
Когда данных накапливается очень много, и их начинают запрашивать самые разные системы, управление информацией становится критически важной задачей. В этом посте мы расскажем, как в нашей компании появилась такая задача и почему мы решили создавать хранилище мастер-данных, которое назвали «М.Каталог». Мы расскажем о его архитектуре, уже достигнутых результатах и планах развития. А всех, кто имеет свой опыт построения системы работы с мастер-данными, приглашаем присоединиться к обсуждению вопроса в комментариях.

Идея создания «М.Каталога» появилась еще в 2016 году. На тот момент мы использовали Description Keys, чтобы хранить данные о продуктах с полок магазинов. Любые запросы на изменения нужно было делать через поддержку, а об автоматизации не шло даже речи. По мере увеличения ассортимента, развития новых каналов продаж и подключения внешних источников данных решение все сильнее отставало от бизнеса.
Сначала потребовалось типизировать хранение данных, создать единую точку доступа к ним, внедрить практики управления мастер-данными. Так мы начали создавать «М.Каталог» — хранилище потребительской информации о каждом товаре. За счет интеграции с другими информационными системами оно обеспечивает единое представление характеристик всех товаров в эталонном формате, исключая ошибки.
Единый репозиторий помогает ускорить процесс обновления данных и обмена информацией о товарах с внутренними системами, поставщиками и маркетплейсами. Чтобы система была максимально полезной, мы расширили функциональность для хранения и обработки других сущностей — подборок товаров по моделям и общим характеристикам, SEO-коллекций (например, телевизоры на Android, красные утюги, смартфоны с мощной батареей и так далее).
Однако, теперь мы снова стоим на периферии и понимаем, что бизнес очень быстро меняется — мы перешли на продуктовый подход, объединяем разные каналы продаж в единое OneRetail-пространство, автоматизируем процессы принятия решений на основе глубинной аналитики.
В рамках этой стратегии мы развиваем М.Каталог в полноценный PIM, реализуем возможность выстраивать гибкий и модульный процесс управления мастер-данными по продуктам.
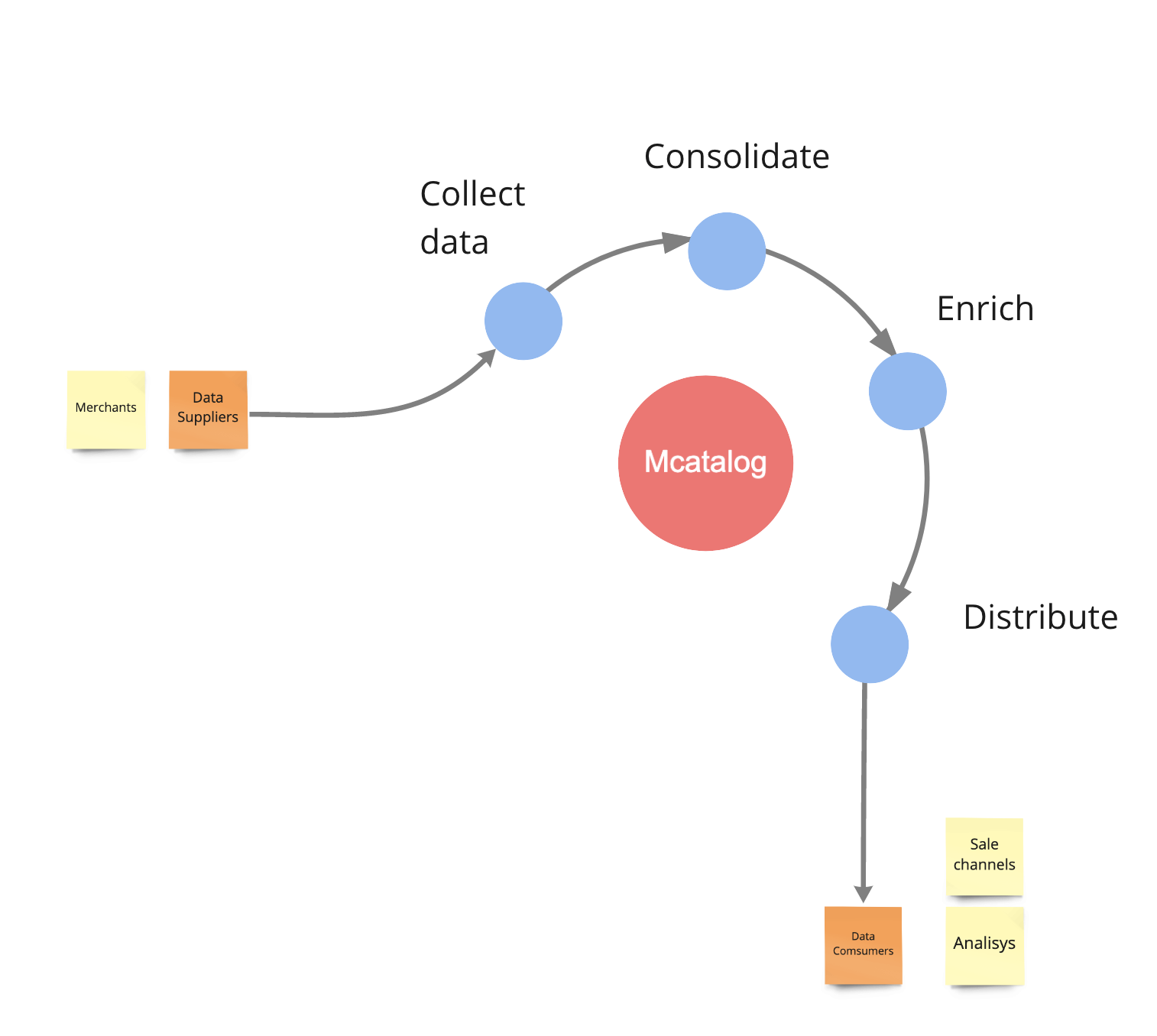
От старой архитектуры к новой
В процессе развития нового решения мы ушли от старой модели взаимодействия систем. На схеме ниже показано, как данные о продуктах попадали в различные информационные системы компании изначально.
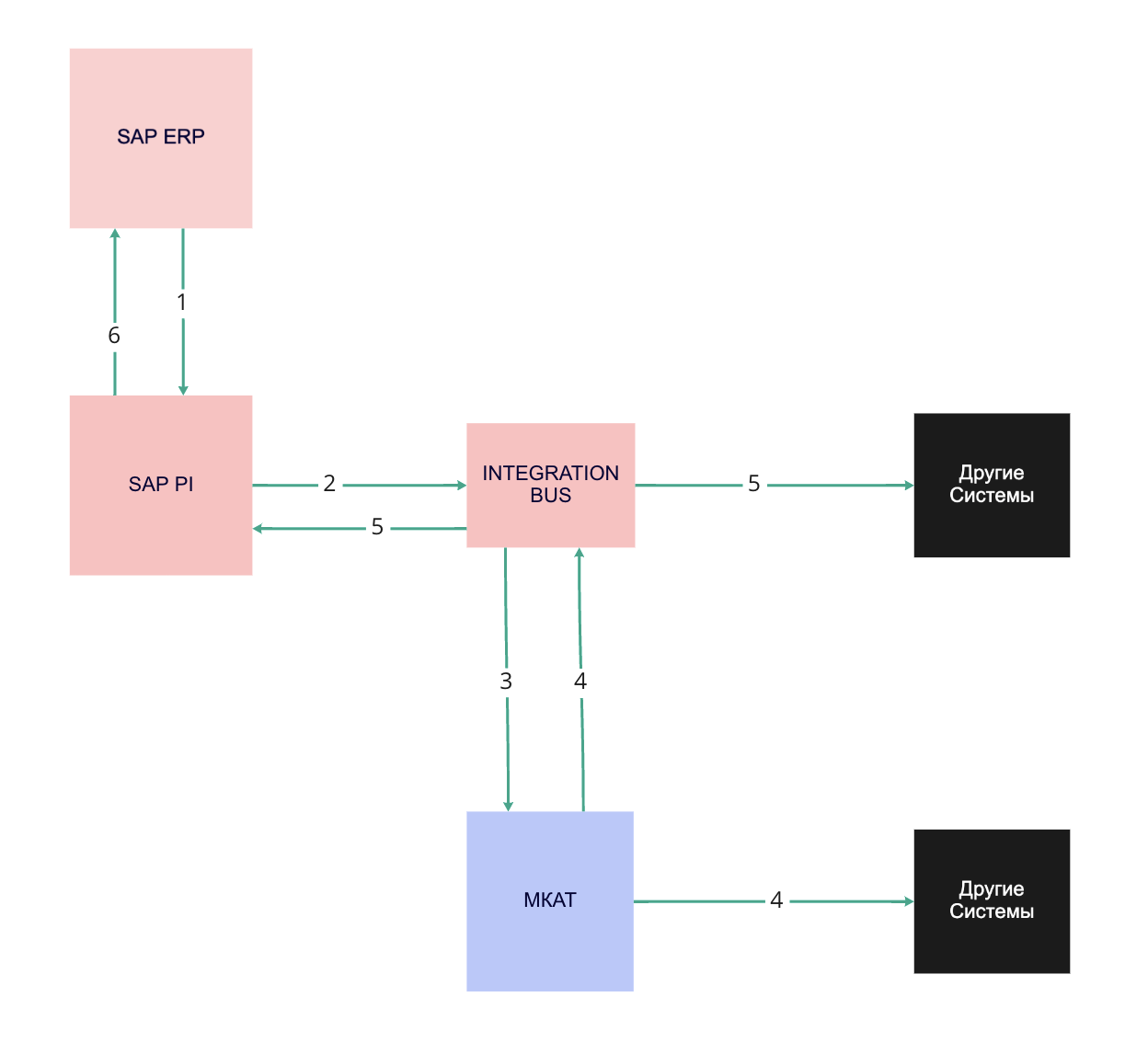
Товары заводились через ERP-систему, что создавало сложный flow данных — информация проходила долгий путь через множество промежуточных систем прежде чем попасть на сайт, логика управления продуктами была «размазана» по разным системам, что тоже усложняло процесс.
Новая модель, мастер-дата менеджмент (PIM), подразумевает, что «М.Каталог» полностью отвечает за управление мастер-данными и является единым «местом правды» по продуктам.
Такой подход решает часть ключевых проблем. Во-первых, логика управления мастер-данных не распределена по разным системам, а соответственно, стала проще, меньше точек отказа и выше скорость доставки данных конечному пользователю.
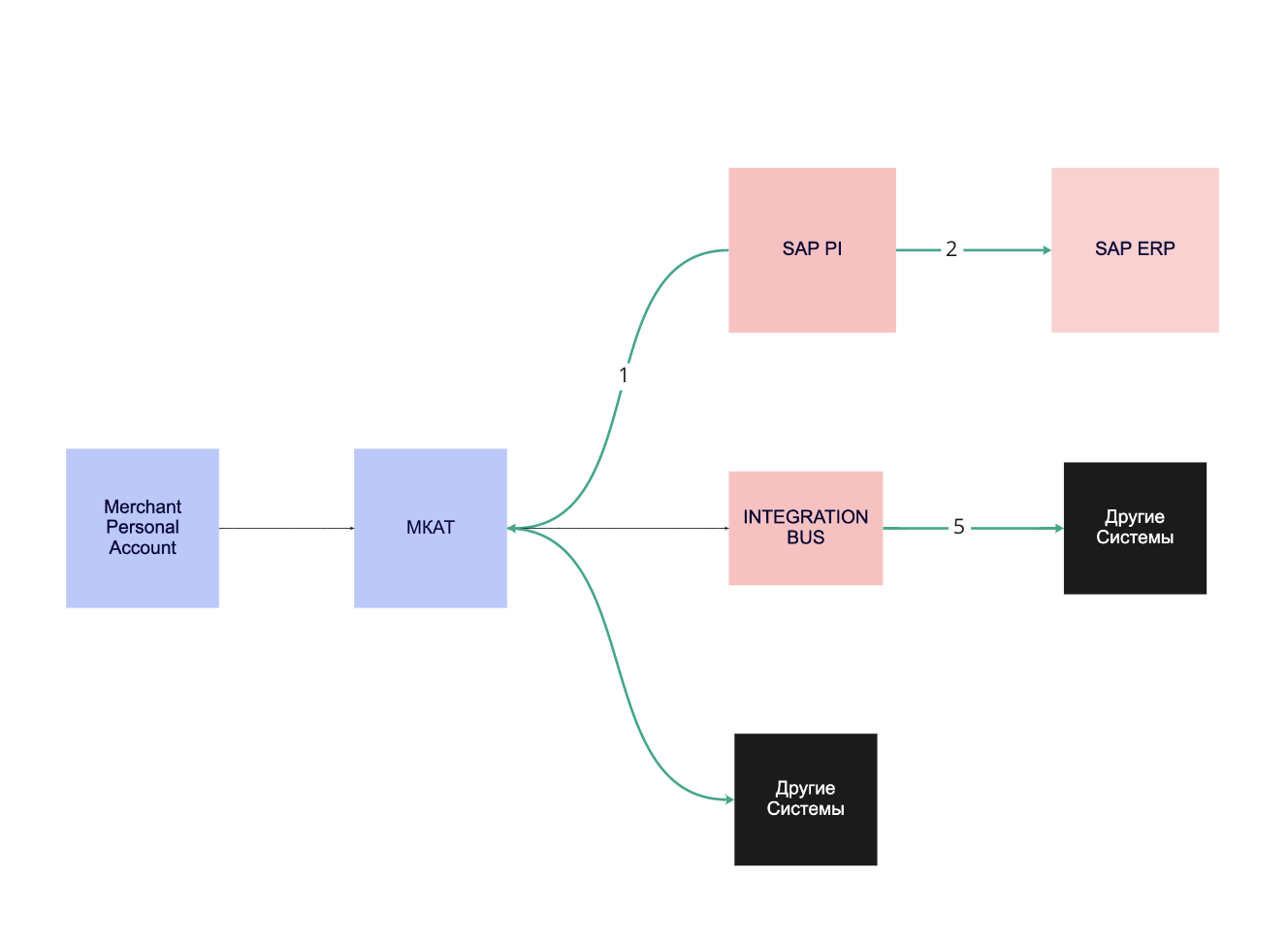
Во-вторых, процесс стал более гибким, повысилось качество данных.

Продукт, как сущность легко поддается конвейеризации, что позволяет выстраивать понятный и отлаженный процесс, увеличить скорость производства продуктов, гибко расширять функциональность конвейера.
Давайте рассмотрим основные компоненты конвейера:

Обработка и манипуляции над продуктом:
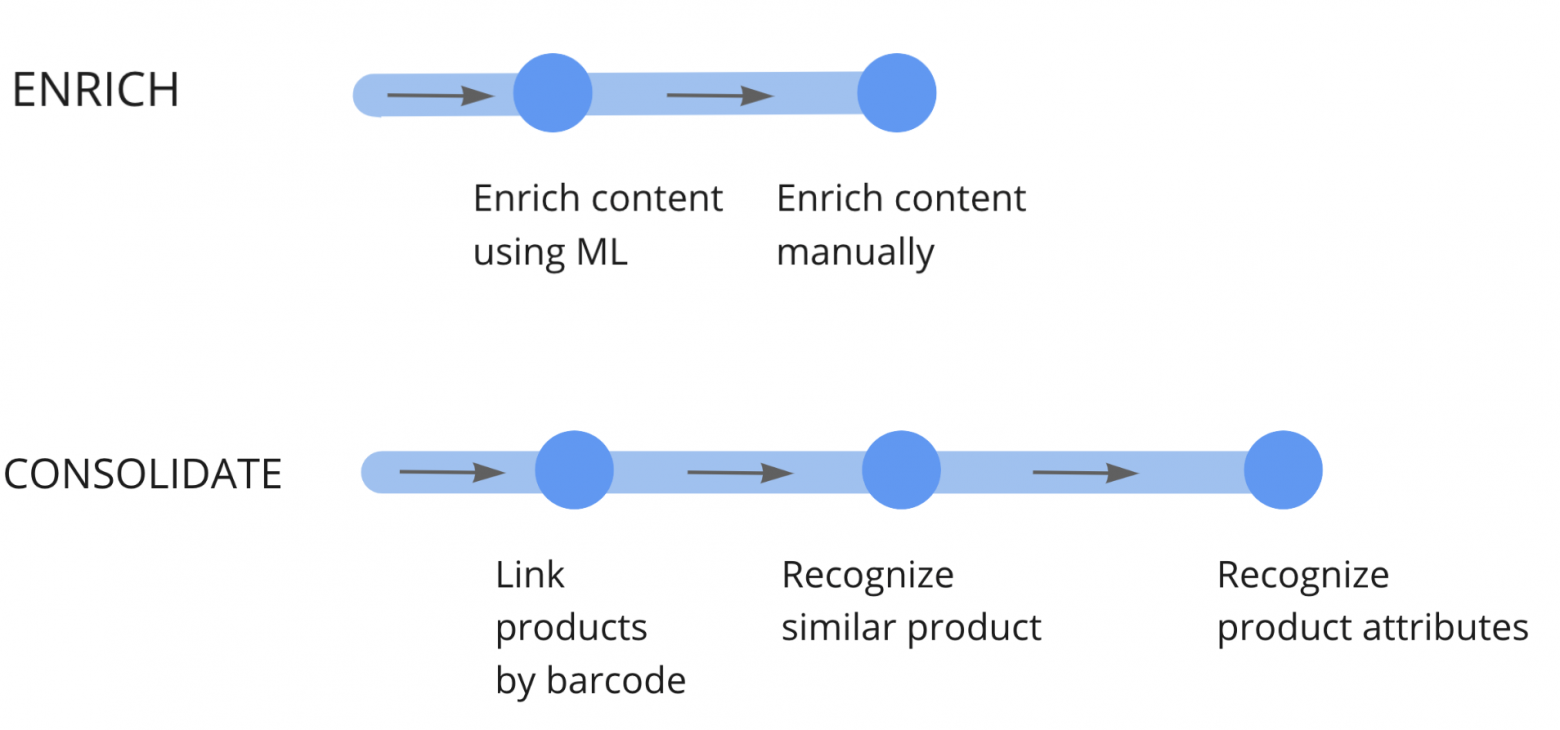
Механизмы получения и отправки данных:


Такой flow позволяет внедрять новые промежуточные обработки, а также механизмы получения и отправки данных.
Наконец, «М.Каталог» поддерживает создание real-time интеграций (или Near-Real-Time). Интеграции с обновлением данных в реальном времени позволят увеличить скорость распространения данных, позволив снизить time2market.
Также потребитель может подписаться на обновления тех блоков данных, которые ему необходимы. Для интеграции с легаси-системами используются адаптеры. Впрочем, мы не планируем плодить количество адаптеров — скорее будем избавляться от старых по мере доработки прочих элементов инфраструктуры.
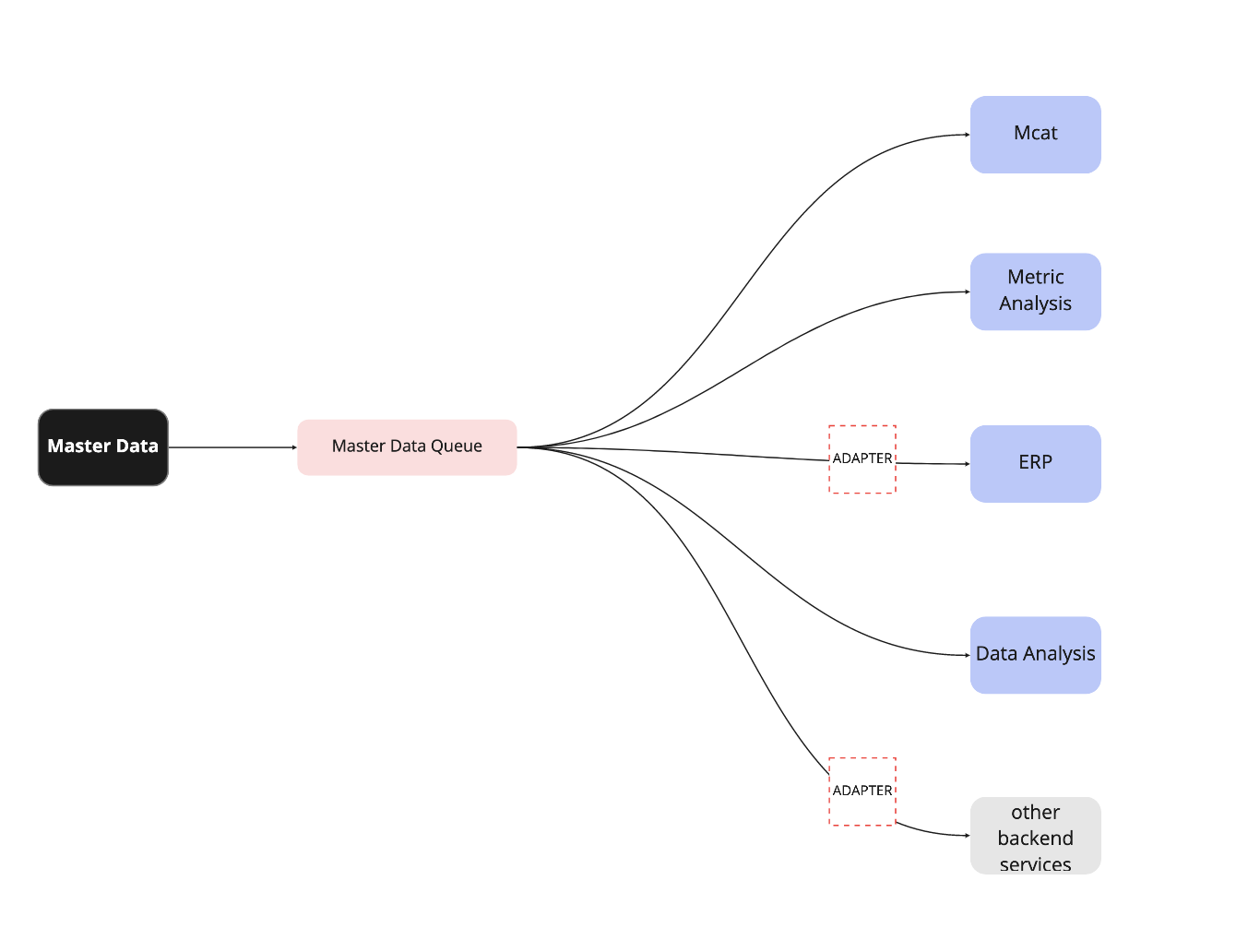
Решая проблему скорости передачи данных, мы остановились на Near-Real-Time + Event-Carried State Transfer.
— Near-Real-Time — псевдо-реалтайм — обновление с заданной частотой. Такой подход позволит регулировать нагрузку на потребителей данных.
Для обеспечения распределенных транзакций используется паттерн TransactionOutbox, который по сути является Near-Real-Time.
— Event-Carried State Transfer — данный подход заключается в передаче измененой сущности целиком, в отличие от обмена оповещениями, которые носят исключительно уведомительный характер.
Про время доставки пользователю
Чем раньше продукт попадает на «витрину», тем раньше мы сможем продавать этот продукт. time2market одно из ключевых value, которые может дать PIM система. Мы не можем позволить себе такой сложный flow для продукта.
Монолит или микросервисы
“Вне зависимости от наших вкусов и пожеланий НЕЛЬЗЯ начинать новый проект сразу с использованием микросервисной архитектуры. Вначале нужно сосредоточиться на понимании задачи и на способе её достижения, не тратя ресурсы на преодоление огромной сложности создания экосистемы микросервисов”. Ребекка Парсонс, Саймон Браун
Система в продуктиве уже 3 года и достаточно хорошо видно все проблемы, связанные с монолитной архитектурой.
Домен мастер-данных по продуктам — сущность довольно комплексная и включает в себя большое количество поддоменов. Мы имеем достаточно внушительный монолит, проблемы с масштабируемостью и расширением функционала.

Эту проблему можно решить, разделив монолит на микросервисы. При этом сами сервисы будут делится по группам, исходя из функциональной ответственности:
1) Data Access Layer (Core services) — дата-центричные сервисы, отвечающий за конкретный домен мастер-данных. Реализовывает легковесный API для чтения/изменения данных. Отвечает за валидацию мастер-данных, а также дистрибуцию изменений в очередь.
2) Business Logic Services (Business services) — бизнес-специфичные сервисы.
Реализовывают логику взаимодействия с Core сервисами.
3) Front services — сервисы, ответственные за приведение мастер-данных к необходимому для отображения на конкретном фронте виде.


Это разделение позволит нам уменьшить связанность сервисов и решить проблемы масштабируемости и расширяемости. Поскольку в «М.Каталоге» практически нет кросс-доменных изменений, проблема поддержки распределенных транзакций решается классической для микросервисов связкой паттернов Saga + Transaction Outbox.
Общая архитектура
Обобщенное разделение на функциональные компоненты:

● UI-tool —- интерфейс для пользователя, через который можно работать с данными о продуктах.
● Merchant Account — личный кабинет поставщика, через который можно заносить данные в систему.
● Product Factory — кластер сервисов, отвечающих за имплементацию логики конвейера продуктов.
● Master Data — сервисы управления мастер-данными.

«М.Каталог» сегодня
Что дает компании «М.Каталог»? Мы используем данные о продуктах для работы бэкэнд- систем. В частности, на базе М.Каталога работают рекомендации. Если кто-то покупает телевизор с креплением 200х200, система предложит только подходящие кронштейны. Если в пульте используются батарейки АА — рекомендованы будут только они.
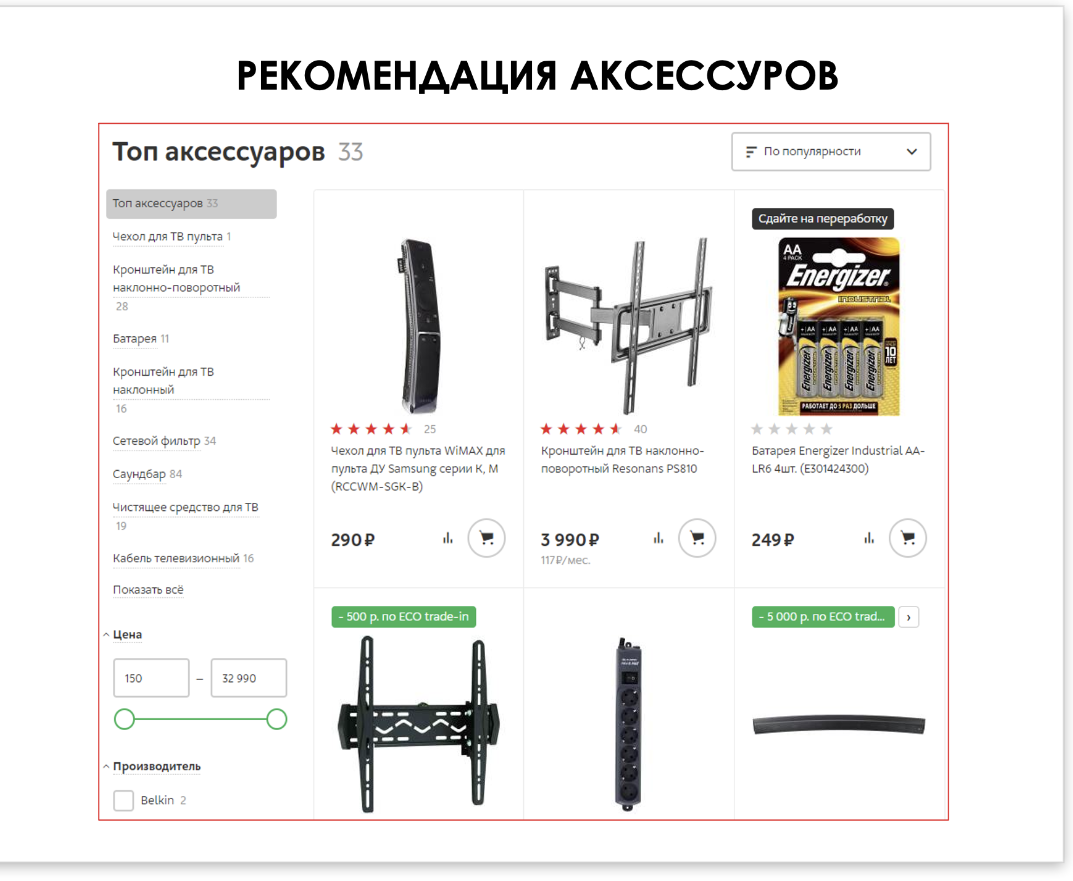
Кроме этого, «М.Каталога» помогает оптимизировать просмотр наиболее важных параметров на мобильных устройствах. Для этого схлопываются несколько строчек, чтобы удобнее было изучить товар на маленьком экране. В «М.Каталоге» также был создан глоссарий, в котором хранится единая терминология для выдачи справки пользователям.
Сегодня в «М.Каталоге» хранится более 20 000 атрибутов, и для каждого уникального типа товаров используется своя инфомодель. При этом описание остается типизированным, так что на всех страницах и во всех системах будут представлены одни и те же характеристики, причем в одном и том же формате.
Эта возможность оказалась очень полезна, когда в прошлом году мы провели интеграцию «М.Каталога» с маркетплейсом СберМегаМаркет. И благодаря типизации атрибуты СберМегаМаркета были полностью синхронизированы с форматами «М.Каталога».
«М.Каталог» также помогает нам строить разные отчеты для разных заказчиков. Например, менеджер по сертификации получает один формат отчета, менеджер склада — другой, менеджер категорий — третий. И это большая ответственность, разрабатывать отчеты, которые должны всем нравиться.
«М.Каталог» завтра
Мы только начали развивать платформу управления мастер-данными, хотим интегрировать «М.Каталог» с другими системами М.Видео-Эльдорадо и обеспечить прямой обмен информацией с партнерами. В ближайшее время мы планируем доделать дополнительный функционал и обеспечить гибкий механизм подписки на мастер-данные, чтобы потребитель (пользователь или система) сам выбирал, какие данные по продукту ему нужны.
Уже сейчас развитие собственного маркетплейса создает новую нагрузку на «М.Каталог». Мы работает на тем, чтобы дополнительно разделить основные Core-сервисы, на которые сегодня приходится 90 % всей работы «М.Каталога».
В ближайшей перспективе развития решения — создание единой корпоративной платформы, в которой «М.Каталог» выполняет роль Common Data Model и хранит данные обо всех товарах, внедрение ИИ для сортировки и обработки данных, создание механизмов сбора и анализа метрик по продуктам, переход на Kubernetes и многое другое, о чем мы расскажем в будущих постах.
Кстати, а вам приходилось как-то модернизировать системы работы с мастер-данными? Какие решения вы для этого применяли? Поделитесь, пожалуйста, своим опытом в комментариях.
