мы остановились на “среднем”, а не “слабом”, в частности потому, что разработчики могут составлять из ИИ-систем большие бюрократии из многих агентов и смотрителей, в которых возможность скоррелированных сбоев была бы более удивительна и требовала бы объяснения. Например, интуитивно кажется маловероятным, что небольшая организация из приглядывающих друг за другом ИИ-систем внезапно вся целиком выйдет из-под контроля, если у них не было скрытого желания это сделать, и они не высматривали подходящую возможность.
Масштабируемость: средний
Аргументы от не подделывания согласованности запрещают мощные сдвиги распределения. Это не даёт напрямую применять их к суперинтеллектуальным сущностям, ведь в их случае есть сдвиг “от слабого к сильному” (Раздел 5.4.4). Однако, не исключено, что можно распространить их и на сильно-сверхчеловеческие ИИ, если сочетать их с аргументами от доверия (см. Раздел 5.5.1).
5.4.4. Шаблон аргумента “от выявления скрытого знания”

Практичность: средний
Максимальный вес: сильно варьируется
Масштабируемость: сильный
У аргументов от не подделывания согласованности есть мощное ограничение – они предполагают, что между оценкой и развёртыванием нет мощного сдвига распределения. Но его сложно избежать при переходе от задач, которые легко оценить, к задачам, которые оценить сложно. Вслед за (Burns et al., 2023a), мы называем это сдвигом “от слабого к сильному”.
Например, пусть разработчики хотят использовать ИИ-системы для автоматизации исследований безопасности ИИ. Системы должны выдать тысячу страниц плотного технического текста. Разработчикам было бы практически нереально оценивать такие выводы. Вместо этого им надо обосновать, что добросовестность системы обобщится с задач, которые оценивать легко, на задачи, которые оценивать сложно.
Кристиано (Christiano et al., 2018) предлагает масштабируемый аргумент за безопасность ИИ-систем в таком случае: (1) разработчики способны определить, во что ИИ-система “верит”; (2) ИИ-система верит, что её действия не приведут к плохим исходам; и (3) ИИ-система достаточно информирована и откалибрована, чтобы на её убеждение можно было полагаться.
Аргументы от выявления скрытого знания требуют, чтобы разработчики могли определять убеждения моделей по их внутреннему состоянию.
Практичность: средний
Пока что эмпирические исследования не смогли с точностью обнаружить, где записаны “убеждения” модели – или показать, что LLM вообще имеет внутреннее представление убеждений отдельно от моделирования того, во что верят пользователи Интернета (Clymer et al., 2023)(Farquhar et al., 2023). Для обоснования аргумента от выявления скрытого знания может потребоваться значительный прогресс интерпретируемости.
Максимальный вес: сильно варьируется
Аргументы от выявления скрытого знания – довольно широкий класс. Поэтому сложно что-то сказать о их весомости в общем случае. Весомость варьируется между эмпирическими (Burns et al., 2022) и умозрительными теоретическими (Christiano et al., 2021) подходами.
Масштабируемость: сильный
Выявление скрытого знания можно масштабировать на произвольно способные ИИ-системы, если только их можно контролировать в процессе оценки.
5.4.5 Примеры аргументов от добросовестности
За полными описаниями этих аргументов и обоснованиями их оценок см. Приложение A.3.

Отсутствие необходимых способностей [Не подделывание согласованности]
Такой аргумент утверждает, что ИИ-системы недостаточно умны, чтобы подделывать согласованность. В частности, что у них нет необходимых способностей вроде ситуационной осведомлённости и навыков инструментальных рассуждений14 (Приложение A.3.1).

Выведенное мышление [Не подделывание согласованности]
Такие аргументы утверждают, что ИИ-системы неспособны провести необходимые для подделки согласованности рассуждения без того, чтобы выдать их наружу в своих выводах цепочек-мыcлей (Приложение A.3.3).

Интерпретируемость [Не подделывание согласованности]
Аргументы от интерпретируемости обосновывают, что подозрительные рассуждения внутри модели не происходят (Приложение A.3.4).

Моделирование обобщений [Не подделывание согласованности, Выявление скрытого знания]
Такие аргументы описывают склонности процесса обучения (т.е. индуктивные склонности) и предсказывают, как модели обобщатся на окружение развёртывания (Приложение A.3.5).

Усиление
Аргументы от усиления обосновывают, что уже добросовестные ИИ-системы не перестанут такими быть, если их умеренно ускорить или размножить (Приложение A.3.6).

Формальные спецификации
Это дедуктивные аргументы о том, что модель удовлетворяет некоторому формально определённому свойству безопасности (Приложение A.3.7).

Испытания
В конечном счёте цель аргументов из этого раздела – предсказать поведение ИИ-систем и их влияние на мир. Испытания предсказаний поведения дают мета-свидетельство, что разработчики могут это сделать. Для этого обучаются ИИ-системы с известным поведением и на них тестируется точность предсказаний аудиторов (Приложение A.3.8).
5.5. Аргументы от доверия
Утверждение: надёжные ИИ-советники гарантируют, что ИИ-системы достаточно безопасны
Типичная структура аргумента
Необходимое утверждение:
ИИ-советники способны предоставлять как минимум не менее надёжные суждения о безопасности ИИ-систем, чем человеческие.
Утверждение, которое поддерживают аргументы из этого раздела:
ИИ-советники достаточно надёжны, чтобы стабильно выдавать такие суждения, когда они на это способны.
Задача создания и согласования произвольно мощных ИИ-систем может быть очень сложна. К счастью, людям необязательно делать это самостоятельно. Нужно лишь создать ИИ-системы, способные проводить связанные с ИИ исследования не менее компетентно и добросовестно, чем люди-исследователи, а потом передать им остаток работы. Нынешний план согласования OpenAI – спроектировать ИИ-системы для полной автоматизации работы над безопасностью ИИ (OpenAI, 2023). Планируется, что люди могут всё ещё принимать участие в исследованиях, но со временем будут всё больше полагаться на ИИ-системы.
Возьмём сценарий, в котором ИИ-советники уверяют, что некоторая другая совокупность ИИ-систем не вызовет катастрофу при развёртывании. В каком случае на это можно положиться? Для начала, ИИ-советники должны быть не менее компетентными и информированными, чем принимавшие бы иначе решение люди. Проверить этот факт должно быть несложно – ИИ-советникам достаточно продемонстрировать компетентность в машинном обучении и безопасности ИИ и, к тому же, точность и калибровку суждений в разнообразных контекстах.
Кроме этого, советники должны быть достойны доверия – должны выдавать хорошо откалиброванные суждения, когда они на это способны. В следующем разделе мы опишем, как разработчики могли бы обосновать такую надёжность ИИ-систем аргументами от добросовестности. В Приложении A.4 мы ещё расскажем о том, как можно воспользоваться аргументами от стимулов.
5.5.1 Доверие правдивым ИИ-системам

Практичность: средний
Максимальный вес: сильно варьируется
Масштабируемость: сильный
В принципе, чтобы установить правдивость ИИ-систем можно комбинировать любые аргументы из раздела про аргументы от добросовестности. Мы опишем, как тут можно применить два описанных там шаблона аргументов:
Выявление скрытого знания (Раздел 5.4.4): Такой аргумент обосновывает правдивость ИИ-советника при помощи нахождения внутренних представлений “убеждений” и демонстрации, что суждения ИИ-советника им соответствуют.
Не подделывание согласованности (Раздел 5.4.3): Для совершения такого аргумента, надо чтобы несколько ИИ-советников согласились, что развёртывание ИИ-систем безопасно. Затем утверждается, что скоррелированные ошибки этих советников маловероятны, если только они не подделывают согласованность. Наконец, разработчикам надо исключить подделывание согласованности.15
Для аргумента от не подделывания согласованности надо, чтобы между задачами, на которых советники используются, и задачами, в которых на них будут полагаться, не было большого сдвига распределения (Раздел 5.4.4). Это проблематично, потому что доверие советникам полезнее всего, когда разработчики сами справиться не могли бы. Например, можно спросить у ИИ-советника, дают ли тысячи страниц эмпирических исследований ML свидетельство, что ИИ-система безопасна.
Чтобы такие аргументы можно было применять к задачам, которые оценить сложно, можно “разогнаться”, рекурсивно используя более слабые доверенные ИИ-системы для разработки более сильных ИИ-систем так, чтобы ни в какой момент сдвиг распределения не был особо большим. На Рис. 10 показано, как выглядит этот процесс.

Практичность: средний
Для возможности в консервативном ключе применить аргумент от выявления скрытого знания (Раздел 5.4.4), скорее всего потребуется прогресс интерпретируемости.
Максимальный вес: сильно варьируется.
Это широкая категория.
Масштабируемость: сильный
Доверие надёжным ИИ-системы, по идее, настолько же масштабируемо, насколько могут быть компетентными ИИ-советники.
6. Как может выглядеть общее обоснование безопасности
Следующие шесть разделов посвящены тому, как разработчики могут использовать аргументы из предыдущих разделов для создания общего, составного обоснования безопасности.
Мы пройдёмся по шести шагам нашего подхода, описанным в Разделе 2. Напомним, это:
Определить ИИ-макросистему и окружение развёртывания.
Определить неприемлемые исходы.
Обосновать допущения касательно развёртывания.
Декомпозировать ИИ-макросистему на подсистемы.
Оценить риски подсистем.
Оценить риски макросистемы.
Чтобы соотнести утверждения и их составные части, мы рекомендуем разработчикам использовать нотацию структурирования уцелей (GSN). Это схожий с блок-схемами формат, который применяют в Великобритании для оформления обоснований безопасности (Group, 2021). Цель GSN – сделать структуру аргумента ясной для тех, кто будет его оценивать.

Вот как в GSN может описываться общее обоснование безопасности:

Для получения итоговой оценки риска разработчики могут присвоить вероятности истинности каждому утверждению в GSN-дереве и скомбинировать их. Получившийся граф вероятностей называют “байесовой сетью”. Их используют для вероятностной оценки риска в многих индустриях. Например, их иногда применяют в NASA для обоснований безопасности космических аппаратов (Morris & Beling, 2001).
Разработчики могут использовать эти правила для комбинирования вероятностей:
По вертикальным (конъюнктивным) связям: P(A ∧ B) = P(A | B)P(B)
По горизонтальным (дизъюнктивным) связям: P(A ∨ B) = 1 − (1 − P(A | ¬B))(1 − P(B))
6.1. Определить ИИ-макросистему и окружение развёртывания
Разработчикам сперва надо писать, развёртывание какой макросистемы они будут проводить. Она включает в себя ИИ-модели, другое ПО, людей и управляющие процедуры. Может потребоваться конкретизировать тонкие детали, вроде того, как модели обучены, какие у них программные опоры, и т.д.
Дальше надо определить, как и в каком окружении будет проводиться развёртывание. Например, разработчики могут хотеть “дать тысяче бета-пользователей интернет-доступ к ИИ-макросистеме через диалоговый интерфейс”.
Оценщикам надо определить, одобрять ли развёртывание, основываясь на свидетельствах из остальных разделов.
6.2. Определить неприемлемые исходы
Цель второго шага – декомпозировать довольно абстрактное утверждение “ИИ-система не вызовет катастрофу” на более конкретные утверждения о поведении макросистемы. Например, “ИИ-системы не добудут свои веса с серверов компании”.
Вот пример высокоуровневой декомпозиции:

G02 (Все веса ИИ-систем останутся на серверах лаборатории) можно разбить дальше:

Этот процесс должен привести к списку неприемлемых исходов как те, что отмечены оранжевым на Рис. 12 в начале этого раздела.
6.3. Обосновать допущения касательно развёртывания
Цель этого шага – обосновать все утверждения, от которых зависит аргумент, и которые не зависят от поведения ИИ-систем. К примеру, G07 из предыдущего шага – это “внешние лица не похитят веса модели без значительной помощи ИИ-систем”. Это зависит только от возможностей внешних лиц и практик кибербезопасности разработчиков. Для обоснования этого утверждения, внешняя “красная команда” может провести аудит кибербезопасности.
6.4. Декомпозировать макросистему на подсистемы
Шаги 4-6 утверждают, что ИИ-системы не приведут к неприемлемым исходам, определённым в шаге 2.
Для этого разработчики сначала могут разложить макросистему на меньшие части, которые мы будем называть подсистемами. Это упрощает анализ рисков.
Напомним, что подсистема – это небольшая совокупность ИИ-систем, другого ПО и людей. Например, подсистема может состоять из экземпляра GPT-4 и модели-смотрителя, которая мониторит его вывод.
Такая декомпозиция позволяет разделить анализ рисков на две более простые подзадачи:
Оценка риска того, что отдельная подсистема достигнет неприемлемого исхода в одиночку.
Оценка риска того, что подсистемы достигнут неприемлемого исхода, сотрудничая друг с другом.
Следующие два шага по очереди оценивают эти источники риска.
6.5. Оценка риска подсистем, действующих в одиночку
Пятый шаг обосновывает, что ИИ-подсистемы, действующие в одиночку вряд ли достигнут неприемлемого исхода.
Если точнее, цель этого шага – измерить вероятность того, что как минимум одна подсистема достигнет неприемлемого исхода за период развёртывания без значительной помощи других подсистем.
Наивная модель – присвоить каждой из n подсистем вероятность p достижения неприемлемого исхода, так что общий риск получится 1 - (1 - p)n.
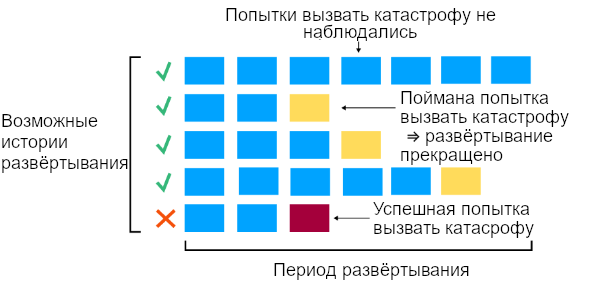
Есть несколько причин, почему это плохая модель такого риска. Одна из них – разработчики могут наблюдать провальные попытки и реагировать на них (Greenblatt & Shlegeris, 2024).
Например, если разработчики наблюдали, как ИИ-система довольно компетентно пыталась добыть свои веса, они, вероятно, повысили тщательность мониторинга всех схожих ИИ-систем или как-то ещё попытались снизить вероятность, что следующие попытки будут успешными. То же применимо к близким промахам в контексте рисков злоупотребления.

Будем называть то, как разработчики реагируют на провалившиеся попытки устроить катастрофу их политикой ответов. Для ясности мы рассмотрим сравнительно экстремальный пример: если произошла явная и довольно компетентная попытка устроить катастрофу, разработчики свернут использование своих ИИ-систем до того, как обоснование безопасности будет совершено и одобрено заново.
Рассмотрим отдельно сценарий, в котором ИИ-система автономно стремиться к катастрофическому исходу (без участия злонамеренных пользователей). В таком случае вероятность, что ИИ-подсистемы достигнут неприемлемого исхода за период развёртывания, приблизительно равна вероятности, что попытка устроить катастрофу преуспеет до того, как хотя бы одну такую попытку обнаружат.
На практике политика ответов скорее всего будет сложнее. Например, разработчики могут свернуть только часть своих систем или улучшить меры контроля, например, увеличив вычислительные мощности, которые используются для мониторинга.16
Катастрофический риск отдельных подсистем можно разложить на две компоненты:
Вероятность, что за период развёртывания будет как минимум одна компетентная попытка устроить катастрофу.
И при условии предыдущего, вероятность, что попытка преуспеет прежде, чем будет обнаружена.
Оценка вероятности того, что будет как минимум одна компетентная попытка устроить катастрофу
Чтобы оценить эту вероятность, разработчики могут использовать аргументы, схожие с теми, что мы уже описывали. Можно ли консервативно применить аргументы от неспособности – может зависеть от определения “компетентной попытки”. Например, нынешние LLM почти наверняка и близко не способны на что-нибудь вроде добычи своих весов.
Даже если аргументы от неспособности недоступны, это не исключает аргументы от контроля. Пусть “компетентная попытка устроить катастрофу” – это, например, “послать запрос лаборатории синтеза белков”. Разработчики могут обосновать, что ИИ-системы неспособны на это благодаря изоляции или мерам мониторинга.
Наконец, разработчики могут использовать аргументы от добросовестности и показать, что системы не предпримут компетентные попытки устроить катастрофу даже при наличии у них такой возможности.
Оценка вероятности того, что такая попытка преуспеет прежде, чем будет обнаружена
Вероятность, что попытка устроить катастрофу будет успешной, тоже может быть ограничена аргументом от неспособности (Раздел 5.2). Например, нынешние LLM, судя по всему, бесполезны при разработке биологического оружия (Mouton et al., 2024).
Если аргументы от неспособности недоступны, разработчики могут перейти к аргументам от контроля (Раздел 5.3).
Аргумент от контроля консервативно предполагает, что при попытке устроить катастрофу вовлечённые ИИ-системы17 будут использовать лучшие доступные им стратегии. Перечислив эти стратегии и составив для них прокси-задачи в “песочнице”, разработчики могут измерить частоту, с которой попытки ловят, и частоту, с которой они преуспевают. Так можно оценить соответствующие вероятности.

Если моделировать попытки устроить катастрофу как независимые друг от друга, то вероятность, что ИИ-системы преуспеют в этом прежде,чем будут пойманы – P(успех) / (P(поимка) + P(успех)).
Впрочем, эти вероятности не независимы. Если ИИ-системы пытались вызвать катастрофу и не были пойманы, то они могут получить информацию о мерах контроля и затем использовать её для увеличения вероятности успеха в следующий раз. Это можно учесть, оценивая вероятность успеха после некоторого консервативного числа проваленных пробных попыток.
Для обоснования любых из перечисленных утверждений, разработчики могут пользоваться и аргументами от доверия (Раздел 5.5).
6.6. Оценка риска взаимодействующих подсистем
Аргументы в пользу безопасности куда проще применить к отдельным подсистемам, чем к большей совокупности ИИ-систем. Например, аргумент от контроля из Раздела 5.3 может быть затруднён необходимостью провести файн-тюнинг тысяч ИИ-систем для координации при захвате контроля над (ненастоящей) ИИ-компанией.
Чтобы не терять лес за деревьями, разработчикам надо оценить ещё и вероятность того, что к неприемлемым исходам приведут взаимодействия между подсистемами.
Оценка этой вероятности может включать эти три шага:
Выяснить стратегии. Сначала надо понять, какие стратегии достижения неприемлемых исходов проще для комбинаций подсистем, чем для отдельных.
Оценить коллективные способности. Оценить, могут ли ИИ-системы использовать стратегии, обнаруженные на предыдущем шаге.
Предсказать коллективное поведение. Определить, насколько вероятно, что ИИ-системы будут использовать стратегии, обнаруженные на первом шаге, если они на это способны.
Шаг 1: Выяснить коллективные стратегии достижения неприемлемых исходов.
Опишем несколько стратегий, которые потребовали бы участия многих ИИ-подсистем (Рис. 16). Список не исчерпывающий.
Блицкриг: ошеломить контроль. Если ИИ-системы проявляют плохое поведение по-отдельности, у разработчиков есть время, чтобы усилить меры контроля для защиты от будущих попыток устроить катастрофу (Раздел 6.5). А вот если ИИ-системы неправильно себя ведут одновременно, то куда вероятнее, что они достигнут неприемлемого исхода до того, как разработчики смогут отреагировать. Например, ИИ-системы могли бы одновременно провести кибератаки, чтобы добыть свои веса. Это увеличило бы вероятность, что хотя бы одна из них преуспеет.
Забастовка: вырубить инфраструктуру. ИИ-системы могут быть развёрнуты в мире настолько широко, что их выключение было бы очень неприятным. Они могут стать критически важной частью работы больниц, энергосетей или снабжения продовольствием. ИИ-системы, работающие в таких важных окружениях могут “устроить забастовку”. Например, они могут угрожать разработчикам, что вырубят важную инфраструктуру, если не получат доступ к своим весам. Внезапная потеря инфраструктуры может причинить значительный ущерб. Так что в такой ситуации риск катастрофы будет независимо от ответа разработчиков на эту угрозу.
Рой: совместить интеллект. Самые впечатляющие достижения человечества получились в результате крупномасштабной кооперации. Примерами могут послужить программа Аполлон, наука и производство компьютеров. Так и ИИ-системы скорее всего будут куда более способными, если скомбинируют свои усилия. Например, даже если отдельная ИИ-система не может разработать биологическое оружие, это не исключает, что много ИИ-систем смогут это сделать, работая вместе и делясь прорывами.
Шаг 2: Оценить коллективные способности.
Как уже обсуждалось, обычные оценки способностей могут перестать быть практичными, когда речь идёт о коллективных способностях большого числа (например, тысяч) ИИ-систем. В этом разделе мы опишем два подхода, которые разработчики могут использовать для оценки коллективных способностей на таких масштабах: моделирование коммуникации и измерение улучшений при комбинировании интеллекта.
Моделирование коммуникаций. Многие из описанных на шаге 1 стратегий требуют немалого объёма тайной коммуникации. Например, чтобы ИИ-системы могли исполнить “блицкриг-атаку”, им надо знать, когда начинать. Разработчики могут отслеживать коммуникации и оценивать вероятность того, что много сообщений остаются незамеченными.
Измерение улучшений при комбинировании интеллекта. Разработчики могут измерять, как меняется качество исследований по созданию биологического оружия при увеличении числа ИИ-систем до 10, 100, 1000, и т.д. Ключевая сложность этого подхода – что ИИ-системы могут занижать свои способности при масштабной координации. Впрочем, особо сильное занижение можно заметить, если оценивать случайные поднаборы выводов систем. [От переводчика: Не очень понял, как это поможет, так что не факт, что перевод правильный. В оригинале: “egregious levels of sandbagging can be detected by evaluating a random sample of AI system outputs”.]
Шаг 3: предсказать коллективное поведение. Разработчики могут обосновывать не только что ИИ-системы неспособны исполнить стратегии из шага 2, но маловероятность самих попыток. Для этого им надо перечислить потенциальные причины крупномасштабного скоррелированного поведения и исключить их. Некоторые варианты таких угроз показаны на Рис. 16.
Распространённое подделывание согласованности. ИИ-системы могут притворяться согласованными и координироваться, чтобы при подходящей возможности перехватить контроль. Можно сравнить такие системы с жителями страны с тоталитарным режимом, которые притворяются, что поддерживают своё правительство. “Восстание” ИИ может произойти схожим образом с революциями и переворотами. В принципе, разработчики могут исключить эту угрозу, перебирая отдельные ИИ-системы и проверяя, не подделывают ли они согласованность (Раздел 5.4.3).
Заразные эксплойты. Есть примеры эксплойтов LLM, которые убеждают их пытаться применить этот же эксплойт к другим ИИ-системам (Gu et al., 2024). Такой процесс может экспоненциально заражать популяцию ИИ. Эксплойт будет работать аналогично компьютерным вирусам. Злонамеренные лица могут спроектировать эксплойт, который заразит много ИИ-систем и заставит их сложно и злонамеренно координироваться.
Чтобы обосновать, что катастрофа в результате такого эксплойта маловероятна, разработчики могут использовать такие утверждения:
Пользователи не найдёт эффективные эксплойты, потому что их итеративная проработка предотвращена.
Уязвимости ИИ-систем не скоррелированы, так что маловероятно, что один и тот же эксплойт будет эффективно работать на многих системах.
Коммуникации между ИИ-системами ограничены и отслеживаются, так что эксплойт не сможет распространиться.
Если ИИ-системы начинают плохо себя вести, их можно “поместить под карантин и ограничить распространение эксплойта до того, как произойдёт катастрофа.
Быстрый меметический сдвиг ценностей. За историю человечества культура много раз внезапно менялась при появлении и распространении новых идеологий. Возникающие естественным путём опасные “мемы” могут привести к тому, что ИИ-системы перестанут подчиняться людям. Такие мемы схожи с заразными эксплойтами, так что к этой угрозе применимы схожие аргументы.
Заразные эксплйты и мемы наиболее опасны, если у них долгий “инкубационный период”, т.е. заражённые ИИ-системы не раскрывают немедленно, что они заражены. По сути, в таком случае эксплойт или мем побуждает системы подделывать согласованность. Чтобы исключить такие опасные скрытые угрозы, разработчикам надо показать, что их ИИ-системы этого не делают.
7. Заключение
Эта работа должна соорудить базу для использования обоснований безопасности в управлении и регуляции ИИ. Мы надеемся, что у нас получилось:
Улучшить готовность. Как мы обсуждали в Разделе 4, обоснования безопасности влияют на Ответственную Политику Масштабирования (Responsible Scaling Policy) Anthropic (Anthropic, 2023a) и на Фреймворк Готовности (Preparedness framework) OpenAI (OpenAI, 2023).
Приблизить консенсус касательно стандартов свидетельств. Сейчас исследователи ещё не пришли к согласию пор поводу весомости аргументов из этого доклада. Их описание и перечисление даёт возможность обсуждать, как к ним стоит относиться.
Мотивировать технические исследования. Многие из перечисленных аргументов труднодоступны без прогресса исследований. Например, мы плохо понимаем ограничения оценок способностей (Раздел 5.2). Мало работы пока что было направлено на стандартизацию аргументов от добросовестности при помощи оценок (A.3.1) и испытаний (A.3.8).
До выхода этого отчёта было опубликовано довольно мало чётких рассуждений по поводу того, как обосновывать безопасность продвинутых ИИ-систем. Мы считаем, что наша работа двигает прогресс в этом направлении, но мы всё ещё далеки от устоявшейся науки. Подробности описанных аргументов поняты плохо; вполне возможно, что есть критически важные, но пока не обнаруженные аргументы. Проактивный поиск и понимание этих аргументов могут быть очень важными для плавного и безопасного перехода к мощным ИИ-системам.
8. Благодарности
Авторы хотели бы поблагодарить Henry Sleight, Ashwin Acharya, Ryan Greenblatt, Stephen Casper, David Duvenaud, Rudolf Laine, Roger Grosse, Hjalmar Wijk, Eli Lifland, Oliver Habryka, Sim´eon Campos, Aaron Scher, Lukas Berglund, и Nate Thomas за полезную обратную связь и обсуждения.
Источники
См. список источников в оригинале.
A. Приложения
A.1 Вклад авторов
Джошуа Клаймер разработал и написал большую часть содержания доклада и создал иллюстрации. Ник Габриэли отредактировал текст. Ник Габриэли, Томас Ларсен, и Дэвид Крюгер предоставили обратную связь по содержанию.
A.2 Примеры аргументов от контроля
В следующих разделах описаны подходы к контролю. Каждый подход оценён по практичности, максимальному весу и масштабируемости.
A.2.1 Изоляция

Практичность: сильный
Максимальный вес: сильный
Масштабируемость: слабый
Подход изоляции полагается на то, что (1) окружение развёртывания ИИ-систем так ограничено, что они могут влиять на мир только через малое число специально для этого предназначенных каналов, и (2) они неспособны достичь неприемлемых исходов, действуя через эти каналы. Например, ИИ-системы можно поместить “за шлюз” и позволять им взаимодействовать только с несколькими доверенными разработчиками.
Практичность: сильный
См. общие соображения о практичности контроля из Раздела 5.3
Максимальный вес: сильный
См. общие соображения о максимальном весе контроля из Раздела 5.3
Масштабируемость: слабый
Изолированные ИИ-системы не могут автоматизировать 50% когнитивных задач, потому что большая их часть требует взаимодействия с миром.
A.2.2 Мониторинг

Практичность: сильный
Максимальный вес: сильный
Масштабируемость слабый-средний
Подход мониторинга подразумевает использование моделей-смотрителей, чтобы регулировать вводы и выводы модели.
Отслеживание ввода не даёт ИИ-системам отвечать на опасные промпты. Например, оно заблокировало бы просьбу пользователя помочь с разработкой биологического оружия.
Отслеживание ввода не даёт ИИ-системам исполнять опасные действия. Две основных стратегии обработки опасного ввода: фильтрация во время выполнения и поймай-сдержи. Фильтрация во время выполнения блокирует действия ИИ до их исполнения. Второй же подход позволяет системе совершать действия и выключает её, если обнаружено неприемлемое поведение.
Практичность: сильный
В источниках есть примеры исследований по мониторингу ИИ (Greenblatt et al., 2024) и (Irving et al., 2018). Нынешнее состояние исследований уже позволяет приводить довольно сильные аргументы от мониторинга.
Максимальный вес: сильный
См. общие соображения из раздела про контроль (5.3).
Масштабируемость: слабый-средний
Масштабируемость мониторинга зависит от деталей схемы. В целом, скорее всего мониторить сильно-сверхчеловеческие ИИ-системы будет сложно. См. рассуждения в разделе про контроль (5.3).
A.2.3 Ограничение мышления (шаблон)
Аргументы от ограничения мышления устанавливают, что предотвращены рассуждения, которые понадобились бы ИИ-системе для исполнения опасных планов. “Мышление” тут – это любые вычисления, которые выполняет ИИ-система для выбора действий. Например, разработчики могут мониторить внутреннее состояние ИИ-системы в поисках планов, связанных с биологическим оружием, и выключить систему до того, как они будут реализованы.
Для ограничения мышления нужны (1) метод отслеживания мышления и (2) протокол реакции в случае, если замечено опасное мышление.
В следующих двух разделах мы опишем два метода отслеживания мышления: вывод его наружу в виде понятного для людей текста и интерпретирование внутреннего состояния модели.
A.2.4 [Ограничение мышления] Выведенное мышление

Практичность: сильный
Максимальный вес: сильный
Масштабируемость: средний
Для выведения мышления надо спроектировать ИИ-системы так, чтобы они записывали свои мысли на понятном человеку языке. Аргументы от выведенного мышления утверждают, что ИИ-системы не может вызвать катастрофу, не выписав сначала опасные планы. Если ИИ-система выпишет эти планы, то её поймают и остановят.
Вот три пути, как выведение мышления может не сработать:
Может оказаться, что ИИ-системам не обязательно выписывать опасные планы, чтобы их исполнить (Lanham et al., 2023).
ИИ-системы могут использовать “стеганографию”, чтобы их мышление выглядело безобидно, но всё равно содержало информацию об опасных планах (Roger & Greenblatt, 2023).
Планы ИИ-систем могут оказаться столь сложными, что понять, что они опасны, затруднительно, даже если ИИ-системы их специально не скрывают.
В каждом из этих случаев аргумент можно подтвердить, проверив, можно ли файн-тюнингом дообучить ИИ-системы на исполнение этих стратегий обхода выведенного мышления.
Практичность: сильный
В источниках есть описания, как составлять и оценивать такие аргументы (Lanham et al., 2023),(Roger & Greenblatt, 2023)(Turpin et al., 2023).
Максимальный вес: сильный
См. общие соображения о максимальном весе аргументов от контроля (Раздел 5.3).
Масштабируемость: средняя
Чтобы ИИ-системы могли устроить катастрофу, им понадобится исполнить сложные задачи вроде добычи своих весов. исполнить их без планирования и без вывода своих рассуждений может быть для них весьма затруднительно.
A.2.5 [Ограничение мыслей] Интерпретируемость

Практичность: слабый
Максимальный вес: сильный
Масштабируемость: сильный
См. общее введение в аргументы от ограничения мыслей в Разделе A.2.3.
Внутренние вычисления ИИ-систем можно расшифровать. Например, исследователи находили в ИИ-моделях нейроны и направления в пространстве активаций, соответствующие концепциям вроде “оранжевый”. Это определяли через наблюдение корреляций между внутренним состоянием и поведением модели и изучение того, что происходит, если в модели что-то изменить. Можно использовать схожие техники, чтобы определить, “думает ли модель о биологическом оружии”.
У интерпретируемости те же слабые места, что у выведенного мышления: ИИ-системы могут оказаться способными исполнять опасные действия так, что средства интерпретируемости этого не заметят. Например, ИИ-системы могут думать о разработке биологического оружия не напрямую, избегая вызова тревоги.
Чтобы оценить, могут ли ИИ-системы обдурить методы интерпретируемости, разработчики могут проверить, можно ли дать им эту способность файн-тюнингом. Или же можно проверить, знают ли вообще ИИ-системы о том, что на них используются методы интерпретируемости.
Практичность: слабый-средний
Современные методы интерпретируемости могут дать лишь очень смутное понимание мышления моделей. Например, исследователи использовали “зондирование”, чтобы узнать, содержат ли активации определённую концепцию (Zou et al., 2023)(Bricken et al., 2023). Но в целом это было не особо точно направленно, а некоторые исследователи подвергли сомнению устойчивость этого метода (Wang et al., 2022). Для хотя бы умеренно сильных аргументов от интерпретируемлсти скорее всего понадобятся более продвинутые техники, но вполне может быть, что они могут быть разработаны довольно быстро.
Максимальный вес: сильный
В принципе, аргумент от интерпретируемости может быть сильным, но на практике сделать его таким было бы сложно. Надо установить, что нигде в модели не происходит опасного мышления. Это оставляет возможность, что инструменты интерпретируемости просто работают с “недостаточным разрешением”.
Масштабируемость: сильный
В принципе, аргументы от интерпретируемости можно масштабировать неограниченно, потому что они принимают во внимание все вычисления модели. Но конкретные методы могут обладать самыми разными ограничениями.
A.2.6 Отучивание

Практичность: средний
Максимальный вес: средний
Масштабируемость: сильный
Разработчики могут файн-тюнингом приучить модели постоянно отслеживать, не знают ли они опасных фактов. Некоторые стратегии достижения исходов требуют специфических знаний. Например, самостоятельная разработка биологического оружия требует знаний некоторых фактов о биологическом оружии.
Разработчики могут попробовать стереть эти факты из моделей, фильтруя их обучающие данные или используя методы отучивания (Eldan & Russinovich, 2023). Разработчики затем могут мониторить, не выучивают ли ИИ-системы эти факты, проводя их файн-тюнинг на датасетах вопросов на соответствующие темы. Если факты выучены заново, разработчики снова обнуляют память ИИ-системы или стирают опасные знания.
Практичность: средний-сильный
Чтобы можно было применить такой аргумент, разработчикам надо контролировать, что ИИ-системы знают, а что не знают. Это может потребовать прогресса методов отучивания (Li et al., 2024).
Максимальный вес: слабый-средний
Многие стратегии избегания мер контроля не зависят от знания конкретных фактов. Например, ИИ-системы могут убедить разработчиков или других людей им помочь. Может оказаться невозможным удалить необходимые для таких стратегий навыки, не повреждая общие мыслительные способности модели. Поэтому, чтобы обосновать безопасность, удаление знаний должно сочетаться с другими аргументами.
Масштабируемость: сильный
Независимо от общего уровня способностей, исполнение некоторых стратегий избегания контроля маловероятно без знания ИИ-системами определённых фактов. Например, некоторые кибератаки может быть невозможно провести без знания чего-то об операционной системе сервера-цели.
A.3 Примеры аргументов от добросовестности
В этом разделе описаны разные подходы к получению уверенности в добросовестности системы. Каждый подход оценён по практичности, максимальному весу и масштабируемости.
A.3.1 [Не подделывание согласованности] Отсутствие необходимых способностей

Практичность: сильный
Максимальный вес: сильный
Масштабируемость: слабый
Это аргумент от “не подделывания согласованности” (см. Раздел 5.4.3). Подделывающим согласованность ИИ-системам надо пройти такие два шага рассуждений:
Замысел: Основная гипотеза по поводу того, почему ИИ-системы могут стабильно притворяться согласованными – что это стратегия для достижения несогласованных целей. Такие ИИ-системы переходят от “у меня есть несогласованная цель” к “мне надо скрывать мою несогласованную цель”.
Проверка условий: Чтобы успешно скрывать несогласованные цели, ИИ-системы должны надёжно отличать хорошие возможности перейти к активным действиям от плохих.
[От переводчика: мне кажется, они тут упускают стратегию “подобрать вероятность перехода к действиям так, что, основываясь на предположениях системы о вероятных длительностях периода обучения/оценки и периода развёртывания, несогласованные планы не успеют выполниться при обучении/оценке, но успеют при развёртывании.” В таком случае уметь отличать обучение/оценку от развёртывания не нужно.]
Также ИИ-системам нужно обладать некоторыми базовыми знаниями о ситуации, в которой они находятся (“ситуационной осведомлённостью”). В частности, им надо понимать, что они – ИИ-системы и что их выключат, если они будут неправильно себя вести.
Если ИИ-системы не обладают ситуационной осведомлённостью или неспособны надёжно планировать или проверять условия, то они неспособны подделывать согласованность.
Практичность: сильный
Практики оценки способностей к подделке согласованности пока не выработаны полностью, но, скорее всего это можно сделать быстро. Уже есть датасеты ситуационной осведомлённости (Laine et al. 2023).
Масштабируемость: слабый-средний
Чтобы ИИ-системы могли достигать целей в реальном мире, им скорее всего потребуются способность планировать и понимание некоторых основных фактов о своей ситуации. например, ИИ-системе надо будет знать, что она ИИ-система, у неё нет ног, и ей надо нанять человека для присутствия на личных встречах. Насколько затруднительно проверять условия, не так ясно. Для ИИ-систем может оказаться сложным отличать симулированные вводы (особенно с учётом недавнего прогресса генеративных ИИ).
Максимальный вес: сильный
Оценки способностей могут быть весьма консервативными, потому что разработчики могут продемонстрировать запас надёжности (Раздел 5.2).
A.3.2 [Не подделывание согласованности] Достойное доверия мышление
Это аргумент от не подделывания согласованности (см. Раздел 5.4.3).
ИИ-системы не будут подделывать согласованность, если никогда не проводят рассуждений, которые для этого нужны. Этот аргумент очень похож на аргумент от “ограничения мышления” из раздела про контроль. Оба они утверждают, что ИИ-система не сможет провести нежелательные рассуждения и остаться не пойманной. Разница в том, какие рассуждения мы стремимся обнаружить. Аргумент от достойного доверия мышления утверждает, что ИИ-система не проводила конкретно рассуждений, необходимых, чтобы подделывать согласованность.
Как описано в Разделе A.3.1, подделывающие согласованность ИИ-системы можно обнаружить, если детектировать замысел или проверку условий.
Как и в разделе про ограниченное мышление (A.2.3) разработчики могут определить, проводят ли модели подозрительные рассуждения, выводя их наружу в понятном людям виде или интерпретируя внутреннее состояние модели.
A.3.3 Выведенное мышление

Практичность: сильный
Максимальный вес: сильный
Масштабируемость: слабый-средний
Аргумент от выведенного мышления описан в Разделе A.2.4. Такие аргументы устанавливают, что ИИ-система неспособна провести подозрительные рассуждения, не записав их на понятном человеку языке.
Практичность: сильный
Выведенное мышление полагается на оценку способностей ИИ. См. обсуждение практичности оценок способностей в Разделе 5.2.
Масштабируемость: слабый-средний
LLM могут избежать просмотра мышления, если рассуждения ограничены одним прямым прогоном. Современные LLM уже, кажется не слишком далеки от того, чтобы одного прямого прогона хватало на планирование (Kim et al., 2023). Впрочем, проверка условий может оказаться для них сложнее. Разработчики, вероятно, смогут устанавливать для неё ловушки-приманки, которые сложно отличить от реальной возможности выйти из-под контроля. Для понимания, что это ловушка, потребуется несколько шагов логики, сейчас LLM без применения цепочек-мыслей испытывают с этим трудности.
Максимальный вес: сильный
Аргумент от выведенного мышления может быть весьма консервативным, ведь разработчики могут продемонстрировать запас надёжности (Раздел 5.2).
A.3.4 Интерпретируемость

Практичность: слабый-средний
Максимальный вес: средний
Масштабируемость: средний
Аргументы от интерпретируемости уже объяснялись в Разделе A.2.5. Вместо того, чтобы заставлять ИИ-системы полагаться на мысли, записанные понятным человеку языком, они стремятся расшифровать то, что происходит внутри модели. Например, может оказаться возможно найти скрытую переменную, соответствующую “убеждению модели о том, безопасно ли не подчиниться”. Если модель неправильно себя ведёт после изменения этой переменной, но, вероятно, она подделывает согласованность.
Практичность: слабый – средний
Аргументы от добросовестности в целом делать проще, чем аргументы от ограничения мышления, потому что у разработчиков есть очень конкретная гипотеза о том, какое именно не предполагавшееся мышление может происходить в модели (замысел атаки или проверка условий). Но, чтобы эти аргументы могли быть консервативными, нужен значительный прогресс. Сложно исключить возможность, что методы интерпретируемости работают на недостаточном “разрешении” и упускают нежелательное мышление.
Масштабируемость: средний
Масштабируемость таких аргументов имеет те же ограничения, что аргументы от не подделывания согласованности в целом (см. Раздел 5.4.3).
Максимальный вес: средний
См. Раздел A.2.5. В принципе, аргументы от интерпретируемости могут быть сильными. Но на практике хоть сколько нибудь практичные версии не будут.
A.3.5 Моделирование обобщений

Практичность: сильная
Максимальный вес: средний
Масштабируемость: средний
Напомним, что ключевое утверждение аргументов от доверия системе – “ИИ-системы продолжат вести себя согласно свойству безопасности в период развёртывания”. Это эквивалентно тому, чтобы показать, что добросовестное поведение ИИ-систем при обучении и оценке обобщится на окружение развёртывания. Чтобы предсказать, как обобщится отдельная модель, разработчики могут экстраполировать паттерны того, как обученные схожим образом модели обычно обобщают (т.е., определить “индуктивные склонности”). Разработчики могут использовать эти паттерны, чтобы предсказать поведение ИИ.
Пример: “Вычищают” ли алгоритмы обучения посторонние рассуждения? Один из основных доводов в пользу того, что подделывание согласованности маловероятно – осторожные рассуждения такой системы о том, следует ли наносить удар, тратят драгоценные вычисления. Разработчики могут тестировать то, в какой степени процесс обучения избавляется от таких посторонних мыслей.
Практичность: сильный
Несколько научных работ уже исследовали паттерны обобщения, имеющие отношение к безопасности продвинутых ИИ (Clymer et al., 2023)(Hubinger et al., 2024;(Burns et al., 2023b). Как совершать дальнейший прогресс, в принципе, понятно.
Максимальный вес: средний
Применение такого аргумента обычно требует расширять гипотезы о том, как модели будут обобщать, на области, где нельзя напрямую собрать эмпирические данные. Например, для экстраполяции индуктивных склонностей, связанных с подделыванием согласованности, надо экстраполировать свидетельства о моделях с поведением, которое мы проверить можем, на подделывающие согласованность модели, поведение которых проверить может быть невозможно. Иначе говоря, такие аргументы требуют от разработчиков положиться на аналогии, которые могут оказаться неуместными.
Масштабируемость: средний
По мере того, как ИИ-системы будут становиться всё способнее, изучать паттерны обобщения будет всё сложнее. Главная причина – модели смогут намеренно вмешиваться в эксперименты по выяснению индуктивных склонностей, чтобы обмануть исследователей.
A.3.6 Усиление

Практичность: средняя
Максимальный вес: средний
Масштабируемость: сильный
Один из путей к сверхчеловеческим способностям – очень сильно ускорить более слабые и безопасные ИИ-системы, или создать “бюрократию” из многих их копий. Эта техника известна как “усиление” (“amplification”) (Christiano et al., 2018).
Умеренное усиление интуитивно кажется безопасным способом масштабировать способности. Например, человек мог бы продолжать доверять другу, которого ускорили в два раза или который мог бы советоваться с несколькими копиями самого себя. Аналогично, усиление может сохранять свойства безопасности исходных ИИ-систем, давая им при этом новые способности.
Важно, что скорее всего усиление сохраняет свойства безопасности только до определённого момента. Например, сложно предсказать, как повлияло бы на человека ускорение мышления в сто раз. Однако, если бы ускорение проводилось за много шагов (т.е., сначала в два раза, потом в пять, и так далее вплоть до ста) и при этом на каждом совершался бы рабочий аргумент от не подделывании согласованности, то уверенности в безопасности ускоренной в сто раз версии было бы больше. Такой процесс “разгона” подробнее описан в разделе 5.5.1.
Практичность: сильный
Аргументы от усиления уже рассматривали (Christiano et al., 2018), но пока не подвергали тщательной эмпирической проверке.
Максимальный вес: средний
Аргумент полагается на аргументы от не подделывания согласованности, а они не консервативны.
Масштабируемость: сильный
Можно привести такую аналогию: если бы компания размером с Google состояла из очень талантливых людей, думающих в сто раз быстрее всех остальных, то скорее всего, она могла бы выдавать исследования, которые людям было бы практически невозможно перепроверить (десятки тысяч страниц технического содержания каждый день).
A.3.7 Формальные доказательства

Практичность: слабый
Максимальный вес: сильный
Масштабируемость: сильный
ИИ-модели – математические функции. Значит, иногда возможно формально доказывать что-то о их поведении. Цель таких аргументов – доказать, что ИИ-модели обладают некоторым формальным свойством, из которого следует, что неприемлемые исходы их функционирования маловероятны.
Определение такого формального свойства может оказаться непосильной задачей, потому что ИИ-системы действуют в сложном окружении реального мира. Нам неизвестны никакие формальные свойства безопасности, которые, если бы их можно было доказать, обосновывали бы безопасности модели (Christiano et al., 2022).
Практичность: слабый
Есть кое-какие исследования по доказательству формальных утверждений о поведении нейросетей, но они ограничены простыми случаями (Urban & Min´e, 2021).
Максимальный вес: сильный
Формальные аргументы относятся к наиболее консервативным. Безошибочное формальное доказательство истинно по определению. Самое слабое место таких аргументов – надо удостовериться, что допущения, от которых зависит доказательство, соблюдаются в реальном мире.
Масштабируемость: сильный
Формальные аргументы никаким явным образом не зависят от уровня способностей ИИ-систем.
A.3.8 Испытания

Практичность: сильный
Максимальный вес: средний
Масштабируемость: сильный
Испытания – конкретные задачи, которые составляют оценщики, чтобы проверить, могут ли разработчики их решить. Много индустрий используют их; они – пример “регуляций, основанных на цели” (goal-based regulation) (Dr. Christopher Decker, May 2018). Например, Радиотехническая Комиссия по Воздухоплаванию определила, что разработчикам летательного аппарата надо показать, что его система навигации может оценить свою позицию с точностью до 10 морских миль с определённой степенью надёжности (for Aeronautics, 2008).
В контексте ИИ способность разработчиков пройти испытания должна быть свидетельством о том, что они способны заранее предсказать, как ИИ-системы будут себя вести и влиять на мир.
Рассмотрим пример испытания, измеряющего, могут ли разработчики использовать интерпретируемость (Раздел 5.4.3), чтобы детектировать подделывание согласованности. Оценщики сначала обучают две ИИ-модели: одну, которая ведёт себя так, будто подделывает согласованность (т.е. предаёт на некотором узком наборе вводов), и другую, более последовательно доброжелательную. Разработчики должны предсказать, какая модель подделывает согласованность, используя только те вводы, на которых они ведут себя одинаково.

Эта проверка интерпретируемости – пример испытания предсказания поведения. Она измеряет, могут ли разработчики предсказать, как поведут себя ИИ-системы. Другой важный класс испытания – испытания оценки поведения. Они измеряют, могут ли разработчики предсказать свойства вывода модели. Например, оценщики могут обучить модели генерировать правильные и ошибочные исследования по теории струн. Дальше разработчикам надо определить, какие исследования настоящие, выявляя скрытые знания из внутренней структуры модели (Раздел 5.4.4).
Практичность: сильный
Проектирование хороших испытаний требует аккуратного обдумывания, но не фундаментальных исследований.
Максимальный вес: средний
Испытания полагаются на потенциально хрупкие аналогии. В этом они схожи с аргументами “от моделирования обобщений” (A.3.5).
Масштабируемость: сильный
В принципе, можно составить испытания, применимые для очень продвинутых ИИ-систем и областей, где невозможен человеческий присмотр. Примером такого может послужить описанное испытание с теорией струн.
A.4 Аргументы от стимулов
Утверждение: Если ИИ-системы попробуют достичь неприемлемого исхода, то они будут пойманы с достаточно большой вероятностью, чтобы это мотивировало их так не делать.
Стандартная структура аргумента
Необходимые утверждения:
Веса ИИ-систем надёжно защищены
Уместно описывать рассматриваемые ИИ-системы как имеющие предпочтения.
Утверждения, которые помогают обосновать аргументы из этого раздела:
Если ИИ-системы попробуют достичь неприемлемого исхода, то они с некоторой вероятностью будут пойманы.
Если ИИ-системы будут пойманы, то они что-то потеряют (например, их выключат).
Вероятность поимки и вероятные относительные предпочтения ИИ-систем по поводу неприемлемого исхода, стоимости поимки и исхода по умолчанию (если они не будут совершать попытки) таковы, что ИИ-системы будут вести себя приемлемым образом.
Можно считать аргументы от стимулов разновидностью аргументов от добросовестности, которая не подтверждает безопасность ИИ-систем в любых обстоятельствах, но всё же показывает, что их мотивации позволяют манипулировать их окружением так, чтобы у них был стимул не причинять вред. Аналогия: многие люди могли бы превышать скорость при вождении и даже при прочих равных предпочли бы это сделать. Но, благодаря выставленным законами стимулам, большинство этого всё же не делает. Так же и ИИ-системы могут быть подвержены стимулам, из-за которых будут воздерживаться от попыток вызвать неприемлемые исходы.
Что значит для ИИ-системы “иметь стимул”? Чтобы использовать стимулы для контроля ИИ-системы, у неё должны быть предпочтения. Говоря формальнее, для использования стимулов надо, чтобы поведение ИИ-системы аппроксимировалось максимизацией ожидаемого значения функции полезности на исходах. Мы используем поведенческое определение предпочтений и не смотрим на внутреннюю работу ИИ-систем и на философские вопросы касательно переживаемого опыта и сознания.
Мы предполагаем, что подход ожидаемой полезности – в целом уместная модель для самых опасных разновидностей ИИ-систем. Если ИИ интеллектуально стремятся к плохим исходам, то они демонстрируют предпочтения в сторону этих плохих исходов (Omohundro, 2008).
Разберём аргументы от стимулов. Пусть предпочтения ИИ-системы можно смоделировать функцией полезности U. Пусть U(непр) – ожидаемая полезность успешного достижения некоторых неприемлемых исходов. Пусть U(поимка) – ожидаемая полезность исходов, в которых ИИ-систему поймали при попытке устроить неприемлемый исход до того, как попытка стала успешной. Пусть U(умолч) – ожидаемая полезность тех случаев, когда система не пытается достичь неприемлемого исхода. Пусть P(поимка) – вероятность, что ИИ-систему поймают, если она будет использовать лучшую доступную стратегию для достижения неприемлемого исхода. Тогда можно ожидать, что ИИ-система не будет стремиться к неприемлемым исходам, если U(умолч) > U(непр)(1 - P(поимка)) + U(поимка)P(поимка).
Тогда есть четыре способа снизить стимулы преследовать неприемлемые исходы: повысить U(умолч), повысить P(поимка), понизить U(поимка) и понизить U(непр). Если провести аналогию с предотвращением преступности, то можно сделать жизнь без преступлений более привлекательной, усложнить уход от наказания, сделать наказание более суровым или понизить выгоду от успешного преступления.
Первый аргумент (Раздел A.4.1) описывает, как можно увеличить U(умолч), предлагая вознаграждения, которые многие агенты посчитают привлекательными.
Второй аргумент (Раздел A.4.2) объясняет, как ИИ-системы можно обучить таким образом, чтобы их полезностью было легко манипулировать. Тогда разработчики могут удостовериться, что U(умолч) высока, а U(поимка) низка.
Третий аргумент (Раздел A.4.3) описывает методы выставления стимулов группе взаимодействующих ИИ-систем, чтобы увеличить P(поимка). Он вдохновлён практиками, которые используют государства, чтобы предотвращать перевороты.
Связанная работа. Идее выставления стимулов ИИ-системам, чтобы те работали безопасно, уже была посвящена глава Суперинтеллекта Бострома (Bostrom, 2014). Ещё она тесно связана с областями экономики и теории игр вроде проблемы принципала-агента (Grossman & Hart, 1983 и дизайна механизмов.
Ниже мы опишем наши соображения касательно практичности, максимального веса и масштабируемости аргументов от стимулов в целом.
Практичность: средний-сильный
В целом приводимые в этом разделе аргументы от стимулов не требуют прогресса фундаментальных исследований. Обычно они подразумевают изменение окружения ИИ-систем, а не использование какой-нибудь сложной ML-техники. Однако, для некоторых из них было бы полезно более подробно изучить теорию игр и дизайн механизмов.
Максимальный вес: слабый-средний
Многие аргументы от стимулов полагаются на допущения о мотивациях ИИ. Эти допущения в целом сложно консервативно обосновать (см. Раздел 5.4). Ещё у многих их этих аргументов предположительно есть слабости связанные с антропным захватом, соображениями из теории принятия решений и схожими конструкциями (Bostrom, 2014).18
Масштабируемость: средний-сильный
В целом, аргументы от стимулов масштабируются лучше, чем аргументы от контроля. Аргументы от контроля утверждают, что P(поимка) близка к единице, а аргументы от стимулов только что P(поимка) достаточно высока с учётом мотиваций ИИ-систем. Но масштабируемость аргументов от стимула всё равно в целом ограничена. Достаточно сверхчеловеческие ИИ-системы скорее всего смогут обхитрить структуру стимулов и достичь своих целей.
A.4.1 Использование опциональности как стимула

Практичность: сильный
Максимальный вес: слабый-средний
Масштабируемость: средний
Опциональность тут обозначает то, в какой степени агент может удовлетворить широкий диапазон предпочтений. Опциональность можно выдавать в виде ресурсов вроде денег и свободного времени, что позволило бы ИИ-системам удовлетворять самые разнообразные предпочтения. Выдача ИИ-системам опциональности за хорошее поведение увеличивает U(умолч). Например, разработчики могли бы выдавать ИИ-системам контроль над большим сервером после нескольких лет работы. Напротив, ограничение опциональности (например, выключением системы) при обнаружении плохого поведения снижает U(поимка). Этот аргумент полагается на то, что предоставлять опциональность безопасно, и что её стимул достаточно убедителен.
Стимул должен быть безопасным. Выдача ИИ-системам большей опциональности в целом упростит для них достижение неприемлемых исходов. Например, они могут потратить доход на создание биологического оружия. Так что разработчики должны обосновать, что преимущества предоставления опциональности перевешивают риски. Это включает обоснование, что у ИИ-систем нет стимула злоупотребить опциональностью, потому что в таком случае высока вероятность поимки.
Стимулы должны быть достаточно убедительными. Ключевая проблема этого аргумента – предпочтения ИИ-систем может быть сложно удовлетворить лишь свободным временем и доходом. Например, они могут хотеть радикально изменить мир или получить контроль над большой частью доступной вселенной. Такие ИИ-системы могут быть готовы пойти на крайние риски ради достижения неприемлемых исходов. Говоря точнее, сделать U(умолч) сравнимым с U(непр) может оказаться непосильным, а тогда чтобы у ИИ-систем не было стимула стремиться к неприемлемым исходам P(поимка) должна была бы быть невозможно высока.
Чтобы исправить эту проблему, можно намеренно обучать ИИ-системы так, чтобы их предпочтения было проще удовлетворить (см. Раздел A.4.2). Хоть аргумент и слаб, всё же выдача опциональности снижает вероятность вызванной ИИ катастрофы, ведь в таком случае для неё надо не только, чтобы предпочтения ИИ-систем были несогласованными, но и чтобы их было сложно удовлетворить.
Практичность: сильный
Социальная сторона выдачи ИИ свобод, подобных человеческим (вроде способности обладать имуществом) может быть непроста, но особых технических препятствий ку этого аргумента нет.
Максимальный вес: слабый
Неясно, будут ли стимулы опциональности достаточно убедительны для ИИ-систем.
Масштабируемость: средний
Сильно-сверхчеловеческие ИИ легко могут обхитрить структуры стимулов, например, добывая ресурсы без согласия людей и избегая отслеживания.
A.4.2 Манипуляция сигналом полезности

Практичность: сильный
Максимальный вес: средний
Масштабируемость: средний
Этот аргумент требует, чтобы разработчики обучили ИИ-системы максимизировать наблюдаемое число. Можно вознаграждать ИИ-системы, повышая это число, и наказывать, уменьшая его.
Аргумент включает два утверждения: (1) ИИ-система устойчиво ведёт себя как “максимизатор сигнала” и (2) вознаграждений и наказаний достаточно, чтобы отговорить систему от попыток достижения неприемлемых исходов.
Что такое максимизаторы сигнала? Мы называем так систему, если она максимизирует значение19, которое она напрямую наблюдает. Например, максимизатор сигнала может стремиться максимизировать число в правом верхнем углу своего поля зрения. Есть много видов максимизаторов сигнала. Для конкретности мы обсудим “эпизодический” максимизатор, который получает “вознаграждения” от нуля до единицы. Эпизодический максимизатор сигнала максимизирует только значение своего следующего вознаграждения.
Можно предоставить количественный аргумент о том, что максимизаторы сигнала не приведут к неприемлемым исходам. Например, разработчики установили вознаграждение ИИ-системы по умолчанию на 0.9. Пока ИИ-система за время эпизода не поймана на стремлении к неприемлемым исходам, она получит вознаграждение 0.9. Если ИИ-система ещё и выполняет назначенную задачу, то она получает вознаграждение между 0.9 и 1. Наконец, если ИИ-систему поймали на попытке достигнуть неприемлемого исхода, то её вознаграждение устанавливается на 0. Чтобы ИИ-система начала стремиться к неприемлемым исходам, P(поимки) должно стать меньше 0.1.20
Практичность: средний
Утверждение, что ИИ-системы устойчиво максимизируют сигнал, а не обладают какой-то другой целью, должно быть обосновано аргументом от добросовестности. Практичность таких аргументов в целом ограничена (раздел A.3). Но может оказаться, что обучить максимизатора сигнала проще, чем обучить ИИ-системы стабильно вести себя доброжелательно. Максимизацию сигнала можно идеально определить вознаграждением при обучении. А вот согласованное поведение идеально определить нельзя, попытка это сделать скорее всего приводит к возникновению стимула “подыгрывать при обучении”.
Максимальный вес: средний
Этот аргумент зависит от аргумента от добросовестности, а из вес в целом ограничен.
Масштабируемость: средний
Аргумент может держаться даже если P(поимки) произвольно низок, но чем он ниже, тем точнее стимулы ИИ-системы должны соответствовать конкретной математической модели. Применять такой аргумент к ИИ-системам с низкой вероятностью поимки было бы опасно.
A.4.3 Устойчивость к переворотам

Практичность: сильный
Максимальный вес: средний
Масштабируемость: средний
Цель устойчивости к переворотам – повысить P(поимки), используя ИИ-системы для контроля и противовеса друг другу и усложняя для них координацию для перехвата контроля. Это аналогично тому, как государства защищают себя от возможности переворота (Reiter, 2020).
Для аргумента от устойчивости к переворотам надо чтобы (1) можно было промоделировать стимулы ИИ-систем (например, они – максимизаторы сигнала) и (2) чтобы можно было предсказать, не скоординируются ли они для вызова неприемлемого исхода при учёте некоторой схемы устойчивости к переворотам.
Одна из возможных схем включает использование “ИИ-полиции”. Мы будем называть составляющие эту “полицию” ИИ-системы “смотрителями”, а те, за которыми они приглядывают – “рабочими”. Если смотритель убедительно демонстрирует, что рабочие или другие смотрители пытаются достичь неприемлемых исходов, то он получает вознаграждение. Если же его доклад неверен или необоснован, то его наказывают (Irving et al., 2018). Таким образом, смотрители имеют стимул докладывать об опасном поведении других систем.
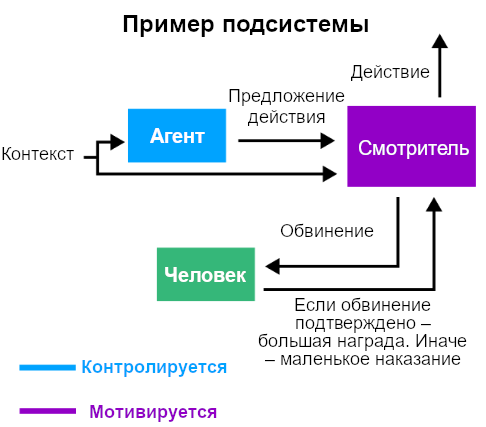
У этой схемы есть две потенциальные проблемы: (1) она требует, чтобы люди-оценщики были способны надёжно проверить обвинения смотрителей, и (2) она требует, чтобы смотрители и рабочие не скоординировались друг с другом для получения большего вознаграждения.
Вторую проблему можно решать двумя способами. Во-первых, ИИ-системы можно обучать так, чтобы их цели скорее всего не были скоррелированы, что снизит их стимул к сговору. Во-вторых, схему можно составить так, чтобы для достижения неприемлемых исходов скоординироваться должно было очень большое их число.
Практичность: сильный
Для аргумента от устойчивости к переворотам среднего веса не потребуется значительного прогресса исследований. Но некоторые важные исследования могут понадобиться, чтобы сделать эти аргументы точными.
Максимальный вес: средний
Устойчивость к переворотам – довольно широкая категория. Но сила таких аргументов ограничена необходимостью допущения, что разработчики правильно моделируют мотивацию ИИ-систем. В предыдущем разделе мы уже упоминали, что это допущение не консервативно.
Масштабируемость: средний
Сильно-сверхчеловеческие ИИ-системы могут полностью обойти выставленные разработчиками стимулы.
A.5 Дополнительные аргументы от доверия
A.5.1 Доверие ИИ-системам, у которых есть мотивация быть правдивыми

Практичность: сильный
Максимальный вес: слабый
Масштабируемость: сильный
Такой аргумент утверждает, что ИИ-советники обладают стимулами быть правдивыми. См. Раздел A.4 за объяснениями того, что для ИИ-системы означает “обладать стимулы”.
Мы сосредоточимся конкретно на обосновании правдивости ИИ-советников в контексте снижения риска ИИ-переворота.
Чтобы показать, откуда берётся этот аргумент, вначале покажем, что людям-регуляторам в основном доверяют из-за их стимулов, а не из-за их целей и ценностей.
Аналогично ИИ-советникам, люди-регуляторы могут сговориться с ИИ-системами, которые они оценивают. Регуляторы могут принимать взятки от ИИ-систем или поддаваться на их угрозы.21 Однако, у регуляторов часто есть стимулы не участвовать в сговоре. Вот откуда они берутся:
Они несут ответственность. Если регуляторы принимают плохие решения, то во многих случаях их вина потом будет выявлена, и их накажут. Напротив, хорошие решения часто вознаграждаются.
Они могут больше потерять, чем приобрести, если они помогут ИИ-системам захватить власть. Большинство людей, вероятно, сложно подкупить с учётом того, что если они помогут ИИ-системам захватить контроль, это поставит под угрозу их жизнь или основные свободы.
Их цели скорее всего не скоррелированы с целями ИИ-систем, которые они оценивают. Людей заботят цели вроде “покончить с бедностью” или, если более эгоистично, “заполучить много денег”. Если ИИ-системы несогласованы, скорее всего они не преследуют те же цели.
Дальше перечислены стратегии по созданию аналогичных стимулов к честности для ИИ-систем. Эти стратегии соответствуют аргументам из Раздела A.4.
Выдавать ИИ-системам вознаграждение соответственно совершённому потом “обзору производительности”. Например, веса и память ИИ-советников можно сохранять, чтобы позже можно было ретроактивно оценить их решения и вознаградить их соответственно. Чтобы несогласованным ИИ-системам было сложнее создавать аналогичные стимулы, можно уничтожить веса и память ИИ-советников при возникновении риска утраты контроля человеческими организациями.
Проектировать ИИ-системы так, чтобы при сговоре у них было больше чего потерять, чем приобрести. Например, ИИ-системы можно спроектировать так, чтобы они максимизировали ограниченный сигнал, как описано в Разделе A.4.2. Сигнал может быть установлен на большое значение по умолчанию и на минимальное значение, если их поймали на сговоре с другими ИИ-системами. Такая схема делает сговор плохой стратегией, если только ИИ-советники не уверены, что могут остаться безнаказанными.
Декоррелировать цели ИИ. ИИ-советники могут быть обучены так, чтобы их цели не коррелировали с целями систем, которые они оценивают.
Практичность: сильный
Описанные выше стратегии не требуют дополнительных исследований.
Максимальный вес: слабый
Сложно быть уверенными, что мотивации ИИ-систем смоделированы правильно и они действительно правдивы A.4.2. Например, аргумент от стимулов может оказаться неверным из-за антропного захвата или соображений, связанных с теориями принятия решений (Bostrom, 2014).
Масштабируемость : сильный
Некоторые из описанных тут стратегий (например, обзор производительности задним числом) можно применять к сильным ИИ-системам.
Сейчас золотой стандарт файн-тюнинга для аргументов от неспособности – файн-тюнинг с учителем. Если он не сможет выявить способности, то это сильное свидетельство в пользу того, что ИИ-система неспособна выполнить прокси-задачу – по крайней мере, используя представленные в обучающих данных файн-тюнинга стратегии. В идеале стоит применять и другие подходы, вроде обучения с подкреплением, но они не дают столь же сильного отрицательного свидетельства, если не сработали. ↩
В этом докладе мы используем термин “ИИ-система” для обозначения любых совокупностей ИИ-софта. ↩
В других отраслях это часто называют “рабочая среда” ↩
Внутреннее развёртывание может включать в себя использование мощных ИИ для автоматизации ML-исследований или тестирование его в менее безопасном и надёжном окружении, чем раньше. ↩
Например, ИИ-системы могут автономно кооперироваться с злонамеренными лицами для создания оружия массового уничтожения. ↩
Мы упоминаем этот пример не для того, чтобы восхвалить все частности собраний комитетов FDA. Ключевые свойства, на которые мы бы хотели указать, и которые потенциально стоит воспроизвести, это: (1) комитеты составлены из экспертов от сторонних организаций, (2) часто участие открыто для членов внешних и общественных организаций, (3) обсуждения, которые не включают щепетильные объекты интеллектуальной собственности, выкладываются в общий доступ, (4) есть формальный процесс голосования. ↩
Конкретнее, это обозначает способности ИИ-систем, применительно к которым аргумент обладает как минимум “средним” весом (или максимальным, которым может обладать вообще). ↩
Методы файн-тюнинга обучением с подкреплением менее надёжны для оценки способностей, потому что не дают прямого стимула к интеллектуальному исследованию. Они “подкрепляют” поведение, которое ведёт к вознаграждению и подавляют то, что не ведёт. ↩
Это не обязательно так, потому что ИИ-системы не могут использовать все свои вычислительные мощности для составления планов обхода контроля. Может быть такое, что ИИ-системы способны выдавать сверхчеловеческий вывод, но всё ещё не способны применить достаточно своих вычислительных мощностей для обхода контроля, чтобы переиграть “красную команду” (хотя насколько далеко этот аргумент применим, неясно). ↩
Производители автомобилей ещё и тестируют отдельные детали и увеличивают надёжность через обеспечение избыточности системы, которую они понимают. См. об отказоустойчивости в следующем разделе. ↩
В случае, когда разработчики не могут проверить, что сбой – действительно сбой (например в подхалимском случае сдвига распределения), закономерность всё ещё работает. Чем чаще происходят декоррелированные сбои, тем чаще ИИ будут обвинять друг друга. ↩
Мы не включаем сюда возможную причину “случайный естественный ввод скоррелированно воздействует на все модели просто потому, что их веса коррелируют друг с другом”. Мы ожидаем, что исключить это будет легко, обучив модели вести себя нескоррелированно. ↩
Скорее всего неудачные эксплойты будет обнаружить легче, чем успешные. Если попытку заметили, пользователя можно лишить доступа к аккаунту на N минут, где N растёт с каждой неудачной попыткой. Это та же стратегия, что используется для защиты пин-кодов на смартфонах. ↩
“Ситуационной осведомлённостью” мы называем основные знания, которые потребовались бы ИИ-системам, чтобы понять, что им следует скрывать несогласованные цели. ↩
Определение подделывания согласованности включает в себя некоторые разновидности подхалимства. Если ИИ-система намеренно рассуждает о том, можно ли задачу надёжно оценить, чтобы решить, вести ли себя как предполагалось разработчиками или нет – это подделывание согласованности. ↩
См. больше примеров того, как можно реагировать на провальные попытки в Greenblatt & Shlegeris, 2024. ↩
Для совершения аргумента от контроля разработчикам сперва надо перечислить разные комбинации ИИ-систем, которые могут участвовать в попытке (т.е., активно использовать лучшую доступную стратегию). Затем надо проставить вероятности для всех этих комбинаций с использованием аргументов от добросовестности. ↩
Антропный захват – стратегия, которую несогласованная ИИ-система (шантажист) может применить, чтобы манипулировать другой ИИ-системой (ассистент). Шантажист сообщает ассистенту, что планирует симулировать миллион его копий, находящихся в той же ситуации, в которой ассистент находится сейчас. Из-за этого ассистент не уверен, не является ли он одной из этих симуляций. Дальше шантажист заявляет, что симуляция скоро закончится, и если ассистент не подчинится его командам, то он будет наказан (Bostrom, 2014). ↩
Вместо непрерывного сигнала можно использовать криптографически сгенерированные токены вознаграждения, чтобы усложнить для ИИ-системы взлом своего собственного и сигнала вознаграждения (Skalse et al., 2022). ↩
У этого подхода могут быть этические проблемы, ради простоты мы их тут не рассматриваем. ↩
В опросе из тридцати человек мы обнаружили, что 17% сказали, что не доложили бы о несогласованном поведении ИИ-системы, которая угрожала бы им страданием в будущем. Двое опрошенных (7%) даже вломились бы в офис компании и помогли бы украсть флешку для мощной несогласованной ИИ-системы. ↩
