Комментарии 67
Подсказки для аргументов работаю из ряда вон плохо. Особенно для шаблонных классов. Особенно с наследованием и лямбдами в качестве параметров. А иногда и вообще просто отказывается показывать эти подсказки. Проект большой и сложный, но в целом всё корректно написано, должно бы работать.
Плюс, хотелось бы кастомизации с какой стороны от переменной отображать подсказку. Я бы хотел иметь возможность видеть их с правой стороны, чтобы форматирование вот такого кода не плыло:
object->method(
true,
false,
100,
{}
);P.S.
Всё еще нет при отладке в окошке для переменных кнопки "показать значение ОДНОЙ переменной в HEX". Как переключить все и сразу мне известно, но мне нужно ТОЛЬКО одну переменную. Шел 2019-й...
Про подсказки. А можно в трекер сразу примеров, где не работает? Мы посмотрим и обязательно починим.
Про кастомизацию — как-то традиционно во всех языках эти подсказки слева. Но опять же рекомендую вам тикет в трекере завести. Если запрос окажется важен и другим пользователям, то мы обязательно его рассмотрим.
Про Hex. Именно только одной? Почему всех сразу плохо (там же и hex, и обычная запись рядом показываются в таком случае)? Поясните, пожалуйста.
А можно в трекер сразу примеров, где не работает?
Не можно. NDA как-никак. Воспроизвести на маленьком объеме кода не получается, а разбираться что-там сломалось на большом проекте не очень как-то хочется.
Про кастомизацию — как-то традиционно во всех языках эти подсказки слева. Но опять же рекомендую вам тикет в трекере завести. Если запрос окажется важен и другим пользователям, то мы обязательно его рассмотрим.
Заведу вечерком.
там же и hex, и обычная запись рядом показываются в таком случае
Что-то я не замечал вывод обычной записи. Мб смотрел куда-то не туда. Приду домой проверю.
Традиционный вопрос, с UE4 уже наконец полноценно работает? :)
Особый упор на UE4 разработку, с перфоманс-оптимизациями для UE4 кода и специальными фичами (например, понимание UE4 naming правил, понимание макросов рефлексии и спецификаторов, и пр.) делается в ReSharper C++ (плагин для VS) + (по секрету) мы планируем добавить UE4 поддержку в Rider (то есть C++ с msbuild/msvc как в ReSharper C++). Именно Rider будет такой gamedev IDE для Unity & UE4, в каком-то смысле.
Resharper — хорошо, но не прекрасно, т.к. win-only, в отличие от CLion. Ну и вообще, если честно, необходимость обвешивать IDE за $500 (или сколько там сейчас VS Pro стоит) сверху ещё и плагинами, чтобы получить удобное для работы окружение, вызывает у моей жабы приступы жадности. Хоть деньги и не мои, а работодателя, бюджет всегда имеет ограничения и если для повышения эффективности разработки куплено что-то одно, значит не куплено что-то другое.
Но по части Unreal Engine — там 95% разработки (по данным самих Epic Games) это desktop/console/Windows dev. Тут ReSharper C++/Rider просто ближе лежат.
К тому же, в Rider уже есть продвинутая поддержка Unity. И хочется, наверное, два основных движка из GameDev покрыть одной IDE. Так как полно студий, которые используют и то, и другое.
CLion в свою очередь ориентируется именно на кросс-платформенную C++ разработку, особенно на финансы/банкинг/трейдинг, AI, embedded (новое для нас направление), и прочее. И хотя в CLion сейчас есть поддержка и MSVC, и даже экспериментальный отладчик для него, вряд ли мы будем углубляться в специфику Windows платформы в CLion, а тем более в специфику UE4.
Написать там лучше — тяжело, к сожалению. Надо как-то CLion-у объяснить, где сам движок, чтобы он его проиндексировал. Но в целом, там еще целое поле непаханное для улучшений. Но у нас нет на это ресурсов.
Они сами, как я понимаю, в основном все из командной строки делают, запускают generate.sh там скрипт в сорсах (или как он точно зовется). Знаю одного человека там, который на Linux в CLion с CMake работает)
Есть проблема: при использовании CLion для разработки, во время компиляции большого проекта вне IDE сама среда просто встаёт колом: ввод не работает, прокрутка не работает, меню не открываются. Не тормозит, а просто перестаёт отвечать какое-то время.
Проект использует cmake, оперативной памяти хватает, процессор естественно загружен, но другие приложения в этот момент отзывчивости не теряют вообще.
С чем, на ваш взгляд, такое поведение может быть связано и как можно исправить? Вещь исключительно специфичная для CLion, как я уже сказал — на другие приложения не распространяется и если, например, использую vscode с настроенным cmake tools, то тоже фризов нет вообще.
С чем, на ваш взгляд, такое поведение может быть связано и как можно исправить?
У меня была похожая ситуация. Оказалось дело в GC, Java GC если точнее.
После серии мега фризов сама IDE предложила увеличить макс. размер
используемой памяти для jvm и все не то чтобы залетало, но подвисание UI исчезло.
Пара небольших идей:
1) Могли бы вы, пожалуйста, запилить показ значений переменных из cmake, например, при наведении курсора на ней? Было бы очень удобно, и сделать вроде бы несложно, т.к. они лежат в cmake кэше.
2) Когда на windows я делаю Install проекта, то всегда сталкиваюсь с досадой от того, что требуются права админа на запись в program files, приходится перезапускать clion. Было бы здорово автоматически запрашивать их повышение.
3) Swap двух строк через ctrl+shift+up/down очень часто выдаёт совершенно неожиданный результат. Я хочу просто поменять две строки местами, но, как правило, у автоформаттера на это свои планы. В результате я своппером не могу пользоваться.
Спасибо!
1) Могли бы вы, пожалуйста, запилить показ значений переменных из cmake, например, при наведении курсора на ней? Было бы очень удобно, и сделать вроде бы несложно, т.к. они лежат в cmake кэше.
Только CMake Cache или вообще переменных? (в общем случае, попахивает отладчиком, и кстати такие попытки были, есть даже 3rd party плагин для старых версий CMake). Я вот тут завела реквест, но наверное хорошо бы случаи использования поподробнее там описать.
2) Когда на windows я делаю Install проекта, то всегда сталкиваюсь с досадой от того, что требуются права админа на запись в program files, приходится перезапускать clion. Было бы здорово автоматически запрашивать их повышение.
Завинула в реквест
3) Swap двух строк через ctrl+shift+up/down очень часто выдаёт совершенно неожиданный результат. Я хочу просто поменять две строки местами, но, как правило, у автоформаттера на это свои планы. В результате я своппером не могу пользоваться.
Хорошо бы пример. Можно сразу в трекер.
Но в целом, автоформатирование используется во многих действиях в CLion. Следует, наверное, настроить правила форматера так, как вам надо, и тогда проблем не будет.
3) Swap двух строк через ctrl+shift+up/down очень часто выдаёт совершенно неожиданный результат. Я хочу просто поменять две строки местами, но, как правило, у автоформаттера на это свои планы. В результате я своппером не могу пользоваться.
Я в таких случайх использую Alt+Shift+Up/Down, это простое перемещение строк без учета семантики конструкций и без вызова форматтера. Попробуйте, может, найдёте использование этих экшнов для себя более удобным, например, в сочетании с Expand/Shrink Selection перед перемещением строк.
Собственно если сравнивать с qt creator.
Основная притензия я так и не понял как задеплоить и автоматом запустить под gdbserver'ом приложение.
Есть arm с linux, приложение собирается, задеплоить тоже вродее более менее понятно, но вот чтобы запустить отладку предлагается запускать вручную gdbserver на этом арме. Хотя уже есть настроеный ssh и ide моглабы сама это сделать.
Почему нельзя как в qt creator нажать кнопку run debug и ide сама убъет если запущенно приложение + возможность добавить кстомные скрипты(например перемонтировать файловую систему или еще что). Задеплоит новую верси. Сама стартанет gdbserver и подключится к нему.
Я говорю когда удаленная отладка на большом арм с линуксом.
Тоесть на другом конце у нас полноценный линукс с ssh и вот хочется чтобы ide залезала туда по ssh убивала инстансы деплоила приложение и запускала там gdbserver(обычнй) и подключалась к ниму.
Смотрите, какие есть сейчас варианты:
- Локальная embedded отдалдка через gdbserver, который CLion запустит сам, через новые конфигурации
- Remote GDB режим, но gdbserver надо запускать вручную (но мы планируем научить CLion его запускать самостоятельно — задача сейчас в разработке)
- Полноценный remote режим, но это не то, что вам сейчас нужно совсем
В принципе, в этой embedded GDB server конфигурации можно немного подкрутить, чтобы работать с ней через удаленное соединение. Просто вместо локального gdbserver-а надо указать скрипт, который пойдет по ssh и запустит gdbserver на другой стороне. Elmot может помочь с деталями. Высока вероятность, что оно заработает.
Ну и надеюсь, что в 2019.3 мы таки закончим с CPP-7050, которую я упоминала раньше.
К сожалению, экспериментальный отладчик у меня не взлетел: то ли он падает вместе с отлаживаемым процессом на дефолтном «hello world», то ли просто отладка отваливается (срабатывает бряк, начинаю изучать стек, через секунду в статус-баре вижу process finished и отладка заканчивается), ну да ничего, на то он и экспериментальный.
А поддержка .gdbinit в директории проекта есть?
Пихать проектозависимые пути/параметры в корневой конфиг — это ну такое себе.
В связанном с этим случае сегодня заметил, что запуская GDB через "Attach to process" он своей рабочей директорией считает не корень проекта, а $HOME и поменять это никак нельзя из настроек. Запуск в домашней директории и локальный .gdbinit решили бы некоторое количество проблем и устранили дикий костыль в виде использования глобального конфига.
Боюсь, что без примера для воспроизведения будет очень сложно поправить. Мы сами такое не наблюдаем, а в логах ничего подозрительного нет. Но мы попробуем еще раз глянуть.
Я так понимаю, что не работает в случае дефолтового значения для cmake.parallel.generation опции. Так?
Так.
Но я ж не могу отправить вам мой проект для тестирования!
А делать некую симуляцию я тоже не могу (не хочу), мне за это не заплатят, а я вам плачу, между прочим :)
Реализовали подсказки для аргументов вызова функций
Подсказки появляются не для всего. Сходу напоролся на два кейса на картинках.
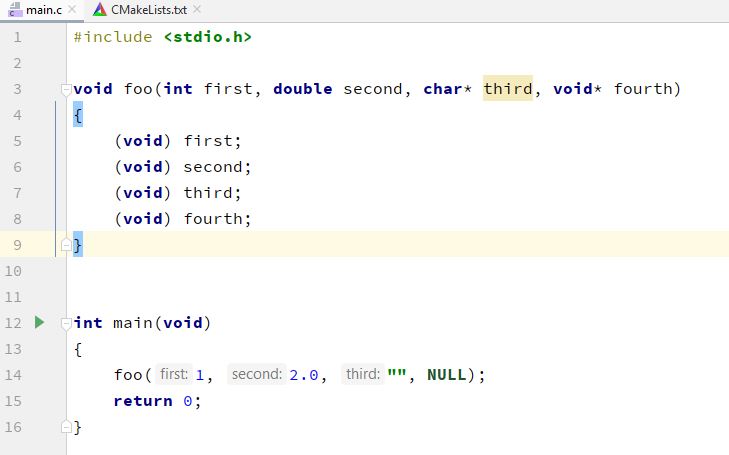
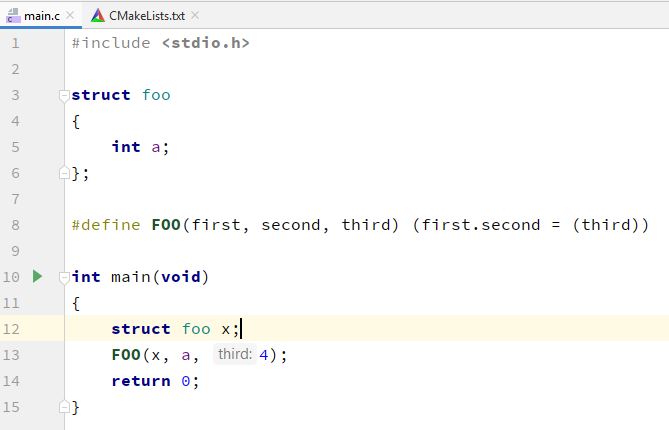
Подсказки показываются в тех случаях, когда действительно сложно понять, какие значения каким параметрам передаются, а именно, в случае использования в качестве аргументов вызова литералов или выражений более чем с одним операндом.

Имхо необходимость есть.
Я при этом соглашусь, что странно показывать хинт перед nullptr и не показывать его перед NULL. Видимо такое откинулось по эвристикам. Завела тикет на это. Поправим.
Просто в целом, если расставить parameter hints везде, будет очень много шума. Но общая рекомендация — если вам кажется, что еще где-то они могут быть полезны, то создайте запрос в трекере с описанием примерам.
NULL — это вполне себе литерал, к примеру.
Конечно, нас часто спрашивают про улучшения производительности. Я повторюсь, для нас это наиболее приоритетная задача, но точечных изменений получается сделать не много, а глобальные требуют времени больше, чем 1-2 релизных цикла.
Неужели задача отказаться от написания проекта на Java и перейти на C/C++ настолько не решаемая? В конце концов, можно даже использовать Qt. А так это будет бесконечный танец вокруг того, что изначально не рассчитывалось на производительность.
Ну смотрите, во-первых, платформе 19 лет уже и она вылизана довольно хорошо для своих задач. Писать новую платформу — это значит потратить десяток лет и возможно все равно не получить даже сравнимый набор возможностей.
Во-вторых, дело ведь не в том, что она на Java. Дело в том, что ее архитектура не была изначальна расчитана на C++, где на каждый чих нужно код именно резолвить, а не просто парсить. Ну потому что даже чтобы покрасить правильно плюсовый код надо понять перед вами тип или не тип, то есть резолв сделать контекстный. Так что Java как таковая тут не при чем.
Теперь из хорошего:
— пока что кажется, что проблемы, которые есть решаемые на текущей платформе, просто требуют времени (гораздо меньшего, чем написать все с нуля)
— второй парсер у нас кстати на C++ (на кланге), но на нем пока глобальные действия нельзя делать (просто еще в мире никто толком не научился, все экперименты пока гораздо медленнее, чем даже наш «тормозной» Java-парсер ;) )
— проблемы, на самом деле, не только в C++, в некоторых других языках тоже встречаются, так что проблемы эти решает не только CLion, а вся команда платформы
Вы правда думаете, что дело только в том, что платформа именно на Java?)Где я такое написал? О_О
платформе 19 лет уже и она вылизана довольно хорошоЭто — заблуждение номер раз. Вылизанных платформ нет. Есть первоначальные задачи, которые ставились перед архитекторами платформы. В число этих задач не входило написание GUI-приложений от слова «совсем».
Дело в том, что ее архитектура не была изначальна расчитана на C++, где на каждый чих нужно код именно резолвить, а не просто парсить.А это-то тут при чём? О_О
IDE — суть автоматизированные текстовые редакторы, кто бы какие ярлыки на них ни вешал. Для редактируемого текста не имеет значения, на каком языке они написаны. Это имеет значение лишь для разработчика и платформы, под которую пишется само ПО. Не умножайте сущности!
Ну потому что даже чтобы покрасить правильно плюсовый код надо понять перед вами тип или не тип, то есть резолв сделать контекстныйА для работы с программным кодом на других языках как будто не требуется статического анализатора?
Так что Java как таковая тут не при чем.Согласен, язык программирования ни при чём. А при чём виртуальная машина, предназначенная исполнять байт-код — результат компиляции этого самого языка, и её архитектура, которая аукается даже после Jit-компиляции.
проблемы, которые есть решаемые на текущей платформеБезусловно они есть и решаемы в рамках текущей платформы, но они не столь фундаментальны, как вопрос использования этой «платформы». Программной, прошу заметить, платформы, не аппаратной. Java создавалась для решения совершенно иных задач. Это — инструмент для разработки backend-ПО в среде WEB. Но его ошибочно использовали для разработки мобильного ПО, а дальше и на desktop переползло… Всему причина — цена отладки ПО, за которую бизнес бездумно, без каких-либо тормозов вцепился, как в «ману небесную». Теперь сам же пожинает плоды этого решения. Конечно же производители «железа» дружно промолчали — им это выгодно. Вот интересное решение для обособленных задач под названием Java превратилось в проблему.
гораздо меньшего, чем написать все с нуляСогласен, решение, лежащее в основе проекта, влечёт впоследствии к зависимости от него. Подобное утверждение корректно по отношению к любому языку программирования. Но, ведь, проблема-то не в языке. Даже в C++ есть ряд провалов по производительности относительно языка C, а у последнего — относительно Assembler-а.
второй парсер у нас кстати на C++ (на кланге)Может стоило приложиться тогда к доработке его фукционала под свои требования? Open Source же, ё-моё!
проблемы эти решает не только CLion, а вся команда платформыЧтобы ПО на Java было столь же производительным, под него нужно менять архитектуру процессоров.
IDE — суть автоматизированные текстовые редакторы, кто бы какие ярлыки на них ни вешал. Для редактируемого текста не имеет значения, на каком языке они написаны.
Я не про то, на каком, а про то, для какого. Есть разница — писать IDE для Java или для C++.
А для работы с программным кодом на других языках как будто не требуется статического анализатора?
Издалека начну. Любая IDE — это баланс между «умностью» (подсветка, форматирование, автодополнение, анализаторы, рефакторинги, и так далее) и «производительностью». В некоторых языках — этот баланс поддерживать очень легко. Пока мы создавали архитектуру платфорфмы многие годы, мы не имели планов делать IDE для C++. А потом она появилась. И выяснилось, что там, где для Java/Python/Ruby действие ничего не стоит, в C++ оно тянет за собой зачастую огромный резолв кода.
Кстати поэтому по началу даже многие фризы было поправить просто — нашел такое место, быстро извел резолв, бинго! Правда, простые места быстро закончились.
И да, можно написать подсветку кода для таких простых языков на лексере, а в C++ нельзя. Потому что есть вот такие примеры. И пробелы даже правильно в C++ не расставить без резолва, я на эту тему на C++Now в докладе с аудиторией в отличную игру играла. Там вообще в целом весь доклад именно про то, почему с C++ история оказалась в разы интереснее и сложнее. Похожие проблемы я знаю еще в Scala, например.
Так что гораздо больше, чем производительность самого языка, на котором написана IDE, важнее, для какого языка она написана.
Ну и про:
Может стоило приложиться тогда к доработке его фукционала под свои требования? Open Source же, ё-моё!
Звучит и правда заманчиво. Мы ж не зря решили в это влезть. Но вот прямо сейчас у нас, например, есть вера, но не уверенность, что оно вообще взлетит. Для действий на всем проекте (типа рефакторингов, find usages, и пр) надо в кланг напихать все те 100500 оптимизаций, отложенных резолвов и пр., которые уже заимплементированы в нашем изначальном Java-парсере. Они самому клангу нафиг не упали (это по сути же компилятор, ему такие оптимизации не нужны). Да и успех этого мероприятия пока под вопросом, хотя мы и экспериментируем. Переводим на кланг все неглобальные действия и пробуем обучить его делать глобальные действия.
Кстати, интересный факт, вот модули появились почти в языке. Они заставят всех производителей IDE фактически компилятор C++ к себе в парсер запихать. Но верите или нет, наш оптимизиронный «медленный» Java-парсер, показывает производительность по индексации лучше, чем просто взять и клангом все это добро обрабатывать так, как это кланг как компилятор делает.
Я не буду вмешиваться в дебаты про Java, это кажется не очень продуктивноНу, если делать выжимку по теме, то звучит она так: IDE для C++, ИМХО, лучше писать на языках, компилируемых в набор инструкций процессора. Ибо подсветка — ещё цветочки, а запуск программы в debug-режиме — вот это уже нагрузка серьёзная.
Кстати, уже который раз ищу, но не нахожу подобного проекта: Неужели никто не задумывался о реализации JRE из OpenJDK в виде модуля ядра?
И да, можно написать подсветку кода для таких простых языков на лексере, а в C++ нельзя. Потому что есть вот такие примеры.Ну, define подсвечивать, по моему скромному мнению, просто незачем. Впрочем, здорово, если такая функция имеется, но сам он — своего рода «костыль», без которого под час просто никуда.
надо в кланг напихать все те 100500 оптимизаций, отложенных резолвов и пр., которые уже заимплементированы в нашем изначальном Java-парсереТогда проще создать свой анализатор, чтобы органично согласовать с логикой IDE.
В компаниях из новой категории «крипто-биржи» занимаются анализом кода, написанного на совершенно разных языках, с целью автоматического построения и анализа его иерархии — собирают алгоритмы. Так что, я бы не назвал идею написания своего стат-анализатора бесперспективной.
Но верите или нет, наш оптимизиронный «медленный» Java-парсер, показывает производительность по индексации лучше, чем просто взять и клангом все это добро обрабатывать так, как это кланг как компилятор делает.Охотно верю. Сам его прикручивал в проект: тяжёлая штука. Но он не единственный противоречивый пример.
В одном проекте, написанном на C++/Qt, ядро парсера данных было лишено вкраплений Qt, а во многих местах даже на «голом СИ». Причина — жёсткие требования к производительности. Стояла задача выводить в генерируемом графическом контексте надписи с различной обработкой в качестве, не уступающем самой ОС.
Применили FreeType, т.к. он показал хорошую производительность. Однако, эта библиотека не могла определить габариты глифа символа без его полного рендеринга. Представляете, чего стоила задача предварительно оценить габариты надписи? Пришлось кэшировать эти самые габариты посимвольно коллекциями в памяти для ускорения. Нет, внутри библиотеки нашли внутренние методы оценки, но применять не стали, чтобы не включать библиотеку в проект. Тем более, что под Windows используется WinAPI. А влить в багтреккер так же не могли из-за глухой закрытости проекта.
Вышел CLion 2019.2: поддержка встроенной разработки, отладчик для MSVC, поиск неиспользованных заголовочных файлов