
Я Денис Соколов, руковожу R&D в Zenia Yoga — первого приложения для йоги на основе ИИ. В этой статье я расскажу, из чего состоит современная система, работающая с компьютерным зрением: как влияет каждый элемент пайплайна на конечный результат, который видит пользователь. Мы пошагово разберем создание модели для human pose estimation и сравним ее с готовыми «коробочными» решениями от производителей мобильных платформ, а также открытыми аналогами.
Задача human pose estimation
Мы решаем задачу, которая называется human pose estimation: по изображению с камеры ищем положение определенных точек на теле человека. Это нужно, чтобы занятия йогой через мобильное приложение были безопаснее и эффективнее. Мы сравниваем позы ученика и инструктора с помощью компьютерного зрения и сообщаем, если асана выполнена с ошибкой.
Zenia Yoga распознаёт положение 22-х точек на теле человека. На вход системы принимаем изображение с обычной камеры: не используем специальное оборудование, чтобы запускаться на максимальном количестве устройств. Система работает сразу на 3-х платформах: iOS, Android и, с недавнего времени, веб-браузер.
Шаг 1. Выбираем датасет
Данные — основа любой системы, построенной с помощью машинного обучения. Главные критерии качества датасета: точность разметки и разнообразие данных. Самые популярные датасеты pose estimation — MPII и COCO. Они отличаются между собой разметкой и количеством изображений. Есть и более специализированные датасеты, например, Yoga-82. Часто открытые датасеты запрещают коммерческое использование. Поэтому мы приняли решение собрать свой собственный.
Шаг 2. Размечаем данные
Мы размечаем 22 точки на теле человека. Когда началась работа над Zenia Yoga, инструментов для разметки, которые бы нас устроили, ещё не существовало. Пришлось разработать собственное решение: web-инструмент, который поддерживает менеджмент базы изображений, распределение задач между разметчиками и кросс-проверку. Сейчас это уже стандартный набор функций для таких инструментов (например, Supervisely).
")
Команда разметки у нас в штате. Это дает высокое качество и возможность пообщаться с людьми, которые постоянно работают с данными «руками». Отсюда полезные инсайты о том, как устроены данные и какие могут быть проблемные места. Платформы вроде Яндекс.Толока не использовали — не было необходимости. Со временем стали больше вовлекать команду разметки в процесс улучшения модели: теперь ребята не только размечают изображения, но и помогают искать ошибки модели в распознавании.
Чтобы помочь модели разобраться, как расположено тело человека в пространстве, мы размечаем точки с несколькими степенями видимости. Показываем, на каком плане от камеры расположена точка — ближе или дальше. Получается эффект псевдо-3D. Он позволяет получить более полную информацию о расположении тела в пространстве, важную для распознавания сложных поз.
Шаг 3. Выбираем архитектуру модели
Сейчас для решения задачи pose estimation можно найти огромное количество архитектур. Достаточно зайти на Paperswithcode. Я считаю, что выбор конкретной архитектуры из множества вариантов, которые появляются каждую неделю, имеет куда меньшее значение, чем правильно размеченный и подготовленный датасет, аккуратно подобранные аугментации, правильный выбор таргета для модели и режима обучения. Статьи вроде этой подкрепляют мою точку зрения.
Мы с самого начала придерживались принципа «чем проще, тем лучше». Это гарантирует, что модель точно сконвертируется в нужный формат. Стандартные слои встречаются наиболее часто, а значит, лучше всего оптимизированы и поддерживаются железом. А еще «простые» слои обычно самые эффективные с точки зрения соотношения доступа к памяти и вычислений.
За основу модели взяли Stacked Hourglass. Стандартная и простая архитектура, которая состоит из последовательных encoding и decoding блоков, с входным initial block. Оригинальная архитектура не предполагала использования на мобильных устройствах и была слишком тяжелой. Поэтому мы скрестили её с ENet — крайне лёгкой моделью — для решения задачи сегментации. За несколько лет архитектура нашей модели эволюционировала и обросла улучшениями, но основа всё ещё с нами.
Шаг 4. Препроцессинг — Сжатие и трекинг
Свёрточные нейронные сети обычно принимают на вход изображение фиксированного размера. Чем больше размер изображения, тем лучше будет работать модель. Но вместе с увеличением качества квадратично растёт необходимый объём вычислений и памяти. Поэтому размер изображения — важный параметр при настройке маленькой модели.
Представим последовательность обработки изображения по шагам. Нам нужно распознать позу человека на изображении. Обычно, даже если человек занимает максимально возможную площадь на изображении, это всего 20% картинки.

Мы получаем изображение с камеры с большим разрешением, скажем, 1280х720. А модель принимает на вход изображение 256х256. Если просто сжать входное изображение, на вход пойдёт что-то вроде этого:

Во-первых, получается, что на изображении около 80% пикселей вообще не нужны для решения нашей задачи. Во-вторых, операция resize безвозвратно теряет информацию, которая могла быть полезна для решения задачи (Learning to Resize Images for Computer Vision Tasks).
Чтобы добиться максимального качества при минимально возможном размере картинки, хочется, чтобы модель получала на вход подобное изображение:

Один из способов получить такой результат — использовать отдельную модель: детектор человека. Так, например, работают top-down multi-person распознаватели поз.
Мы не хотели использовать дополнительную модель. Поэтому наша модель выступает в роли детектора сама для себя. На первом кадре она получает на вход изображение целиком и находит первое положение суставов человека в кадре. Это положение неточное, но его достаточно, чтобы инициализировать трекер. Для следующего кадра трекер рассчитывает область, в которой скорее всего находится человек, на основе истории предыдущих детекций. Так положение человека в кадре постоянно отслеживается и уточняется. На вход модели подаётся картинка, на которой человек занимает максимально возможную площадь, что улучшает качество предсказаний.


Если вам интересно, какие ещё варианты трекинга применяются на практике, рекомендую прочитать статью BlazePose. Там применяется очень интересная система детектора и извлекателя точек, которые помогают друг другу.
Шаг 5. Постпроцессинг — извлечение координат и фильтры
Извлечение координат из heatmap

Для каждого сустава модель предсказывает heatmap: это матрица, значения в которой показывают «вероятность» того, что сустав находится в данной клетке. Обычно разрешение heatmap меньше разрешения входного изображения в 2-8 раз. Это тоже способ сэкономить ресурсы.
Цель pose estimation модели — получить а) координаты суставов человека на входном изображении и б) степень уверенности в предсказании. Итак, на выходе модели мы получили матрицу со значениями «вероятностей» расположения сустава. Но чтобы получить координаты, нужно их из матрицы извлечь.
Самый простой, но и самый неточный способ — посчитать argmax, функцию, которая найдёт координаты максимального значения в матрице.

Чтобы более точно расшифровать координаты, после поиска максимального элемента рядом с ним ищут следующего по величине соседа и немного сдвигают предсказание в его сторону. Этот приём был предложен достаточно давно в Stacked Hourglass. Сейчас на тему кодирования и декодирования координат можно найти множество статей — например, DarkPose.

Фильтр шума
Изображение с камеры содержит шум, незаметный глазу человека. Он влияет на входные данные, поэтому предсказания на соседних кадрах немного отличаются.
Чтобы точки не дрожали и результат выглядел красивее, применяют различные фильтры шума. Они бывают разными: довольно простые — скользящее среднее и экспоненциальный фильтр, или более сложный фильтр Калмана.
Отдельно можно выделить 1-euro filter: экспоненциальный фильтр, в котором значение экспоненты задаётся динамически. Это позволяет ему, с одной стороны, фильтровать шум в статическом режиме, когда предсказания колеблются вокруг одной точки, и при этом хорошо реагировать в случае, когда предсказания быстро изменяются.
Параметры фильтров подбираются эмпирически под конкретный режим работы и особенности шума, которые выдаёт модель. Мы долго пользовались простым экспоненциальным фильтром, а сейчас переходим на 1-euro из-за его способности быстро реагировать на изменения координат. Можно наглядно посмотреть на разницу в работе фильтров в этом демо.


Особые фильтры
В нашем арсенале есть еще несколько фильтров, которые помогают справляться со специфическими ошибками, которые влияют на пользовательский опыт. Например, фильтр «моргания» точек: он борется с ситуацией, когда уверенность точки колеблется возле порога, но при этом точка детектируется в одном и том же месте. Со стороны пользователя в этом случае кажется, что точка «моргает» (как на правом колене Феликса).
Проблему можно решить, фильтруя сами значения уверенности: не давать им колебаться возле порога, обновлять значение только в случае, когда оно выходит за пределы некоторого окна. Мы выбрали другой способ: сделали фильтр, который проверяет, что положение точки не сильно изменилось по сравнению с предыдущим, а её уверенность проходит дополнительный, более низкий порог. Тогда мы искусственно увеличиваем уверенность такой точки и моргание пропадает.


Часто возникает ошибка «перескоков», когда суставы парных конечностей меняются местами. Иногда модели тяжело предсказать, какая конечность правая, а какая левая, и её предсказания от кадра к кадру меняются. Бороться с этим приходится как со стороны модели, так и в пост-процессинге. Если на уровне модели учесть, какое решение она приняла на предыдущем кадре, ошибка исправится автоматически. Но такой способ требует достаточно серьёзных изменений в пайплайне. Сейчас он находится в разработке, а пока мы решаем эту проблему на уровне постпроцессинга.


Шаг 6. Сравнение с аналогами
Какие есть аналоги
Рассмотрим «коробочные» решения для pose estimation от производителей мобильных платформ, а также открытые аналоги.
Наиболее полного покрытия платформ можно добиться с помощью решения от Google на базе архитектуры BlazePose. Оно доступно как в MLKit в виде высокоуровневого API для распознавания позы человека, так и в MediaPipe, где можно воспользоваться им в большем количестве вариантов (для верхней части тела, всего тела, а также holistic-модели, в которой объединены распознавание позы, положения рук и лица) и для большего количества платформ, в т.ч javascript и python.
В дальнейшем мы будем сравнивать наше решение с Full-Body версией BlazePose. Она поддерживает распознавание 33 точек на теле человека.
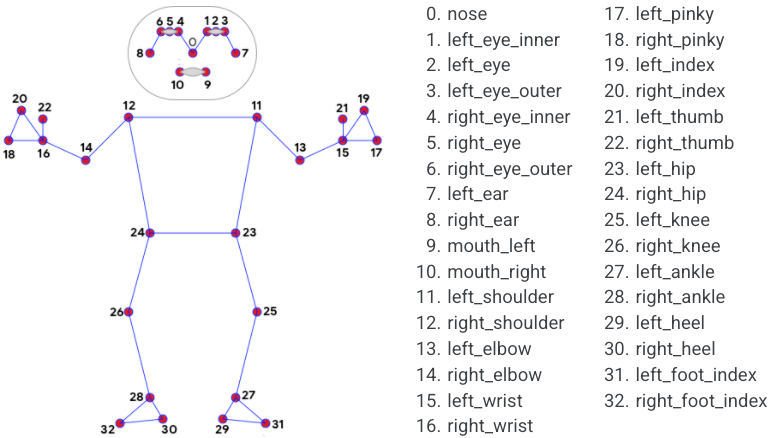
MediaPipe предоставляет не только модель для распознавания позы человека, но и весь пайплайн вместе с трекингом, пре- и пост-процессингом.
Apple
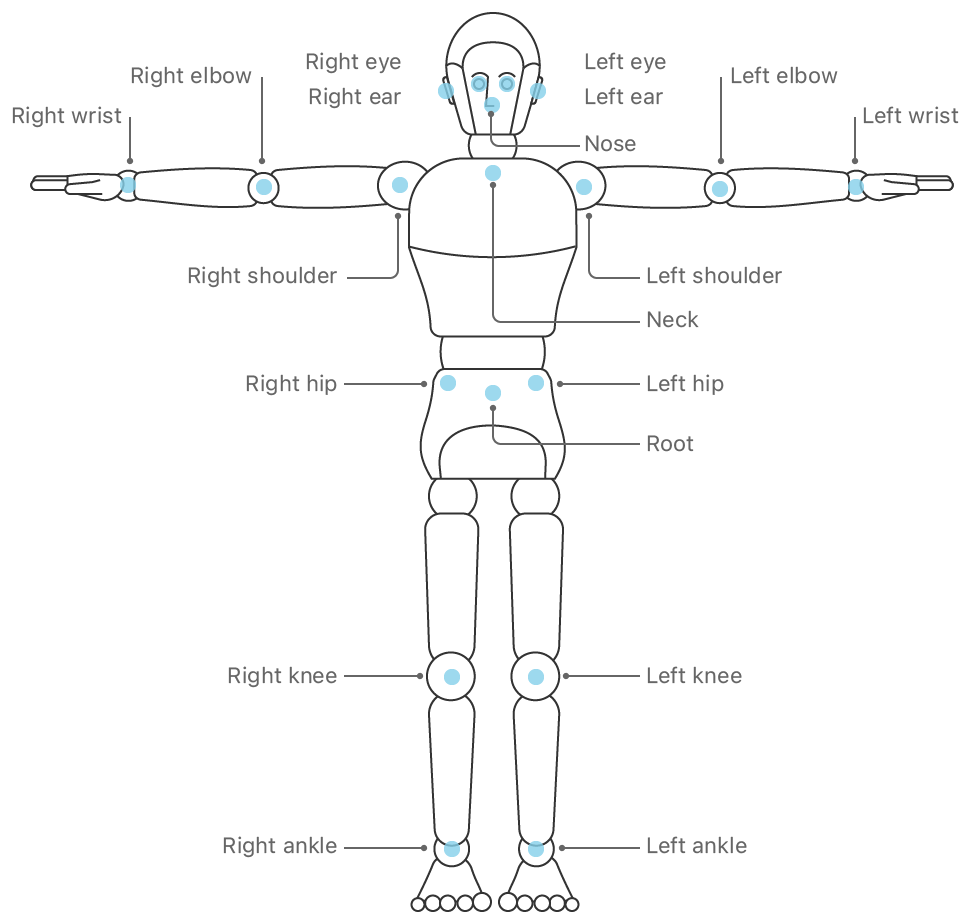
Apple представил своё решение для Human Pose Estimation на WWDC2020. Модуль доступен в составе фреймворка Vision, начиная с iOS 14, и macOS 11. Внутренности решения Apple неизвестны. Оно позволяет распознавать положение до 19 точек на теле человека.
Открытые библиотеки
Другой класс решений задачи human pose estimation — это открытые библиотеки. Самые популярные среди них OpenPose и AlphaPose. Обе библиотеки поддерживают распознавание поз нескольких человек в кадре (multi-person), а также Whole-Body (Holistic) Pose Estimation. К сожалению, они не предоставляют готовых решений для запуска пайплайнов на мобильных устройствах или в браузерах. OpenPose написан на C++, поэтому теоретически его можно портировать на мобильные устройства, но сложно сказать, сколько это может занять времени.
Оба решения запрещают коммерческое использование, но предоставляют возможность купить лицензию. Однако даже с лицензией OpenPose запрещает использование в сфере спорта.
Если вы хотите сравнить между собой различные модели или обучить свою, обратите внимание на mmpose — открытый фреймворк для экспериментов с human pose estimation моделями.
Сравнение качества моделей
Измерение качества работы системы — это сложно. Свести это качество к одной цифре — ещё сложнее. Тем не менее, сравнивать модели между собой необходимо для отслеживания прогресса. Для этого существует несколько метрик. Самые популярные — PCK и OKS AP.
PCK (Percent of Correct Keypoints) — метрика, по которой считают точность моделей на датасете MPII. Считается просто: выбираем базовый элемент — это может быть длина торса, высота головы или длина диагонали bounding box позы, и некоторый порог определения, который указывается после имени метрики. Например PCK@0.5 означает, что сустав считается правильно определённым, если он попал в окружность радиусом 0.5 * torso_size вокруг правильного сустава. Количество правильно определённых суставов делится на количество видимых эталонных суставов, чтобы получить значение метрики.
OKS (Object Keypoint Similarity) AP (Average Precision) — метрика, по которой модели сравнивают на датасете COCO. Она считается гораздо сложнее, поэтому не будем приводить здесь алгоритм, а сошлёмся на прекрасную статью Benchmarking and Error Diagnosis in Multi-Instance Pose Estimation, в которой разбираются типы ошибок, которые могут произойти при работе pose estimation системы. Основное отличие OKS — это то, что для каждой точки вводится дополнительная «допустимая погрешность». Чтобы её получить, авторы многократно разметили 5000 изображений и посчитали среднеквадратическое отклонение положения каждой точки. Это позволяет приблизить оценку точности к тому, как её воспринимает человек, ведь ошибка предсказания положения глаз для нас гораздо заметнее, чем, например, плеча.
Эти метрики, особенно OKS AP, хорошо подходят для того, чтобы оценить качество модели «в целом». Однако у них есть недостаток, из-за которого мы не пользуемся ими в качестве основных. В случае single person pose estimation обе эти метрики:
Не учитывают предсказания для точек, которые в эталонной разметке размечены, как невидимые
Не учитывают уверенность (confidence) предсказанных точек
Эти факторы очень важны для реального использования. Ведь финальным результатом предсказания для нас является положение сустава, только если он прошёл порог уверенности. И в обратную сторону — невидимость бывает разная. Не всегда то, что точка отмечена как невидимая, означает, что не нужно предсказывать её положение.
Поэтому для оценки точности мы считаем свою метрику. Она напоминает PCK@0.2, но отдельно учитывает случаи невидимости или недостаточной уверенности модели в предсказанном положении сустава.
В качестве тестовой выборки используем ~5000 изображений, классифицированных по асанам. Это позволяет оценивать точность не только в целом или по каждому суставу, но и смотреть, какая асана оказалась самой сложной для модели. Также мы отдельно проверяем ложные срабатывания на небольшом наборе изображений, на которых совсем нет людей — на изображениях интерьера.
Было бы здорово иметь возможность оценить качество работы всей системы всего лишь по одной цифре, но сделать это тяжело. Метрики для нас — скорее sanity check для сравнения моделей, чтобы посмотреть, что ничего не сломалось и найти самые проблемные места.
Отдельно считаем метрики, важные для бизнеса: это количество специфических ошибок, которые допускает модель — перескоки (когда парные суставы меняют положение) и False Discovery Rate.
И, наконец, цифры. Здесь мы приведём Average Precision и Average Recall (которые рассчитаны как средние по суставам при фиксированном значении отсечки по уверенности предсказаний).
Для того, чтобы сравнить модели между собой, нам пришлось пересчитать положение некоторых точек, чтобы перевести их в одинаковую «систему разметки».
Отдельно заметим, что из-за сложности поз в тесте детекторы не всегда справляются с тем, чтобы обнаружить человека на изображении. В первой таблице метрики, усреднённые для изображений, на которых модель смогла найти человека.
Zenia Yoga | MediaPipe | Apple | |
Avg Precision | 90.06 | 82.28 | 82.93 |
Avg Recall | 93.57 | 80.24 | 70.59 |
Detected Persons | 4408 | 4065 | 3181 |
А во второй таблице метрики качества на подмножестве людей, которых смогли найти все системы.
Zenia Yoga | MediaPipe | Apple | |
Avg Precision | 92.58 | 88.31 | 82.83 |
Avg Recall | 97.18 | 83.8 | 76.99 |
Detected Persons | 2343 | 2343 | 2343 |
Дополнительно о том, насколько популярные метрики соответствуют тому, как оценил бы точность человек, рекомендуем прочитать заключение статьи YOLOv3.
Из этого сравнения видно, что система, специализированная для решения конкретной задачи, работает значительно лучше, чем системы общего назначения. Тем не менее, если вам нужно решение здесь и сейчас, набор моделей из MediaPipe — отличный выбор.

