
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Все это исследование времени жизни заявок для арбитража никакого значения не имеет. При возникновении возможности арбитража заявки выкупаются за миллисекунды hft-роботами.
Во-первых, цепочек обменов может быть очень много. В этом случае поиск выигрышной стратегии, допустим, для двух арбитражеров с абсолютно одинаковыми техническими возможностями становится нетривиальной задачей. В предыдущей статье я как раз рассматривал пример, где наглядно показывается, что скорость вовсе не является гарантией успеха.
Во-вторых, на некоторых рынках, например, на p2p-платформах возможности для арбитража могут существовать неделями, но нет возможности для их автоматизации. В качестве примера также можно привести «синтетические» офферы: когда ставку делает сам арбитражер, создавая «звено» цепочки, вследствие чего модель становится вероятностной.
Устойчивое распределение очень схоже с гиперболическим: при больших значениях аргумента они убывают практически в точности, как гиперболы.
Кстати вы не пробовали сделать такую не совсем стандартную вещь как начертить гистограмму в двойных логарифмических координатах (возможно даже точками а не барами)? Так как вы рассматриваете устойчивые распределения с  и
и  , то есть те которые определены на положительной полуоси, если модельное распределение согласуется с эмпирическим, то вы увидите асимптотическое приближение точек к некоторой прямой хвоста на таком графике (эта прямая хвоста в таких координатах и есть гипербола). Вообще гиперболический хвост у L-устойчивого распределения должен убывать как
, то есть те которые определены на положительной полуоси, если модельное распределение согласуется с эмпирическим, то вы увидите асимптотическое приближение точек к некоторой прямой хвоста на таком графике (эта прямая хвоста в таких координатах и есть гипербола). Вообще гиперболический хвост у L-устойчивого распределения должен убывать как  (A - некоторая константа). Если мы считаем модель верной, то по углу наклона этой прямой можно также определять параметр
(A - некоторая константа). Если мы считаем модель верной, то по углу наклона этой прямой можно также определять параметр  .
.
То, что устойчивые распределения вылезают в данных изменениях цен и биржевых котировок (причем там альфа как правило больше 1) - это в принципе известно (хотя не так широко как хотелось бы), а вот что так распределено время жизни ордеров в стакане - немного подозрительно звучит. Я бы все же присмотрелся к хвосту. Как я указал выше, если такая модель верна, то он не может убывать быстрее чем  , а если брать максимальную альфу в модели, то не может убывать быстрее чем
, а если брать максимальную альфу в модели, то не может убывать быстрее чем  . То есть, если хвост по эмпирическим данным убывает быстрее чем , я бы не стал рассматривать такое распределение в качестве модельного для данного случая.
. То есть, если хвост по эмпирическим данным убывает быстрее чем , я бы не стал рассматривать такое распределение в качестве модельного для данного случая.
Благодарю за столь детальный комментарий с подробным разъяснением. Результаты вышли следующими, это однозначно стоило рассмотреть:

Действительно, для основательной проверки того, что время жизни ордеров лучше всего описывается односторонним устойчивым распределением, нужны данные лучшего качества. Из-за ограничений API данные были еще хуже, ввиду чего параметры любого подходящего закона можно подкручивать к данным практически идеально, поэтому от данной идеи пришлось полностью отказаться.
В целом, все обусловлено принципами работы с большими данными и операциями над ними, поэтому решили пробовать извлекать полезную информацию из книг методами ML.
То, что так теоретическая PDF против гиперболы выглядит это ожидаемо. Интересно все таки попробовать точки нанести эмпирических данных на такой log-log график (каждая точка = (<cредняя точка интервала бара гистограммы>, <относительная частота бара гистограммы>)). Неужели там очень сильный разброс получается?
Фактически на этом графике, что у вас в статье по оси частот log шкалу сделать, бары убрать, точки оставить
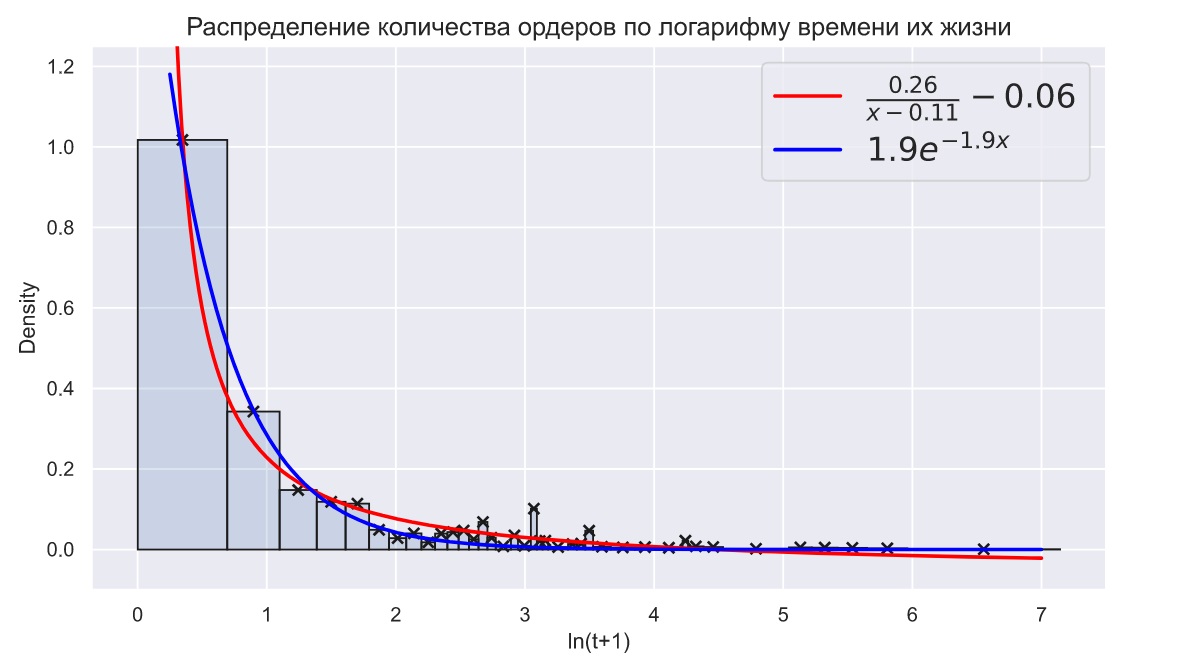
Хотя судя по этому графику может оказаться, что там бары в хвосте с нулевыми значениями есть - то есть придется перестраивать с другими интервалами, чтобы что-то вменяемое получить.
Метод максимального правдоподобия тут неуместен, просто потому что сама выборка является ограниченной и цензурированной. Получить что-то вменяемое действительно есть как цель, но это не должно быть достигнуто путем "подкручивания". Устойчивое одностороннее распределение - это именно гипотеза.
Взгляните еще раз на гифку в статье - это самый идеальный "подгон", и проблема как раз именно в этом. Книга ордеров - это место, в котором статистические методы как минимум перестают быть надежными. В этом случае уже ML выходит на передний план.
Продолжаем изучение арбитража криптовалют: прогноз срока жизни оффера