
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Зеркалирование диска с важными данными теперь считается игрушкой для богатых?
А почему не смотрите в сторону облачных хранилищ?
Сейчас они стоят копейки, а стабильности и простоты добавляют в разы больше. Как правило всегда есть "еще один ноутбук", "вон тот старенький ПиСи", "простенький смартфон" и тд, которые позволят получить доступ к необходимым данным "прямо здесь и сейчас".
Ограничений такого подхода, на мой взгляд, два:
IMHO, RAID в текущих реалиях нужен только для машинок, которые должны быть с максимальной доступностью — сервера (но тут рейда недостаточно — должны быть более сложные системы отказоустойчивости), регистраторы систем видеонаблюдения и тд. Явно речь идет не про домашнюю машинку.
Но как быть с потерей суток, если например это был дедлайн по крупному заказу?
А вот облачное хранение остановит всю работу на сутки.
Я упоминал про обрыв входа в город.
когда у меня дома развалился этот самый RAID-1 по причине смерти одного дискаКакой-то у вас RAID1 неправильный.
А в чём смысл использования встроенки?
Флешки кингстона уходили только так. Самые надежные флешки, что попадались мне одна серия transcend jetflash. Радовали и ценой и производительностью и стойкостью, было штук 5, до сих пор работают две, остальные просто растерялись
много ли у Вас кингстонов или м2 самсунгов, так внезапно уходило в страну вечной охоты?
Все проблемы с дисками решаются бэкапом и гарантией производителя.
бекап — это решения проблемы информации, а не дисков. Пока ты не купишь/не поменяешь вышедший из строя диск, работа может простаивать.
И так как неизвестно, из-за чего он вышел из строя, то в ближайшее время могут и другие диски туда же отправиться.
Ситуация с SSD отличается только тем, что количество иллюзий стало меньше.
За всю свою жизнь, включая 90-е, я всего дважды сталкивался с выходом HDD из строя. Именно мгновенным выходом, а не ситуацией, когда диск начинает постепенно «сыпаться» и этот процесс растягивается на недели.
Тогда как с дохлыми SSD только за последние 3 года сталкивался 4 раза.
бекап — это решения проблемы информации, а не дисков. Пока ты не купишь/не поменяешь вышедший из строя диск, работа может простаивать.
RAID, корзина с "горячей" заменой и ЗИП обоснованных размеров "спасут отца русской демократии".
Даже в ноутбуке.
Системный диск заменяется из ЗИПа, после чего быстро накатывается образ.
Небольшие по объему данные быстро восстанавливаюься из бэкапа.
Объемные данные на внешнем устройстве с RAID1. Второе такое же устройство и диски к нему в ЗИПе
Как-то так.
Вы выше пишете про RAID-1 и корзину с hot-plug. Я написал, что для ноутбука это, очевидно, не подходит.
У меня было как-то интересное усттойство, которое имело габариты внешнего жесткого диска (чуть больше ноутбучного жесткого диска по длине и ширине и чуть толще двух ноутбучных жестких дисков, уложенных один на другой.
Устройство умело подключаться по USB, умело RAID1 с горячей заменой (две дверки с простыми, но достаточно надежными защелками.
Что мне особо нравилось, диск, работающий в RAID1 можно было вынуть и полключить к компьютеру через SATA или простой USB переходник, и он нормально воспринимался, поскольку не имел в разметке извращений, свойственных дискам, крутящимся во мноших других RAID контроллерах.
Я его как раз использовал с ноутбуком в качестве носителя для объемных данных.
Восстановление системы с образа и пользовательских данных из бэкапа на SSD никогда не занимало очень много времени (не больше часа на все).
Еще вспомнился один интересный ноутбук, которыц довелось видеть живьем (ни производителя, ни модель сейчас не вспомню уже). 17" монстр с аппаратным рэйдом и ттемя слотами для SATA дисков. Горячей замены, правдв, не было, но замена диска заеимала всего пару минут: открутить винт (обычный крест), открыть крышку, заменить диск, поставить крышку на место и закрутить. Если экстремальное использование не ожидается, винт на крыоке можно не закручивать. Защелка нормально держит.
Это, кстати, плохо, что разметка была обычной и устройство читалось без софта специального. Ибо это означает, что контроллер не хранил контрольных сумм. Тогда в ситуации, когда он внезапно обнаруживает, что данные на дисках отличаются, ему только остаётся сказать об ошибке и отключиться — и пусть уже пользователь гадает, какая же из копий верная. Правильный контроллер делает нестандартную разметку, в которой помимо самих данных хранит ещё и контрольные суммы блоков. Тогда при обнаружении разных данных на диске он может проверить контрольную сумму и сказать "ребята, вот этот диск хороший, а другой какую-то фигню стал содержать, поменяйте именно его".
Ну как-то это устройство определяло, какой диск объявить поврежденным в случае сбоя и с какого диска копировать данные при замене диска в устройстве, когда вставлялся диск, ранее уже использовавшийся в нем и не отформатированный.
Подозреваю, что всякую служебку, включая контрольные суммы, оно просто хранило в областях дисков, не распределенных под разделы.
Подозреваю также, что оно очень неэффективно (не зря же в серьезных контроллерах всегда извращенная разметка), но зато такой приятный бонус.
У меня не было в запасе второго такого же, и когда устройство померло, это позволило без лишних трат и ухищрений получить свои данные.
особенно в ноутбукеОт ноутбука зависит.
Как будто ждал пока я не сделаю бэкап :)Возможно.
Кстати, в домашнем ПК, SSD никогда не умрет по причине износа ячеек
Но да, вообще-то я не припоминаю таких сбоев контроллеров жестких дисков (кроме багов, как в Seagate Barracuda 11, если не изменяет память)
Ну, перегибаете. Все сложно. Повторюсь, что каждый производитель застал черную полосу
К сожалению, не могу согласиться полностью
К сожалению, не могу согласиться полностьюТак тем и интересно, поскольку личная статистика у каждого своя.
что ещё у квантума было хорошо — так это их энтерпрайз линейка Atlas.С Атласами не общался, только слышал. Но держал в руках два Бигфута — статистически незначимо, но к этим двум претензий не было.
разъемом Ultra-320
Проблемы IBM 75GXP/60GXP (тех самых «дятлов»
Интеловские ссд на 512 купленные отнюдь не по 100$ умерли поочередно в течении года от нагрузки простой в виде двух виртуалок на одном хдд. Умерли в виде внезапного пропадания из системы, сначала раз в неделю, потом чаще, чаще и чаще… Уж если интел мрет, то я хз что покупать.
Пацаны говорят, что новые самсунги, вроде pro 950/960, очень хороши.
Когда HDD помирает в юном возрасте, можно представить, что у него не выявили проявившиеся в итоге дефекты производства. С SSD теоретически такого происходить не должно
Дополнительно — использование принципиально разных накопителей в RAID такая себе идея, т.к. в RAID1 мы должны дождаться подтверждения записи от обоих накопителей, иначе — отказ.
не вижу как это может помешать использовать различные накопители
Чет напомнило историю пятнадцатилетней давности про DVD-резаки LiteOn, которые все накупили из-за низкой стоимости и невероятной способности читать диски произвольной степени потертости. А потом оказалось, что читаемость достигается выкрученной под максимум мощностью лазера, и все эти резаки радостно сыпятся один за другим через полгода-год интенсивного использования.
У меня был Teac (до сих пор не уверен, как правильно это произносится). Читал только заводские и очень бережно хранимые болванки, записанное им читалось абсолютно везде. Был жив пять лет, продан вместе с системником в 2007 году. Не удивлюсь, если жив до сих пор.
TEAC Corporation (ティアック株式会社 Tiakku Kabushiki-gaisha) (/ˈtiːæk/) is an electronics company based in Japan.
Из строя лайтоны выходи на уровне остальных. Но записывали и читали очень достойно. Лучше заменить через год, чем плохо писать и нельзя прочитать, но два года службы.
К примеру покупка нека (3500 кажется, не помню) привела к необходимости купить читающий привод.
Не могу подтвердить. Жил в то время в общаге, был буквально окружен компами сожителей, потому моя статистика кажется репрезентативной. LiteON слетели у большинства купивших в пределах полутора лет. Точно не одна бракованная партия, так как было много иногородних, которые привозили купленные по месту жительства компы.
Intel 540 пропал из системы, после очередной перезагрузки. В сервисе сказали всё норм. Помогло обновление BIOS на матери. Так что проблема может быть не только в диске. Есть подозрение, что ошибка возникла при заполнении больше половины диска.
но если мониторить TBW
Intel 540s. Помер не совсем внезапно, постепенно росли значения аттрибутов 5 и 9. Вот смарт за час до смерти:
SMART Attributes Data Structure revision number: 1
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
5 Reallocated_Sector_Ct -O--CK 100 100 000 - 387
9 Power_On_Hours_and_Msec -O--CK 100 100 000 - 241h+00m+00.000s
12 Power_Cycle_Count -O--CK 100 100 000 - 145
170 Available_Reservd_Space PO--CK 095 095 010 - 0
171 Program_Fail_Count -O--CK 100 100 010 - 0
172 Erase_Fail_Count -O--CK 100 100 010 - 0
174 Unexpect_Power_Loss_Ct -O--CK 100 100 000 - 9
183 SATA_Downshift_Count -O--CK 100 100 000 - 0
184 End-to-End_Error PO--CK 100 100 090 - 0
187 Uncorrectable_Error_Cnt -O--CK 100 100 000 - 199
190 Airflow_Temperature_Cel -O--CK 033 048 000 - 33 (Min/Max 25/48)
192 Power-Off_Retract_Count -O--CK 100 100 000 - 9
199 UDMA_CRC_Error_Count -O--CK 100 100 000 - 0
225 Host_Writes_32MiB -O--CK 100 100 000 - 89514
226 Workld_Media_Wear_Indic -O--CK 100 100 000 - 0
227 Workld_Host_Reads_Perc -O--CK 100 100 000 - 0
228 Workload_Minutes -O--CK 100 100 000 - 0
232 Available_Reservd_Space PO--CK 095 095 010 - 0
233 Media_Wearout_Indicator -O--CK 099 099 000 - 0
241 Total_LBAs_Written -O--CK 100 100 000 - 89514
242 Total_LBAs_Read -O--CK 100 100 000 - 39026
249 NAND_Writes_1GiB -O--CK 100 100 000 - 814
252 Unknown_Attribute -O--CK 100 100 000 - 3Обратите внимание на TBW и на соотношение 241 и 249. Хост подал на запись 2797 GiB, на диск записано 814 GiB.
Mad__Max, SMART не обнулялся, но, судя по истории, атрибут 9 рос не каждый час, а когда диск был под нагрузкой (в ноутбуке). Предположу, что связно это с DevSleep. Реальное время работы — с 3 сентября по 10 марта, то есть где-то полгода.
Tangeman, TBW как раз указывает в 241. А в 249 указывает, сколько реально записано было на чипы. Кстати, в 535 серии была проблема из-за DevSleep, когда рос 249 при отсутствии роста 241. А если имелась в виду спецификация, то тоже указывает в описании гарантии. 40 гигов в день в течение 5 лет, что дает 73000 гигов.
Атрибут 5 вырос 21.12 в первый раз. 187 — 26.01. Вот 26.01 уже надо было задуматься о замене. В поддержке сказали, что лечится это обновлением прошивки (кстати, при этом обнуляется 5 атрибут), но этот диск перестал определяться совсем, а другой после обновления тоже стал показывать растущие показатели 5 и 187.
Так что я бы сказал, что дефектная вся 540 серия.
Не очень понял, как наличие кэша может уменьшить 249 атрибут. Может быть, имелось в виду сжатие?
Про кэш понятно, спасибо. Мне кажется, это не мой случай, у меня обычный ноутбук.
TBW как раз логично считать от хоста, потому что на это пользователь влияет. Какая ему разница, как пишутся данные? Может быть, производитель реализовал контроллер так, что в ячейки пишется в 2 раза больше информации, чем хост дает, но все ячейки идет с 3-кратным запасом.
Про 241 час уже отвечал:
SMART не обнулялся, но, судя по истории, атрибут 9 рос не каждый час, а когда диск был под нагрузкой (в ноутбуке). Предположу, что связно это с DevSleep. Реальное время работы — с 3 сентября по 10 марта, то есть где-то полгода.
Вот, например, 2 смарта с разницей в месяц, ноут я не выключал почти:
01.10.2017 0:00:00,05
smartctl 6.5 2016-05-07 r4318 [x86_64-w64-mingw32-win8.1] (sf-6.5-1)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 1
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
5 Reallocated_Sector_Ct -O--CK 100 100 000 - 0
9 Power_On_Hours_and_Msec -O--CK 100 100 000 - 32
12 Power_Cycle_Count -O--CK 100 100 000 - 11
170 Available_Reservd_Space PO--CK 100 100 010 - 0
171 Program_Fail_Count -O--CK 100 100 010 - 0
172 Erase_Fail_Count -O--CK 100 100 010 - 0
174 Unexpect_Power_Loss_Ct -O--CK 100 100 000 - 1
183 SATA_Downshift_Count -O--CK 100 100 000 - 0
184 End-to-End_Error PO--CK 100 100 090 - 0
187 Uncorrectable_Error_Cnt -O--CK 100 100 000 - 0
190 Airflow_Temperature_Cel -O--CK 035 048 000 - 35 (Min/Max 28/48)
192 Power-Off_Retract_Count -O--CK 100 100 000 - 1
199 UDMA_CRC_Error_Count -O--CK 100 100 000 - 0
225 Host_Writes_32MiB -O--CK 100 100 000 - 19066
226 Workld_Media_Wear_Indic -O--CK 100 100 000 - 0
227 Workld_Host_Reads_Perc -O--CK 100 100 000 - 0
228 Workload_Minutes -O--CK 100 100 000 - 0
232 Available_Reservd_Space PO--CK 100 100 010 - 0
233 Media_Wearout_Indicator -O--CK 100 100 000 - 0
241 Total_LBAs_Written -O--CK 100 100 000 - 19066
242 Total_LBAs_Read -O--CK 100 100 000 - 4496
249 NAND_Writes_1GiB -O--CK 100 100 000 - 317
252 Unknown_Attribute -O--CK 100 100 000 - 1
01.11.2017 0:00:00,09
smartctl 6.5 2016-05-07 r4318 [x86_64-w64-mingw32-win8.1] (sf-6.5-1)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 1
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
5 Reallocated_Sector_Ct -O--CK 100 100 000 - 0
9 Power_On_Hours_and_Msec -O--CK 100 100 000 - 66
12 Power_Cycle_Count -O--CK 100 100 000 - 45
170 Available_Reservd_Space PO--CK 100 100 010 - 0
171 Program_Fail_Count -O--CK 100 100 010 - 0
172 Erase_Fail_Count -O--CK 100 100 010 - 0
174 Unexpect_Power_Loss_Ct -O--CK 100 100 000 - 1
183 SATA_Downshift_Count -O--CK 100 100 000 - 0
184 End-to-End_Error PO--CK 100 100 090 - 0
187 Uncorrectable_Error_Cnt -O--CK 100 100 000 - 0
190 Airflow_Temperature_Cel -O--CK 034 048 000 - 34 (Min/Max 27/48)
192 Power-Off_Retract_Count -O--CK 100 100 000 - 1
199 UDMA_CRC_Error_Count -O--CK 100 100 000 - 0
225 Host_Writes_32MiB -O--CK 100 100 000 - 30290
226 Workld_Media_Wear_Indic -O--CK 100 100 000 - 0
227 Workld_Host_Reads_Perc -O--CK 100 100 000 - 0
228 Workload_Minutes -O--CK 100 100 000 - 0
232 Available_Reservd_Space PO--CK 100 100 010 - 0
233 Media_Wearout_Indicator -O--CK 100 100 000 - 0
241 Total_LBAs_Written -O--CK 100 100 000 - 30290
242 Total_LBAs_Read -O--CK 100 100 000 - 8288
249 NAND_Writes_1GiB -O--CK 100 100 000 - 391
252 Unknown_Attribute -O--CK 100 100 000 - 1для меня сигналом к замене послужил бы первый перераспределенный сектор или первое использование резервной области
Опять же тесты без выключения питания. А как поведут себя при выключении на пару месяцев или больше? Таких тестов нет, а по слухам дохнут при выключении питания.
Я в итоге пришел к схеме:
1 SSD для системы
2 HDD с данными (разными).
Всё это еженедельно бекапится акронисом — SSD и первый хард — на второй, а второй хард — на первый.
SSD если умирает, выкидываешь, покупаешь новый, разворачиваешь акронис — вуаля, у тебя за полчаса рабочая система с новым диском. Данные при этом не затронуты, софт каждую неделю не ставишь — так что не теряется вообще ничего.
Ну а если умирает один из жестких (что происходит гораздо реже) — в принципе то же самое. Но это за ближайшие 10 лет было только пока один раз, т.к. HDD не системные — в работе они гораздо меньше, износа мало. При этом система работает на быстром SSD, все плюсы скорости загрузки и работы остаются.
Остаётся только при каждом обновлении наращивать объем дисков про запас… Начинал я когда-то с SSD на 64гб, сейчас уже 512 стоит. Жесткие были по 512, сейчас по 4ТБ.
А зачем на серверах использовать десктопные ssd?
Без обид, если вы 'колхозите', то тогда жаловаться на то, что что-то пошло не так, как в статье, это смешно. Есть северная инфраструктура, есть десктоп. Если в компании, в которой нет бабла, начинается колхоз, то появляются вот такие статьи :)
Бизнес — это зарабатывание денег, а не замена дисков, перезагрузка серверов и иные несуразные действия. Я прекрасно понимаю, что бизнесы бывают разные, но для меня, работать в бизнесе, где надо в инфраструктуре финансово балансировать на экономии северного диска это не допустимо.
глупость говорите.
Поддержание инфраструктуры с абсолютно надежными дисками — это утопия и сверхдорого.
Соответственно, бизнесу решать выгодно ли держать специально обученного человека, который будет только и заниматься заменой диской. Тем более, если это обеспечивает SLA/SLO.
Надеюсь, что персонально Вам (и мне) такой рутинной работой, как замена дисков, заниматься не придется (разве что только за соответствующее денежное вознаграждение).
но для меня, работать в бизнесе, где надо в инфраструктуре финансово балансировать на экономии северного диска это не допустимо.
SATA интерфейс на SAS контроллере уже намекает на возможные проблемыО каком SAS-контроллере идёт речь, и на какие именно проблемы намекает SATA-интерфейс?
Что касается отказа Crucial MX300 — это накопитель для персонального компьютера, для серверного использования не годится.
Самая большая проблема SSD — это запроприетаренная прошивка.
Раздражает, но в случае кофеварки и видеокарты это не так фатально.
Я не слышал отказы видеокарт из-за того, что им прошивку криво обновили. Ах, да, так потому что видеобиос — это не фирмварь видяхи, а коды для основного процессора ПК.
Всякую дичь типа оверклокинга не рассматриваем. Именно штатную работу и обновления.
К тому же, даже отказ видеокарты не настолько фатален, как потеря сотен гигов уникальной информации (да-да-да, жду комментария про бекапы и облако)
Жесткий диск имеет совершенно иное устройство, и задачи прошивки там в принципе минимальны, ошибиться почти негде, кривая прошивка будет означать фейл всей серии, а не рандомных устройств.
Потому что в этом случае не теряются данные, и девайс не превращается в кирпич из-за какого-нить division by zero.
потому что покупать нужно не говно всякое типа киуикал, а интел
у меня ssd intel от 2011 года 240 гигов, пашет в ноуте круглосуточно, проблем нету сейчас
Отдельный диск из RAID-1 вынимаем
Disk failures in the real world: What does an MTTF of 1,000,000 hours mean to you?Да, это 2002–2007 год, эпоха HDD, но суть статей как раз в том, что накопители просто дохнут — и всё. Можно пытаться строить статистические модели, если у вас во владении есть тысячи накопителей из одной партии, но для конкретного экземпляра это всегда выглядело и будет выглядеть как внезапный выход из строя. Можете сколько угодно отрицать это, нервничать и впадать в депрессию, но рано или поздно вам придётся принять за аксиому, что накопители умирают, когда ничто не предвещало. Надо заранее быть к этому готовыми.
за авторством Bianca Schroeder и Garth A. Gibson
Failure Trends in a Large Disk Drive Population
за авторством Eduardo Pinheiro, Wolf-Dietrich Weber и Luiz Andre Barroso
А также статьи из библиографического списка, в частности про Internet Archive.

за небольшую плату
уже полумертвую флешку можно такой перепайкой стереть окончательно
Наблюдаю всё больше отказов SSD-дисков в SATA-формате. Диагноз одинаков работает-работает, бум! - диск пропал из системы. Кнопка "сброс" не помогает; лишь полное отключение питания сбрасывает диск, он становится виден вновь и работает вплоть до очередного отказа через несколько дней. Масса разных материнок, масса разных дисков (из последних наблюдаемых с проблемой - Verbatim, AData, GoodRAM).
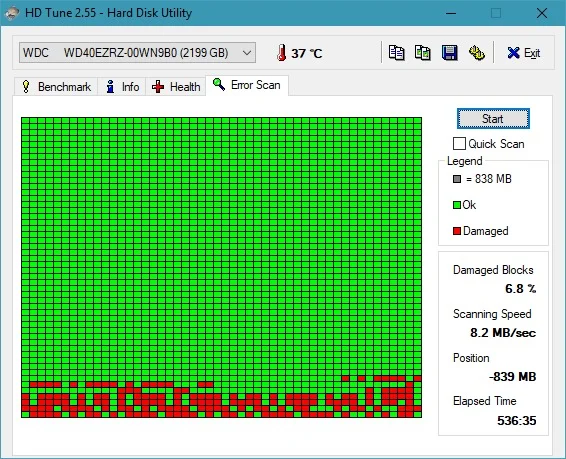

Почему меня нервируют отказы современных SSD