
«В режиме трассировки программист видит последовательность выполнения команд и значения переменных на данном шаге выполнения программы, что позволяет легче обнаруживать ошибки» — сообщает нам Википедия. Сами будучи поклонниками Linux, мы регулярно сталкиваемся с вопросом, какими именно инструментами её лучше осуществлять. И хотим поделиться переводом статьи программиста Хонгли Лая, который рекомендует bpftrace. Забегая вперёд, скажу, что заканчивается статья лаконично: «bpftrace — это будущее». Так чем же он так впечатлил коллегу Лая? Развёрнутый ответ под катом.
В Linux есть два основных инструмента трассировки:
strace позволяет вам увидеть, какие совершаются системные вызовы;
ltrace позволяет увидеть, какие вызываются динамические библиотеки.
Несмотря на свою полезность, эти инструменты ограничены. А если вам нужно выяснить, что происходит внутри системного или библиотечного вызова? А если вам нужно не просто составить список вызовов, но и, например, собрать статистику по определённому поведению? А если вам нужно трассировать несколько процессов и сопоставить данные из нескольких источников?
В 2019 году мы, наконец, получили достойный ответ на эти вопросы на Linux: bpftrace, основанный на технологии eBPF. Bpftrace позволяет писать небольшие программы, которые выполняются каждый раз, когда происходит событие.
В этой статье я опишу, как установить bpftrace и научу его базовому применению. А также сделаю обзор того, как выглядит трассировочная экосистема (например, «что такое eBPF?») и как она развивалась в то, что мы имеем сегодня.
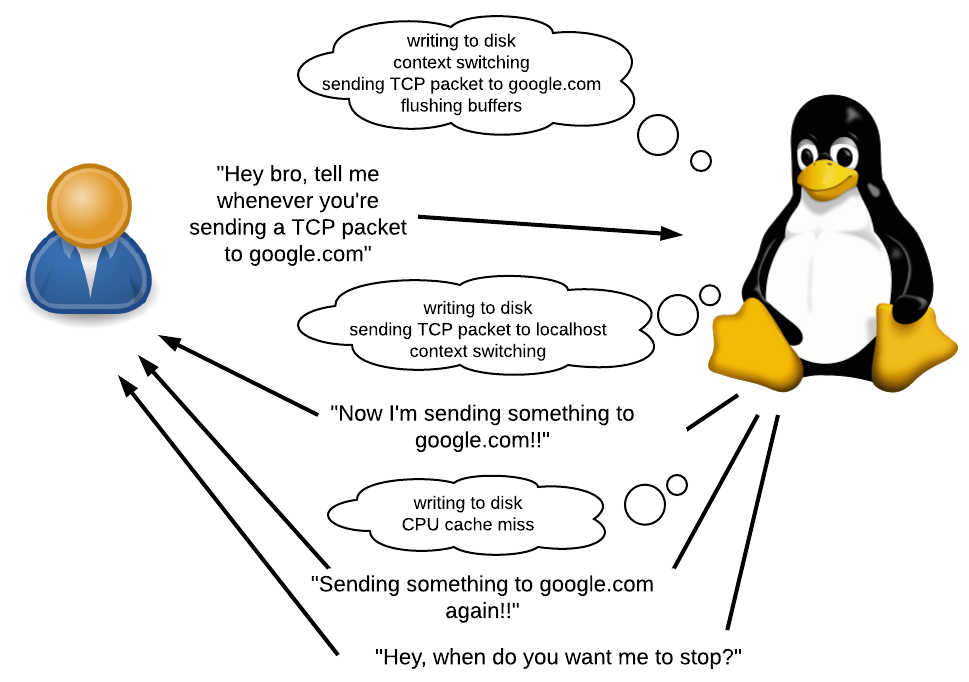
Что такое трассировка?
Как уже было сказано ранее, bpftrace позволяет писать небольшие программы, которые выполняются каждый раз, когда происходит событие.
Что такое событие? Это может быть системный вызов, вызов функции или даже что-то, происходящие внутри таких запросов. Это также может быть таймер или аппаратное событие, например «50 мс прошло с последнего такого же события», «произошёл отказ страницы», «произошло переключение контекста» или «произошёл cashe-miss процессора».
Что можно сделать в ответ на событие? Вы можете что-нибудь залогировать, собрать статистические данные и выполнить произвольные команды оболочки. У вас будет доступ к различной контекстной информации, такой как текущий PID, трассировка стека, время, аргументы вызовов, возвращаемые значения, и т.д.
В каких случаях использовать? Во многих. Вы можете разобраться в том, почему приложение медленно работает, собрав список наиболее медленных вызовов. Вы можете определить, имеются ли в приложении утечки памяти и если да, то откуда. Я использую его, чтобы разбираться с тем, почему Ruby использует так много памяти.
Большим плюсом bpftrace является то, что вам нет нужды перекомпилировать приложения. Нет необходимости руками прописывать в исходниках исследуемого приложения вызовы print или любой другой отладочный код. Нет даже необходимости перезапуска приложений. И всё это с очень низкими накладными расходами. Это делает bpftrace особенно полезным для отладки систем прямо на проде или в иной ситуации, когда есть сложности с перекомпиляцией.
DTrace: отец трассировки
В течение долгого времени лучшим инструментом для трассировки был DTrace, полновесный фреймворк для динамической трассировки, изначально разработанный Sun Microsystems (создателями Java). Как и bpftrace, DTrace позволяет писать небольшие программы, которые выполняются в ответ на события. На самом деле, многие ключевые элементы экосистемы в значительной степени разработаны Бренданом Греггом, известным экспертом по DTrace, который сейчас работает в Netflix. Что объясняет сходство между DTrace и bpftrace.
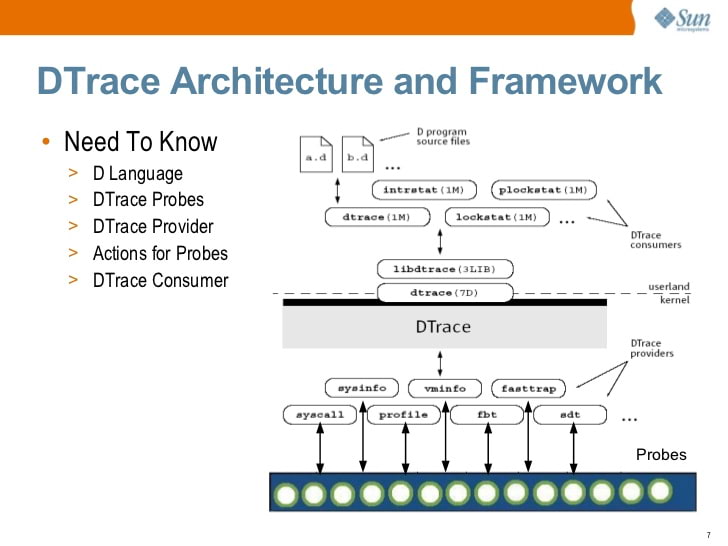
Solaris DTrace introduction (2009) by S. Tripathi, Sun Microsystems
В какой-то момент Sun открыли исходники DTrace. Сегодня DTrace доступен на Solaris, FreeBSD и macOS (хотя версия для macOS в целом неработоспособна, поскольку Защита Системной Целостности, SIP, сломала многие принципы, на которых работает DTrace).
Да, вы правильно заметили… Linux в этом списке отсутствует. Это не инженерная проблема, это проблема лицензирования. DTrace был открыт под лицензией CDDL вместо GPL. Порт DTrace на Linux был доступен с 2011 года, но он никогда не поддерживался основными разработчиками Linux. В начале 2018 года Oracle переоткрыли DTrace под GPL, но к тому моменту было уже слишком поздно.
Экосистема трассировки в Linux
Без сомнения, возможность трассировки очень полезна, и сообщество Linux стремилось разработать свои собственные решения на эту тему. Но, в отличие от Solaris, Linux не регулируется одним конкретным вендором, в связи с чем не возникало целенаправленных усилий разработать полнофункциональную замену DTrace. Экосистема трассировки в Linux развивалась медленно и естественно, решая проблемы по мере их возникновения. И только недавно эта экосистема выросла достаточно, чтобы серьёзно конкурировать с DTrace.
Из-за естественного роста эта экосистема может показаться немного хаотичной, состоящей из множества различных компонентов. К счастью, Джулия Эванс написала обзор этой экосистемы (внимание, дата публикации — 2017 год, до появления bpftrace).

Экосистема трассировки Linux, описанная Джулией Эванс
Не все элементы одинаково важны. Позвольте мне кратко резюмировать, какие элементы я считаю наиболее важными.
Источники событий
Данные о событиях могут поступать как из ядра, так и из пространства пользователя (приложений и библиотек). Некоторые из них доступны автоматически, без дополнительных усилий разработчиков, остальные же требуют ручного объявления.

Обзор самых важных источников трассируемых событий в Linux
Со стороны ядра существует kprobes (от «kernel probes», «датчик ядра», прим. пер.) — механизм, позволяющий трассировать любой вызов функции внутри ядра. С его помощью вы можете трассировать не только сами системные вызовы, но и то, что происходит внутри них (потому что точки входа системных вызовов вызывают другие внутренние функции). Вы также можете использовать kprobes для трассировки событий ядра, не являющихся системными вызовами, например, «буферизированные данные записываются на диск», «TCP-пакет посылается по сети» или «в данный момент происходит переключение контекста».
Точки трассировки (tracepoints) ядра позволяют трассировать нестандартные события, определённые разработчиками ядра. Эти события находятся не на уровне вызовов функций. Для создания таких точек разработчики ядра вручную размещают макрос TRACE_EVENT в коде ядра.
У обоих источников есть и плюсы и минусы. Kprobes работает «автоматически», т.к. не требует от разработчиков ядра ручной разметки кода. Но события kprobe могут произвольно меняться от одной версии ядра к другой, потому что функции постоянно изменяются — добавляются, удаляются, переименовываются.
Точки трассировки ядра, как правило, более стабильны с течением времени и могут предоставлять полезную контекстную информацию, которая может быть недоступна в случае использования kprobes. Используя kprobes, можно получить доступ к аргументам вызовов функций. Но с помощью точек трассировки можно получить любую информацию, которую разработчик ядра решит вручную описать.
В пространстве пользователя существует аналог kprobes — uprobes. Он предназначен для трассировки вызовов функций в пространстве пользователя.
Датчики USDT («Статически Определённые Трассировки Пользовательского Пространства») — это аналог точек трассировки ядра в пространстве пользователя. Разработчикам приложений необходимо вручную добавлять датчики USDT в свой код.
Интересный факт: DTrace в течение долгого времени предоставлял C API для определения собственного аналога USDT датчиков (с помощью макроса DTRACE_PROBE). Разработчики экосистем трассировки в Linux решили оставить исходный код совместимым с этим API, так что любые макросы DTRACE_PROBE автоматически преобразуются в USDT датчики!
Поэтому, в теории, strace может быть реализован с помощью kprobes, а ltrace — с помощью uprobes. Я не уверен, практикуется ли такое уже или нет.
Интерфейсы
Интерфейсы — это приложения, позволяющие пользователям с легкостью использовать источники событий.
Давайте рассмотрим, как работают источники событий. Рабочий процесс выглядит следующим образом:
- Ядро представляет механизм – обычно файл /proc или /sys, открытый для записи, – который регистрирует как намерение трассировать событие, так и то, что должно последовать за событием.
- Зарегистрировав, ядро локализует в памяти ядро/функция в пространстве пользователя/точки трассировки/USDT-датчики и изменяет их код так, чтобы произошло что-то еще.
- Результат этого «что-то еще» может быть собран позже с помощью какого-нибудь механизма.
Не хотелось бы делать все это вручную! Поэтому на помощь приходят интерфейсы: они делают всё это за вас.
Существуют интерфейсы на любой вкус и цвет. В области интерфейсов на основе eBPF есть низкоуровневые, требующие глубокого понимания того, как взаимодействовать с источниками событий и как работает байт-код eBPF. А есть и высокоуровневые и простые в эксплуатации, хотя за время своего существования они не демонстрировали большой гибкости.
Вот почему bpftrace – новейший интерфейс – это мой любимый. Он легкий в использовании и гибкий, как DTrace. Но он довольно новый и требует шлифовки.
eBPF
eBPF — это новая звезда трассировки в Linux, на которой базируется bpftrace. Когда вы трассируете событие, вы хотите чтобы «что-то» случилось в ядре. Как гибким способом определить что есть это «что-то»? Конечно, с помощью языка программирования (или с помощью машинного кода).
eBPF (расширенной версии Пакетного Фильтра Беркли). Это высокопроизводительная виртуальная машина, которая работает в ядре и имеет следующие свойства/ограничения:
- Все взаимодействия с пользовательским пространством происходят через «карты» eBPF, которые являются хранилищем данных типа ключ-значение.
- Циклов нет для того, чтобы каждая eBPF программа завершалась в определенное время.
- Подождите, мы сказали «Пакетный фильтр»? Вы правы: они были первоначально разработаны для фильтрации сетевых пакетов. Это похожая задача: при пересылке пакетов (возникновение события) вам требуется выполнить какое-нибудь действие администраторского характера (принять, сбросить, журналировать или перенаправить пакет, и т.д.) Для быстроты выполнения таких действий и была изобретена виртуальная машина (с возможностью JIT-компиляции). «Расширенной» версия считается из-за того, что, по сравнению с оригинальной версией Пакетного Фильтра Беркли, eBPF может использоваться вне сетевого контекста.
Вот так. С помощью bpftrace вы можете определить, какие события отслеживать и что должно произойти в ответ. Bpftrace компилирует вашу высокоуровневую написанную на языке bpftrace программу в байт-код eBPF, отслеживает события и загружает байт-код в ядро.
Темные дни до eBPF
До появления eBPF варианты решения были, мягко говоря, неуклюжими. SystemTap — что-то вроде «наиболее серьезного» предшественника bpftrace в семействе Linux. Cкрипты SystemTap транслируются в язык C и загружаются в ядро в виде модулей. Полученный модуль ядра затем загружается.
Этот подход был очень хрупким и плохо поддерживался вне Red Hat Enterprise Linux. У меня он никогда хорошо не работал на Ubuntu, которая имела тенденцию ломать SystemTap на каждом обновлении ядра по причине изменения структуры данных ядра. Говорят также, что в первые дни своего существования SystemTap легко приводил к kernel panic.
Установка bpftrace
Пришло время засучить рукава! В этом руководстве мы рассмотрим установку bpftrace на Ubuntu 18.04. Более новые версии дистрибутива использовать нежелательно, т.к. при установке нам понадобятся пакеты, которые пока для них не собраны.
Установка зависимостей
Для начала установим Clang 5.0, lbclang 5.0 и LLVM 5.0, включая все заголовочные файлы. Мы будем использовать пакеты, предоставляемые llvm.org, потому что те, что есть в репозиториях Ubuntu, проблемные.
wget -O - https://apt.llvm.org/llvm-snapshot.gpg.key | sudo apt-key add -
cat <<EOF | sudo tee -a /etc/apt/sources.list
deb http://apt.llvm.org/xenial/ llvm-toolchain-xenial main
deb-src http://apt.llvm.org/xenial/ llvm-toolchain-xenial main
deb http://apt.llvm.org/xenial/ llvm-toolchain-xenial-5.0 main
deb-src http://apt.llvm.org/xenial/ llvm-toolchain-xenial-5.0 main
EOF
sudo apt update
sudo apt install clang-5.0 libclang-5.0-dev llvm-5.0 llvm-5.0-devДалее:
sudo apt install bison cmake flex g++ git libelf-dev zlib1g-dev libfl-devИ, наконец, установите libbfcc-dev из апстрима, а не из репозитория Ubuntu. В пакете, что есть в Ubuntu, отсутствуют заголовочные файлы. И эта проблема не была решена даже в 18.10.
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD
echo "deb https://repo.iovisor.org/apt/$(lsb_release -cs) $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/iovisor.list
sudo apt update
sudo apt install bcc-tools libbcc-examples linux-headers-$(uname -r)Основная установка bpftrace
Пришло время установить сам bpftrace из исходников! Давайте склонируем его, соберём и установим в /usr/local:
git clone https://github.com/iovisor/bpftrace
cd bpftrace
mkdir build && cd build
cmake -DCMAKE_BUILD_TYPE=DEBUG ..
make -j4
sudo make installИ готово! Исполняемый файл будет установлен в /usr/local/bin/bpftrace. Вы можете изменить целевое расположение, используя аргумент для cmake, который по умолчанию выглядит вот так:
DCMAKE_INSTALL_PREFIX=/usr/local.Однострочные примеры
Давайте запустим несколько однострочников bpftrace, чтобы понять наши возможности. Эти я взял из руководства Брендана Грегга, в котором есть подробное описание каждого из них.
# 1. Выводим список датчиков
bpftrace -l 'tracepoint:syscalls:sys_enter_*'# 2. Приветственное слово
bpftrace -e 'BEGIN { printf("hello world\n"); }'# 3. Открытие файла
bpftrace -e 'tracepoint:syscalls:sys_enter_open { printf("%s %s\n", comm, str(args->filename)); }'# 4. Количество системных вызовов на процесс
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'# 5. Распределение вызовов read() по количеству байт
bpftrace -e 'tracepoint:syscalls:sys_exit_read /pid == 18644/ { @bytes = hist(args->retval); }'# 6. Динамическая трассировка содержимого read()
bpftrace -e 'kretprobe:vfs_read { @bytes = lhist(retval, 0, 2000, 200); }'# 7. Время, затраченное на вызовы read()
bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; }
kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'# 8. Подсчёт событий уровня процесса
bpftrace -e 'tracepoint:sched:sched* { @[name] = count(); } interval:s:5 { exit(); }'# 9. Профайлинг рабочих стеков ядра
bpftrace -e 'profile:hz:99 { @[stack] = count(); }'# 10. Трассировка планировщика
bpftrace -e 'tracepoint:sched:sched_switch { @[stack] = count(); }'# 11. Трассировка блокирующего ввода/вывода
bpftrace -e 'tracepoint:block:block_rq_complete { @ = hist(args->nr_sector * 512); }'Загляните на сайт Брендана Грегга, чтобы узнать, какой вывод могут генерировать перечисленные выше команды.
Синтаксис скриптов и пример тайминга ввода/вывода
Строка, передаваемая через ключ '-e' — это содержимое скрипта bpftrace. Синтаксис в данном случае — это, условно, набор конструкций:
<event source> /<optional filter>/ { <program body> }Давайте разберём седьмой пример, про тайминги операций чтения файловой системы:
kprobe:vfs_read { @start[tid] = nsecs; }
<- 1 -><-- 2 -> <---------- 3 --------->Трассируем событие от механизма kprobe, т. е. отслеживаем начало функции ядра.
Функция ядра для трассировки — vfs_read, эта функция вызывается, когда ядро производит операцию чтения с файловой системы (VFS от «Virtual FileSystem», абстракции файловой системы внутри ядра).
Когда начинает выполняться vfs_read (т.е. до того, как функция выполнила какую-либо полезную работу), запускается программа bpftrace. Она сохраняет текущую метку времени (в наносекундах) в глобальный ассоциативный массив, именуемый stаrt. Ключом является tid, ссылка на текущий идентификатор потока (thread id).
kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }
<-- 1 --> <-- 2 -> <---- 3 ----> <----------------------------- 4 ----------------------------->1. Трассируем событие от механизма kretprobe, который похож на kprobe, за исключением того, что он вызывается, когда функция возвращает результат своего выполнения.
2. Функция ядра для трассировки — vfs_read.
3. Это опциональный фильтр. Он проверяет, было ли ранее записано время старта. Без этого фильтра программа может быть запущена во время чтения и поймать только конец, в результате чего получить рассчётное время nsecs — 0, вместо nsecs — start.
4. Тело программы.
nsecs — stаrt[tid] вычисляет, сколько времени прошло с начала работы функции vfs_read.
@ns[comm] = hist(...) добавляет указанные данные в двумерную гистограмму, хранящуюся в @ns. Ключ comm ссылается на имя текущего приложения. Так что у нас будет покомандная гистограмма.
delete(...) удаляет время начала из ассоциативного массива, потому что оно нам больше не требуется.
Это окончательный вывод. Обратите внимание, что все гистограммы выводятся автоматически. Явное использование команды «напечатать гистограмму» не требуется. @ns — это не специальная переменная, так что гистограмма выводится не из-за него.
@ns[snmp-pass]:
[0, 1] 0 | |
[2, 4) 0 | |
[4, 8) 0 | |
[8, 16) 0 | |
[16, 32) 0 | |
[32, 64) 0 | |
[64, 128) 0 | |
[128, 256) 0 | |
[256, 512) 27 |@@@@@@@@@ |
[512, 1k) 125 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[1k, 2k) 22 |@@@@@@@ |
[2k, 4k) 1 | |
[4k, 8k) 10 |@@@ |
[8k, 16k) 1 | |
[16k, 32k) 3 |@ |
[32k, 64k) 144 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[64k, 128k) 7 |@@ |
[128k, 256k) 28 |@@@@@@@@@@ |
[256k, 512k) 2 | |
[512k, 1M) 3 |@ |
[1M, 2M) 1 | | Пример датчика USDT
Давайте возьмём этот код на Си и сохраним его в файле tracetest.c:
#include <sys/sdt.h>
#include <sys/time.h>
#include <unistd.h>
#include <stdio.h>
static long
myclock() {
struct timeval tv;
gettimeofday(&tv, NULL);
DTRACE_PROBE1(tracetest, testprobe, tv.tv_sec);
return tv.tv_sec;
}
int
main(int argc, char **argv) {
while (1) {
myclock();
sleep(1);
}
return 0;
} Эта программа выполняется бесконечно, вызывая myclock() раз в секунду. myclock() запрашивает текущее время и возвращает количество секунд с начала эпохи.
Вызов DTRACE_PROBE1 здесь определяет статическую точку трассировки USDT.
- Макрос DTRACE_PROBE1 берётся из sys/sdt.h. Официальный макрос USDT, который делает то же самое, называется STAP_PROBE1 (STAP от SystemTap, который был первым линуксовым механизмом, поддерживаемым в USDT). Но так как USDT совместим с датчиками пользовательского пространства DTrace, DTRACE_PROBE1 — это просто ссылка на STAP_PROBE1.
- Первый параметр — это имя провайдера. Я полагаю, что это рудимент оставшийся от DTrace, потому что не похоже, чтобы bpftrace делал с ним что-то полезное. Однако есть нюанс (который я обнаружил, отлаживая проблему по заявке 328): имя провайдера должно быть идентично имени бинарного файла приложения, иначе bpftrace не сможет найти точку трассировки.
- Второй параметр — это собственное имя точки трассировки.
- Любые дополнительные параметры являются контекстом, предоставляемым разработчиками. Цифра 1 в DTRACE_PROBE1 означает, что мы хотим передать один дополнительный параметр.
Давайте удостоверимся, что sys/sdt.h нам доступен, и соберём программу:
sudo apt install systemtap-sdt-dev
gcc tracetest.c -o tracetest -Wall -gМы поручаем bpftrace вывести PID и «time is [число]» всякий раз, когда достигается testprobe:
sudo bpftrace -e 'usdt:/full-path-to/tracetest:testprobe { printf("%d: time is %d\n", pid, arg0); }'Bpftrace продолжает работать, пока мы нажмём Ctrl-С. Поэтому откроем новый терминал и запустим tracetest там:
# В новом терминале
./tracetest
Вернитесь к первому терминалу с bpftrace, там вы должны увидеть что-то вроде:
Attaching 1 probe...
30909: time is 1549023215
30909: time is 1549023216
30909: time is 1549023217
...
^CПример выделения области памяти с помощью glibc ptmalloc
Я использую bpftrace, чтобы разбираться с тем, почему Ruby использует так много памяти. И в части моего исследования мне требуется понимание того, как аллокатор памяти glibc использует области памяти.
В целях оптимизации многоядерной производительности, аллокатор памяти glibc выделяет несколько «областей» из ОС. Когда приложение запрашивает выделение памяти, аллокатор выбирает область, которая не используется, и помечает часть этой области как «использующуюся». Так как потоки используют различные области, количество блокировок уменьшается, что приводит к улучшению многопоточной производительности.
Но такой подход генерирует много мусора, и похоже, что такое высокое потребление памяти в Ruby именно из-за него. Для того чтобы лучше понять природу этого мусора, я задался вопросом: что вообще значит «выбрать область, которая не используется»? Это может означать одно из:
- При каждом вызове malloc() аллокатор перебирает все области и находит ту, что в данный момент не заблокирована. И только если они все заблокированы, он попытается создать новую.
- При первом вызове malloc() конкретного потока (или при старте потока) аллокатор выберет ту, что в данный момент не заблокирована. И если они все заблокированы, он попытается создать новую.
- При первом вызове malloc() конкретного потока (или при старте потока) аллокатор попытается создать новую область вне зависимости от того, есть ли незаблокированные области. Только если новая область не может быть создана (например, при исчерпании лимита), он будет повторно использовать существующую.
- Вероятно, существует больше опций, которые я не учел.
В документации нет конкретного ответа, какая из этих возможностей позволяет выбрать область, которая не используется. Я изучил исходный код glibc, который предположил, что опция 3 может это сделать. Но я захотел экспериментально проверить, правильно ли я интерпретировал исходный код, без необходимости внесения отладочного кода в glibc.
Вот функция аллокатора памяти glibc, который создает новую область. Но вызывать ее можно только после проверки лимита.
static mstate
_int_new_arena(size_t size)
{
mstate arena;
size = calculate_how_much_memory_to_ask_from_os(size);
arena = do_some_stuff_to_allocate_memory_from_os();
LIBC_PROBE(memory_arena_new, 2, arena, size);
do_more_stuff();
return arena;
}Можно ли использовать uprobes для трассирования функции _int_new_arena? К сожалению, нет. По какой-то причине этот символ не доступен в glibc Ubuntu 18.04. Даже после установки отладочных символов.
К счастью, в этой функции есть USDT-датчик. LIBC_PROBE — это макрос-псевдоним для STAP_PROBE.
Имя провайдера — libc.
Имя датчика — memory_arena_new.
Цифра 2 означает, что есть 2 дополнительных аргумента, заданных разработчиком.
arena — это адрес области, которая была выделена из ОС, а size — её размер.
Прежде чем мы сможем использовать этот датчик, нам нужно обойти проблему 328. Нам нужно создать символическую ссылку с glibc куда-нибудь с именем именно libc, потому что bpftrace ожидает, что имя библиотеки (которое в противном случае было бы libc-2.27.so) будет идентично имени провайдера (libc).
ln -s /lib/x86_64-linux-gnu/libc-2.27.so /tmp/libcТеперь мы поручаем bpftrace прицепиться к USDT датчику memory_arena_new, именем поставщика которого является libc:
sudo bpftrace -e 'usdt:/tmp/libc:memory_arena_new { printf("PID %d: created new arena at %p, size %d\n", pid, arg0, arg1); }'В другом терминале мы запустим Ruby, который создаст три ничего не делающих потока и через секунду завершится. Из-за глобальной блокировки интерпретатора Ruby malloc() не должен вызываться параллельно разными потоками.
ruby -e '3.times { Thread.new { } }; sleep 1' Вернувшись к терминалу с bpftrace, мы увидим:
Attaching 1 probe...
PID 431: created new arena at 0x7f40e8000020, size 576
PID 431: created new arena at 0x7f40e0000020, size 576
PID 431: created new arena at 0x7f40e4000020, size 576Вот ответ на наш вопрос! Каждый раз при создании нового потока в Ruby glibc выделяет новую область безотносительно конкурентности.
Какие доступны точки трассировки? Что я должен трассировать?
Вы можете перечислить всё оборудование, таймеры, kprobe и статические точки трассировки ядра, выполнив команду:
sudo bpftrace -lВы можете перечислить все точки трассировки uprobe (функциональные символы) приложения или библиотеки, выполнив:
nm /path-to-binaryВы можете перечислить все точки трассировки USDT приложения или библиотеки, выполнив следующую команду:
/usr/share/bcc/tools/tplist -l /path-to/binaryКасательно того, какие точки трассировки использовать: тут не помешало бы понимание исходников того, что вы собираетесь трассировать. Я рекомендую вам изучать исходный код.
Совет: структурный формат точек трассировки в ядре
Вот полезная заметка по точкам трассировки ядра. Вы можете проверить, какие доступны поля аргументов, прочитав файл /sys/kernel/debug/tracing/events!
Например, предположим, что вы хотите трассировать вызовы madvise(..., MADV_DONTNEED):
sudo bpftrace -l | grep madvise— скажет нам, что мы можем использовать tracepoint:syscalls:sys_enter_madvise.
sudo cat /sys/kernel/debug/tracing/events/syscalls/sys_enter_madvise/format— даст нам следующую информацию:
name: sys_enter_madvise
ID: 569
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:int __syscall_nr; offset:8; size:4; signed:1;
field:unsigned long start; offset:16; size:8; signed:0;
field:size_t len_in; offset:24; size:8; signed:0;
field:int behavior; offset:32; size:8; signed:0;
print fmt: "start: 0x%08lx, len_in: 0x%08lx, behavior: 0x%08lx", ((unsigned long)(REC->start)), ((unsigned long)(REC->len_in)), ((unsigned long)(REC->behavior))Подпись madvise согласно мануалу: (void *addr, size_t length, int advice). Последние три поля этой структуры соответствуют этим параметрам!
Каково значение MADV_DONTNEED? Судя по grep MADV_DONTNEED /usr/include, оно равняется 4:
/usr/include/x86_64-linux-gnu/bits/mman-linux.h:80:# define MADV_DONTNEED 4 /* Don't need these pages. */Так что наша команда bpftrace становится:
sudo bpftrace -e 'tracepoint:syscalls:sys_enter_madvise /args->behavior == 4/ { printf("madvise DONTNEED called\n"); }'Заключение
Bpftrace прекрасен! Bpftrace — это будущее!
Если вы хотите узнать о нём побольше, то я рекомендую ознакомиться с его руководством, а также с первым постом 2019 года в блоге Брендана Грегга.
Удачной отладки!
