В 2ГИС мы аккумулируем огромное количество геоданных, с которыми взаимодействуют миллионы пользователей ежедневно. Анализируя их, мы можем получить ценную информацию и найти важные идеи для развития городов. Эти данные также полезны организациям.
Чтобы помочь бизнесу и муниципальным организациям, мы создали 2GIS PRO — инструмент для GPU‑аналитики, с возможностью визуализации огромного количества данных на карте в виде диаграмм и графиков.
Расскажем, как мы получаем такую картинку, как это всё работает под капотом, и посмотрим, на что способен ваш браузер, ведь ему предстоит отображать сотни тысяч объектов одновременно.
На старте у нас было всего 2 основных требования со стороны будущих пользователей:
«Хочу фильтровать все объекты по всем интересующим меня атрибутам и видеть агрегированную информацию».
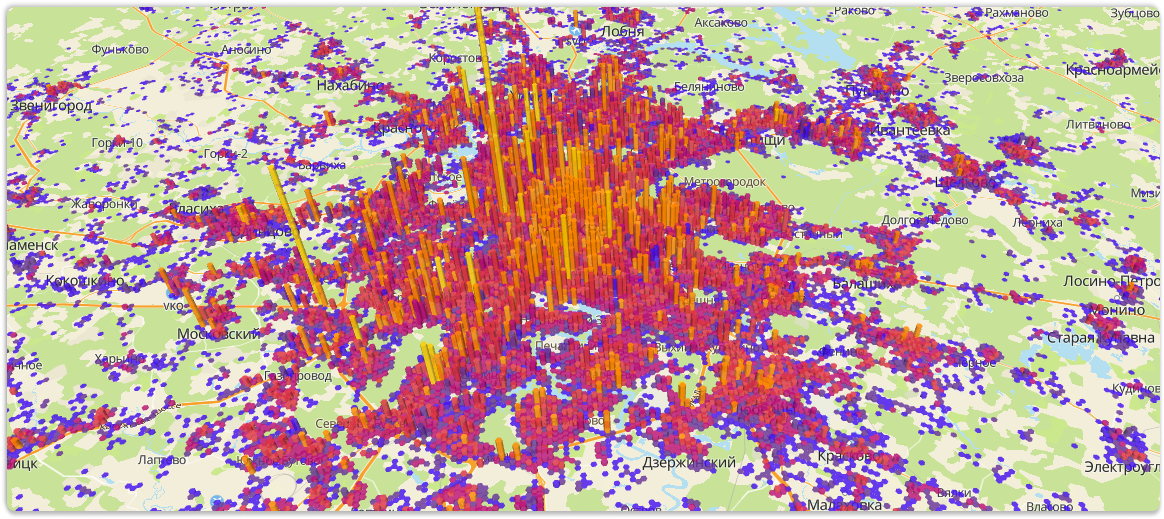
«Хочу видеть все здания Москвы и области в виде гексагонов на карте и раскрашивать их в зависимости от этажности».
А теперь поговорим об этом подробнее.
Как фильтровать и агрегировать всё подряд
Это относительно простая задача, нужно лишь выбрать подходящую базу данных, всё правильным образом проиндексировать и написать пару‑тройку запросов.
Мы выбрали для этих целей elasticsearch, у него из коробки было практически всё, что требовалось:
Возможность хранения миллионов документов
Быстрая индексация по произвольным атрибутам, включая геопоиск
Хорошая агрегация данных
Оставалось только сверстать json-описание агрегатов — описать в общем виде представление, в котором хочется показывать данные на клиенте по выбранному типу объектов.
В итоге мы получаем вот такую картинку

Мы можем менять это представление просто через БД, выбирать различные графики и диаграммы, собирать агрегаты в разрезе нужных атрибутов. А ещё — можем делать это на лету.
Кусочек конфигурации, на основе которого получается результат выше:
[
{
"caption": "Total count of buildings",
"agg_type": "value_count",
"group_id": "building_counts",
"placement": "header"
},
{
"filter": [
{
"tag": "purpose_group",
"type": "number",
"value": "1000001"
}
],
"caption": "Administrative and Commercial",
"agg_type": "value_count",
"group_id": "building_counts",
"placement": "chart"
}
]Как показать миллион гексагонов
Разберем второе требование к продукту — заказчики хотят видеть все здания Москвы и области в виде гексагонов и раскрашивать их в зависимости от этажности. Погодите, но ведь речь идёт о миллионах объектов!
Вообще, для отображения карты у нас есть классный mapGL-движок, который умеет показывать все наши геообъекты на карте и делает это довольно быстро. Но у него есть ряд особенностей: данные довольно статичны, они нарезаны на тайлы и на клиент загружается относительно небольшой сет упакованных в тайлы данных, попадающих во вьюпорт. Хочешь показать редко-меняющиеся данные и есть время на их предварительную подготовку и нарезку — используй этот движок.
Но если нужна динамика и гибкая настройка визуализаций в виде гексагонов, гридов, хитмапов, то потребуется другой механизм. Для решения этой задачи мы взяли библиотеку deckgl — очень крутой опенсорсный инструмент, который из коробки давал нам практически всё, что требуется.
Осталась одна проблема — объектов всё равно миллионы. Чтобы красиво нарисовать те же гексагоны, требуется загрузить все данные, рассчитать минимумы/максимумы, высоты, палитру и все остальные параметры, зависящие от атрибутов данных. А потом — отрисовать всё это богатство поверх нашей базовой карты. И желательно делать это не на топовом железе, с каким то вменяемым уровнем потребления памяти, и чтоб не тормозило и можно было пользоваться и делать необходимый анализ.
Подготовка данных
Погодите, но не зря ведь придумали пэйджинг, агрегации, симплификации, тайлирование и множество других умных слов! Всё это нужно, чтобы уменьшить количество объектов до какого-то вменяемого количества, обычно это несколько десятков, максимум сотен. Миллион объектов отдавать на фронт нельзя, работать такое просто не будет.
Или будет?
Да если и будет, то загрузки и обработки данных придётся ждать минуты (или часы, если не повезет). Всё будет крепко тормозить — пользователи будут недовольны. Одним словом, всё нереально.
Или реально?

Первые эксперименты показали, что это реально. Но есть нюансы
Такое количество данных нужно выгрести из эластика. А в нашем случае нужно еще и фильтровать данные по заданным критериям. Иными словами выборка отличается от запроса к запросу — и с ходу её не кешировать.
Нельзя просто так отдать json в 2 миллиона объектов. Это очень долго, от нескольких десятков секунд до нескольких минут. Даже в режиме потокового чтения-сжатия-отправки данных.
Простое и очевидное решение: готовим данные к отправке в фоне, а на клиент временно отправляем кластеризованный результат в несколько сотен и даже тысяч объектов. Тут нет никакого рокет-сайнс: хочешь много данных, придётся подождать.

Сама подготовка данных — это просто задача, которая выбирает данные из хранилища, складывает их в gzip файл и отправляет этот файл в файловое хранилище (в нашем случае — в s3). А на клиент при очередном запросе отправляет уже готовый файл в несколько килобайт или мегабайт.
Это происходит относительно быстро, данные уже готовы, не нужно доставать их из базы, не нужно сжимать, просто стримим файл в выходной поток и всё.
А дальше — магия фронтенда.
Подготовка данных для работы в браузере
Для примера того с какими объемами нам нужно работать, возьмем набор данных со всеми зданиями Москвы. Это, на минуточку, 170 тысяч объектов, которые выглядят следующим образом:
{
"id": "70030076129543595",
"point": {
"lon": 37.874927,
"lat": 55.739908
},
"values": {
"area": 9,
"building_id": "70030076129543595",
"floors_count": 1
}
}Количество ключей в values может быть разнообразным, от 2 до N полей. Это количество ключей зависит от того, какая информации по каждому зданию у нас есть: этажность, год постройки, количество подъездов, тип здания, количество проживающих / работающий людей и др.
Этот слой удобно использовать как подложку для обозначения области аналитики, так как здания естественным образом образуют нужный контур. А поверх можно наложить еще несколько слоев с анализируемыми данными, например со спросом, который даст еще несколько десятков тысяч объектов. Итого — иметь несколько сот тысяч объектов в одном проекте не аномалия, а вполне себе стандартный пользовательский сценарий.
Как работать с такими объемами данных и не блокировать интерфейс
Большинство современных браузеров могут выносить часть работы в отдельный Background Thread через Web Workers API. Изучив все возможности, мы поняли, что можем абсолютно безболезненно вынести всю работу с получением и подготовкой данных в этот слой.
Для удобной работы с WebWorker используем библиотеку СomLink от команды разработчиков Google Chrome.
Интерфейс WebWorker’а — вот такой:
type PromisifyFn<T extends (...args: any[]) => any> = (
...args: Parameters<T>
) => Promise<ReturnType<T>>;
const worker = {
requestItemValues: async (assetId: string, services: Services) {
// В данном методе мы:
// Запрашиваем данные через Axios (библиотека http запросов)
// Складываем их в хранилище данных (кэширование на клиенте)
}
getDeckData: (layerId: string) {
// В данной функции мы подготавливаем данные для работы в deck.gl
}
// … другие вспомогательные методы
}
type ProWebWorker = typeof worker;
type ProWorker = {
requestItemValues: PromisifyFn<ProWebWorker[‘requestItemValues’]>,
getDeckData: PromisifyFn<ProWebWorker['getDeckData']>
}
Как видно, у нас есть 2 основных метода, которые реализуют сначала запрос данных, а после - получение их в нужном формате.
Логика получения с сервера данных не сильно отличается от того, как бы мы это делали в обычном приложении, поэтому перейдем к более интересной части. Поговорим про подготовку данных.
Бинарные данные
На первом этапе исследования работы с фоновой обработкой данных, мы только запрашивали данные и разбирали JSON через JSON.parse, остальные же операции делали в основном потоке.
Вскоре у нас появился очень большой набор данных о спросе — и приложение опять стало блокировать основной поток. Ребята из команды WebGL карты рассказали, что решали похожую проблему через переход к бинарным данным.
Оказалось, у deck.gl дружественный интерфейс для бинарных данных. Это позволяет нам максимально эффективно использовать WebWorker. Дело в том, что передача данных в виде типизированных массивов из фонового потока работает гораздо более эффективно чем передача в любом другом формате, при этом нам не требуется дополнительно трансформировать данные в основном потоке.
Также при передаче бинарных данных важно использовать Transferable Objects чтобы не тратить лишней памяти. У библиотеки Comlink есть специальный метод transfer.
Давайте посмотрим как выглядит формат бинарных данных на примере визуализации Grid
export function getGridData(data: GridHexLayerData) {
return {
length: data.positions.length / 2,
attributes: {
// В значениях у нас будет массив Float32Array со значениями координат
// [37.575541, 55.724986, 36.575541, 54.724986]
// Size же говорит нам сколько нужно взять элементов массива
// чтобы получить координаты одного элемента
getPosition: { value: data.positions, size: 2 },
// В цветах у нас Uint8ClampedArray
// [255, 255, 255, 255, 255, 255, 255, 255]
// Тут мы уже берем 4 элемента чтобы превратить это в RGBA
getFillColor: { value: data.colors, size: 4 },
},
};
}
Не трудно заметить, что формат достаточно трудночитаемый. Но именно за счет него мы получаем высокую скорость отображения данных поверх карты. Разработчик может всегда получить исходные данные в рамках WebWorker с хорошо знакомым интерфейсом JSON.
Агрегация данных
Для части визуализаций (grid, hex, h3) требуется предварительная агрегация. В исходных данных у нас представлены полноценные наборы без каких либо трансформаций на сервере. Это нужно для того, чтоб не перезапрашивать данные с сервера при каждом изменении способа визуализации или её параметров.
В рамках агрегации мы превращаем наши тысячи объектов в коллекцию ячеек, которые будут отображены на карте, а также собираем различную статистическую информацию. Например, минимальное и максимальное значение выбранной пользователем основы цвета среди всех точек. Такие данные нам нужны, чтобы мы могли построить легенду значений.
Помимо этого мы храним значения различных атрибутов для быстрого доступа к ним из подсказок и карточек объекта.
Производительность
В начале рассказа о Web Worker, я привел пример двух слоев, состоящих из примерно 200 000 объектов. Насколько быстро мы сможем выполнить получение, подготовку и отображение этих данных?

Как видно на демо, загрузка не превышает 3 секунд. При этом слой с тепловой картой (данные по спросу) появились в момент отображения карты. Если же взять все реальные проекты, которые мы изучали, максимальная длительность на среднем офисном ноутбуке составляла 12 секунд, при объёме данных в несколько миллионов точек.
Отсутствие лишней работы на сервере, быстрая клиентская фоновая загрузка и подготовка данных, бинарный формат и эффективный GPU движок в deck.gl позволяют отображать практически "безграничный" объём данных!
Что еще можно попробовать
Мы вполне довольны текущим решением. Кажется, удалось элегантно выбраться из ситуации, которая казалась безнадежной.
А вообще, хочется попробовать «растянуть» процесс получения данных, например, с помощью потоковой отрисовки в NextJS и других клиентских библиотек. Думаю, это еще улучшит пользовательский опыт. И сделать данные сразу в бинарном формате при подготовке данных на сервере... Но это, как известно, уже совсем другая история.
Благодарности
С написанием статьи по части фронтенда мне помогал Кайсаров Кирилл, за что ему огромное спасибо!
