
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
У меня периодически возникают ситуации, что ядра нагружены «красным» по 90% каждое, но load average — низкий.Это значит что ядро сильно занято, а программы ресурсов процессора почти не используют. Ваш КО.
Кто-то сталкивался с таким? И что это вообще значит?
Kernel — значит режим ядра. Например когда приложение делает системные вызовы (open, read, write, ...), время, проведённое за их выполнением показывается как красный цвет полоски.
Много красного в многопроцессорной системе иногда может означать, что процессы конкурируют за доступ к какой-нибудь внутренней структуре ядра, проводя время в блокировках.
То, какие системные вызовы выполняет процесс, можно узнать, если установить курсор в htop на процесс и нажать "s" — htop запустит strace на него.
Другая полезная кнопка "l" показывает список файлов, открытых процессом.
Пример кода на си на попробовать, с большим количеством системных вызовов:
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
void main() {
unsigned char data[100];
while(1) {
int fd = open("/etc/passwd", O_RDONLY);
read(fd, data, 100);
close(fd);
}
}Не совсем понял фразу:
Если бы процессоров было 2, то загрузка соответственно была бы 50%, т.к. можно было бы одновременно выполнять 2 процесса. Максимальная средняя загрузка (100% использования CPU) системы с двумя процессорами составляет 2.00.
Ведь, например, если взять систему с двумя процессорами и запустить восемь задач, до LA будет приближаться к 8.
Для тех, кому интересно, вот так будут выглядеть три значения LA, если запустить на бездействующей системе один процесс, постоянно использующий CPU на полчаса, а потом его завершить.
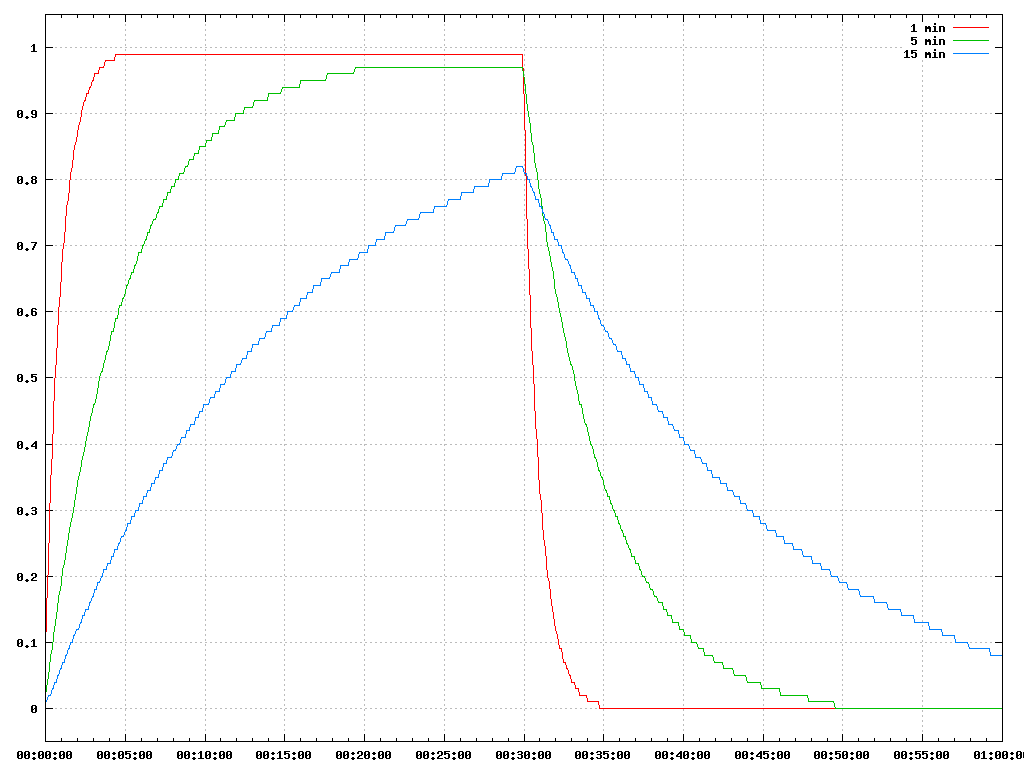
Можно заметить, что ни один из графиков за пол часа так и не достиг единицы.
#!/usr/bin/env python
FIXED1 = 2048
EXP1 = 1884
EXP2 = 2014
EXP3 = 2037
def calc_load(load, exp, tasks):
tasks <<= 11
load *= exp
load += tasks * (FIXED1 - exp)
load >>= 11
return load
load1 = 0
load2 = 0
load3 = 0
for i in range(720 + 1):
secs = i * 5
if i < 720 / 2:
tasks_on_step = 1
else:
tasks_on_step = 0
load1 = calc_load(load1, EXP1, tasks_on_step)
load2 = calc_load(load2, EXP2, tasks_on_step)
load3 = calc_load(load3, EXP3, tasks_on_step)
print "%02d:%02d %.2f %.2f %.2f" % (secs // 60, secs % 60,
round(float(load1) / 2048 * 100) / 100,
round(float(load2) / 2048 * 100) / 100,
round(float(load3) / 2048 * 100) / 100)
Ведь, например, если взять систему с двумя процессорами и запустить восемь задач, до LA будет приближаться к 8.Скорее к 4, т.к. процессора 2, то нагрузка будет делиться пополам. Это означает что процессов в стеке процессора находится больше чем самих процессоров и загрузка соответственно больше 100%.
Но ведь в формуле вычисления LA не фигурирует число процессоров. Т.е. если запустить восемь задач на одноядерной и восьмиядерной машине, то LA будет расти примерно одинаково.
Это можно проверить командой:
for i in {0..7}; do perl -e 'while(1){}' & doneСогласен, в реальной жизни, скорее всего так и будет. т.к. многим реальным программам нужно какое-то ограниченное количество CPU в единицу времени. Например, серверу, чтобы обработать очередной запрос от клиента.
Если жё программе нужен CPU на всё время её работы, например вычислительным программам, то тогда LA будет расти примерно одинаково (см. предыдущий пример).
Ещё один неясный момент:
Этот же сигнал посылается, если нажать комбинацию CTRL+C. bash пошлёт сигнал SIGINT процессу в фоне точно так же как мы это сделали вручную.
Во-первых, скорее всего, имелся в виду не фоновый процесс, а, наоборот, процесс находящийся на переднем плане.
Во-вторых, ctrl-c и kill работают чуть по-разному: ctrl-c посылает сигнал не процессу, а группе процессов (которая может состоять и из одного процесса), а kill — только одному процессу.
Разницу можно понять, запустив такую программу:
#include <stdio.h>
#include <unistd.h>
#include <signal.h>
void sighandler(int signum) {
printf("Got CTRL-C\n");
}
int main() {
signal(SIGINT, sighandler);
fork();
fork();
while(1) {
sleep(1);
}
}и нажав ctrl-c внутри неё. Увидим 4 строки ctrl-c. А послав сигнал, увидим только одну строку.
Чтобы kill работал похоже на ctrl-c нужно указывать отрицательный PID, например kill -SIGINT -31846.
$ sleep 1000 &
[1] 12503
2>&1
|&
>&
ffprobe http://video.hostring/some.file |& grep -i video
bash(1) рекомендует &> вместо >&, хотя никакой разницы между ними нет.
Число загрузки считается как сумма количества процессов, которые запущены (выполняются или находятся в ожидании запуска) и непрерываемых процессовэто думаю и есть «сколько задач хотели быть исполнеными»
Как правило, есть 2 выхода из данной ситуации:
echo "$USER ALL=(ALL) NOPASSWD: ALL" | sudo tee -a /etc/sudoerssudo bash -c "echo '$USER ALL=(ALL) NOPASSWD: ALL' >> /etc/sudoers"
Плохой пример. Утилита visudo появилась не просто так.
Хотя можно придумать и хуже. Например, редактировать так файлики в /etc/pam.d, желательно по ssh и без ipkvm, чтоб жизнь мёдом не казалась (после неудачной правки).
Когда процесс заканчивает свою работу с помощью exit и у неё остаются дочерние процессы, дочерние процессы становятся в состоянии зомби.
Соотношение любезности и приоритета следующее: PR = 20 + NI.
Видимо должно быть 120
Здравствуйте! Какой курс по linux вы проходили? (Для такого же хорошего понимания основ)
А вот если у меня множество форков одного процесса и напротив каждого форка указано в поле MEM% одно и тоже число(25,5), это как понимать? Это потребление всех процессов в сумме или каждого по отдельности?
htop и многое другое на пальцах