Это история о том, что подсказка умная, а мы — нет :))
Рассказываем, как мы планировали сделать всё быстро и просто, а получилось как всегда не так. Но мы справились, хоть и не сразу. Речь пойдёт о навигаторе 2ГИС: пользователи строят в нём маршруты и приезжают, куда планировали. Это навело нас на мысль, что хорошо бы предугадывать желание пользователя — предлагать точку назначения и строить маршрут сразу, как только он открыл приложение. Например, пользователь-отец только подумал, что пора забирать ребёнка из детского сада, открыл 2ГИС, а мы ему — готовый маршрут с учётом пробок.

Все счастливы — мы понимаем пользователя, пользователь благодарен (ему не пришлось вбивать адрес, а возможно, и вспоминать его), ребёнка забрали домой.
Понятно, что не у всех есть дети или работа, на которую надо ездить, поэтому решили сосредоточится на качестве, а не на охвате.

Что мы стали делать
«Начните с себя» — говорят нам мотивационные плакаты, и мы задумались: ездим ли мы куда-то постоянно? «Да», − сказали мы себе. Проверили гипотезу и выяснили, что другие люди тоже ездят в одни и те же места.
Результат превзошел все ожидания:
во-первых, 40% маршрутов в приложении приходятся на объекты, куда человек уже ездил;
во вторых, число таких мест не так велико: человек в среднем строит повторные маршруты всего в 10 мест.
Таким образом, задача довольно проста: выбрать одно место из 10 и построить по нему маршрут. Нужно только научиться определять, почему и при каких условиях люди возвращаются в эти условные 10 мест.

Что могло пойти так
Итак, мы прикинули сценарии, по которым люди строят повторные маршруты: забрать ребёнка из детсада и школы, съездить на работу и вернуться с работы домой, увезти рассаду на дачу, вечером заехать поужинать в кафе. Логично, что люди ездят по этим сценариям примерно в одно и то же время: на работу с утра, после 18.00 — домой; на дачу или в кафе — пятничным вечером.
Таким образом, повторюсь, казалось абсолютно логичным сделать алгоритм на основе периодичности обращений пользователя к одному и тому же месту. Казалось, что найти такие повторяющиеся паттерны будет просто, и что их будет много — все мы и правда ездим домой каждый вечер.
Но всё пошло не так.

Что конкретно пошло не так
Напомню, что мы решили сделать алгоритм на основе периодичности обращений, но поведение пользователей на переодичность мы не проверили. Периодичность нам казалась чем-то само собой разумеющимся — мы сами работаем по постоянному графику (и живём тоже :)). Да, бывают большие праздники, но обычных «одинаковых» дней сильно больше.
Мы ожидали увидеть, что большинство маршрутов в определенное место будут выполнятся в один и тот же день недели и схожее время суток. Например, пользователь-отец ездит в детский сад утром каждого вторника.
Во-первых, это оказалось ложным ожиданием: люди не ездят в одно и то же время в одно и то же место. Даже домой. Даже в детский сад.
Во-вторых (и, думаю, вы уже давно догадались), периодически ездить в одно и то же место и периодически использовать для этого навигатор — хоть и связанные процессы, но явно не одинаковые. Фактически мы предполагали, что повторные поездки — как долгосрочные интересы, нечто устоявшееся. Конечно, люди действительно каждый день ездят с работы домой. Но они могут делать это без навигатора.
А ещё они могут ездить в спортзал три месяца каждый день, потом бросить на полгода и снова начать, но теперь уже — два раза в неделю.

Оказалось гораздо эффективнее прогнозировать интерес к месту в определенное время вне зависимости от того, бывал человек там в это время или нет. Мы смещаем фокус, и вместо устоявшихся привычек пытаемся восстановить полную картину возможных действий пользователя.
В этой картине пользователь — хаотический нейтрал, он может сделать что угодно в любой момент! Поехать в университет в три часа ночи или утром построить маршрут домой находясь… дома? Запросто! *нервный смех*
Прогнозировать все возможные маршруты пользователя — более сложная задача, так нужно учитывать гораздо больше факторов, чем просто «ездил на прошлой неделе», однако и охват пользователей будет в разы выше.
Что пошло так
Мы начали решать задачу как классическую классификацию, где мы прогнозируем вероятность, что пользователь построит маршрут в тот или иной объект в определенную дату и время суток.
Мы уже поняли, что человек может построить неожиданный маршрут (вау!) и что маршруты в приложении не всегда отражают поездки в реальности. Если человек в прошлом не строил маршрутов вечером в четверг, это вовсе не значит, что он не сделает это в будущем.
Поэтому при классификации мы отталкивались от того, что вероятность построения маршрута — пусть и минимальная — но есть всегда, для любой комбинации даты и времени. И наша задача — научить модель эту вероятность считать.

Какие данные рассматриваем
Для начала нам нужно было:
выбрать период, который будем рассматривать при формировании признаков для модели;
выделить маршруты, которые мы будем пытаться классифицировать.
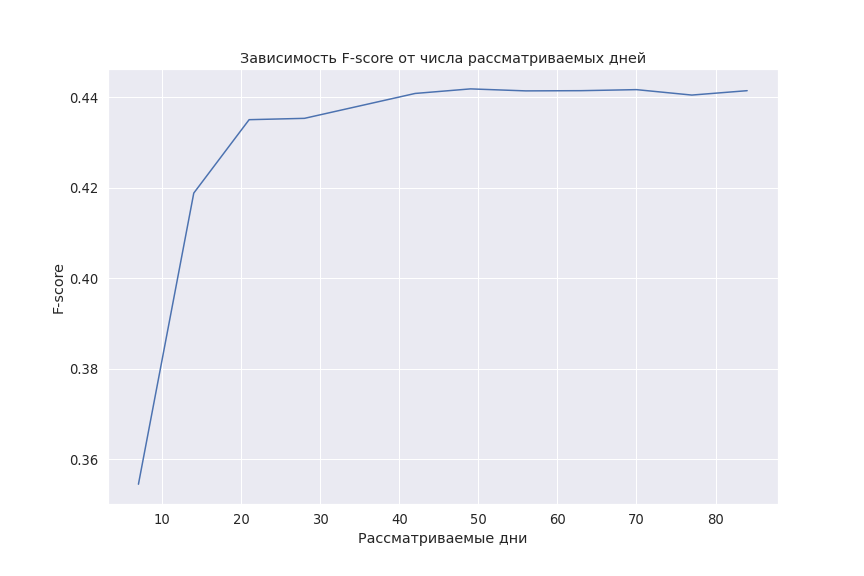
Если смотреть на данные за слишком большой период, в признаки попадут интересы пользователя, которые уже изменились. А если за слишком короткий — не получится понять пользователя достаточно хорошо. Здесь мы просто увеличивали период рассмотрения до тех пор, пока это увеличение не перестало давать положительного эффекта, и остановились на данных за последние два месяца.
Ниже — график с качеством модели в зависимости от периода, за который мы смотрим на маршруты. Можно заметить, что после ~45 дней качество перестаёт расти, и, в целом, можно было остановиться здесь. Но мы хотели захватывать чуть больше долгосрочных интересов пользователей, немного жертвуя точностью, поэтому пошли дальше.
При выборе маршрутов для классификации важно определить, что́ мы вообще можем адекватно предсказывать.
С одной стороны, мы не можем хорошо понять интерес человека к месту, если ранее он не строил туда маршрутов или делал это очень редко.
С другой стороны, большинство маршрутов в приложении как раз приходятся на подобные места. 82% маршрутов построены туда, где за последние два месяца пользователь был однажды или не был вообще.
В данном случае мы отсекли эти 82% маршрутов, потому что качество подсказок на них было бы слишком низким. Например, человек вряд ли вернётся туда, где был всего однажды за последние два месяца (вероятность в среднем 0.8%). И ещё менее вероятно, что он поедет в конкретное новое место.
В итоге мы смотрим только на места, куда человек ездил больше двух раз за последние два месяца.
. И какова вероятность, что он туда вернётся на следующей неделе.")
Можно поспорить, что два маршрута — тоже слишком мало для понимания поведения пользователя. Но, игнорируя такие маршруты, мы бы игнорировали и малоактивных пользователей, что не здорово.
Как считаем вероятность повторяющегося маршрута
Допустим, мы хотим понять, поедет ли Человек Человекович в школу утром вторника, чтобы отвезти туда детей. Для этого мы посмотрим на маршруты Человека, построенные в эту школу (и во все остальные объекты) за последние два месяца, и дадим ответы на всевозможные вопросы про прошлые маршруты, например:
Ездил ли Человек в школу утром вторника до этого?
Ездил ли Человек в школу утром любого другого дня?
Ездил ли Человек в школу во вторник вне зависимости от времени?
Ездил ли Человек в школу в похожее время с тем, что мы рассматриваем (например, утро вторника похоже на утро среды и утро понедельника, но не похоже на вечер субботы)?
Как давно был первый и последний маршрут в эту школу?
Как часто и с какими промежутками времени человек ездил в эту школу?
И так далее.
В зависимости от комбинации значений этих характеристик, мы будем увеличивать или уменьшать ожидаемую вероятность поездки. В качестве алгоритма для выявления подобных зависимостей используем градиентный бустинг, в частности, lightGBM. Результат работы этого алгоритма — набор деревьев, каждое из которых отвечает на последовательность вопросов «Да / Нет», и на основе ответов выдаёт маршруту определенный скор. Потом все деревья голосуют вместе, чтобы получить финальную вероятность маршрута.
Представим: мы прогнозируем маршрут вечером вторника. Тогда одно из деревьев в урезанном варианте может выглядеть так (урезанное, потому что целиком оно даже не влезет на страницу):
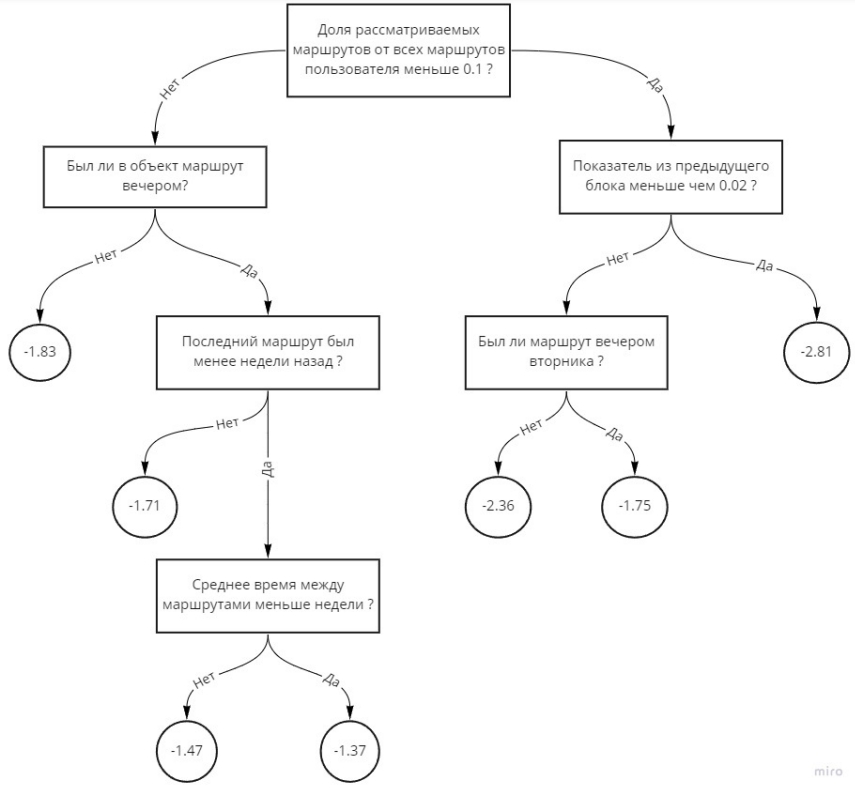
Понятно, что мы знаем только о поездках через 2ГИС, и что маршруты могут быть неожиданными. Поэтому в частных случаях вероятность, которую мы считаем, не будет отражать реальную картину. Но в среднем — будет.
Вероятности построения маршрутов мы считаем каждый день, чтобы учесть в том числе активность человека за вчерашний день. Затем передаём данные в приложение, где подсказка «Построить маршрут» отображается на главном экране, если вероятность построить маршрут выше определенной границы, например, 15%. Исключение составляют дом и работа пользователя, которые отображаются всегда. Например, вечером пятницы подсказки могут выглядеть так, где зеленым выделены подсказки которые пойдут в приложение:

С границей для отображения подсказки сейчас экспериментируем. Выставление слишком высокой границы ведёт к тому, что мы не спрогнозируем важные для пользователя маршруты и не сэкономим ему время. А слишком низкая граница заспамит пользователя бесполезными подсказками.
Работаем и над второй итерацией алгоритма. Он станет более качественным за счёт прогнозирования отдельных часов (а не утро/день/вечер) и благодаря приоритезации объектов, которые имеют большую значимость для пользователя в целом. Спрогнозировать, что человек поедет в магазин, в котором был вчера — неплохо, но гораздо важнее прогнозировать постоянные маршруты.
Итоговые итоги
Мы хотели сделать простенький алгоритм, который прогнозировал бы интересные пользователю места чуть ли не SQL-запросом. Аспекты использования приложения и случайные решения людей заставили нас задуматься — в итоге мы воротим признаки, описывающие очень разряженный временной ряд. Зато повеселились!

