
В последнее время фишинг является наиболее простым и популярным у киберпреступников способом кражи денег или информации. За примерами далеко ходить не нужно. В прошлом году ведущие российские предприятия столкнулись с беспрецедентной по масштабу атакой — злоумышленники массово регистрировали фейковые ресурсы, точные копии сайтов производителей удобрений и нефтехимии, чтобы заключать контракты от их имени. Средний ущерб от такой атаки — от 1,5 млн рублей, не говоря уже про репутационный ущерб, который понесли компании. В этой статье мы поговорим о том, как эффективно детектировать фишинговые сайты с помощью анализа ресурсов (изображений CSS, JS и т.д.), а не HTML, и как специалист по Data Science может решить эти задачи.
Павел Слипенчук, архитектор систем машинного обучения, Group-IB
Эпидемия фишинга
По данным Group-IB, ежедневно жертвами только финансового фишинга в России становятся свыше 900 клиентов различных банков, — этот показатель в 3 раза превышает ежедневное количество жертв от вредоносных программ. Ущерб от одной фишинговой атаки на пользователя варьируется от 2000 до 50 000 рублей. Мошенники не просто копируют сайт компании или банка, их логотипы и фирменные цвета, контент, контактные данные, регистрируют похожее доменное имя, они еще активно рекламируют свои ресурсы в соцсетях и поисковиках. Например, пытаются вывести в топы выдачи ссылки на свои фишинговые сайты по запросу «Перевод денег на карту». Чаще всего поддельные сайты создаются именно для того, чтобы украсть деньги при переводе с карты на карту или при мгновенной оплате услуг операторов сотовой связи.
Фишинг (англ. phishing, от fishing — рыбная ловля, выуживание) — вид интернет-мошенничества, цель которого — обманным путем вынудить жертву предоставить мошеннику нужную ему конфиденциальную информацию. Чаще всего похищают пароли доступа к банковскому счету для дальнейшей кражи денег, аккаунты в социальных сетях (для вымогательства денег или рассылки спама от лица жертвы), подписывают на платные услуги, рассылки или заражают компьютер, делая его звеном в бот-сети.По способам атак следует различать 2 вида фишинга, ориентированные на пользователей и компании:
- Фишинговые сайты, копирующие оригинальный ресурс жертвы (банки, авиакомпании, интернет-магазины, предприятия, госучреждения и т.д.).
- Фишинговые рассылки, e-mail, sms, сообщения в соцсетях и т.д.
Атакой на пользователей часто занимаются одиночки, и порог входа в этот сегмент преступного бизнеса такой низкий, что для реализации хватит минимальных «инвестиций» и базовых знаний. Распространению данного типа мошенничества способствуют и phishing kits — программы-конструкторы фишинговых сайтов, которые можно свободно купить в Даркнете на хакерских форумах.
Атаки на компании или банки устроены иначе. Их проводят технически более подкованные злоумышленники. Как правило, в качестве жертв выбирают крупные промышленные предприятия, онлайн-магазины, авиакомпании, а чаще всего банки. В большинстве случаев фишинг сводится к отправке письма с прикрепленным зараженным файлом. Чтобы подобная атака была успешной, в «штате» группировки необходимо иметь и специалистов по написанию вредоносного кода, и программистов для автоматизации своей деятельности, и людей, способных провести первичную разведку по жертве и найти у нее слабые места.
В России, по нашим оценкам, действует 15 преступных групп, занимающихся фишингом, направленным на финансовые учреждения. Суммы ущерба всегда небольшие (в десятки раз меньше, чем от банковских троянов), но количество жертв, которые они заманивают на свои сайты, ежедневно исчисляется тысячами. Около 10–15% посетителей финансовых фишинговых сайтов сами вводят свои данные.
При появлении фишинговой страницы счет идет на часы, а иногда даже на минуты, поскольку пользователи несут серьезный финансовый, а в случае компаний — еще и репутационный ущерб. Например, некоторые успешные фишинговые страницы были доступны менее суток, но смогли нанести ущерб на суммы от 1 000 000 рублей.
В этой статье мы подробно остановимся на первом типе фишинга: фишинговых сайтах. Ресурсы, «подозреваемые» в фишинге, можно легко детектировать с помощью различных технических средств: honeypots, краулеров и т.д., однако убедиться в том, что они действительно фишинговые, и определить атакуемый бренд проблематично. Разберем, как решить эту задачу.
Ловля фишей
Если бренд не следит за своей репутацией, он становится легкой мишенью. Необходимо перехватывать инициативу у преступников сразу после регистрации их фальшивых сайтов. На практике поиск фишинговой страницы делится на 4 этапа:
- Формирование множества подозрительных адресов (URL) для проверки фишинга (краулер, honeypots и т.д.).
- Формирование множества фишинговых адресов.
- Классификация уже задетектированных фишинговых адресов по направлению деятельности и атакуемой технологии, например «ДБО:: Сбербанк Онлайн» или «ДБО:: Альфа-Банк».
- Поиск страницы-донора.
Выполнение пунктов 2 и 3 ложится на плечи специалистов по Data Science.
После этого уже можно предпринимать активные действия для блокировки фишинговой страницы. В частности:
- вносить URL в черные списки продуктов Group-IB и продуктов наших партнеров;
- автоматически или вручную отправлять письма владельцу доменной зоны с просьбой удалить фишинговый URL;
- отправлять письма службе безопасности атакуемого бренда;
- и т.д.

Методы, основанные на анализе HTML
Классическим решением задач по проверке подозрительных адресов на фишинг и автоматическое определение пострадавшего бренда являются различные способы разбора HTML исходных страниц. Самое простое — это написание регулярных выражений. Забавно, но этот прием до сих пор работает. И поныне большинство начинающих фишеров просто копируют контент с сайта оригинала.
Также весьма эффективные системы для антифишинга могут разрабатывать исследователи phishing kits. Но и в данном случае нужно исследовать HTML-страницу. Кроме того, эти решения не универсальные — для их разработки необходима база самих «китов». Некоторые phishing kits могут быть неизвестны исследователю. И, разумеется, разбор каждого нового «кита» — это достаточно трудоемкий и дорогой процесс.
Все системы обнаружения фишинга, основанные на анализе HTML-страницы, перестают работать после обфускации HTML. Причем во многих случаях достаточно просто поменять каркас HTML-страницы.
По данным Group-IB, в настоящий момент таких фишинговых сайтов не более 10% от общего количества, однако пропуск даже одного может дорого обойтись жертве.
Таким образом, фишеру для обхода блокировки достаточно просто менять каркас HTML, реже — обфусцировать HTML-страницу (запутывая разметку и/или подгружая контент через JS).
Постановка задачи. Метод, основанный на ресурсах
Гораздо более эффективны и универсальны для обнаружения фишинговых страниц методы, основанные на анализе используемых ресурсов. Ресурс — это любой файл, подгружаемый при рендеринге web-страницы (все изображения, каскадные таблицы стилей (CSS), JS-файлы, шрифты и т.д.).
В этом случае можно построить двудольный граф, где одни вершины будут адресами, подозрительными на фишинг, а другие — ресурсами, связанными с ними.
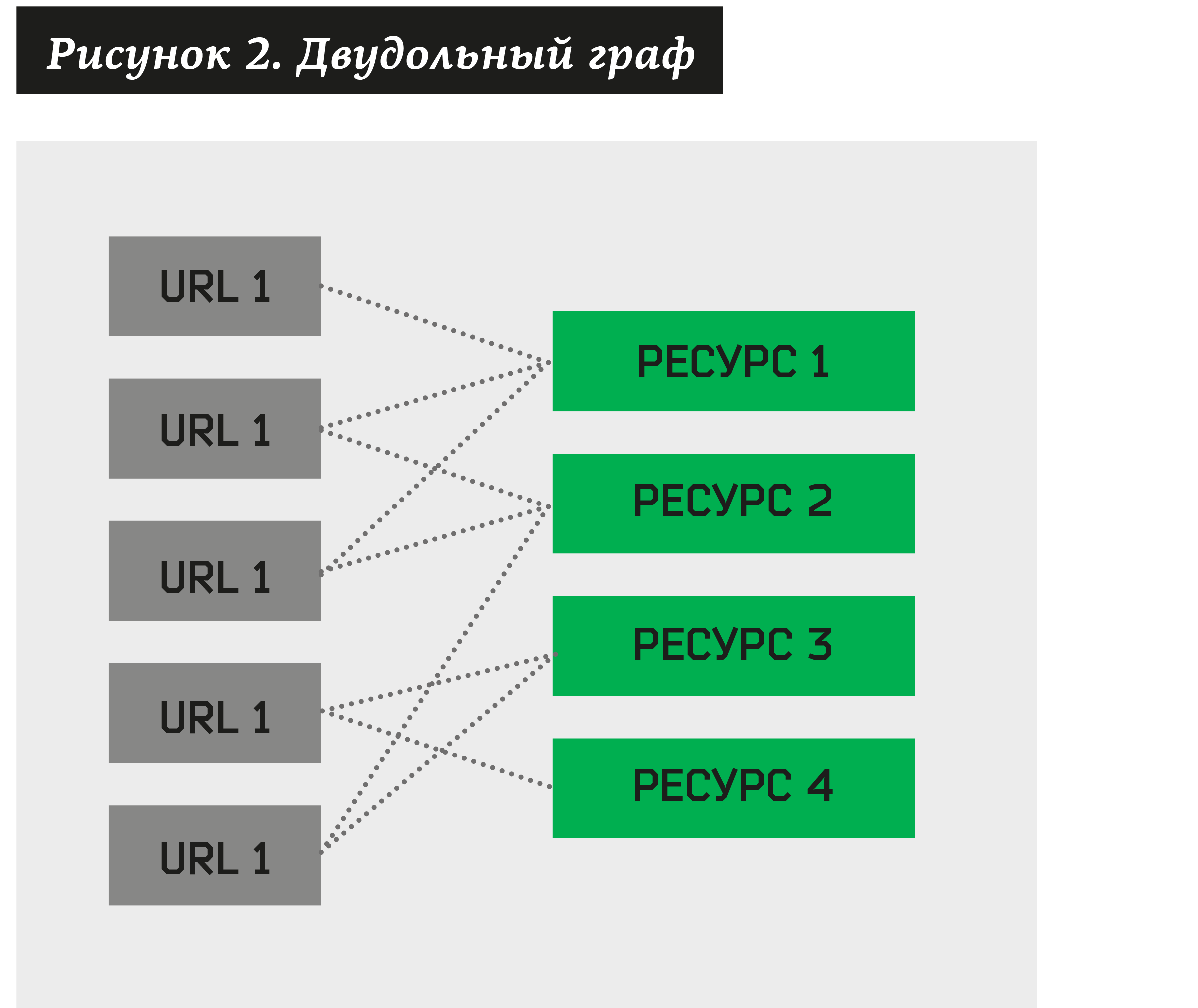
Возникает задача кластеризации — найти совокупность таких ресурсов, которым принадлежат достаточно большое количество различных URL. Построив такой алгоритм, мы сможем разложить на кластеры любой двудольный граф.
Гипотеза заключается в том, что, основываясь на реальных данных, с достаточно большой долей вероятности можно сказать, что кластер содержит совокупность URL, которые принадлежат одному бренду и генерируются одним phishing kits. Тогда для проверки данной гипотезы каждый такой кластер можно отправить на ручную проверку в CERT (Центр реагирования на инциденты информационной безопасности). Аналитик в свою очередь проставлял бы статус кластеру: +1 («утвержденный») или –1 (отвергнутый»). Всем утвержденным кластерам аналитик также присваивал бы атакуемый бренд. На этом «ручная работа» заканчивается — остальной процесс автоматизирован. В среднем на одну утвержденную группу приходится 152 фишинговых адреса (данные на июнь 2018 г.), а иногда даже попадаются кластеры по 500–1000 адресов! Аналитик тратит около 1 минуты на утверждение или опровержение кластера.
Далее все отвергнутые кластеры удаляют из системы, а все их адреса и ресурсы через некоторое время вновь подают на вход алгоритма кластеризации. В итоге мы получаем новые кластеры. И опять отправляем их на проверку, и т.д.
Таким образом, для каждого вновь поступившего адреса система должна делать следующее:
- Извлекать множество всех ресурсов для сайта.
- Проверять на принадлежность хотя бы одному ранее утвержденному кластеру.
- Если URL принадлежит какому-либо кластеру, автоматически извлечь название бренда и выполнить действие для него (уведомить заказчика, удалить ресурс и т.д.).
- Если по ресурсам нельзя проставить ни один кластер, добавить адрес и ресурсы в двудольный граф. В дальнейшем данный URL и ресурсы будут участвовать в образовании новых кластеров.
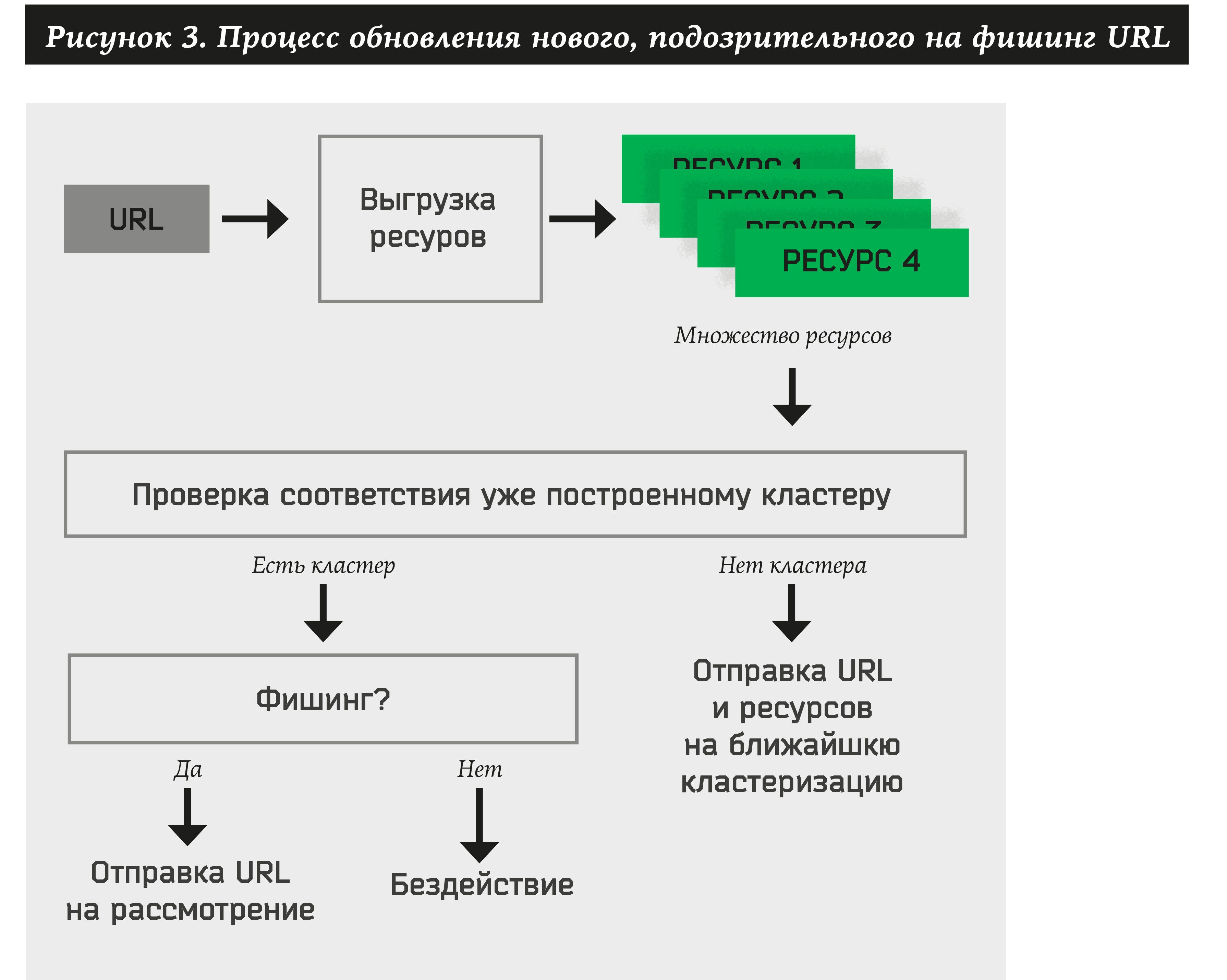
Простой алгоритм кластеризации по ресурсам
Один из важнейших нюансов, который должен учитывать специалист Data Science в ИБ, — тот факт, что его противником является человек. По этой причине условия и данные для анализа очень быстро меняются! Решение, замечательно устраняющее проблему сейчас, через 2–3 месяца может перестать работать в принципе. Поэтому важно создавать либо универсальные (топорные) механизмы, если это возможно, либо максимально гибкие системы, которые можно быстро доработать. Специалист по Data Science в ИБ не сможет решить задачу раз и навсегда.
Стандартные методы кластеризации не работают из-за большого количества признаков. Каждый ресурс можно представить как булевый признак. Однако на практике мы получаем от 5000 адресов сайтов ежедневно, и каждый из них в среднем содержит 17,2 ресурса (данные на июнь 2018 г.). Проклятье размерности не позволяет даже загрузить данные в память, не то что построить какие-то алгоритмы кластеризации.
Другая идея — попытаться разбить на кластеры с помощью различных алгоритмов коллаборативной фильтрации. В данном случае нужно было создать еще один признак — принадлежность к тому или иному бренду. Задача будет сводиться к тому, что система должна спрогнозировать наличие или отсутствие этого признака для остальных URL. Метод дал положительные результаты, однако обладал двумя недостатками:
- для каждого бренда нужно было создавать свой признак для коллаборативной фильтрации;
- нужна была обучающая выборка.
В последнее время все больше компаний хотят защитить свой бренд в интернете и просят автоматизировать детектирование фишинговых сайтов. Каждый новый бренд, взятый под защиту, добавлял бы новый признак. Да и создавать обучающую выборку для каждого нового бренда — это дополнительный ручной труд и время.
Мы начали искать решение этой задачи. И нашли очень простой и эффективный способ.
Для начала построим пары ресурсов по следующему алгоритму:
- Возьмем всевозможные ресурсы (обозначим их как а), для которых не менее N1 адресов, обозначим данное отношение как #(a) ≥ N1.
- Построим всевозможные пары ресурсов (a1, a2) и выберем только те, для которых будет не менее N2 адресов, т.е. #(a1, a2) ≥ N2.
Затем мы аналогичным образом рассматриваем пары, состоящие из пар, полученных в предыдущем пункте. В итоге получаем четверки: (a1, a2) + (a3, a4) → (a1, a2, a3, a4). При этом, если хотя бы один элемент присутствует в одной из пар, вместо четверок мы получаем тройки: (a1, a2) + (a2, a3) → (a1, a2, a3). Из полученного множества оставим только те четверки и тройки, которым соответствует не менее N3 адресов. И так далее…
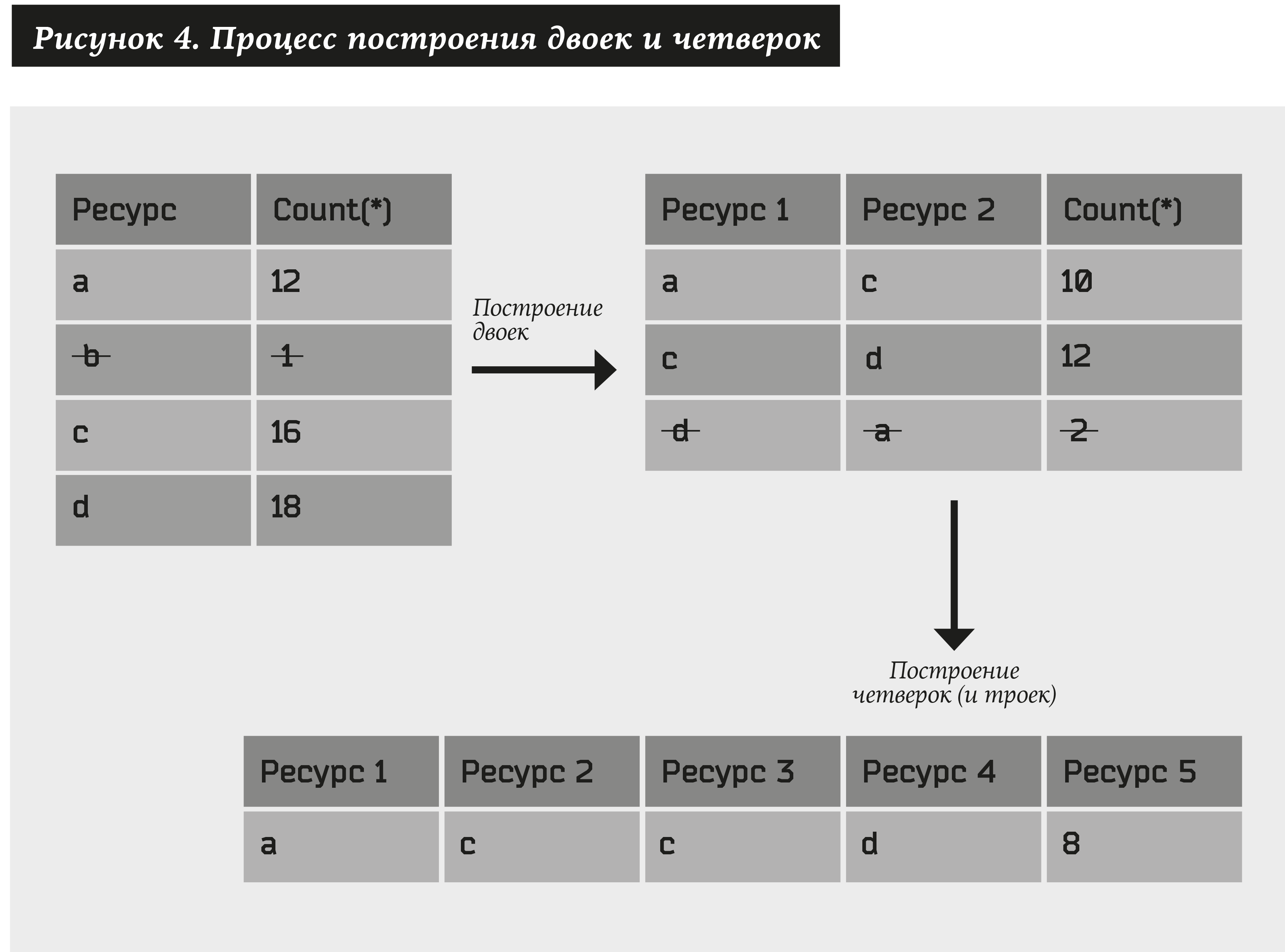
Можно получать множества ресурсов произвольной длины. Ограничим количество шагов до U. Тогда N1, N2… NU — это параметры системы.
Величины N1, N2… NU — параметры алгоритма, они задаются вручную. В общем случае мы имеем CL2 различных пар, где L — количество ресурсов, т.е. сложность для построения пар будет O(L2). Затем из каждой пары создается четверка. И в теории мы, возможно, получим O(L4). Однако на практике таких пар значительно меньше, и при большом количестве адресов эмпирически была получена зависимость O(L2log L). При этом последующие шаги (превращения двоек в четверки, четверок в восьмерки и т.д.) пренебрежимо малы.
Следует заметить, что L — это количество некластеризированных URL. Все URL, которые уже можно отнести к какому-либо ранее утвержденному кластеру, не попадают в выборку для кластеризации.
На выходе можно создать множество кластеров, состоящих из максимально больших по размерам множеств ресурсов. Например, если существует (a1, a2, a3, a4, a5), удовлетворяющая границам Ni, следует убрать из множества кластеров (a1, a2, a3) и (a4, a5).
Затем каждый полученный кластер отправляется на ручную проверку, где аналитик CERT присваивает ему статус: +1 («утвержден») или –1 («отвергнут»), а также указывает, какими являются URL, попадающие в кластер, — фишинговыми или легитимными сайтами.
При добавлении нового ресурса количество URL может уменьшиться, остаться тем же, но никогда не увеличиться. Поэтому для любых ресурсов a1… aN справедливо отношение:
#(a1) ≥ #(a1, a2) ≥ #(a1, a2, a3) ≥ … ≥ #(a1, a2, …, aN).
Следовательно, разумно задавать параметры:
N1 ≥ N2 ≥ N3 ≥ … ≥ NU.
На выходе мы выдаем всевозможные группы для проверки. На рис. 1 в самом начале статьи приведены реальные кластеры, для которых все ресурсы — изображения.
Использование алгоритма на практике
Заметим, что теперь полностью отпадает необходимость исследовать phishing kits! Система автоматически кластеризует и найдет нужную фишинговую страницу.
Ежедневно система получает от 5000 фишинговых страниц и конструирует всего от 3 до 25 новых кластеров в сутки. Для каждого кластера выгружается список ресурсов, создается множество скринов. Данный кластер отправляется аналитику CERT на подтверждение или опровержение.
При запуске точность алгоритма была невысокой — всего 5%. Однако уже через 3 месяца система держала точность от 50 до 85%. В действительности точность не имеет значения! Главное, чтобы аналитики успевали просмотреть кластеры. Поэтому, если система, например, генерирует около 10 000 кластеров в сутки и у вас только один аналитик, придется менять параметры системы. Если не более 200 в сутки, это задача, посильная для одного человека. Как показывает практика, на визуальный анализ в среднем требуется около 1 минуты.
Полнота системы — около 82%. Оставшиеся 18% — это либо уникальные случаи фишинга (поэтому их нельзя сгруппировать), либо фишинг, у которого малое количество ресурсов (не по чему группировать), либо фишинговые страницы, которые вышли за границы параметров N1, N2… NU.
Важный момент: как часто запускать новую кластеризацию на свежих, непроставленных URL? Мы делаем это каждые 15 минут. При этом в зависимости от количества данных само время кластеризации занимает 10–15 минут. Это значит, что после появления фишингового URL есть лаг во времени в 30 минут.
Ниже приведены 2 скриншота из GUI-системы: сигнатуры для обнаружения фишинга соцсети «ВКонтакте» и «Bank Of America».
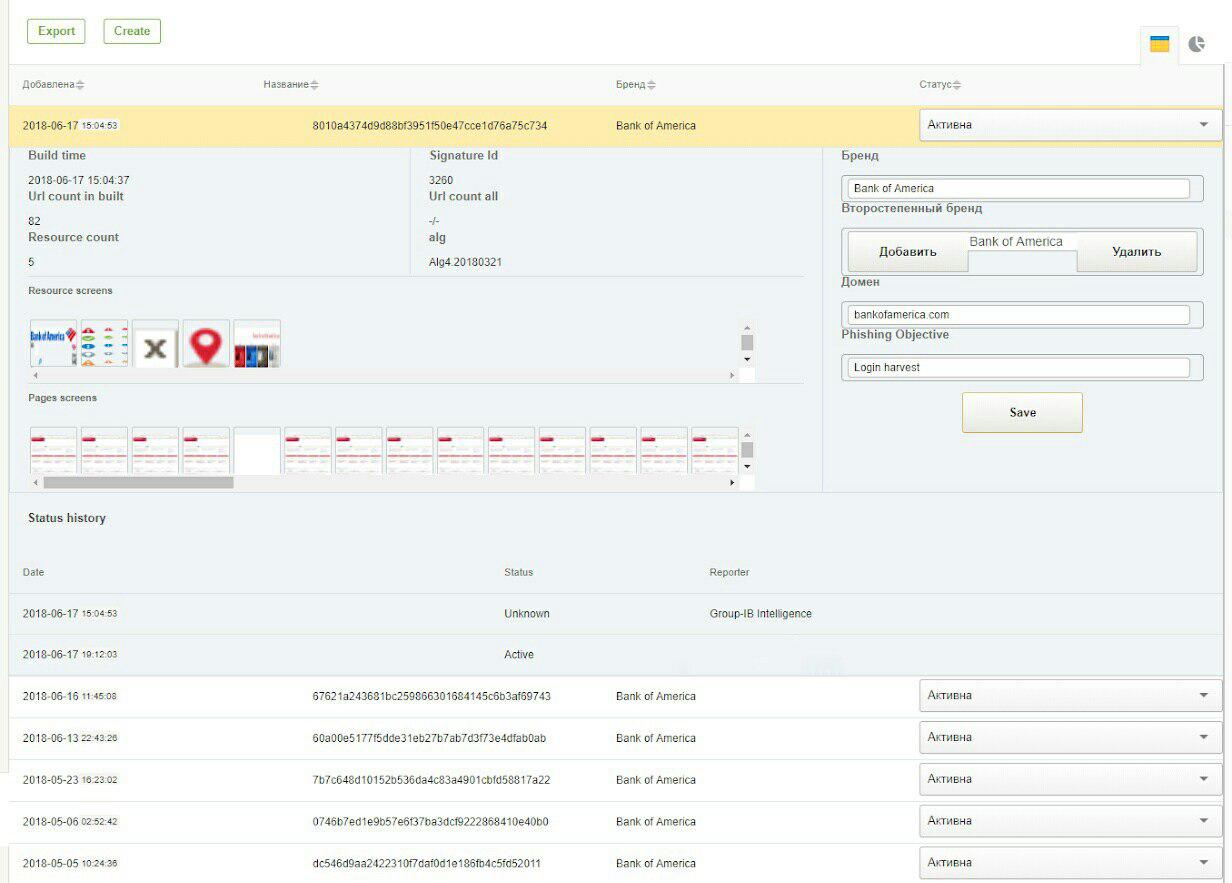
Когда алгоритм не работает
Как уже было сказано выше, алгоритм не работает в принципе, если не достигаются границы, заданные параметрами N1, N2, N3… NU, или если количество ресурсов слишком мало, чтобы образовать необходимый кластер.
Фишер может обойти алгоритм, создавая для каждого фишингового сайта уникальные ресурсы. Например, в каждом изображении можно поменять один пиксель, а для подгружаемых JS- и CSS-библиотек использовать обфускацию. В данном случае необходимо разработать алгоритм сравнимого хеша (перцептивного хеша) для каждого типа подгружаемых документов. Однако данные вопросы выходят за рамки этой статьи.
Соединяем все вместе
Соединяем наш модуль с классическими HTML-регулярками, данными, полученными от Threat Intelligence (система киберразведки), и получаем полноту в 99,4%. Разумеется, это полнота на данных, которые уже предварительно классифицированы Threat Intelligence как подозрительные на фишинг.
Какова полнота на всех возможных данных, не знает никто, так как охватить весь Даркнет невозможно в принципе, однако, согласно отчетам Gartner, IDC и Forrester, по своим возможностям Group-IB входит в число ведущих международных поставщиков Threat Intelligence-решений.
А что делать с непроклассифицированными фишинговыми страницами? В день их получается примерно 25–50. Их вполне можно проверить ручным способом. В целом в любой достаточно сложной для Data Sciense задаче в сфере ИБ всегда есть ручной труд, а любые утверждения о 100-процентной автоматизации — это маркетинговый вымысел. Задача специалиста Data Sciense уменьшить ручной труд на 2–3 порядка, сделав работу аналитика максимально эффективной.
Статья опубликована на JETINFO
