Комментарии 167
Я не адвокат микросервисов, но как-то большинство проблем описанных связаны с низким качеством разработки:
- Версионность API. Да проблемы переходного периода довольно сложны. Но нужно учитывать несколько правил. Во-первых, в системе не может быть больше одной версии запущенного софта на постоянной основе (две версии только в момент обновления/черрипиков). Во-вторых, если в API добавилась новая функция, то сначала полностью обновляется сервис предоставляющий API и только потом обновляются клиенты. В-третьих, разумеется обратная совместимость и тестирование регрессий.
- Statefull проблемы в соответствующей литературе описаны. Да, они тоже сложны. Но пример написанный в статье мне просто не понятен. Что значит "новая версия сервиса подписки хранит данные в БД нового вида"? Если там на столько разрушительное изменение, то только полная остановка, как и в монолите.
Микросервисы во многом больше относятся к техническим процессам, связанным с упаковыванием и эксплуатацией, чем к самой архитектуре системы. Уместные границы для компонентов остаются одной из главных сложностей в инженерных системах.
Самая большая беда микросервисов в том, что они требует правильной организации труда, а это не всем компаниям дано. Грубо говоря, заставить хипстеров внимательно относится к проектированию и версионности очень сложно, а хороших инженеров на рынке мало.
Грубо говоря, заставить хипстеров внимательно относится к проектированию и версионности очень сложно, а хороших инженеров на рынке мало.
Вот сам этого не умел, однако как усилилась разработка вплотную с драйверами под браузеры и платформа (Automated System for Tests) приобрела свой первый «сервер инстансов» на базе Jersey glassfish, так очень быстро усвоил уроки жизни.
Тут же не вопрос "не умел", а в том, что многие "не хотят".
Хочется или нет учиться самоорганизации (и организации процессов, соответственно), приучать себя к максимальной унификации и стандартизации, описанию/документированию — тут как бы без разницы, ибо… кушать хочется всегда, а без повышения культуры разработки, в критических областях выгоняют.
P.S. Изначально, когда только все стартовало, AST не несла такой важной роли — сейчас ответственность и критичность резко возросла. И сложность софта так же стала совсем иной.
кушать хочется всегда
Эх, если бы мне в "начале пути" дали совет: "первое что ты должен сделать — обеспечить себе автономность (сделать автоматически возобновляемым ресурсом: еду, энергию, ...), а затем можешь заниматься
И, причем это не противоречит "учиться самоорганизации" — свое дело всегда делаешь качественно. Иначе зачем его делать?
большинство проблем описанных связаны с низким качеством разработки
Я думаю, это в целом подходит всей IT сфере)
Statefull проблемы в соответствующей литературе описаны.
А можете порекомендовать что почитать для перехода на SOA?
Эм. Ну вообще-то микросервисы != SOA. SOA более общая концепция. Это очень важно понять. И книг именно по SOA я не читал, а вот если нужно введение в микросервисы, то хорошая книга есть у O'Reilly: Building Microservice автор Sam Numan. Издательство Питер делало перевод. Там не обсуждаются частности, а скорее модели взаимодействия. Много обсуждают как разорвать связи в монолитной базе и надо ли это делать вообще.
У меня прямо противоположный опыт. Запустить монолит такая сложная история что виртуалка, передаваемая от одного поколения другому, ценится как артефакт из фентези.
В то время как микросервисы с docker-compose и четко очерченным avro-схемами API разворачиваются довольно просто. А т.к. микросервисы взаимодействуют между собой только через кафку (есть особые исключения, но это другая история) — то запускать их можно последовательно (по пути на графе) по одному.
А т.к. микросервисы взаимодействуют между собой только через кафку
А подробнее об опыте работы через кафку можете рассказать? Как устойчивость, какие подводные камни?
Если коротко:
0) По производительности и надежности наши потребности перекрываются многократно.
1) Кафка передает байтики, схему нужно делать самостоятельно. Мы делаем вот так — habrahabr.ru/post/346698
2) Кафка pub-sub, и вопросы повторов нужно решать с особой щепетильностью.
Если есть цепочка на графе процесса вида: A->B и A->C и в С произошёл сбой, тогда нельзя так просто повторить сообщение из А, т.к. его поймают и B и С.
Вариантов борьбы — масса, начиная с проверкой уникальности и заканчивая внутр. очередями.
Мы сейчас выбрали такую стратегию — обработка очереди приостанавливается до решения проблемы. Но это потребовало ввести классификацию ошибок на требующие остановки и не требующие.
3) Кафка отдельно хранит поток данных и отдельно — позицию читателя на этом потоке. Так же у читателя есть стратегия чтения в случае, если он не знает откуда читать. Он может начать с новых данных (конец потока), а может со старых (начало).
Мы как то увеличили время жизни данных до недели, а время жизни информации о позиции — нет, при этом несколько разрабатываемых читателей были настроены на чтение с начала. В результате переукладки в докер\номад они **заново** обработали недельный массив данных.
4) У нас получился граф с циклами, в узлах которого сервисы, а ребра — кафочные топики.
Чтобы как то восстановить путь сообщения я при прохождении каждого узла дописываю в сообщениях метаинформацию о локальном времени прохода и uuid процесса в данном узле. В результате на конечном узле можно понять в результате каких процессов это сообщение вообще сюда пришло, и как долго оно шло.
Я думал про это отдельно написать в Хабр.
Это было бы неплохо. По Кафке вообще мало хороших историй, не синтетических.
Кафка pub-sub, и вопросы повторов нужно решать с особой щепетильностью.
Во-во. Именно такие проблемы и вызывают интерес. А то многие воспринимают такие вещи как магические коробки, которые все, всегда делают правильно.
Запустить монолит такая сложная история что виртуалка, передаваемая от одного поколения другому, ценится как артефакт из фентези.
Да, бывает такое. Но эта проблема обычно связана не с монолитами, а со сторонним ПО. Если разбить подобный монолит на микросервисы — то наверняка появится 2-3 "артефакта", по количеству стороннего ПО.
В то время как микросервисы с docker-compose и четко очерченным avro-схемами API разворачиваются довольно просто.
Использование докера намекает, что новой красивой системе всего года три-четыре от роду, так что нужно помнить, что:
- Через 15 лет докер вполне может стать дремучим legacy, к которому не притронется ни один хипстер, а ваша система ещё будет жить (мы ведь рассуждаем об удавшихся, а не провальных проектах)
- Легко написать первую версию новой системы, да и вторую нетрудно. На любом языке, да хоть на Фортране. Сложности начинаются когда система становится успешной, на ней основываются основные процессы предприятия, и к вам приходят с предложением «чуть-чуть подправить» функциональность чтоб получить ещё больще прибыли. И так 30 раз в течение десяти лет, причём приходят разные люди из разных отделов, да и у вас уже два раза сменился состав команды.
- Сложные проблемы требуют сложных решений — всё простое уже было автоматизировано в прошлом веке. В микросервисах сложность прячется в конфигах и схемах взаимодействий между сервисами, особенно при реакции на ошибки и нестандартные ситуации.
Кто знает, может в 2030 году будут передаваться от одного поколения к другому магические скрипты на экзотическом к тому времени DSL, которые как-то связывают зоопарк сервисов в нечто рабочее.
Например, alphine.
Это если гонять докер под маком, где в итоге всё равно виртуалка с линуксом запускается, потому что докер — это довольно тонкая обёртка над следующими возможностями ядра Linux: capabilities (1999 г.), namespaces (2006 г.), cgroups (2006 г.), veth, aufs, overlays, iptables… Docker их просто все настраивает за вас. Всё. Сами фичи включены и работают всегда (systemd очень активно cgroups использует, например). Поэтому накладных расходов по сравнению с работающими процессами в вашей Linux-системе нет. Процесс в контейнере — это процесс в вашем Linux, просто ограниченный. (А если у вас MacOS, то просадка IO происходит именно за счёт виртуализации для запуска Linux).
Это один из плюсов докера перед виртуалками — докер не запускает отдельный экземпляр ОС со всеми базовыми сервисами для каждого компонента-сервиса. Стандартный паттерн использования — на один компонент один мастер-процесс, работающий непосредственно с ОС хост-системы.
> а так же 2 и 3
Увы, но это применимо ко всему. У нас тут государсва очертания чаще меняют.
Через 15 лет вообще всё что угодно будет, начиная от массового MIPS вместо X86 и кончая втрожением инопланетян.
Так при проектирвоании и общении внутри команды я настаиваю на том, что бы оперирровали не названиями технологий (тут мы бахнем кафку, а тут аэроспайк), а множествами, отображениями (морфизмы рано пока ) очередями и т.п. Приберегая конкретные названия на потом.
В заметке от переводчика говорится что это опытный разработчик, у меня возникли в этом сомнения так как неоднократно в статье речь заходила о stateful и distributed transaction. Хотя можно наверное быть опытным и любить боль.
В самом начале статьи автор говорит про Netflix. Которые вовсю проповедуют stateless. Таких примеров достаточно много.
Автор указывает, что у вас скорее всего, все равно есть база данных и все равно есть проблема с данными и схемами, от которой вы не убежите.
То что вы описываете есть результат какой то обработки, если у вас есть хранилище данных то это не значит что вы храните состояние между этапами вашего бизнес процесса. Вот например понятие stateless protocol если ваш http сервер ведет логи запросов, от этого протокол HTTP не перестает быть stateless.
У вас внутри может быть ряд stateless приложений, например, приложение которое просто будет выдавать кусок видео по запросу, но как минимум приложения, которые будут взаимодействовать с пользователем, а скорее всего получится еще и немного глубже, что бы решить некоторые проблемы безопасности и так далее.
У вас как минимум есть сессия пользователя
Есть техники позволяющие не хранить сессию на стороне сервера. Недавно читал, как сесии хранят в Json Web Token. Думаю далеко не один способ существует для организации чистого stateless
Выход у вас один — это хранить данные на клиенте. Я думаю вполне очевидно, что доверять клиенту бывает опасно, в том числе тот же в интернете можно найти довольно много примеров, что плохая реализация работы с jwt приводит к тому, что пользователь на основе только секрета для jwt может в целом делать все, что хочет.
Я думаю, какой-то Netflix может, допустим, себе такое позволить, но даже неплохому стартапу вряд ли стоит так рисковать, потому что экспертизы по криптографии и безопасности обычно маловато.
Если вы увидели идентификатор сессии в ваших куках, это ничего не значит. Сессии на сервере могут водится из-за конфига по умолчанию, не отключенного в свое время. Для идентификации клиента и контроля его доступа к ресурсам существуют различные стандарты, например OAuth. И ничего лишнего на клиенте не хранится. Да в каждом запросе вы передаете токен и что с того? Если говорить об организации приложений в SPA то тут все ясно, по определению вам никакие сессии не нужны.
Я не вижу, и тут я согласен с сообществом, никакого риска использования stateless. Мне кажется что вы не до конца осознаете что есть сервис без состояния.
Ну, я вот не понимаю. Состояние у вас все равно есть, но в данных случаях вы просто выносите его в сторонний сервис и каждый раз, когда его нужно провалидировать или проверить опрашиваете этот сторонний сервис.
В конечном итоге у вас все равно есть состояние в системе, храните вы его на клиенте (что небезопасно), в какой-то части вашей системы (и получаете statefull проблемы) или у внешнего провайдера (а значит он получает statefull проблемы). Возможно, я не совсем понимаю проблему, но я не вижу способа избавится от состояния вообще, оно все равно будет поджидать вас в конце цепочки вызовов.
Хранилище данных не есть сервис с состоянием. Ваши данные где то хранятся но ваши сервисы не передают состояние от одного к другому. Наличие хранимых данных не означает наличие состояния.
Если приложение хранит какую-то информацию в себе (базы данных, картинки, отчеты) — оно stateful, потому что не может быть просто так развернуты где угодно.
Возможно, я не прав, но на примере Netflix, вам все равно нужно хранить где-то информацию о моих правах доступа, или хранить какую-то информацию, из которой вы можете получить информацию по мои права доступа. Я не прав?
Мы здесь говорим не о dataless a о stateless, в первую очередь сервисах, а потом уже и о приложениях.
Если приложение хранит какую-то информацию в себе (базы данных, картинки, отчеты) — оно stateful
С чего вы взяли? Ваше приложение или сервис могут зависеть от внешних сервисов или источников данных но это не значит что они привязаны к какому-либо состоянию.
Что для вас есть stateful?
Скажем, сервис, который в любых условиях (если он работает корректно) по ссылке cute.service.com/t1?t2=t2 выдает один и тот же ответ — stateless.
А если вы добавите сюда, допустим, хедер авторизации и список пользователей с паролями в файлике, который можно будет менять и это будет влиять на ответы сервиса — он уже stateful.
Я не прав?
Нет тут вы не правы. Вы путаете концепцию чистых и не чистых функций с концепцией stateful/stateless. Вот тут есть доходчивое объяснение обоих понятий.
Вы не слышали о понятии антероградной амнезии? Это когда мозг не в состоянии перемещать информацию из кратковременной в долговременную память. Т.е. человеку после пробуждения каждое утро приходится объяснять как он прожил жизнь с момента травмы и до сего дня.
Так вот понятие stateless это и есть полная и желаемая амнезия вашего сервиса, где при каждом обращении вы должны ему напомнить кто вы и каков ваш контекст. Для облегчения этого дела есть фильтры или цепочки обработки запроса, но в целом это так.
Ну и как я понимаю, с технической точки зрения, хранить абсолютно все состояния в базе данных может быть и немного больно, зато довольно производительно.
Возможно, вы правы, но в конечном итоге у вас все равно будет в системе stateful сервис.
Грубо говоря если вы не используете сессий или их подобий у вас будет сервис без состояния. Все что у меня будет в конечном состоянии это нечистая функция с точки зрения ФП.
Ну и как я понимаю, с технической точки зрения, хранить абсолютно все состояния в базе данных ...
Если не вдаваться в подробности EventSourcing то вы не храните состояния в БД, вы храните бизнес данные. Если вы используете БД как хранилище сессий то вы stateful.
Я тут про базу фигню написал, я имел ввиду, что хранить все состояния в конечном сервисе может и круто с архитектурной точки зрения, но довольно плохо с точки зрения производительности.
Если не вдаваться в подробности EventSourcing то вы не храните состояния в БД, вы храните бизнес данные. Если вы используете БД как хранилище сессий то вы stateful.
К сожалению, я все еще могу понять, как можно не использовать сессии. Что у вас будет служить переключением того, что текущий пользователь может получить получить доступ к страницам, которые доступны только пользователям, которые вошли в систему?
К сожалению, по "Asynchronous Web" гуглиться в основном именно асинхронная работа, которая никак не связана с тем, есть сессии или нет.
Что у вас будет служить переключением того, что текущий пользователь может получить получить доступ к страницам, которые доступны только пользователям, которые вошли в систему?
Подписанный токен, включающий срок действия, который передается с каждым запросом.
А если надо сверять токен с чем-то в базе, опять же получается что состояние есть в базе.
Ну, то есть хранить все на клиенте и надеяться на силу своей криптографии
Клиенту передается лишь временный токен. И да in cryptography we trust. В базе нет состояния, в базе есть информация о токене. И это не stateful, вы статью внимательно читали?
Ну, если вы доверяете токену, который приходит с клиента — это так себе идея. После страшных докладов, где люди высчитывают секретный ключ по тому, сколько сервер обрабатывает разные ключи, если бы у меня была большая компания, я бы очень сомневался, прежде чем использовать такой подход. Понятное дело, что куча сайтов как Неуловимый Джо.
А если вы сверяете информацию о токене с записью в базе данных, то это уже состояние. Или я не прав?
Ну такое, практика показывается что это всегда плохо.
А можно примеры, когда именно криптография подвела?
Вам конкретно при клиентском хранении или вообще? Для вообще есть вот такие штуки, которые меня довольно пугают.
Классический пример: REST-like веб-сервис, состоящий из nginx, php-fpm и mysql. Если серверные сессии не используется хоть в каком-то виде, то у вас stateless API, если используются для, например, аутентификации, то у вас statefull API, но в обоих случаях у вас statefull сервис, вы не можете развернуть его на других серверах без потери или переноса данных. Может быть stateless nginx, может быть stateless php-fpm, но mysql stateful (даже не по API, а по своей сути, по своему назначению), а значит и весь сервис в целом statefull, хотя API у него может быть stateless, и сервер или контейнер с nginx и php-fpm могут быть развёрнуты с нуля за минуты, а то и секунды в новом окружении. Но вот базу надо будет переносить, без базы это будет уже новый сервис, а перенесенный старый.
Это вы что то путаете. API это просто программный контракт, как контракт может иметь или не иметь состояние?
С чего вы взяли что зависимость от бизнес данных хоть как-то влияет на состояние. В случае stateless вы будете чаще обращаться к источникам данных чем в случае с stateful, тут речь не об этом.
Если у вас есть workflow, с этапaми login->choose_item->put_to_cart->purchase где за каждый этап отвечает микросервис. И если от login к choose_item или к put_to_cart у вас сохраняются данные в некой сессии, то у вас stateful. Так как сервер используя механизм сессий сохраняет некоторые данные между запросами HTTP(s). Что тут непонятного, ума не приложу, вам может литературу какую посоветовать по теме? Я там выше ссылку на статью оставлял.
Это вы что то путаете. API это просто программный контракт, как контракт может иметь или не иметь состояние?
Не зря же REST так назвали.
Так как сервер используя механизм сессий сохраняет некоторые данные между запросами HTTP(s). Что тут непонятного, ума не приложу, вам может литературу какую посоветовать по теме?
Непонятно то, почему если вы храните токен, то это внезапно становится stateless, хотя вы так же храните информацию о сессии.
Непонятно то, почему если вы храните токен, то это внезапно становится stateless
Дак никто же не хранит токен нигде, кроме клиента.
Не зря же REST так назвали.
REST-compliant Web services allow requesting systems to access and manipulate textual representations of Web resources using a uniform and predefined set of stateless operations
Термин State здесь не про stateful. И официально на великий и могучий переводится как передача состояния представления. Помните про амнезию.
REST Это архитектурный стиль. API в стиле REST остается всего лишь контрактом, так как контракт может быть stateful или stateless?
Дак никто же не хранит токен нигде, кроме клиента.
И мы обратно возвращаемся к тому, что или вы полагаетесь на клиент (что очень не безопасно) или делаете свое приложение таки немного stateful.
То есть можно сделать полностью stateless приложения, но получить потенциальную очень неприятную дыру в безопасности. И не совсем понятно, почему вы ставите под сомнение профессионализм автора, если он выбирает немного постоянной боли, вместо ночных кошмаров.
И мы обратно возвращаемся к тому, что или вы полагаетесь на клиент (что очень не безопасно) или делаете свое приложение таки немного stateful.
Да с чего вы взяли что хранить временный токен где-то на клиенте это менее безопаснее чем хранить куки с данными сессиями на том же клиенте. REST по определению не может быть stateful, определение еще раз перечитайте.
Да с чего вы взяли что хранить временный токен где-то на клиенте это менее безопаснее чем хранить куки с данными сессиями на том же клиенте.
Потому что у вас есть проверочная информация на сервере, с которой вы его сравниваете.
REST по определению не может быть stateful, определение еще раз перечитайте.
Кто бы еще делал этот REST правильно)
Пример контракта имеющего состояние:
- сначала надо отправить запрос POST /auth с логином и паролем, в ответ придёт кука sessionId
- сервер сохраняет userId в сессии
- на все дальнейшие запросы нужно отправлять эту куку
- сервер будет логировать Userid из сессии и проыерять права доступа.
Пример контракта без состояния:
- сначала надо отправить запрос POST /auth с логином и паролем, в ответ придёт подписанный токен с userId
- на все дальнейшие запросы нужно отправлять этот токен
- сервер будет логировать Userid из токена и проыерять права доступа.
Бизнес-данные, принадлежащие сервису — часть его состояния, как свойства объекта — часть его состояния. Мутирующие запросы к сервису имеют целью изменить его состояние, как мутирующие методы имеют целью изменить состояние объекта. Если вызов мутирующего запроса или метода требует предварительного вызова других запросов или методов, то интерфейс этого сервиса или объекта является stateful.
Изменение состояния сервиса — суть большинства моделей бизнес-процессов.
Бизнес-данные, принадлежащие сервису — часть его состояния.
А вот и нет. Бизнес данные отражают состояния ресурсов к которым тот или иной сервис имеет доступ. Состояние ресурса и состояние сервиса это разные вещи.
Если вызов мутирующего запроса или метода требует предварительного вызова других запросов или методов, то интерфейс этого сервиса или объекта является stateful.
Я свои доводы подкрепил ссылками на статьи и даже википедию. Вы чем можете подкрепить свои утверждения?
Например http://whatisrest.com/state_management_explained/types_of_state
Обратите внимание на диаграмму: состояние в stateful сервисах делится на состояние контекста, сессии и бизнес-модели. Вы говорите только о stateless sessions.
Statefull vs Stateless не про контракты, а про особенность обработки запросов конкретно в этом узле. Если какой-либо стороне нужно помнить контекст, чтобы с учетом этого контекста правильно обращаться в следующий раз, то это Statefull. В обратном случае — Stateless.
Например в вашем примере два варианта, с кукой и токеном. В общем случае клиенту, нужно помнить куку или токен. Для него это Statefull. Если он будет забывать куку или токен, то не сможет нормально обращаться к сервису. Т.е. клиент в обоих случаях должен помнить состояние.
А серверное приложение может помнить куку или токен. А может и не помнить, и при каждом запросе идти в хранилище кук или токенов и пересоздавать сессию. Тогда (во втором варианте) серверное приложение будет Stateless. У него не будет внутреннего состояния. И тогда получаем выигрыш от Stateless — возможность обрабатывать запрос на любой из имеющихся нод.
При этом в целом сервис (то как его видит клиент) — Statefull. Очевидно в недрах него где-то сохраняется его состояние, чтобы клиент мог нормально к нему обращаться.
Вот такой дуализм
Это вы что то путаете. API это просто программный контракт, как контракт может иметь или не иметь состояние?
Очень просто. Stateless контракт выглядит вот так:
login(): token
foo(token)
bar(token)Statefull же — вот так:
login()
foo*()
bar*()
* вызывать только после login()Если токен передаете через заголовки то у вас никакой разницы в сигнатурах не будет. То что вы пометили звездочкой справедливо для обоих сценариев.
Если следовать вашей логике со счетчиком то любой stateful контракт можно замаскировать под stateless и наоборот.
Да и вообще я не вижу смысла пытаться передать эту информацию здесь, контракты API не для этого. Клиенту вашего API будет все равно что там внутри.
Не "замаскировать", а "преобразовать". Нет, не любой.
То что вы пометили звездочкой справедливо для обоих сценариев.
Не совсем. Во втором сценарии требуется чтобы login был вызван раньше foo в рамках одного соединения или сессии. В первом этого не требуется, клиент может получить token любым способом. Например, прочитать его из конфига или принять от третьей стороны которая управляет авторизацией.
Stateless service — это когда ни один инстанс ни одного клиента не помнит (has no state), и каждый раз устанавливает его личность заново, глядя в его пропуск (token), в котором написано всё необходимое для работы сервиса (claims: имя, пол, возраст, должность, ...), а подлинность пропуска и написанного в нём устанавливает проверкой подписи выдавшего этот паспорт органа (trusted issuer). Сервис не хранит в своей БД никакой личной информации о клиенте (всё «личное» есть в пропуске) — БД становится деперсонифицированной, что добавляет безопасности при её компроментации. Это добавляет немного расходов, но позволяет футболить клиента от окошка к окошку, распределяя нагрузку и делая узкоспециализированные «тупые» инстансы, работающие по простому шаблону «глянул в пропуск — сверился с инструкциями безопасности и правил доступа — обслужил/отказал — немедленно забыл — NEXT PLEASE!».
Если я вместо локальной ФС начну хранить данные сессии на расшаренной ФС, redis или ещё где, неужели мой сервис станет stateless?
Но нет, сервис не станет stateless, если он сам лезет за данными сессии, а не клиент ему приносит.
Вы говорите о приклеивании клиента к инстансу как об основном практическом признаке и недостатке stateful. Расшаривание данных сессий между инстансами устранит приклеивание — любой из инстансов апп-сервера может записать и (или) достать данные из сессии.
Собственно, это стандартный способ сделать stateless как можно большее число внутренних подсервисов, чтобы сосредоточить state лишь в нескольких, специально заточенных под хранение state, типа Redis или *SQL
Не, я понимаю, что можно говорить о разных градациях statefulness/statelessness, но где-то нужно провести границу, хотя бы для сессий. В моём понимании этой границей является способ распространения shared user data. Либо через клиента (который всё равно сам приходит, и может заодно принести данные) — и тогда у инстанса нет забот, не нужно хранить состояние сессии нигде вообще, только знай проверяй подпись и сверяйся с полиси. Либо состояние есть и передаётся через какой-то back-channel, который нужно позаботиться установить, обезопасить и поддерживать.
У вас как минимум есть сессия пользователя, а еще, например, текущая временная точка на ролике.
Это вовсе не обязательно, технически если вы используете Apache Netty, Sinatra в спец конфигурации или какую-нибудь легковесную имплементацию OWIN, итд, ничего этого у вас нет и быть не может по определению. 9 лет назад впервые начали говорит о понятии async web где внутренней организации чуждо само понятие сессии.
Ну вот не знаю, мой аккаунт как-то хранится в netflix, какой тут stateless
То что у них есть база данных где ваш аккаунт лежит — как то влияет на «statefullness» самого приложения?
На самом деле правы и Вы, и Ваши оппоненты.
Действительно, во многих случаях где-то там, в конечном итоге, всё-равно будет существовать stateful микросервис (и не один). Тем не менее, если часть кода находится в кучке stateless микросервисов, которые, в конечном итоге, по цепочке вызывают этот stateful — это всё-равно упрощает жизнь. Потому что ту часть кода проекта, которую удалось поместить в stateless микросервисы, будет проще поддерживать и масштабировать, а значит их действительно корректно называть stateless.
С другой стороны, когда данные сервиса кладут в MySQL и по этой причине решают что сервис стал stateless — это некорректно. На первый взгляд, если строго формально, у нас получается как бы два сервиса: stateful MySQL с данными, и наш stateless сервис без данных. И наш "stateless" сервис действительно можно запускать в нескольких экземплярах и масштабировать как настоящие stateless сервисы (только все эти экземпляры должны работать с общим MySQL). Но ключевой момент в том, что сервис MySQL не является настоящим "владельцем" хранящихся в нём данных — владельцем данных остался наш "stateless" сервис, т.к. именно он определяет схему данных и его требуется изменять синхронно с изменением схемы данных. Не важно, через какой интерфейс (файловое API OS, сетевой доступ к серверу БД или какому-то другому сервису) сервис получает доступ к данным, важно насколько сильно он связан с этими данными и кто имеет возможность изменять структуру этих данных — именно этим определяется, stateful он или нет.
В качестве "теста на stateless" можно задаваться простым вопросом: нужно ли изменить код сервиса если незначительно изменится схема данных (например переименовали таблицу в БД). Если да — значит он stateful.
Если следовать вашей логике то в природе есть только stateful приложения. Поскольку исходники любого приложения развернуты на сервере и прежде чем обработать запрос в первый раз серверу нужно подгрузить исходники или залить байткод в JIT компилятор или whatever. Следовательно в любом случае нужно куда-то обращаться соу это stateful. Вздор.
Нет, не следует. Если приложение на все одинаковые запросы отдаёт одинаковые ответы независимо от того, только что оно развёрнуто/запущено или уже обработало миллион запросов, то это стейтлесс. А если на запрос GET /posts/count оно отдаёт количество успешно обработанных запросов POST /posts, то оно stateful.
Чем подкрепите свое утверждение?
Укажите где в источнике на который вы ссылаетесь есть подтверждение тому что вы сказали выше?
Я же нашел след формулировку:
As you may have guessed, a service that is actively processing or retaining state data is classified as being stateful.
Это не соответствует вашему утверждению. Капнем глубже и увидим:
A classic example of statelessness is the use of the HTTP protocol. When a browser requests a Web page from a Web server, the Web server responds by delivering the content and then returning to a stateless condition wherein it retains no further memory of the browser or the request.
Следовательно, состояние stateless это состояние при котором сервер не удерживает никакой информации о браузере или запросе или прочей под информации. Следуя данной формулировке мой endpoint GET /posts/count, which does not retain neither further memory of the browser nor the request is considered as stateless. То же самое можно сказать про ваш POST.
Ну так что же подтвердит ваше утверждение что
Если приложение на все одинаковые запросы отдаёт одинаковые ответы независимо от того, только что оно развёрнуто/запущено или уже обработало миллион запросов, то это стейтлесс. А если на запрос GET /posts/count оно отдаёт количество успешно обработанных запросов POST /posts, то оно stateful.
Первая цитата. Почему не соотвествует? Если ответ всегда одинаков, то значит состояние приложения не изменяется. По факту этого состояния и нет. По крайней мере для клиента. Может приложение и пишет активно логи и эти логи можно считать состоянием, но как-то натянуто.
По второй цитате — stateless там о протоколе, а не о приложении в целом. Сервер не удерживает никакой информации о текущей сессии, о текущем клиенте, о его предыдущих запросах в рамках протокола. Но вот ваше "или прочей под информации" некорректно. Сервер удерживает информацию из тела некоторых запросов, он может не хранить связь с запросом или хранить, но не использовать для бизнес-логики, но своё состояние изменяет — это изменение цель таких запросов. Хранить он его может в памяти, файлах, встроенной базе данных или сервере баз данных, облачном хранилище — это лишь деталь хранения.
Но вот ваше "или прочей под информации" некорректно
Под прочей подобной информацией понимается технические данные которые для бизнес части не представляют никакого интереса, например данные о мобильном или IoT устройстве. Так что некорректно ваше замечание.
Если ответ всегда одинаков, то значит состояние приложения не изменяется.
Следовательно, по вашему, если ответ меняется то и состояние меняется. Возьмем к примеру сервис который выдает вам тек время, по вашему выходит что это stateful сервис.
По второй цитате — stateless там о протоколе, а не о приложении в целом.
Брехня, пожалуйста вчитайтесь, там как раз говорится о свободе от состояния в целом на примере отдельно взятого протокола. Вот отрывок ниже:
A classic example of statelessness is the use of the HTTP protocol.
Все остальное ваши фантазии.
Сервер удерживает информацию из тела некоторых запросов, он может не хранить связь с запросом или хранить, но не использовать для бизнес-логики, но своё состояние изменяет.
Сервер ничего сам по себе удерживать не будет если вы ему не скажете об этом. Вернемся еще раз к определению REST из википедии раз у вы не в состоянии трактовать его из вашей же статьи:
REST-compliant Web services allow requesting systems to access and manipulate textual representations of Web resources using a uniform and predefined set of stateless operations.
Возьмем к примеру сервис который выдает вам тек время, по вашему выходит что это stateful сервис.
Конечно stateful. Есть некое состояние, изменяющееся со временем, и сервис даёт его текущий срез.
Брехня, пожалуйста вчитайтесь, там как раз говорится о свободе от состояния в целом на примере отдельно взятого протокола.
Да, протокол в этом примере свободен от состояния. Про состояние приложения не говорится вообще ничего.
Сервер ничего сам по себе удерживать не будет если вы ему не скажете об этом.
Ну, условно можно и так считать. Но большинство сервисов как раз и создаются, чтобы удерживать состояние бизнес-модели и им я прямо об этом говорю, например, путём INSERT/UPDATE/DELETE SQL-запросв.
Вы выделили "операции" — в REST-сервисе операции должны быть stateless, операции — это интерфейс сервиса, его внешний контракт. Но сам сервис не должен быть stateless.
Конечно stateful. Есть некое состояние, изменяющееся со временем, и сервис даёт его текущий срез.
Чем подкрепите ваше утверждение? Я говорю что этот сервис stateless если не удерживает состояния в виде контекста сессии от предыдущего запроса. Что абсолютно симметрично примеру с HTTP протоколом из вашего источника.
чтобы удерживать состояние бизнес-модели
Наличие изменения представления ресурса не влияет на statelessness/statefulness сервиса. См определение из вашего источника.
Вы выделили "операции" — в REST-сервисе операции должны быть stateless, операции — это интерфейс сервиса
А вот и нет, операция это лишь часть интерфейса. REST-сервис может состоять из одной или множества stateless операций. До тех пор пока все операции данного сервиса stateless этот сервис можно считать REST-совместимым. Следовательно REST-сервис это stateless сервис.
REST-compliant Web services allow requesting systems to access and manipulate textual representations of Web resources using a uniform and predefined set of stateless operations.
Мне кажется то что вы так яро называете состоянием приложения или системы, в данном определении названо представлением ресурса (representation of resource) но увы не его состоянием. Наличие изменяемых или неизменяемых ресурсов в системе делает ее immutable/mutable но не stateful/stateless.
Я говорю, что сервис может быть stateless относительно контекста сессии, но при этом быть stateful относительно бизнес-данных. В случае сервиса времени у него определенно есть изменяющиеся бизнес-данные, значит сервис не является stateless, даже если использует stateless контекст сессии.
Наличие изменения представления ресурса не влияет на statelessness/statefulness сервиса.
Наличие операций изменения ресурса точно делает ресурс stateful, даже если клиенты обращаются к нему по stateless протоколу.
А вот и нет, операция это лишь часть интерфейса. REST-сервис может состоять из одной или множества stateless операций. До тех пор пока все операции данного сервиса stateless этот сервис можно считать REST-совместимым. Следовательно REST-сервис это stateless сервис.
REST-сервис является stateless сервисом на уровне своего интерфейса, протокола, но, как правило, он является stateful на уровне бизнес-модели.
Вы ограничиваете характеристику stateful/stateless только на сессию, может ещё на контекст, а я распространяю её на бизнес-данные. Можно говорить, что в многозвенной архитектуре, например, типичной для веб-сервисов трёхзвенке (веб-сервер, апп-сервер, сервер СУБД) только одно звено является stateful, но оно делает весь сервис stateful. Если вы захотите перенести или склонировать сервис, вам понадобится переносить данные. Собственно, это главное практическое отличие stateless от stateful. Не хотите рвать сессию при переносе/масштабировании — делайте приложение session stateless, не хотите терять бизнес-данные — делайте приложение business stateless.
Вы ограничиваете характеристику stateful/stateless только на сессию, может ещё на контекст, а я распространяю её на бизнес-данные.
Ну это вы тут ваш огород городите. Вы не привели ни одного внятного определения из литературы подтверждающие ваши гипотезы. Все ваши доводы основываются на недопонимании вами отдельных концепций и не имеют ничего общего с реальностью. Хотите называть красное зеленым, пожалуйста.
Понятия stateless/stateful используются в контексте потоков информации в контексте движения. Ваш БД слой никаких потоков или движения не осуществляет, это такая же абстрактная структура данных только не в памяти.
Тоже stateful, только state в нём immutable :)
Как пример, у вас будут сотни и даже тысячи микросервисов их деплой и обслуживания станут головной болью. Боюсь если ваш проект требует тысячи микросервисов, то на монолите это станет значительно большей головной болью, если он вообще дотянет до такой сложности.
Остальные минусы примерно такие же, в стиле в микросервисах это плохо, но есть инструменты для решения данной проблемы, при этому увеличивается, что на монолите проблемы порождаемые теми же причинами другие и решаются значительно сложнее.
Да и часто проблемы являются обратной стороной достоинств, например распределенные транзакции, или не нужны( можно обойтись итоговой консистентностью данных ) или и на монолите транзакции таких размеров приводят к огромным сложностям в проектировании бд и запросов, в итоге одну проблему сняли, сложность базы, блокировки и т.д., но получили более сложную логику работы с целостностью данных, и к этому часто приходят в итоге и в монолите, только несколько позже.
Я бы сказал, что у микросервисов проблемы которые вылезут на монолите рано или поздно есть сразу и это повышает порог входа.
Если же взаимодействие есть, то тут есть простое правило: Inter-process communication сложнее, чем in process Communication. Причём, если ошибка передачи параметров внутри программы часто ловится компилятором/интерпретатором, то ошибки в IPC ловятся в махровом рантайме и погружают администраторов в потрошки внутреннего мира программы.
Утрируя: если фабрика DSL'ей содержит баг, приводящий в ошибке интерпретации некоторых инструкций некоторых DSL'ей, то это чисто баг в программе.
Если же фабрика генерации версионированных сообщений на DSL для IPC содержит баг, то это проблема админов, потому что у них один сервис с другим больше общаться не может.
Делегация компетенции — это очень плохой паттерн в архитектуре. Иногда он имеет смысл (когда, например, мы делегируем компетенцию с целью предоставления возможностей), но если мы делегируем компетенцию только ради того, чтобы реализовать какой-то (другой) модный паттерн разработки — это катастрофа.
Потому что администратору иногда очень трудно понять какие тараканы были в голове у разработчика, когда он сделал «ТАК» (когда оно работает, то всё сделано хорошо, мы же баг обсуждаем, правда?).
Inter-process communication сложнее, чем in process Communication
Это конечно верно, но когда в рантайм возникает проблема с in process Communication, для администратора все становится ещё сложнее. Нужен трейсер или дебагер. А побольшому счету обязательно нужен программист. И не факт, что он доступен конкретно сейчас.
К тому же проблемы мискоммуникаций сервисов гораздо проще ловятся на этапе тестирования, чем взаимодействия в монолите.
IPC же может сломаться по совершенно эзотерической причине — превышение unknown unicast лимита на свитче, изменение алгоритма выставления don't fragment на туннелях, etc. Эти штуки требуют отдельной компетенции (не связанной с приложением).
Получается, что тыкая IPC всюду, возможные баги в приложениях вытаскиваются на тот же уровень, на котором находятся сайд-эффекты внешнего мира. Это не только усложняет отладку, но и резко повышает требования к программисту, который отлаживает свой (кривой) IPC — он должен думать уже не только про структуры данных и архитектуру, но и про посторонние вещи, вроде ERD на роутере, глюков на агрегированных линках, кешей DNS, etc.
Вот для этого и нужны люди, которые в этом понимают. Плюс админы. Для них вся эта кухня весьма понятна и проста (я сам выходец из админов). Т.е. нужно разделение ролей: есть люди которые работают над IPC и понимают его. Они делают удобные инструменты для тех кто пишет бизнеслогику и объясняют последним границы допустимого.
Шапкозакидательный подход (разработчик пишет идеальный код для идеального окружения работающего на идеальном железе) в индустрии не работает.
Поскольку IPC по своей сути — это целиком и полностью использование side effect'ов, то перевод из вызова силами языка в IPC, это перевод чистого кода в код с side effect'ами. Что, традиционно, вызывает боль и проблемы.
Чем более код остаётся в чистом виде (без side effect'ов), тем легче его сопровождать. Чем меньше у кода точек соприкосновения с side effect'ами, тем легче его администрировать.
Монолит у вас тоже не в воздухе повешен, он тоже взаимодействует с окружением, аппаратным обеспечением, внешними источниками данных.
В микросервисах у вас эти проблемы просто вылезут раньше, при этом скорее всего качество кода исходно будет выше( в разрезе устойчивости и логирования подобных ситуации ), а проблема будет более изолированной.
В монолите вы когда на эти проблемы наткнетесь( например на туже потерю пакетов между субд и приложением ) будете очень удивлены информативностью ошибок.
А в «монолите» таймаутов такого рода не будет, потому что это чистый код. Работа с СУБД — разумеется, да, но это как раз «отдельные места для side effects».
Микросервисы упрощают разработку за счёт того, что часть сложности переносится в связи между микросервисами. Частично эта новая сложность сказывается на программистах (обработка сетевых ошибок, таймауты, повторы, …), частично на админах/девопсах. Так что да, Вам, как админу, микросервисы проблем только добавили. Так задумано, и во многих случаях оно того стоит. :)
Могут быть подобного рода таймауты, например, когда очередь диска забита. Или даже планировщик не даёт процессу времени. Или тупо питание обрубится. Инфраструктура не идеальна, а уж если люди там замешаны…
Грубо, одной из задач админов всегда было минимизировать количество таких проблем, а одной из задач программистов минимизировать последствия проблем, которые админы (ожидаемо) не смогли предотвратить. Ничего качественно нового микросервисы в задачи программистов не внесли в этом плане. Помните же "Abort, Retry, Fail?" Кажется в MS-DOS появилось, а в CP/M просто ждала до бесконечности.
1. Таймауты описанные вами в 99% случаев до приложения не дойдут, только в случае длительной перегрузки каналов. Они обрабатываются на tcp уровне для которого потеря пакетов это часть нормального функционирования, что называется байдизаин, более того, на эту саму потерю он частично завязан и без корректной обработки вообще не может функционировать в более менее сложных сетях.
2. Таймауты нужно по возможности устранять, о чем я вам и написал. Это не значит, что их всех можно вывести, но при большом кол-ве таймаутов пользовательский опыт от приложения сильно снизиться.
3. Следует сравнивать различные подходы. Недостаток, только тогда становиться недостатком, когда его есть с чем сравнить.
Подходы следует сравнивать в равных условиях, мне кажется не корректным сравнение сложной континентально распределенной системы на микросервисах, с монолитом в пределах одной серверной.
Если мы говорим о распределенных системах, то проблемы таймаутов будут и там и там, и в микросервисах они решаются проще, если в пределах серверной, то проблем и там и там не будет при условии адекватной инфраструктуры, проблемы с которой являются вполне устранимыми.
4. Микросервисы изначально следует проектировать с учетом возможных отказов сетевого уровня. Учитывая требования к сложности отдельно сервиса, это не rocket science.
Они обрабатываются на tcp уровне для которого потеря пакетов это часть нормального функционирования, что называется байдизаин, более того, на эту саму потерю он частично завязан и без корректной обработки вообще не может функционировать в более менее сложных сетях.
Тут речь не об этом. TCP хорошо отрабатывает потерю пакета на быстром канале, но в условиях перегруза он показывает очень плохой результат из-за высоких таймаутов. Кроме того он дорогой с точки зрения ресурсов. Именно поэтому авторизация в телеком сетях сделана на UDP (Radious протокол). TCP очень сложный вопрос. Я бы сказал болезненый. Он был придуман в другое время, при других условиях, нежели сейчас. Кроме того конкретные реализации в разных операционках страдают разной степени идиотией, поэтому возникают разные инфраструктурные и протокольные костыли: типа поддержка постоянного tcp коннекта с брокером сообщений (точнее целого пула), websockets или собственные протоколы поверх UDP (как упомянутый Radious). Проблема здесь действительно есть и не имеет к прикладному уровню прямого отношения.
Я ж как раз про это и говорил — должна быть веская причина. Микросервисы без причины — признак дурачины.
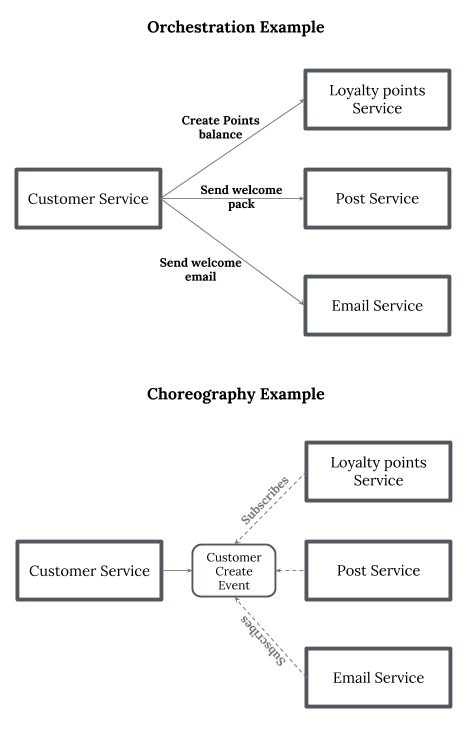
Orchestrating также применили тут на презентации www.slideshare.net/weaveworks/orchestrating-microservices-with-kubernetes по полному циклу управления микросервисами. Это из другой области.
Ну это всё сухие термины…
А потом пришли инструменты оркестрации, и оркестрация из идеи в голове превратилась в конкретные yaml'ы, и сейчас оркестрация — это не только идея, но и её практическое воплощение. Средство оркестрации, описание этого взаимодействия в машиночитаемых (машиноисполнимых!) формах, etc.
Примерно то же самое случилось с configuration management. Начиналось оно с идеи, а потом превратилось в конкретные проявляения конкретных софтин.
Я как представлю что когда бобрики, таймзоны, морковки, валюты, карты речек, и белочки — лежат в разных БД — мне хочется горько заплакать. Потому что я в упор не понимаю, как можно сделать распределенный join 10-ка таблиц, если эти таблицы лежат на разных дисках, и доступны через REST API. Ну, кроме как иметь гигансткий, неконсистентный кеш всего этого у себя в БД, от чего я плакаю еще больше.
Короче, может все тут и пишут high-load видео-стриминг сервисы, а я один — про белочек и зайчиков. И всех дикий-предикий high-load, и прям надо половину сервисов писать на rust, и половину на python, и прям чтобы все скейлилось в разы за секунды, и умело жить когда половина системы легло. Тогда да. Тогда, наверное, хорошо все эти микросервисы работают.
Но если у вас про белочек и зайчиков, как у меня, и вы решили перейти на микросервисы — подумайте еще раз.
По теме:
«Microservices prefer letting each service manage its own database»
Pattern: Database per service
если бобробелочка хорошо вместе с зайчиками, и плохо по-отдельности, оставьте как есть
если бобробелочка хорошо вместе с зайчиками, и плохо по-отдельности, оставьте как есть
… и тут мы получили снова монолит
Легко поменять систему которой никто не пользутеся, но вот бизнес почему-то ищет успешные (читай «старые») продукты и думает как бы их ещё проинтегрировать чтоб извлечь дополнительную пользу.
Корс сервисные агрегации данных это действительно проблема, но не в этом случае.
«всем зайчикам, проживающим в одной хатке с бобриками»
Выделяем хатки и их обитателей.
", с 3 до 5 утра по их таймзоне,
давать скидку на морковку зеленого цвета,"
В условиях скидки пописываем возможность указать цвет объекта и время операции.
" в 10 долларов в рублях по текущему курсу,"
Прикручиваем запрос курса у цб, возможно кэшируем его у себя.
«если морковку сажали беременные белочки, и грядки были не далее 10 км от речки»
Указываем тип «посадчика», белочка( зайчик, медведь, иван иваныч ), выбриваем все грядки на которые нужно считать скидку и которые сажали белочки, агрегируем белочек и запрашиваем их были ли они беременны на дату.
Указываем для каждой грудки расстояние до речки.
Вообще вопрос в выделении зон ответственности сервисов и в способности предсказывать как они будут меняться в будущем.
Ну и такие штуки хорошо работают, пока у вас не 100к белочек и несколько миллионов грядок.
Все эти задачи решаемы, кто спорит. Можно например что-то вообще на клиенте считать или оффлайн на очередях обрабатывая пачками и выстраивая в цепочки. Просто там где можно было бы решить вопрос аггрегацией (или несколькими), приходится городить огороды. На десятой по счету задаче ты обнаруживаешь что мир состоит из велосипедов и костылей, когда все должно быть просто как яйцо.
Собственно суть то в чем — мода городить микросервисы везде неглядя и не думая, причинила довольно много боли и страданий разработчикам по всему миру.
Я как представлю что когда бобрики, таймзоны, морковки, валюты, карты речек, и белочки — лежат в разных БД — мне хочется горько заплакать.
Это не микросервисная архитектура, а просто плохая. И она не имеет никакого отношения ни к микросервисам, ни к монолиту.
Потому что я в упор не понимаю, как можно сделать распределенный join 10-ка таблиц
Если в проекте возникла такая задача, то это сразу маркер абсолютной некомпетентности архитектора проекта. А если разработчики спокойно скушали подобное — то, скорее всего, и их тоже.
«всем зайчикам, проживающим в одной хатке с бобриками, с 3 до 5 утра по их таймзоне, давать скидку на морковку зеленого цвета, в 10 долларов в рублях по текущему курсу, если морковку сажали беременные белочки, и грядки были не далее 10 км от речки»
Хотя даже в этой задаче сервис "поставщик курса валют" может быть отдельным.
Если в проекте возникла такая задача, то это сразу маркер абсолютной некомпетентности архитектора проекта.
Бизнес меняется и требования меняются. Если белка — покупатель и бобёр покупатель то кажется логичным их объеденить в одну базу\таблицу Customer. Но вот о том, что они будут покупателями могли и не знать предыдущие 5 лет разработки системы.
Другое дело что микросервисы тут совсем не виноваты, а пример с белкобобрами плох и дает нам ложную интуицию о том, что они должны были быть вместе с самого начала. Осуществлять же такую коренную переделку системы проще там, где меньше связанность. У микросервисов она скорее будет меньше, чем у монолита.
То есть вы считаете архитектора и разработчиков квалифицированными, если ошибка сохраняется
5 лет разработки системы
?
Нет, тут не кровати (т.е. микросервисы) двигать надо.
Пишем еще один микросервис, который объединяет этот зоопарк в один домик.
Наружу выставляются нужные методы (REST-API).
Делов-то
<:o)
Сильно зависит от задачи. Одно дело проверить вот этого конкретного клиента давать ли ему здесь и сейчас скидку, другое — разослать смс-рассылку "завтра с 3 до 5 ночи у вас скидка 0.01%", третье — дать бизнесу оценку сколько клиентов попадёт под скидку, если завтра мы её запустим. По разные задачи разные решения. Первую вполне можно решить походом по нескольким енд-поинтам.
У зайчиков, белочек и прочих животных свои БД и микросервисы.
К ним и ходим «в гости», а потом создаем «фрянкенпуха» и отдаем дальше.
В общем считайте, что БД у вас нет, а есть сервисы, с которых тянутся животные.
Понятно, что базист в шоке.
Но кто сказал, что будет легко.
<:o)
Сервис «маркет» идет в сервис «грядки», дергает «getAllGryadkiVozleRechki», достает 10000 ID-шек грядок. Потом идет в сервис «морковки», и передает ему 10000 ID-шек грядок в «getMorkovki?gryadkiId={...10k грядок}&{tcvet='green'}»
Ну и дальше все начинают заниматься какой-нибудь хернёй типа кешей, репликацией куска БД через кафку, построением общего сервиса «поиск морковок», подключением graphQL, бинарной сериализацией 10к ID-шек в AVRO, индексированием морковок мна GPU и нейросетях…
Короче хорошая архитектура — все при деле, можно новые технологии попробовать, деньги платят. Можно статьи на хабр про микросервисы писать, и на конференциях рассказывать.
Сервис грядок вполне может (а скорее должен) хранить отношение морковок к грядкам и отдать id-шки морковок в ответ на getMorkovkiSGraydokVozleRechki, а сервис маркет может в запросе ограничить количество морковок в ответе по какому-то критерию грядок или просто первые деять идшников морковок в случайном порядке. В принципе даже сервис грядок может хранить мастер-данные о цвете морковок, если цвет используется только в контексте грядок. Либо хранить реплику мастер-данных о цвете, но тут надо будет позаботиться так или иначе об консистенции.
Или можно сделать горизонтальные сервисы типа «data warehouse», и «elastic index» — которые собирают и индексируют все имеющиеся данные, предоставляют к ним быстрый доступ, но принципиально не делают никакой бизнес-логики (для них зайчики и морковки — просто какие-то там таблицы)
Пойми правильно — я не против идеи микросервисов, и у меня у самого тут большая распределенная фигня с кафками и докерами. Просто ко мне регулярно приходят разные люди, с предложениями типа «а зачем тебе таблица employees со всеми сотрудниками в БД каждого приложения? Почему вы не сделали микросервис под это, и туда по REST API не ходите»? И вот этот пример с зайками и морковками — они воспринимают как что-то типа «опа, а реально такая проблема есть?».
И мне от этого как-то страшно становится — идея микросервисов очень активно продается, все ее к себе тащат, но мало кто понимает эту всю историю достаточно глубоко.
Выделяется отдельный сервис — Бонусы. В него сливается тем или иным способов все, что нужно для принятия решения по бонусам. И затем либо сам сервис Бонусов строит кампании и отдает их потребителям, либо сами потребители идут в сервис Бонуса и спрашивают, есть ли что предложить для клиента Х.
А все потому, что вы верно отметили, у нас куча разных (не всегда микро) сервисов.
И не потому что кто-то очень любит сегментацию и пилит сервисы пачками. А потому, что бизнес большой и команд много, и многие команды слышали друг про друга, но реально не общались. Потому что когда команд за три десятка, общаться со всеми невозможно в принципе. И монолит даже теоретически невозможен.
Из всего сказанного я бы вынес одну важную мысль: Микросервисы не избавляют от необходимости думать над архитектурой всего приложения. Наоборот, думать надо еще больше
«Netflix хороши в DevOps. Netflix делают микросервисы. Таким образом, если я делаю микросервисы, я хорош в DevOps».
Мысли из серии You Are Not Amazon, Again
Последние мысли: не путайте микросервисы с архитектурой
Можно сказать так: «Если вы не знаете вашего бизнеса, и не в состоянии спроектировать монолит выделив правильно ограниченные контексты и разбив его на компоненты, микросервисы вам скорее всего не помогут».
А если выделите правильно, то и монолит будет выглядеть норм ;)
Смерть микросервисного безумия в 2018 году