Привет. Прошло уже почти полгода как я сделал новостной агрегатор каналов в Телеграме с открытым исходным кодом. Краткую статью про него можно прочитать на VC. Здесь же я бы хотел поделиться некоторыми интересными вещами, которые я нашёл в данных за всё время работы агрегатора.

Дисклеймер 1: многое из этого отчёта может показаться политизированным, особенно некоторые примеры новостей. Но здесь я не делаю никаких выводов про то, кто прав, а кто виноват; кто грязный пропагандист, а кто носитель священной истины.
Дисклеймер 2: это не руководство по визуализации данных средствами Plotly и PyVis. В самой статье я не привожу код и не объясняю, почему он устроен именно так. При этом Colab с кодом открыт, и примеры оттуда можно использовать для своих задач.
При подготовке этого отчёта я вдохновлялся несколькими вещами:
NewsViz - проект ODS ML4SG по визуализации тем в новостях, статья о нём. Впрочем, в финальной версии отчёта никаких тематических моделей нет, уж слишком они сложны для понимания.
Упомянутая в той же статье визуализация разницы освещения разных событий американскими телеканалами.
Описание данных
Всего в коллекции около 225 тысяч документов с 5 апреля по 6 августа из 59 каналов основного выпуска, и около 4 тысяч состоящих из них сюжетов. На картинке ниже можно увидеть распределение количества документов и сюжетов во времени.


Что тут можно увидеть:
меньшее количество документов по выходным
общее уменьшение количества документов до конца июля
рост в начале августа: добавил каналы для технологического выпуска
дыра в мае: закончилось место на диске и часть данных не сохранилась
уменьшение количества сюжетов в начале мая: измененил настройки кластеризации
Деление каналов по группам

Каналы в рамках основного выпуска новостей разделены на три категории: красные (прогосударственные, консервативные), синие (оппозиционные, зарубежные, либеральные) и фиолетовые (нейтральные).
Разделены они на глаз, но есть свидетельства того, что это деление разумное.
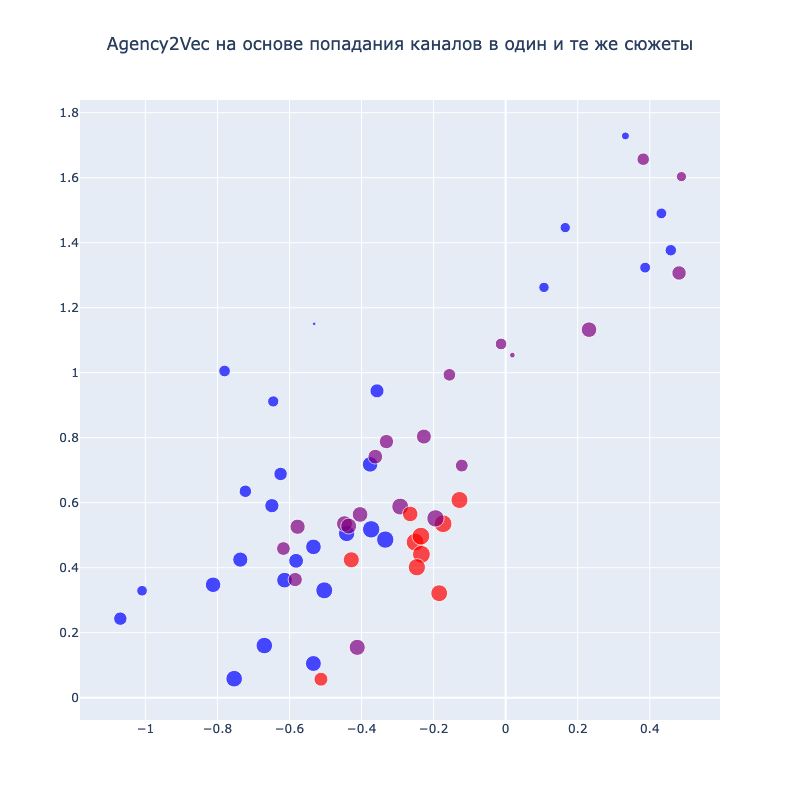
Первое свидетельство — Word2Vec-like модель, где вместо предложений сюжеты, а вместо слов каналы. В результате её работы для каждого канала получается вектор в некотором пространстве. Чем вероятнее каналы встречаются в одних и тех же сюжетах, тем ближе должны лежать их векторы. Подобная визуализация есть на картинке ниже. Цветами отмечены разные группы источников. Красная и синяя группы явно выделяются на этой картинке.
Другое свидетельство — граф цитирований. Рёбра в нём означают наличие цитирований одними каналами других, размер вершин — это их PageRank в этом графе.

Видно, что на пару красных источников ссылаются почти все. Но в остальном графе есть чёткие сети синих и красных каналов.
Есть ли события, освещаемые только одной стороной?
Первый способ ответить на этот вопрос — посмотреть сами сюжеты. Сэмплировать их можно по-разному, в таблицах ниже приведены самые просматриваемые (по совокупности просмотров на документах) и случайные сюжеты каждой из сторон.

Второй способ — облака слов.

В целом видно, что различия в освещаемых событиях есть. Обычно это либо события, выставляющие другую сторону в плохом свете, либо продвигающие свою точку зрения, либо просто локальные новости.
Правда ли, что одни и те же события могут освещаться по-разному?
На этот вопрос ответить немного сложнее. С одной стороны, у нас есть данные кластеризации, которая пыталась склеить документы про одно и то же. Мы могли бы посмотреть на наиболее отличающиеся документы от разных сторон внутри одного сюжета. С другой стороны, кластеризация делает ошибки, и большинство таких пар будут именно этими ошибками.
Поэтому я выбрал путь компромисса. Примеры ниже отобраны вручную среди всех подобных пар документов (внутри одного кластера + с разных сторон + с большим расстоянием между векторами) для показа наличия разных точек зрения на одни и те же события.

Содержание таблицы примерно отражает то, что мы видели на иллюстрации в самом начале статьи.
Есть ли запретные термины или типичные штампы?
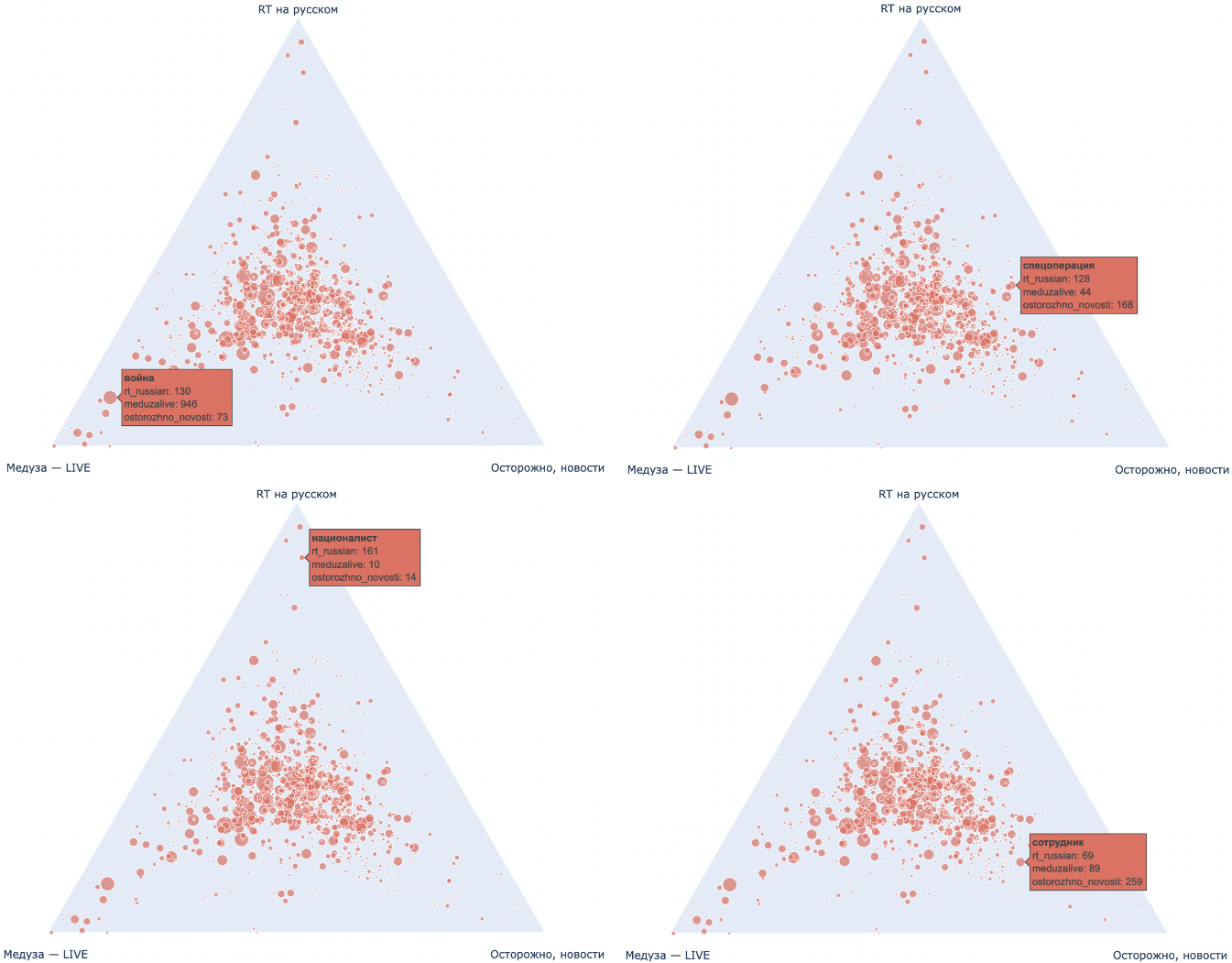
Здесь мы воспользуемся визуализацией отсюда. Идея в том, чтобы взять 3 источника с разными точками зрения и посчитать употребления ими разных слов. На картинке ниже я привожу 4 субъективно интересных примера слов-штампов, но в Колабе эта визуализация интерактивна.
Заключение
Здесь приведены не все возможные способы исследования полученных данных. Более того, приведённые здесь примеры — малая часть даже из моих экспериментов. Если ты, читатель, знаешь как сделать лучше — данные открыты и регулярно обновляются. Буду рад увидеть другую аналитику.
Основная же мысль этой статьи проста: будьте аккуратны с теми источниками информации, которые используете. Пользуйтесь новостными агрегаторами — так вы хотя бы будете получать информацию из разных источников. К тому же и новостных агрегаторов сейчас существует немало:
Яндекс.Новости (субъективно красный)
The True Story (субъективно синий, ещё не конца запустившийся)
НЯН (мой агрегатор, данные которого я здесь и использовал)
И как говорил классик, "берегите себя и своих близких!".
Ссылки
Код в Google Colab: ссылка на ноутбук
Оригинальные данные: ссылка на архив
Код агрегатора: ссылка на Github

