Я пришел в Wish 2,5 года назад, дела в компании шли отлично. Наше приложение было в топе в iOS и Android магазинах и продавало более 2 миллионов товаров в день.
Мало кто верил, что можно построить большой бизнес, продавая дешевые товары. Однако, используя данные, Wish смогли бросить вызов этим сомнениям. Аналитика данных всегда была у нас в крови.
Но когда наш бизнес стал расти огромными темпами, мы не были к этому готовы, обнаружилось множество проблем с аналитикой. Каждая команда внутри компании стала нуждаться в срочной поддержке в работе с данными и многое упускала из виду в своем поле деятельности. В то время наши аналитические возможности еще только зарождались и не могли удовлетворить все растущий спрос.
В данном посте я расскажу о том, какие уроки мы извлекли за это время, а также распишу верный путь для компаний, находящихся в поисках способов масштабирования их аналитических функций.
Проблем было много, в первую очередь с доступом к данным. Единственными, кто мог извлекать данные и строить отчеты были инженеры, работающие над продуктом, а так как инфраструктура данных была совсем «сырой», мы не могли нанять аналитиков в помощь. В результате выполнение запросов данных и построение отчетов могли проходить неделями.
В течение следующих 2 лет мы работали не покладая рук, чтобы выстроить аналитику в компании. Мы с нуля построили пайплайн данных, который позволяет инженерам, аналитикам и data scientist-ам выполнять ETL-процессы надежно и безопасно для своей работы. Хранилище данных было собрано в Redshift и BigQuery с основными таблицами, которые поддерживают вторичные таблицы, используемые аналитиками. Также мы развернули BI платформу Looker, которая теперь используется в качестве источника данных компании, а это значит более чем 200 сотрудниками на трех континентах.
На сегодняшний день более 30 человек в Wish занимаются аналитикой. В этом году мы планируем удвоить их количество. Мы уверены, что теперь наши процессы и системы хорошо масштабируемы, а значит мы готовы к будущим вызовам.
Начнем с ранних деньков. Когда я пришел в компанию, было совершенно очевидно, что у нас огромные проблемы с тем, как мы работаем с данными:
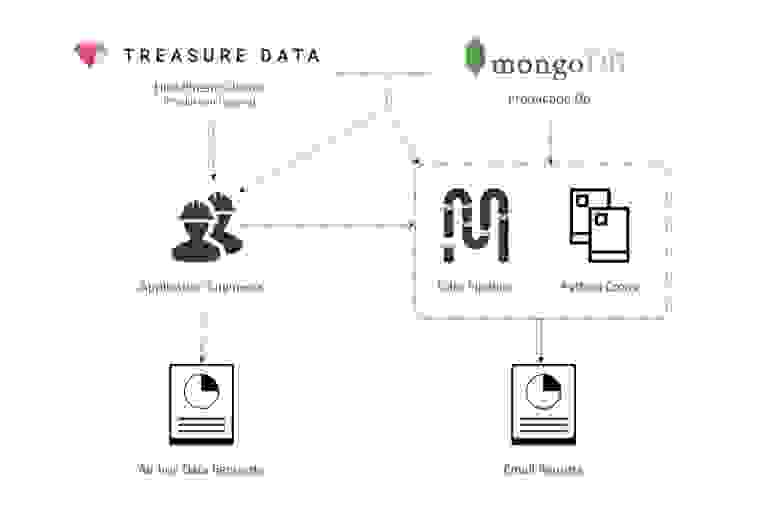
Первоначальная система данных
Во-первых, создание запросов данных было кошмарным, несмотря на то, что к тому времени наши MongoDB кластеры были одними из крупнейших в мире (топ 3). В целях надежности наша команда по инфраструктуре отключила запросы агрегирования в Mongo, то есть теперь агрегирование данных должно выполняться на клиентской стороне (в Python скрипте). Вместо простых SUM и GROUP BY SQL-запросов мы писали код в Python скрипте, который по очереди обрабатывал каждый из миллионов документов, храня результаты в словаре, в который вложены другие словари. Стоит ли говорить, что такие запросы было тяжело писать, а запускались они вечность.
Ситуация с пайплайном данных была немногим лучше. Система была слишком проста, и в ней не было ключевых функций, которые бы позволяли управлять огромным количеством ETL-задач, к примеру, возникали проблемы с управлением зависимостями. Поток сбоев и ошибок практически не прекращался, и в результате весь рабочий день приходилось посвящать именно борьбе с ними.
Очевидно, что было необходимо переделать инфраструктуру, перенести пайплайн данных на более масштабируемую и надежную платформу, а также построить отдельное хранилище данных для аналитиков, чтобы ускорить создание запросов и отчетов.
Тот факт, что я был одним из всего двух сотрудников в компании с фокусом на аналитику, значительно усложнял задачу. Я разрывался между поддержкой текущего пайплайна, созданием огромного количества отчетов и запросов данных, а еще нужно было выкроить время для перестройки инфраструктуры. Таким образом, я периодически переключался с data engineering-а на аналитические задачи и обратно, то есть занимался двумя областями одновременно, каждая из которых требует особые навыки и стиль мышления. Пытаясь успеть везде, я не уверен, что хорошо справлялся и с тем, и другим.
Наконец, нам удалось нанять наших первых, серьезных аналитиков данных, это нас и спасло. Нам повезло, что они были достаточно технически подкованы, чтобы писать ad-hoc запросы для MongoDB и работать с нашими отчетами на Python. Также они были достаточно опытны, чтобы разбираться с незадокументированными и новыми источниками данных. Это значит, что они могли бы взять на себя часть обязанностей, под завалом которых я оказался.
В течение следующего года в Wish мы выстраивали инфраструктуру. Пока аналитики занимались обработкой запросов данных со всех уголков компании, я мог сконцентрироваться на построении новой системы.
Невозможно представить, чтобы кто-то из нашей пары «я — команда аналитиков» протянул в компании долго, не будь другого. Две проблемы, над которыми мы работали: извлечение данных / построение отчетов и улучшение инфраструктуры были по-своему сложны и требовали настолько разного рода умений, что каждый из нас не мог быть достаточно хорош, чтобы выполнять работу другого.
Главное, что стоит извлечь из этой части — создавая команду по работе с данными, необходимо иметь и data engineer-а, и аналитика(ов). Без как минимум одного аналитика инженер данных будет тонуть в создании отчетов и извлечении данных, а без data engineer-а аналитики, в свою очередь, перегорят от количества запросов из разных сложных источников данных. В итоге и тот, и другой должны быть опытны и терпеливы в ожидании, пока достойная система будет построена.
В следующих двух частях я более подробно расскажу о вызовах, с которыми предстоит встретиться аналитикам и инженерам, и как с ними справиться.
Быть одним из первых аналитиков в Wish означало взять на себя огромное количество отчетов и запросов данных. Начнем с отчетов.
Создание отчетов — это система из Python скриптов, которая генерировала HTML email-ы через определенные интервалы времени. Их были тысячи, и они покрывали различные системы и функции внутри компании.
Следить за тем, чтобы скрипты работали, а отчеты отправлялись по расписанию — это работа на полную ставку. Обрабатывать данные и учитывать все возможные ошибки тяжело: опечатки, пропущенные или неполные данные, проблемы с отображением — все это ежедневно мешало нормальной отправке отчетов. В течение недели банально не хватало времени, чтобы исправить все накопившиеся ошибки, поэтому нужно было сортировать их по важности и исправлять лишь наиболее серьезные.
Конечно, просто поддерживать функционирование системы было недостаточно. Рост компании привел к увеличению спроса на новые отчеты. К тому же, мы только наняли нового операционного директора, а это значит, что все наши отчеты об обслуживании клиентов необходимо было переделать. Также мы запустили новые программы для продавцов, такие как Wish Express с 7-дневной доставкой, и каждая из них требовала своего набора отчетов.
Также, помимо отчетов, аналитику нужно было как-то справляться с непрекращающимся потоком запросов данных со всей компании. По опыту мы знали, что скорость поступления этих запросов растёт экспоненциально, поэтому одной из основных задач стали приоритизация наиболее важных запросов и отсеивание ненужных.
Несомненно, это было тяжело. У аналитика всегда был соблазн какие-то вещи сделать наспех, чтобы справиться с огромным объемом работы, что приводило к ошибкам и, соответственно, снижению доверия к нему.
Таким образом, чтобы преуспеть в этой роли, необходимо два навыка:
Ниже мы обсудим эти два навыка в деталях: почему они так сложны на ранних стадиях и как преодолеть эти сложности.
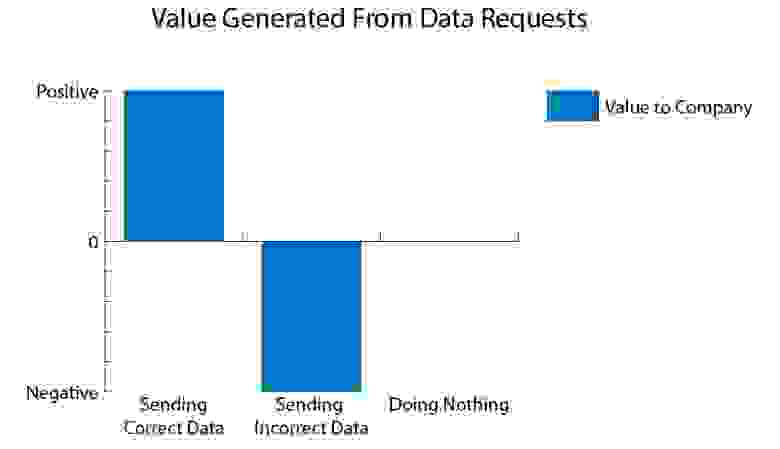
Отправить плохие данные < ничего не делать < отправить хорошие данные
Неопытные аналитики чаще всего пробуют создавать запросы данных, полностью не понимая, как это работает. Для примера, допустим, что нам поступил запрос, получить текущую долю возвращенных товаров. Наивный способ — это найти в модели данных заказы и посмотреть, есть ли у них поле «Возвращен». Затем, отфильтровав по этому критерию все данные за определенный промежуток времени, мы можем посчитать эту долю: # возвратов / # заказов. Затем это число мы и отправляем.
Через какое-то время приходит ответ от начальства: теперь необходимо выяснить, как отличается доля возвращенных товаров для товаров с подтверждением доставки и без нее. Будучи таким же наивным, аналитик применит тот же подход, найдет отдельную модель данных для отслеживания заказов и увидит, что там есть поле «Подтвержденное время доставки», которое можно присоединить к заказам из первой модели данных, используя ключ — id заказа.
Наконец, мы пишем тот же запрос, что и раньше, но с условием наличия / отсутствия времени подтверждения доставки, чтобы получить две метрики:
Затем отправляем. Все довольно просто.
Однако заметили ли вы ошибку?
Для Wish, отмена заказа также считается возвратом товара, а так как отмена означает, что товар еще не доставлен, то такие заказы всегда будут оказываться во второй группе — заказы без подтверждения доставки. Вследствие этого вторая метрика будет сильно завышена, что может привести к неверным управленческим решениям.
Этот пример не выдуман, он действительно случился (к счастью, мы быстро заметили ошибку). Теперь я по опыту знаю, что каждый раз, когда я шел быстрым путем и работал с запросами без понимания самой системы, в итоге я отправлял неправильные числа.
Чтобы успешно избегать таких ловушек, необходим опыт. Всегда, работая с новой метрикой или источником данных, с которым аналитик не знаком, он должен потратить дополнительное время на понимание данных и самой системы. А первым аналитикам в компании это приходилось делать каждый раз, поскольку любая новая задача означала работу с незнакомыми данными.
Опытные аналитики понимают, где не нужно торопиться, даже в условиях огромного давления и срочности.
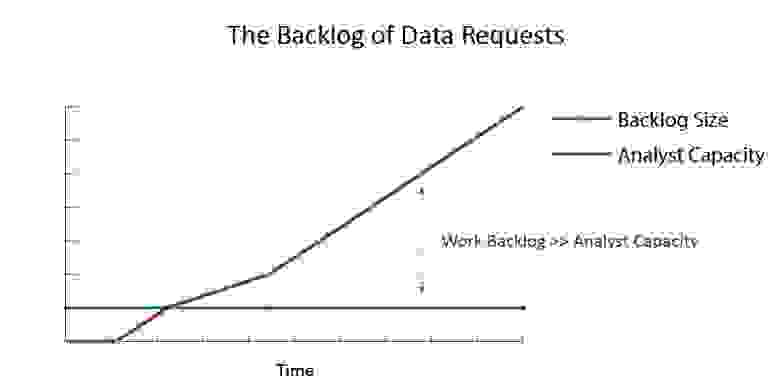
Загруженность аналитиков в стартапах
Раньше в Wish мы были всего лишь группой аналитиков и инженеров, которые должны были поддерживать бизнес с оборотом в несколько миллионов долларов в год. Дело тут даже не в количестве людей, нас могло быть 20, и мы все равно не справлялись бы с огромным количеством данных. Поэтому мы должны были правильно расставлять приоритеты, концентрироваться на самых важных задачах и откладывать все остальное.
Конечно, легче сказать, чем сделать. Почему один запрос важнее другого? Все ли баги исправлены перед отправкой запроса? Какой отдел нуждается в помощи в первую очередь? Чтобы ответить на эти вопросы, каждый запрос оценивается по двум критериям:
Во-первых, перед началом работы над запросом необходимо оценить его влияние, то есть подумать, как эта задача повлияет на компанию. К примеру, подходящие вопросы: какие области нашего бизнеса эта задача затрагивает и каков размер этих областей? Какова возможная выгода? Какова вероятность успешного выполнения задачи? Важна ли эта задача с точки зрения стратегии компании?
Ответив на эти вопросы, сравниваем оценку важности задачи с объемом работы на ее выполнение. Мы примерно представляли, сколько занимает та или иная задача: исправление бага занимает от половины до целого дня, отчет — от 2 дней до недели, а ad-hoc запрос данных — полдня.
Используя этот фреймворк, мы в Wish следующим образом приоретизировали входящие запросы:
Также, если запрос имеет влияние на бизнес, однако требует больше усилий, чем необходимо, то чаще всего мы урезаем некоторые требования из задачи. Так, если метрику слишком тяжело считать, то мы попросту убираем ее из запроса.
Таким образом, ранжируя задачи по степени важности и фокусируясь на задачах, требующих меньше усилий для достижения большего результата, мы смогли достигнуть многого в условиях критической нехватки времени.
Подводя итоги этой части: запросы данных тяжело обрабатывать, а поступают они с невероятной скоростью. Даже делая все идеально, рано или поздно ты сгоришь. Ни один аналитик не может удерживать такой темп достаточно долго.
Именно поэтому необходимо было взяться за data engineering. Нам нужна была качественная инфраструктура.
MVP (минимальный жизнеспособный продукт) инфраструктуры данных состоит из:
Наличие всех этих элементов приведет к значительному увеличению эффективности. Создание источника данных специально под бизнес-аналитику в Wish привело к тому, что на один запрос стало уходить в 5-7 раз меньше времени. Также это позволило нам снизить требования к техническим навыкам новых аналитиков, что значительно ускорило найм. Теперь они могли прокачать какие-то навыки позже, при необходимости.
Реализовать все это — не только инженерная проблема. Так, нам необходимо было убедить акционеров в покупке готовой BI-платформы, поскольку корпоративная культура Wish направлена на самостоятельную разработку всего, что нужно.
Ниже я опишу, как мы шаг за шагом разрабатывали инфраструктуру, и какие уроки я из этого извлек.

Как уже было сказано, существующий в Wish пайплайн не справлялся, поэтому его перестройка была первостепенной задачей. В качестве базового фреймворка мы выбрали Luigi — ETL инструмент, который лучше по ряду аспектов:
В результате за 2 месяца я перенес более чем 200 ETL job-ов со старой системы на новую вместе с несколькими cron скриптами.
Вот что мне удалось вынести для себя из этого проекта:
Также, главный риск при рефакторинге кода заключается в том, что можно получить еще больше новых багов. Перенося более 200 job-ов на новую платформу, нужно было внимательно проверять систему на наличие багов, иначе все бы развалилось.
Таким образом, самый легкий способ — это постепенно вносить небольшие изменения, которые автоматически проверяются на наличие багов. Принципиальных изменений же следует избегать, пока проект полностью не будет готов. В нашем случае это означает: пропускать / блокировать пайплайны, сравнивая результат их работы со старой системой.
Новая платформа на основе Luigi была довольно примитивной, однако она работала и самостоятельно справлялась с ошибками, а это как раз то, что нам было нужно: система, на которую можно положиться, выстраивая остальные элементы инфраструктуры.
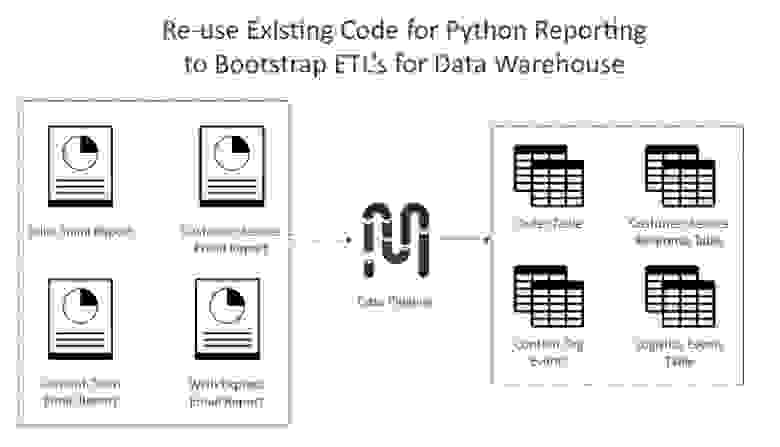
Хранилище данных — это база данных, которая позволяет быстрее писать и запускать аналитические запросы. Обычно в нее входят таблицы, которые более просты для понимания. Например, одна из наиболее часто используемых таблиц в нашем хранилище называется merch_merchanttransaction. Каждая строка в ней содержит всю необходимую аналитику информацию о заказе. Вместо того, чтобы тратить часы на написание join-ов в MongoDB, чтобы извлечь заказ + его id + информацию о возврате товара, теперь можно было писать запросы к одной таблице, где содержатся все данные о заказе, потратив на это несколько минут.
Развернуть хранилище данных очень легко, ведь для этого мы могли использовать все, что было сделано раньше при создании отчетов. Во-первых, для новых таблиц мы взяли лишь наиболее важные метрики и измерения из старых отчетов. Во-вторых, мы переориентировали код, который производил расчеты для отчетов, на работу с пайплайнами данных, чтобы генерировать более детальные записи в нашем хранилище.
Все это заняло менее чем 3 недели. В результате мы получили хранилище данных, которое покрывало большую часть бизнес-процессов компании и сильно ускорило работу аналитиков.
В качестве базы данных мы выбрали Redshift. Также мы уже использовали Hive (TreasureData) для ведения логов приложения, но он пригодился еще и для сброса и создания новых таблиц. У TreasureData есть интеграция с Redshift, чем мы и воспользовались для того, чтобы перенести точные копии этих таблиц на наш новый Redshift кластер.
На ранних этапах развития компании отчеты создавались с помощью Python скриптов, отправляющих данные в формате HTML. На самом деле это было довольно эффективно:
Однако были и ограничения, которые мешали масштабированию системы:
Чтобы избавиться от этих ограничений, нам был нужен BI-инструмент, способный быстро визуализировать информацию из хранилища данных.
Современные готовые облачные решения довольно легко интегрируются систему. Главная же проблема была в другом: нужно было убедить нашего CTO, что нам не обойтись без BI-инструмента, в то время как он не имел никакого понятия, с какими проблемами (перечисленными выше) нам приходится сталкиваться. Все, что он видел — готовые отчеты, поэтому для него система работала на ура.
В конце концов, я имел достаточный авторитет в глазах менеджмента компании, чтобы они выслушали меня и запустили процесс покупки и интеграции Looker. С того момента и до завершения процесса прошло 2 месяца. Вот какие шаги нам нужно было сделать:
Все это может звучать слишком бюрократизировано, однако решение о том, чтобы внедрить инструмент, которым будут пользоваться все в компании, должно быть взвешенным. Поэтому все шаги, описанные выше, гарантируют, что решение действительно окажет положительный эффект на компанию с точки зрения всех, кто каким-либо образом зависит от данных в компании.
Итоговая инфраструктура данных
В результате, запустив Looker, мы смогли успешно завершить процесс перестройки аналитики в Wish. Теперь, когда фундамент заложен, мы могли заниматься масштабированием инфраструктуры и увеличением количества сотрудников, чтобы, наконец, разобраться с лавиной данных, которая начала обрушиваться на нас.
Увидимся в следующих частях серии статей, где мы отдельно обсудим, как проходило масштабирование аналитики и data engineering-а в Wish!
Мало кто верил, что можно построить большой бизнес, продавая дешевые товары. Однако, используя данные, Wish смогли бросить вызов этим сомнениям. Аналитика данных всегда была у нас в крови.
Но когда наш бизнес стал расти огромными темпами, мы не были к этому готовы, обнаружилось множество проблем с аналитикой. Каждая команда внутри компании стала нуждаться в срочной поддержке в работе с данными и многое упускала из виду в своем поле деятельности. В то время наши аналитические возможности еще только зарождались и не могли удовлетворить все растущий спрос.
В данном посте я расскажу о том, какие уроки мы извлекли за это время, а также распишу верный путь для компаний, находящихся в поисках способов масштабирования их аналитических функций.
Проблем было много, в первую очередь с доступом к данным. Единственными, кто мог извлекать данные и строить отчеты были инженеры, работающие над продуктом, а так как инфраструктура данных была совсем «сырой», мы не могли нанять аналитиков в помощь. В результате выполнение запросов данных и построение отчетов могли проходить неделями.
В течение следующих 2 лет мы работали не покладая рук, чтобы выстроить аналитику в компании. Мы с нуля построили пайплайн данных, который позволяет инженерам, аналитикам и data scientist-ам выполнять ETL-процессы надежно и безопасно для своей работы. Хранилище данных было собрано в Redshift и BigQuery с основными таблицами, которые поддерживают вторичные таблицы, используемые аналитиками. Также мы развернули BI платформу Looker, которая теперь используется в качестве источника данных компании, а это значит более чем 200 сотрудниками на трех континентах.
На сегодняшний день более 30 человек в Wish занимаются аналитикой. В этом году мы планируем удвоить их количество. Мы уверены, что теперь наши процессы и системы хорошо масштабируемы, а значит мы готовы к будущим вызовам.
Сломать фундамент и воздвигнуть новый
Начнем с ранних деньков. Когда я пришел в компанию, было совершенно очевидно, что у нас огромные проблемы с тем, как мы работаем с данными:
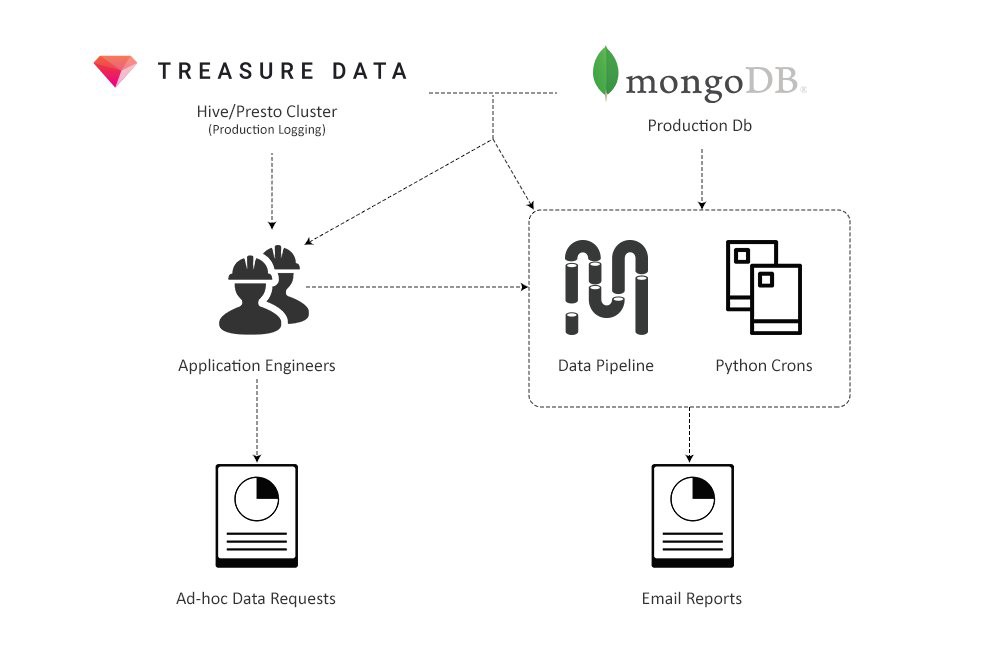
Первоначальная система данных
Во-первых, создание запросов данных было кошмарным, несмотря на то, что к тому времени наши MongoDB кластеры были одними из крупнейших в мире (топ 3). В целях надежности наша команда по инфраструктуре отключила запросы агрегирования в Mongo, то есть теперь агрегирование данных должно выполняться на клиентской стороне (в Python скрипте). Вместо простых SUM и GROUP BY SQL-запросов мы писали код в Python скрипте, который по очереди обрабатывал каждый из миллионов документов, храня результаты в словаре, в который вложены другие словари. Стоит ли говорить, что такие запросы было тяжело писать, а запускались они вечность.
Ситуация с пайплайном данных была немногим лучше. Система была слишком проста, и в ней не было ключевых функций, которые бы позволяли управлять огромным количеством ETL-задач, к примеру, возникали проблемы с управлением зависимостями. Поток сбоев и ошибок практически не прекращался, и в результате весь рабочий день приходилось посвящать именно борьбе с ними.
Очевидно, что было необходимо переделать инфраструктуру, перенести пайплайн данных на более масштабируемую и надежную платформу, а также построить отдельное хранилище данных для аналитиков, чтобы ускорить создание запросов и отчетов.
Тот факт, что я был одним из всего двух сотрудников в компании с фокусом на аналитику, значительно усложнял задачу. Я разрывался между поддержкой текущего пайплайна, созданием огромного количества отчетов и запросов данных, а еще нужно было выкроить время для перестройки инфраструктуры. Таким образом, я периодически переключался с data engineering-а на аналитические задачи и обратно, то есть занимался двумя областями одновременно, каждая из которых требует особые навыки и стиль мышления. Пытаясь успеть везде, я не уверен, что хорошо справлялся и с тем, и другим.
Наконец, нам удалось нанять наших первых, серьезных аналитиков данных, это нас и спасло. Нам повезло, что они были достаточно технически подкованы, чтобы писать ad-hoc запросы для MongoDB и работать с нашими отчетами на Python. Также они были достаточно опытны, чтобы разбираться с незадокументированными и новыми источниками данных. Это значит, что они могли бы взять на себя часть обязанностей, под завалом которых я оказался.
В течение следующего года в Wish мы выстраивали инфраструктуру. Пока аналитики занимались обработкой запросов данных со всех уголков компании, я мог сконцентрироваться на построении новой системы.
Невозможно представить, чтобы кто-то из нашей пары «я — команда аналитиков» протянул в компании долго, не будь другого. Две проблемы, над которыми мы работали: извлечение данных / построение отчетов и улучшение инфраструктуры были по-своему сложны и требовали настолько разного рода умений, что каждый из нас не мог быть достаточно хорош, чтобы выполнять работу другого.
Главное, что стоит извлечь из этой части — создавая команду по работе с данными, необходимо иметь и data engineer-а, и аналитика(ов). Без как минимум одного аналитика инженер данных будет тонуть в создании отчетов и извлечении данных, а без data engineer-а аналитики, в свою очередь, перегорят от количества запросов из разных сложных источников данных. В итоге и тот, и другой должны быть опытны и терпеливы в ожидании, пока достойная система будет построена.
В следующих двух частях я более подробно расскажу о вызовах, с которыми предстоит встретиться аналитикам и инженерам, и как с ними справиться.
Каково это: прийти к нам одним из первых data scientist-ов?
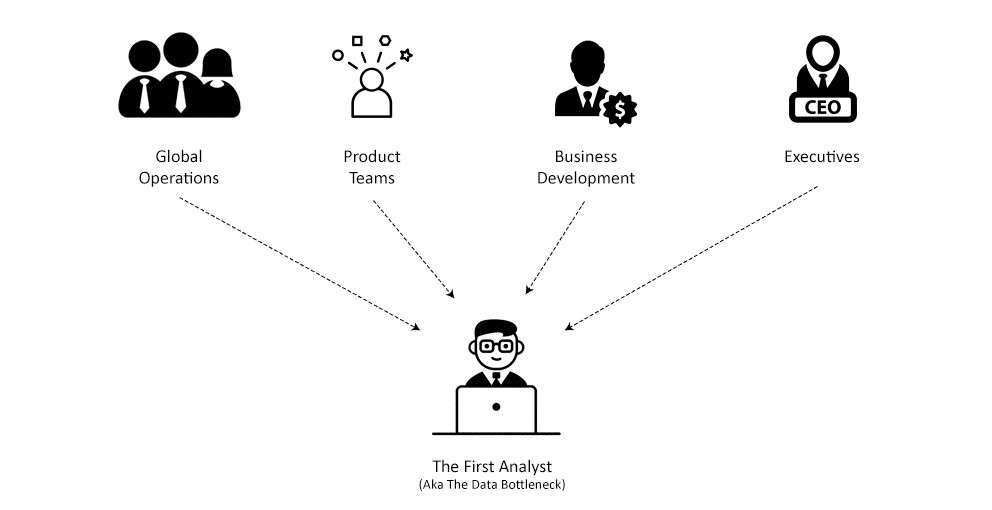
Быть одним из первых аналитиков в Wish означало взять на себя огромное количество отчетов и запросов данных. Начнем с отчетов.
Создание отчетов — это система из Python скриптов, которая генерировала HTML email-ы через определенные интервалы времени. Их были тысячи, и они покрывали различные системы и функции внутри компании.
Следить за тем, чтобы скрипты работали, а отчеты отправлялись по расписанию — это работа на полную ставку. Обрабатывать данные и учитывать все возможные ошибки тяжело: опечатки, пропущенные или неполные данные, проблемы с отображением — все это ежедневно мешало нормальной отправке отчетов. В течение недели банально не хватало времени, чтобы исправить все накопившиеся ошибки, поэтому нужно было сортировать их по важности и исправлять лишь наиболее серьезные.
Конечно, просто поддерживать функционирование системы было недостаточно. Рост компании привел к увеличению спроса на новые отчеты. К тому же, мы только наняли нового операционного директора, а это значит, что все наши отчеты об обслуживании клиентов необходимо было переделать. Также мы запустили новые программы для продавцов, такие как Wish Express с 7-дневной доставкой, и каждая из них требовала своего набора отчетов.
Также, помимо отчетов, аналитику нужно было как-то справляться с непрекращающимся потоком запросов данных со всей компании. По опыту мы знали, что скорость поступления этих запросов растёт экспоненциально, поэтому одной из основных задач стали приоритизация наиболее важных запросов и отсеивание ненужных.
Несомненно, это было тяжело. У аналитика всегда был соблазн какие-то вещи сделать наспех, чтобы справиться с огромным объемом работы, что приводило к ошибкам и, соответственно, снижению доверия к нему.
Таким образом, чтобы преуспеть в этой роли, необходимо два навыка:
- Уметь разбираться в системе и делать качественные расчеты.
- Справляться с невероятным количеством запросов данных.
Ниже мы обсудим эти два навыка в деталях: почему они так сложны на ранних стадиях и как преодолеть эти сложности.
О том, как не отправить плохие данные
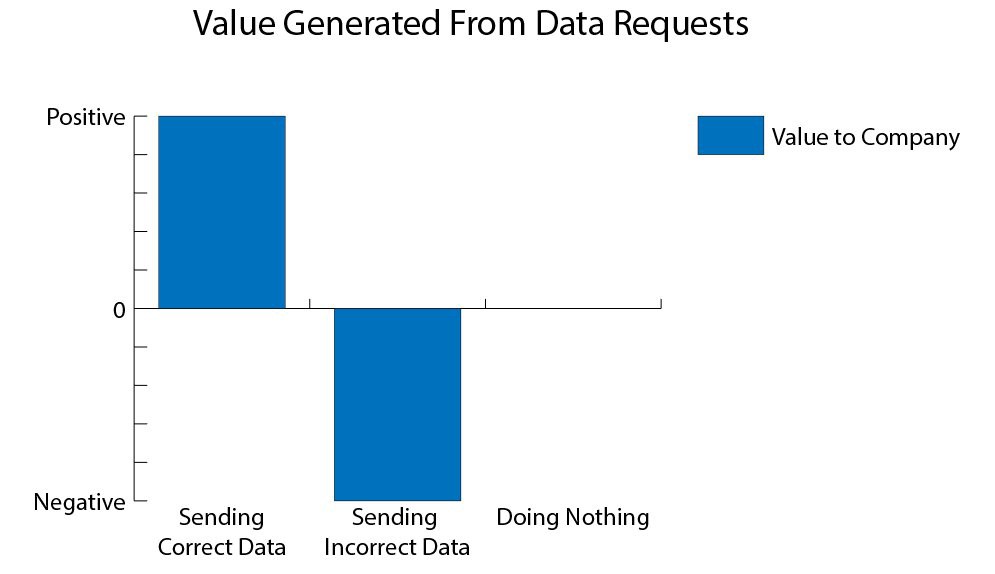
Отправить плохие данные < ничего не делать < отправить хорошие данные
Неопытные аналитики чаще всего пробуют создавать запросы данных, полностью не понимая, как это работает. Для примера, допустим, что нам поступил запрос, получить текущую долю возвращенных товаров. Наивный способ — это найти в модели данных заказы и посмотреть, есть ли у них поле «Возвращен». Затем, отфильтровав по этому критерию все данные за определенный промежуток времени, мы можем посчитать эту долю: # возвратов / # заказов. Затем это число мы и отправляем.
Через какое-то время приходит ответ от начальства: теперь необходимо выяснить, как отличается доля возвращенных товаров для товаров с подтверждением доставки и без нее. Будучи таким же наивным, аналитик применит тот же подход, найдет отдельную модель данных для отслеживания заказов и увидит, что там есть поле «Подтвержденное время доставки», которое можно присоединить к заказам из первой модели данных, используя ключ — id заказа.
Наконец, мы пишем тот же запрос, что и раньше, но с условием наличия / отсутствия времени подтверждения доставки, чтобы получить две метрики:
- Доля заказов с подтверждением доставки: Х%.
- Доля заказов без подтверждения доставки: Y%.
Затем отправляем. Все довольно просто.
Однако заметили ли вы ошибку?
Для Wish, отмена заказа также считается возвратом товара, а так как отмена означает, что товар еще не доставлен, то такие заказы всегда будут оказываться во второй группе — заказы без подтверждения доставки. Вследствие этого вторая метрика будет сильно завышена, что может привести к неверным управленческим решениям.
Этот пример не выдуман, он действительно случился (к счастью, мы быстро заметили ошибку). Теперь я по опыту знаю, что каждый раз, когда я шел быстрым путем и работал с запросами без понимания самой системы, в итоге я отправлял неправильные числа.
Чтобы успешно избегать таких ловушек, необходим опыт. Всегда, работая с новой метрикой или источником данных, с которым аналитик не знаком, он должен потратить дополнительное время на понимание данных и самой системы. А первым аналитикам в компании это приходилось делать каждый раз, поскольку любая новая задача означала работу с незнакомыми данными.
Опытные аналитики понимают, где не нужно торопиться, даже в условиях огромного давления и срочности.
О том, как справляться с огромным количеством запросов
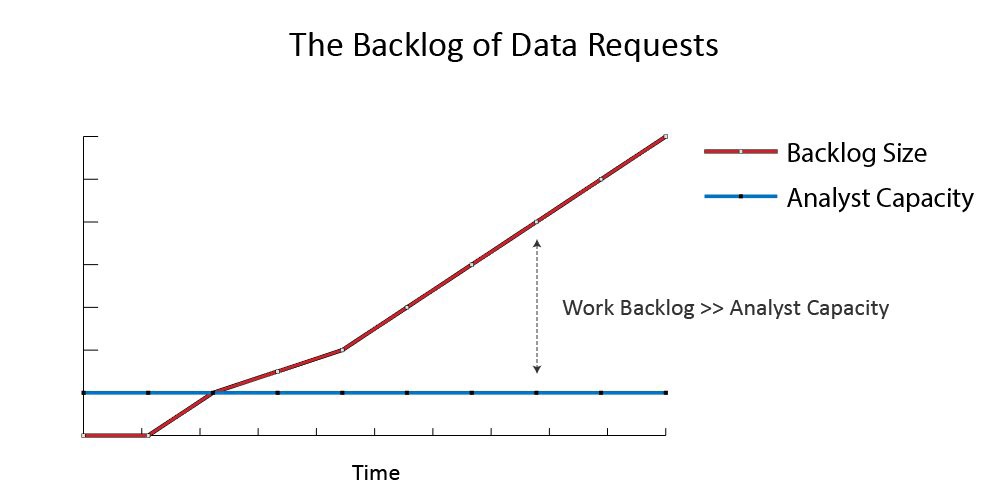
Загруженность аналитиков в стартапах
Раньше в Wish мы были всего лишь группой аналитиков и инженеров, которые должны были поддерживать бизнес с оборотом в несколько миллионов долларов в год. Дело тут даже не в количестве людей, нас могло быть 20, и мы все равно не справлялись бы с огромным количеством данных. Поэтому мы должны были правильно расставлять приоритеты, концентрироваться на самых важных задачах и откладывать все остальное.
Конечно, легче сказать, чем сделать. Почему один запрос важнее другого? Все ли баги исправлены перед отправкой запроса? Какой отдел нуждается в помощи в первую очередь? Чтобы ответить на эти вопросы, каждый запрос оценивается по двум критериям:
- Степень влияния запроса на деятельность компании.
- Необходимый объем работы для его выполнения.
Во-первых, перед началом работы над запросом необходимо оценить его влияние, то есть подумать, как эта задача повлияет на компанию. К примеру, подходящие вопросы: какие области нашего бизнеса эта задача затрагивает и каков размер этих областей? Какова возможная выгода? Какова вероятность успешного выполнения задачи? Важна ли эта задача с точки зрения стратегии компании?
Ответив на эти вопросы, сравниваем оценку важности задачи с объемом работы на ее выполнение. Мы примерно представляли, сколько занимает та или иная задача: исправление бага занимает от половины до целого дня, отчет — от 2 дней до недели, а ad-hoc запрос данных — полдня.
Используя этот фреймворк, мы в Wish следующим образом приоретизировали входящие запросы:
- Чаще всего исправление багов наиболее важно. Если кто-то просит что-то починить, то скорее всего это какая-то полезная фича. Исправив баг, мы улучшим работу компании. К тому же, это довольно быстро, поэтому у этой задачи отношение важности к объему работы очень велико.
- К работе с отчетами нужно подходить более осторожно. Добавление новой метрики в отчет или создание нового действительно поможет акционерам принимать лучшие решения?
- Далее идут системные улучшения, как, например, консолидирование отчетов или выделение частых расчетов в отдельный пайплайн, так как они в хорошем ключе влияют на бизнес в среднесрочной перспективе, но почти не влияют в краткосрочной. Поэтому эти задачи следует откладывать до тех пор, пока это не угрожает функционированию всей системы.
- Наконец, низший приоритет имеют задачи без четкой цели. Например, когда акционеры не уверены, какую проблему нужно решить, и просто хотят получить данные для анализа. Такие задачи нужно решать в последнюю очередь, поскольку они редко влияют на работу бизнеса и чаще всего требуют, чтобы ты несколько раз к ним возвращался.
Также, если запрос имеет влияние на бизнес, однако требует больше усилий, чем необходимо, то чаще всего мы урезаем некоторые требования из задачи. Так, если метрику слишком тяжело считать, то мы попросту убираем ее из запроса.
Таким образом, ранжируя задачи по степени важности и фокусируясь на задачах, требующих меньше усилий для достижения большего результата, мы смогли достигнуть многого в условиях критической нехватки времени.
Подводя итоги этой части: запросы данных тяжело обрабатывать, а поступают они с невероятной скоростью. Даже делая все идеально, рано или поздно ты сгоришь. Ни один аналитик не может удерживать такой темп достаточно долго.
Именно поэтому необходимо было взяться за data engineering. Нам нужна была качественная инфраструктура.
Каково это: прийти к нам одним из первых инженеров данных?
MVP (минимальный жизнеспособный продукт) инфраструктуры данных состоит из:
- Пайплайна данных, чтобы передавать данные.
- Хранилища данных, которое подстроено под запросы аналитиков.
- BI-платформы, с помощью которой аналитики могут быстро визуализировать данные.
Наличие всех этих элементов приведет к значительному увеличению эффективности. Создание источника данных специально под бизнес-аналитику в Wish привело к тому, что на один запрос стало уходить в 5-7 раз меньше времени. Также это позволило нам снизить требования к техническим навыкам новых аналитиков, что значительно ускорило найм. Теперь они могли прокачать какие-то навыки позже, при необходимости.
Реализовать все это — не только инженерная проблема. Так, нам необходимо было убедить акционеров в покупке готовой BI-платформы, поскольку корпоративная культура Wish направлена на самостоятельную разработку всего, что нужно.
Ниже я опишу, как мы шаг за шагом разрабатывали инфраструктуру, и какие уроки я из этого извлек.
Как мы заново строили пайплайн данных

Как уже было сказано, существующий в Wish пайплайн не справлялся, поэтому его перестройка была первостепенной задачей. В качестве базового фреймворка мы выбрали Luigi — ETL инструмент, который лучше по ряду аспектов:
- Нынешний пайплайн использовал cron-ы для определения зависимостей. Такой способ не блещет элегантностью и вызывает множество проблем. В Luigi же есть встроенное управление зависимостями.
- Также проблема старого пайплайна в том, что его ошибки приводили к трате времени из-за ручных перезапусков. В свою очередь Luigi идемпотентен, то есть запоминает, какие задачи были успешно выполнены и перезапускает только неудавшиеся.
- Наконец, чтобы выполнить всю работу за день, пайплайну требовалось более чем 24 часов, тогда как в Luigi есть планировщик, который не позволяет одному ETL-запросу запускаться дважды в одно и то же время. Следовательно, мы можем распределить этот запрос по нескольким машинам и вдвое урезать время работы программы.
В результате за 2 месяца я перенес более чем 200 ETL job-ов со старой системы на новую вместе с несколькими cron скриптами.
Вот что мне удалось вынести для себя из этого проекта:
- Не пытайтесь поменять кучу вещей одновременно.
- Меняя инфраструктуру, не пытайтесь изменить логику бизнеса.
- Автоматизируйте тестирование кода с помощью валидационных скриптов.
Также, главный риск при рефакторинге кода заключается в том, что можно получить еще больше новых багов. Перенося более 200 job-ов на новую платформу, нужно было внимательно проверять систему на наличие багов, иначе все бы развалилось.
Таким образом, самый легкий способ — это постепенно вносить небольшие изменения, которые автоматически проверяются на наличие багов. Принципиальных изменений же следует избегать, пока проект полностью не будет готов. В нашем случае это означает: пропускать / блокировать пайплайны, сравнивая результат их работы со старой системой.
Новая платформа на основе Luigi была довольно примитивной, однако она работала и самостоятельно справлялась с ошибками, а это как раз то, что нам было нужно: система, на которую можно положиться, выстраивая остальные элементы инфраструктуры.
Создание хранилища данных

Хранилище данных — это база данных, которая позволяет быстрее писать и запускать аналитические запросы. Обычно в нее входят таблицы, которые более просты для понимания. Например, одна из наиболее часто используемых таблиц в нашем хранилище называется merch_merchanttransaction. Каждая строка в ней содержит всю необходимую аналитику информацию о заказе. Вместо того, чтобы тратить часы на написание join-ов в MongoDB, чтобы извлечь заказ + его id + информацию о возврате товара, теперь можно было писать запросы к одной таблице, где содержатся все данные о заказе, потратив на это несколько минут.
Развернуть хранилище данных очень легко, ведь для этого мы могли использовать все, что было сделано раньше при создании отчетов. Во-первых, для новых таблиц мы взяли лишь наиболее важные метрики и измерения из старых отчетов. Во-вторых, мы переориентировали код, который производил расчеты для отчетов, на работу с пайплайнами данных, чтобы генерировать более детальные записи в нашем хранилище.
Все это заняло менее чем 3 недели. В результате мы получили хранилище данных, которое покрывало большую часть бизнес-процессов компании и сильно ускорило работу аналитиков.
В качестве базы данных мы выбрали Redshift. Также мы уже использовали Hive (TreasureData) для ведения логов приложения, но он пригодился еще и для сброса и создания новых таблиц. У TreasureData есть интеграция с Redshift, чем мы и воспользовались для того, чтобы перенести точные копии этих таблиц на наш новый Redshift кластер.
Запуск BI инструментов
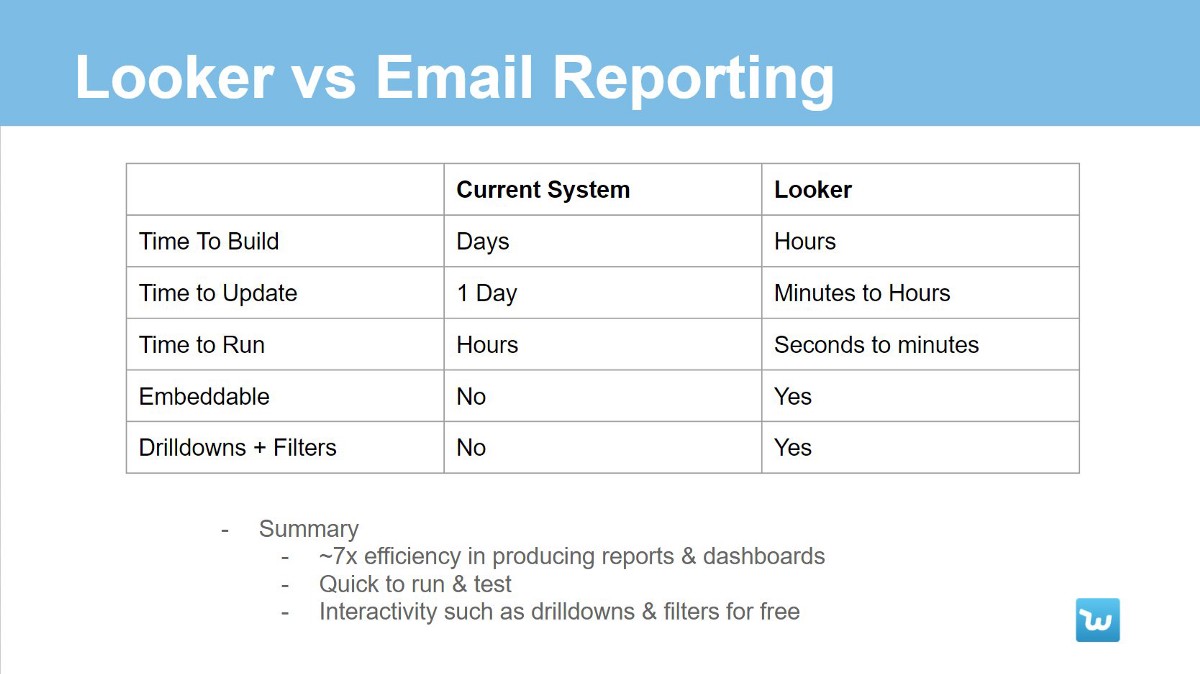
На ранних этапах развития компании отчеты создавались с помощью Python скриптов, отправляющих данные в формате HTML. На самом деле это было довольно эффективно:
- Так как это были всего лишь Python скрипты, с этим мог справиться любой инженер в команде.
- Не было никаких ограничений на формат таблиц и на то, как визуализировать информацию, в отличии от менее гибких структур в рамках BI инструментов. Отчеты можно было создавать и подстраивать под конкретную систему.
Однако были и ограничения, которые мешали масштабированию системы:
- Эти отчеты было трудно писать и тестировать — иногда требовалось около суток, чтобы скрипт был выполнен.
- Не было ни детализации, ни фильтрации данных, то есть, чтобы посмотреть немного другой срез данных, необходимо было создавать новый отчет.
- Добавление даже малейших исправлений в эти отчеты занимало кучу времени из-за долгого тестирования. Также через какое-то время накапливалась огромная база кода, которую необходимо поддерживать.
Чтобы избавиться от этих ограничений, нам был нужен BI-инструмент, способный быстро визуализировать информацию из хранилища данных.
Современные готовые облачные решения довольно легко интегрируются систему. Главная же проблема была в другом: нужно было убедить нашего CTO, что нам не обойтись без BI-инструмента, в то время как он не имел никакого понятия, с какими проблемами (перечисленными выше) нам приходится сталкиваться. Все, что он видел — готовые отчеты, поэтому для него система работала на ура.
В конце концов, я имел достаточный авторитет в глазах менеджмента компании, чтобы они выслушали меня и запустили процесс покупки и интеграции Looker. С того момента и до завершения процесса прошло 2 месяца. Вот какие шаги нам нужно было сделать:
- Выступление с презентацией перед моим менеджером (Главой платформы) о том, какую потенциальную выгоду принесет Looker, включая оценку сэкономленных ресурсов и времени на построение дашбордов.
- Получить согласие от менеджеров из отдела бизнес-процессов.
- Получить согласие от Джека — нашего Главы отдела данных, используя поддержку первых двух.
- Договориться с Looker о пробном периоде, чтобы мы могли создать несколько первых дашбордов (4 недели).
- Использовать эти 4 недели, чтобы построить базовый набор дашбордов для компании (20 штук).
- Выступление перед CTO с отчетом, где был оценен ROI проекта, чтобы получить финальное согласие на покупку лицензии Looker.
Все это может звучать слишком бюрократизировано, однако решение о том, чтобы внедрить инструмент, которым будут пользоваться все в компании, должно быть взвешенным. Поэтому все шаги, описанные выше, гарантируют, что решение действительно окажет положительный эффект на компанию с точки зрения всех, кто каким-либо образом зависит от данных в компании.
Итоговая инфраструктура данных
В результате, запустив Looker, мы смогли успешно завершить процесс перестройки аналитики в Wish. Теперь, когда фундамент заложен, мы могли заниматься масштабированием инфраструктуры и увеличением количества сотрудников, чтобы, наконец, разобраться с лавиной данных, которая начала обрушиваться на нас.
Увидимся в следующих частях серии статей, где мы отдельно обсудим, как проходило масштабирование аналитики и data engineering-а в Wish!
