
Всем привет, меня зовут Александр Карташов, я Java-бэкенд разработчик в Альфа-Банке. Работаю в проекте Альфа Бизнес Мобайл, мобильное приложение для юрлиц. В рамках проекта мне часто приходилось интегрироваться с разными банковскими системами, с разными стеком технологий, так и родилась эта статья, как попытка все упорядочить.

Обобщая, под клиент-серверным взаимодействием можно считать весь путь передачи от сервиса А к сервису Б.
Существует много вариантов как это сделать: разные подходы, архитектуры, технологии, протоколы.
В больших проектах часто используются разные комбинации разных инструментов, как на картинке ниже.
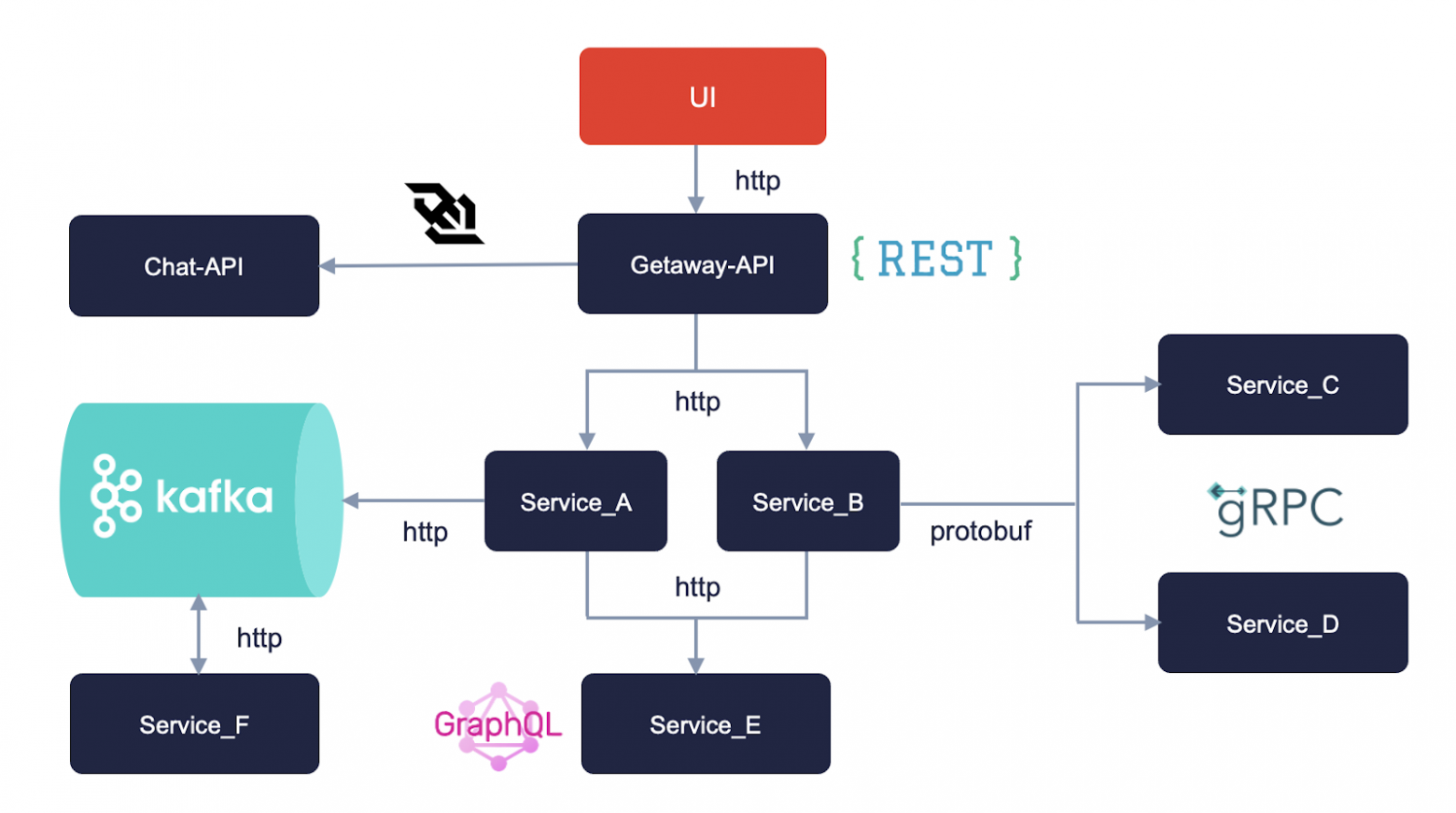
Но почему выбраны именно эти инструменты, а не другие? В чём между ними разница, как они связаны между собой и почему их так много?
Как выбирают технологии?
Ответ в том, что каждый инструмент имеет определенный пул задач, которые решают их лучше всего. Уже в зависимости от задачи подбирается комбинация инструментов для наиболее продуктивного решения.
А как именно они подбираются? Чтобы понять выбор той или иной технологии, давайте пройдемся по такой схеме:
определим условия задачи;
посмотрим классификацию решения этой задачи;
и подберем реализацию.
Начнём с условий.
Условия
Условия — это требования и свойства.
У решения могут быть какие-то требования, допустим, выдерживать определенный уровень нагрузки, поддерживать определенный тип клиентов и быть отказоустойчивой.
Из свойств обычно отмечаются какие-то характеристики сообщений и важность запроса — насколько важно его обработать.
Классификация
Можно по-разному классифицировать клиент-серверные взаимодействия, но я выбрал основные:
по характеру запроса: синхронное/асинхронные;
и по методу обмена данными: запрос-ответ и публикация-подписка.
Теперь чуть подробнее.
По характеру запроса.
Синхронный характер запроса — когда у нас все вызовы идут в одном потоке.

Допустим сервис А должен вызвать сервис В и С. Он делает к ним запрос и пока сервисы обрабатывают, А ничего не делает и просто ожидает.
Это ожидание называется блокировкой потока, что не очень хорошо.
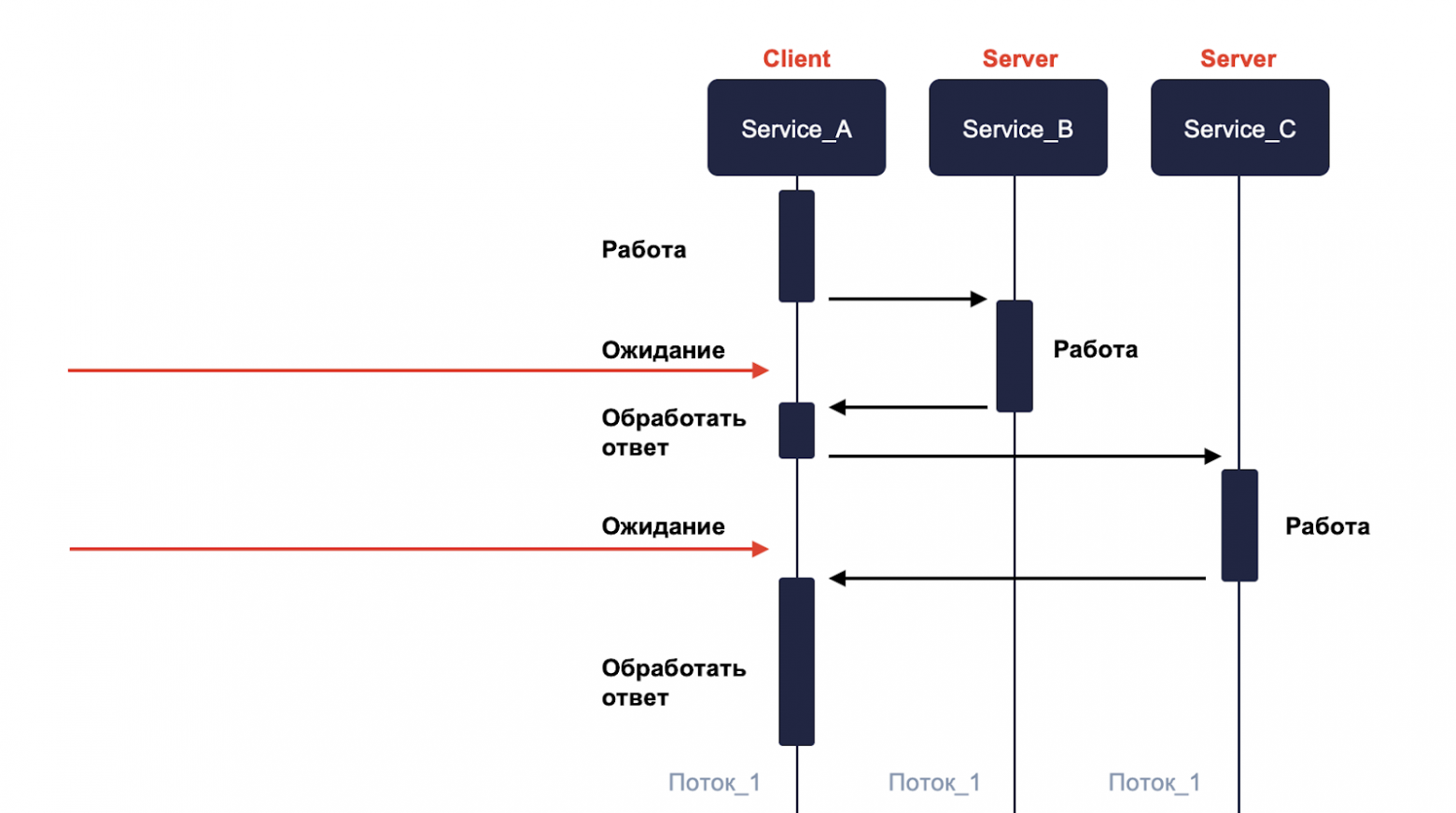
Асинхронный подразумевает, что у нас не будет блокировки, то есть сервис А вызывает сервис B и C, но продолжает дальше свою работу не дожидаясь ответа.
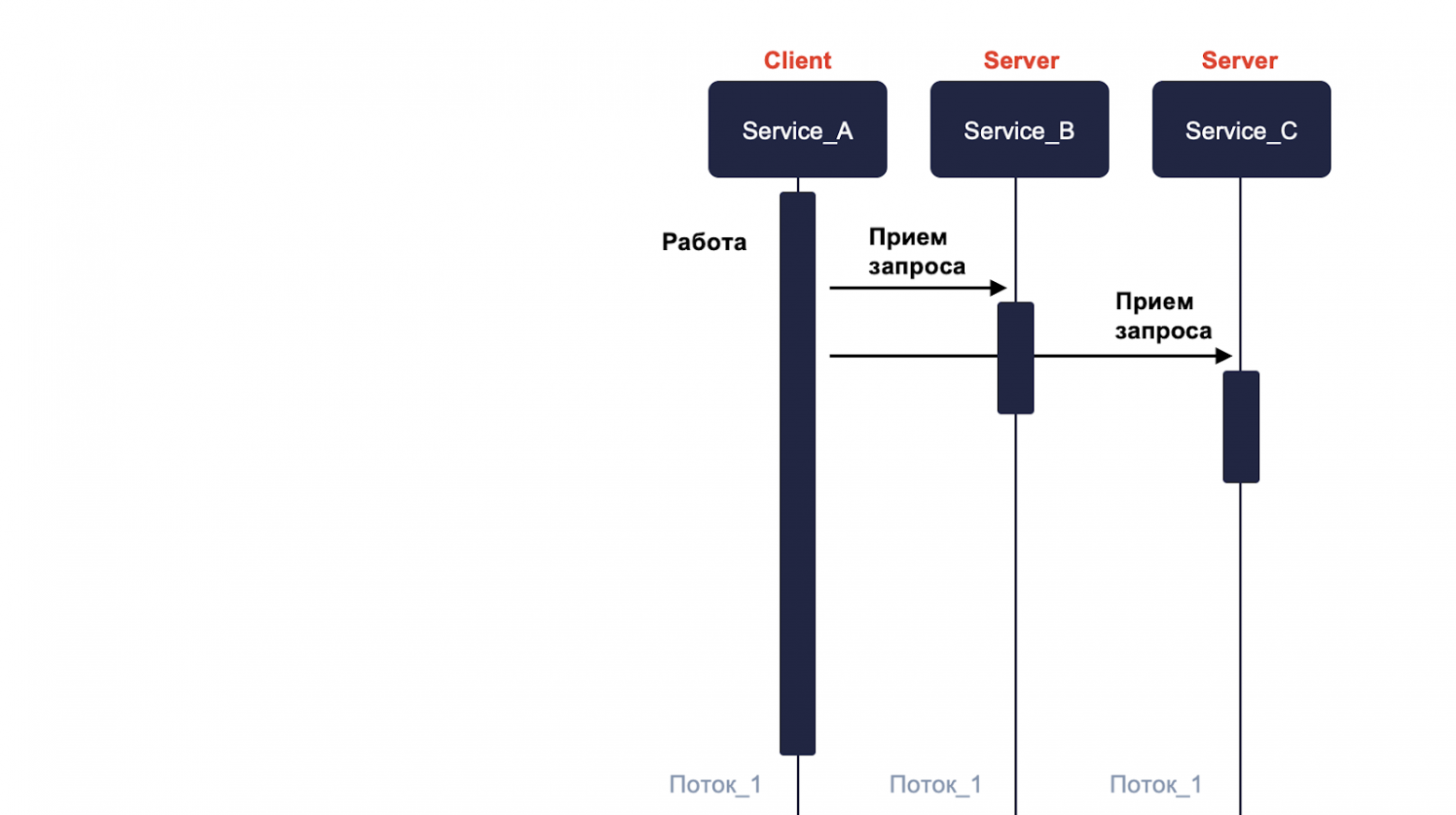
Если наши сервисы B и C также синхронные, то они тоже не будут делать в основном потоке работу, а передают дополнительный поток на генерацию ответа.
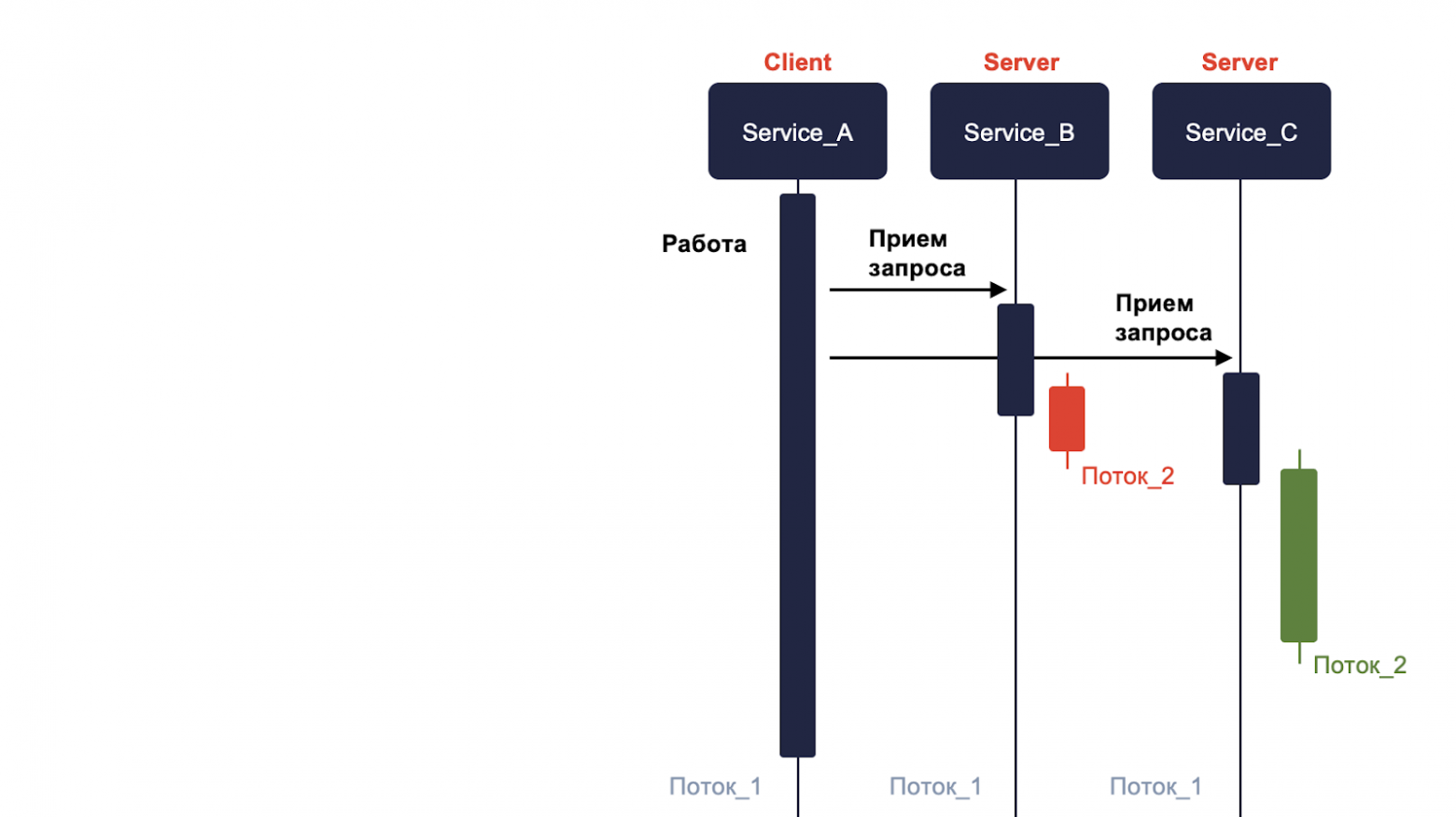
И как только они закончат, то возвращают ответ. Наш сервис А получает его и обрабатывает в уже специально созданном для этого потоке. Таким образом мы избегаем блокировки.
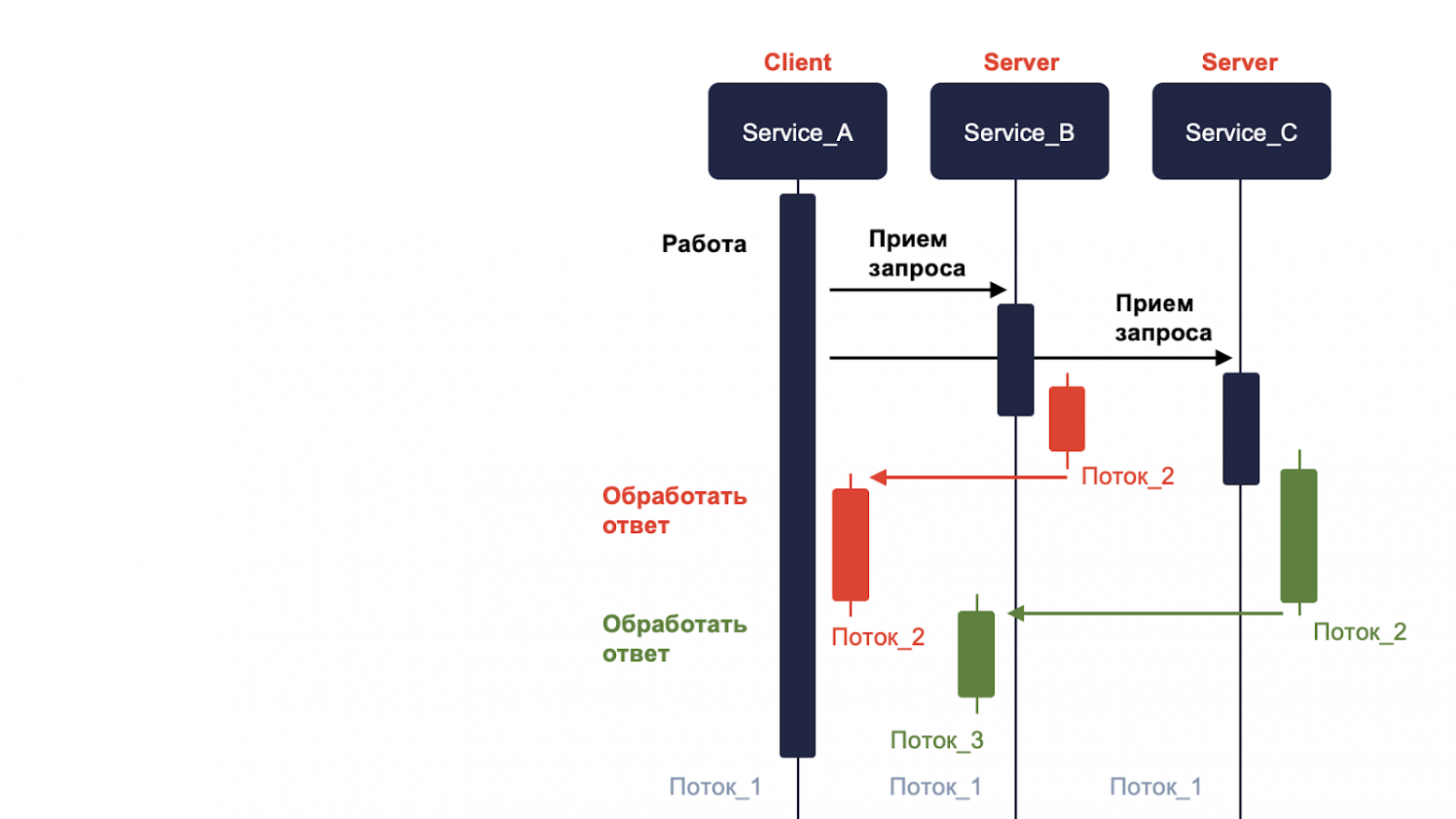
Плюс синхронного соединения — это, в первую очередь, простота реализации и детерминированность, когда каждому запросу соответствует один ответ. Минусы — это блокировка и производительность, поскольку мы не очень правильно расходуем ресурсы.
Плюс асинхронного соединения — оно, наоборот, не блокирует, поэтому более производительно. Но, говоря о минусах, его сложнее реализовать и сложнее отлаживать.
Можно сделать вывод что синхронный подход подходит для простых систем без высокой нагрузки, а асинхронный для систем с высокой нагрузкой.
По методу обмена данными.
Запрос-ответ работает по принципу «клиент делает запрос на сервер — получает ответ».
Публикация-подписка работает по такому принципу, что у нас добавляется третий элемент — message брокер (брокер сообщений). Наш клиент отправляет запрос сначала ему, а далее наш сервис, который этот запрос должен получить, либо запрашивает его у брокера, либо сам брокер ему передает.
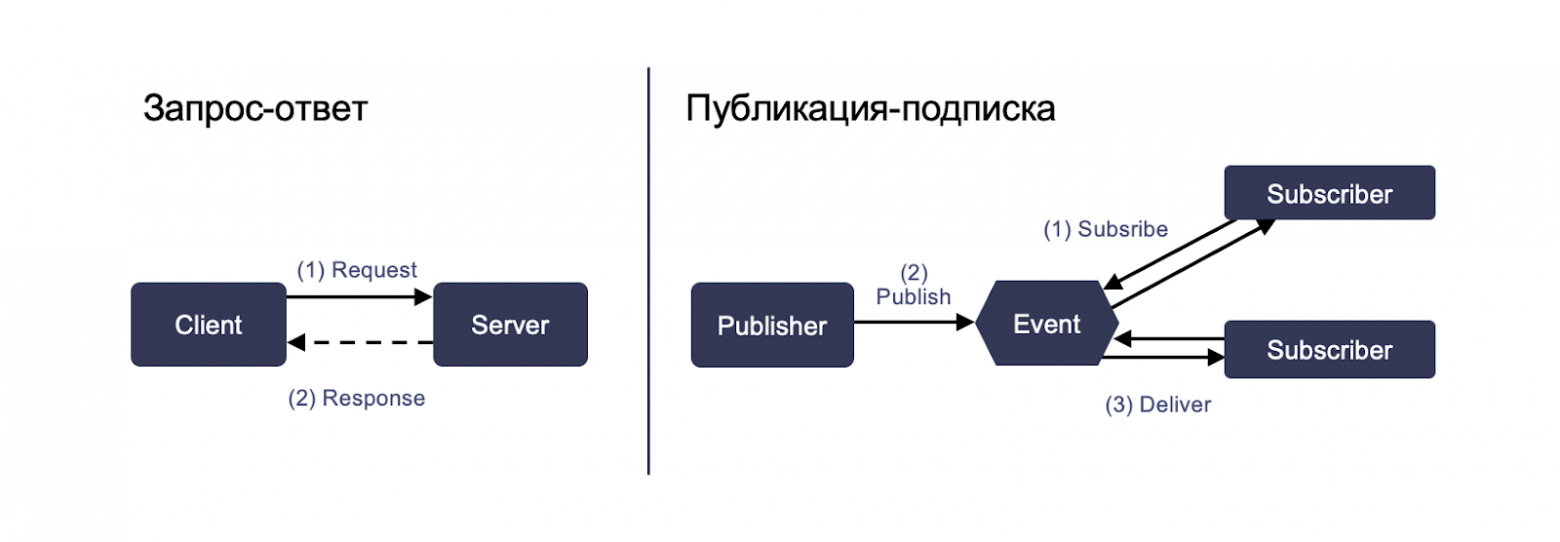
Эта третья прослойка добавляет такие плюсы, как распределение данных: наш запрос могут получить сразу несколько сервисов или группа, как угодно. Такая группа легче масштабируется, поскольку мы можем увеличивать количество брокеров и увеличивать количество запросов, которые можно принять. Также эта система более надежная, потому что в таком случае запрос потерять сложнее: даже если один сервер упадет — будет другой, который также сохраняет все эти запросы.
Из минусов стоит отметить сложность реализации и сложность отладки.
Что касается плюсов запрос-ответ то, как и у синхронного, это простота реализации и детерминированность. Из минусов — легче потерять запрос и ограниченная производительность.
Можно сделать вывод, что запрос-ответ подходит, в принципе, под любые системы, а публикации-подписка — для систем с высокой нагрузкой, где важно не потерять запрос.
Перейдем к реализации.
Реализация
Я выделил вот такую иерархию (по важности):
Сначала идёт архитектура — набор рекомендаций о том, как должна выглядеть система в целом.
Технологии — реализация отправки данных по протоколу.
Далее протокол — набор правил, описывающих взаимодействие сети.
И формат данных — «что» мы будем передавать.
В итоге у нас получается такая схема, ответы на вопросы и приведут к правильному выбору.

Теперь пройдемся по нашему плану, и чтобы было проще понять как выбирать технологии, покажу работу с планом на примере пары проектов Альфа-Банка.
МКС
Начнём с проекта МКС — микросервисный корпоративный стандарт.
Небольшая предыстория. Есть такой проект — НИБ, Новый Интернет-Банк.
Это веб-приложение банка для юрлиц. У него есть фронт часть и бэкенд. Бэкенд часть делится на домены и МКС — один из доменов.
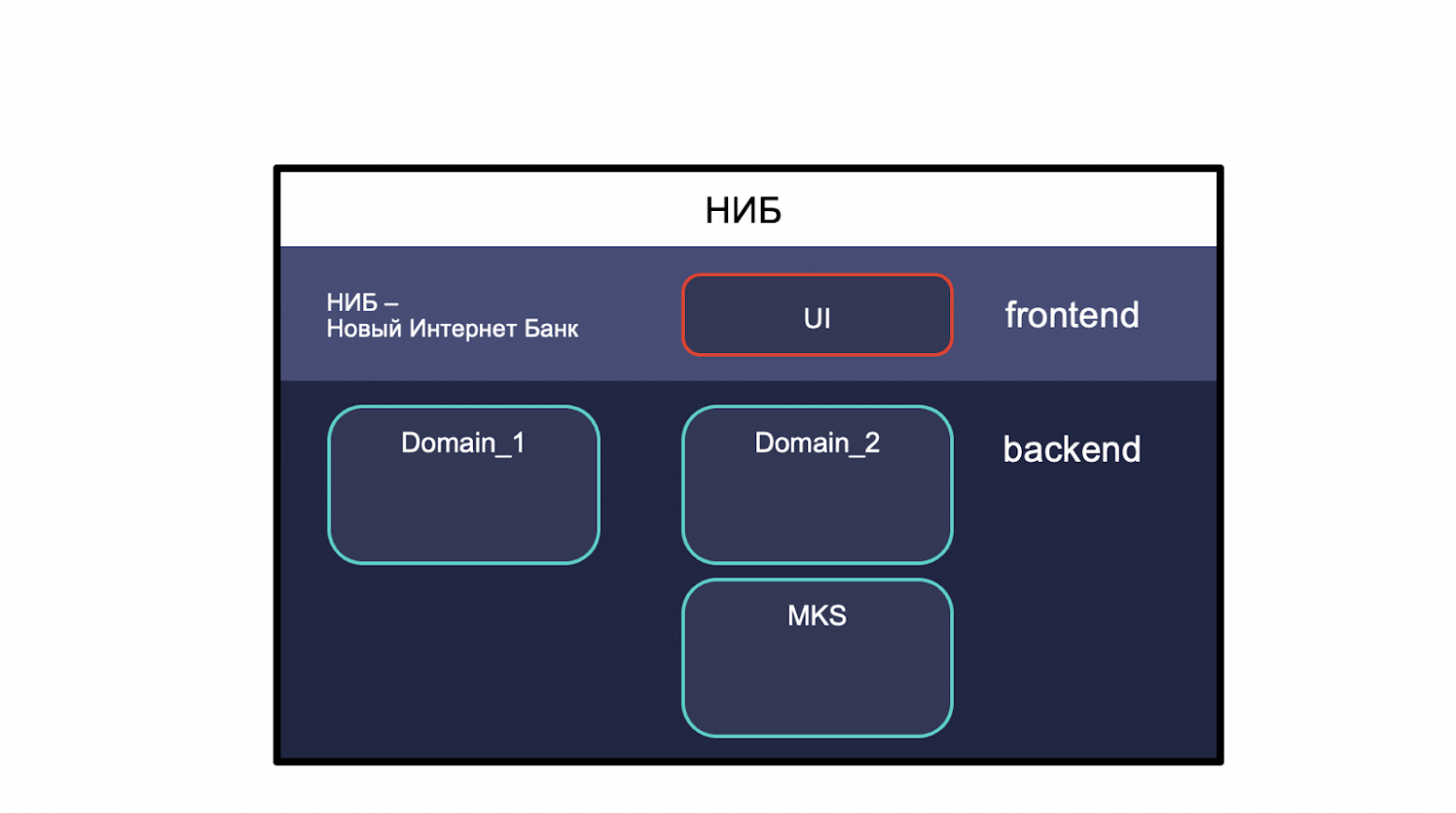
Он относится к платформенным условиям в том смысле, что решает задачи напрямую не относящиеся к бизнес логике, и другие домены используют его как клиент своего.

И нам нужно понять, собственно, как с этим доменом взаимодействовать.
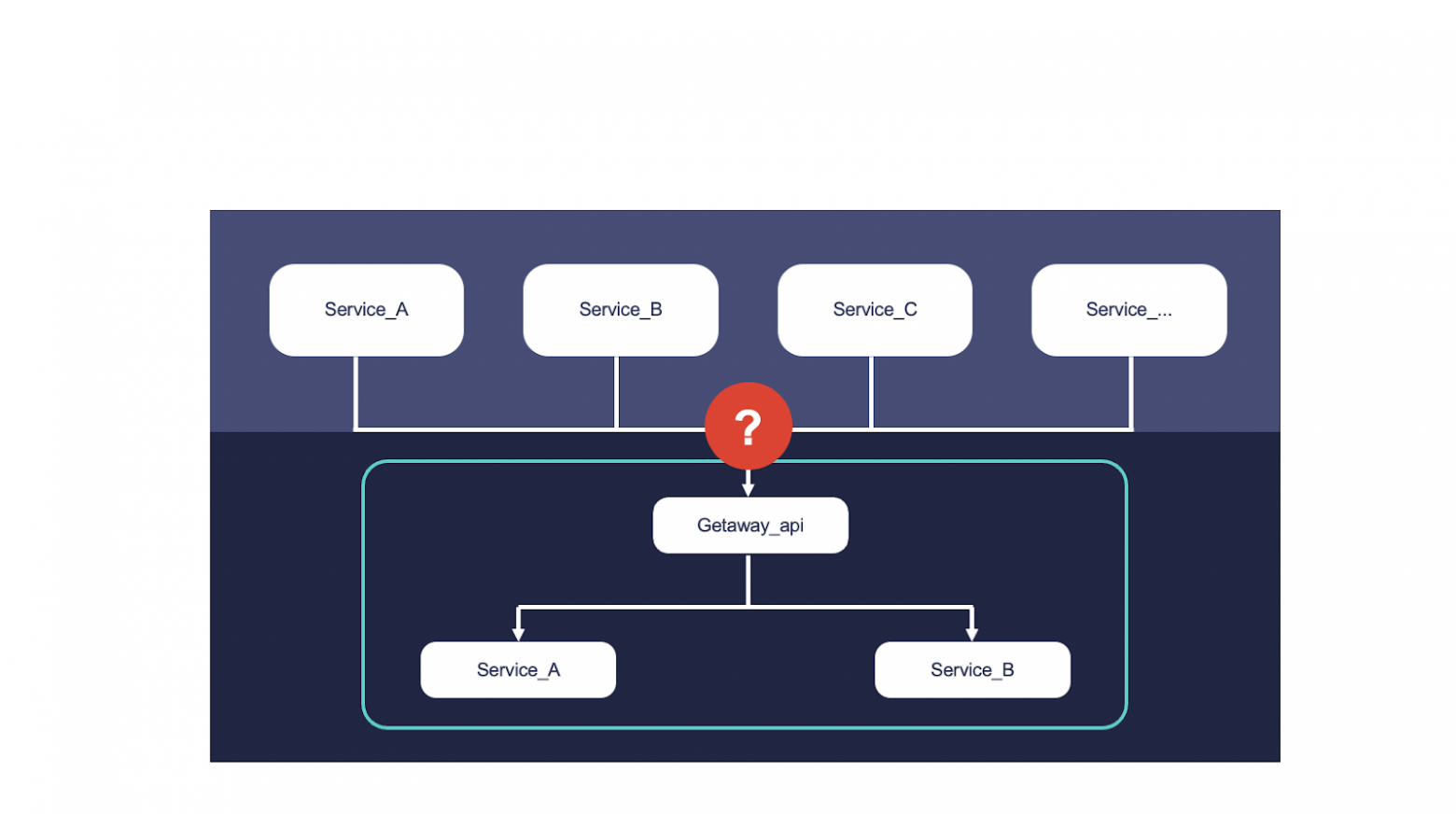
Начнём с условий
Выделим требования.
В первую очередь важно выдерживать высокую нагрузку, потому что у нас будет много клиентов.
Также клиенты разнообразны, потому что могут быть написаны на разных языках.
Но интеграция с ними должна быть легкая.
Свойства:
Можно отметить, что ответы и запросы формируются небольшого размера.
Ответы формируются быстро.
Классифицируем решение
Выберем запрос-ответ, потому что у нас нет требований о том, что каждый запрос нужно обязательно обработать, поэтому выберем более простой вариант. А так как одно из условий, что ответы должны формироваться быстро, то тем более выберем этот вариант.
По характеру соединения нам придётся выбрать более сложный асинхронный вариант, так как необходимо выдерживать высокую нагрузку.
Реализация
С классификацией разобрались, теперь нужно определить реализацию.

Какие у нас есть варианты? Самый распространенный — это архитектура REST. Она подразумевает использование HTTP-протокола и его метода. Технологию не указал (первый столбик), потому что нам достаточно любого инструмента, который умеет отправлять HTTP-запрос. Такой есть почти в любом языке в дефолтной библиотеке.
Формат данных также не указан, поскольку REST не подразумевает какой-то конкретный формат.
Другой распространенный вариант это RPC-методология. И это именно методология, а не архитектура, поскольку она подразумевает только взаимоотношения клиента и сервера: клиент должен вызывать конкретный метод у сервера.
REST или RPC?
Давайте немного поговорим о том, какая между ними разница?
REST это про то, что мы формируем запрос HTTP и отправляем его куда-то по URL.
RPC это когда мы, допустим, из сервиса А вызываем конкретный метод сервиса B и должны знать конкретно, что туда передавать и что нам вернется.
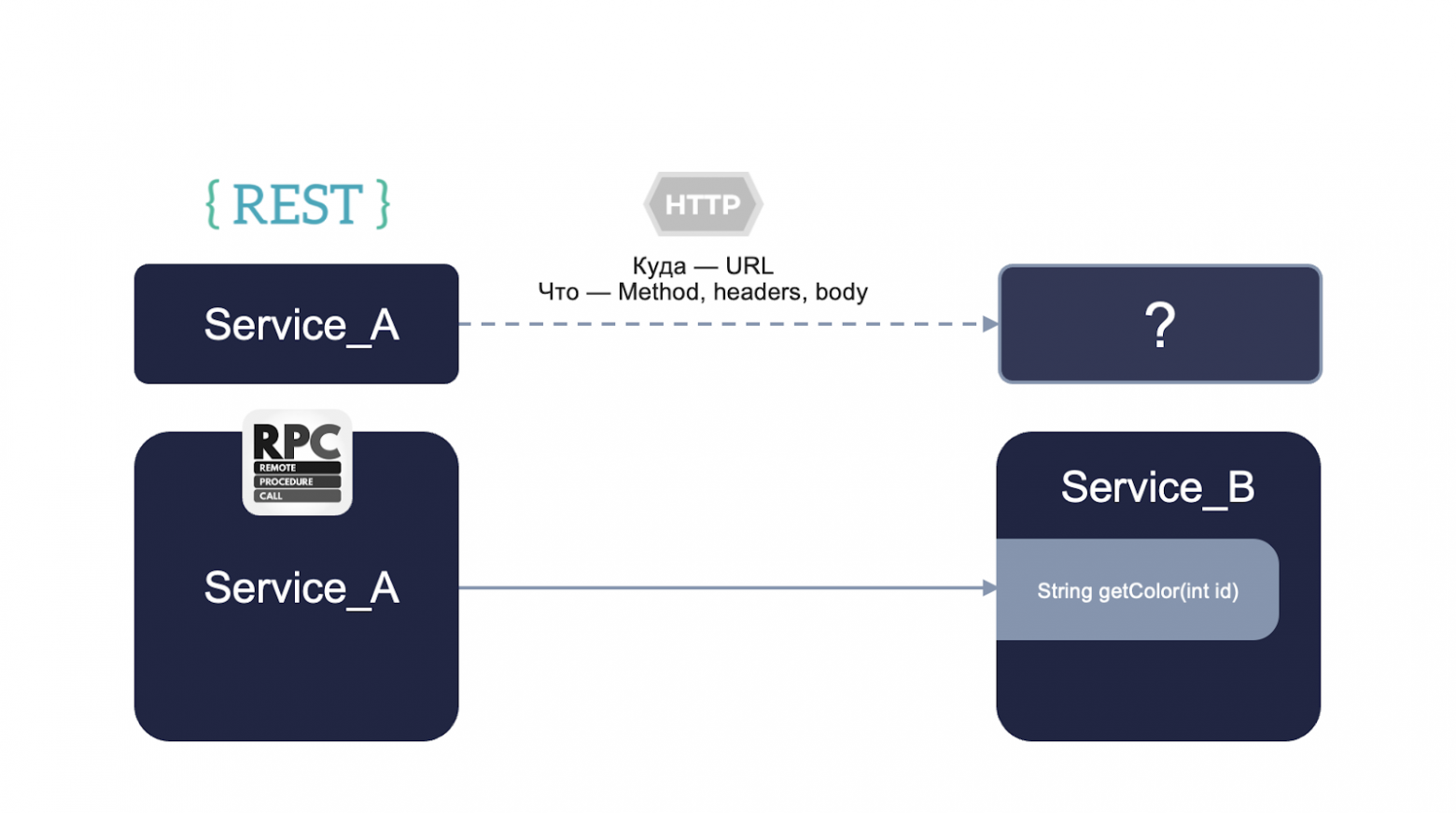
Я выбрал три реализации RPC: gRPC, Apache Thrift и реализация через Saab. Но с REST мы сравним только gRPC, поскольку это самый популярный вариант из этих троих.
Итак, сравнение начнём с REST.
Мы должны сформировать HTTP-запрос. В боди должны указать (но можно и не указывать) какие-то данные в HTML, JSON. Формат не важен, но обычно используют JSON.

С помощью какого-нибудь механизма мы формируем запрос и отправляем.

На другой стороне тоже при помощи любого механизма его обрабатываем.

Вот теперь, что касается gRPC — это реализация RPC от Google.
Начнем с задачи: нам нужно из сервиса А вызвать метод getColor() сервиса B. Мы описываем контракт, указываем контроллер нашего сервиса В и модельки, которые будем получать и передавать.

Далее gRPC компилятор генерирует код на нужном нам языке, который мы добавляем в наши сервисы.
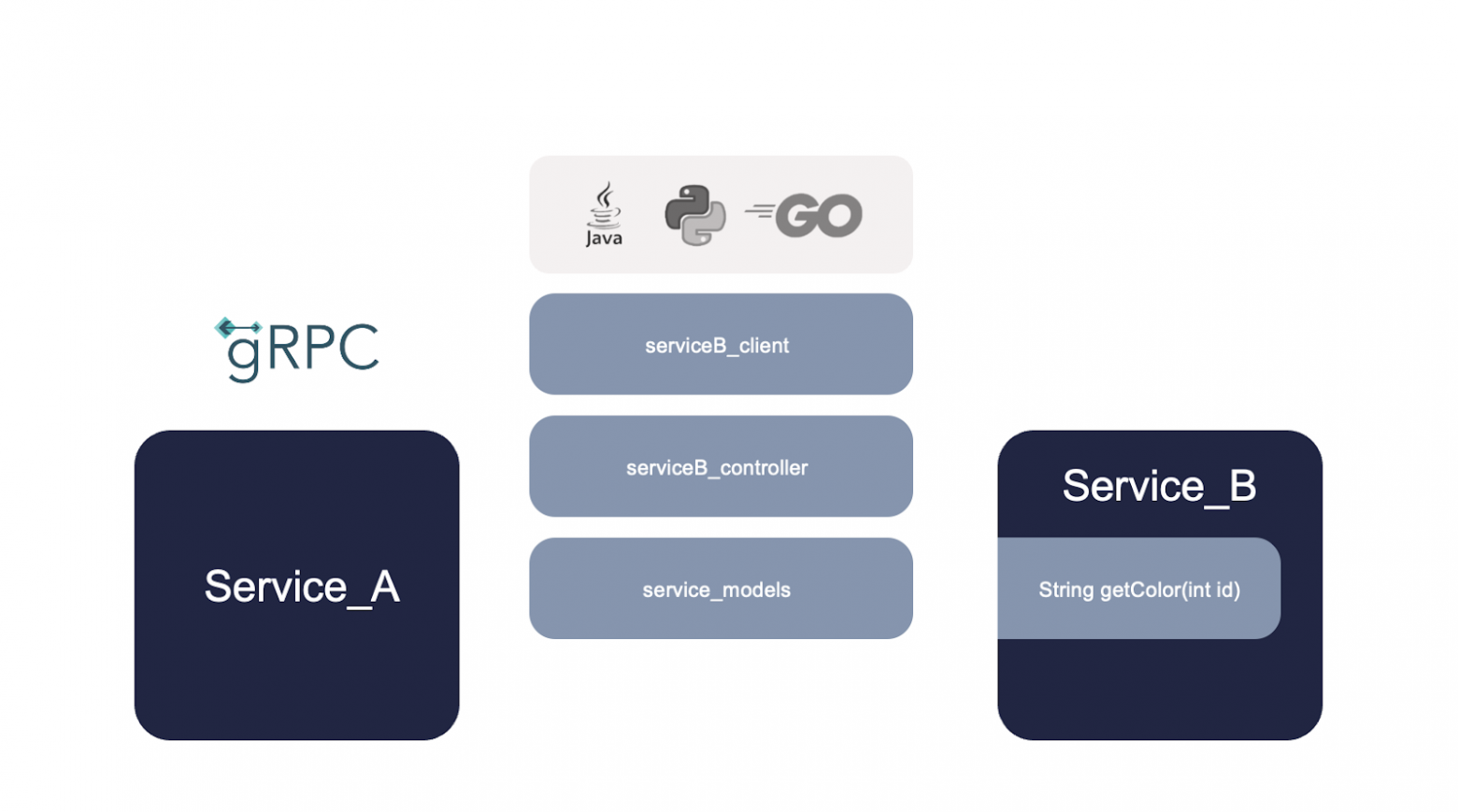
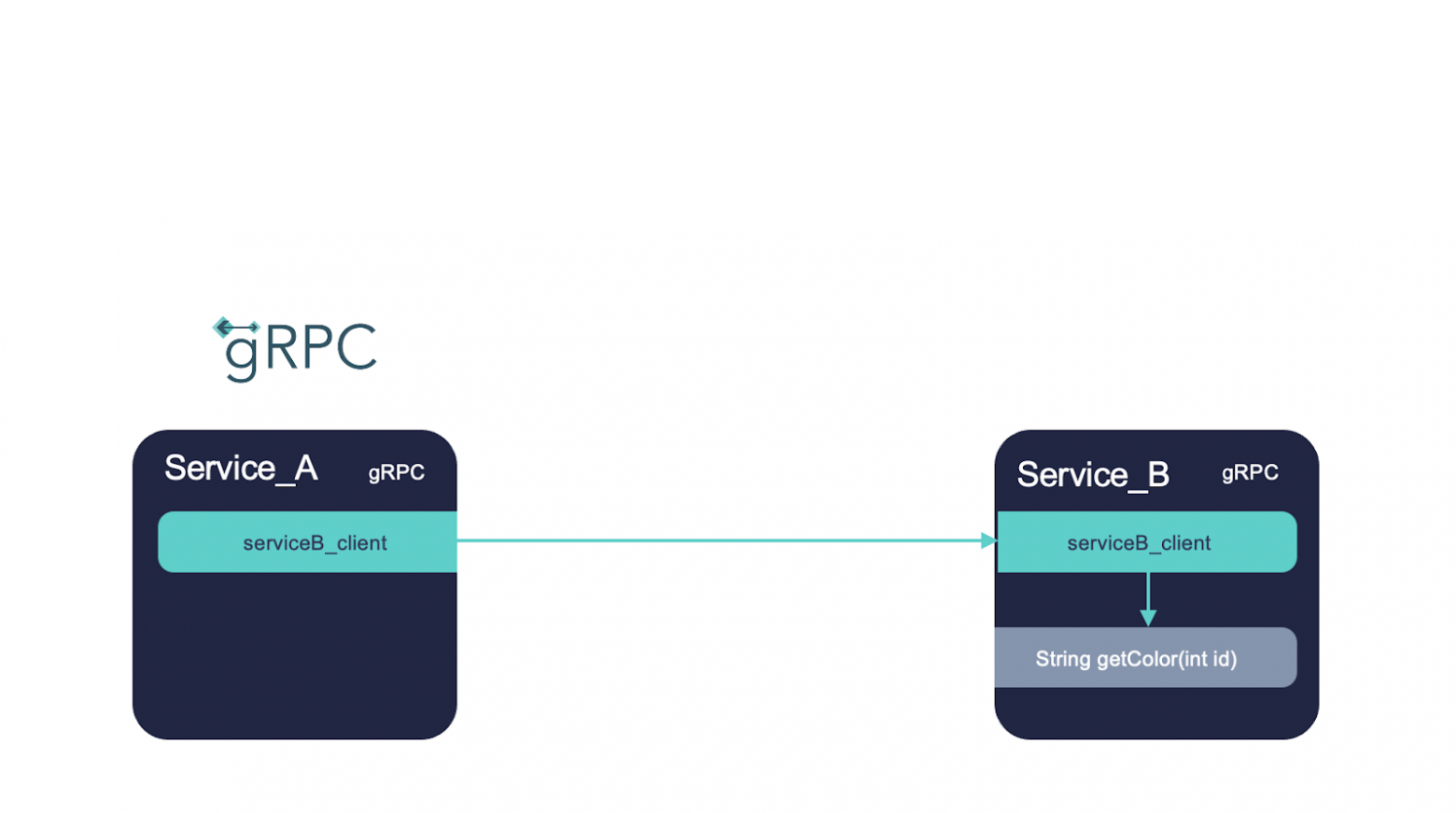
Теперь сервис A с помощью сгенерированного кода для клиента сервиса B сможет вызвать метод из сервиса B.
С gRPC в комплекте идет их протокол protobuf. Он использует прикладной протокол HTTP/2 (но это не обязательное условие).
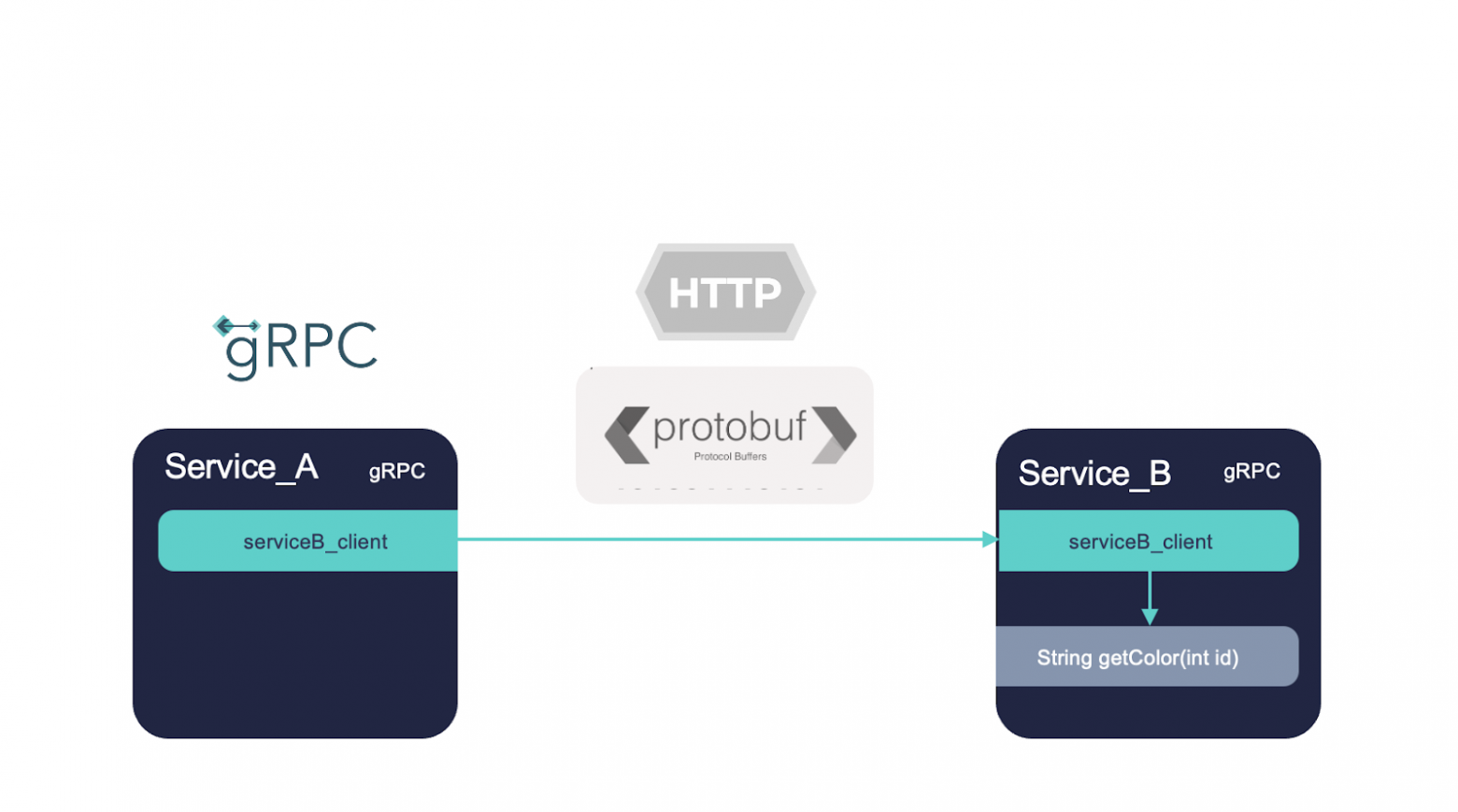
К слову, это бинарный протокол, поэтому нам нужно иметь два механизма сериализации и десериализации. Соответственно, мы формируем запрос, сериализуем его в байты, передаем их в HTTP и десериализуем на другой стороне обратно в модельку.

Как итог укажем плюсы и минусы.
Напрямую REST и gRPC мы сравнивать не можем, поскольку они находятся на разных уровнях абстракции, поэтому сравним с конкретной реализацией REST — REST API, который использует JSON как формат данных.
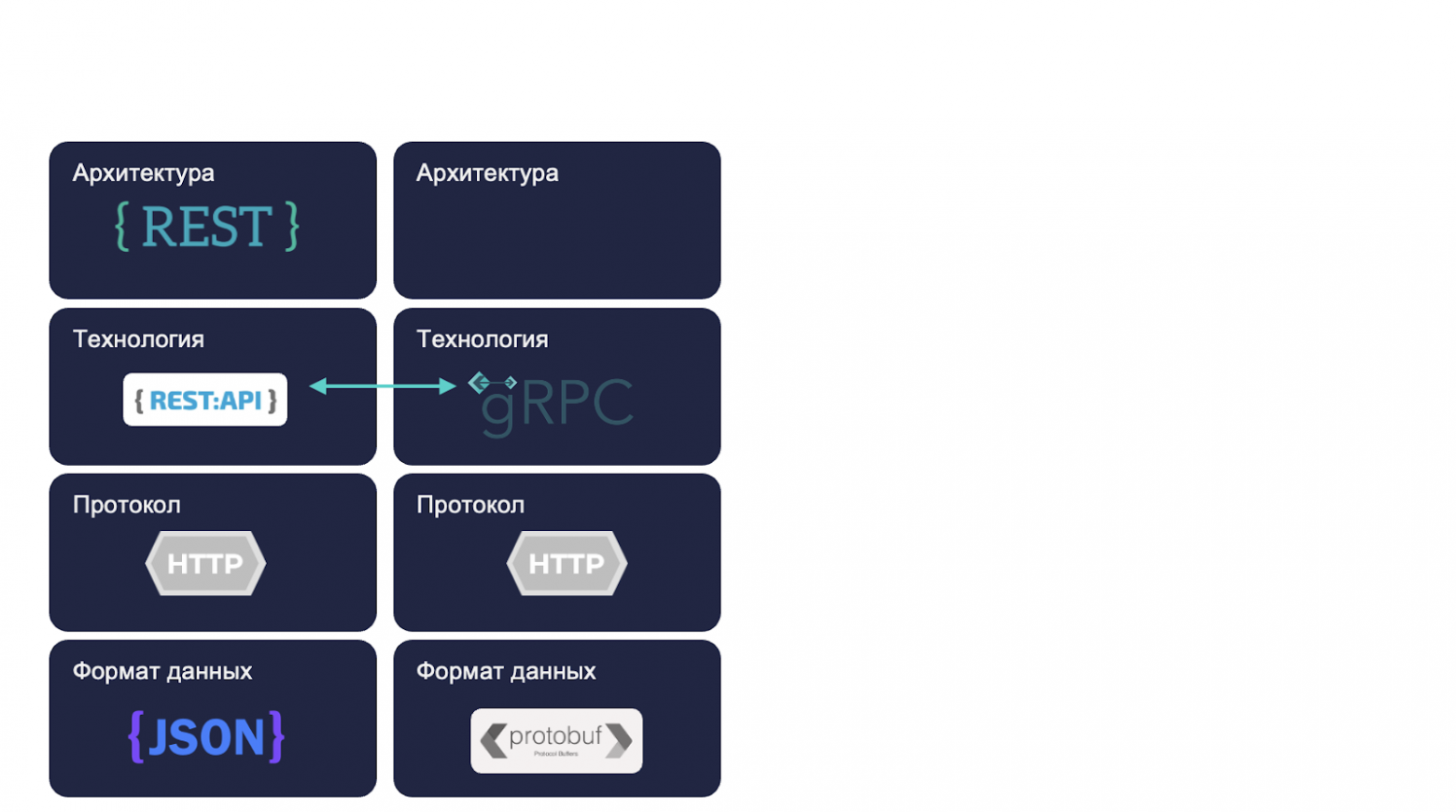
Итак, отметим плюсы и минусы.
Плюсы REST:
простота реализации;
поддерживаемость разными языками программирования;
читаемость запросов и ответов, поскольку JSON — это текстовый формат, можем его перехватить и прочитать.
Из минусов можно отметить, что нет определенности (определенного контракта) и относительно gRPC низкая производительность, опять же, из-за JSON.
Примечание. Минус «неопределенности» у REST JSON можно исключить, поскольку REST не запрещает использование контрактов и есть специальные библиотеки, которые контракт добавляют.
Плюс gRPC:
производительность, потому что мы используем бинарный формат данных, а его передавать намного проще;
определенность, за счет контракта.
Из минусов — это сложность: реализации и отладки.
Также оба поддерживают асинхронный формат.
Можно сделать вывод что REST JSON подходит, в принципе, под любые системы, а gRPC в первую очередь там, где необходима высокая производительность.
Вспомним наши требования. У нас не было речи о высокой производительности, скорее, наоборот, про легкую интеграцию, поэтому наш выбор — это асинхронный REST на JSON.

Тогда делаем нашим сервисом асинхронные REST API.

Создаём библиотеку с клиентами для наших сервисов, чтобы было проще интегрироваться.

Интегрируем её в наши клиенты или, если нужно, клиент сам напишет код для отправки по нашему контракту. И теперь клиенты могут взаимодействовать с МКС.
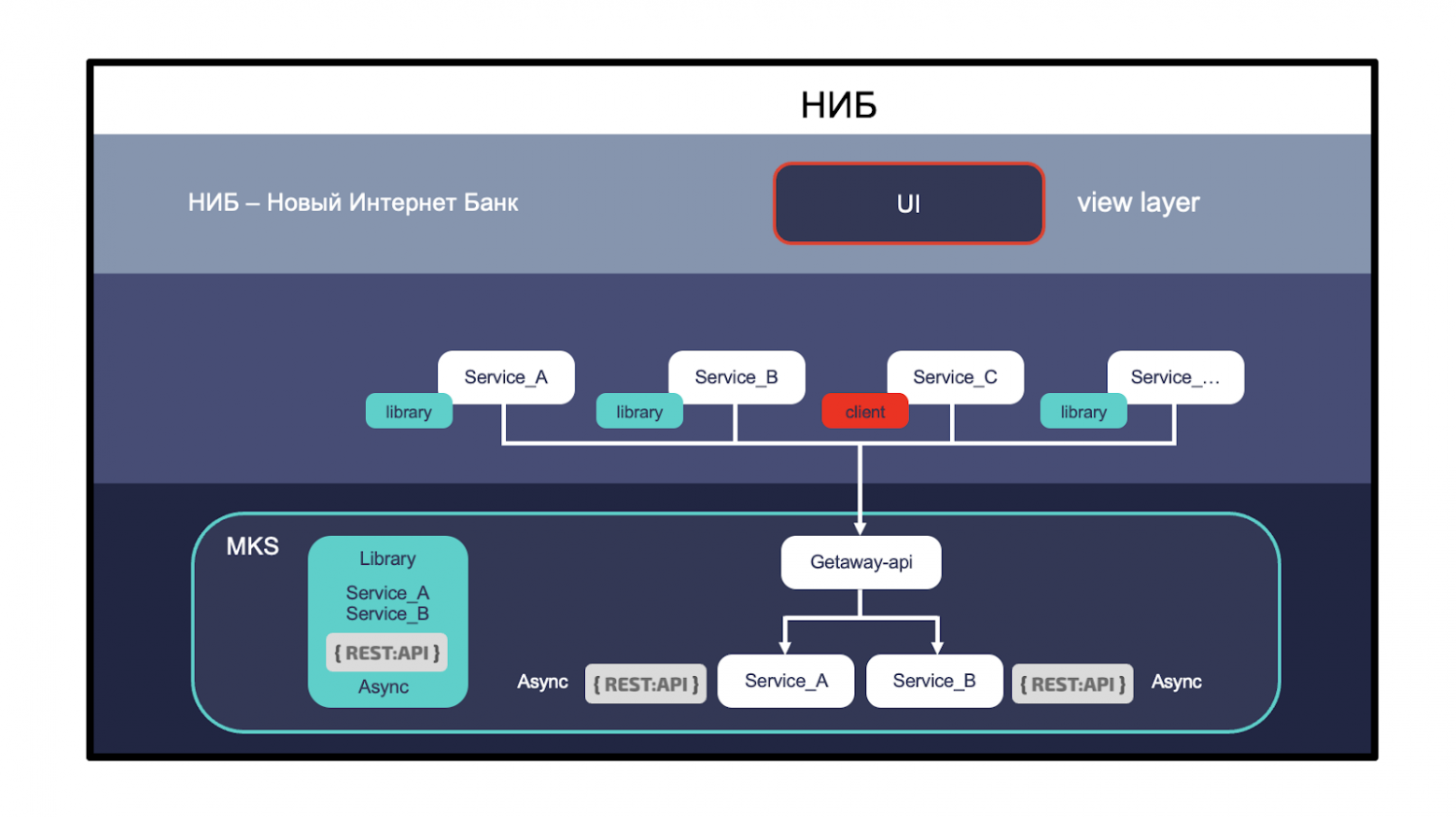
Мы покрыли все требования — это выдерживать высокую нагрузку, разнообразность клиентов и легкая интеграция.
АБМ-нотификация
Это проект про отправку различных уведомлений, пушей, емейлов, СМС и так далее.
АБМ — это Альфа-Бизнес Мобайл, мобильное приложение для юридических лиц. Есть фронт часть, бэкенд часть. К слову, это сосед НИБ, но НИБ — это веб-версия, а АБМ — мобильная.
AБM также делится на домены и нам нужно как-то решить вопрос отправки уведомлений клиентам.

Для этого надо отправить запрос Android и iOS — выделим в отдельный домен, в который уже будут стучаться другие домены и другие системы для отправки уведомлений.

Но поскольку НИБ и АБМ работают с одними и теми же клиентами, то логично вынести этот домен куда-то в одно место. Этим местом стал НИБ.

У нас есть домен корп corp_notifications, куда ходят другие домены для отправки различных уведомлений.
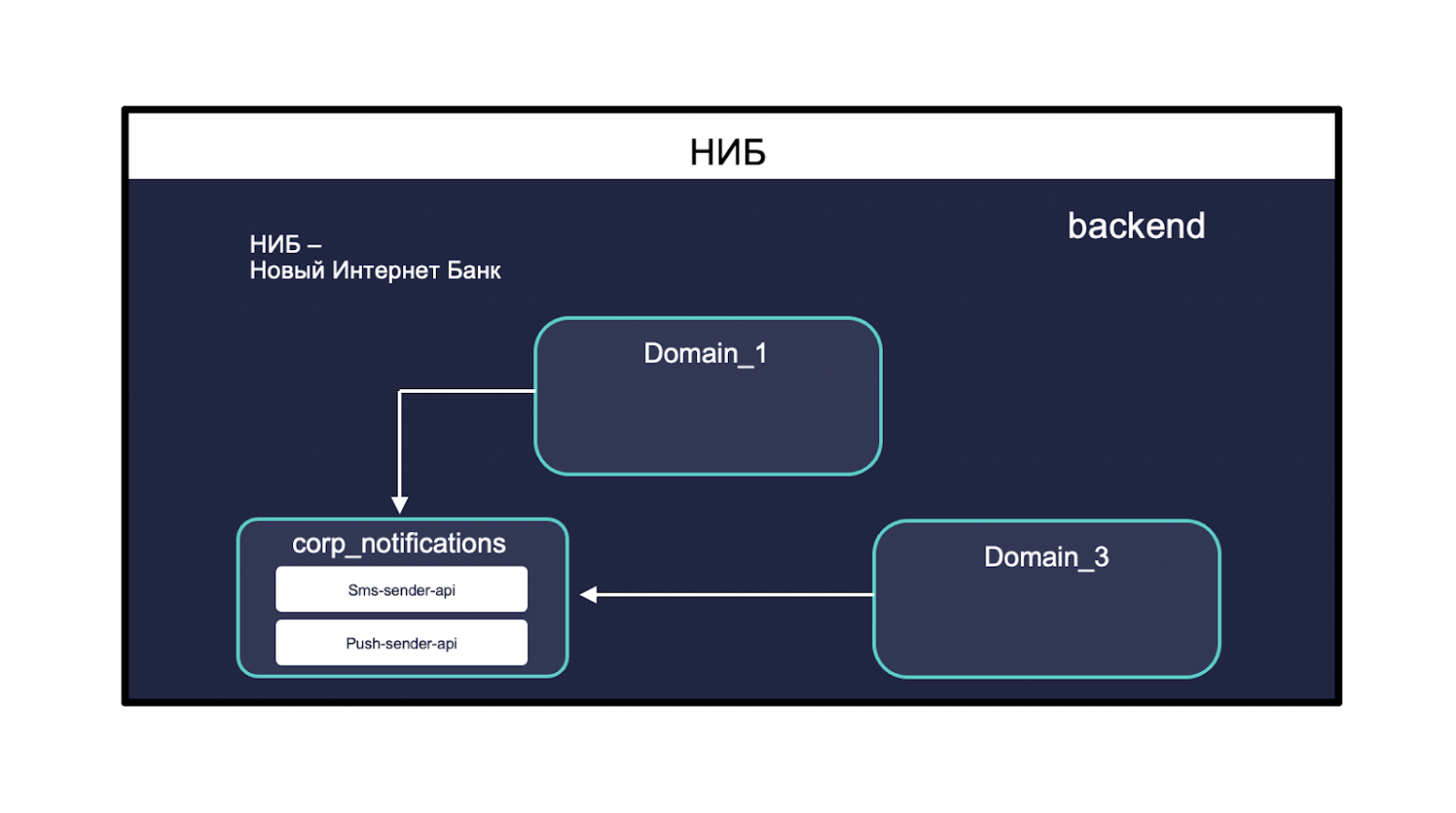
Соответственно, нам нужно понять, как с ним взаимодействовать.
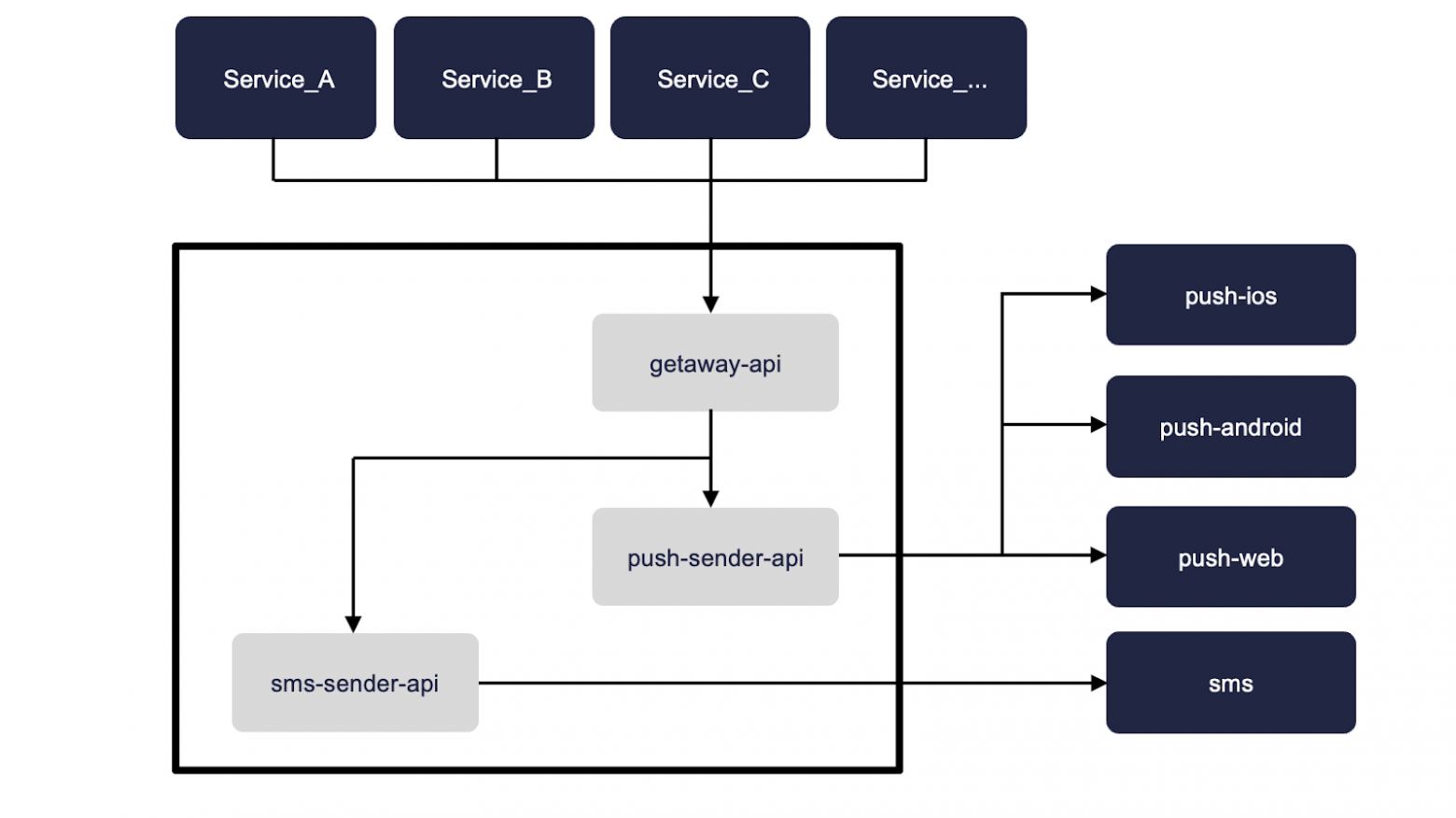
Условия
Посмотрим наши требования — это разнообразность клиентов и нельзя терять запрос, поскольку уведомление это очень важно.
Из свойств можно отметить, что запросы небольшого размера и ответы не обязательны.
Классифицируем решение
В данном случае нам придется использовать публикацию-подписку из-за требований, а характер соединения, в принципе, можно оставить синхронным.
Реализация
Схема, с которой мы работали была про запрос-ответ, а сейчас у нас публикация-подписка.

В этом кейсе нет архитектуры, поскольку все эти технологии message брокера не имеет какой-то конкретной архитектуры. Но я указал для них тип — модель передачи данных.
Как это вообще работает?
Если при запрос-ответ мы просто между сервисами общаемся, делаем запросы и отправляем куда-то и получаем от него же ответ, то в системе с message брокерами все запросы шлются на него и он отсылает их дальше. Ну или клиенты их сами запрашивают у него.

Есть два основных типа message брокеров: point-to-point и Publish/Subscribe.
В point-to-point каждому запросу соответствует только один клиент и он его получит. Отправитель и получатель сообщения не зависят от времени. Получатель отправит подтверждение после успешного получения сообщения.
Publish/Subscribe содержит различных подписчиков для каждого сообщения — запрос могут обработать сразу несколько сервисов из разных проектов. Этот подход имеет несколько издателей, а также несколько потребителей. Существует временная зависимость для издателей и потребителей.
Я выбрал три разных реализации:
IBM MQ — Point to Point тип;
Kafka — Publish/Subscribe;
и RabbitMQ — он не имеет типа, поскольку реализует оба типа, а они используют разные протоколы.
Формат данных, опять же, у них конкретно не указан.
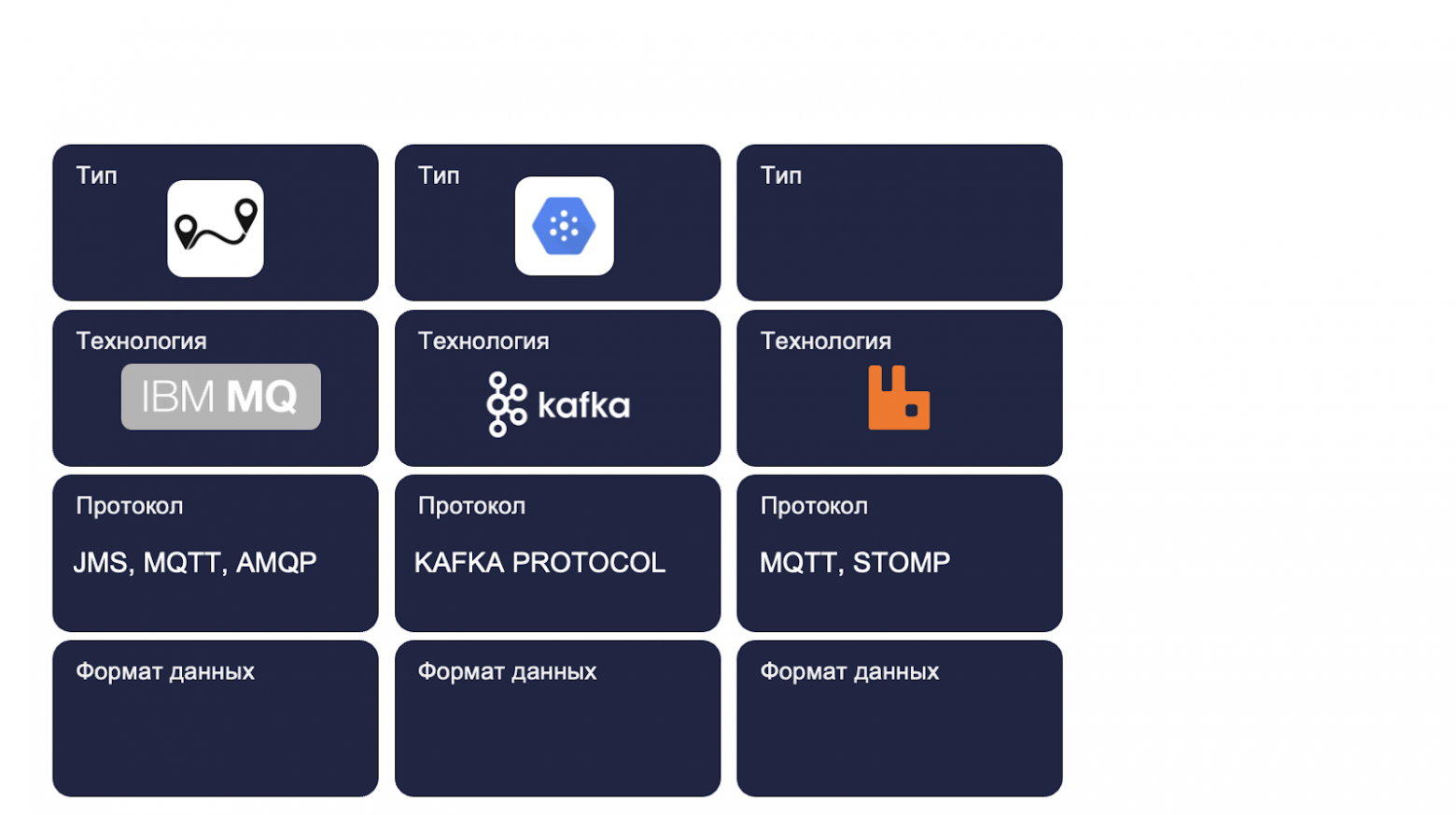
Небольшое отступление. Я все протоколы выносил в одну ячейку. Но это некое упрощение, поскольку они все находятся на разных уровнях, решают разные задачи и это не совсем корректно.
Вернемся к нашей схеме и выберем нужный сервис.
По нашей архитектурной схеме понятно, что нам нужно просто получить запросы от клиентов, где-то их временно сохранить, чтобы они не потерялись и обработать.
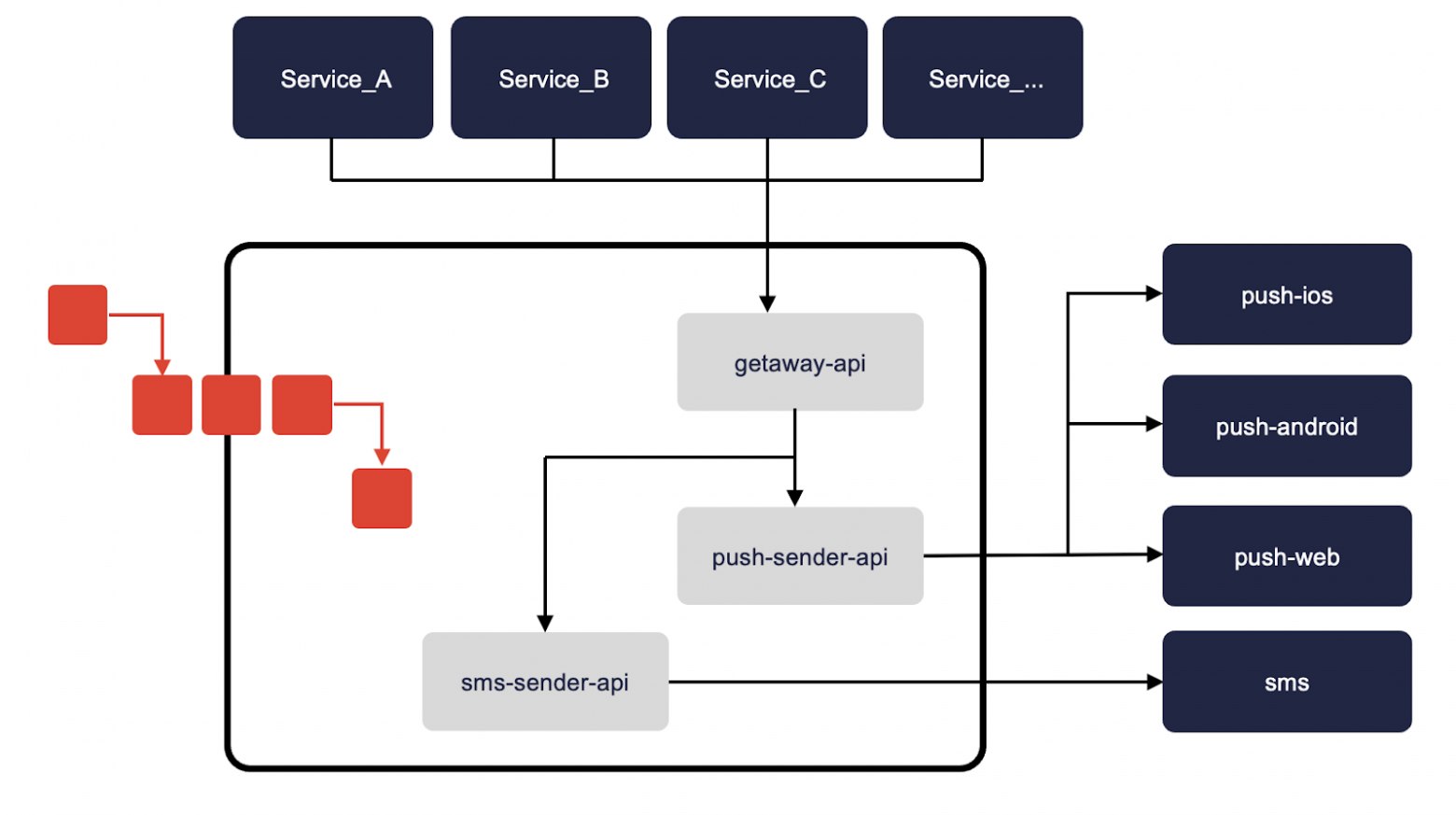
В принципе, нам подойдет любая технология. Но, наверное, лучшим решением будет какой-нибудь Point to Point. Я бы выбрал RabbitMQ, поскольку он как раз поддерживает Point to Point, это Open Source технология, много документации, легко внедрить и, в принципе, популярная.
Но у нас есть одно ключевое требование — безопасно и быстро внедрить в инфраструктуру. А на больших проектах с этим бывают сложности. И сложность в том, что на нашем проекте развернута только Kafka, а значит придется использовать её.
Заключение
Разнообразие инструментов и протоколов межсервисного взаимодействия возникло в ответ на уникальные потребности каждого проекта. Но, надеюсь, на примерах Альфа-Банка мне удалось донести, как происходит их отбор в нашем случае и как правильный выбор инструментов влияет на эффективность и надежность системы. Именно гибкость выбора обеспечивает оптимальное решение для каждой конкретной задачи.
Статьи, которые могут быть интересны:
Эксперименты на 3,5 квадратах: качнул сетап от «бомж-уровня» до «мини-студии»
Как у нас почти получилось сделать автономного робота для «Битвы Роботов»
Как дизайнеру с помощью макетов оптимизировать процессы и сэкономить время
База об организации процесса разметки: команда, онбординг, метрики
Подписывайтесь на Телеграм-канал Alfa Digital. Рассказываем о работе в IT и Digital, делимся полезными советами, новостями, видео с митапов, краткими выжимками из статей и многим другим, иногда шутим.
Подписывайтесь на блог Альфа-Банка на Хабре, впереди много хороших статей.
