Привет, Хабр!
В back in 2007 трое гуру из Google — Роб Пайк, Кен Томпсон и Роберт Гриземер — решили, что мир нуждается в чем-то свежем и быстром. Они метили на упрощение процесса разработки, но при этом хотели сохранить весь перфоманс на уровне C. И вот, в 2009 году появился Golang.
Первые версии были далеки от совершенства, но с каждым релизом Go становился только круче. Garbage collector, goroutines, channels — эти фичи сделали Go особенным. С каждым апдейтом Go становился только быстрее и надежнее. И не забудем про экосистему — с каждым годом она росла как на дрожжах, предлагая всё новые инструменты и библиотеки.
С версии 1.5 компилятор Go сам начал компилироваться в Go. С тех пор производительность только растет. JIT, улучшения в escape analysis, введение модулей в версии 1.11 — каждая фича делала Go всё более мощным.
В последних версиях появились дженерики, которые все так долго ждали. Это был следующий шаг в удобстве написания кода в go.
Архитектура
Компилятор Go не просто черный ящик, который берет на входе код и выдает бинарник. Он скорее похож на хорошо отлаженный конвейер, где каждый этап выполняет свою роль.
Классически, компилятор делится на две большие части: frontend, который занимается пониманием и анализом вашего кода, и backend, который отвечает за генерацию машинного кода.
В части фронтенда исходный код проходит через несколько этапов. Лексический анализ разбивает ваш код на токены, как если бы вы разрезали строку на слова и знаки пунктуации. Синтаксический анализ берет эти токены и строит из них абстрактное синтаксическое дерево (AST).
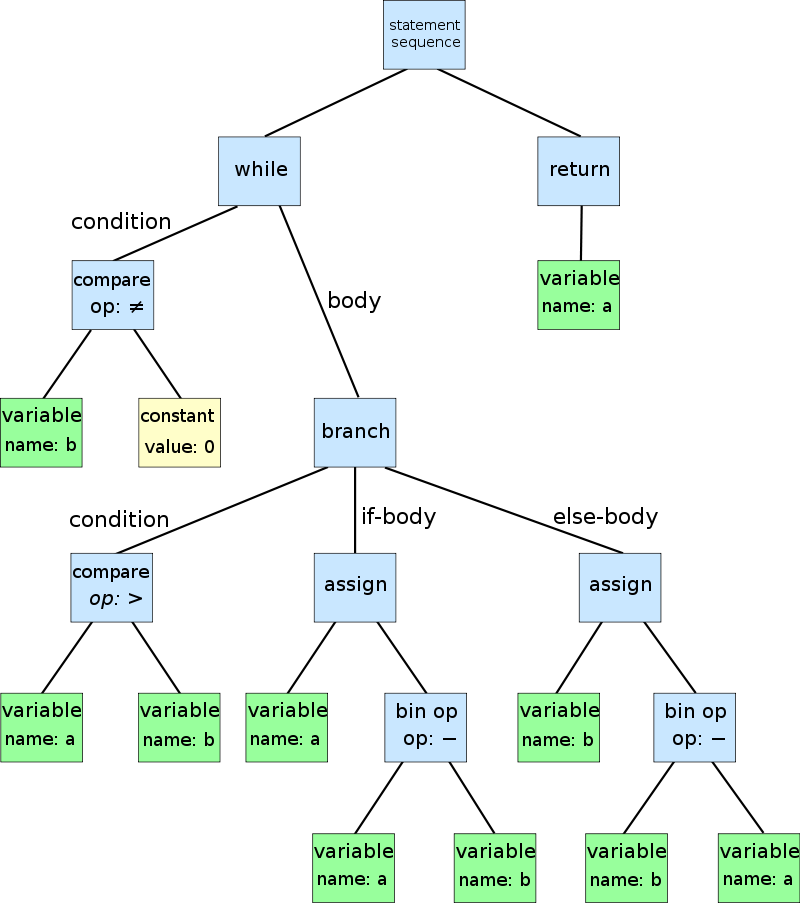
После этого идет семантический анализ, где компилятор проверяет, все ли в порядке с типами данных и другими важными вещами.
Как только AST готово. AST преобразуется в специфический для платформы машинный код. Это сложный процесс, включающий в себя оптимизации, выбор правильных инструкций процессора и многое другое.
Основные компоненты
Lexer
Lexer (Лексический анализатор) — это первый этап компиляции, где ваши исходники превращаются в понятный для компьютера набор токенов.
Лексер начинает с чтения вашего кода.
Как только лексер натыкается на известные ему конструкции (ключевые слова, операторы, идентификаторы и т.д.), он вырезает их из текста и превращает в токены. Каждый токен — это пара: тип токена и его значение. Например, для var myVar = "Hello" лексер сгенерирует токены VAR, IDENTIFIER(myVar), ASSIGN, и STRING("Hello").
Благодаря простому синтаксису Go, лексер работает очень быстро. Он не должен учитывать сложные исключения и правила, как в некоторых других языках. Если лексер находит что-то непонятное, он не паникует, а сообщает об ошибке.
package main
import (
"fmt"
"regexp"
"strings"
)
// типы токенов
const (
TOKEN_VAR = "VAR"
TOKEN_IDENTIFIER = "IDENTIFIER"
TOKEN_ASSIGN = "ASSIGN"
TOKEN_STRING = "STRING"
TOKEN_UNKNOWN = "UNKNOWN"
)
// token представляет собой структуру токена
type Token struct {
Type string
Value string
}
// lexer представляет собой структуру лексера
type Lexer struct {
source string
tokens []Token
position int
}
// создаем новый лексер
func NewLexer(source string) *Lexer {
return &Lexer{source: source}
}
// Tokenize выполняет лексический анализ исходного кода
func (l *Lexer) Tokenize() []Token {
// Регулярные выражения для распознавания токенов
patterns := map[string]*regexp.Regexp{
TOKEN_VAR: regexp.MustCompile(`\bvar\b`),
TOKEN_IDENTIFIER: regexp.MustCompile(`\b[a-zA-Z_][a-zA-Z0-9_]*\b`),
TOKEN_ASSIGN: regexp.MustCompile(`=`),
TOKEN_STRING: regexp.MustCompile(`"([^"]*)"|'([^']*)'`),
}
for l.position < len(l.source) {
if strings.TrimSpace(l.source[l.position:]) == "" {
break
}
found := false
for tokenType, pattern := range patterns {
loc := pattern.FindStringIndex(l.source[l.position:])
if loc != nil && loc[0] == 0 {
value := l.source[l.position+loc[0]:l.position+loc[1]]
l.tokens = append(l.tokens, Token{Type: tokenType, Value: value})
l.position += loc[1]
found = true
break
}
}
if !found {
l.tokens = append(l.tokens, Token{Type: TOKEN_UNKNOWN, Value: string(l.source[l.position])})
l.position++
}
}
return l.tokens
}
func main() {
source := `var myVar = "Hello"`
lexer := NewLexer(source)
tokens := lexer.Tokenize()
for _, token := range tokens {
fmt.Printf("Тип: %s, Значение: %s\n", token.Type, token.Value)
}
}Token: представляет собой структуру токена с типом и значением.Lexer: содержит исходный текст и методTokenize, который сканирует текст и генерирует токены.
Parser
Parser (Синтаксический анализатор) — это компонент компилятора, который берет линейную последовательность токенов от лексера и превращает ее в дерево, отражающее структуру кода.
В Go, как и во многих языках, парсер строит AST, но делает это со своими особенностями. Парсер начинает свою работу с получения токенов от лексера. Эти токены содержат информацию о типе элемента (например, идентификатор, ключевое слово) и его значении.
Парсер анализирует последовательность токенов и по правилам синтаксиса Go строит AST. Каждый узел в AST соответствует конструкции в исходном коде, будь то оператор, выражение, объявление и так далее.
Go обычно использует метод рекурсивного спуска для парсинга, что означает, что он рекурсивно вызывает функции для разбора каждой конструкции языка. Если парсер сталкивается с чем-то неожиданным или не соответствующим синтаксису Go, он сообщает об ошибке.
Go предоставляет инструменты, которые используют AST для анализа и форматирования кода:
gofmt: автоматически форматирует код Go, делая его более читаемым и соответствующим стандартам.
go vet: анализирует AST на предмет частых ошибок или подозрительных конструкций.
package main
import (
"fmt"
)
// определения типов токенов и узлов AST
type TokenType string
type Node interface {
String() string
}
const (
TOKEN_IDENTIFIER TokenType = "IDENTIFIER"
TOKEN_ASSIGN TokenType = "ASSIGN"
TOKEN_NUMBER TokenType = "NUMBER"
)
type Token struct {
Type TokenType
Value string
}
type ExpressionNode struct {
Left Node
Operator Token
Right Node
}
func (n *ExpressionNode) String() string {
return fmt.Sprintf("(%s %s %s)", n.Left, n.Operator.Value, n.Right)
}
type IdentifierNode struct {
Value string
}
func (n *IdentifierNode) String() string {
return n.Value
}
type Parser struct {
tokens []Token
current int
}
func NewParser(tokens []Token) *Parser {
return &Parser{tokens: tokens, current: 0}
}
// ParseExpr анализирует выражения
func (p *Parser) ParseExpr() Node {
// Базовый пример парсинга бинарного выражения
left := p.ParseIdentifier()
if p.current < len(p.tokens) {
op := p.tokens[p.current]
p.current++
right := p.ParseIdentifier()
return &ExpressionNode{Left: left, Operator: op, Right: right}
}
return left
}
// ParseIdentifier анализирует идентификаторы
func (p *Parser) ParseIdentifier() Node {
if p.current < len(p.tokens) && p.tokens[p.current].Type == TOKEN_IDENTIFIER {
token := p.tokens[p.current]
p.current++
return &IdentifierNode{Value: token.Value}
}
return nil // Возвращается nil в случае ошибки
}
func main() {
// Пример последовательности токенов
tokens := []Token{
{Type: TOKEN_IDENTIFIER, Value: "x"},
{Type: TOKEN_ASSIGN, Value: "="},
{Type: TOKEN_NUMBER, Value: "42"},
}
parser := NewParser(tokens)
ast := parser.ParseExpr()
fmt.Println(ast)
// Вывод: (x = 42)
}Type checker
Type checker (Проверка типов) — это компонент компилятора Go, который удостоверяется, что все операции в вашем коде типологически корректны. Он проверяет, что вы не пытаетесь выполнить операции, которые не имеют смысла, например, сложить строку и число или вызвать метод на переменной неподходящего типа.
После того, как парсер построил AST, Type Checker начинает сбор информации о типах всех переменных, функций, и т.д.
Для каждой операции (например, сложения, присваивания, вызова функции) Type Checker удостоверяется, что типы операндов соответствуют ожидаемым. Если вы пытаетесь сделать что-то нелогичное, например сложить строку и число, он поднимет флаг.
В Go есть механизм автоматического вывода типов, который помогает уменьшить количество кода, который вам нужно написать. Type Checker использует этот механизм для определения типов там, где они не указаны явно.
Если Type Checker находит несоответствие типов, он не просто молчит, он активно сообщает об этом, предоставляя информацию о том, что пошло не так, и даже в каком месте кода это произошло.
Проверка типов помогает предотвратить множество распространенных ошибок, таких как попытка обращения к методам, которые не существуют для данного типа, или некорректные операции с данными.
Представим, что у нас есть следующий код:
var a int = 10
var b string = "10"
var c = a + bType checker поднимет флаг на строке с c = a + b, указывая, что сложение int и string недопустимо.
Или если у нас есть функция:
func add(x int, y int) int {
return x + y
}И вы пытаетесь вызвать add("this", "that"), Type Checker сразу скажет, что это не сработает.
Optimizer
Optimizer (Оптимизатор) – это набор алгоритмов, которые анализируют и трансформируют код для улучшения его производительности и уменьшения размера.
Если часть кода никогда не выполняется, оптимизатор уберет ее. Когда маленькие функции встраиваются прямо в место их вызова, это уменьшает накладные расходы на вызов функций
Если компилятор видит выражение, значение которого он может вычислить на этапе компиляции (например, 2 + 2), он заменит его на результат (4). Оптимизатор пытается использовать процессорные регистры наиболее эффективно, чтобы минимизировать медленные обращения к памяти.
К примеру если у нас есть цикл, который вычисляет сумму чисел от 1 до 100. Оптимизатор может заменить весь цикл на одно вычисление, используя формулу арифметической прогрессии, и ваш код будет выполняться мгновенно.
Code generator
Code generator (Генератор кода) — это фаза в компиляторе Go, которая берет оптимизированное AST и превращает его в инструкции, понятные процессору вашего компьютера.
Каждая операция в коде соответствует определенной инструкции или набору инструкций на уровне машины:
Определение целевой архитектуры: Прежде всего, генератор кода должен знать, под какую архитектуру он компилирует код — это может быть x86, ARM, MIPS и так далее. Каждая архитектура имеет свой набор инструкций.
Анализ операций: Для каждой операции в AST (например, сложение, вызов функции, доступ к памяти) генератор кода определяет, какая машинная инструкция или последовательность инструкций соответствует данной операции.
Некоторые процессоры могут иметь специальные инструкции для часто используемых операций, таких как векторные вычисления или атомарные операции, и генератор кода старается использовать их для ускорения работы.
Регистры — выступают рабочей памятью процессора, доступ к которой происходит мгновенно.
Генератор кода анализирует, какие переменные и когда используются в программе, чтобы определить, какие из них следует хранить в регистрах.
На основе этого анализа генератор кода решает, какие значения будут храниться в регистрах, а какие — в памяти. Идея состоит в том, чтобы максимально использовать ограниченное количество регистров для наиболее часто используемых данных.
Если регистров не хватает для всех необходимых значений, некоторые из них будут временно перемещены в память и загружены обратно при необходимости.
В конце генератор кода превращает инструкции и данные в бинарный формат, который может исполнить процессор:
Каждая машинная инструкция преобразуется в последовательность битов — это и есть код, который будет исполнять процессор.
Инструкции и данные упаковываются в формат исполняемого файла (например, ELF для Linux или PE для Windows), который содержит информацию о том, как операционная система должна загрузить и выполнить программу.
Если программа использует библиотеки или модули, генератор кода должен сконнектить их с основной программой, правильно разместив вызовы функций и доступы к данным.
Garbage collection
Go использует алгоритм три-цветной маркировки для GC. В этом алгоритме объекты в памяти маркируются тремя цветами:
Белый: Объекты, которые еще не были достигнуты.
Серый: Объекты, которые были достигнуты, но их дочерние объекты еще не обработаны.
Черный: Объекты, которые и их дочерние объекты были полностью обработаны.
В начале процесса все объекты белые. По мере продвижения алгоритма, объекты переходят от белого к серому и, наконец, к черному. В конце процесса все достижимые объекты будут черными, а недостижимые (белые) могут быть собраны.
Go всегда стремится к минимизации пауз в работе программы из-за GC.
Компилятор Go помогает в процессе GC на нескольких уровнях:
На этапе компиляции проводится анализ "убегания" переменных. Если компилятор определяет, что переменная не убегает из своей области видимости (то есть не становится доступной вне своей функции), то она может быть выделена на стеке, а не в куче, уменьшая нагрузку на GC.
Компилятор вставляет специальный код, который помогает среде выполнения отслеживать ссылки на объекты и управлять жизненным циклом объектов.
Переменная среды GOGC позволяет настроить частоту сбора мусора, указывая, на сколько процентов должна увеличиться куча перед следующим сбором мусора.
Компилятор Go продолжает развиваться и улучшаться благодаря усилиям сообщества.
