Into
Считается, что Julia – это нишевый язык созданный для лабораторий, научных симуляций и HPC.
Хотя на самом деле благодаря свой экспрессивности и динамизму Julia можно и нужно использовать для автоматизации и скриптинга.
Давайте на паре простых примеров посмотрим как Julia можно использовать для решения рутинных задач.
Ad-hoc analytics
С помощью Julia можно работать с данными используя привычные для Питонистов концепции и инструменты.
Вместо kaggle, попробуем подготовить свой собственный дата-сет.
Для этого нам понадобится несколько сторонних утилит: git и jq.
Centos:
yum install epel-release -y
yum install jq
Давайте клонируем какой-нибудь популярный репозиторий:
julia> run(`git clone https://github.com/freebsd/freebsd-src.git`)
julia> cd("freebsd-src/")
У FreeBSD долгая история и десятки тысяч коммитеров. Анализировать не структурированный лог-файл (примерно 170Мб) с помощью grep и AWK достаточно сложно,
поэтому давайте напишем небольшой скрипт, который конвертирует историю коммитов в JSON.
cmd = `git log --all --pretty=format:"%h%x09%an%x09%ad%x09%s" --date=short --no-merges`
cmd1 = `jq -R '[ inputs | split("\t") | { hash: .[0], author: .[1], date: .[2], message: .[3] }]'`
try
redirect_stdio(stdout="repo.json") do
run(pipeline(cmd, cmd1))
end
catch err
Pkg.Types.pkgerror("The command $(cmd) '|' $(cmd1) failed, error: $err")
end
Теперь необходимо скопировать содержимое файла repo.json в DataFrames – привычную для аналитиков структуру данных.
Для этого нужно будет установить пакеты DataFrames и JSON3.
julia> using DataFrames, JSON3
Создаем функцию-помощник для чтения JSON:
function read_json(file)
open(file,"r") do f
return JSON.parse(f)
end
end
Копируем содержимое файла в Data Frame:
julia> df = DataFrame(read_json("repo.json"))
Можно кстати использовать один из встроенных макросов – интересно будет сравнить насколько эта операция быстрее чем в Python:
julia> @time df = DataFrame(read_json("repo.json"))
29.901792 seconds (49.18 M allocations: 2.809 GiB, 14.31% gc time)
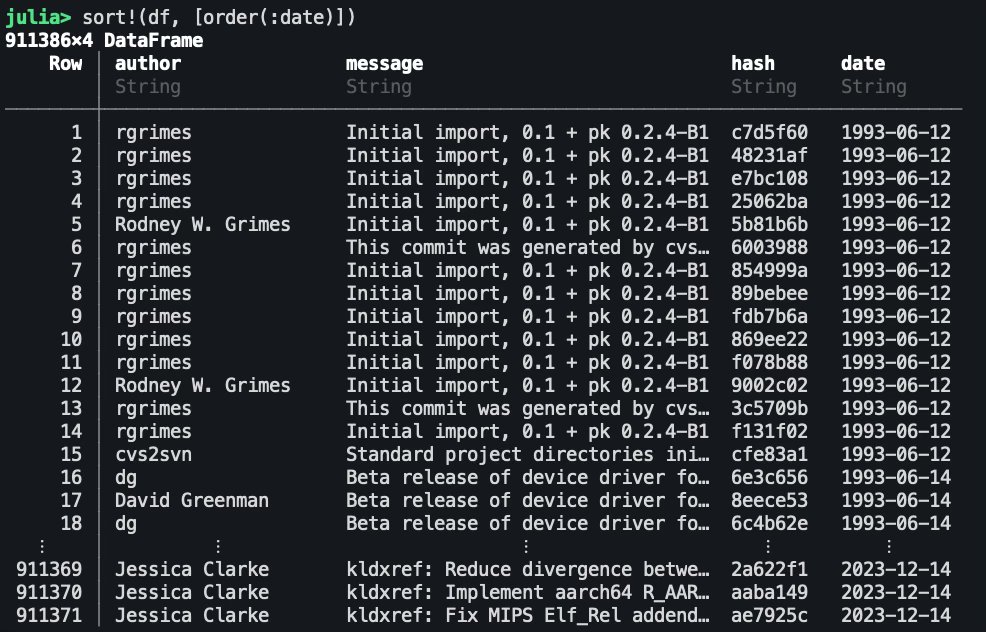
Отсортируем DataFrame по дате:
julia> sort!(df, [order(:date, rev=true)])
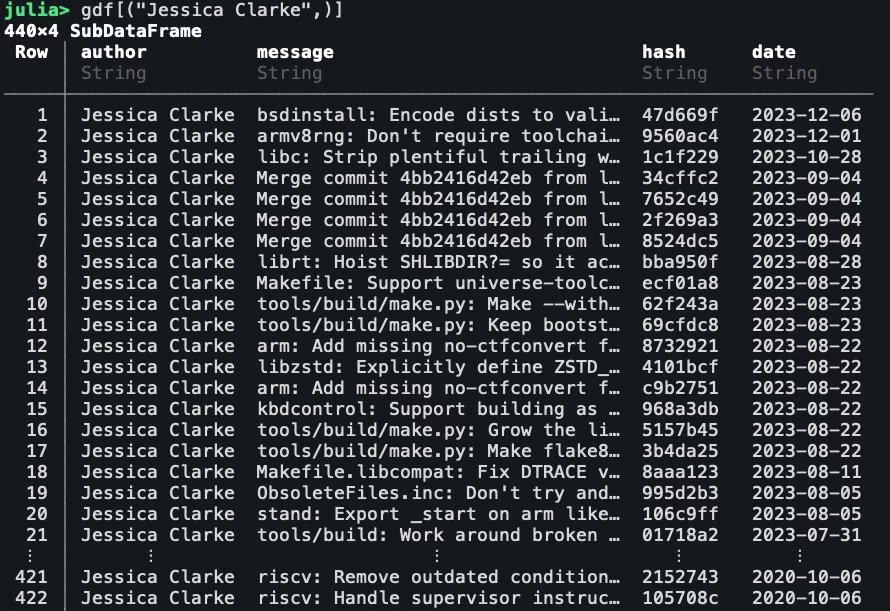
Как группировать по определенному значению в датасете? Например имя автора коммита:
julia> gdf = groupby(df, :author)
julia> gdf[("Jessica Clarke",)]
Scripting
Если нужно быстро написать небольшой скрипт для git-hooks, CI/CD, резервного копирования, то Julia прекрасно справляется с этой задачей.
Компактный синтаксис и REPL позволяют парсить и склеивать вывод системных утилит не хуже чем на Bash:
#!/usr/bin/env julia
if isdir(".git") println
@info("== Remote Branches: ")
run(`git branch -r`)
@info("== Local Branches: ")
run(`git branch`)
@info("== Configuration (.git/config)")
run(`cat .git/config`)
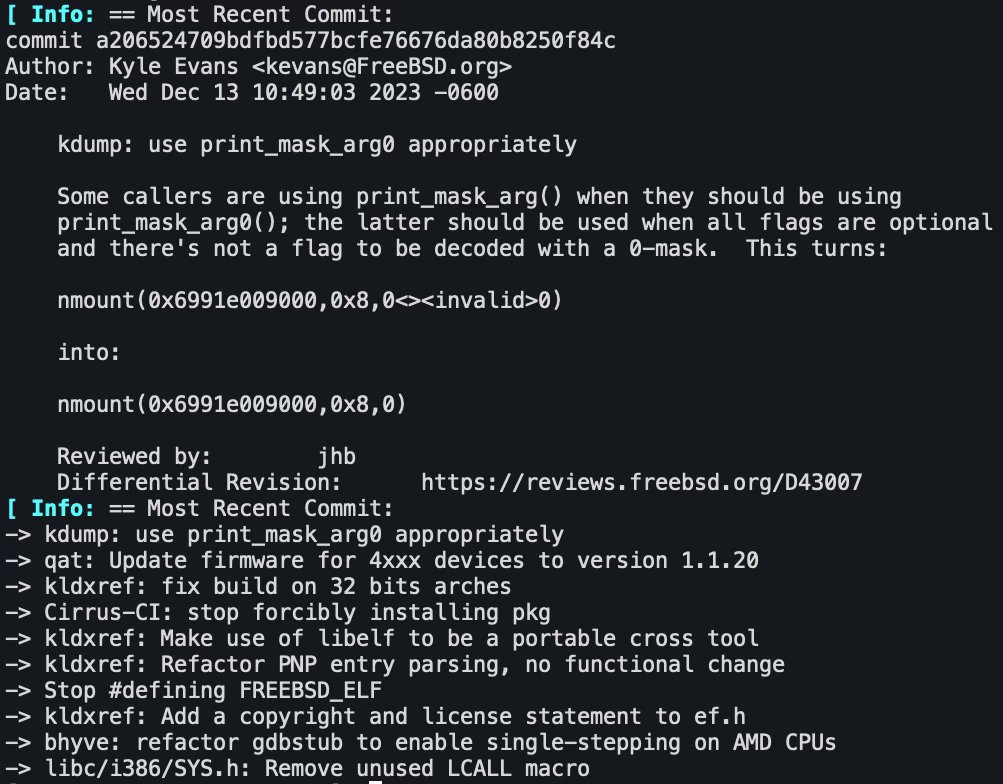
@info("== Most Recent Commit: ")
run(` git --no-pager log --max-count=1`)
@info("== Most Recent Commit: ")
run(`git log --pretty=format:"-> %s" --before=today -10`)
else
println("Not a git repository.")
end
Давайте выполним скрипт:
chmod +x git-info.jl
./git-info.jl
Этот скрипт только выводит информацию о текущем репозитории Git, но если нам нужно будет сделать что-то посложнее, то в отличие от Bash,
на Julia есть готовая библиотека для парсинга аргументов – ArgParse.jl.
Pluto & CSV
Pluto.jl – это Jupyter notebook, для Julia. Пока он уступает по возможностям и в "отполированности" Jupyter, но проект постоянно развивается.
Для того, чтобы запустить Pluto в удаленном режиме:
julia> using Pluto
Нужно будет запустить web Ui Pluto:
julia> Pluto.run(host="0.0.0.0", port=11234)
[ Info: Loading...
┌ Info:
└ Go to http://0.0.0.0:11234/?secret=coDN9HGC in your browser to start writing ~ have fun!
┌ Info:
│ Press Ctrl+C in this terminal to stop Pluto
Скопируйте адрес (http://IP_ADDR:11234/?secret=coDN9HGC) в браузер и поменяйте IP адрес.
В ноутбуке в первой ячейке нужно будет загрузить пакеты DataFrames, CSV:
julia> using CSV, DataFrames
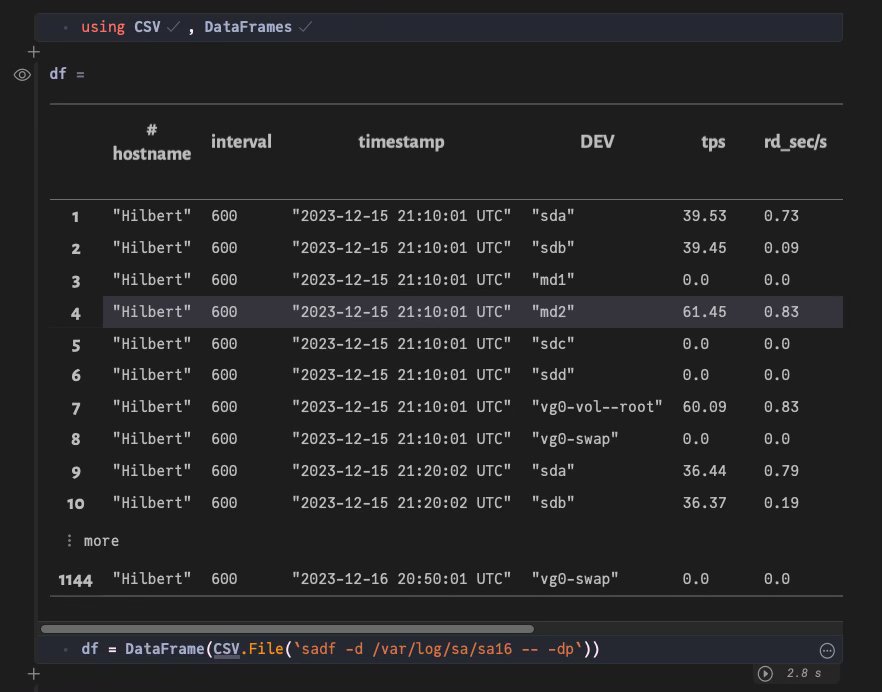
Sadf и sar – это две утилиты, которые входят в пакет Sysstat – демон мониторинга,
который используется мониторинга и сбора системных метрик. Мы будем использовать его в качестве примера дата-сета:
julia> df = DataFrame(CSV.File(`sadf -d /var/log/sa/sa16 -- -dp`))
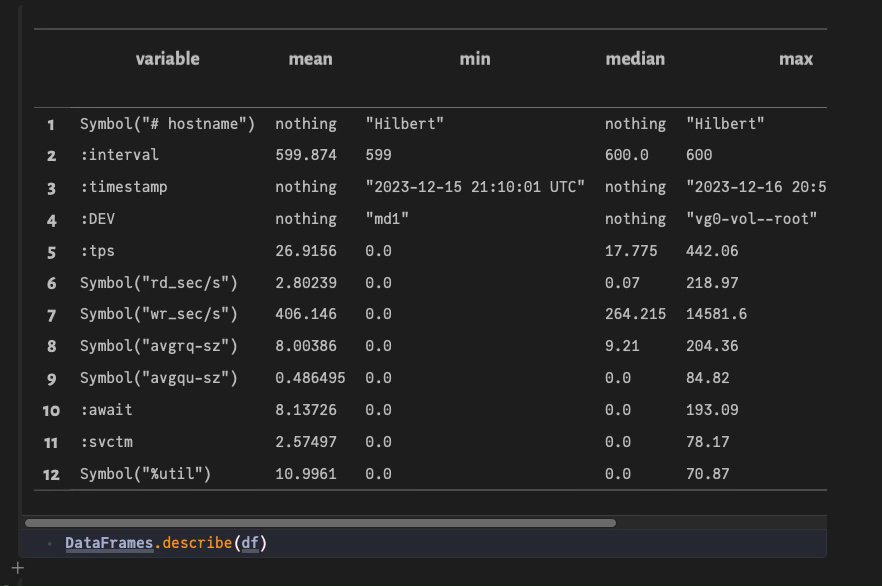
Можно вывести более подробную информацию о созданном дата-сете:
julia> DataFrames.describe(df)
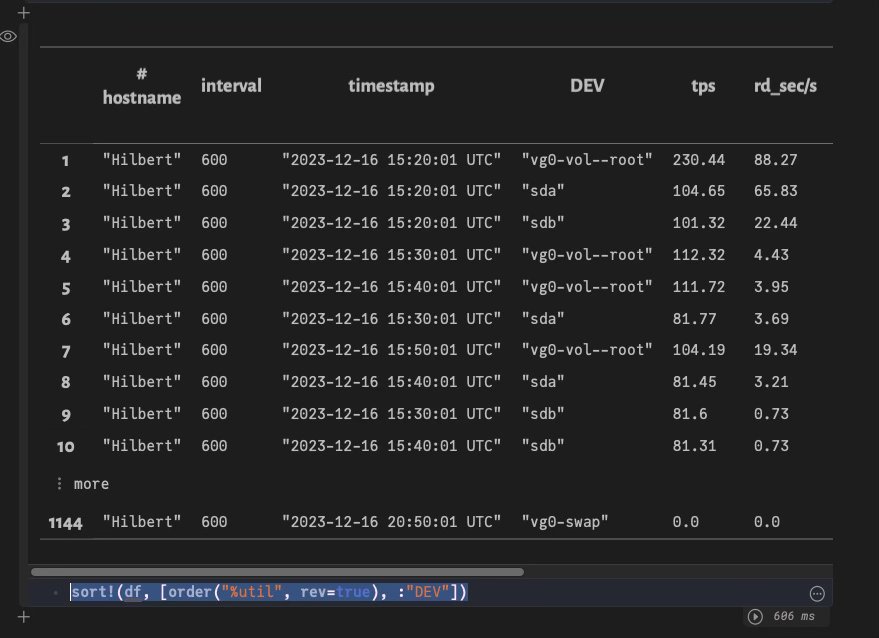
Отсортировать сетевые устройства по утилизации:
julia> sort!(df, [order("%util", rev=true), :"DEV"])
Для парсинга вывода sar отлично подходит grep, sed и AWK, а для мониторинга распределенных систем Prometheus и Grafana. Но если вам нужно «склеить» с помощью join несколько разных дата-сетов (табулярные данные и не структурированные логи) и построить графики на основе этих данных, то для решения этих задач отлично подойдет Julia:
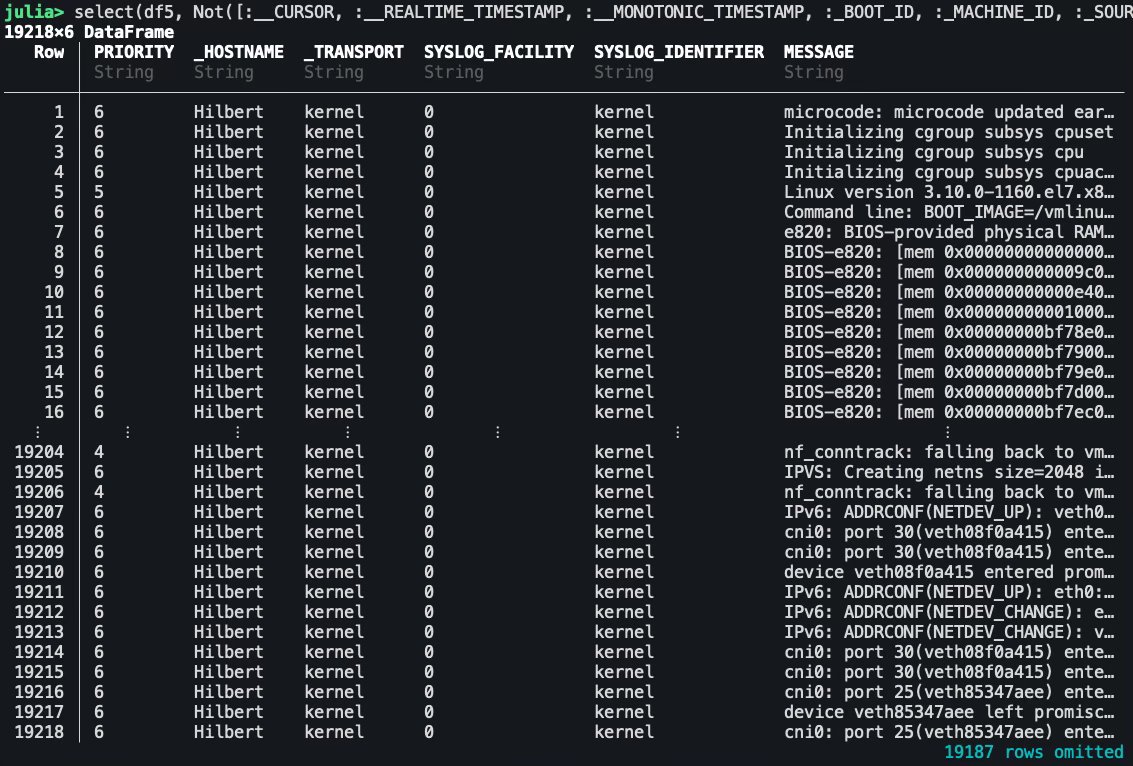
julia> j = JSON3.read(`journalctl -k -b -o json-pretty`, jsonlines=true)
julia> df = DataFrame(j)
julia> select(df5, Not([:__CURSOR, :__REALTIME_TIMESTAMP, :__MONOTONIC_TIMESTAMP, :_BOOT_ID, :_MACHINE_ID, :_SOURCE_MONOTONIC_TIMESTAMP]))
End
Авторы Julia в своем манифесте Why We Created Julia ставили перед собой определенные цели:
"We want something as usable for general programming as Python, as easy for statistics as R, as natural for string processing as Perl, as powerful for linear algebra as Matlab, as good at gluing programs together as the shell. Something that is dirt simple to learn, yet keeps the most serious hackers happy. We want it interactive and we want it compiled."
Не все из того, что они планировали удалось воплотить в жизнь, Julia не идеальна. Получился Lisp, который взял все лучшее у Python (julia --lisp).
Язык на котором хочется написать библиотеку, даже если вы никогда до этого на нем ничего не писали.
PS. Может быть это станет началом «Automate the boring stuff with Julia» :)






