Автор: Сергей Лукьянчиков, инженер-консультант InterSystems
Начнем с примеров из опыта Data Science-практики компании InterSystems:
Резюмируя эти и множество других примеров, мы пришли к формулировкам тех вызовов, которые возникают при переходе к использованию механизмов машинного обучения и искусственного интеллекта в реальном времени:
Наша статья – это обстоятельный обзор возможностей платформы InterSystems IRIS в части универсальной поддержки развертывания AI/ML-механизмов, сборки (интеграции) AI/ML-решений и обучения (тестирования) AI/ML-решений на интенсивных потоках данных. Мы обратимся к исследованиям рынка, к практическим примерам AI/ML-решений и концептуальным аспектам того, что мы называем в этой статье AI/ML-платформой реального времени.
Результаты опроса, проведенного среди около 800 ИТ-профессионалов в 2019 году компанией Lightbend, говорят сами за себя:
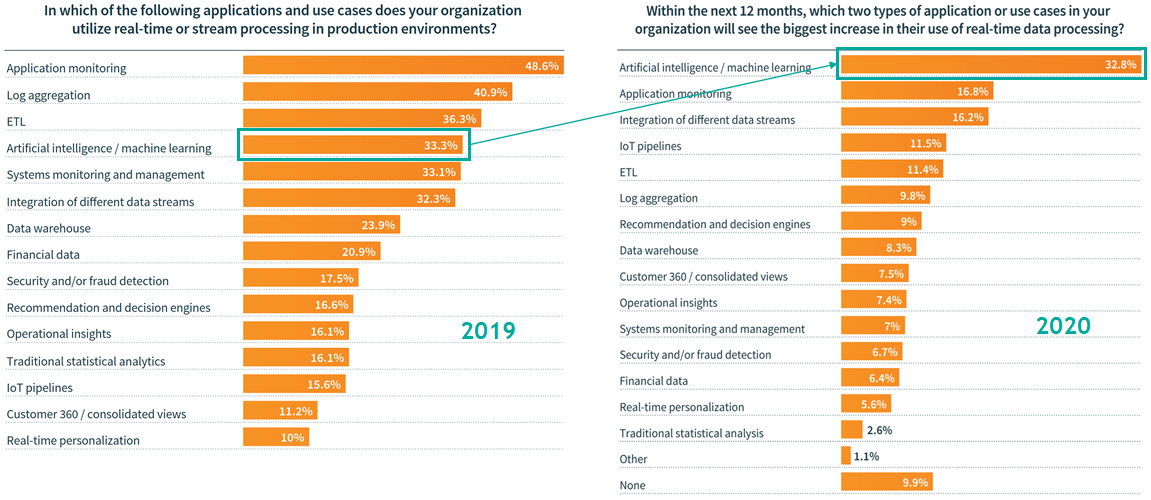
Рисунок 1 Лидирующие потребители данных реального времени
Процитируем важные для нас фрагменты отчета о результатах этого опроса в нашем переводе:
«… Тенденции популярности средств интеграции потоков данных и, одновременно, поддержки вычислений в контейнерах дают синергетический отклик на запрос рынком более оперативного, рационального, динамичного предложения эффективных решений. Потоки данных позволяют быстрее передать информацию, чем традиционные пакетные данные. К этому добавляется возможность оперативного применения вычислительных методов, таких как, например, основанные на AI/ML рекомендации, создавая конкурентные преимущества за счет роста удовлетворенности клиентской аудитории. Гонка за оперативностью также влияет на все роли в парадигме DevOps – повышая эффективность разработки и развертывания приложений. … Восемьсот четыре ИТ-специалиста предоставили информацию по использованию потоков данных в их организациях. Респонденты находились преимущественно в западных странах (41% в Европе и 37% в Северной Америке) и были практически равномерно распределены между малыми, средними и крупными компаниями. …
… Искусственный интеллект – не хайп. Пятьдесят восемь процентов тех, кто уже применяет обработку потоков данных в продуктивных AI/ML-приложениях, подтверждают, что их применение в AI/ML получит наибольший прирост в следующем году (по сравнению с прочими приложениями).
Из этого довольно интересного опроса видно, что восприятие сценариев машинного обучения и искусственного интеллекта как лидеров потребления потоков данных уже «на подходе». Но не менее важным наблюдением становится и восприятие AI/ML реального времени через оптику DevOps: здесь уже можно начинать говорить о трансформации господствующей пока еще культуры «одноразового AI/ML с полностью доступным набором данных».
Одной из типичных областей применения AI/ML реального времени является управление технологическими процессами на производстве. На ее примере и с учетом предыдущих размышлений, сформулируем концепцию AI/ML-платформы реального времени.
Использование искусственного интеллекта и машинного обучения в управлении технологическими процессами имеет ряд особенностей:
Эти особенности заставляют нас, помимо приема и базовой обработки в реальном времени интенсивного «широкополосного входящего сигнала» от технологического процесса, выполнять (параллельно) применение, обучение и контроль качества результатов работы AI/ML-моделей – также в режиме реального времени. Тот «кадр», который наши модели «видят» в скользящем окне актуальности, постоянно меняется – а вместе с ним меняется и качество результатов работы AI/ML-моделей, обученных на одном из «кадров» в прошлом. При ухудшении качества результатов работы AI/ML-моделей (например: значение ошибки классификации «тревога-норма» вышло за определенные нами границы) должно автоматически быть запущено дообучение моделей на более актуальном «кадре» — и выбор момента для запуска дообучения моделей должен учитывать как продолжительность самого обучения, так и динамику ухудшения качества работы текущей версии моделей (т.к. текущие версии моделей продолжают применяться, пока модели обучаются, и пока не будут сформированы их «заново обученные» версии).
InterSystems IRIS обладает ключевыми платформенными возможностями для обеспечения работы AI/ML-решений при управлении технологическими процессами в режиме реального времени. Эти возможности можно разделить на три основные группы:
Классификация платформенных возможностей применительно к машинному обучению и искусственному интеллекту именно по таким группам неслучайна. Процитируем методологическую публикацию компании Google, в которой подводится концептуальная основа под эту классификацию, в нашем переводе:
«… Популярная в наши дни концепция DevOps охватывает разработку и эксплуатацию масштабных информационных систем. Преимуществами внедрения этой концепции становятся сокращение длительности циклов разработки, ускорение развертывания разработок, гибкость планирования релизов. Для получения этих преимуществ DevOps предполагает внедрение, как минимум, двух практик:
Эти практики также применимы и к AI/ML-платформам – в целях обеспечения надежной и производительной сборки продуктивных AI/ML-решений.
AI/ML-платформы отличаются от остальных информационных систем в следующих аспектах:
AI/ML-платформы схожи с другими информационными системами в том, что и тем, и другим необходима непрерывная интеграция кода с контролем версий, модульное тестирование, интеграционное тестирование, непрерывное развертывание разработок. Тем не менее, в случае с AI/ML, есть несколько важных отличий:
Мы можем констатировать, что машинное обучение и искусственный интеллект, работающие на данных реального времени, требуют более широкого набора инструментов и компетенций (от разработки кода до оркестровки сред математического моделирования), более тесной интеграции между всеми функциональными и предметными областями, более эффективной организации человеческих и машинных ресурсов.
Продолжая использовать в качестве примера область управления технологическими процессами, рассмотрим конкретную задачу (уже упоминалась нами в самом начале): требуется обеспечить в реальном времени мониторинг развития дефектов в насосах на основе потока значений параметров технологического процесса и отчетов ремонтного персонала о выявленных дефектах.
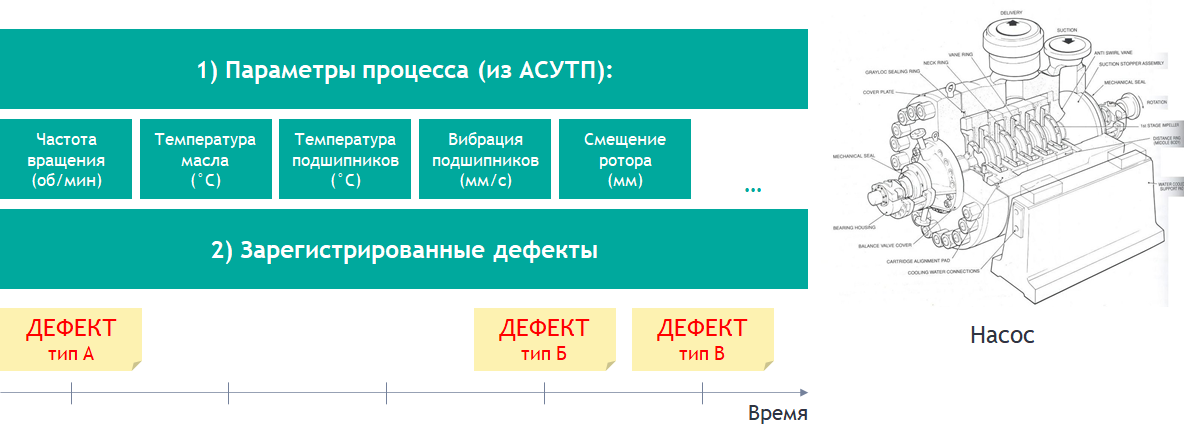
Рисунок 2 Формулировка задачи по мониторингу развития дефектов
Особенностью большинства подобным образом поставленных задач на практике является то, что регулярность и оперативность поступления данных (АСУТП) должны рассматриваться на фоне эпизодичности и нерегулярности возникновения (и регистрации) дефектов различных типов. Другими словами: данные из АСУТП приходят раз в секунду правильные-точные, а о дефектах делаются записи химическим карандашом с указанием даты в общей тетради в цеху (например: «12.01 – течь в крышку со стороны 3-го подшипника»).
Таким образом, можно дополнить формулировку задачи следующим важным ограничением: «метка» дефекта конкретного типа у нас всего одна (т. е. пример дефекта конкретного типа представлен данными из АСУТП на конкретную дату – и больше примеров дефекта именно этого типа у нас нет). Данное ограничение сразу выводит нас за рамки классического машинного обучения (supervised learning), для которого «меток» должно быть много.
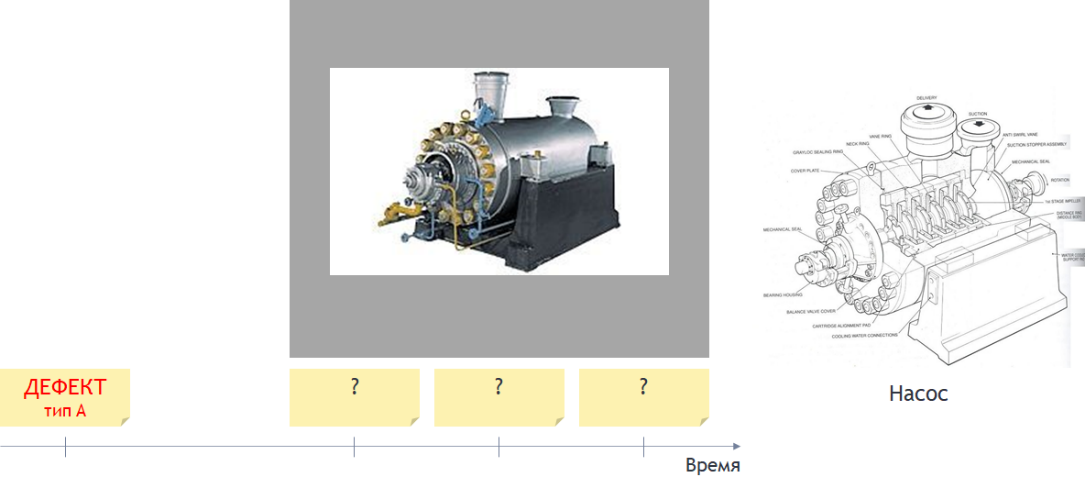
Рисунок 3 Уточнение задачи по мониторингу развития дефектов
Можем ли мы каким-то образом «размножить» имеющуюся в нашем распоряжении единственную «метку»? Да, можем. Текущее состояние насоса характеризуется степенью подобия зарегистрированным дефектам. Даже без применения количественных методов, на уровне зрительного восприятия, наблюдая за динамикой значений данных, прибывающих из АСУТП, уже можно многое почерпнуть:
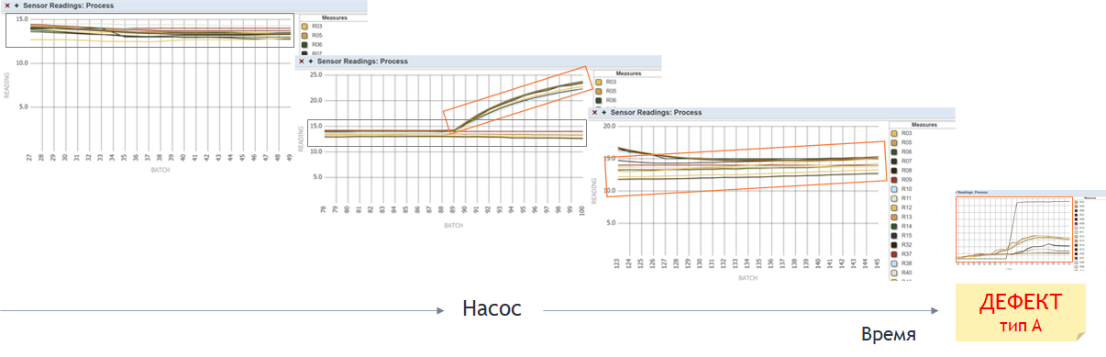
Рисунок 4 Динамика состояния насоса на фоне «метки» дефекта заданного типа
Но зрительное восприятие (по крайней мере, пока) – не самый подходящий генератор «меток» в нашем быстроменяющемся сценарии. Мы будем оценивать подобие текущего состояния насоса зарегистрированным дефектам при помощи статистического теста.
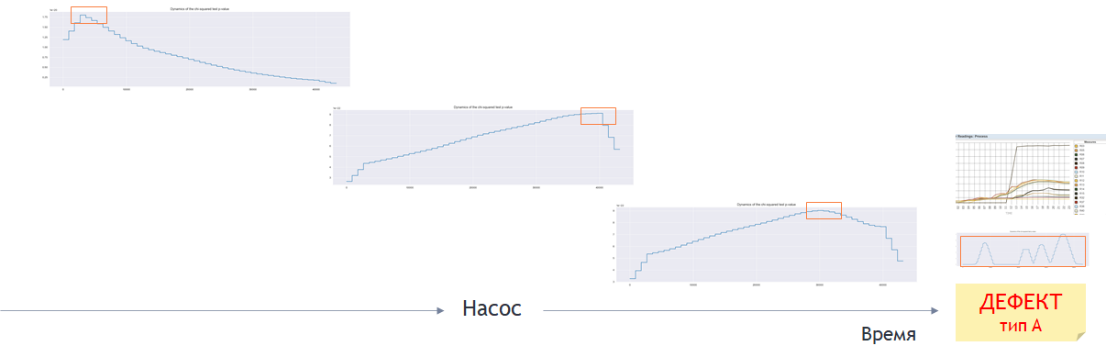
Рисунок 5 Применение статистического теста к поступающим данным на фоне «метки» дефекта
Статистический тест определяет вероятность того, что записи со значениями параметров технологического процесса в полученном из АСУТП «поток-пакете» подобны записям «метки» дефекта определенного типа. Вычисленное в результате применения статистического теста значение вероятности (индекс статистического подобия) преобразуется к значению 0 или 1, становясь «меткой» для машинного обучения в каждой конкретной записи в исследуемом на подобие пакете. Т. е. после обработки вновь поступившего к нам пакета записей состояния насоса статистическим тестом у нас появляется возможность (а) добавить данный пакет в обучающую выборку для обучения AI/ML-модели и (б) осуществить контроль качества работы текущей версии модели при ее применении к данному пакету.
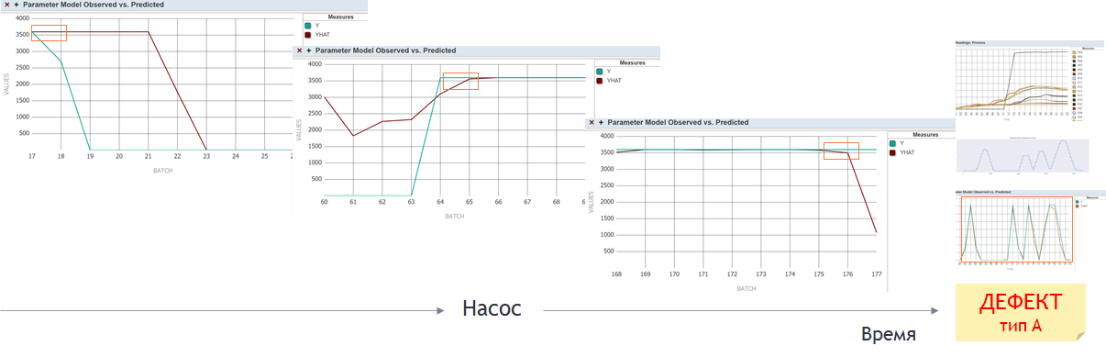
Рисунок 6 Применение модели машинного обучения к поступающим данным на фоне «метки» дефекта
В одном из наших предыдущих вебинаров мы показываем и объясняем, каким образом платформа InterSystems IRIS позволяет реализовать любой AI/ML-механизм в виде непрерывно исполняемых бизнес-процессов, осуществляющих контроль достоверности результатов моделирования и адаптирующих параметры моделей. При реализации прототипа нашего сценария с насосами мы используем весь представленный в ходе вебинара функционал InterSystems IRIS – имплементируя в процессе-анализаторе в составе нашего решения не классический supervised learning, а скорее обучение с подкреплением (reinforcement learning), автоматически управляющее выборкой для обучения моделей. В выборку для обучения помещаются записи, на которых возникает «консенсус детекции» после применения и статистического теста, и текущей версии модели – т. е. и статистический тест (после трансформации индекса подобия к 0 или 1), и модель выдали на таких записях результат 1. При новом обучении модели, при ее валидации (заново обученная модель применяется к собственной обучающей выборке, с предварительным применением к ней же статистического теста), записи, «не удержавшие» после обработки статистическим тестом результат 1 (из-за постоянного присутствия в обучающей выборке записей из изначальной «метки» дефекта), из обучающей выборки удаляются, и новая версия модели учится на «метке» дефекта плюс на «удержавшихся» записях из потока.
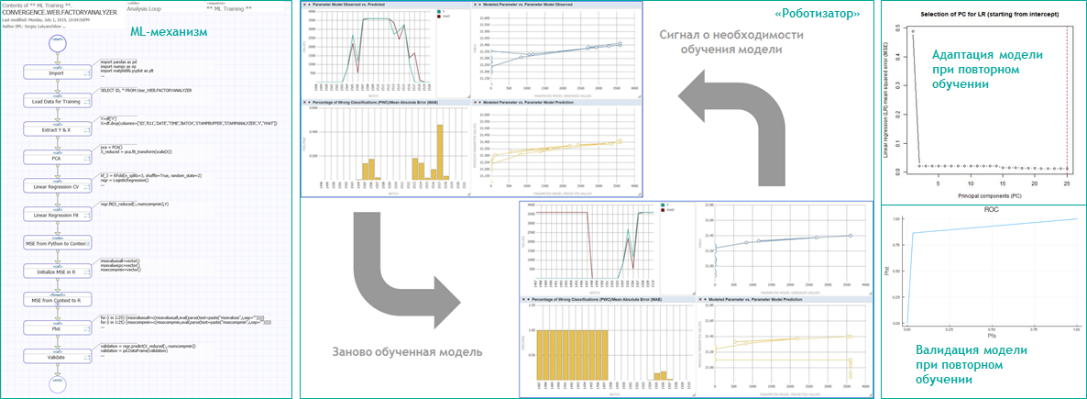
Рисунок 7 Роботизация AI/ML-вычислений в InterSystems IRIS
В случае, если возникает потребность в своего рода «втором мнении» по качеству детекции, получаемой при локальных вычислениях в InterSystems IRIS, создается процесс-советник для выполнения обучения-применения моделей на контрольном датасете с помощью облачных сервисов (например Microsoft Azure, Amazon Web Services, Google Cloud Platform и т. п.):

Рисунок 8 «Второе мнение» из Microsoft Azure под оркестровкой InterSystems IRIS
Прототип нашего сценария в InterSystems IRIS выполнен в виде агентной системы аналитических процессов, осуществляющих взаимодействия с объектом оборудования (насосом), средами математического моделирования (Python, R и Julia), и обеспечивающих самообучение всех задействованных AI/ML-механизмов – на потоках данных реального времени.
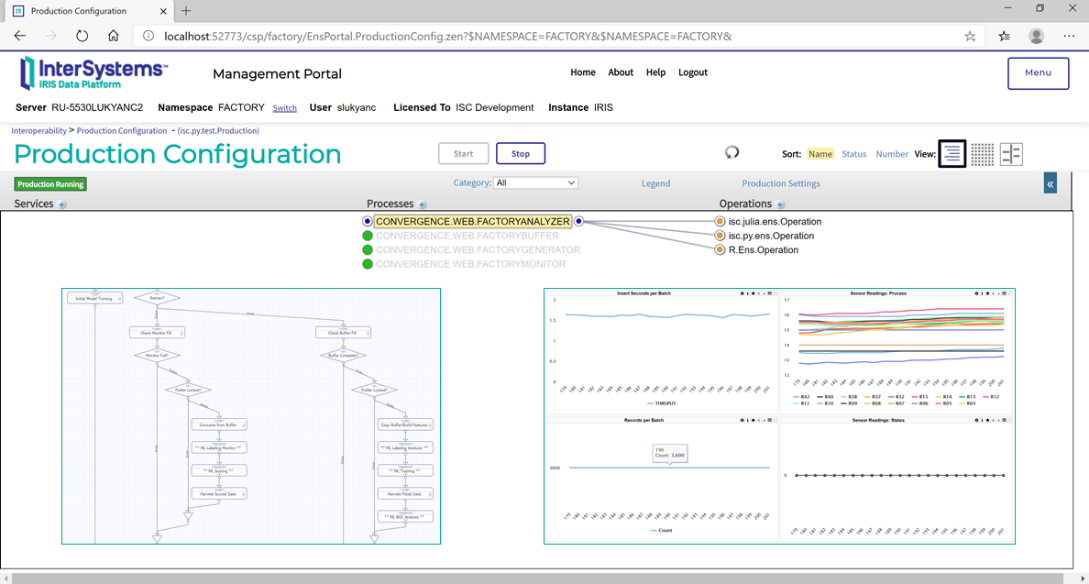
Рисунок 9 Основной функционал AI/ML-решения реального времени в InterSystems IRIS
Практический результат работы нашего прототипа:
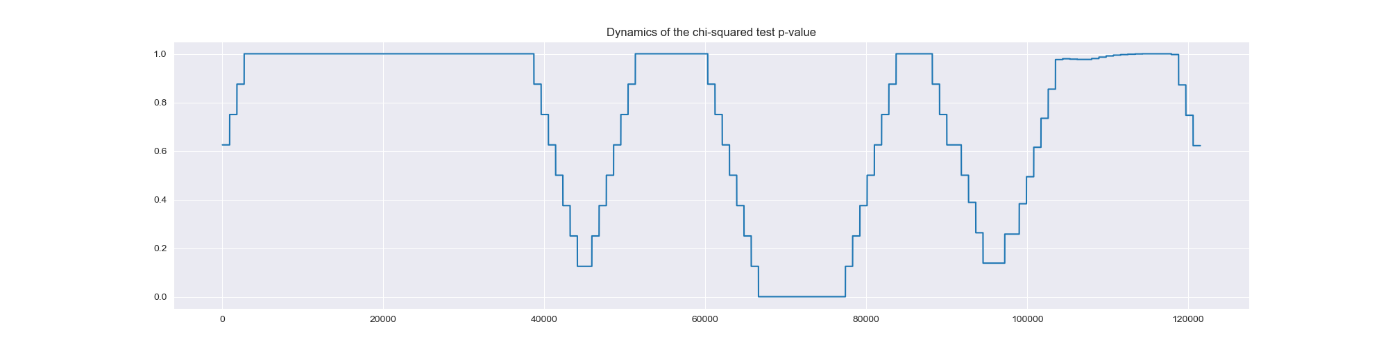
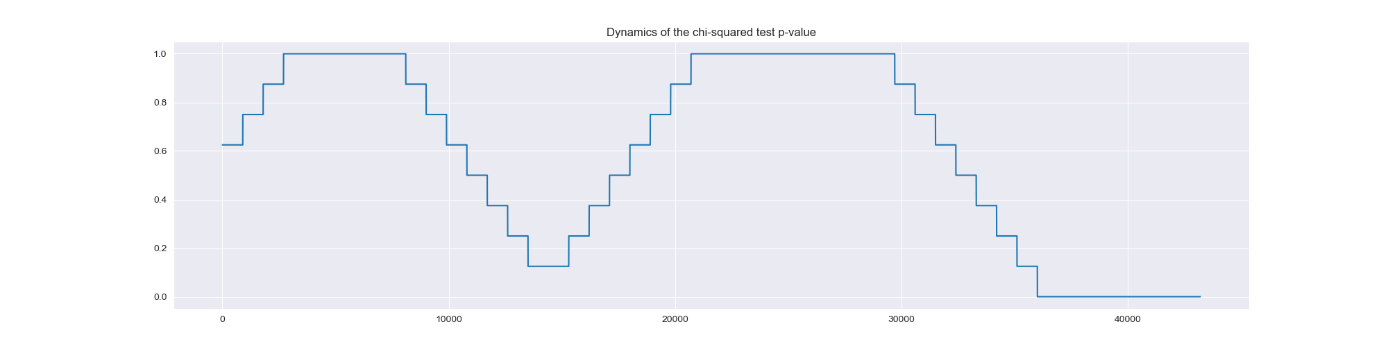
Имитация на реальных данных, содержащих несколько эпизодов одного и того же дефекта, показала, что наше решение, реализованное на платформе InterSystems IRIS, позволяет выявить развитие дефектов данного типа за несколько суток до момента их обнаружения ремонтной бригадой.
Платформа InterSystems IRIS упрощает разработку, развертывание и эксплуатацию решений на данных реального времени. InterSystems IRIS способна одновременно выполнять транзакционную и аналитическую обработку данных; поддерживать синхронизированные представления данных в соответствии с несколькими моделями (в т.ч. реляционной, иерархической, объектной и документной); выступать платформой интеграции широкого спектра источников данных и отдельных приложений; обеспечивать развитую аналитику в реальном времени на структурированных и неструктурированных данных. InterSystems IRIS также предоставляет механизмы для применения внешнего аналитического инструментария, позволяет гибко сочетать размещение в облаке и на локальных серверах.
Приложения, построенные на платформе InterSystems IRIS, внедрены в различных отраслях, помогая компаниям получать существенный экономический эффект в стратегической и операционной перспективах, повышая информированность принятия решений и устраняя «зазоры» между событием, анализом и действием.
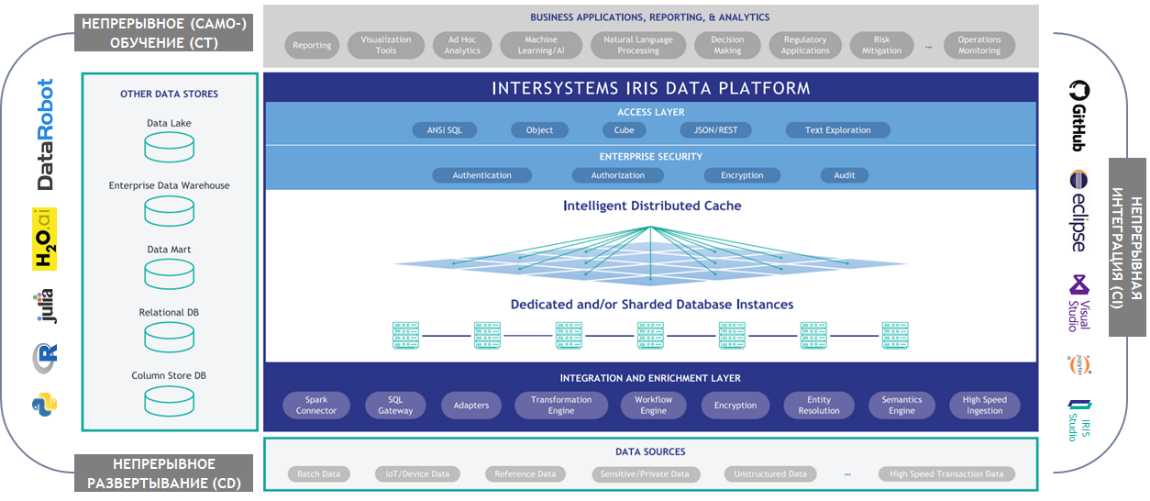
Рисунок 10 Архитектура InterSystems IRIS в контексте AI/ML реального времени
Как и предыдущая диаграмма, нижеприведенная диаграмма сочетает новую «систему координат» (CD/CI/CT) со схемой потоков информации между рабочими элементами платформы. Визуализация начинается с макромеханизма CD и продолжается макромеханизмами CI и СТ.
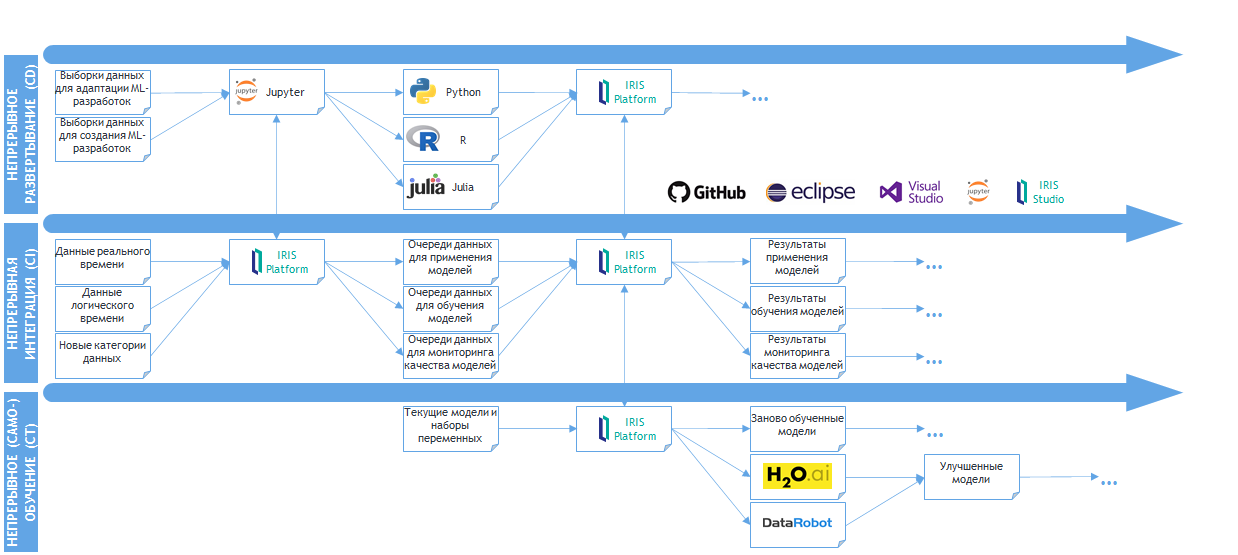
Рисунок 11 Схема потоков информации между AI/ML-элементами платформы InterSystems IRIS
Суть механизма CD в InterSystems IRIS: пользователи платформы (разработчики AI/ML-решений) адаптируют уже имеющиеся и/или создают новые AI/ML-разработки с применением специализированного редактора программного кода AI/ML-механизмов: Jupyter (полное наименование: Jupyter Notebook; так же, для краткости, иногда называются и документы, созданные в данном редакторе). В Jupyter разработчик имеет возможность написать, отладить и убедиться в работоспособности (в т. ч., с использованием графики) конкретной AI/ML-разработки до ее размещения («развертывания») в InterSystems IRIS. Понятно, что создаваемая таким образом новая разработка будет получать только базовую отладку (т. к., в частности, Jupyter не работает с потоками данных реального времени) – это в порядке вещей, ведь основным результатом разработки в Jupyter становится подтверждение принципиальной работоспособности отдельного AI/ML-механизма («на выборке данных показывает ожидаемый результат»). Аналогичным образом, уже размещенный в платформу механизм (см. следующие макромеханизмы) перед отладкой в Jupyter может потребовать «отката» к «доплатформенному» виду (чтение данных из файлов, работа с данными через xDBC вместо таблиц, непосредственное взаимодействие с глобалами – многомерными массивами данных InterSystems IRIS – и т. п.).
Важный аспект имплементации CD именно в InterSystems IRIS: между платформой и Jupyter реализована двунаправленная интеграция, позволяющая переносить в платформу (и, в дальнейшем, обрабатывать в платформе) контент на языках Python, R и Julia (все три являются языками программирования в соответствующих ведущих open-source средах математического моделирования). Таким образом, разработчики AI/ML-контента имеют возможность осуществлять «непрерывное развертывание» этого контента в платформе, работая в привычном им редакторе Jupyter, с привычными библиотеками, доступными в Python, R, Julia, и выполняя базовую отладку (при необходимости) вне платформы.
Переходим к макромеханизму CI в InterSystems IRIS. На диаграмме изображен макропроцесс работы «роботизатора реального времени» (комплекс из структур данных, бизнес-процессов и оркестрируемых ими фрагментов кода на языках матсред и языке ObjectScript – нативном языке разработки InterSystems IRIS). Задача этого макропроцесса: поддерживать необходимые для работы AI/ML-механизмов очереди данных (на основе потоков данных, передаваемых платформе в реальном времени), принимать решения о последовательности применения и «ассортименту» механизмов AI/ML (они же «математические алгоритмы», «модели» и т. д. – могут называться по-разному в зависимости от конкретики реализации и от терминологических предпочтений), поддерживать в актуальном состоянии структуры данных для анализа результатов работы AI/ML-механизмов (кубы, таблицы, многомерные массивы данных и т. д. – для отчетов, дэшбордов и т. п.).
Важный аспект имплементации CI именно в InterSystems IRIS: между платформой и средами математического моделирования реализована двунаправленная интеграция, позволяющая исполнять размещенный в платформе контент на языках Python, R и Julia в их соответствующих средах с получением обратно результатов исполнения. Эта интеграция реализована как в «режиме терминала» (т. е. AI/ML-контент формулируется как код на ObjectScript, осуществляющий вызовы матсред), так и в «режиме бизнес-процесса» (т. е. AI/ML-контент формулируется как бизнес-процесс при помощи графического редактора, или иногда при помощи Jupyter, или при помощи IDE – IRIS Studio, Eclipse, Visual Studio Code). Доступность бизнес-процессов для редактирования в Jupyter отражена при помощи связи между IRIS на уровне CI и Jupyter на уровне CD. Более детальный обзор интеграции со средами математического моделирования производится далее. На данном этапе, на наш взгляд, есть все основания для того, чтобы зафиксировать наличие в платформе всех необходимых инструментов для реализации «непрерывной интеграции» AI/ML-разработок (приходящих из «непрерывного развертывания») в AI/ML-решения реального времени.
И главный макромеханизм: CT. Без него не получится AI/ML-платформы (хоть «реальное время» и будет имплементировано через CD/CI). Сутью CT является работа платформы с «артефактами» машинного обучения и искусственного интеллекта непосредственно в рабочих сессиях сред математического моделирования: моделями, таблицами распределений, векторами-матрицами, слоями нейросетей и т.п. Данная «работа», в большинстве случаев, состоит в создании упомянутых артефактов в средах (в случае моделей, например, «создание» состоит из задания спецификации модели и последующего подбора значений ее параметров – так называемого «обучения» модели), их применении (для моделей: расчет при их помощи «модельных» значений целевых переменных – прогнозов, принадлежности к категории, вероятности наступления события и т.п.) и усовершенствовании уже созданных и примененных артефактов (например, переопределение набора входных переменных модели по результатам применения – в целях повышения точности прогнозирования, как вариант). Ключевым моментом в понимании роли CT является его «абстрагированность» от реалий CD и CI: CT будет имплементировать все артефакты, ориентируясь на вычислительную и математическую специфику AI/ML-решения в рамках возможностей, предоставляемых конкретными средами. Ответственность за «снабжение входными данными» и «доставку результатов» будут нести CD и CI.
Важный аспект имплементации CT именно в InterSystems IRIS: пользуясь уже упомянутой выше интеграцией со средами математического моделирования, платформа имеет возможность извлекать из рабочих сессий, протекающих под ее управлением в матсредах, те самые артефакты и (самое важное) превращать их в объекты данных платформы. Например, таблица распределения, которая создалась только что в рабочей сессии Python может быть (без остановки сессии в Python) перенесена в платформу в виде, например, глобала (многомерного массива данных InterSystems IRIS), – и использована для вычислений в другом AI/ML-механизме (реализованном уже на языке другой среды – например, на R) – или виртуальной таблицы. Другой пример: в параллель со «штатным режимом» работы модели (в рабочей сессии Python), на ее входных данных осуществляется «авто-ML »: автоматический подбор оптимальных входных переменных и значений параметров. И вместе со «штатным» обучением, продуктивная модель в режиме реального времени получает еще и «предложение по оптимизации» своей спецификации – в которой меняется набор входных переменных, меняются значения параметров (уже не в результате обучения в Python, а в результате обучения «альтернативной» версии ее самой, например, в стеке H2O), позволяя общему AI/ML-решению автономно справляться с непредвиденными изменениями в характере входных данных и моделируемых явлений.
Познакомимся более подробно с платформенным AI/ML-функционалом InterSystems IRIS, на примере реально существующего прототипа.
На нижеприведенной диаграмме, в левой части слайда – часть бизнес-процесса, имплементирующая отработку скриптов на Python и R. В центральной части – визуальные логи исполнения некоторых из этих скриптов, соответственно, на Python и на R. Сразу за ними – примеры контента на одном и другом языке, переданные на исполнение в соответствующие среды. В конце справа – визуализации, основанные на результатах исполнения скриптов. Визуализации вверху – сделаны на IRIS Analytics (данные забраны из Python в платформу данных InterSystems IRIS и выведены на дэшборд средствами платформы), внизу – сделаны прямо в рабочей сессии R и выведены оттуда в графические файлы. Важный аспект: представленный фрагмент в прототипе отвечает за обучение модели (классификация состояний оборудования) на данных, поступающих в реальном времени от процесса-имитатора оборудования, по команде от процесса-монитора качества классификации, наблюдаемого в ходе применении модели. Об имплементации AI/ML-решения в виде набора взаимодействующих процессов («агентов») речь пойдет далее.
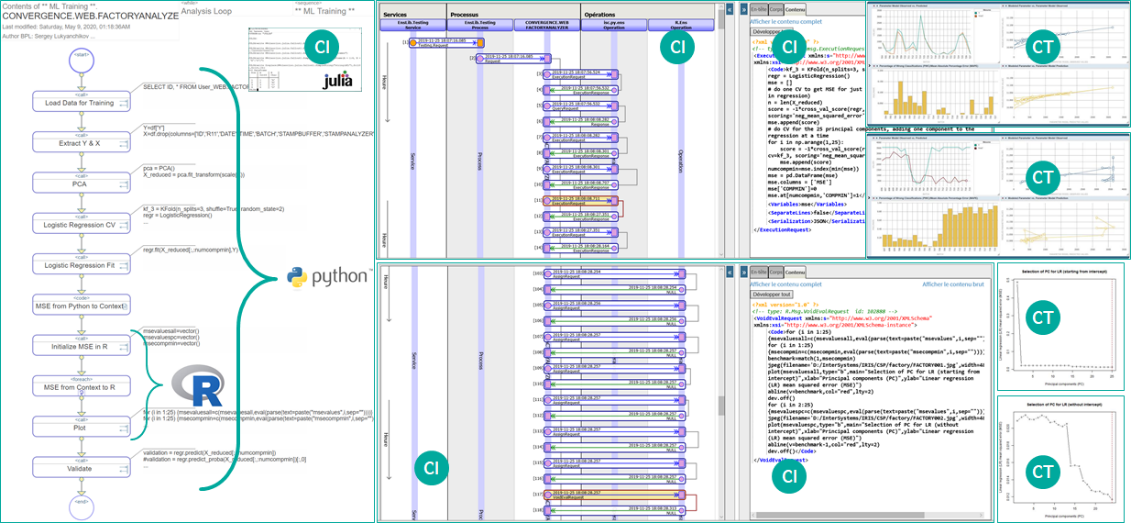
Рисунок 12 Взаимодействие с Python, R и Julia в InterSystems IRIS
Платформенные процессы (они же «бизнес-процессы», «аналитические процессы», «пайплайны» и т.п. – в зависимости от контекста), прежде всего, редактируемы в графическом редакторе бизнес-процессов в самой платформе, причем таким образом, что создаются одновременно и его блок-схема, и соответствующий AI/ML-механизм (программный код). Говоря о том, что «получается AI/ML-механизм», мы изначально подразумеваем гибридность (в рамках одного процесса): контент на языках сред математического моделирования соседствует с контентом на SQL (в т. ч., с расширениями от IntegratedML), на InterSystems ObjectScript, с другими поддерживаемыми языками. Более того, платформенный процесс дает очень широкие возможности для «отрисовки» в виде иерархически вложенных фрагментов (как видно в примере на приведенной ниже диаграмме), что позволяет эффективно организовывать даже весьма сложный контент, нигде не «выпадая» из графического формата (в «неграфические» методы/классы/процедуры и т. п.). Т. е. при необходимости (а она предвидится в большинстве проектов) абсолютно все AI/ML-решение может быть имплементировано в графическом самодукоментирующемся формате. Обращаем внимание на то, что в центральной части нижеприведенной диаграммы, на которой представлен более высокий «уровень вложенности», видно, что помимо собственно работы по обучению модели (при помощи Python и R), добавляется анализ так называемой ROC-кривой обученной модели, позволяющий визуально (и вычислительно тоже) оценить качество обучения – и этот анализ реализован на языке Julia (исполняется, соответственно, в матсреде Julia).
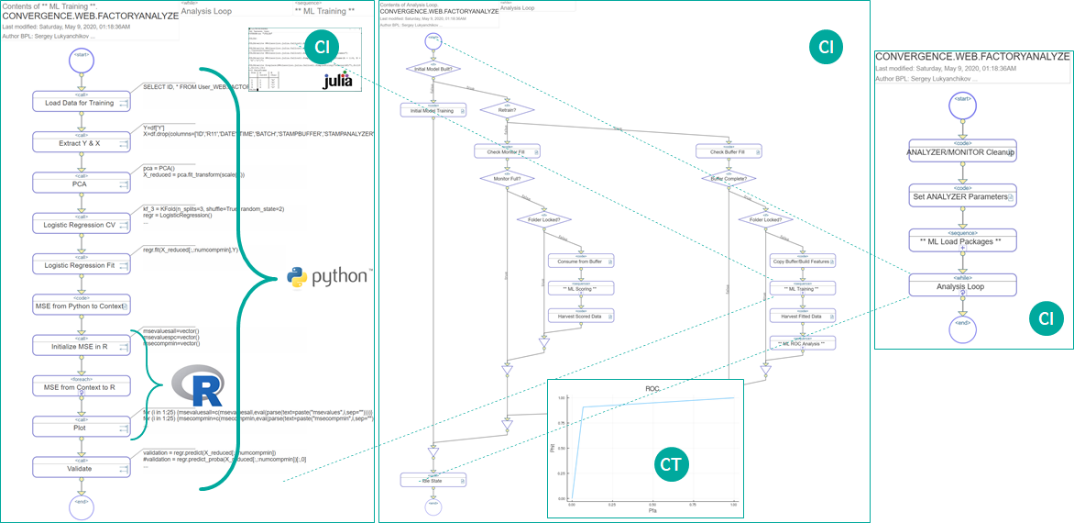
Рисунок 13 Визуальная среда композиции AI/ML-решений в InterSystems IRIS
Как уже упоминалось ранее, начальная разработка и (в ряде случаев) адаптация уже имплементированных в платформе AI/ML-механизмов будет/может производиться вне платформы в редакторе Jupyter. На диаграмме ниже мы видим пример адаптации существующего платформенного процесса (того же, что и на диаграмме выше) – таким образом выглядит в Jupyter тот его фрагмент, который отвечает за обучение модели. Контент на языке Python доступен для редактирования, отладки, вывода графики прямо в Jupyter. Изменения (при необходимости) могут производиться с мгновенной синхронизацией в платформенный процесс, в т. ч. в его продуктивную версию. Аналогичным образом может передаваться в платформу и новый контент (автоматически формируется новый платформенный процесс).
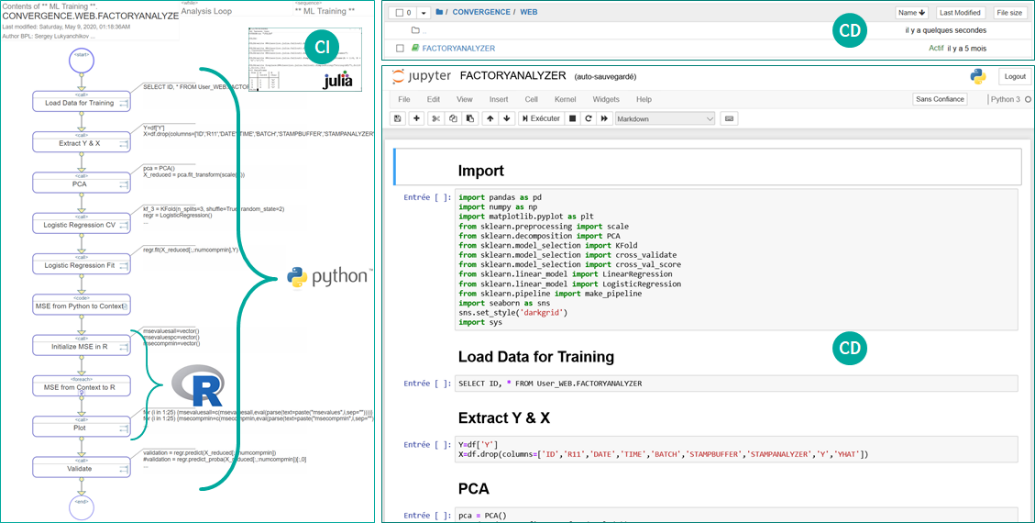
Рисунок 14 Применение Jupyter Notebook для редактирования AI/ML-механизма в платформе InterSystems IRIS
Адаптация платформенного процесса может выполняться не только в графическом или ноутбучном формате – но и в «тотальном» формате IDE (Integrated Development Environment). Такими IDE выступают IRIS Studio (нативная студия IRIS), Visual Studio Code (расширение InterSystems IRIS для VSCode) и Eclipse (плагин Atelier). В ряде случаев возможно одновременное использование командой разработчиков всех трех IDE. На диаграмме ниже показан пример редактирования все того же процесса в студии IRIS, в Visual Studio Code и в Eclipse. Для редактирования доступен абсолютно весь контент: и Python/R/Julia/SQL, и ObjectScript, и бизнес-процесс.
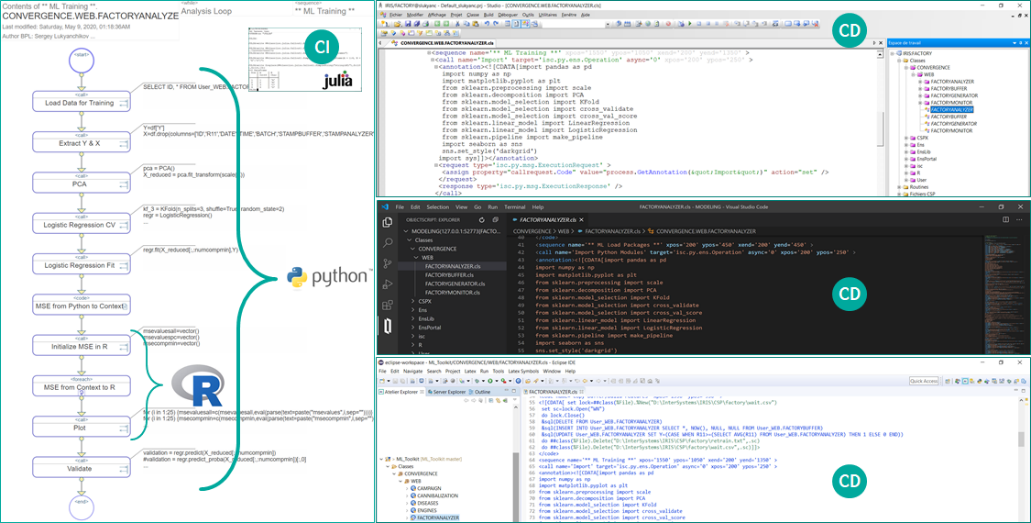
Рисунок 15 Разработка бизнес-процесса InterSystems IRIS в различных IDE
Отдельного упоминания заслуживают средства описания и исполнения бизнес-процессов InterSystems IRIS на языке Business Process Language (BPL). BPL дает возможность использовать в бизнес-процессах «готовые интеграционные компоненты» (activities) – что, собственно говоря, и дает полные основания утверждать, что в InterSystems IRIS реализована «непрерывная интеграция». Готовые компоненты бизнес-процесса (активности и связи между ними) являются мощнейшим акселератором сборки AI/ML-решения. И не только сборки: благодаря активностям и связям между ними над разрозненными AI/ML-разработками и механизмами возникает «автономный управленческий слой», способный принимать решения сообразно ситуации, в реальном времени.
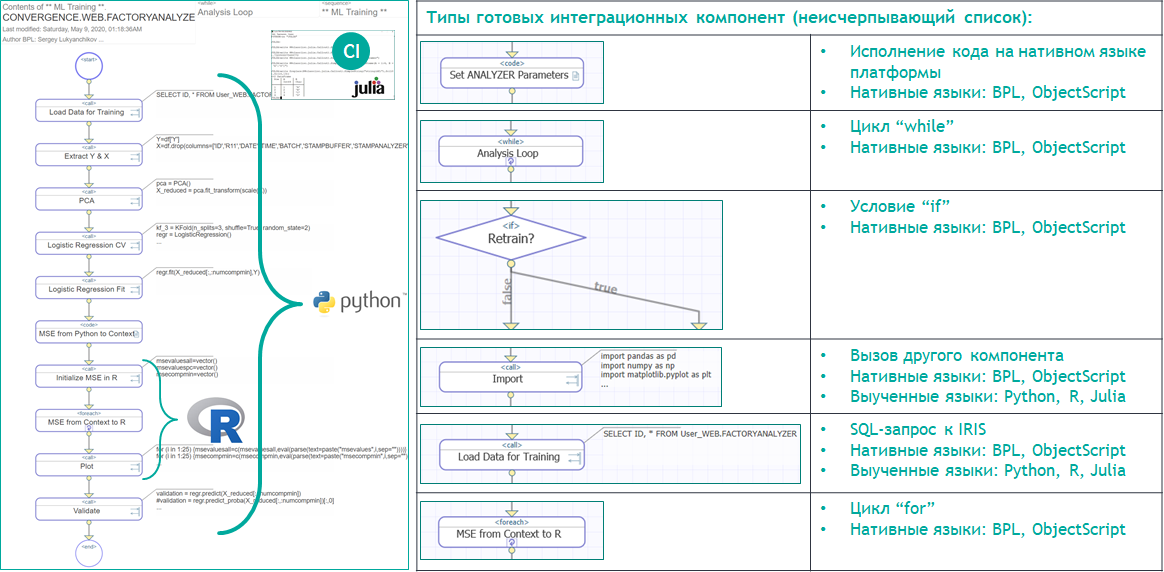
Рисунок 16 Готовые компоненты бизнес-процессов для непрерывной интеграции (CI) на платформе InterSystems IRIS
Концепция агентных систем (они же «мультиагентные системы») имеет сильные позиции в роботизации, и платформа InterSystems IRIS органично ее поддерживает через конструкт «продукция-процесс». Помимо неограниченных возможностей для «начинки» каждого процесса необходимым для общего решения функционалом, наделение системы платформенных процессов свойством «агентности» позволяет создавать эффективные решения для крайне нестабильных моделируемых явлений (поведение социальных/биосистем, частично наблюдаемых технологических процессов и т. п.).
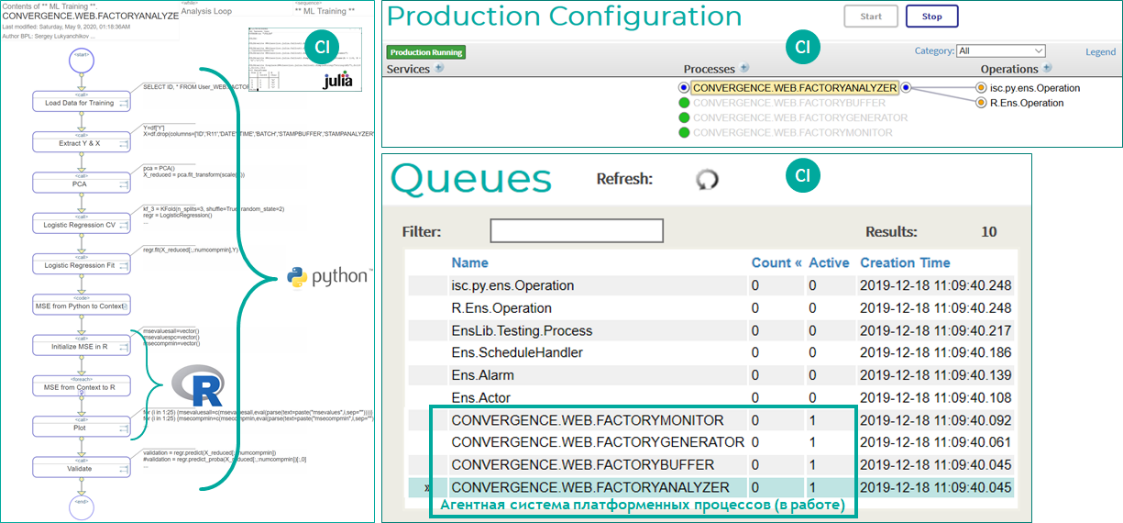
Рисунок 17 Работа AI/ML-решения в виде агентной системы бизнес-процессов в InterSystems IRIS
Мы продолжаем наш обзор InterSystems IRIS рассказом о прикладном использовании платформы для решения целых классов задач реального времени (довольно подробное знакомство с некоторыми лучшими практиками платформенного AI/ML на InterSystems IRIS происходит в одном из наших предыдущих вебинаров).
По «горячим следам» предыдущей диаграммы, ниже приведена более подробная диаграмма агентной системы. На диаграмме изображен все тот же прототип, видны все четыре процесса-агента, схематически отрисованы взаимоотношения между ними: GENERATOR – отрабатывает создание данных датчиками оборудования, BUFFER – управляет очередями данных, ANALYZER – выполняет собственно машинное обучение, MONITOR – контролирует качество машинного обучения и подает сигнал о необходимости повторного обучения модели.

Рисунок 18 Композиция AI/ML-решения в виде агентной системы бизнес-процессов в InterSystems IRIS
На диаграмме ниже проиллюстрировано автономное функционирование уже другого роботизированного прототипа (распознавание эмоциональной окраски текстов) на протяжении некоторого времени. В верхней части – эволюция показателя качества обучения модели (качество растет), в нижней части – динамика показателя качества применения модели и факты повторного обучения (красные полоски). Как можно видеть, решение эффективно и автономно самообучилось, и работает на заданном уровне качества (значения показателя качества не падают ниже 80%).
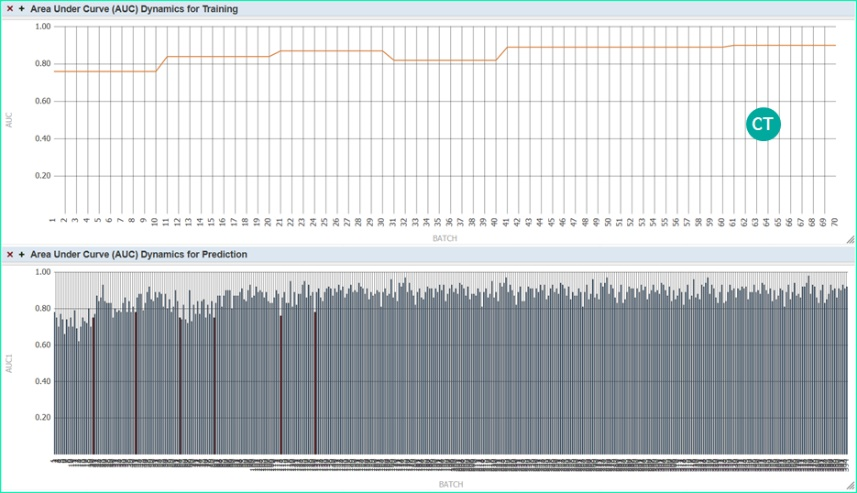
Рисунок 19 Непрерывное (само-)обучение (CT) на платформе InterSystems IRIS
Об «авто-ML» мы тоже упоминали ранее, но на нижеприведенной диаграмме применение данного функционала показано в подробностях на примере еще одного прототипа. На графической схеме фрагмента бизнес-процесса показана активность, запускающая моделирование в стеке H2O, показаны результаты этого моделирования (явное доминирование полученной модели над «рукотворными» моделями, согласно сравнительной диаграмме ROC-кривых, а также автоматизированное выявление «наиболее влиятельных переменных» из доступных в исходном наборе данных). Важным моментом здесь является та экономия времени и экспертных ресурсов, которая достигается за счет «авто-ML»: то, что наш платформенный процесс делает за полминуты (нахождение и обучение оптимальной модели), у эксперта может занять от недели до месяца.
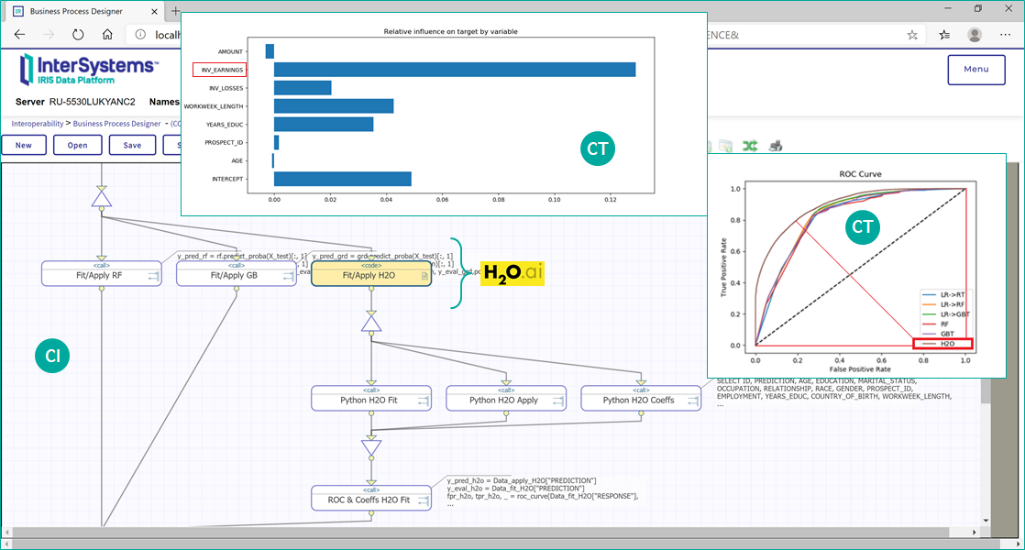
Рисунок 20 Интеграция «авто-ML» в AI/ML-решение на платформе InterSystems IRIS
Диаграмма ниже немного «сбивает кульминацию», но это хороший вариант завершения рассказа о классах решаемых задач реального времени: мы напоминаем о том, что при всех возможностях платформы InterSystems IRIS, обучение моделей именно под ее управлением не является обязательным. Платформа может получить извне так называемую PMML-спецификацию модели, обученную в инструменте, не находящемся под управлением платформы – и применять эту модель в реальном времени с момента импорта ее PMML-спецификации. При этом важно учесть, что далеко не все AI/ML-артефакты могут быть сведены к PMML-спецификации, даже если большинство наиболее распространенных артефактов это позволяют сделать. Таким образом платформа InterSystems IRIS имеет «открытый контур» и не означает «платформенного рабства» для пользователей.
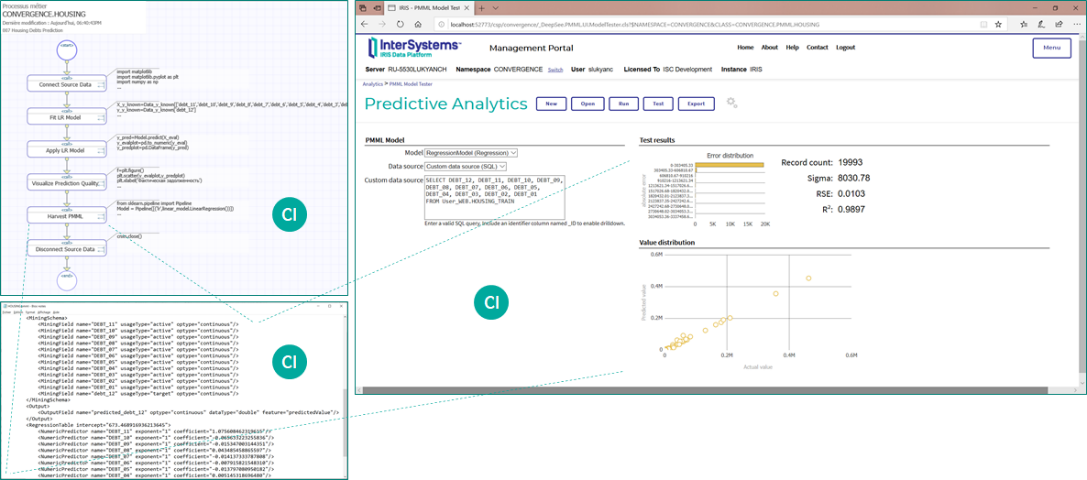
Рисунок 21 Применение модели по PMML-спецификации в платформе InterSystems IRIS
Перечислим дополнительные платформенные преимущества InterSystems IRIS (для наглядности, применительно к управлению технологическими процессами), имеющие большое значение при автоматизации искусственного интеллекта и машинного обучения реального времени:
AI/ML-решения на платформе InterSystems IRIS легко вписываются в существующую ИТ-инфраструктуру. Платформа InterSystems IRIS обеспечивает высокую надежность AI/ML-решений за счет поддержки отказоустойчивых и катастрофоустойчивых конфигураций и гибкое развертывание в виртуальных средах, на физических серверах, в частных и публичных облаках, Docker-контейнерах.
Таким образом, InterSystems IRIS является универсальной платформой AI/ML-вычислений реального времени. Универсальность нашей платформы подтверждается на практике отсутствием де-факто ограничений по сложности имплементируемых вычислений, способностью InterSystems IRIS совмещать (в режиме реального времени) обработку сценариев из самых различных отраслей, исключительной адаптируемостью любых функций и механизмов платформы под конкретные потребности пользователей.
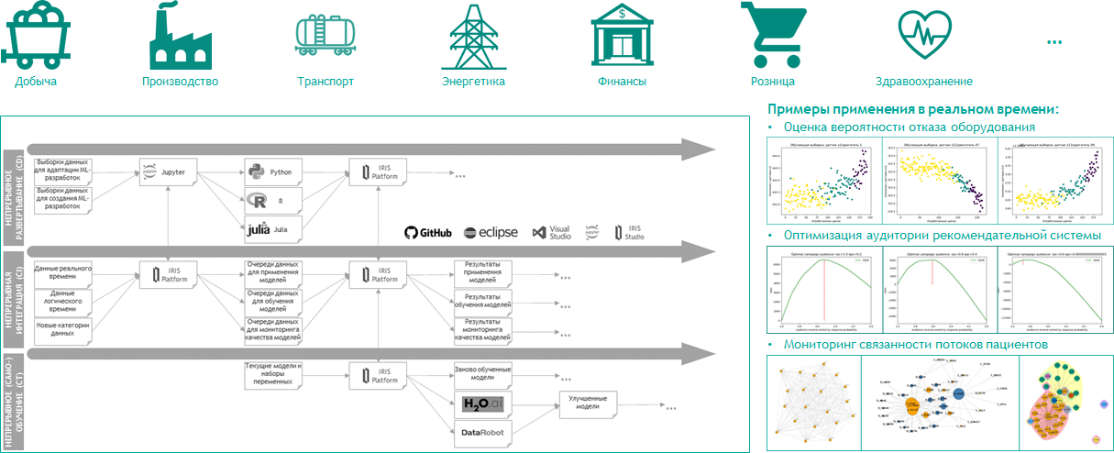
Рисунок 22 InterSystems IRIS — универсальная платформа AI/ML-вычислений реального времени
Для более предметного взаимодействия с теми из наших читателей, кого заинтересовал представленный здесь материал, мы рекомендуем не ограничиваться его прочтением и продолжить диалог «вживую». Мы с готовностью окажем поддержку с формулировкой сценариев AI/ML реального времени применительно к специфике вашей компании, выполним совместное прототипирование на платформе InterSystems IRIS, сформируем и реализуем на практике дорожную карту внедрения искусственного интеллекта и машинного обучения в ваши производственные и управленческие процессы. Контактный адрес электронной почты нашей экспертной группы AI/ML – MLToolkit@intersystems.com.
Вызовы AI/ML-вычислений реального времени
Начнем с примеров из опыта Data Science-практики компании InterSystems:
- «Нагруженный» портал покупателя подключен к онлайновой рекомендательной системе. Предстоит реструктуризация промо-акций в масштабе розничной сети (допустим, вместо «плоской» линейки промо-акций теперь будет применяться матрица «сегмент-тактика»). Что происходит с рекомендательными механизмами? Что происходит с подачей и актуализацией данных в рекомендательный механизм (объем входных данных возрос в 25000 раз)? Что происходит с выработкой рекомендаций (необходимость тысячекратного снижения порога фильтрации рекомендательных правил в связи с тысячекратным возрастанием их количества и «ассортимента»)?
- Есть система мониторинга вероятности развития дефектов в узлах оборудования. К системе мониторинга была подключена АСУТП, передающая тысячи параметров технологического процесса ежесекундно. Что происходит с системой мониторинга, ранее работавшей на «ручных выборках» (способна ли она обеспечивать ежесекундный мониторинг вероятности)? Что будет происходить, если во входных данных появляется новый блок в несколько сотен колонок с показаниями датчиков, недавно заведенных в АСУТП (потребуется ли и как надолго останавливать систему мониторинга для включения в анализ данных от новых датчиков)?
- Создан комплекс AI/ML-механизмов (рекомендательные, мониторинговые, прогностические), использующих результаты работы друг друга. Сколько человеко-часов требуется ежемесячно для адаптации работы этого комплекса к изменениям во входных данных? Каково общее «замедление» при поддержке комплексом принятия управленческих решений (частота возникновения в нем новой поддерживающей информации относительно частоты возникновения новых входных данных)?
Резюмируя эти и множество других примеров, мы пришли к формулировкам тех вызовов, которые возникают при переходе к использованию механизмов машинного обучения и искусственного интеллекта в реальном времени:
- Устраивает ли нас оперативность создания и адаптации (к меняющейся ситуации) AI/ML-разработок в нашей компании?
- Насколько используемые нами AI/ML-решения поддерживают управление бизнесом в режиме реального времени?
- Способны ли используемые нами AI/ML-решения самостоятельно (без разработчиков) адаптироваться к изменениям в данных и в практике управления бизнесом?
Наша статья – это обстоятельный обзор возможностей платформы InterSystems IRIS в части универсальной поддержки развертывания AI/ML-механизмов, сборки (интеграции) AI/ML-решений и обучения (тестирования) AI/ML-решений на интенсивных потоках данных. Мы обратимся к исследованиям рынка, к практическим примерам AI/ML-решений и концептуальным аспектам того, что мы называем в этой статье AI/ML-платформой реального времени.
Что известно из опросов: приложения реального времени
Результаты опроса, проведенного среди около 800 ИТ-профессионалов в 2019 году компанией Lightbend, говорят сами за себя:

Рисунок 1 Лидирующие потребители данных реального времени
Процитируем важные для нас фрагменты отчета о результатах этого опроса в нашем переводе:
«… Тенденции популярности средств интеграции потоков данных и, одновременно, поддержки вычислений в контейнерах дают синергетический отклик на запрос рынком более оперативного, рационального, динамичного предложения эффективных решений. Потоки данных позволяют быстрее передать информацию, чем традиционные пакетные данные. К этому добавляется возможность оперативного применения вычислительных методов, таких как, например, основанные на AI/ML рекомендации, создавая конкурентные преимущества за счет роста удовлетворенности клиентской аудитории. Гонка за оперативностью также влияет на все роли в парадигме DevOps – повышая эффективность разработки и развертывания приложений. … Восемьсот четыре ИТ-специалиста предоставили информацию по использованию потоков данных в их организациях. Респонденты находились преимущественно в западных странах (41% в Европе и 37% в Северной Америке) и были практически равномерно распределены между малыми, средними и крупными компаниями. …
… Искусственный интеллект – не хайп. Пятьдесят восемь процентов тех, кто уже применяет обработку потоков данных в продуктивных AI/ML-приложениях, подтверждают, что их применение в AI/ML получит наибольший прирост в следующем году (по сравнению с прочими приложениями).
- По мнению большинства опрошенных, применение потоков данных в сценариях AI/ML получит наибольший прирост в следующем году.
- Применение в AI/ML будет прирастать не только за счет относительно новых типов сценариев, но и за счет традиционных сценариев, в которых данные реального времени применяются все интенсивнее.
- В дополнение к AI/ML, уровень энтузиазма среди пользователей пайплайнов IoT-данных впечатляет — 48% из тех, кто уже интегрировал IoT-данные, утверждают, что реализация сценариев на этих данных получит существенный прирост в ближайшем будущем. … »
Из этого довольно интересного опроса видно, что восприятие сценариев машинного обучения и искусственного интеллекта как лидеров потребления потоков данных уже «на подходе». Но не менее важным наблюдением становится и восприятие AI/ML реального времени через оптику DevOps: здесь уже можно начинать говорить о трансформации господствующей пока еще культуры «одноразового AI/ML с полностью доступным набором данных».
Концепция AI/ML-платформы реального времени
Одной из типичных областей применения AI/ML реального времени является управление технологическими процессами на производстве. На ее примере и с учетом предыдущих размышлений, сформулируем концепцию AI/ML-платформы реального времени.
Использование искусственного интеллекта и машинного обучения в управлении технологическими процессами имеет ряд особенностей:
- Данные о состоянии технологического процесса поступают интенсивно: с большой частотой и по широкому спектру параметров (вплоть до десятков тысяч значений параметров, передаваемых в секунду из АСУТП)
- Данные о выявлении дефектов, не говоря уже о данных об их развитии, напротив, скудны и нерегулярны, характеризуются недостаточностью типизации дефектов и их локализации во времени (зачастую, представлены записями на бумажном носителе)
- С практической точки зрения, для обучения и применения моделей доступно только «окно актуальности» исходных данных, отражающее динамику технологического процесса за разумный скользящий интервал, заканчивающийся последними считанными значениями параметров процесса
Эти особенности заставляют нас, помимо приема и базовой обработки в реальном времени интенсивного «широкополосного входящего сигнала» от технологического процесса, выполнять (параллельно) применение, обучение и контроль качества результатов работы AI/ML-моделей – также в режиме реального времени. Тот «кадр», который наши модели «видят» в скользящем окне актуальности, постоянно меняется – а вместе с ним меняется и качество результатов работы AI/ML-моделей, обученных на одном из «кадров» в прошлом. При ухудшении качества результатов работы AI/ML-моделей (например: значение ошибки классификации «тревога-норма» вышло за определенные нами границы) должно автоматически быть запущено дообучение моделей на более актуальном «кадре» — и выбор момента для запуска дообучения моделей должен учитывать как продолжительность самого обучения, так и динамику ухудшения качества работы текущей версии моделей (т.к. текущие версии моделей продолжают применяться, пока модели обучаются, и пока не будут сформированы их «заново обученные» версии).
InterSystems IRIS обладает ключевыми платформенными возможностями для обеспечения работы AI/ML-решений при управлении технологическими процессами в режиме реального времени. Эти возможности можно разделить на три основные группы:
- Непрерывное развертывание (Continuous Deployment/Delivery, CD) новых или адаптированных существующих AI/ML-механизмов в продуктивное решение, функционирующее в режиме реального времени на платформе InterSystems IRIS
- Непрерывная интеграция (Continuous Integration, CI) в единое продуктивное решение входящих потоков данных технологического процесса, очередей данных для применения/обучения/контроля качества работы AI/ML-механизмов и обменов данными/кодом/управляющими воздействиями со средами математического моделирования, оркестровку которых осуществляет в реальном времени платформа InterSystems IRIS
- Непрерывное (само-)обучение (Continuous Training, CT) AI/ML-механизмов, выполняемое в средах математического моделирования с использованием данных, кода и управляющих воздействий («принимаемых решений»), передаваемых платформой InterSystems IRIS
Классификация платформенных возможностей применительно к машинному обучению и искусственному интеллекту именно по таким группам неслучайна. Процитируем методологическую публикацию компании Google, в которой подводится концептуальная основа под эту классификацию, в нашем переводе:
«… Популярная в наши дни концепция DevOps охватывает разработку и эксплуатацию масштабных информационных систем. Преимуществами внедрения этой концепции становятся сокращение длительности циклов разработки, ускорение развертывания разработок, гибкость планирования релизов. Для получения этих преимуществ DevOps предполагает внедрение, как минимум, двух практик:
- Continuous Integration (CI)
- Continuous Delivery (CD)
Эти практики также применимы и к AI/ML-платформам – в целях обеспечения надежной и производительной сборки продуктивных AI/ML-решений.
AI/ML-платформы отличаются от остальных информационных систем в следующих аспектах:
- Компетенции команды: при создании AI/ML-решения, команда обычно включает дата-саентистов или экспертов-«академиков» в области исследования данных, которые проводят анализ данных, разработку и апробацию моделей. Эти участники команды могут и не быть профессиональными разработчиками продуктивного программного кода.
- Разработка: AI/ML-механизмы экспериментальны по своей природе. Для того, чтобы решить задачу наиболее эффективным путем, требуется перебрать различные комбинации входных переменных, алгоритмов, способов моделирования и параметров модели. Сложность такого перебора заключается в трассировке «что сработало/не сработало», обеспечении воспроизводимости эпизодов, генерализации разработок для повторяющихся внедрений.
- Тестирование: тестирование AI/ML-механизмов требует большего спектра тестов, чем большинство других разработок. В дополнение к типовым модульным и интеграционным тестам тестируются валидность данных, качество результатов применения модели к обучающим и контрольным выборкам.
- Развертывание: развертывание AI/ML-решений не сводится к предиктивным сервисам, применяющим единожды обученную модель. AI/ML-решения строятся вокруг многоэтапных пайплайнов, выполняющих автоматизированное обучение и применение моделей. Развертывание таких пайплайнов подразумевает автоматизацию нетривиальных действий, традиционно выполняемых дата-саентистами вручную для того, чтобы получить возможность обучить и протестировать модели.
- Продуктив: AI/ML-механизмам может не хватать производительности не только из-за неэффективного программирования, но и вследствие постоянно изменяющегося характера входных данных. Иначе говоря, производительность AI/ML-механизмов может деградировать в связи с более широким спектром причин, нежели производительность обычных разработок. Что приводит к необходимости мониторинга (в режиме «онлайн») производительности наших AI/ML-механизмов, а также рассылки оповещений или отбраковки результатов, если показатели производительности не соответствуют ожиданиям.
AI/ML-платформы схожи с другими информационными системами в том, что и тем, и другим необходима непрерывная интеграция кода с контролем версий, модульное тестирование, интеграционное тестирование, непрерывное развертывание разработок. Тем не менее, в случае с AI/ML, есть несколько важных отличий:
- CI (Continuous Integration, непрерывная интеграция) больше не ограничивается тестированием и валидацией кода развертываемых компонент – к ней также относится тестирование и валидация данных и AI/ML-моделей.
- CD (Continuous Delivery/Deployment, непрерывное развертывание) не сводится к написанию и релизам пакетов или сервисов, а подразумевает платформу для композиции, обучения и применения AI/ML-решений.
- CT (Continuous Training, непрерывное обучение) – новый элемент [прим. автора статьи: новый элемент по отношению к традиционной концепции DevOps, в которой CT это, как правило, Continuous Testing], присущий AI/ML-платформам, отвечающий за автономное управление механизмами обучения и применения AI/ML-моделей. …»
Мы можем констатировать, что машинное обучение и искусственный интеллект, работающие на данных реального времени, требуют более широкого набора инструментов и компетенций (от разработки кода до оркестровки сред математического моделирования), более тесной интеграции между всеми функциональными и предметными областями, более эффективной организации человеческих и машинных ресурсов.
Сценарий реального времени: распознавание развития дефектов в питательных насосах
Продолжая использовать в качестве примера область управления технологическими процессами, рассмотрим конкретную задачу (уже упоминалась нами в самом начале): требуется обеспечить в реальном времени мониторинг развития дефектов в насосах на основе потока значений параметров технологического процесса и отчетов ремонтного персонала о выявленных дефектах.

Рисунок 2 Формулировка задачи по мониторингу развития дефектов
Особенностью большинства подобным образом поставленных задач на практике является то, что регулярность и оперативность поступления данных (АСУТП) должны рассматриваться на фоне эпизодичности и нерегулярности возникновения (и регистрации) дефектов различных типов. Другими словами: данные из АСУТП приходят раз в секунду правильные-точные, а о дефектах делаются записи химическим карандашом с указанием даты в общей тетради в цеху (например: «12.01 – течь в крышку со стороны 3-го подшипника»).
Таким образом, можно дополнить формулировку задачи следующим важным ограничением: «метка» дефекта конкретного типа у нас всего одна (т. е. пример дефекта конкретного типа представлен данными из АСУТП на конкретную дату – и больше примеров дефекта именно этого типа у нас нет). Данное ограничение сразу выводит нас за рамки классического машинного обучения (supervised learning), для которого «меток» должно быть много.

Рисунок 3 Уточнение задачи по мониторингу развития дефектов
Можем ли мы каким-то образом «размножить» имеющуюся в нашем распоряжении единственную «метку»? Да, можем. Текущее состояние насоса характеризуется степенью подобия зарегистрированным дефектам. Даже без применения количественных методов, на уровне зрительного восприятия, наблюдая за динамикой значений данных, прибывающих из АСУТП, уже можно многое почерпнуть:

Рисунок 4 Динамика состояния насоса на фоне «метки» дефекта заданного типа
Но зрительное восприятие (по крайней мере, пока) – не самый подходящий генератор «меток» в нашем быстроменяющемся сценарии. Мы будем оценивать подобие текущего состояния насоса зарегистрированным дефектам при помощи статистического теста.

Рисунок 5 Применение статистического теста к поступающим данным на фоне «метки» дефекта
Статистический тест определяет вероятность того, что записи со значениями параметров технологического процесса в полученном из АСУТП «поток-пакете» подобны записям «метки» дефекта определенного типа. Вычисленное в результате применения статистического теста значение вероятности (индекс статистического подобия) преобразуется к значению 0 или 1, становясь «меткой» для машинного обучения в каждой конкретной записи в исследуемом на подобие пакете. Т. е. после обработки вновь поступившего к нам пакета записей состояния насоса статистическим тестом у нас появляется возможность (а) добавить данный пакет в обучающую выборку для обучения AI/ML-модели и (б) осуществить контроль качества работы текущей версии модели при ее применении к данному пакету.

Рисунок 6 Применение модели машинного обучения к поступающим данным на фоне «метки» дефекта
В одном из наших предыдущих вебинаров мы показываем и объясняем, каким образом платформа InterSystems IRIS позволяет реализовать любой AI/ML-механизм в виде непрерывно исполняемых бизнес-процессов, осуществляющих контроль достоверности результатов моделирования и адаптирующих параметры моделей. При реализации прототипа нашего сценария с насосами мы используем весь представленный в ходе вебинара функционал InterSystems IRIS – имплементируя в процессе-анализаторе в составе нашего решения не классический supervised learning, а скорее обучение с подкреплением (reinforcement learning), автоматически управляющее выборкой для обучения моделей. В выборку для обучения помещаются записи, на которых возникает «консенсус детекции» после применения и статистического теста, и текущей версии модели – т. е. и статистический тест (после трансформации индекса подобия к 0 или 1), и модель выдали на таких записях результат 1. При новом обучении модели, при ее валидации (заново обученная модель применяется к собственной обучающей выборке, с предварительным применением к ней же статистического теста), записи, «не удержавшие» после обработки статистическим тестом результат 1 (из-за постоянного присутствия в обучающей выборке записей из изначальной «метки» дефекта), из обучающей выборки удаляются, и новая версия модели учится на «метке» дефекта плюс на «удержавшихся» записях из потока.

Рисунок 7 Роботизация AI/ML-вычислений в InterSystems IRIS
В случае, если возникает потребность в своего рода «втором мнении» по качеству детекции, получаемой при локальных вычислениях в InterSystems IRIS, создается процесс-советник для выполнения обучения-применения моделей на контрольном датасете с помощью облачных сервисов (например Microsoft Azure, Amazon Web Services, Google Cloud Platform и т. п.):

Рисунок 8 «Второе мнение» из Microsoft Azure под оркестровкой InterSystems IRIS
Прототип нашего сценария в InterSystems IRIS выполнен в виде агентной системы аналитических процессов, осуществляющих взаимодействия с объектом оборудования (насосом), средами математического моделирования (Python, R и Julia), и обеспечивающих самообучение всех задействованных AI/ML-механизмов – на потоках данных реального времени.

Рисунок 9 Основной функционал AI/ML-решения реального времени в InterSystems IRIS
Практический результат работы нашего прототипа:
- Распознанный моделью образец дефекта (12 января):

- Распознанный моделью развивающийся дефект, не вошедший в образец (11 сентября, сам дефект был констатирован ремонтной бригадой только через двое суток – 13 сентября):

Имитация на реальных данных, содержащих несколько эпизодов одного и того же дефекта, показала, что наше решение, реализованное на платформе InterSystems IRIS, позволяет выявить развитие дефектов данного типа за несколько суток до момента их обнаружения ремонтной бригадой.
InterSystems IRIS – универсальная платформа AI/ML-вычислений реального времени
Платформа InterSystems IRIS упрощает разработку, развертывание и эксплуатацию решений на данных реального времени. InterSystems IRIS способна одновременно выполнять транзакционную и аналитическую обработку данных; поддерживать синхронизированные представления данных в соответствии с несколькими моделями (в т.ч. реляционной, иерархической, объектной и документной); выступать платформой интеграции широкого спектра источников данных и отдельных приложений; обеспечивать развитую аналитику в реальном времени на структурированных и неструктурированных данных. InterSystems IRIS также предоставляет механизмы для применения внешнего аналитического инструментария, позволяет гибко сочетать размещение в облаке и на локальных серверах.
Приложения, построенные на платформе InterSystems IRIS, внедрены в различных отраслях, помогая компаниям получать существенный экономический эффект в стратегической и операционной перспективах, повышая информированность принятия решений и устраняя «зазоры» между событием, анализом и действием.

Рисунок 10 Архитектура InterSystems IRIS в контексте AI/ML реального времени
Как и предыдущая диаграмма, нижеприведенная диаграмма сочетает новую «систему координат» (CD/CI/CT) со схемой потоков информации между рабочими элементами платформы. Визуализация начинается с макромеханизма CD и продолжается макромеханизмами CI и СТ.

Рисунок 11 Схема потоков информации между AI/ML-элементами платформы InterSystems IRIS
Суть механизма CD в InterSystems IRIS: пользователи платформы (разработчики AI/ML-решений) адаптируют уже имеющиеся и/или создают новые AI/ML-разработки с применением специализированного редактора программного кода AI/ML-механизмов: Jupyter (полное наименование: Jupyter Notebook; так же, для краткости, иногда называются и документы, созданные в данном редакторе). В Jupyter разработчик имеет возможность написать, отладить и убедиться в работоспособности (в т. ч., с использованием графики) конкретной AI/ML-разработки до ее размещения («развертывания») в InterSystems IRIS. Понятно, что создаваемая таким образом новая разработка будет получать только базовую отладку (т. к., в частности, Jupyter не работает с потоками данных реального времени) – это в порядке вещей, ведь основным результатом разработки в Jupyter становится подтверждение принципиальной работоспособности отдельного AI/ML-механизма («на выборке данных показывает ожидаемый результат»). Аналогичным образом, уже размещенный в платформу механизм (см. следующие макромеханизмы) перед отладкой в Jupyter может потребовать «отката» к «доплатформенному» виду (чтение данных из файлов, работа с данными через xDBC вместо таблиц, непосредственное взаимодействие с глобалами – многомерными массивами данных InterSystems IRIS – и т. п.).
Важный аспект имплементации CD именно в InterSystems IRIS: между платформой и Jupyter реализована двунаправленная интеграция, позволяющая переносить в платформу (и, в дальнейшем, обрабатывать в платформе) контент на языках Python, R и Julia (все три являются языками программирования в соответствующих ведущих open-source средах математического моделирования). Таким образом, разработчики AI/ML-контента имеют возможность осуществлять «непрерывное развертывание» этого контента в платформе, работая в привычном им редакторе Jupyter, с привычными библиотеками, доступными в Python, R, Julia, и выполняя базовую отладку (при необходимости) вне платформы.
Переходим к макромеханизму CI в InterSystems IRIS. На диаграмме изображен макропроцесс работы «роботизатора реального времени» (комплекс из структур данных, бизнес-процессов и оркестрируемых ими фрагментов кода на языках матсред и языке ObjectScript – нативном языке разработки InterSystems IRIS). Задача этого макропроцесса: поддерживать необходимые для работы AI/ML-механизмов очереди данных (на основе потоков данных, передаваемых платформе в реальном времени), принимать решения о последовательности применения и «ассортименту» механизмов AI/ML (они же «математические алгоритмы», «модели» и т. д. – могут называться по-разному в зависимости от конкретики реализации и от терминологических предпочтений), поддерживать в актуальном состоянии структуры данных для анализа результатов работы AI/ML-механизмов (кубы, таблицы, многомерные массивы данных и т. д. – для отчетов, дэшбордов и т. п.).
Важный аспект имплементации CI именно в InterSystems IRIS: между платформой и средами математического моделирования реализована двунаправленная интеграция, позволяющая исполнять размещенный в платформе контент на языках Python, R и Julia в их соответствующих средах с получением обратно результатов исполнения. Эта интеграция реализована как в «режиме терминала» (т. е. AI/ML-контент формулируется как код на ObjectScript, осуществляющий вызовы матсред), так и в «режиме бизнес-процесса» (т. е. AI/ML-контент формулируется как бизнес-процесс при помощи графического редактора, или иногда при помощи Jupyter, или при помощи IDE – IRIS Studio, Eclipse, Visual Studio Code). Доступность бизнес-процессов для редактирования в Jupyter отражена при помощи связи между IRIS на уровне CI и Jupyter на уровне CD. Более детальный обзор интеграции со средами математического моделирования производится далее. На данном этапе, на наш взгляд, есть все основания для того, чтобы зафиксировать наличие в платформе всех необходимых инструментов для реализации «непрерывной интеграции» AI/ML-разработок (приходящих из «непрерывного развертывания») в AI/ML-решения реального времени.
И главный макромеханизм: CT. Без него не получится AI/ML-платформы (хоть «реальное время» и будет имплементировано через CD/CI). Сутью CT является работа платформы с «артефактами» машинного обучения и искусственного интеллекта непосредственно в рабочих сессиях сред математического моделирования: моделями, таблицами распределений, векторами-матрицами, слоями нейросетей и т.п. Данная «работа», в большинстве случаев, состоит в создании упомянутых артефактов в средах (в случае моделей, например, «создание» состоит из задания спецификации модели и последующего подбора значений ее параметров – так называемого «обучения» модели), их применении (для моделей: расчет при их помощи «модельных» значений целевых переменных – прогнозов, принадлежности к категории, вероятности наступления события и т.п.) и усовершенствовании уже созданных и примененных артефактов (например, переопределение набора входных переменных модели по результатам применения – в целях повышения точности прогнозирования, как вариант). Ключевым моментом в понимании роли CT является его «абстрагированность» от реалий CD и CI: CT будет имплементировать все артефакты, ориентируясь на вычислительную и математическую специфику AI/ML-решения в рамках возможностей, предоставляемых конкретными средами. Ответственность за «снабжение входными данными» и «доставку результатов» будут нести CD и CI.
Важный аспект имплементации CT именно в InterSystems IRIS: пользуясь уже упомянутой выше интеграцией со средами математического моделирования, платформа имеет возможность извлекать из рабочих сессий, протекающих под ее управлением в матсредах, те самые артефакты и (самое важное) превращать их в объекты данных платформы. Например, таблица распределения, которая создалась только что в рабочей сессии Python может быть (без остановки сессии в Python) перенесена в платформу в виде, например, глобала (многомерного массива данных InterSystems IRIS), – и использована для вычислений в другом AI/ML-механизме (реализованном уже на языке другой среды – например, на R) – или виртуальной таблицы. Другой пример: в параллель со «штатным режимом» работы модели (в рабочей сессии Python), на ее входных данных осуществляется «авто-ML »: автоматический подбор оптимальных входных переменных и значений параметров. И вместе со «штатным» обучением, продуктивная модель в режиме реального времени получает еще и «предложение по оптимизации» своей спецификации – в которой меняется набор входных переменных, меняются значения параметров (уже не в результате обучения в Python, а в результате обучения «альтернативной» версии ее самой, например, в стеке H2O), позволяя общему AI/ML-решению автономно справляться с непредвиденными изменениями в характере входных данных и моделируемых явлений.
Познакомимся более подробно с платформенным AI/ML-функционалом InterSystems IRIS, на примере реально существующего прототипа.
На нижеприведенной диаграмме, в левой части слайда – часть бизнес-процесса, имплементирующая отработку скриптов на Python и R. В центральной части – визуальные логи исполнения некоторых из этих скриптов, соответственно, на Python и на R. Сразу за ними – примеры контента на одном и другом языке, переданные на исполнение в соответствующие среды. В конце справа – визуализации, основанные на результатах исполнения скриптов. Визуализации вверху – сделаны на IRIS Analytics (данные забраны из Python в платформу данных InterSystems IRIS и выведены на дэшборд средствами платформы), внизу – сделаны прямо в рабочей сессии R и выведены оттуда в графические файлы. Важный аспект: представленный фрагмент в прототипе отвечает за обучение модели (классификация состояний оборудования) на данных, поступающих в реальном времени от процесса-имитатора оборудования, по команде от процесса-монитора качества классификации, наблюдаемого в ходе применении модели. Об имплементации AI/ML-решения в виде набора взаимодействующих процессов («агентов») речь пойдет далее.

Рисунок 12 Взаимодействие с Python, R и Julia в InterSystems IRIS
Платформенные процессы (они же «бизнес-процессы», «аналитические процессы», «пайплайны» и т.п. – в зависимости от контекста), прежде всего, редактируемы в графическом редакторе бизнес-процессов в самой платформе, причем таким образом, что создаются одновременно и его блок-схема, и соответствующий AI/ML-механизм (программный код). Говоря о том, что «получается AI/ML-механизм», мы изначально подразумеваем гибридность (в рамках одного процесса): контент на языках сред математического моделирования соседствует с контентом на SQL (в т. ч., с расширениями от IntegratedML), на InterSystems ObjectScript, с другими поддерживаемыми языками. Более того, платформенный процесс дает очень широкие возможности для «отрисовки» в виде иерархически вложенных фрагментов (как видно в примере на приведенной ниже диаграмме), что позволяет эффективно организовывать даже весьма сложный контент, нигде не «выпадая» из графического формата (в «неграфические» методы/классы/процедуры и т. п.). Т. е. при необходимости (а она предвидится в большинстве проектов) абсолютно все AI/ML-решение может быть имплементировано в графическом самодукоментирующемся формате. Обращаем внимание на то, что в центральной части нижеприведенной диаграммы, на которой представлен более высокий «уровень вложенности», видно, что помимо собственно работы по обучению модели (при помощи Python и R), добавляется анализ так называемой ROC-кривой обученной модели, позволяющий визуально (и вычислительно тоже) оценить качество обучения – и этот анализ реализован на языке Julia (исполняется, соответственно, в матсреде Julia).

Рисунок 13 Визуальная среда композиции AI/ML-решений в InterSystems IRIS
Как уже упоминалось ранее, начальная разработка и (в ряде случаев) адаптация уже имплементированных в платформе AI/ML-механизмов будет/может производиться вне платформы в редакторе Jupyter. На диаграмме ниже мы видим пример адаптации существующего платформенного процесса (того же, что и на диаграмме выше) – таким образом выглядит в Jupyter тот его фрагмент, который отвечает за обучение модели. Контент на языке Python доступен для редактирования, отладки, вывода графики прямо в Jupyter. Изменения (при необходимости) могут производиться с мгновенной синхронизацией в платформенный процесс, в т. ч. в его продуктивную версию. Аналогичным образом может передаваться в платформу и новый контент (автоматически формируется новый платформенный процесс).

Рисунок 14 Применение Jupyter Notebook для редактирования AI/ML-механизма в платформе InterSystems IRIS
Адаптация платформенного процесса может выполняться не только в графическом или ноутбучном формате – но и в «тотальном» формате IDE (Integrated Development Environment). Такими IDE выступают IRIS Studio (нативная студия IRIS), Visual Studio Code (расширение InterSystems IRIS для VSCode) и Eclipse (плагин Atelier). В ряде случаев возможно одновременное использование командой разработчиков всех трех IDE. На диаграмме ниже показан пример редактирования все того же процесса в студии IRIS, в Visual Studio Code и в Eclipse. Для редактирования доступен абсолютно весь контент: и Python/R/Julia/SQL, и ObjectScript, и бизнес-процесс.

Рисунок 15 Разработка бизнес-процесса InterSystems IRIS в различных IDE
Отдельного упоминания заслуживают средства описания и исполнения бизнес-процессов InterSystems IRIS на языке Business Process Language (BPL). BPL дает возможность использовать в бизнес-процессах «готовые интеграционные компоненты» (activities) – что, собственно говоря, и дает полные основания утверждать, что в InterSystems IRIS реализована «непрерывная интеграция». Готовые компоненты бизнес-процесса (активности и связи между ними) являются мощнейшим акселератором сборки AI/ML-решения. И не только сборки: благодаря активностям и связям между ними над разрозненными AI/ML-разработками и механизмами возникает «автономный управленческий слой», способный принимать решения сообразно ситуации, в реальном времени.

Рисунок 16 Готовые компоненты бизнес-процессов для непрерывной интеграции (CI) на платформе InterSystems IRIS
Концепция агентных систем (они же «мультиагентные системы») имеет сильные позиции в роботизации, и платформа InterSystems IRIS органично ее поддерживает через конструкт «продукция-процесс». Помимо неограниченных возможностей для «начинки» каждого процесса необходимым для общего решения функционалом, наделение системы платформенных процессов свойством «агентности» позволяет создавать эффективные решения для крайне нестабильных моделируемых явлений (поведение социальных/биосистем, частично наблюдаемых технологических процессов и т. п.).

Рисунок 17 Работа AI/ML-решения в виде агентной системы бизнес-процессов в InterSystems IRIS
Мы продолжаем наш обзор InterSystems IRIS рассказом о прикладном использовании платформы для решения целых классов задач реального времени (довольно подробное знакомство с некоторыми лучшими практиками платформенного AI/ML на InterSystems IRIS происходит в одном из наших предыдущих вебинаров).
По «горячим следам» предыдущей диаграммы, ниже приведена более подробная диаграмма агентной системы. На диаграмме изображен все тот же прототип, видны все четыре процесса-агента, схематически отрисованы взаимоотношения между ними: GENERATOR – отрабатывает создание данных датчиками оборудования, BUFFER – управляет очередями данных, ANALYZER – выполняет собственно машинное обучение, MONITOR – контролирует качество машинного обучения и подает сигнал о необходимости повторного обучения модели.

Рисунок 18 Композиция AI/ML-решения в виде агентной системы бизнес-процессов в InterSystems IRIS
На диаграмме ниже проиллюстрировано автономное функционирование уже другого роботизированного прототипа (распознавание эмоциональной окраски текстов) на протяжении некоторого времени. В верхней части – эволюция показателя качества обучения модели (качество растет), в нижней части – динамика показателя качества применения модели и факты повторного обучения (красные полоски). Как можно видеть, решение эффективно и автономно самообучилось, и работает на заданном уровне качества (значения показателя качества не падают ниже 80%).

Рисунок 19 Непрерывное (само-)обучение (CT) на платформе InterSystems IRIS
Об «авто-ML» мы тоже упоминали ранее, но на нижеприведенной диаграмме применение данного функционала показано в подробностях на примере еще одного прототипа. На графической схеме фрагмента бизнес-процесса показана активность, запускающая моделирование в стеке H2O, показаны результаты этого моделирования (явное доминирование полученной модели над «рукотворными» моделями, согласно сравнительной диаграмме ROC-кривых, а также автоматизированное выявление «наиболее влиятельных переменных» из доступных в исходном наборе данных). Важным моментом здесь является та экономия времени и экспертных ресурсов, которая достигается за счет «авто-ML»: то, что наш платформенный процесс делает за полминуты (нахождение и обучение оптимальной модели), у эксперта может занять от недели до месяца.

Рисунок 20 Интеграция «авто-ML» в AI/ML-решение на платформе InterSystems IRIS
Диаграмма ниже немного «сбивает кульминацию», но это хороший вариант завершения рассказа о классах решаемых задач реального времени: мы напоминаем о том, что при всех возможностях платформы InterSystems IRIS, обучение моделей именно под ее управлением не является обязательным. Платформа может получить извне так называемую PMML-спецификацию модели, обученную в инструменте, не находящемся под управлением платформы – и применять эту модель в реальном времени с момента импорта ее PMML-спецификации. При этом важно учесть, что далеко не все AI/ML-артефакты могут быть сведены к PMML-спецификации, даже если большинство наиболее распространенных артефактов это позволяют сделать. Таким образом платформа InterSystems IRIS имеет «открытый контур» и не означает «платформенного рабства» для пользователей.

Рисунок 21 Применение модели по PMML-спецификации в платформе InterSystems IRIS
Перечислим дополнительные платформенные преимущества InterSystems IRIS (для наглядности, применительно к управлению технологическими процессами), имеющие большое значение при автоматизации искусственного интеллекта и машинного обучения реального времени:
- Развитые средства интеграции с любыми источниками и потребителями данных (АСУТП/SCADA, оборудование, ТОиР, ERP и т. д.)
- Встроенная мультимодельная СУБД для высокопроизводительной транзакционно-аналитической обработки (Hybrid Transaction/Analytical Processing, HTAP) любых объемов данных технологических процессов
- Средства разработки для непрерывного развертывания AI/ML-механизмов решений реального времени на основе Python, R, Julia
- Адаптивные бизнес-процессы для непрерывной интеграции и (само-)обучения механизмов AI/ML-решений реального времени
- Встроенные средства Business Intelligence для визуализации данных технологических процессов и результатов работы AI/ML-решения
- Управление API для доставки результатов работы AI/ML-решения в АСУТП/SCADA, информационно-аналитические системы, рассылки оповещений и т. д.
AI/ML-решения на платформе InterSystems IRIS легко вписываются в существующую ИТ-инфраструктуру. Платформа InterSystems IRIS обеспечивает высокую надежность AI/ML-решений за счет поддержки отказоустойчивых и катастрофоустойчивых конфигураций и гибкое развертывание в виртуальных средах, на физических серверах, в частных и публичных облаках, Docker-контейнерах.
Таким образом, InterSystems IRIS является универсальной платформой AI/ML-вычислений реального времени. Универсальность нашей платформы подтверждается на практике отсутствием де-факто ограничений по сложности имплементируемых вычислений, способностью InterSystems IRIS совмещать (в режиме реального времени) обработку сценариев из самых различных отраслей, исключительной адаптируемостью любых функций и механизмов платформы под конкретные потребности пользователей.

Рисунок 22 InterSystems IRIS — универсальная платформа AI/ML-вычислений реального времени
Для более предметного взаимодействия с теми из наших читателей, кого заинтересовал представленный здесь материал, мы рекомендуем не ограничиваться его прочтением и продолжить диалог «вживую». Мы с готовностью окажем поддержку с формулировкой сценариев AI/ML реального времени применительно к специфике вашей компании, выполним совместное прототипирование на платформе InterSystems IRIS, сформируем и реализуем на практике дорожную карту внедрения искусственного интеллекта и машинного обучения в ваши производственные и управленческие процессы. Контактный адрес электронной почты нашей экспертной группы AI/ML – MLToolkit@intersystems.com.
