Исторически сложилось так, что наибольшего успеха глубокое обучение достигло в задачах image processing – распознавания, сегментации и обработки изображений. Однако не сверточными сетями едиными, как говорится, живет наука о данных.
Мы попробовали составить гайд по решению задач, связанных с обработкой речи. Самой популярной и востребованной из них является, вероятно, распознавание того, что именно говорят, анализ на семантическом уровне, но мы обратимся к более простой задаче – определению пола говорящего. Впрочем, инструментарий в обоих случаях оказывается практически одинаков.
 / Фотография justin lincoln / CC-BY
/ Фотография justin lincoln / CC-BY
Первым делом нужно разобраться в физике процессов – понять, чем мужской голос отличается от женского. Про устройство речевого тракта у людей можно почитать в обзорах или специальной литературе, но и базовое объяснение «на пальцах» вполне прозрачно: голосовые связки, колебания которых производят звуковые волны до модуляции другими органами речи, у мужчин и женщин имеют различную толщину и натяжение, что ведет к разной частоте основного тона (она же pitch, высота звука). У мужчин она обычно находится в пределах 65-260 Гц, а у женщин – 100-525 Гц. Иными словами, мужской голос чаще всего звучит ниже женского.
Наивно предполагать, что одной лишь высоты звука может быть достаточно. Видно, что для обоих полов эти интервалы довольно сильно перекрываются. Более того, в процессе речи частоту основного тона – вариативный параметр, меняющийся, например, при передаче интонации, – невозможно определить для многих согласных звуков, а алгоритмы ее вычисления не безупречны.
В восприятии человека индивидуальность голоса содержится не только в частоте, но и в тембре – совокупности всех частот в голосе. В каком-то смысле его можно описать с помощью спектра, и тут на помощь приходит математика.
Звук – изменчивый сигнал, а значит его спектр с точки зрения среднего времени вряд ли даст нам что-то осмысленное, поэтому разумно рассмотреть спектрограмму — спектр в каждый момент времени, а также его статистику. Звуковой сигнал делят на перекрывающиеся 25-50 миллисекундные отрезки – фреймы, для каждого из которых при помощи быстрого преобразования Фурье вычисляют спектр, а для него уже после ищутся моменты. Чаще всего используют центроид, энтропию, дисперсию, коэффициенты асимметрии и эксцесса – много всего, к чему прибегают при подсчете случайных величин и временных рядов.
Также используют мел-частотные кепстральные коэффициенты (MFCC). Про них стоит почитать, например, тут. Проблем, которые они пытаются решить, две. Во-первых, восприятие звука человеком не линейно по частоте и по амплитуде сигнала, стало быть, требуется провести некоторое шкалирование (логарифмическое). Во-вторых, сам спектр речевого сигнала меняется по частоте довольно плавно, и его описание можно сократить до нескольких чисел без особенных потерь в точности. Как правило, используют 12 мел-кепстральных коэффициентов, каждый из которых представляет собой логарифм спектральной плотности внутри определенных частотных полос (ее ширина тем выше, чем больше частота).
Именно этот набор признаков (pitch, статистики спектрограммы, MFCC) мы и будем использовать для классификации.

/ Фотография Daniel Oines / CC-BY
Машинное обучение начинается с данных. К сожалению, нет открытых и популярных баз для идентификации пола, таких как ImageNet для классификации изображений или же IMDB – для тональности текстов. Можно взять известную базу для распознавания речи TIMIT, но она платная (что накладывает некоторые ограничения на её публичное использование), поэтому воспользуемся VCTK – 7 Гб базой в свободном доступе. Она предназначена для задачи синтеза речи, но устраивает нас по всем параметрам: там есть звук и данные о 109 спикерах. Для каждого из них мы возьмем по 4 случайных высказывания длительностью 1-5 секунд и попытаемся определить пол их автора.
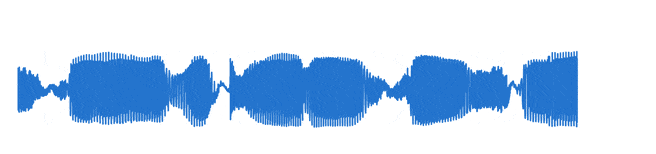
В компьютере звук выводится как последовательность чисел – отклонений мембраны микрофона от равновесного положения. Частота дискретизации чаще всего выбирается из диапазона от 8 до 96 кГц, и для одноканального звука одна его секунда будет представляться как минимум 8 тысячами чисел: любое из них кодирует отклонение мембраны от равновесного положения в каждый из восьми тысяч моментов времени в секунду. Для тех, кто слышал про Wavenet – нейросетевую архитектуру для синтеза звукового сигнала, – это не кажется проблемой, но в нашем случае подобный подход избыточен. Логичным действием на этапе предобработки данных является расчет признаков, которые позволяют существенно снизить количество параметров, описывающих звук. Здесь мы обратились к openSMILE – удобному пакету, способному рассчитать почти все, что имеет отношение к звуку.
Код написан на Python, а реализация – Random Forest, который лучше всего справился с классификацией, – взята из библиотеки sklearn. Также любопытно посмотреть, как с этой задачей справятся нейросети, но о них мы сделаем отдельный пост.
Решить задачу классификации – значит на обучающих данных построить функцию, которая по аналогичным параметрам возвращает метку класса, причем делает это довольно-таки точно. В нашем случае необходимо, чтобы по набору признаков для произвольного аудиофайла наш классификатор отвечал, чья речь в нем записана, мужчины или женщины.
Аудиофайл состоит из множества фреймов, обычно их число намного больше числа обучающих примеров. Если мы будем обучаться на совокупности фреймов, то едва ли получим что-то стоящее – число параметров разумно уменьшить. В принципе, можно классифицировать каждый фрейм по отдельности, но из-за выбросов конечный результат будет тоже не слишком воодушевляющим. Золотой серединой является подсчет статистик признаков по всем фреймам в аудиофайле.
Кроме того, нам необходим алгоритм валидации классификатора – следует убедиться, что он все делает правильно. В задачах обработки речи считается, что обобщающая способность модели низкая, если она хорошо работает не для всех спикеров, а только для тех, на которых обучалась. В противном случае говорят, что модель является т.н. speaker free, и это само по себе неплохо. Чтобы проверить этот факт, достаточно разбить спикеров на группы: на одних обучиться, а на остальных – проверить точность.
Так мы и поступим.
Таблица с данными хранится в файле data.csv, столбцы подписаны в первой строчке, при желании ее можно вывести на экран или посмотреть вручную.
Подключаем нужные библиотеки, читаем данные:
Сейчас нужно организовать процедуру кросс-валидации по спикерам. Встроенный в sklearn итератор GroupKFold работает следующим образом: каждая точка в выборке относится к какой-либо группе, в нашем случае – к одному из спикеров. Множество всех спикеров разбивается на равные части и последовательно исключается каждая из них, на оставшихся обучается классификатор и запоминается точность на выкинутой. За точность классификатора берется средняя по всем частям точность.
Когда все готово, можно ставить эксперименты. Сначала попробуем классифицировать фреймы. На вход классификатору подается вектор признаков, а выходная метка совпадает с меткой файла, из которого взят текущий фрейм. Сравним классификацию отдельно по частоте и по всем признакам (частота + спектральные + mfcc):
Ожидаемо мы получили невысокую точность – 66 и 73% верно классифицированных фреймов. Не густо, ненамного лучше, чем случайный классификатор, который дал бы порядка 50%. В первую очередь такая низкая точность связана с наличием мусора в выборке – для 64% фреймов не удалось посчитать частоту основного тона. Причин может быть две: фреймы либо не содержали речь совсем (тишина, вздохи), либо были составными частями согласных звуков. И если первые можно отбраковать безнаказанно, то вторые – с оговорками: мы считаем, что по звуковым фреймам нам удастся корректно разделять мужскую и женскую речь.
На самом деле хочется классифицировать не фреймы, а аудиофайлы целиком. Можно вычислить разнообразные статистики от временных последовательностей признаков, а затем классифицировать уже их:
Теперь каждый аудиофайл представляется вектором. Мы считаем среднее, дисперсию, медианное и экстремальные значения признаков и классифицируем их:
97,2% — уже совсем другое дело, вроде бы всё здорово. Осталось отбросить мусорные фреймы, пересчитать статистики и радоваться результату:
Ура, планка в 98.4% достигнута. Подбором параметров модели (и выбором самой модели), наверное, можно увеличить и это число, но качественно новых знаний мы не получим.
Машинное обучение в обработке речи – объективно сложно. Решение «в лоб» в большинстве случаев оказывается в итоге далеким от желаемого, и часто приходится дополнительно «наскребать» по 1-2% точности, меняя что-то, казалось бы, малозначимое, но обоснованное физикой или математикой. Строго говоря, этот процесс можно продолжать бесконечно, но…
В следующей и последней части нашего вводного гайда мы детально рассмотрим, справятся ли нейронные сети с этой задачей лучше, изучим разные постановки эксперимента, архитектуры сетей и сопутствующие вопросы.
Над материалом работали:
Оставайтесь с нами.

Мы попробовали составить гайд по решению задач, связанных с обработкой речи. Самой популярной и востребованной из них является, вероятно, распознавание того, что именно говорят, анализ на семантическом уровне, но мы обратимся к более простой задаче – определению пола говорящего. Впрочем, инструментарий в обоих случаях оказывается практически одинаков.
/ Фотография justin lincoln / CC-BYЧто «услышит» наш алгоритм
Характеристики голоса, которые мы будем использовать
Первым делом нужно разобраться в физике процессов – понять, чем мужской голос отличается от женского. Про устройство речевого тракта у людей можно почитать в обзорах или специальной литературе, но и базовое объяснение «на пальцах» вполне прозрачно: голосовые связки, колебания которых производят звуковые волны до модуляции другими органами речи, у мужчин и женщин имеют различную толщину и натяжение, что ведет к разной частоте основного тона (она же pitch, высота звука). У мужчин она обычно находится в пределах 65-260 Гц, а у женщин – 100-525 Гц. Иными словами, мужской голос чаще всего звучит ниже женского.
Наивно предполагать, что одной лишь высоты звука может быть достаточно. Видно, что для обоих полов эти интервалы довольно сильно перекрываются. Более того, в процессе речи частоту основного тона – вариативный параметр, меняющийся, например, при передаче интонации, – невозможно определить для многих согласных звуков, а алгоритмы ее вычисления не безупречны.
В восприятии человека индивидуальность голоса содержится не только в частоте, но и в тембре – совокупности всех частот в голосе. В каком-то смысле его можно описать с помощью спектра, и тут на помощь приходит математика.
Звук – изменчивый сигнал, а значит его спектр с точки зрения среднего времени вряд ли даст нам что-то осмысленное, поэтому разумно рассмотреть спектрограмму — спектр в каждый момент времени, а также его статистику. Звуковой сигнал делят на перекрывающиеся 25-50 миллисекундные отрезки – фреймы, для каждого из которых при помощи быстрого преобразования Фурье вычисляют спектр, а для него уже после ищутся моменты. Чаще всего используют центроид, энтропию, дисперсию, коэффициенты асимметрии и эксцесса – много всего, к чему прибегают при подсчете случайных величин и временных рядов.
Также используют мел-частотные кепстральные коэффициенты (MFCC). Про них стоит почитать, например, тут. Проблем, которые они пытаются решить, две. Во-первых, восприятие звука человеком не линейно по частоте и по амплитуде сигнала, стало быть, требуется провести некоторое шкалирование (логарифмическое). Во-вторых, сам спектр речевого сигнала меняется по частоте довольно плавно, и его описание можно сократить до нескольких чисел без особенных потерь в точности. Как правило, используют 12 мел-кепстральных коэффициентов, каждый из которых представляет собой логарифм спектральной плотности внутри определенных частотных полос (ее ширина тем выше, чем больше частота).
Именно этот набор признаков (pitch, статистики спектрограммы, MFCC) мы и будем использовать для классификации.
/ Фотография Daniel Oines / CC-BY
Решаем задачу классификации
Машинное обучение начинается с данных. К сожалению, нет открытых и популярных баз для идентификации пола, таких как ImageNet для классификации изображений или же IMDB – для тональности текстов. Можно взять известную базу для распознавания речи TIMIT, но она платная (что накладывает некоторые ограничения на её публичное использование), поэтому воспользуемся VCTK – 7 Гб базой в свободном доступе. Она предназначена для задачи синтеза речи, но устраивает нас по всем параметрам: там есть звук и данные о 109 спикерах. Для каждого из них мы возьмем по 4 случайных высказывания длительностью 1-5 секунд и попытаемся определить пол их автора.
В компьютере звук выводится как последовательность чисел – отклонений мембраны микрофона от равновесного положения. Частота дискретизации чаще всего выбирается из диапазона от 8 до 96 кГц, и для одноканального звука одна его секунда будет представляться как минимум 8 тысячами чисел: любое из них кодирует отклонение мембраны от равновесного положения в каждый из восьми тысяч моментов времени в секунду. Для тех, кто слышал про Wavenet – нейросетевую архитектуру для синтеза звукового сигнала, – это не кажется проблемой, но в нашем случае подобный подход избыточен. Логичным действием на этапе предобработки данных является расчет признаков, которые позволяют существенно снизить количество параметров, описывающих звук. Здесь мы обратились к openSMILE – удобному пакету, способному рассчитать почти все, что имеет отношение к звуку.
Код написан на Python, а реализация – Random Forest, который лучше всего справился с классификацией, – взята из библиотеки sklearn. Также любопытно посмотреть, как с этой задачей справятся нейросети, но о них мы сделаем отдельный пост.
Решить задачу классификации – значит на обучающих данных построить функцию, которая по аналогичным параметрам возвращает метку класса, причем делает это довольно-таки точно. В нашем случае необходимо, чтобы по набору признаков для произвольного аудиофайла наш классификатор отвечал, чья речь в нем записана, мужчины или женщины.
Аудиофайл состоит из множества фреймов, обычно их число намного больше числа обучающих примеров. Если мы будем обучаться на совокупности фреймов, то едва ли получим что-то стоящее – число параметров разумно уменьшить. В принципе, можно классифицировать каждый фрейм по отдельности, но из-за выбросов конечный результат будет тоже не слишком воодушевляющим. Золотой серединой является подсчет статистик признаков по всем фреймам в аудиофайле.
Кроме того, нам необходим алгоритм валидации классификатора – следует убедиться, что он все делает правильно. В задачах обработки речи считается, что обобщающая способность модели низкая, если она хорошо работает не для всех спикеров, а только для тех, на которых обучалась. В противном случае говорят, что модель является т.н. speaker free, и это само по себе неплохо. Чтобы проверить этот факт, достаточно разбить спикеров на группы: на одних обучиться, а на остальных – проверить точность.
Так мы и поступим.
Таблица с данными хранится в файле data.csv, столбцы подписаны в первой строчке, при желании ее можно вывести на экран или посмотреть вручную.
Подключаем нужные библиотеки, читаем данные:
import csv, os
import numpy as np
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import GroupKFold
# read data
with open('data.csv', 'r')as c:
r = csv.reader(c, delimiter=',')
header = r.next()
data = []
for row in r:
data.append(row)
data = np.array(data)
# preprocess
genders = data[:, 0].astype(int)
speakers = data[:, 1].astype(int)
filenames = data[:, 2]
times = data[:, 3].astype(float)
pitch = data[:, 4:5].astype(float)
features = data[:, 4:].astype(float)Сейчас нужно организовать процедуру кросс-валидации по спикерам. Встроенный в sklearn итератор GroupKFold работает следующим образом: каждая точка в выборке относится к какой-либо группе, в нашем случае – к одному из спикеров. Множество всех спикеров разбивается на равные части и последовательно исключается каждая из них, на оставшихся обучается классификатор и запоминается точность на выкинутой. За точность классификатора берется средняя по всем частям точность.
def subject_cross_validation(clf, x, y, subj, folds):
gkf = GroupKFold(n_splits=folds)
scores = []
for train, test in gkf.split(x, y, groups=subj):
clf.fit(x[train], y[train])
scores.append(clf.score(x[test], y[test]))
return np.mean(scores)Когда все готово, можно ставить эксперименты. Сначала попробуем классифицировать фреймы. На вход классификатору подается вектор признаков, а выходная метка совпадает с меткой файла, из которого взят текущий фрейм. Сравним классификацию отдельно по частоте и по всем признакам (частота + спектральные + mfcc):
# classify frames separately
score_frames_pitch = subject_cross_validation(RFC(n_estimators=100), pitch, genders, speakers, 5)
print 'Frames classification on pitch, accuracy:', score_frames_pitch
score_frames_features = subject_cross_validation(RFC(n_estimators=100), features, genders, speakers, 5)
print 'Frames classification on all features, accuracy:', score_frames_featuresОжидаемо мы получили невысокую точность – 66 и 73% верно классифицированных фреймов. Не густо, ненамного лучше, чем случайный классификатор, который дал бы порядка 50%. В первую очередь такая низкая точность связана с наличием мусора в выборке – для 64% фреймов не удалось посчитать частоту основного тона. Причин может быть две: фреймы либо не содержали речь совсем (тишина, вздохи), либо были составными частями согласных звуков. И если первые можно отбраковать безнаказанно, то вторые – с оговорками: мы считаем, что по звуковым фреймам нам удастся корректно разделять мужскую и женскую речь.
На самом деле хочется классифицировать не фреймы, а аудиофайлы целиком. Можно вычислить разнообразные статистики от временных последовательностей признаков, а затем классифицировать уже их:
def make_sample(x, y, subj, names, statistics=[np.mean, np.std, np.median, np.min, np.max]):
avx = []
avy = []
avs = []
keys = np.unique(names)
for k in keys:
idx = names == k
v = []
for stat in statistics:
v += stat(x[idx], axis=0).tolist()
avx.append(v)
avy.append(y[idx][0])
avs.append(subj[idx][0])
return np.array(avx), np.array(avy).astype(int), np.array(avs).astype(int)
# average features for each frame
average_features, average_genders, average_speakers = make_sample(features, genders, speakers, filenames)
average_pitch, average_genders, average_speakers = make_sample(pitch, genders, speakers, filenames)Теперь каждый аудиофайл представляется вектором. Мы считаем среднее, дисперсию, медианное и экстремальные значения признаков и классифицируем их:
# train models on pitch and on all features
score_pitch = subject_cross_validation(RFC(n_estimators=100), average_pitch, average_genders, average_speakers, 5)
print 'Utterance classification on pitch, accuracy:', score_pitch
score_features = subject_cross_validation(RFC(n_estimators=100), average_features, average_genders, average_speakers, 5)
print 'Utterance classification on features, accuracy:', score_features97,2% — уже совсем другое дело, вроде бы всё здорово. Осталось отбросить мусорные фреймы, пересчитать статистики и радоваться результату:
# skip all frames without pitch
filter_idx = pitch[:, 0] > 1
filtered_average_features, filtered_average_genders, filtered_average_speakers = make_sample(features[filter_idx], genders[filter_idx], speakers[filter_idx], filenames[filter_idx])
score_filtered = subject_cross_validation(RFC(n_estimators=100), filtered_average_features, filtered_average_genders, filtered_average_speakers, 5)
print 'Utterance classification an averaged features over filtered frames, accuracy:', score_filteredУра, планка в 98.4% достигнута. Подбором параметров модели (и выбором самой модели), наверное, можно увеличить и это число, но качественно новых знаний мы не получим.
Заключение
Машинное обучение в обработке речи – объективно сложно. Решение «в лоб» в большинстве случаев оказывается в итоге далеким от желаемого, и часто приходится дополнительно «наскребать» по 1-2% точности, меняя что-то, казалось бы, малозначимое, но обоснованное физикой или математикой. Строго говоря, этот процесс можно продолжать бесконечно, но…
В следующей и последней части нашего вводного гайда мы детально рассмотрим, справятся ли нейронные сети с этой задачей лучше, изучим разные постановки эксперимента, архитектуры сетей и сопутствующие вопросы.
Над материалом работали:
- Григорий Стерлинг, математик, ведущий эксперт Neurodata Lab по машинному обучению и анализу данных
- Ева Казимирова, биолог, физиолог, эксперт Neurodata Lab в области акустики, анализа голоса и речевых сигналов
Оставайтесь с нами.
