О чем эта статья
Всем привет! Меня зовут Сергей Коньков — я архитектор данных в компании BR Systems. Когда есть возможность, я посещаю различные конференции по анализу данных, машинному обучению и разработке. Однажды мне пришла в голову мысль, что часто на сцене этих конференций мы видим представителей одних и тех же компаний из ТОП 5 крупнейших банков или ритейлеров страны. Они рассказывают очень интересные кейсы, как кластеры из десятков серверов обрабатывают терабайты данных, как тысячи сотрудников корпорации используют результаты этого анализа. А в зале сидят и слушают их айтишники из среднего бизнеса, для которых насущные проблемы, это выбить бюджет на дополнительны диски и память для единственного SQL сервера.
Тут же на этих конференциях нам предлагают записаться на курсы дата инженеров и аналитиков. Средний бизнес отправляют туда сотрудника и там преподаватель (иногда тот же сотрудник суперкорпорации) объясняет, что для того что бы работать с данными нужно на хорошем уровне знать Linux, Hadoop, Spark, Kafka, Airflow. Это так называемый классический стек технологий для работы с bigdata.
Как быть если у вас в ИТ отделе всего 5 человек и один из них отвечает за данные в нагрузку к прочей работе? Ему нужно достать данные из 1С, CRM, Google Analytics, соединить это все вместе и быстро построить отчетность, а завтра уже будет новые источники из новой производственной системы. И все это каждый день меняется. Он знает SQL, иногда Python и где в 1С найти данные. И у него нет времени на изучение Spark. Да даже у тех у кого в ИТ службе 50 человек проблематично иметь в штате инженера данных который знает все эти технологии.
Рассказываем как перестать переживать о том, что вы не знаете Hadoop и вывести работу с данными в компании на новый уровень, как быстро и без больших затрат создать в аналитическое хранилище данных, наладить процессы загрузки туда данных, дать возможность аналитикам строить отчеты в современных BI инструментах и применять машинное обучение.
Разбираемся в задачах
Итак мы компания среднего бизнеса. Торгуем оптом строительными материалами. Что у нас есть:
ERP система в компании (например: 1С или Axapta)
CRM система (Amo CRM или Bitrix 24)
Облачная система для учета товаров которая используется в одном из филиалов (Мой склад)
Интернет магазин написанный на PHP с подключенным Google Analytics
Что нам нужно: строить консолидированную отчетность на основании данных их всех этих источников.
Как решаем сейчас: делаем отчеты в каждой из этих систем, все выгружаем в Excel, в нем сводим, высылаем отчеты в Excel пользователям по почте. Есть отчеты которые нужны каждый месяц: ежемесячно тратим время на их сведение и подготовку. Есть отчеты, которые нужны каждую неделю: теряем время еженедельно. Есть отчеты, которые нужны каждый день, но их не делаем: нет времени, отправляем их раз в неделю.
Что хотим получить
Примерно это:

Хотим загружать данные из разных источников в одну базу (хранилище данных) и строить на основании него отчеты. И все это желательно автоматически.
Многие компании используют технологию OLAP, как правило от Microsoft. Продукт SQL Server Analysis Services включен во все версии MS SQL Server, начиная со Standard и является отличной технологией для решения данной задачи. Однако если вы разворачиваете OLAP в компании вам нужен специалист который в нем хорошо разбирается, а это не так просто. И зачастую этот специалист становиться бутылочным горлышком в процессе создания отчетности.
Мы рассмотрим альтернативу OLAP и вышеупомянутому классическому стеку для работы с bigdata - Google BigQuery и посмотрим какие плюсы можно извлечь из этого.
Google BigQuery (BQ)
Что это?
Это база данных, она находится в облаке Google, точнее в Google Cloud Platform. Она поддерживает язык SQL для работы с данными. Эту технологию Google сделал специально для анализа данных. Архитектура и движок этой базы отличается от привычных MS SQL и MySQL. Колоночное хранение данных и ряд других особенностей делают все расчеты очень быстрыми. Например можно посчитать сумму продаж из розничной сети используя таблицу из 10 миллионов чеков за пару секунд.
Как все это работает?
Довольно просто: нужно зарегистрироваться в облачных службах Google, создать там проект BigQuery, загрузить данные и можно получать результаты. Попробуем для начала пройти этот процесс шаг за шагом, а потом рассмотрим более детальные вопросы по построению архитектуры.
Сколько это стоит?
Не дорого. Цены здесь: https://cloud.google.com/bigquery/pricing. Вы платите за хранение данных ($0.020 за GB, 10 GB бесплатно) и за обработку данных при анализе (5$ за TB, 1 TB в месяц бесплатно). Пример: вы загрузили в BQ данные объемом 10 GB и ваши аналитики делают SQL запросы к ним. Допустим за один запрос они обрабатывают в среднем 1 GB данных (это объем данных в таблиц который нужно обработать что бы получить результат. Ваши аналитики за месяц сделали 1000 запросов (в сумме 1 TB данных). В итоге использование BQ в этом месяце будет для вам бесплатным - вы уложились в лимиты на бесплатное использование.
Допустим вы загрузили 100 GB данных, тогда их хранение будет стоить $1.8 в месяц. Аналитики пусть сделали 1000 запросов по 10 GB, обработка будет вам стоить $45 в месяц.
Тестируем BigQuery шаг за шагом
Регистрация
Для начала нам нужна учетная запись в Google. Если у вас есть почта на gmail, то она у вас есть. Если нет, заведите: https://accounts.google.com.
Далее подключаем BigQuery. Есть два способа:
Обычный платежный аккаунт Google Cloud Platform
Песочница - для тех кто не хочет пока оставлять в Google Cloud данные своей банковской карты и хочет бесплатно протестировать систему
Платежный аккаунт подключаем по этой ссылке https://console.cloud.google.com/billing. Нужна будет банковская карта. Если вы впервые используете Google Cloud Platform вам будет предоставлен бесплатный пробный период 90 дней на использование ряда сервисов, в том числе и BigQuery в размере $300.
Если карту оставлять пока не хотите создаем песочницу. Переходим по ссылке https://console.cloud.google.com/bigquery, выбираем страну и подтверждаем условия. Все, среда создана, можно начинать работу.
Создаем проект, датасет
Данные в BigQuery хранятся в таблицах, таблицы находятся в датасетах, датасеты в проектах. На уровне проектов можно разграничивать доступ к данным. Например если у вас несколько независимых бизнесов, то для каждого можно сделать в проект. А внутри проекта сделать несколько датасетов по направлениям анализа, например датасет Производство и датасет Розница. На каждом уровне можно управлять правами доступа к объектам.
Создадим проект habrtest:

Нажмите три точки справа от названия проект и выберете опцию Create dataset, создайте датасет habrdata:

Загрузка данных в таблицу
Скачайте архив с тестовыми данными: https://www.ssa.gov/OACT/babynames/names.zip
Разархивируйте его у себя на пк
Нажмите три точки справа от названия датасета и выберите опцию Open
В открывшемся окне нажмите копку Create table
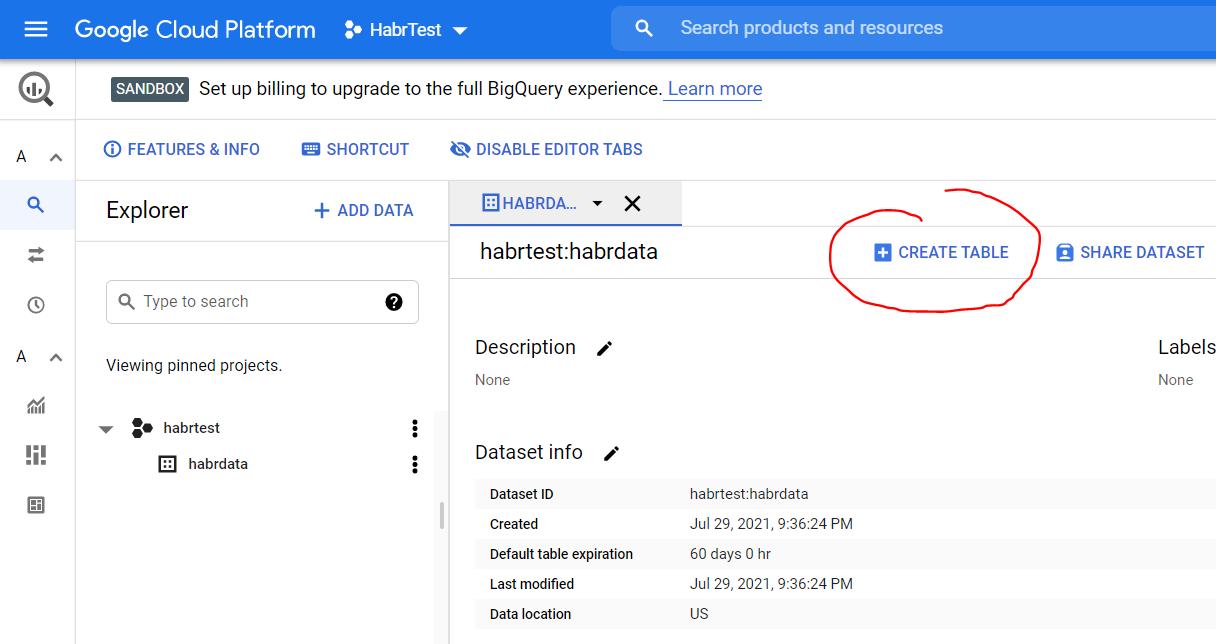
В настройках Source для Create table from, выберете Upload.
Для Select file, нажмите Browse, и выберете файл yob2014.txt из ранее разархивированной папке.
Для File format, выберете CSV.
В настройках Destination, для Table name, введите names_2014.
В настройках Schema, выберете Edit as text и введите этот код:
name:string,gender:string,count:integer
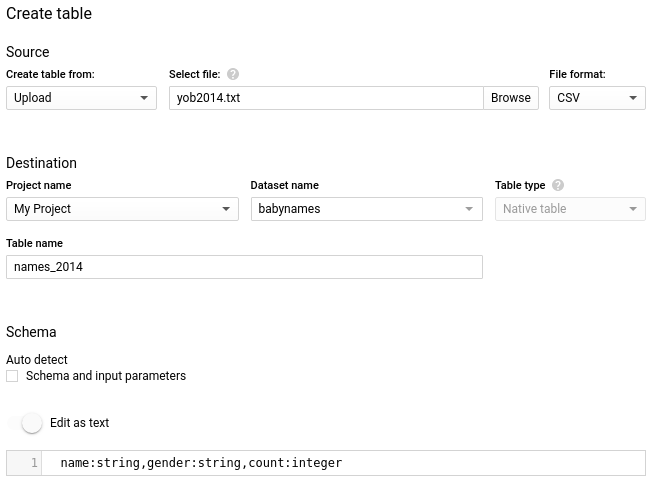
Нажмите Create table
Подождите пока BigQuery загрузит данные
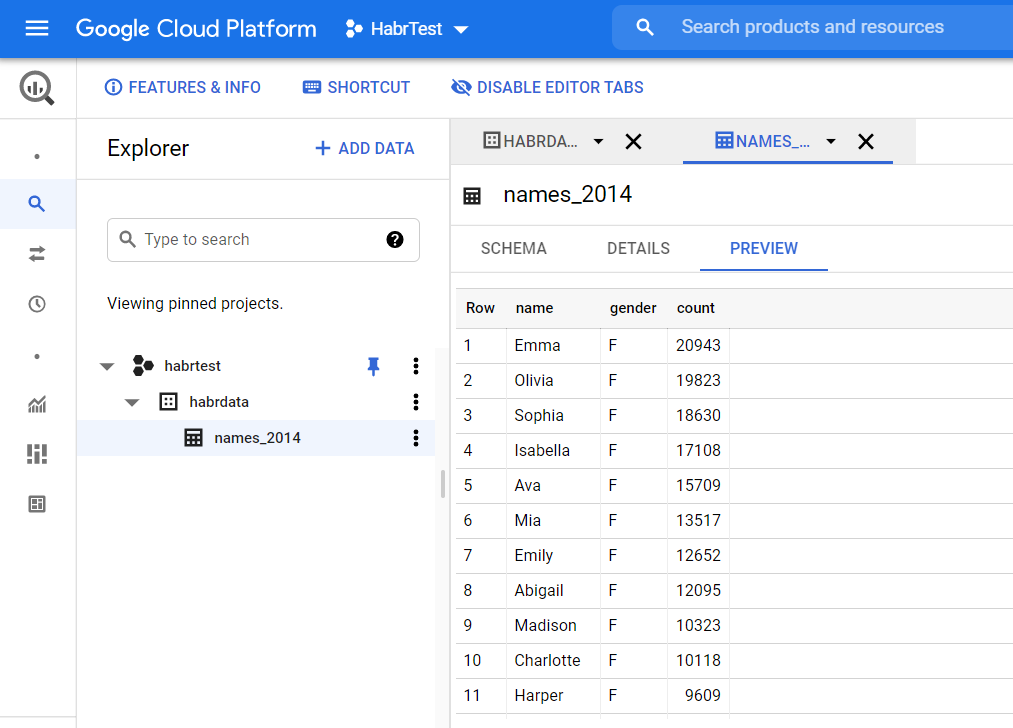
В панели навигации нажмите созданную таблицу и в открывшемся окне выберете вкладку Preview что бы посмотреть загруженные нами данные:
Запросы к данным
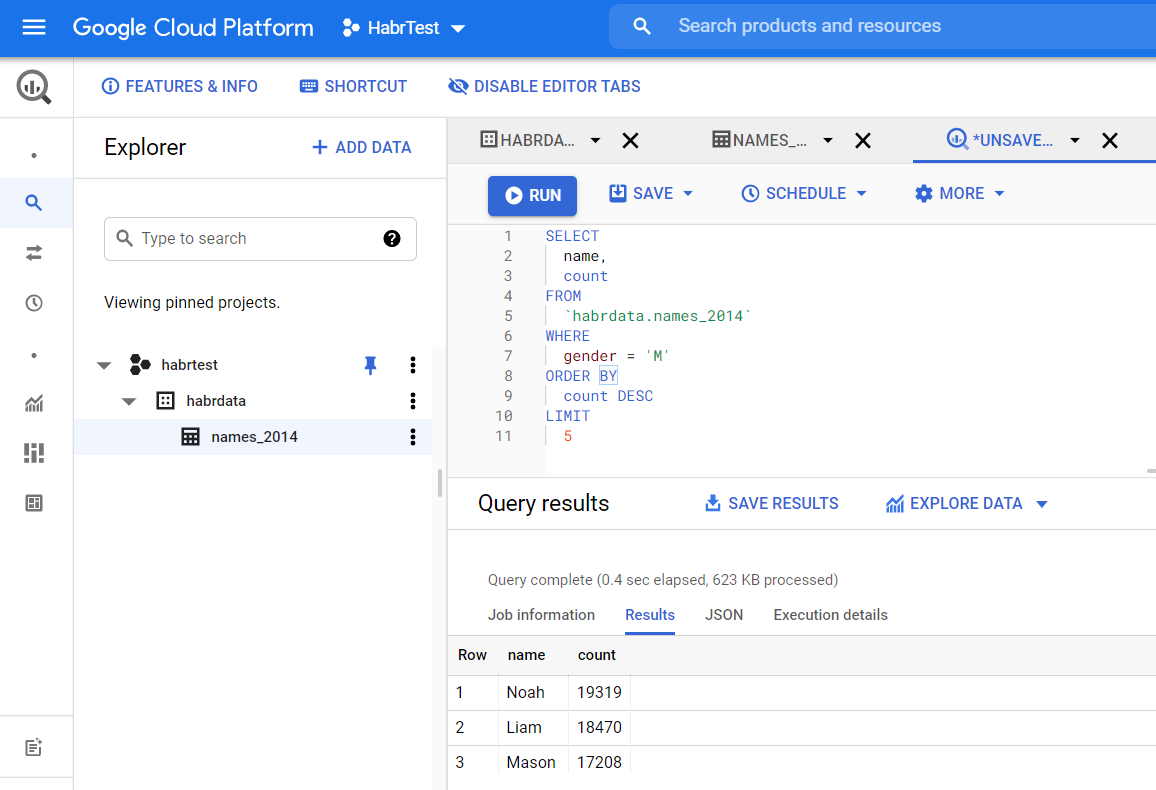
Нажмите Compose new query и в открывшемся редакторе введите этот код:
SELECT name, count FROM `habrdata.names_2014` WHERE gender = 'M' ORDER BY count DESC LIMIT 5
нажмите Run, отобразятся результаты запроса
Строим отчет
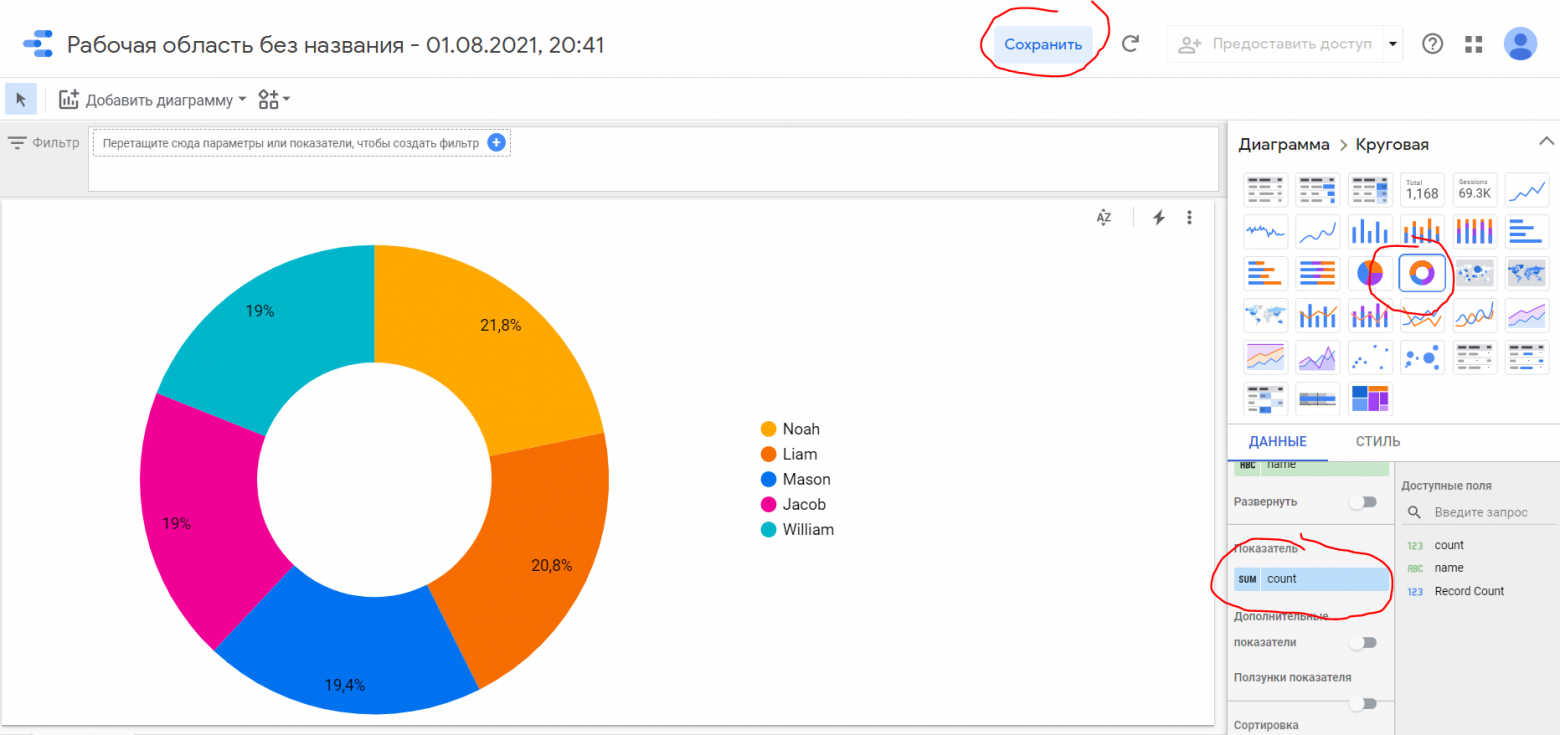
Сверху от результатов запроса нажмите Explore data
Дайте приложению Google Data Studio доступ к данным
В открывшемся дизайнере отчетов выберите тип диаграммы Кольцевая и в показатели добавьте поле count. Затем нажмите кнопку Сохранить
Выводы
Мы рассмотрели как за 10 минут зарегистрироваться в BigQuery, загрузить туда данные и построить отчет. Если вас заинтересовала эта технология - продолжайте читать. В следующей главе мы рассмотрим практические шаги по развертыванию BigQuery в компании.
Разворачиваем BigQuery в компании
Переходим на платный аккаунт
Ранее в примерах мы использовали режим песочницы. Часть функций в этом режиме не доступна. Например мы не можем выполнить sql инструкции Insert или Delete. Рекомендуем подключить платежный аккаунт. Напомню: вам будет предоставлен кредит на $300 и 90 дней для полноценного тестирования облачной платформы Google. Для начала перейдите по этой ссылке и следуйте инструкциям https://console.cloud.google.com/freetrial/signup.
Читаем литературу и документацию
Основной источник информации, вот эта книжка: Google BigQuery. Всё о хранилищах данных, аналитике и машинном обучении
А так же официальная документация.
Здесь рассмотрены сценарии миграции существующего хранилища данных в BigQuery.
Проектируем таблицы в хранилище
Информацию об этом вы найдете в книге. Если вы ранее создавали витрины данных для аналитиков, вы можете следовать тем же принципам. Для тех у кого мало опыта в этом читайте книжку. Построение таблиц в хранилище данных отличается от обычных схем-снежинок, так например иногда данные могут храниться в ненормализованном виде. Например информация о заказе покупателя (дата, имя клиента, адрес клиента) и информация о строчках заказов (товар, количество, сумма): в 90% случаях эти данные используются в одном запросе и есть смысл хранить их в одной таблице, повторяя данные о клиенте в каждой строчкой с товаром. Таким образом можно увеличить быстродействие запросов к данным.
Загружаем данные
Так выглядят основные пути загрузки данных по рекомендациям Google:

Дадим краткие пояснения по ним:
Можно загружать CSV и JSON файл с помощью консоли, как мы делали выше
Есть множество готовых интеграций c BigQuery для различных сервисов, например Google Analytics, и их становится все больше. Например мы в нашей компании разработали за последний год интеграции с BigQuery для нескольких российских облачных сервисов
Есть мощный ETL инструмент от Google - Cloud Data Fusion. Но он не дешевый.
Есть клиентская библиотека Google Cloud Client Library для BigQuery. Сейчас она доступна для семи языков: Go, Java, Node.js, Python, Ruby, PHP и C++. Вот пример загрузки данных с помощью Python из MS SQL Server в BigQuery:
from sqlalchemy import create_engine from pandas import DataFrame from google.cloud import bigquery import pandas import pytz # подключаемся к MS SQL engine = create_engine("mssql+pyodbc://(localdb)\MSSQLLocalDB/habrtest?driver= \ ODBC Driver 17 for SQL Server", fast_executemany=True) connection = engine.connect() # подключаемся к BigQuery с помощью сервисного аккаунта client = bigquery.Client.from_service_account_json('habrtest.json') # определяем таблицу в BigQuery для загрузки данных table_id = "habrtest.habrdata.tb2" # запрос к MS SQL для выборки данных resoverall = connection.execute('select * from Test') df = DataFrame(resoverall.fetchall()) df.columns = resoverall.keys() # отправляем данные в BigQuery job = client.load_table_from_dataframe(df, table_id) job.result()
Данный код будет работать только для платного аккаунта BigQuery (в песочнице не будет).
В целом по загрузке данных такие рекомендации: используйте где можно готовые интеграции, в остальных случаях стройте свои интеграционные процессы используя Google Cloud Client Library. Разработчики которые поддерживают информационные системы в вашей компании могут загружать данные с помощью Cloud Client Library в указанные вами таблицы с необходимой периодичностью.
Настраиваем безопасность
В Google Clooud Platform механизм управления идентификацией и доступом (Identity and Access Management, IAM). Он позволяет разграничить доступ к данным: https://console.cloud.google.com/iam-admin. Вы можете дать доступ к данным для учетной записи @gmail.com или @example.com, где example.com — это домен G Suite. Например таким образом вы можете дать вашим аналитикам доступ для анализа данных.
Так же вы можете создавать сервисные аккаунты: https://console.cloud.google.com/iam-admin/serviceaccounts для доступа приложений. Например вы можете создать тестовый аккаунт для ваших разработчиков 1С, передать им ключ доступа (JSON файл), а они используя этот ключ смогут загружать данные в BigQuery.
Уровень доступа определяется ролями. Ниже представлены эти роли, в порядке увеличения прав:
metadataViewer (полное имя roles/bigquery.metadataViewer) предоставляет доступ только к метаданным наборов данных, таблиц и представлений.
dataViewer предоставляет право читать данные и метаданные.
dataEditor предоставляет право читать наборы данных, а также перечислять, создавать, изменять, читать и удалять таблицы в наборе данных.
dataOwner добавляет возможность удалить набор данных.
readSessionUser предоставляет доступ к BigQuery Storage API, оплачиваемый за счет проекта.
jobUser позволяет запускать задания (и выполнять запросы), оплачиваемые за счет проекта.
user позволяет запускать задания и создавать наборы данных, хранение которых оплачивается за счет проекта.
admin позволяет управлять всеми данными в проекте и отменять задания, запущенные другими пользователями.
Работаем с данными
Данные загрузили, права раздали, значит можно извлекать из данных пользу. Вот основные возможности:
Делаем SQL запросы в консоли BigQuery. Документация по синтаксису запросов - https://cloud.google.com/bigquery/docs/reference/standard-sql а так же в книжке.
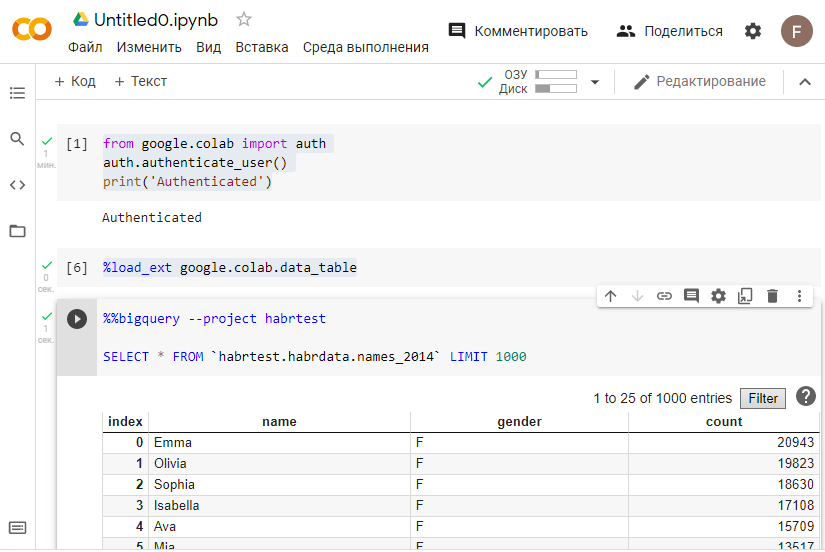
Работаем с BiqQuery в ноутбуках на Python. Пример кода для выборки данных из ранее созданной нами таблицы
from google.colab import auth auth.authenticate_user() print('Authenticated') %load_ext google.colab.data_table %%bigquery --project yourprojectid SELECT * FROM `habrtest.habrdata.names_2014` LIMIT 1000
Используем BI инструменты: Google DataStudio, MS Power BI, Tableau. У этих трех, и у многих других есть встроенные коннекторы к BigQuery

Ускоряем запросы с помощью BI Engine
Если есть таблицы, к которым вы часто обращаетесь из инструментов бизнес-аналитики, такие как информационные панели с агрегатами и фильтрами, для ускорения запросов можно воспользоваться движком BI Engine. Он автоматически сохраняет соответствующие фрагменты данных в памяти и использует специализированный процессор запросов. С помощью консоли администратора BigQuery Admin Console можно зарезервировать объем памяти (до 10 Гбайт), который BigQuery должна использовать для своего кеша: https://console.cloud.google.com/bigquery/admin/bi-engine. BI Engine платный: 1GB памяти будет стоить примерно $30 в месяц. Для пользователей Google DataStudio этот объем будет бесплатным. Здесь видео о том что такое BI Engine: https://youtu.be/kifUXfwqzVo
Подключаем модули машинного обучения
Модули BigQuery ML позволяют пользователям создавать и выполнять модели машинного обучения в BigQuery, используя стандартные запросы SQL.
Пример создания модели рекомендаций основании публичного набора данных о просмотре фильмов:
CREATE OR REPLACE MODEL ch09eu.movie_recommender_16 options(model_type='matrix_factorization', user_col='userId', item_col='movieId', rating_col='rating', l2_reg=0.2, num_factors=16) AS SELECT userId, movieId, rating FROM ch09eu.movielens_ratings
Получаем данные из модели, найдем лучшие комедийные фильмы, которые можно рекомендовать пользователю с идентификатором (userId) 903:
SELECT * FROM ML.PREDICT(MODEL ch09eu.movie_recommender_16, ( SELECT movieId, title, 903 AS userId FROM ch09eu.movielens_movies, UNNEST(genres) g WHERE g = 'Comedy' )) ORDER BY predicted_rating DESC LIMIT 5
Вот список типов задач машинного обучения, которые можно решать с помощью BigQuery ML:
Кластеризация
Регрессия
Рекомендации
Таргетинг клиентов (Выбор целевой аудитории для предложения продукта)
Бинарная классификация
Многоклассовая классификация
Классификация изображений, классификация текста, анализ эмоциональной окраски, извлечение сущностей
Ответы на вопросы, аннотирование текста, генерирование подписей к изображениям
Так же вы можете использовать в BigQuery ML TensorFlow.
За использование BigQuery ML взымается отдельная плата. Информация по ценам здесь.
Заключение
Мы затронули основные моменты, знание которых позволит вам запустить использование BigQuery в компании. BigQuery это реально очень крутая штука, рекомендую попробовать ее в деле. Есть возможность быстро загрузить данные из своих источников, начать строить отчеты и использовать машинное обучение. И все это без больших затрат а в некоторых случая вообще бесплатно. Буду рад ответить на вопросы в комментариях.

