Всем привет! Меня зовут Владимир Касаткин, и я работаю бэкенд-разработчиком в компании ivi.ru, в команде "UX". Цель этой статьи — показать, как мы уменьшили объём клиентской разработки, но при этом увеличили количество проводимых A/B-тестов.
Раньше вся продуктовая разработка была разбита на большие направления ("платформы"): бэкенд, Smart TV, iOS, Android, веб. При этом фичи пилились достаточно долго (по полгода), а побочным эффектом были заметные различия внешнего вида и функционала одной и той же фичи на разных платформах.
Потом нас разбили по маленьким кросс-функциональным командам. Разработка пошла быстрее, костылей и платформенных различий на клиентах становилось всё больше.

Постановка задачи
На тот момент вся компания занималась глобальным редизайном всего продукта, и нам были озвучены следующие требования:
- хотим добавить много новых блоков, поэтому система должна полностью управлять структурой выдачи на клиентах;
- хотим иметь возможность таргетировать выдачу;
- хотим иметь возможность проводить A/B-тесты выдачи.
Это очень справедливые требования, так как на тот момент вся логика по расположению блоков была зашита на клиентах. Например промо-блок нужно прибить к верху экрана, избранное поместить на 3 строчку, и так далее.
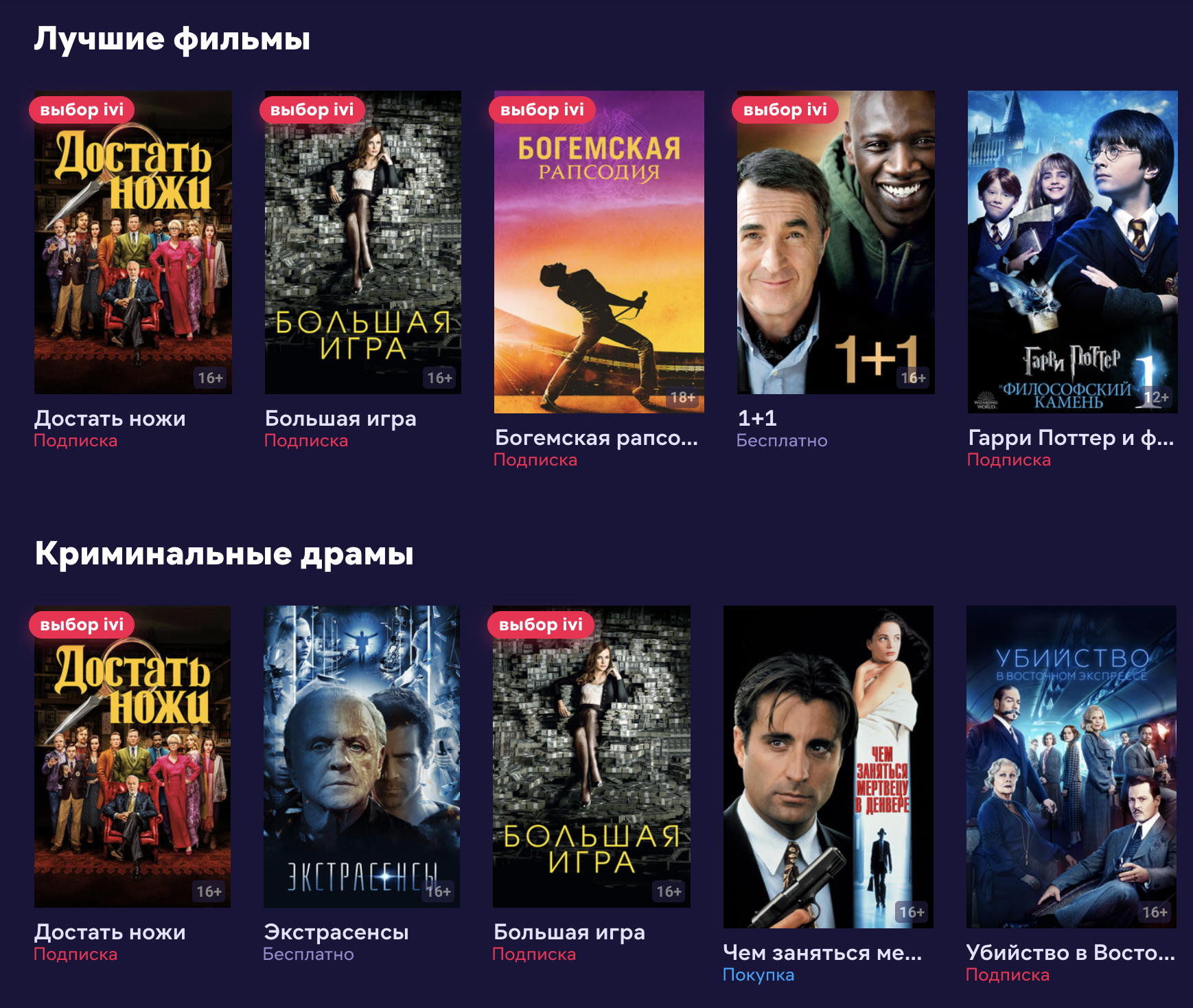
Заодно мы смогли побороть старую проблему на главной странице, где рекомендации были не согласованы друг с другом.
Структура страницы была зашита на клиентах, и загрузка содержимого была разбита на несколько этапов:
- вначале запрашивался список подборок;
- потом запрашивалось содержимое каждой подборки по отдельности.

Схема запросов
Из-за этого рекомендательная система старалась сделать каждую подборку максимально релевантной, и на первых позициях оказывался один и тот же контент. Так происходит из-за большого пересечения контента в подборках между собой. Ведь любой новый фильм может входить сразу в несколько подборок, например: "Новинки 2020", "Претенденты на Оскар", "Лучшая режиссура" и так далее. То есть пользователь мог видеть несколько новых фильмов почти во всех блоках на одной странице.
Варианты реализации
Мы рассмотрели несколько возможных вариантов реализации. Каждый из вариантов сводился к тому, чтобы клиенты получали некий скелет страницы, содержащий в себе указание какие сущности рисовать, какими данными их заполнять. Разница лишь в детализации и скорости работы такой системы.
Вариант 1 — внедрить GraphQL, и пусть клиенты сами разбираются что куда рисовать. Главный минус: мы никогда не работали с GraphQL, все команды могут потратить уйму времени на выяснение нюансов. А ещё всё API придётся строить с нуля и при этом бесконечно поддерживать старое API для старых клиентов.
Вариант 2 — отдавать полотно, содержащие в себе все ответы всех команд, которые клиенты запрашивали раньше по отдельности, с минимальной обёрткой. Это почти как GraphQL, но без GraphQL.
Мы начали разработку второго варианта и столкнулись с тем, что бекенд не справлялся. Клиентам требуется такой объём информации, что собрать её всю в одной команде крайне тяжело. Время ответа новый команды API составляло 1.5 сек для страницы из 15 блоков по 20 единиц контента в каждой.
Есть и нюанс производительности клиентов. Если отдавать всё сразу, то размер ответа для одной страницы из 15 блоков будет весить примерно 3 Мб. Старые Smart TV не могут переваривать столько данных за раз "by design", а пагинация страницы пачками по 1-2 блока приводит к схеме "отдельный запрос на каждый блок".
Вариант 3 — Server Driven UI. В предыдущем варианте у нас есть конечное описание фичей, которые понимает клиент. Что если мы захотим добавить новый абзац текста, или какую-нибудь хитрую кнопку в левом верхнем углу? Мы не управляем вёрсткой, мы не можем внедрить ещё один "такой же" объект, но в другое место на экране. У нас есть только конечный набор вариаций.
Об этом есть хорошие выступления от OZON: (1) и (2). Но мы не пошли этим путём, потому что у нас были жёсткие временные ограничения.
Как устроено
В итоге мы остановились на усреднённом варианте. В новой команде API мы отдаём скелет страницы, а содержимое для блоков клиенты запрашивают отдельно из старых команд API. Весь механизм построен на трёх новых сущностях:
- страница;
- блок;
- таргетинг.
Мы назвали этот механизм pages.
Страница соответствует какому-либо экрану с вертикальным скроллом в приложении и содержит в себе последовательность блоков. Идентификаторы базовых страниц (главная, каталоги, поиск) захардкожены в приложениях. Все дальнейшие манипуляции с выдачей происходят на бекенде исходя из базовых страниц.
У блока есть некий тип (type), который указывает клиенту на используемую структуру данных. Каждому типу блока соответствует конкретная команда API, которую клиент должен запросить, чтобы отобразить содержимое блока. Блок содержит в себе необходимые параметры для запроса этой команды API (request_params). И тут же есть данные для аналитики (groot_params), которые необходимо затрекать при отображении блока.
Пример такого блока:
{
"id": 4121,
"type": "collection",
"title": "Фильмы в 4K UHD",
"hru": "movies-uhd4k",
"groot_identifier": "collection",
"version": 1,
"groot_params": {
"ui_type": "collection",
"ui_id": "collection"
},
"request_params": {
"sort": "priority_in_collection",
"id": 8239,
"withpreorderable": true,
}
}Вообще блок как сущность может содержать в себе следующие свойства:
- заголовок;
- подзаголовок;
- hru (для веба и аналитики);
- абзац текста под содержимым;
- массив кнопок под содержимым (аналог deep-link);
- указание что часть содержимого блока заблокирована (некликабельная);
- является ли блок зацикленной каруселью;
- версию дизайна блока.
Визуальный пример сложного блока:

Таргетинг — внутренняя сущность, служит для описания условий, в которых может отображаться блок. У нас есть таргетинги по территориям, по типам приложений, по идентификаторам A/B-тестов. Таргетинги можно объединять и пересекать друг с другом. Они нужны для выполнения требований правообладателей, а так же для соответствия здравому смыслу (например, нет смысла показывать подборку с боевиками в детском приложении или детском профиле).
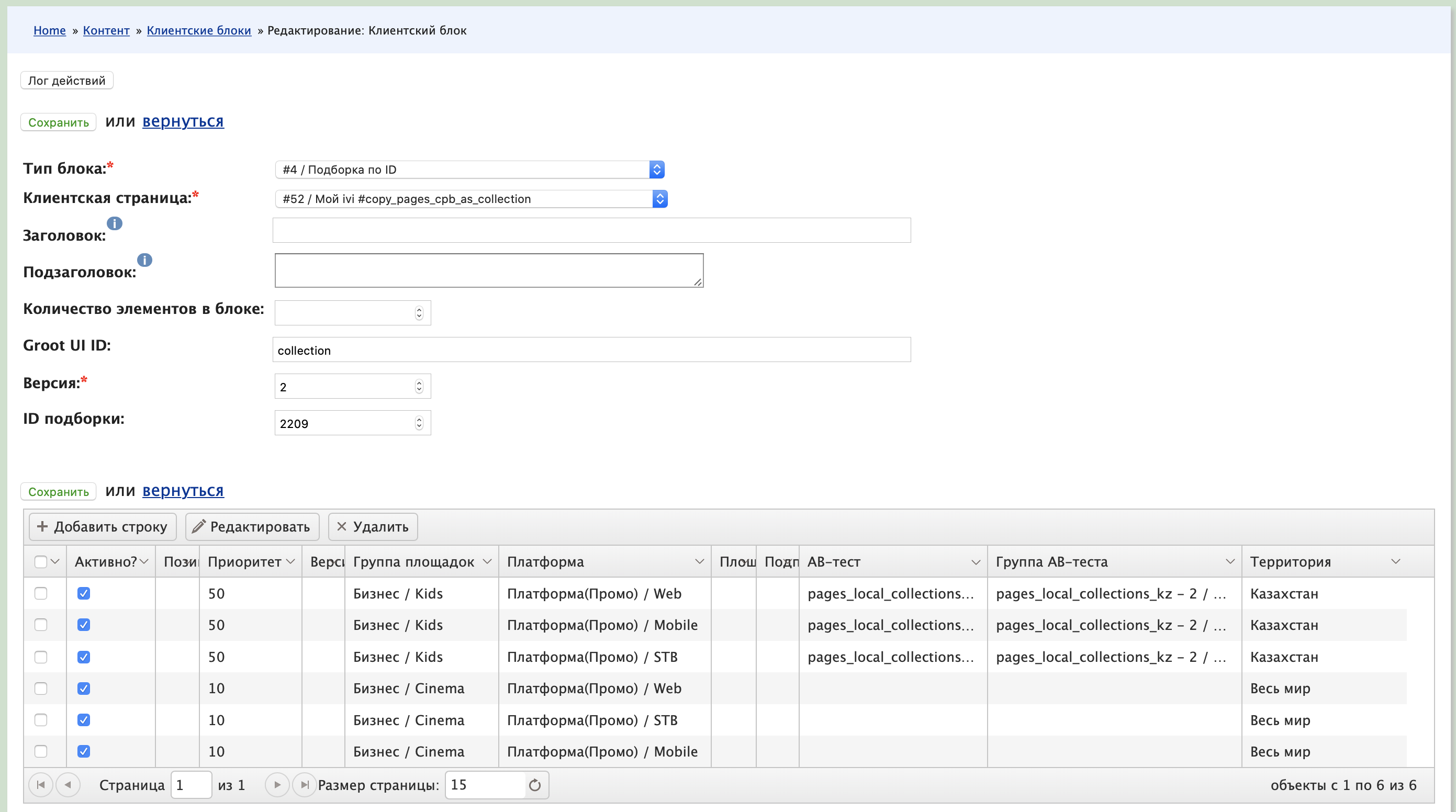
При этом хардкодить новые сущности на бэкенде было не интересно, и мы сразу разрешили управлять ими через админку. На скриншоте показана форма редактирования одного блока. На одной странице таких блоков может быть несколько сотен.
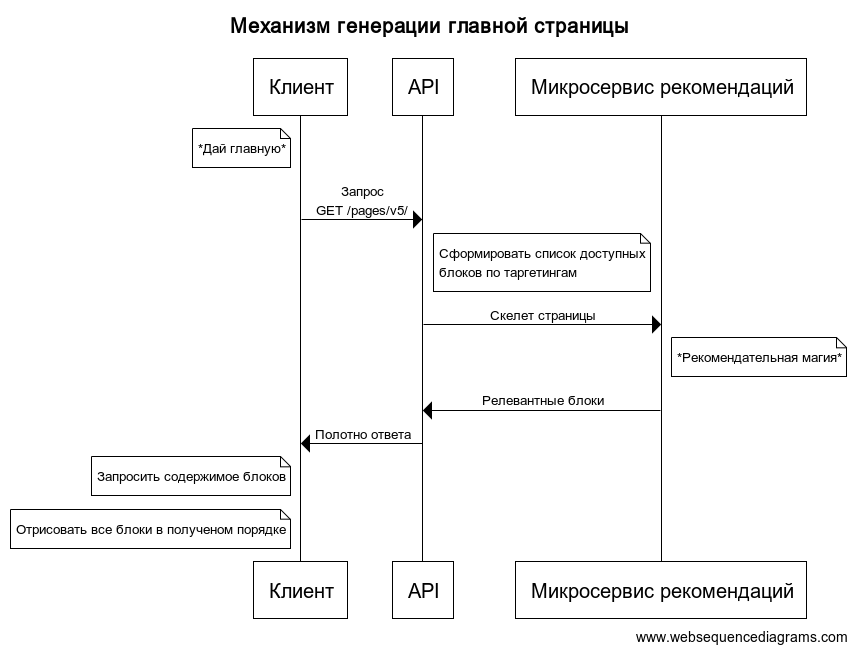
Возвращаясь к примеру с главной страницей сервиса, порядок работы стал следующим:
- клиент запрашивает команду API "pages";
- определяется набор таргетингов пользователя;
- выгружается список блоков, подходящих под таргетинги;
- делается запрос в API рекомендательной системы, содержащий в себе "скелет" страницы;
- рекомендательная система наполняет скелет с учётом контекста;
- для каждого блока проверяется что содержимое есть (запрос соответствующей команды что-то вернёт);
- итоговый ответ отдаётся клиенту.
После этого мы перенесли и другие страницы на новый механизм:
- каталожные страницы: не содержат рекомендаций, но внешне выглядят так же, а значит можно полностью переиспользовать
новый механизм рендера на клиентах; - поиск: содержит много логики, зависящей от контента (например, если ничего не нашлось, то надо показать два других блока).
A/B-тесты
После "расхардкоживания" выдачи мы сделали следующий шаг: создали механизм A/B-тестирования внутри одной "страницы".
Там всё достаточно просто:
- все имеющиеся опциональные параметры запросов перенесли внутрь "блоков";
- редактор может создать такой же блок, но с новыми параметрами (например, не просто подборка, а подборка только с бесплатным контентом);
- редактор указывает новому блоку таргетинг на нужный A/B-тест;
- пользователь получает свой "новый блок".
Ниже примеры A/B-тестов, которые мы запустили таким образом:
- разные варианты названий блоков;
- разное контентное содержимое страниц;
- выключение рекомендаций.
Ограничения pages
Создание абсолютно нового дизайна блока всё равно требует полной разработки. И в нашем случае это будет выглядеть так:
- дизайнеры рисуют новый дизайн;
- разработчики вносят правки в дизайн-систему;
- клиентские разработчики реализуют у себя интерпретацию нового компонента;
- бекенд-разработчик реализует новый блок pages, новую логику для него;
- редактор конфигурирует A/B-тест через админку.
Новый флоу работы
Рассмотрим несколько сценариев.
A) Продакт-менеджер хочет новый A/B-тест с переиспользованием уже имеющихся компонентов
- Заводит в админке новую страницу (копию старой).
- На новой странице модифицирует (редактирует/создаёт/удаляет) нужные блоки.
- Указывает связь со старой страницей, группу A/B-теста, приоритет данного теста.
Итого: тут никакой разработки.
B) Продакт-менеджер хочет A/B-тест с изменением логики поведения
- Добавляем новые параметры запроса в имеющиеся команды API.
- Добавляем новые параметры в имеющиеся на бекенде блоки.
- Конфигурируем A/B-тест.
- Запускаем новую логику без какой-либо клиентской разработки.
Итого: тут только backend-разработка.
C) Продакт-менеджер хочет новый A/B-тест с новыми компонентами
- При необходимости пишем новую команду API, которая выдаёт какое-то новое содержимое. Или меняем версию блока.
- Клиентские разработчики верстают новый блок, интерпретируют новую структуру данных.
- Дальше работа из пункта A или B.
Итого: в этом сценарии участвует вся разработка.
Заключение
Ранее у нас в компании уже был большой этап унификации дизайна и вёрстки компонентов. Это вылилось в создание дизайн-системы: статья об этом, запись выступления.
Сейчас же произошла унификации работы с API. Каждой из клиентских платформ пришлось полностью переписать своё приложение чтобы "расхардкодить" то что было раньше, и иметь возможность рисовать что угодно где угодно, переиспользовать блоки-компоненты.
Нам удалось одновременно получить несколько плюшек:
- Уменьшили отставание/различие между платформами.
- Получили возможность проводить сложные A/B-тесты без клиентских релизов (переиспользование блоков / логики на уровне разных экранов приложения).
- Гибкие экраны, таргетинги по территории, платформе, платности, A/B-тестам и даже возрасту.
- Внедрили больше персонализации и релевантности.
- Провели множество A/B-тестов по составу выдачи, по характеристикам выдачи с минимальными доработками от клиентов. Раньше мы в принципе не занимались этим, т.к. конфигурация одного подобного теста была практически невозможной.
- Редакторы получили возможность управлять логикой отображения целых экранов из админки.
