Привет, Хабр! 2-3 марта на Мансарде наших партнёров, компании Rambler&Co, прошел уже традиционный Data Science Weekend, на котором было множество выступлений специалистов в области работы с данными. В рамках этой статьи расскажем вам о самых интересных моментах первого дня нашей конференции, когда все внимание было уделено практике использования алгоритмов машинного обучения, управлению коллективами и проведению соревнований в области Data Science.

Открыть Data Science Weekend 2018 выпала честь выпускнику нашей программы «Специалист по большим данным» Роману Смирнову из компании VectorX, которая занимается процессами распространения информации в компании и конфигурацией информационного поля. В рамках выступления Роман рассказал о том, почему с командой data scientist-ов так сложно работать и как сделать их работу максимально эффективной.
Исходя из моего опыта, можно выделить 4 основные проблемы, с которыми сталкивается компания при работе с data scientist-ами (будем называть их экспертами):
Проблема: непредсказуемая производительность, вызванная высоким спросом на экспертизу. Эксперт принадлежит не вам, а обществу, поскольку он ученый и использует свои знания, чтобы сделать всех нас здоровее и богаче. Получается, что всего его хотят, а ему на всех наплевать. Из этого и возможные проблемы с мотивацией и эффективностью труда.
Решение: во-первых, всегда должна быть альтернатива в виде другого эксперта, существование которого должно оставаться в секрете. Во-вторых, необходимо вести учет всех проектов, собирать статистику, чтобы давать эксперту обратную связь и поддерживать в нем ощущение собственной ценности. Наконец, оказалось, что CRM хорош не только в отношении клиентов, но и при работе с распределенными командами.
Проблема: конфликт мотиваций. Data scientist — это человек, который пытается всех убедить, что он является первооткрывателем, занимается важнейшими вопросами, пытается открыть тайну философского камня. К сожалению, ему не чужды и базовые физиологические мотивы, и этот конфликт не дает ему расставить приоритеты, а вам — заключить с ним выгодное соглашение.
Решение: этот дуализм можно использовать в своих целях. Если эксперт говорит, что ему не хватает денег, можно призвать к его гуманистическим ценностям и сказать: «Дружище, ты же ученый!». И наоборот: стоит напомнить ему, что он человек в статусе и не стоит ходить который год в костюме с заплатками на локтях.

Проблема: спекуляция репутацией. Часто бывает, что бесспорно опытный теоретик не способен решить тривиальную практическую задачу. Следовательно, он не может трезво оценить трудоемкость проекта со всеми вытекающими: проваленные сроки, потеря мотивации командой, непомерные расходы и т.д.
Решение: запрашивайте портфолио у потенциального руководителя проекта и не стесняйтесь потратить деньги на code review, чтобы подтвердить или развеять опасения.
Проблема: скрытые мотивы. Эксперт, будучи ученым, хочет стать над обществом, а не в его рядах. Следовательно, у него всегда есть стремление популяризовать свое мнение в как можно более широком кругу областей знаний, что, однако, плохо соотносится с коммерческими выгодами проекта: если репутации эксперта в компании что-то угрожает, то есть риск его потерять.
Решение: сегодня наука очень тесно сплелась с бизнесом: еще пару лет назад никто и не думал, что маркетинг будет распространяться на научные статьи. Финансируйте написание научных статей в соавторстве — для наукоемких проектов это отличный маркетинговый ход.
А в случае угрозы потери экспертизы привлекайте эксперта из конкурирующей лаборатории. Такой поступок может задеть первого ученого и стимулирует его к активным действиям, чтобы утереть нос конкуренту.
Затем настала очередь еще одного нашего выпускника, Александра Ульянова, который является Data science executive директором в Сбербанке. На примере проекта по управлению наличностью в сети банкоматов по всей стране он рассказал о том, почему вместо того, чтобы сразу набрасываться на сложные модели и пытаться их строить, необходимо сначала посидеть и основательно провести статистический анализ данных. Это чрезвычайно важно при работе с реальными данными, поскольку в них зачастую имеется большое количество пропусков, выбросов, неверных измерений и банальных ошибок записи информации, поэтому каждый data scientist должен, к примеру, владеть статистическими методами выявления аномалий или хотя бы элементарно уметь посмотреть на количество нулей в датасете, максимальные и минимальные значения фич. Принцип «garbage in — garbage out» никто не отменял.

Более подробно о выступлении Александра и кейсе по управлению сети банкоматов вы сможете в скором времени прочитать в корпоративном блоге Сбербанка на Хабре. Ждите!
Далее Артем Пичугин, Руководитель образовательных программ по работе с данными у нас в Newprolab, представил новый подход к проведению соревнований по машинному обучению, который будет опробован на грядущей программе «Специалист по большим данным 8.0». Старт программы 22 марта.
Все началось в 2009 году с соревнования от Netflix, в котором победитель получил 1 млн долл., что придало популярности таким мероприятиям, появился Kaggle и все это начало стремительно развиваться. Однако оказалось, что с самого начала все пошло не так: в 2012 году выяснилось, что решение победителя конкурса от Netflix попросту невозможно было внедрить в продакшн, оно было слишком сложным и тяжелым.
Прошло несколько лет, и что мы видим? На дворе 2018 год, а люди все еще пытаются делать суперсложные модели, строят огромные ансамбли. И это все больше и больше напоминает спорт высоких достижений.
Само собой, на программе мы также использовали этот подход, ранжируя студентов по определенной метрике, вне зависимости от сложности их решения. Однако осознав, насколько все эти решения могут быть далеки от бизнеса, мы применяем совершенно новый подход к соревнованию на программе.
Теперь итоговый рейтинг будет учитывать лишь те решения, которые подходят под SLA, то есть укладываются в какой-то разумный промежуток времени. Причем в отличии от некоторых других подходов будет учитываться не общее время обучения модели, а то, насколько быстро рассчитывается прогноз по одному элементу тестовой выборки.
Раньше человек, сделав модель в Jupyter Notebook, составлял прогноз по тестовой выборке, сохранял, отправлял и рассчитывалась итоговая метрика. Теперь же ему нужно эту модель еще и упаковать в Docker, то есть сделать маленькую «апишку», получив файл формата JSON. Таким образом, мы станем ближе к продакшну и призываем всех, кто организовывает соревнования и хакатоны, двигаться в эту сторону.
Кстати, в ближайшие несколько месяцев мы будем проводить свой хакатон. Подписывайтесь на нас в Facebook и Telegram, чтобы не пропустить информацию!
Теперь расскажем о групповом выступлении специалистов по машинному обучению из Rambler&Co, которые разобрали интересный кейс по использованию компьютерного зрения в кинозалах при распознавании количества, пола и возраста посетителей кинотеатров.
Перед нами была поставлена задача оценить состав аудитории на сеансах в сети кинотеатров, чтобы отчитываться перед рекламодателями, которым важно понимать социально-демографический состав аудитории и которые дают нам деньги на ту или иную рекламу, показываемую перед сеансами.
Начнем с источников данных. Казалось бы, у нас есть Рамблер-Касса, поэтому имеем много информации о пользователях, однако по этим данным оценка будет на самом деле смещенной. Для семейного просмотра билеты покупает папа или мама, если это пара, то скорее всего их купит парень и так далее. Поэтому мы смогли найти другое решение: в каждом зале есть камера, которая видит всех, кто сидит в кинозале:
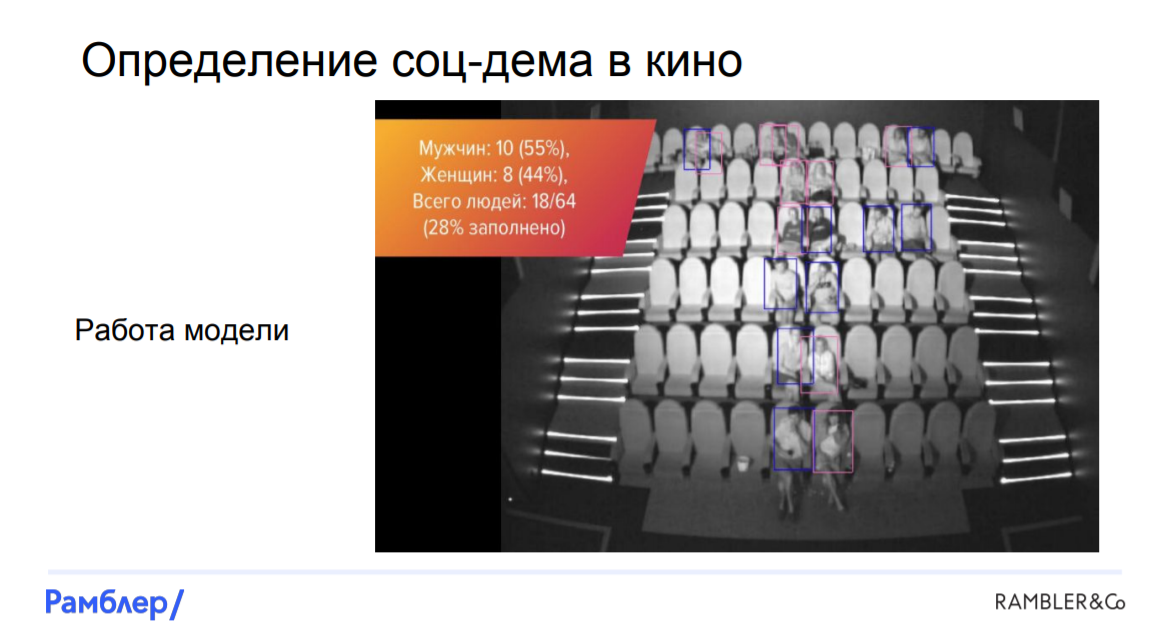
Забегая вперед, скажем, что нам удалось построить модель, которая по фотографиям оценивает, кто где сидит, пол и возраст посетителей. Количество людей мы смогли определять практически со 100% точностью, отличать мужчин от женщин — с 90%, а распознавать детишек с чуть меньшей вероятностью. Как нам это удалось?
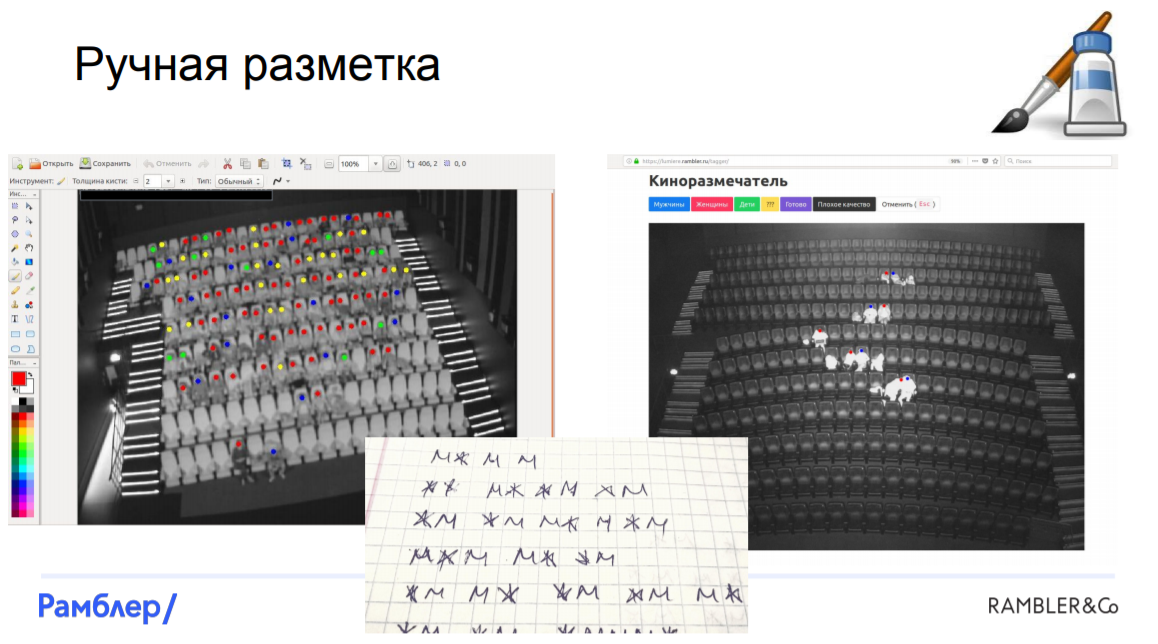
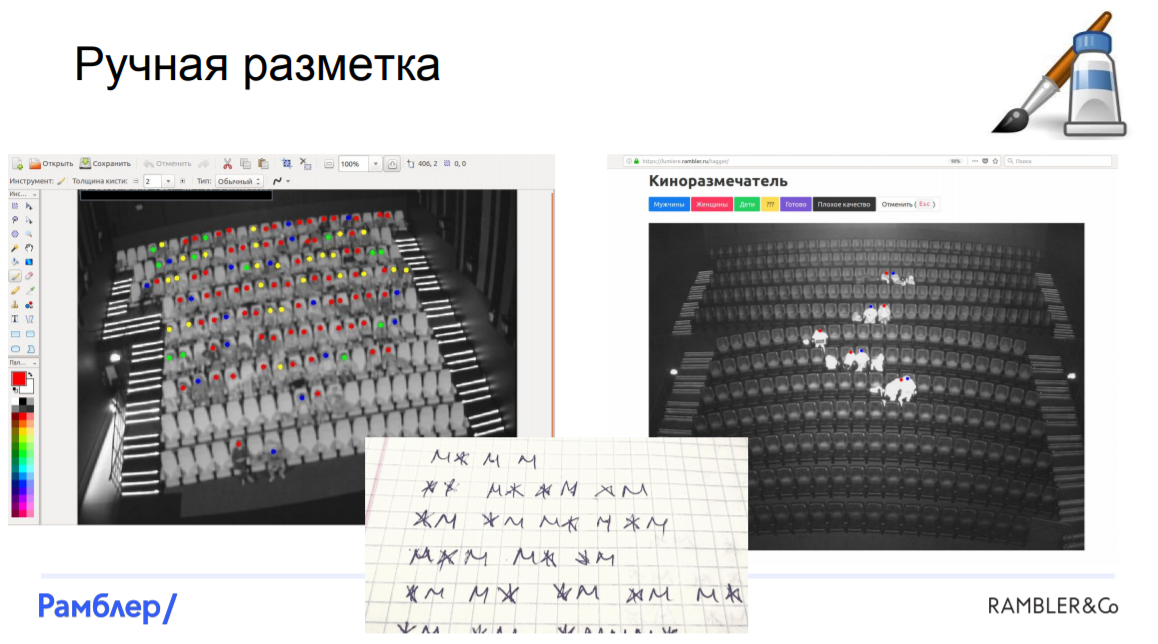
Разметка данных. С самого начала мы столкнулись с кучей проблем. В первую очередь, очень трудно найти хотя бы два похожих кинозала, они все разные, с разным масштабом и перспективой. Есть камеры, которые захватывают не весь зал, снимают под углом. Добавим к этому различную освещенность зала в зависимости от того, что происходит на экране на момент съемки, и получается, что у нас есть данные разного качества, которые разметить автоматически попросту невозможно.
Нам пришлось прибегнуть к ручной разметке. Это было очень дорого, тяжело, занимало большую часть рабочего времени, поэтому мы решили нанять команду «элитных размечателей» со стороны — людей, которые бы нормально и обстоятельно осуществляли разметку данных. Конечно, человеческий фактор исключить невозможно, было некоторое количество ошибок, но в итоге нам все-таки удалось разметить все фотографии и мы были готовы строить модели.
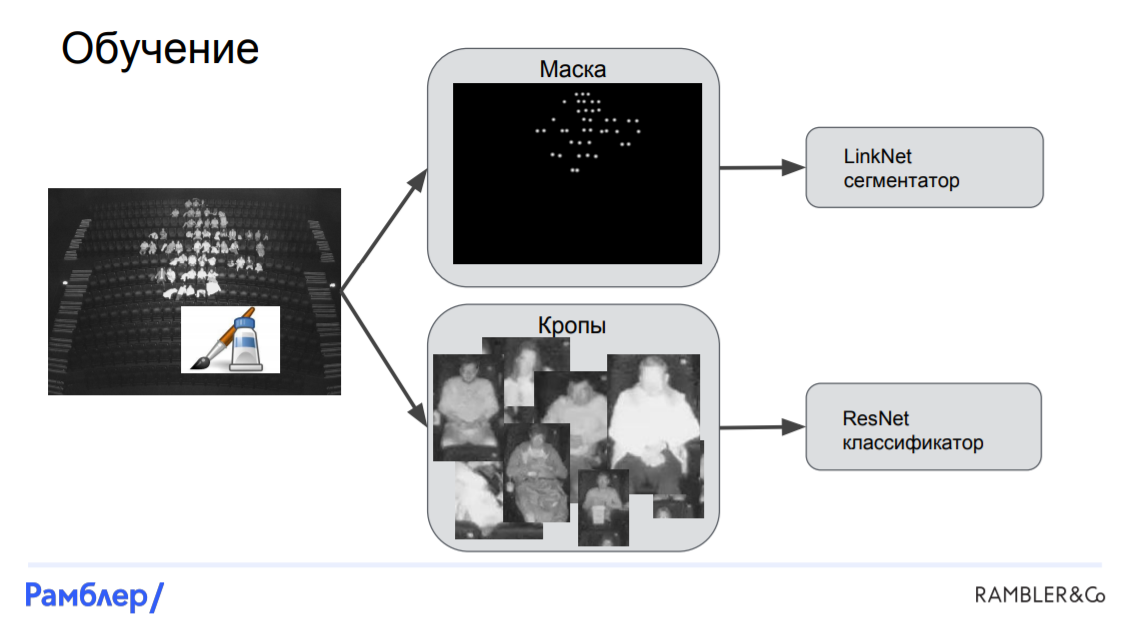
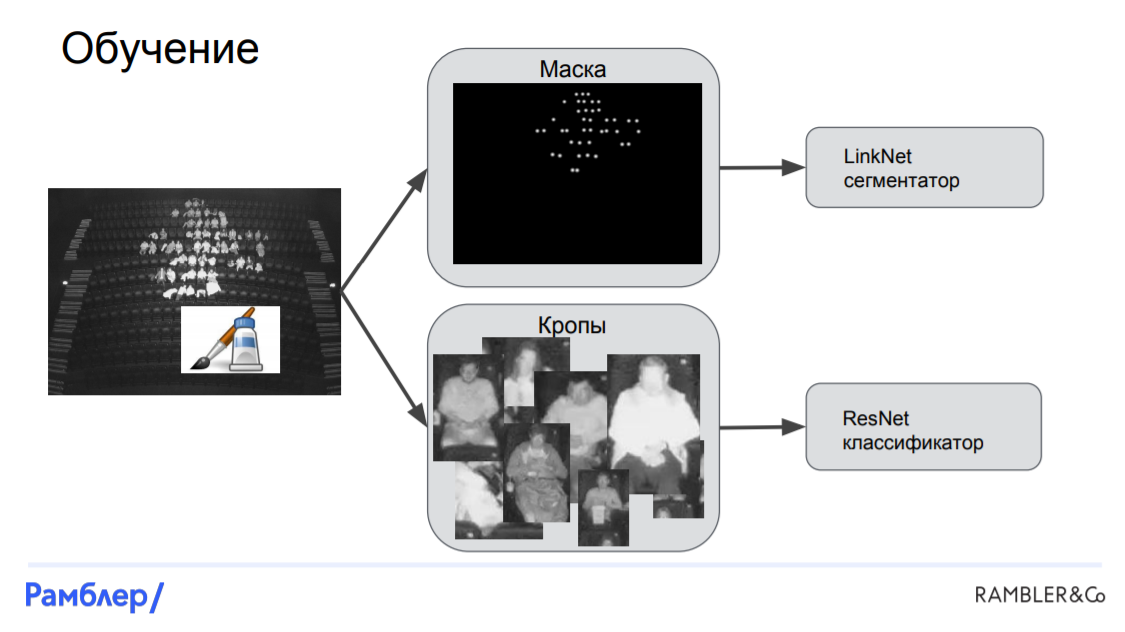
Модель LinkNet-ResNet. Это была наша первая модель, и она показала достаточно высокое качество. Она состояла из трех основных частей: сегментатора (LinkNet), который находит маску расположения голов на картинке, локализатора, который по маске находит координаты головы и bounding box для каждого человека, и классификатора (ResNet), который на основе кропа bounding box-a, определяет, кто же сидит на этой картинке: мужчина, женщина или ребенок.
Обучение начинается с размеченного снимка. По этому снимку мы получаем маску, накладывая белое гауссовое пятно на голову каждого человека. После этого режем картинку на кропы, используя bounding box-ы вокруг каждой головы, а после этого подаем все полученное в наши сети. Маска вместе с исходным изображением подается в сегментатор и получается LinkNet, а кропы вместе с целевыми таргетами подаются в ResNet.
Предсказания же делаются немного по-другому. Подаем исходное изображение в LinkNet, получаем маску. Ее подаем в локализатор, который находит координаты головы и bounding box-ы. Затем по ним вырезаются кропы, которые подаются в ResNet и получаются выходы нейронной сети, на основе которых мы можем получить всю необходимую аналитику: количество людей на сеансе и социально-демографический состав.
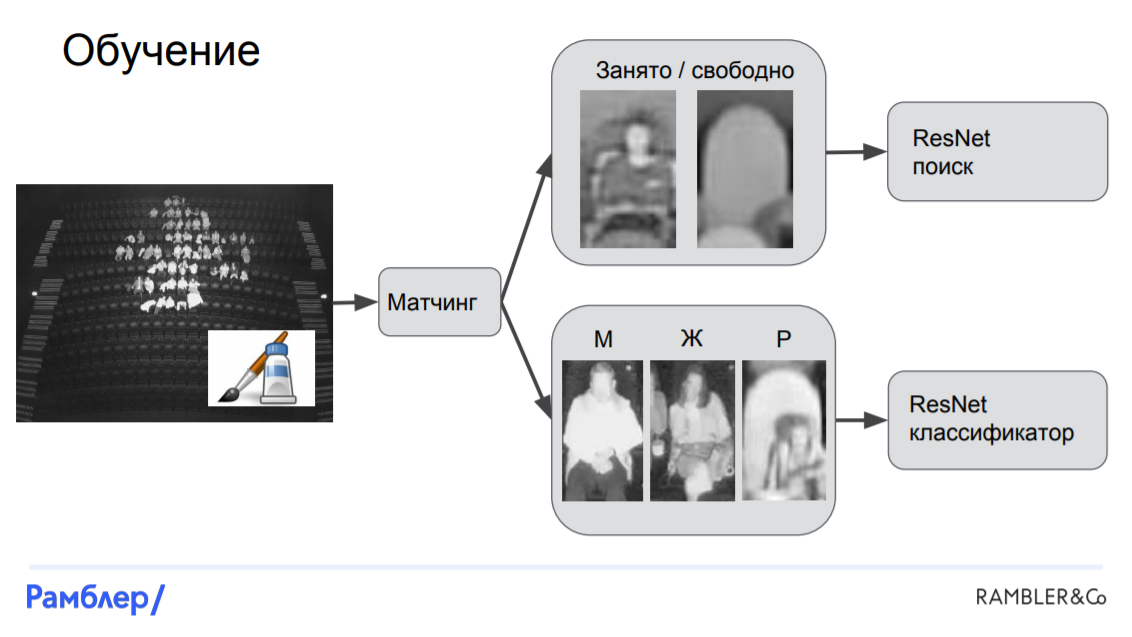
Модель «Креслитель». В предыдущей модели мы никак не использовали априорное знание о том, что в залах есть кресла, которые прибиты к полу, и на снимках они всегда оказываются на одном и том же месте. К тому же, когда люди приходят в зал они, как правило, оказываются в креслах. С учетом этой информации мы и будем строить модель.
Во-первых, нам нужно научить модель распознавать, где же на снимке находятся кресла, и тут мы снова должны прибегнуть к ручной разметке. В каждое кресло каждого зала была проставлена метка в том месте, где бы находилась голова среднестатистического человека, если бы он сидел в кресле.
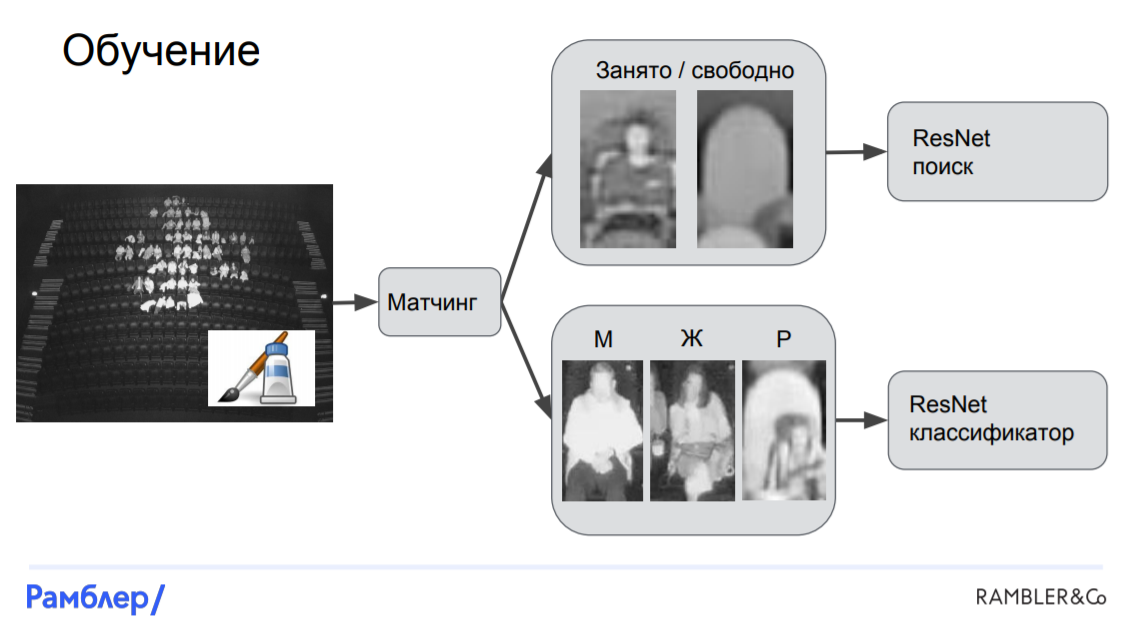
Перейдем к модели. Во-первых, нам нужно осуществить матчинг: сопоставить головы с креслами, а затем для каждого кресла определить, занято оно или свободно, а если занято, то кем именно. После чего мы можем вырезать участки изображений, соответствующие этим креслам и обучать на них две модели: одна будет распознавать, занято ли кресло, а вторая — классифицировать зрителей на 3 категории. Обе модели основаны на нейронной сети ResNet. Таким образом, отличие «Креслителя» от LinkNet-ResNet заключается в том, что в ней все кропы фиксированы, они привязаны к расположению кресел на снимке, тогда как в первой модели они вырезались произвольно — где голова, там и режем.
Очередным выступающим в этот насыщенный день был Артем Просветов — Senior Data Scientist в компании CleverData, которая занимается различными решениями для управления данными. Его проект заключался в оптимизации маркетинговых коммуникаций для beauty-индустрии, о чем он и рассказал.

Чтобы понять, кому, что и когда рассылать, необходимо обладать знанием того, какая у человека история покупок, что ему нужно сейчас, в какой момент к нему обращаться и через какой канал. Причем эту информацию можно получить не только из самой истории покупок, но и из того, как человек ведет себя на сайте, какие ссылки кликает, какие рассылки открывает и так далее. Главный вопрос: как из этой последовательности действий получить фичи для модели?
Наиболее очевидным способом представляется закодировать эти последовательности событий следующим образом:

Все просто: действие кодируется единицей, пропуск действия — нулем. Однако здесь возникает проблема: разные люди имеют разное количество действий. Поэтому следующим логичным шагом будет задать вектора фиксированной длины, равной продолжительности действий человека с самой долгой историей.
Также стоит отметить, что такая кодировка не учитывает время, прошедшее между соседними действиями, что может быть очень важно. Следовательно, в качестве дополнительного вектора мы добавляем разницу во времени между событиями, причем, чтобы не было значений в десятки тысяч секунд, логарифмируем этот вектор. Кстати, тогда распределение будет похоже на логнормальное.

Наконец, фичи получены и мы готовы обучать модель, а именно нейронную сеть, которая является наиболее популярным методом обработки серии событий. Модель, состоящая из автоэнкодеров и нескольких слоев LSTM-сети показала сравнительно высокое качество — метрика ROC-AUC оказалась равна 0,87.
Завершал первый день конференции Артем Трунов — еще один наш выпускник и координатор программы «Специалист по большим данным 8.0». Артем рассказал о том, как ему удалось выиграть соревнование по машинному обучению от платформы TrainMyData.
В рамках соревнования необходимо было прогнозировать временные ряды недельных продаж компании Ascott Group. Конечно, сегодня наиболее популярным методом прогнозирования временных рядов являются нейронные сети, однако это не значит, что классические эконометрические алгоритмы не работают. Именно они помогли мне выиграть этот конкурс, поэтому я хотел бы вам напомнить о каждом из них:

Немного отзывов о мероприятии:
«Было очень полезно и интересно узнать как заявленные технологии используются в реальных проектах.» — Толмачев Андрей, ООО “АССИ”.
«Благодарю за хорошее мероприятие: правильный рабочий формат, достойная подготовка, хороший состав практиков-спикеров и очень много полезной информации.» — Сорокин Максим, руководитель группы R&D, НТЦ “Вулкан”.
Видеозаписи всех выступлений вы можете посмотреть на нашей странице в Facebook.
В скором времени мы опубликуем обзор второго дня Data Science Weekend 2018, когда упор был сделан на Data Engineering, использование различных инструментов инженера данных для нужд data-платформ, ETL, сервисов подсказок при поиске и многое другое. Stay tuned!

VectorX
Открыть Data Science Weekend 2018 выпала честь выпускнику нашей программы «Специалист по большим данным» Роману Смирнову из компании VectorX, которая занимается процессами распространения информации в компании и конфигурацией информационного поля. В рамках выступления Роман рассказал о том, почему с командой data scientist-ов так сложно работать и как сделать их работу максимально эффективной.
Исходя из моего опыта, можно выделить 4 основные проблемы, с которыми сталкивается компания при работе с data scientist-ами (будем называть их экспертами):
Проблема: непредсказуемая производительность, вызванная высоким спросом на экспертизу. Эксперт принадлежит не вам, а обществу, поскольку он ученый и использует свои знания, чтобы сделать всех нас здоровее и богаче. Получается, что всего его хотят, а ему на всех наплевать. Из этого и возможные проблемы с мотивацией и эффективностью труда.
Решение: во-первых, всегда должна быть альтернатива в виде другого эксперта, существование которого должно оставаться в секрете. Во-вторых, необходимо вести учет всех проектов, собирать статистику, чтобы давать эксперту обратную связь и поддерживать в нем ощущение собственной ценности. Наконец, оказалось, что CRM хорош не только в отношении клиентов, но и при работе с распределенными командами.
Проблема: конфликт мотиваций. Data scientist — это человек, который пытается всех убедить, что он является первооткрывателем, занимается важнейшими вопросами, пытается открыть тайну философского камня. К сожалению, ему не чужды и базовые физиологические мотивы, и этот конфликт не дает ему расставить приоритеты, а вам — заключить с ним выгодное соглашение.
Решение: этот дуализм можно использовать в своих целях. Если эксперт говорит, что ему не хватает денег, можно призвать к его гуманистическим ценностям и сказать: «Дружище, ты же ученый!». И наоборот: стоит напомнить ему, что он человек в статусе и не стоит ходить который год в костюме с заплатками на локтях.

Проблема: спекуляция репутацией. Часто бывает, что бесспорно опытный теоретик не способен решить тривиальную практическую задачу. Следовательно, он не может трезво оценить трудоемкость проекта со всеми вытекающими: проваленные сроки, потеря мотивации командой, непомерные расходы и т.д.
Решение: запрашивайте портфолио у потенциального руководителя проекта и не стесняйтесь потратить деньги на code review, чтобы подтвердить или развеять опасения.
Проблема: скрытые мотивы. Эксперт, будучи ученым, хочет стать над обществом, а не в его рядах. Следовательно, у него всегда есть стремление популяризовать свое мнение в как можно более широком кругу областей знаний, что, однако, плохо соотносится с коммерческими выгодами проекта: если репутации эксперта в компании что-то угрожает, то есть риск его потерять.
Решение: сегодня наука очень тесно сплелась с бизнесом: еще пару лет назад никто и не думал, что маркетинг будет распространяться на научные статьи. Финансируйте написание научных статей в соавторстве — для наукоемких проектов это отличный маркетинговый ход.
А в случае угрозы потери экспертизы привлекайте эксперта из конкурирующей лаборатории. Такой поступок может задеть первого ученого и стимулирует его к активным действиям, чтобы утереть нос конкуренту.
Сбербанк
Затем настала очередь еще одного нашего выпускника, Александра Ульянова, который является Data science executive директором в Сбербанке. На примере проекта по управлению наличностью в сети банкоматов по всей стране он рассказал о том, почему вместо того, чтобы сразу набрасываться на сложные модели и пытаться их строить, необходимо сначала посидеть и основательно провести статистический анализ данных. Это чрезвычайно важно при работе с реальными данными, поскольку в них зачастую имеется большое количество пропусков, выбросов, неверных измерений и банальных ошибок записи информации, поэтому каждый data scientist должен, к примеру, владеть статистическими методами выявления аномалий или хотя бы элементарно уметь посмотреть на количество нулей в датасете, максимальные и минимальные значения фич. Принцип «garbage in — garbage out» никто не отменял.

Более подробно о выступлении Александра и кейсе по управлению сети банкоматов вы сможете в скором времени прочитать в корпоративном блоге Сбербанка на Хабре. Ждите!
New Professions Lab
Далее Артем Пичугин, Руководитель образовательных программ по работе с данными у нас в Newprolab, представил новый подход к проведению соревнований по машинному обучению, который будет опробован на грядущей программе «Специалист по большим данным 8.0». Старт программы 22 марта.
Все началось в 2009 году с соревнования от Netflix, в котором победитель получил 1 млн долл., что придало популярности таким мероприятиям, появился Kaggle и все это начало стремительно развиваться. Однако оказалось, что с самого начала все пошло не так: в 2012 году выяснилось, что решение победителя конкурса от Netflix попросту невозможно было внедрить в продакшн, оно было слишком сложным и тяжелым.
Прошло несколько лет, и что мы видим? На дворе 2018 год, а люди все еще пытаются делать суперсложные модели, строят огромные ансамбли. И это все больше и больше напоминает спорт высоких достижений.
Само собой, на программе мы также использовали этот подход, ранжируя студентов по определенной метрике, вне зависимости от сложности их решения. Однако осознав, насколько все эти решения могут быть далеки от бизнеса, мы применяем совершенно новый подход к соревнованию на программе.
Теперь итоговый рейтинг будет учитывать лишь те решения, которые подходят под SLA, то есть укладываются в какой-то разумный промежуток времени. Причем в отличии от некоторых других подходов будет учитываться не общее время обучения модели, а то, насколько быстро рассчитывается прогноз по одному элементу тестовой выборки.
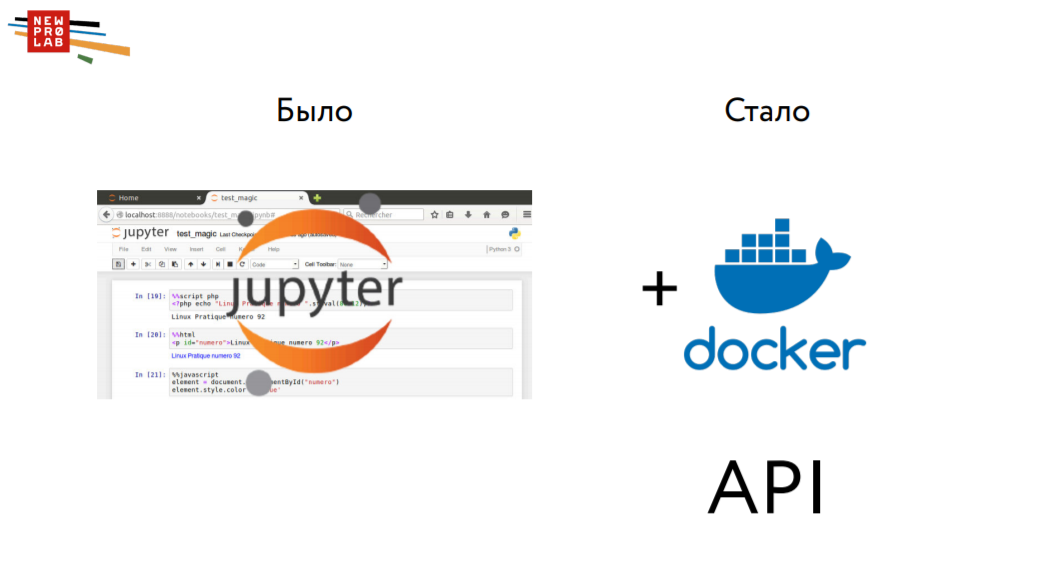
Раньше человек, сделав модель в Jupyter Notebook, составлял прогноз по тестовой выборке, сохранял, отправлял и рассчитывалась итоговая метрика. Теперь же ему нужно эту модель еще и упаковать в Docker, то есть сделать маленькую «апишку», получив файл формата JSON. Таким образом, мы станем ближе к продакшну и призываем всех, кто организовывает соревнования и хакатоны, двигаться в эту сторону.
Кстати, в ближайшие несколько месяцев мы будем проводить свой хакатон. Подписывайтесь на нас в Facebook и Telegram, чтобы не пропустить информацию!
Rambler&Co
Теперь расскажем о групповом выступлении специалистов по машинному обучению из Rambler&Co, которые разобрали интересный кейс по использованию компьютерного зрения в кинозалах при распознавании количества, пола и возраста посетителей кинотеатров.
Перед нами была поставлена задача оценить состав аудитории на сеансах в сети кинотеатров, чтобы отчитываться перед рекламодателями, которым важно понимать социально-демографический состав аудитории и которые дают нам деньги на ту или иную рекламу, показываемую перед сеансами.
Начнем с источников данных. Казалось бы, у нас есть Рамблер-Касса, поэтому имеем много информации о пользователях, однако по этим данным оценка будет на самом деле смещенной. Для семейного просмотра билеты покупает папа или мама, если это пара, то скорее всего их купит парень и так далее. Поэтому мы смогли найти другое решение: в каждом зале есть камера, которая видит всех, кто сидит в кинозале:
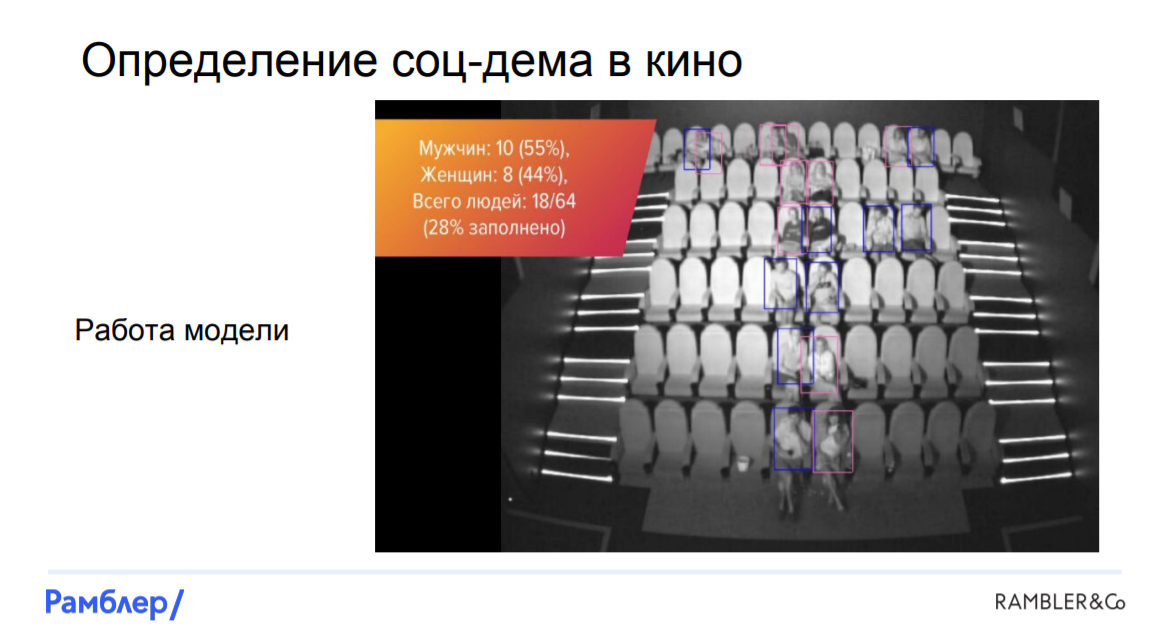
Забегая вперед, скажем, что нам удалось построить модель, которая по фотографиям оценивает, кто где сидит, пол и возраст посетителей. Количество людей мы смогли определять практически со 100% точностью, отличать мужчин от женщин — с 90%, а распознавать детишек с чуть меньшей вероятностью. Как нам это удалось?
Разметка данных. С самого начала мы столкнулись с кучей проблем. В первую очередь, очень трудно найти хотя бы два похожих кинозала, они все разные, с разным масштабом и перспективой. Есть камеры, которые захватывают не весь зал, снимают под углом. Добавим к этому различную освещенность зала в зависимости от того, что происходит на экране на момент съемки, и получается, что у нас есть данные разного качества, которые разметить автоматически попросту невозможно.
Нам пришлось прибегнуть к ручной разметке. Это было очень дорого, тяжело, занимало большую часть рабочего времени, поэтому мы решили нанять команду «элитных размечателей» со стороны — людей, которые бы нормально и обстоятельно осуществляли разметку данных. Конечно, человеческий фактор исключить невозможно, было некоторое количество ошибок, но в итоге нам все-таки удалось разметить все фотографии и мы были готовы строить модели.
Модель LinkNet-ResNet. Это была наша первая модель, и она показала достаточно высокое качество. Она состояла из трех основных частей: сегментатора (LinkNet), который находит маску расположения голов на картинке, локализатора, который по маске находит координаты головы и bounding box для каждого человека, и классификатора (ResNet), который на основе кропа bounding box-a, определяет, кто же сидит на этой картинке: мужчина, женщина или ребенок.
Обучение начинается с размеченного снимка. По этому снимку мы получаем маску, накладывая белое гауссовое пятно на голову каждого человека. После этого режем картинку на кропы, используя bounding box-ы вокруг каждой головы, а после этого подаем все полученное в наши сети. Маска вместе с исходным изображением подается в сегментатор и получается LinkNet, а кропы вместе с целевыми таргетами подаются в ResNet.
Предсказания же делаются немного по-другому. Подаем исходное изображение в LinkNet, получаем маску. Ее подаем в локализатор, который находит координаты головы и bounding box-ы. Затем по ним вырезаются кропы, которые подаются в ResNet и получаются выходы нейронной сети, на основе которых мы можем получить всю необходимую аналитику: количество людей на сеансе и социально-демографический состав.
Модель «Креслитель». В предыдущей модели мы никак не использовали априорное знание о том, что в залах есть кресла, которые прибиты к полу, и на снимках они всегда оказываются на одном и том же месте. К тому же, когда люди приходят в зал они, как правило, оказываются в креслах. С учетом этой информации мы и будем строить модель.
Во-первых, нам нужно научить модель распознавать, где же на снимке находятся кресла, и тут мы снова должны прибегнуть к ручной разметке. В каждое кресло каждого зала была проставлена метка в том месте, где бы находилась голова среднестатистического человека, если бы он сидел в кресле.
Перейдем к модели. Во-первых, нам нужно осуществить матчинг: сопоставить головы с креслами, а затем для каждого кресла определить, занято оно или свободно, а если занято, то кем именно. После чего мы можем вырезать участки изображений, соответствующие этим креслам и обучать на них две модели: одна будет распознавать, занято ли кресло, а вторая — классифицировать зрителей на 3 категории. Обе модели основаны на нейронной сети ResNet. Таким образом, отличие «Креслителя» от LinkNet-ResNet заключается в том, что в ней все кропы фиксированы, они привязаны к расположению кресел на снимке, тогда как в первой модели они вырезались произвольно — где голова, там и режем.
CleverData
Очередным выступающим в этот насыщенный день был Артем Просветов — Senior Data Scientist в компании CleverData, которая занимается различными решениями для управления данными. Его проект заключался в оптимизации маркетинговых коммуникаций для beauty-индустрии, о чем он и рассказал.

Чтобы понять, кому, что и когда рассылать, необходимо обладать знанием того, какая у человека история покупок, что ему нужно сейчас, в какой момент к нему обращаться и через какой канал. Причем эту информацию можно получить не только из самой истории покупок, но и из того, как человек ведет себя на сайте, какие ссылки кликает, какие рассылки открывает и так далее. Главный вопрос: как из этой последовательности действий получить фичи для модели?
Наиболее очевидным способом представляется закодировать эти последовательности событий следующим образом:

Все просто: действие кодируется единицей, пропуск действия — нулем. Однако здесь возникает проблема: разные люди имеют разное количество действий. Поэтому следующим логичным шагом будет задать вектора фиксированной длины, равной продолжительности действий человека с самой долгой историей.
Также стоит отметить, что такая кодировка не учитывает время, прошедшее между соседними действиями, что может быть очень важно. Следовательно, в качестве дополнительного вектора мы добавляем разницу во времени между событиями, причем, чтобы не было значений в десятки тысяч секунд, логарифмируем этот вектор. Кстати, тогда распределение будет похоже на логнормальное.

Наконец, фичи получены и мы готовы обучать модель, а именно нейронную сеть, которая является наиболее популярным методом обработки серии событий. Модель, состоящая из автоэнкодеров и нескольких слоев LSTM-сети показала сравнительно высокое качество — метрика ROC-AUC оказалась равна 0,87.
TrainMyData
Завершал первый день конференции Артем Трунов — еще один наш выпускник и координатор программы «Специалист по большим данным 8.0». Артем рассказал о том, как ему удалось выиграть соревнование по машинному обучению от платформы TrainMyData.
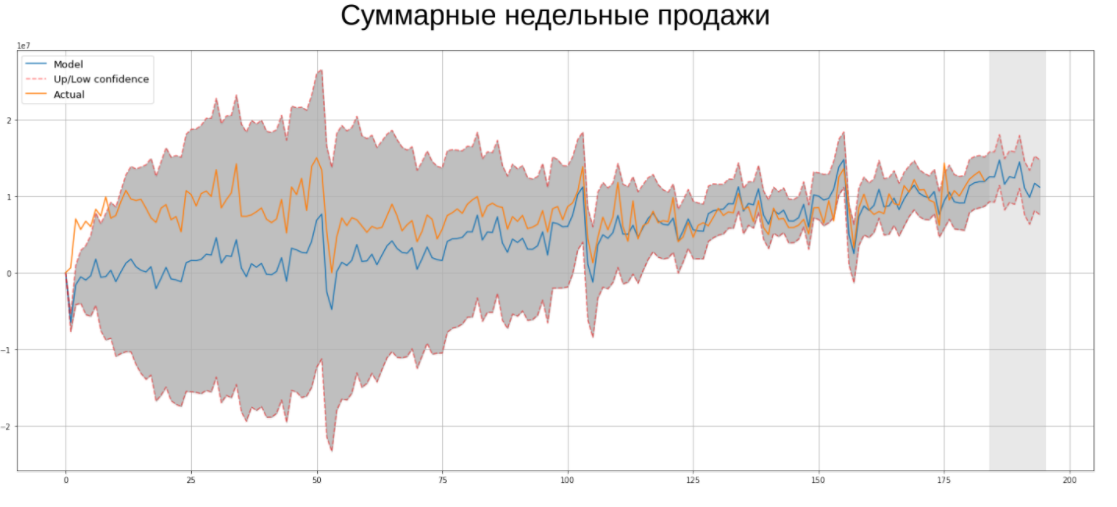
В рамках соревнования необходимо было прогнозировать временные ряды недельных продаж компании Ascott Group. Конечно, сегодня наиболее популярным методом прогнозирования временных рядов являются нейронные сети, однако это не значит, что классические эконометрические алгоритмы не работают. Именно они помогли мне выиграть этот конкурс, поэтому я хотел бы вам напомнить о каждом из них:
- Экспоненциальное сглаживание. Является одним из простейших методов прогнозирования временных рядов, имеет короткую память, поскольку поздним наблюдениям присваивается больший вес.
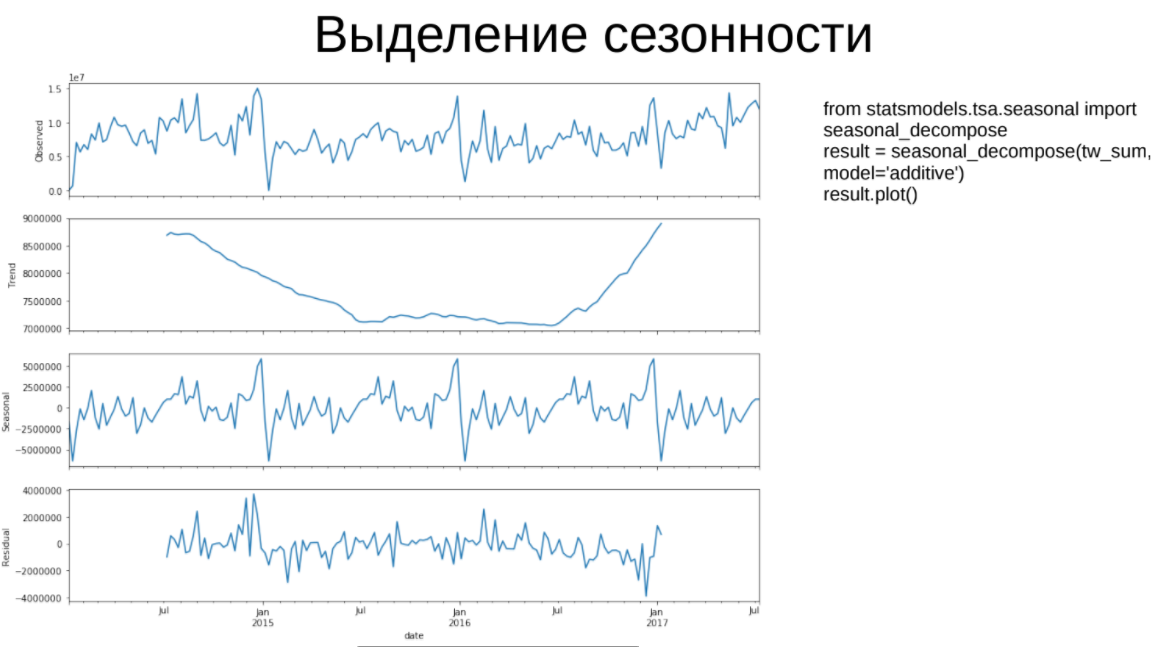
- Выделение сезонности. В рамках данного алгоритма временной ряд раскладывается на 3 составляющих: тренд, сезонную компоненту и остатки, которые должны быть похожи на «белый шум».
- Модель Хольта-Уинтерса. Представляет собой тройное экспоненциальное сглаживание: по исходному ряду, тренду и сезонной компоненте.
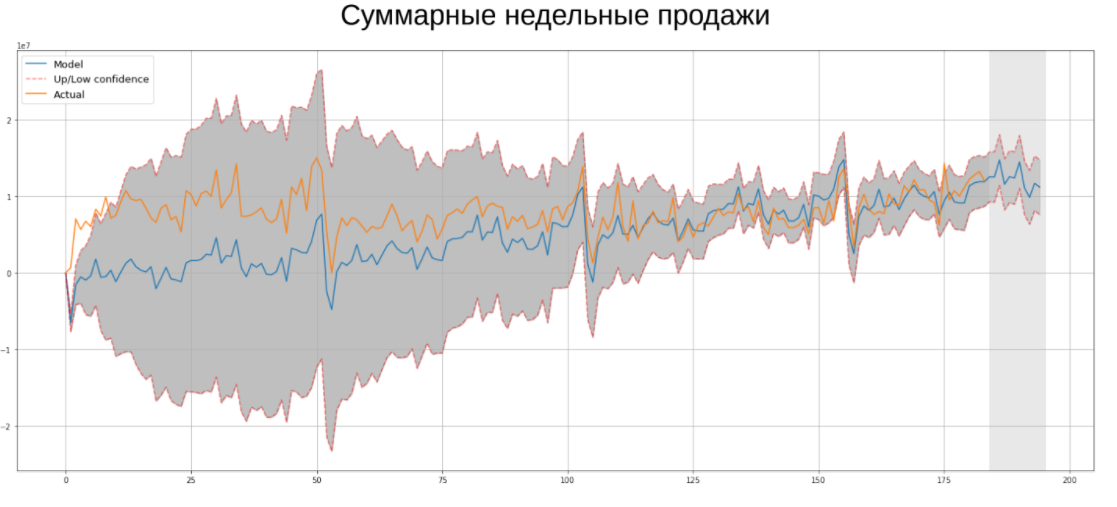
- (S)ARIMA. ARIMA является авторегрессионной моделью, которая обучается на лагах целевой переменной. Лаги нужны, чтобы привести ряд к стационарному (у которого среднее, дисперсия и ковариация не зависят от времени). Модификацией алгоритма является SARIMA, которая позволяет учитывать сезонность в данных. Преимущество ARIMA перед нейронными сетями заключается в небольшом количестве параметров для обучения, она менее склонна к переобучению. Также это значит, что параметры можно быстро и эффективно перебирать по сетке до тех пор, пока информационный критерий Акаике (AIC) не будет минимален.
Немного отзывов о мероприятии:
«Было очень полезно и интересно узнать как заявленные технологии используются в реальных проектах.» — Толмачев Андрей, ООО “АССИ”.
«Благодарю за хорошее мероприятие: правильный рабочий формат, достойная подготовка, хороший состав практиков-спикеров и очень много полезной информации.» — Сорокин Максим, руководитель группы R&D, НТЦ “Вулкан”.
Видеозаписи всех выступлений вы можете посмотреть на нашей странице в Facebook.
В скором времени мы опубликуем обзор второго дня Data Science Weekend 2018, когда упор был сделан на Data Engineering, использование различных инструментов инженера данных для нужд data-платформ, ETL, сервисов подсказок при поиске и многое другое. Stay tuned!
