Автор: Сергей Лукьянчиков, инженер-консультант InterSystems
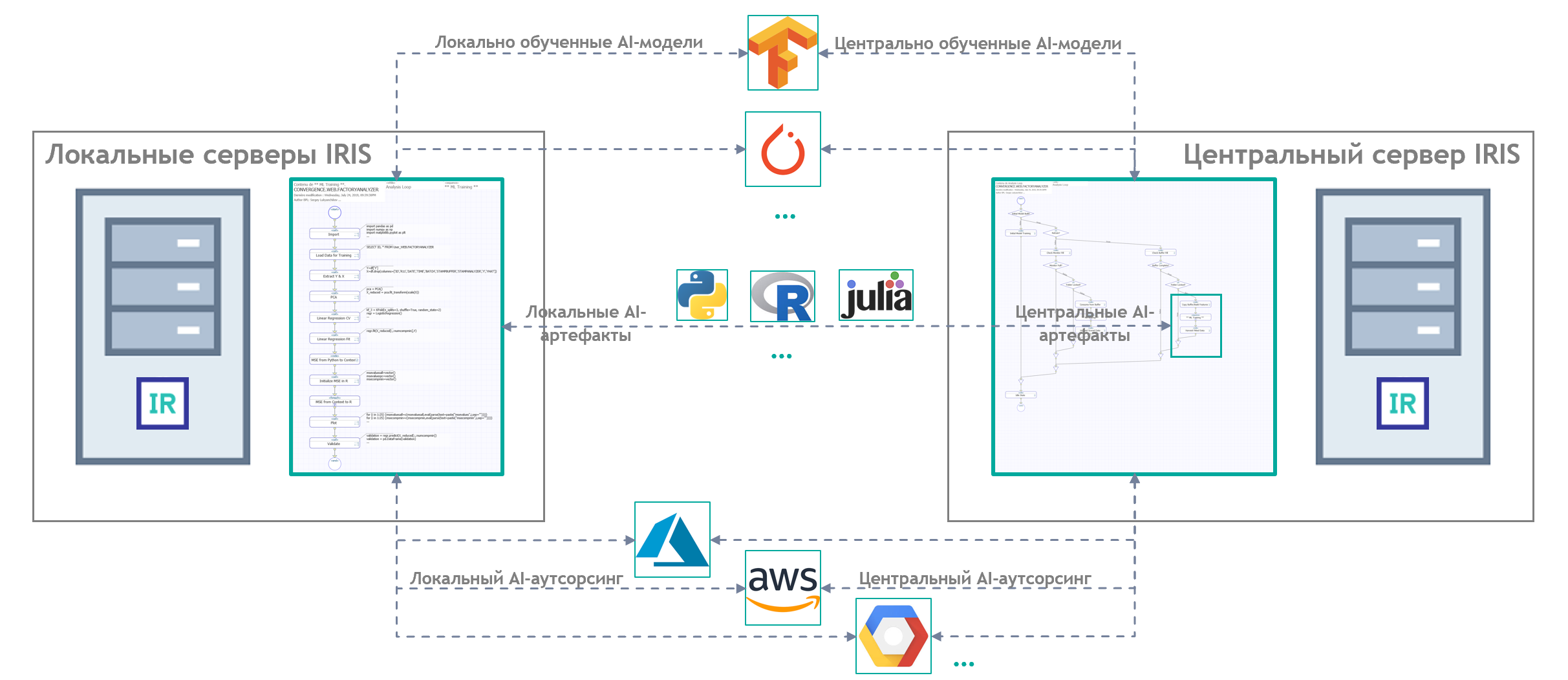
Что такое распределенный искусственный интеллект?
Попытки отыскать «железное» определение ничего не дали: видимо, понятие немного «обогнало время». Но можно попробовать разобрать семантически само понятие – тогда получится, что распределенный искусственный интеллект это тот же самый ИИ (см. наши попытки дать «прикладное» определение), только еще и разнесенный на несколько компьютеров, не объединенных в единый вычислительный кластер (ни по данным, ни по приложениям, ни по доступу к отдельным компьютерам в принципе). Т. е. в абсолюте, распределенный искусственный интеллект должен быть распределен так, чтобы ни с одного из участвующих в этом «распределении» компьютеров не было возможности получить прямой доступ ни к данным, ни к приложениям других компьютеров: единственной альтернативой становится передача фрагментов данных или скриптов приложений через «явные» сообщения. Любые отступления от этого абсолюта, по идее, приводят к возникновению «частично распределенного искусственного интеллекта» – например, данные распределены, а сервер приложений общий. Или наоборот. Так или иначе, мы получаем на выходе набор «федерированных» моделей (т. е. либо обученных каждая на своем источнике данных, либо обученных каждая своим алгоритмом, либо «и то и другое вместе»).
Сценарии распределенного ИИ «для масс»
Речь не пойдет о периферийных вычислениях, операторах конфиденциальных данных, поисковых запросах на мобильных телефонах и тому подобных увлекательных, но не самых (пока что) осознанно применяемых в широких кругах пользователей сценариях. Гораздо более «жизненным» может стать, например, следующий сценарий (детальную демонстрацию можно и нужно посмотреть здесь): на предприятии работает продуктивное AI/ML-решение, качество его работы должен систематически контролировать внешний дата-саентист (т.е. эксперт, не являющийся сотрудником предприятия). Предоставить дата-саентисту доступ к решению предприятие не может (по различным соображениям), но может отправлять ему выгрузку записей из той или иной таблицы по заданному расписанию или по наступлении определенного события (например, завершение очередного сеанса обучения одной или нескольких моделей решения). При этом предполагается, что дата-саентист владеет какой-нибудь версией AI/ML-механизмов, которые были интегрированы в продуктивное решение, работающее на предприятии – скорее всего, сам же дата-саентист эти механизмы и разрабатывает, занимается их усовершенствованием и адаптацией к конкретной задаче конкретного предприятия. Размещением этих механизмов в продуктивное решение, мониторингом их эксплуатации и прочими аспектами жизненного цикла занимается дата-инженер (является сотрудником предприятия).





 PHP с начала своих времён славен (и критикуем) тем, что поддерживает интеграцию с массой библиотек, а также с практически со всеми СУБД существующими на рынке. Однако в силу каких-то странных причин в нём не было поддержки иерархических баз данных на глобалах.
PHP с начала своих времён славен (и критикуем) тем, что поддерживает интеграцию с массой библиотек, а также с практически со всеми СУБД существующими на рынке. Однако в силу каких-то странных причин в нём не было поддержки иерархических баз данных на глобалах.