
Меня зовут Миша Лиз, я специалист по анализу данных в 2ГИС. Мы используем методы машинного обучения в самых разных задачах: поиск оптимального маршрута, нахождение неточностей в дорожном графе, модерация загружаемых фотографий, извлечение фактов из отзывов и многое другое.
Я в основном занимаюсь задачами, связанными с компьютерным зрением. Сегодня поговорим о том, как мы дополняем нашу карту дорожными знаками, как работаем с данными и формализуем задачи. Об этом я подробно рассказывал на Data Fest Siberia.
Дорожные знаки — один из базовых компонентов любого навигатора. Мы собираем и регулярно обновляем информацию о них: добавляем новые и удаляем неактуальные. Для этого используем кадры с видеорегистраторов, глаза и руки картографов и немного ML-магии.
Раньше наши картографы просматривали все видео вручную. Им нужно было найти знак, определить его класс и атрибуты, по карте и текущему местоположению водителя понять, куда его ставить. С развитием технологий компьютерного зрения получилось сократить подобный ручной труд — автоматизировать распознавание и добавление знаков.
Это база
Начали с базового пайплайна. Взяли стандартный детектор и стали детектить все знаки, а отдельным атрибутом предсказывали класс знака, например, 2.1 или 5.15.3.

Столкнулись с дисбалансом классов, поэтому решили добрать редкие знаки для более точной детекции.
Предположим, у нас есть редкий знак 2.4, второстепенная дорога и куча пешеходных переходов. Для детекции надо разметить все знаки на изображении, чтобы обучить модель.

Тут стоит отметить, что все знаки имеют похожий вид. Поэтому дисбаланс классов больше влияет на определение класса знака, чем на его выделение. Если детекционная модель ни разу не видела знак, то она всё равно его найдёт (так как он похож на другие знаки), но не сможет определить его класс.
Поэтому мы отделим задачу определения класса знака от детекционной модели. То есть вместо одной модели у нас будет две: одна выделяет знак, другая определяет его класс. С дисбалансом классов будем бороться, добирая данные только в классификационную модель. Тогда вместо разметки всех знаков на изображении нужно будет размечать только редкие знаки.

Сначала находим все знаки на изображении, потом определяем их класс, прогоняя через классификатор. Процесс разметки ускоряется — проще работать с дисбалансами.

Так родилось базовое решение. Но мы поняли, что нельзя просто взять скопом какие-то данные и закинуть их в сетку — нужно добрать определённые кадры. А ещё добрать данные с разным временем года, временем суток (сумерки, день, утро) и погодными условиями (дождь, снегопад).
Также стоит учесть и разные типы местности, например, городскую трассу или просёлочную дорогу. С некоторыми кадрами мы не работаем вообще, так как знаки на них неразличимы даже для человека: ночные кадры с плохим освещением или кадры в ливень.
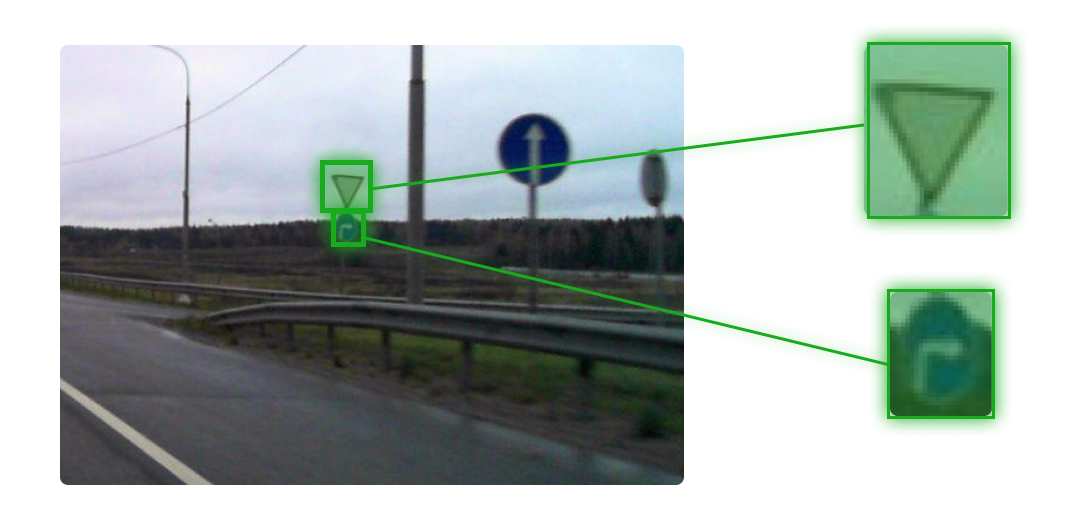
Когда знак выходит боком
Сколько знаков вы видите на изображении?

Наша модель, как и вы, распознаёт четыре знака. Но картографы часто удаляют два боковых знака, потому что они не относятся к дороге, по которой мы движемся. Так после ручной проверки картографом выкидывалось 65% результата работы сетки — те самые боковые знаки.

Мы стали проверять, боковой знак или нет: если знак боковой, не отдаём его дальше в классификатор.

С 65% ручных исправлений упали до 52%. Но хотелось лучшего результата.
Начали копать и поняли, что боковые знаки бывают разных типов. Есть простые боковые знаки, которые очень легко распознаются. Как правило, они перпендикулярны дороге.
Ещё есть знаки на примыкающих дорогах. Их хорошо видно, но они не относятся к нужной нам дороге:
Также есть знаки с другой дороги, которые смотрят на нас, но тоже нам не интересны:

Знаки на развилках относятся к дороге, которая идёт на съезд, и не относятся к главной:

Так рождается новая задача — предсказать тип бокового знака.

И с 65% ручных исправлений мы опускаемся до показателя в 15%.
Знак в положении
Когда изучали боковые знаки, проверяли влияние положения относительно дороги на то, является знак боковым или нет. Но значимой связи не выявили. Однако, знать положение знака оказалось полезным.
Некоторые положения помогли сократить время обработки одного трека картографом:
Дублирующие знаки. Например, знаки направления движения по полосам 5.15. Они дублируются часто, и если есть какой-то знак сверху и сбоку, можно брать только один из них.

Знаки на машинах. Они не боковые, но тоже не нужны нам.

Знаки ремонтных работ, которые стоят на дороге.

Добавления атрибута положения знака относительно дороги уменьшает время обработки на трек одним картографом с 25 минут до 22.

Не классификацией единой
Дальше занялись знаками со значениями — грузовые и ограничения скорости. Раньше картографы вписывали их вручную.
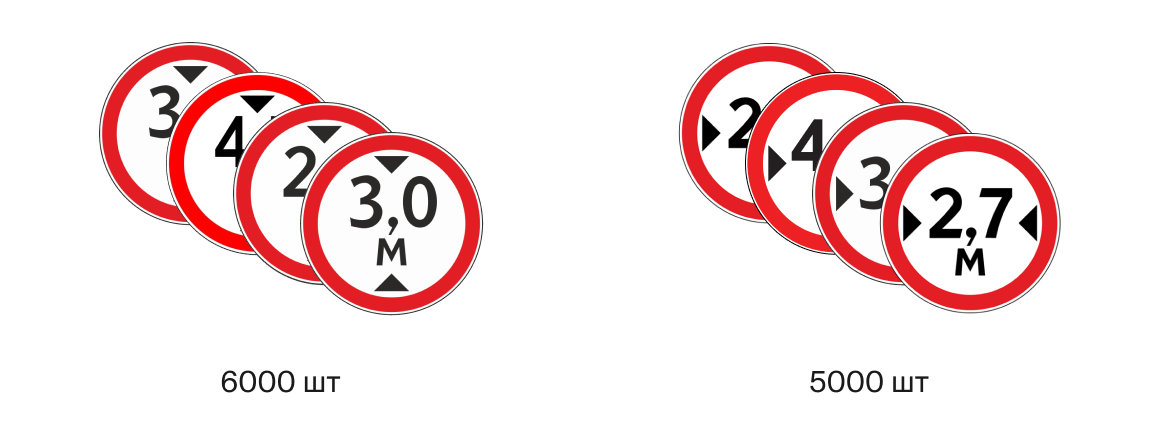
Простое решение — добавить такие знаки отдельными классами. Например, если есть знак ограничения скорости 3.24 с ограничением 40 км/ч, то для него делаем класс 3.24.40. Но работать такой вариант будет плохо:
Из-за дисбаланса классов — значений ограничения скорости очень много, их тяжело собирать.
Есть неустойчивость к новым значениям. Если в датасете не было значения 120, то модель не способна предсказать такой класс.
Есть очень похожие знаки, но при этом из разных классов. Например, знак ограничения высоты и ширины. Даже люди делали кучу ошибок на этих знаках — такие классы совсем запутают сетку.
Поэтому мы ушли от классификации и добавили модель OCR для определения значения внутри знака. Отметим, что OCR-модели обычно детектят поля с текстом, но мы уже задетектили знак, и на нём есть только одна строка со значением, которое нужно распознать. Поэтому в нашем случае детектировать поле с текстом не нужно.

Таким образом, если мы учим классификацию отделять не только класс знака, но и значение внутри него, то сильно усложняем жизнь модели: она должна обращать внимание не только на стрелки справа или сверху, но ещё и на само значение. Однако, если мы классифицируем знаки без учета значения, то модели нужно смотреть только на стрелки.

У нас может быть 1000 примеров с ограничением высоты 3 метра и всего один пример с ограничением ширины 3 метра. И тут не надо гадать, к какому классу классификатор отнесёт последний знак.

Но если снимаем ответственность с классификации за предсказание значений, она смотрит не на конкретный класс со значением 3.24.40, а на класс знака целиком и распознаёт эти стрелки. Так мы упрощаем задачу классификации, перекладывая часть ответственности на OCR-модель, которая предсказывает только значение.
Это отчасти помогает бороться с дисбалансом конкретных значений, потому что мы смотрим на значение не внутри одного класса, а внутри всех классов со значениями.
Теперь время обработки трека картографом снизилось с 22 минут до 16.
Задаём направление
Кроме знаков со значениями, которые картографы заносили руками, есть знаки направления движения по полосам — 5.15.1, 5.15.2. Отличаются они тем, что 5.15.2 только на одну полосу, а 5.15.1 сразу на несколько полос.
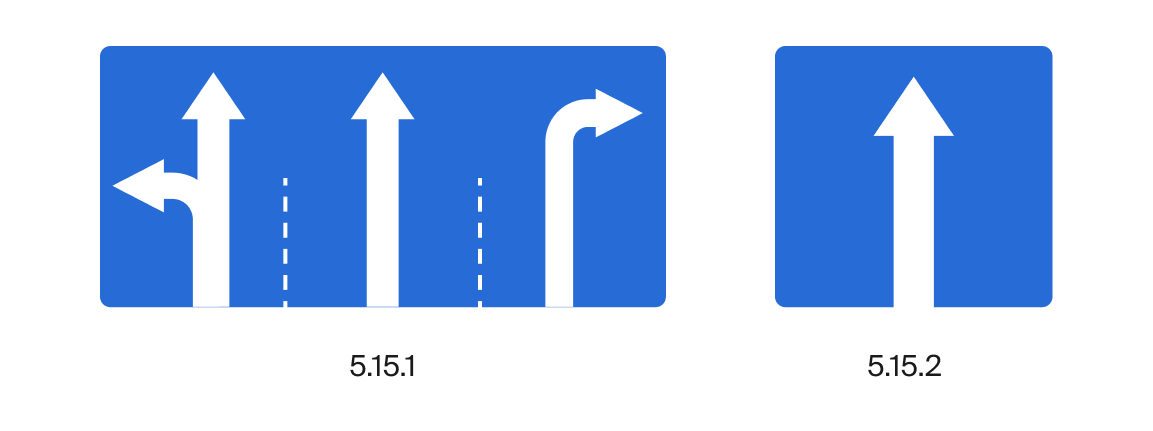
Здесь абсолютно те же проблемы с обучением:
Дисбаланс классов.
Комбинация стрелок. Прямо — это один класс, прямо плюс направо — уже другой.
Комбинация полос движения. На одном знаке может быть несколько стрелок. Например, есть два почти одинаковых знака с небольшими отличием в левом направлении.

Решение — снова оптимизировать пайплайн.
Так 5.15.1 из классификатора сразу пойдёт на OCR, которая распознает направление движения по полосам.

Это помогло сократить работу картографов с 16 минут на один трек до 12.
Итого
Наш итоговый пайплайн выглядит примерно так. Сначала делаем фильтрацию совсем плохих кадров, оставшиеся кадры передаём в детектор для выделения знаков, найденные знаки отдаём в классификатор. Потом нужные классы передаём в OCR, который работает, например, со значениями типа знаков 3.24 с направлениями 5.15.

Получаем результат: один картограф плюс наш ML-сервис работают как четыре картографа. Раньше мы обрабатывали примерно 100 000 км в год, а теперь 1 000 000 км в год. А значит, мы можем держать в актуальном состоянии бОльшую местность и быстрее обрабатывать новую.
