

В далёком 2002 году одна из самых заметных тогдашних ИТ-компаний пригласила консультантов, чтобы решить страшную проблему: служба эксплуатации не хочет использовать новые версии систем, выпущенные разработчиками. Эксплуатация и разработка регулярно вместо работы ходят на уровень вице-президентов компании и в присутствии высокого начальства пытаются друг друга переспорить.
Если проблема вам знакома и интересна, далее в статье приведён практический способ её решения, опробованный в одной из лучших мировых компаний, с теоретическим обоснованием, примерами расчётов и рекомендациями по автоматизации.
Конфликт
Не бывает конфликтов между администратором ПО и производителем этого ПО, если производитель это гигантская международная мега-корпорация, а администратор работает в компании, которая это ПО купила и использует. Каждый занимается своим делом: производитель выпускает новые версии, администратор следит, чтобы «всё работало». Решение, какую версию эксплуатировать, принимает администратор. Некоторые проверяют новые версии. Некоторые новые версии не используют вообще. Когда средства доставки обновлений были развиты слабее, чем теперь, был известен принцип не использовать новую версию ОС, пока к ней не выйдет второй сервис-пак. Администраторы прекрасно знают принцип, положенный в основу процесса управления изменениями: «Любое изменение опасно». Производителю же всё равно, используют новую версию ПО или старую, лишь бы деньги за поддержку платили.
Всё меняется, если администратор и производитель ПО оказываются сотрудниками одной компании. Теперь стремление администратора к стабильности и стремление производителя выполнять планы реализации пожеланий пользователей — это стремления в противоположные стороны. Бывает, что в КПЭ администратора записана стабильность, а в КПЭ разработчика — количество новых функций. Тогда каждый час простоя из-за (или для?) внедрения новых функций это потеря премии администратором, а каждый отказ от установки новой версии ради сохранения стабильности это потеря премии разработчиком.

Поскольку проблема не новая, и разработчики, и эксплуатация сформулировали подходы к её решению.
В нынешней версии ITIL в томе Service Operation этому конфликту посвящен раздел 3.2.2, Stability versus responsiveness («Стабильность против отзывчивости»). Авторы ITIL пишут, что организации обычно не могут найти баланса между стабильностью и отзывчивостью и склоняются к одной из крайностей, принося второе в жертву. Там же даются рекомендации, как этой стабильности достичь:
- Использовать более гибкие технологии, например, виртуальные серверы вместо железных.
- Создать влиятельный процесс управления уровнем сервисов, который был бы вовлечён во все фазы жизненного цикла сервисов, от проектирования до непрерывного улучшения.
- Усилить взаимодействие процесса управления уровнем сервисов с другими процессами фазы дизайна: управлением доступностью, мощностью, непрерывностью.
- Построить процесс управления изменениями так, чтобы он начинался на более ранних фазах жизненного цикла сервиса.
- Добиться вовлечения ИТ-подразделения в процесс управления изменениями бизнеса.
- На фазе проектирования сервисов использовать информацию от процессов фазы эксплуатации.
- Документировать договорённости между ИТ бизнесом, не допускать неформальных соглашений.
ITIL написан для администраторов, а для разработчиков ПО создан DevOps, который даёт следующие рекомендации по решению того же самого конфликта:
- Унифицировать и заставить сильно взаимодействовать процессы разработки и эксплуатации ПО.
- Автоматически выполнять (роботизировать?) операции интеграции, тестирования, выпуска и развёртывания новых версий ПО.
- Встраивать в разрабатываемое ПО средства мониторинга.
Оба источника дают дельные советы, которые не только не противоречат, но порой идеально друг друга дополняют, как последний пункт из второго списка и шестой пункт из первого. Однако, советам недостаёт конкретности. Например, про DevOps непонятно, что этот термин значит и какой смысл за ним стоит: «С момента появления в 2008 году значение термина DevOps так и не устоялось. Поэтому, чтобы ни с кем не спорить, мы называем наш подход к управлению сервисами Site Reliability Engineering (SRE). Принципы SRE не противоречат DevOps.» Так пишут в выпущенной в 2016 году книге сотрудники одной крупной компании, известной своим сервисом поиска в интернете, а теперь ещё и беспилотными автомобилями.
Заметим, что в книге про SRE один за другим рассматриваются, в ключе «а вот как это сделано у нас», процессы из ITIL: управление инцидентами, проблемами, изменениями, уровнем сервисов и др., хотя сама библиотека не упомянута ни разу за все 550 страниц («Сервис» на первых 10 страницах книги упомянут 50 раз, а «менеджмент» — 20).
Что такое «4 девятки» доступности
На минуту отвлечёмся, так как практика показывает, что и представители бизнеса, и представители ИТ с трудом понимают, что такое «доступность %». Обычно понимание упрощается, если от процентов перейти к часам и минутам. Вот как выглядят цифры для некоторых требуемых уровней доступности для режима работы сервиса 9×5. Расчётный период — 1 месяц, в нём 189 рабочих часов.
| Требуемая доступность | Сервис обязан работать | Сервис может простаивать |
|---|---|---|
| 90,00 % | 170 ч 06 мин | 18 ч 54 мин |
| 95,00 % | 179 ч 33 мин | 9 ч 27 мин |
| 99,99 % | 188 ч 48 мин | 11 мин |
Бюджет простоев
Одна из простейших, мощнейших и действенных идей SRE — «бюджет простоев». Исходя из требований заказчика к доступности сервиса, вычисляется допустимое время простоя системы за период, «бюджет простоев». Из этого бюджета берётся время и на устранение инцидентов, и на проведение изменений. В том числе на проведение изменений по внедрению новых функций. Если система работает стабильно, то на проведение изменений и, если потребуется, на устранение последствий этих изменений время есть. Если система работает нестабильно, то бюджет простоев «съедают» инциденты, и времени на проведение изменений в отчётном периоде остаётся мало или не остаётся совсем.
Никто (кроме системы мониторинга) не заметит разницу между доступностью ровно 100 % и доступностью почти 100 %, да и чем ближе доступность сервиса к 100 %, тем он сложнее и дороже. Поэтому можно рассчитывать, что требования заказчика к доступности всегда будут ниже, чем ровно 100 %, а значит, и бюджет простоев будет всегда.
Бюджет простоев автоматически регулирует выпуск новых релизов: пока он не исчерпан, релизы возможны. Для организаций, работающих в режиме push on green (если релиз прошёл все тесты, он выпускается в производственную среду автоматически), процесс может автоматизирован полностью.
Быстрое исчерпание бюджета простоев подсказывает ИТ-руководителям, что нужно больше ресурсов направить на тестирование или проектирование сервиса.
Бюджет простоев ставит для разработки и эксплуатации единые цели и единые КПЭ, решая таким образом конфликт, о котором написана эта статья.
Примеры
При жёстких требованиях к доступности времени на установку новых версий и на борьбу с последствиями почти нет. Например, если установлен режим
24×7, доступность 99,99 % в месяц
то бюджет простоев составляет 43 минуты 12 секунд в месяц. Скорее всего, в течение месяца получится установить только одну-две новые версии программы. Любой инцидент, даже решаемый без раздумий, перезагрузкой, моментально «съест» примерно 20 % бюджета, поэтому, если от сервиса требуется высокий уровень доступности, то ИТ-служба обязана обеспечить высокий уровень тестирования.
Ситуация упрощается, если SLA допускает регламентный простой, то есть если какое-то количество часов зарезервировано именно для установок патчей и новых версий, и простой сервиса в это время не влияет на расчёт доступности. Время проведения регламентного простоя заранее определено, и любые остановки сервиса за его пределами рассматриваются, как инциденты. Крайний случай регламентного простоя это режим 9×5, когда работа сервиса не требуется, скажем, с 18:00 до 9:00 следующего дня, и у ИТ-службы есть 15 часов в сутки на установку новых версий.
Что происходит с бюджетом доступности, если ночью сервис не работает? Из-за того, что количество часов работы сервиса сокращается с 720 часов в месяц при круглосуточном режиме работы до 189 часов при режиме 9×5, бюджет простоев заметно сокращается. На установку новых версий теперь есть целая ночь, но сколько есть времени на борьбу с проблемами, которые новая версия может принести? Для режима
9×5, доступность 99,99 % в месяц
бюджет простоев сокращается до 11 минут 20 секунд. Это, по-большому счёту, один инцидент в месяц.
Снижение требований к доступности увеличивает бюджет простоев, давая ИТ-службе больше времени на проведение изменений и на устранение инцидентов. Так, при популярной в российских SLA требуемой доступности в 97,5 % бюджет простоев составит комфортные 18 часов в месяц для режима 24×7 и чуть меньше 5 часов в месяц для режима 9×5.
Каков бы ни был размер бюджета простоев, и разработчики, и эксплуатация должны понимать, что это их общий бюджет.
Реализации в информационной системе
Для реализации бюджета простоев нужны система мониторинга и ИТСМ-система. Рассмотрим, что предлагает ИТСМ-система ServiceNow в «коробочной» конфигурации для решения такой задачи. На сегодняшний день ServiceNow занимает лидирующие позиции в сфере ITSM-решений и именно его мы предлагаем своим клиентам в собственной облачной платформе Техносерв Cloud.
1.Зафиксируем согласованный с бизнесом требуемый уровень доступности сервиса.
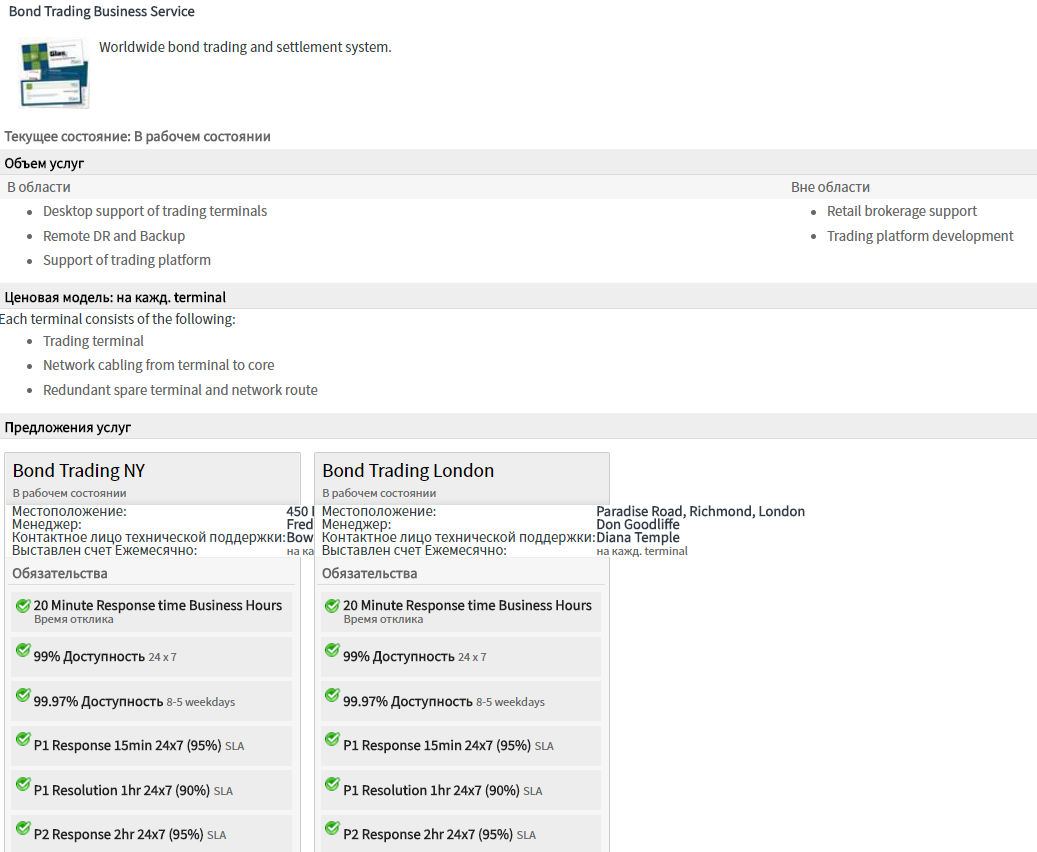
2.Будем записывать перебои в работе сервиса (outages, периоды недоступности), как вызванные сбоями, так и запланированные остановки сервиса для установки новых версий и патчей. Конечно, лучше, если перебои-инциденты будет записывать интегрированная с ServiceNow система мониторинга.

3.Когда разработчики подготовят новый релиз к установке в производственную среду, посмотрите, сколько осталось времени в бюджете простоев. На картинке бюджет потрачен всего лишь на 20 %, ответственный за сервис в такой ситуации разрешит установку нового релиза.

Подведём итоги:
Бюджет простоев решает конфликт между эксплуатацией и разработкой.
Размер бюджета простоев, и следовательно, степень свободы ИТ-организации в проведении изменений, определяется в первую очередь требованиями к доступности сервиса, а регламентный простой на него не влияет.
- Бюджет простоев легко реализовать в ИТСМ-системе ServiceNow даже в коробочной конфигурации.
Упомянутые в первом абзаце службы разработки и эксплуатации породили ещё один масштабный конфликт и с энтузиазмом в нём участвовали, но об этом — в одной из следующих статей.

{kind=link}
{kind=link}