Прошлый год в Computer Vision запомнился тем, что появилось множество больших претрейненных сетей (Fondation Models). Самая известная - GPT4v (ChatGPT с обработкой изображений).
В статье я попробую простым языком объяснить что это такое (для тех кто пропустил), как меняет индустрию. И когда можно будет выгнать на мороз лишних "ресерчеров".
Поговорим о следующем:
Что вообще такое "предтрейненные сети"
Где они используются?
Можно ли заменить ими обучение/разработчиков?
Какие есть ограничения?
Что будет дальше?

Совсем чуть-чуть теории и контекста
Fondation Models нужны для того чтобы не собирать датасеты. Чтобы из коробки работала классификация, детекция, сегментация, аналитика и все такое. В идеальном мире такие сетки должны использоваться как сети-учителя для маленьких сетей, как production-ready системы, как команду разметки, как аналитика.
Смысл больших предтрейненных сетей для Computer Vision проще всего показать на примере FaceRecognition.
Никто не "учит" сетку по каждому человеку отдельно. Сетки учат генерить стабильный "хэш" на базе из миллиона людей. Это называется "эмбеддинг". И чтобы понять насколько один человек похож на другого смотрят близость между хэшами.
Чем больше изображений при обучении, тем стабильнее сеть. Она может работать с разными поворотами лиц, от освещением, возрастом.

То же самое большие претрейн сетки делают и с фотографиями. Учатся на миллионных базах выдавать стабильные хэши.
Показал какой-то предмет. И все аналогичные предметы теперь имеют близкий хэш. Теперь вам не надо собирать огромные датасеты. Достаточно десяток картинок для обучения и ваша задача решена. В теории.
Для обучения таких сеток есть два-три основных высокоуровневых способа:
Первый - через текстовое описание. Например это используется в CLIP. Нейронная сеть построена таким образом чтобы минимизировать дистанцию от ембеддинга сети и ембеддинга текста. Почти так же учат мультимодальные модели.
Второй подход частично пересекается с первым. Возьмем все датасеты которые есть - и обучим их с одним бэкбоном(нижняя часть сетки). Верхушка этого бекбона - и будет достаточно универсальным описанием изображения. Обычно прямо сходу это не работает, а поверх такого бекбона что-то дотренировывают. Такой подход был популярен пару лет назад, сейчас вижу все реже и реже. Примером является, например InternImage. Такие подходы тоже часто мультимодальные.

Другой подход - через SSL (self-supervised learning). Обрезаем изображение двумя разными способами (а можно повернуть или аугментировать другими способами). Просим сеть минимизировать расстояние между ними. И максимизировать с другими изображениями. Dino, I-Jepa и много других моделей натренировано именно так.

Это не все способы (например Segment Anything не попадает в классификацию), но для большинства задач они лежат в основе.
Все что написано выше не отвечает на вопросы:
Как на базе этого "эмбеддинга" делать One-Shot детекцию и сегментацию.
Как это дело интегрируется в LLM нейронки. Например GPT4V и Gemeni.
Я пройдусь по основным сеткам, и проговорю те механики которые там есть для решения этих проблем. И заодно расскажу зачем эти сетки нужны.
К основным Fondation Models я бы отнес:
CLIP и его производные
CLIP - достаточно старая сеть, но до сих пор часто где работает. Его часто используют чтобы найти похожие фотографии, найти аномалии, упростить разметку. CLIP бывает и супер большим и достаточно маленьким. Может работать даже на embedded устройствах (вот тут я показываю несколько примеров для разных железок). Минус CLIP'а - он очень плох для любых мелких изображений, плохо работает для сцен где слабо что-то поменялось но сильно поменялся смысл.
Для CLIP достаточно много моделей и их постоянно апдейтят:

DINOv2
Большая сеть от FaceBook. Для обучения были потрачены большие вычислительные мощности. Кто-то оценивал что аренда таких мощностей на Амазоне стоила бы порядка десяти миллиона долларов. Работает и в медицине и в аэрофотосъемке. Dinov2 генерит не одну фичу на все изображения, а одну фичу на каждый квадрат 14*14 пикселей. Это дает куда больше понимание происходящего, и решает часть проблем CLIP.

Здесь разница цвета показывает насколько близки фичи (дистанция в N-мерном пространстве). Плюс, фон был отрезан методом главных компонент.
Для DINOv2 много сходных сетей. Например I-JEPA, iBot, etc. Я бы сказал что основное отличие DINOv2 - нигде больше нет такого хорошего и качественного претрейна по огромному датасету с такой открытой лицензией. Но при тренировке по своему датасету лучше выбрать I-JEPA.

Через небольшой тюнинг DINOv2 решает массу задач. Детекция, поиск аномалий, one-shot learning и многое другое.
Но сам по себе Dinov2 не очень удобный инструмент для новичков. Главная фича не сильно лучше чем CLIP (если брать последние релизы на хорошей архитектуре). А более низкоуровневыми фичами надо уметь пользоваться.
InternVideo ViCLIP
InternVideo ViCLIP - одна из самых сильных нейронок для создания эмбеддингов видео. Я бы сказал что это единственная CLIP подобная модель для видео с хорошим качеством и открытыми исходниками. Что удивительно - работает очень быстро.

SegmentAnything
Модель появилась весной 2023го года. Одна из немногих тут моделей которая использовала другую схему тренировки. Модель выделяет маски для всех объектов на фотографии. Тут есть небольшой вопрос "а что считать объектом". С этим модель действительно путается. И множество дальнейших модификаций модели позволяют уточнить этот термин по разному:
SAM-HQ для работы с мелкими деталями объектов

SAM-Video - для стабилизации работы с видео и с мелкими объектами:

SAM4MIS - для медицинских данных
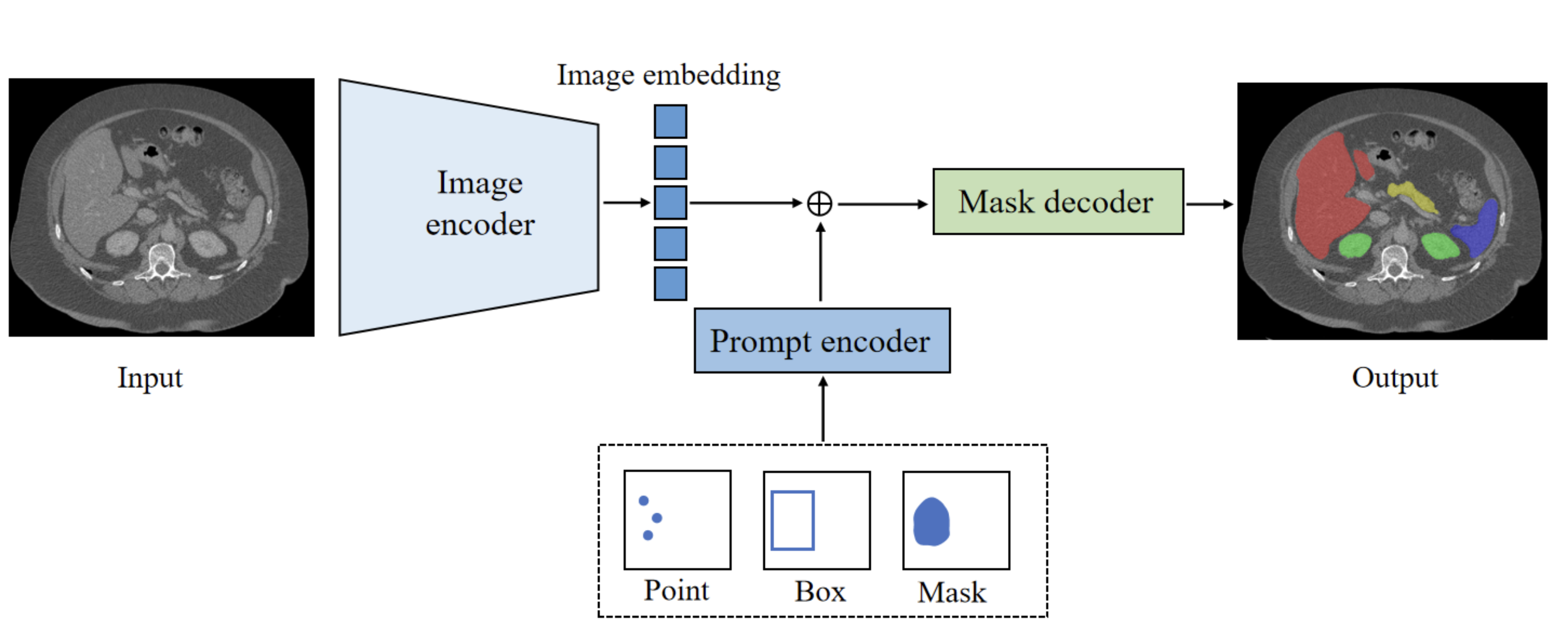
Вот тут я рассказываю чуть-чуть более подробно про SAM и показываю на видео его ограничения.
SAM тренируется иначе чем все остальные приведенные сети. Более классическим подходом с разметкой датасетов. Но, объёмы огромные. И присутствует какой-никакой SSL в тренировке. Специальная модель оценивает качество сегментации и решает на базе этого качества можно ли пускать в обучение или надо доразметить.
Grounding Dino
Сеть в каком-то смысле начиналась как навес на DINO, но по сути воспринимается как отдельная сеть. В неё авторы сосредоточились на том как детектировать объекты с текстовым описанием. Ни DINO ни CLIP напрямую это не умеют. Но тут авторы решали эту задачу из коробки и хорошо. Для многих простых задач работает неплохо

TRex. От тех же авторов. К сожалению для этой сети нет кода. Но идея является развитием GD. Детекция всех похожих объектов по одному отмеченному объекту.

Language models for images: LLAVA, MiniGPT-4, etc.
Больше всего хайпа в последнее время именно вокруг интеграции LLM с изображениями. Зерно истины тут есть. Но есть небольшая проблема. Я не знаю ни одной промышленной задачи где LLM + изображение работало бы лучше чем приведенные выше модели. На LLM можно красивее показывать демки. Например запрос "есть ли на этом изображении ситуация A". Но близость эмбеддингов для CLIP между этим текстом и изображением будет лучше. При этом, конечно, для пользователя более no-brain является использование LLM интерфейса.
За пределами Computer Vision задач больше. Но это уже больше задачи LLM где изображение это лишь часть контекста запроса к LLM модели:

Как эмбеддинги изображения цепляют к LLM? Самый простой вариант - примерно вот так:


По сути подаем на уровне текста, как часть последовательности (обычно отнормировав линейным слоем). Кажется, что это не единственное решение, как минимум видел несколько размышлений как это можно сделать иначе. Но все OpenSource модели прмерно так делают (поправьте если нет). Из OpenSource известнее всего:
LLAVA - https://llava-vl.github.io/
MINI-GPT4 - https://github.com/Vision-CAIR/MiniGPT-4
Про ограничения я тут рассказывал подробно. Это прошлая версия MinGPT. Те же проблемы есть в LLAVA. GPT4V чуть-чуть лучше, но просто ошибки более закопанные. Вот тут есть неплохой разбор про медицину, например.
LLAVA-Video
Кроме обычной LLAVA есть ещё и LLAVA с визуальными эмбеддингами (те самые InternVideo про которые я говорил выше). Опять же те же самые проблемы и плюсы - https://github.com/PKU-YuanGroup/Video-LLaVA
Прочее
Как я и говорил, к большим претрейнам можно отнести много чего. В том числе сетки которые натренированы на больших датасетах. Их таких примеров можно например упомянуть:
UNINEXT - универсальная сетка для трекинга
InternImage - универсальная сетка для детекции, классификации и всего такого, обучавшаяся на всех доступных датасетах
Реальный прод и замена разрабов?
Уф. Краткий экскурс затянулся. Давайте поговорим о том почему хороши One-Shot сетки.
Не надо обучать. Это не совсем так. Чем сложнее задача - тем больше надо потратить времени на хорошую детекцию. По каким-то задачам достаточно одного изображения/промпта. По каким-то их должны быть десятки или сотни. Но все равно это обычно быстрее чем собирать большой датасет.
Возможность корректировать поведение системы в проде. Когда прямо на ходу, без переобучения, можно модифицировать отклик системы. Это решение другого класса задач.
Цена прототипа. Понятно что если можно свернуть разметку/обучение - система будет дешевле. Не все ошибки можно так компенсировать.
А вот минусы у таких сеток оказываются совершенно другие:
Долгий инференс, много памяти. Это не решение когда вам нужно 20FPS. Да, некоторые маленькие модели можно тащить на том же RockChip или Jetson (вот тут рассказываю какая скорость может получиться)
Точность ниже. Если вы делаете что-то сложнее "детекция людей и собачек" - точность будет ниже чем модель натренированная по хорошему датасету.
Сложнее пайплайны/переобучение. Если в проде есть их тренировка. Например Dinov2 или I-Jepa натренированные по медицинскому домену. Такая тренировка может стоить десятки тысяч долларов на один прогон. И засетапить её явно сложнее чем оттюнинговать Yolov8 по вашему датасету:)
Фичи Fondation Models стабильные, но часто они не могут съесть "новую" задачу. Я видел несколько доменов где Dinov2 кое-как работал из коробки, но сильно хуже чем по знакомым доменам (хирургия например). Более слабые модели (InternImage, etc.) были ещё хуже.
Тут уже видно, что все не очень однозначно. Кажется, что не всегда можно поменять ресерчера:)
Но как же "я на GPT4v сделал полезное приложение за два дня!". Давайте посмотрим где действительно Fondation Models дают большой эффект:
Новые продукты. Fondation Models позволяют решать проблемы которые раньше были нерешаемы. Но это очень узкий класс проблем, которые очень сложно внедрять в рынок. Например ещё 5-6 лет назад, в Cherry Labs мы создали One-Shot модели для распознавания действий. По скелетам. Тогда ни у кого такого не было. Думаете мы смогли их эффективно продать? Нет. Но демки на них было делать классно.
Сейчас One-Shot модели для действий стали в OpenSource. При точности выше. Только вот продукты так и не появились. А демок стало ещё больше.
Да, сколько-то новых продуктов появится, я уже видел. Но явно меньше чем для LLM.
Когда мне показывают очередной продукт - я уточняю "а какая точность была бы у нормального Action Recognition" и "а сколько стоит собрать датасет"? Обычно оказывается что собрать данные было бы проще, дешевле и быстрее.Прототипы. Да, не так точно. Не так эффективно. Но быстро собрать и проверить гипотезу.
Оптимизация текущих пайплайнов. Например можно сделать разметку быстрее. Или сделать teacher-сеть для простых задач. Это не взрыв мозга, а это "оптимизация стоимостей на десяток процентов"
Хорошо ли это? Конечно. Но достаточно далеко от мнения "нас заменят". Пока что.
А для каких-то задач это звучит как "ещё больше инженерных задач вместо RnD и ещё больше костов на железо".
Использовал ли такие модели я в последнее время? Да, как минимум в 3х проектах: в одном был таки продукт на базе one-shot, но до прода ещё не дошло. Ещё в одном можно было обойтись без сбора сложного датасета + работало как anomaly detection. И ещё в одном были навигационные задачи. Они бы решались и так, но с помощью One-Shot было бы проще.
Будущее
Я думаю, что модели будут развиваться, появляться больше претрейнов по более хорошим дататсетам - и ситуация должна улучшаться. Прототипы которые могут появится на новых сетях - уже появились или появятся в ближайшие пол года-год. А остальное - это про косты и оптимизацию.
Что, совсем никаких новых прорывов?
Думаю что все же будут. Не в тех областях где сейчас много шума, а чуть чуть рядом:
Робототехника. Мультимодальные модели это круто. Я жду пока появятся хорошие мультимодальные модели для робототехники. Пока что я видел слабо. Кажется что подходы которые появились 5-6 лет назад пока что более стабильные. Я не вижу технически невозможного почему тот же GPT4v не сможет преобразовывать текст + изображения в стабильные команды. Но нужны большие разнообразные датасеты и хорошее железо. А железо дешевеет семимильными шагами (про роботов и CV я иногда рассказываю у себя в канале). Но это так, надежды:)
ASIC-претрейны. Чую что если кто поместит Dinov2 на чип стоимостью в пару долларов и с минимальным энергопотреблением - порвет рынок. Можно будет распознать почти все из коробки без обучения. Это уже какое-никакое взаимодействие с окружением. Понятно, что сейчас есть девайсы где можно то же самое творить с обучением. Например NPU платы за 8 баксов. Но там как-никак требуется экспертиза в сеточках чтобы все запустить.
