Перевод статьи Designing a Microservices Architecture for Failure.
Микросервисная архитектура благодаря точно определённым границам сервисов позволяет изолировать сбои. Однако, как и в любой распределённой системе, здесь выше вероятность проблем на уровне сети, оборудования или приложений. Как следствие зависимости сервисов, любой компонент может оказаться временно недоступен для пользователей. Чтобы минимизировать влияние частичных сбоев, нам нужно построить устойчивые к ним сервисы, которые могут корректно реагировать на определённые типы проблем.
В этой статье представлены самые распространённые методики и архитектурные шаблоны для построения и оперирования высокодоступной микросервисной системой.
Если вы не знакомы с шаблонами, упомянутыми здесь, то вовсе не обязательно, что вы что-то делаете неправильно. Построение надёжной системы всегда требует дополнительных вложений.
При такой архитектуре логика приложения переносится на сервисы, а для взаимодействия между ними используется сетевой уровень. Взаимодействие по сети, а не через вызовы внутри памяти, повышает задержку и сложность системы, которой требуется кооперация многочисленных физических и логических компонентов. А рост сложности распределённой системы ведёт к тому, что растут шансы возникновения определённых сетевых сбоев.
Одним из главных преимуществ микросервисной архитектуры по сравнению с монолитной является то, что команды могут независимо друг от друга проектировать, разрабатывать и развёртывать сервисы. Они полностью управляют всем жизненным циклом своих сервисов. Это также означает, что у команд нет контроля над зависимостями сервисов, поскольку обычно этим заведуют другие люди. При использовании микросервисной архитектуры нужно помнить, что сервисы провайдера могут быть временно недоступны из-за косячных релизов, конфигураций и различных изменений, поскольку это зависит не от разработчиков, и компоненты меняются независимо друг от друга.
Одной из наиболее привлекательных сторон микросервисной архитектуры является возможность изолировать сбои, и за счёт того, что компоненты сбоят отдельно друг от друга, можно добиться постепенной деградации обслуживания (graceful service degradation). Например, при сбое приложения, позволяющего делиться фотографиями, пользователи, вероятно, не смогут загружать новые изображения, но смогут просматривать, редактироваться и делиться уже имеющимися фотографиями.

Раздельные сбои микросервисов (в теории).
Тем не менее, в большинстве случаев трудно реализовать такой вид постепенной деградации обслуживания, потому что приложения в распределённых системах зависят друг от друга, и вам нужно применить несколько разных видов логики обработки отказов (некоторые из них мы рассмотрим ниже), чтобы приготовиться ко временным затруднениям и сбоям.

Без логики обработки сбоев сервисы зависят друг от друга и сбоят все вместе.
Команда обеспечения надёжности Google обнаружила, что около 70% сбоев вызваны изменениями в живых системах. Меняя что-то в своей системе — развёртывая новую версию кода или меняя какую-то конфигурацию, — вы рискуете вызвать сбой или внести новые баги.
В микросервисной архитектуре сервисы зависят друг от друга. Поэтому нужно минимизировать сбои и ограничивать их негативное влияние. Чтобы справляться с проблемами, вызванными изменениями, вы можете реализовать стратегии управления изменениями и автоматические откаты.
Например, внося изменения, постепенно применяйте их к подмножеству своих инстансов, отслеживайте и автоматически откатывайте развёртывание, если замечаете ухудшение ключевых метрик.

Управление изменениями — Rolling Deployment.
Другим решением может быть использование двух production-сред. Всегда развёртывайте только в одной из них, и применяйте к ней балансировщик нагрузки только убедившись, что новая версия работает так, как ожидалось. Это называется «сине-зелёное» или «чёрно-красное» развёртывание.
Откат кода — это не беда. Нельзя оставлять в production сломанный код и потом ломать голову над тем, что же пошло не так. Всегда откатывайте изменения при необходимости. Чем раньше, тем лучше.
Инстансы постоянно запускаются, перезапускаются и останавливаются из-за сбоев, развёртываний или автомасштабирования. И поэтому становятся временно или постоянно недоступны. Чтобы избежать подобных проблем, ваш балансировщик должен исключать сбойные инстансы из ротации, если они не могут обслуживать клиентов или другие подсистемы.
Работоспособность инстансов приложений можно определить посредством внешнего наблюдения. Вы можете делать это с помощью регулярных вызовов конечной точки
«Реанимировать» приложение можно с помощью самовосстановления. Говорить об этом механизме можно в том случае, если приложение выполняет необходимые действия по выходу из сбойного состояния. В большинстве случаев самовосстановление реализуется внешней системой, отслеживающей работостопособность инстансов и перезапускающей их, если они в течение определённого периода находятся в состоянии сбоя. Самовосстановление зачастую бывает очень полезно, но в некоторых ситуациях оно может доставить проблемы за счёт постоянного перезапуска приложения. Это возможно, если приложение не может сообщить о положительном состоянии из-за перегрузки или таймаутов при подключении к базе данных.
Может быть непросто реализовать продвинутый механизм самолечения, который будет готов к деликатным ситуациям вроде потери подключения к базе данных. В этом случае вам нужна дополнительная логика, которая будет обрабатывать крайние случаи и дать внешней системе знать, что не нужно немедленно перезапускать инстанс.
Обычно сервисы сбоят из-за проблем с сетью и изменений в системе. Однако большинство сбоев являются временными благодаря механизмам самовосстановления и продвинутой балансировке. И нам нужно найти решение, позволяющее сервисам работать во время таких происшествий. Тут может помочь отказоустойчивое кэширование, которое будет предоставлять приложениям нужные данные.
Отказоустойчивые кэши обычно используют два разных срока действия. Более короткий говорит о том, как долго вы можете использовать кэш в обычной ситуации, а более длинный — как долго вы можете использовать кэшированные данные в ходе сбоя.

Отказоустойчивое кэширование.
Важно упомянуть, что вы можете использовать отказоустойчивое кэширование только тогда, когда лучше устаревшие данные, чем ничего.
Для настройки обычного и отказоустойчивого кэша вы можете воспользоваться стандартными заголовками ответов в HTTP.
Например, с помощью заголовка
Современные CDN и балансировщики предоставляют различные схемы кэширования и отказоустойчивости, но вы можете также создать общую библиотеку для своей компании, содержащую стандартные решения обеспечения надёжности.
Бывают ситуации, когда мы не можем кэшировать данные, или когда нам нужно внести в них изменения, но наши операции сбоят. Тогда можно попробовать повторить наши действия, если есть шанс, что ресурсы восстановятся некоторое время спустя, или если наш балансировщик шлёт наши запросы на рабочий инстанс.
Будьте осторожны с добавлением логики повтора в ваши приложения и клиенты, потому что большое количество повторов может ухудшить ситуацию или даже помешать приложениям восстановиться.
В распределённой системе повторы в микросервисной структуре могут сгенерировать многочисленные ответы или другие повторы, что создаст каскадный эффект. Для минимизации влияния повторов ограничивайте их количество и используйте экспоненциальный алгоритм отсрочки, чтобы каждый раз увеличивать задержку между повторами, пока не достигнете предела.
Поскольку повтор инициируется клиентом (браузером, другим микросервисом и так далее), который не знает, была ли операция сбойной до или после обработки запроса, приложение должно уметь обрабатывать идемпотентность. Например, когда вы повторяете операцию покупки, то вы не должны дублировать взимание средств с покупателя. Вам поможет использования уникального ключа идемпотентности для каждой транзакции.
Ограничение скорости — это методика определения количества запросов, которые могут быть приняты или обработаны конкретным потребителем или приложением в течение определённого времени. С помощью ограничения скорости мы можем, к примеру, отфильтровывать наших потребителей и микросервисы, из-за которых возникают всплески трафика. Или можем удостовериться, что приложение не будет перегружено, пока на помощь не придёт автомасштабирование.
Также вы можете ограничивать низкоприоритетный трафик, чтобы выделить больше ресурсов на критически важные транзакции.
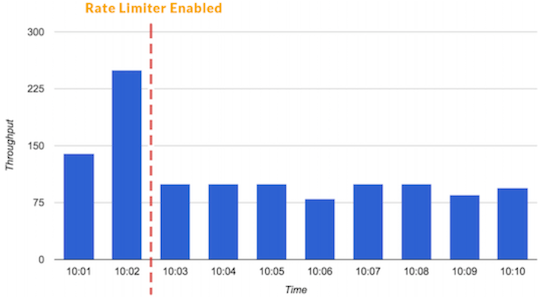
Ограничитель скорости может предотвращать всплески трафика.
Другой вид ограничителя скорости называется ограничитель одновременных запросов (concurrent request limiter). Он может быть полезен, когда у вас есть «дорогие» конечные точки, которые не рекомендуется вызывать больше определённого количества раз, если вы хотите обслуживать трафик.
Чтобы у вас всегда хватало ресурсов для обслуживания критически важных транзакций, используйте fleet usage load shedder. Он удерживает часть ресурсов для высокоприоритетных запросов и не позволяет низкоприоритетным транзакциям их использовать. Load shedder принимает свои решения на основе общего состояния системы, а не размера одиночного пользовательского запроса. Также LS’ы помогут вашей системе восстановиться, поскольку они обеспечивают работу ключевой функциональности в ходе инцидента.
Почитать подробнее об ограничителях скорости и load shedder’ах можно в этой статье: https://stripe.com/blog/rate-limiters.
В микросервисной архитектуре нужно подготовить свои сервисы сбоить быстро и раздельно. Чтобы изолировать проблемы на уровне сервисов, мы можем использовать шаблон bulkhead.
Быстрый сбой компонентов нужен потому, что мы не хотим ждать, пока закончатся таймауты сломанных инстансов. Ничто так не раздражает, как зависший запрос и не отвечающий на ваши действия интерфейс. Это не только потерянные ресурсы, но и испорченный пользовательский опыт. Сервисы вызывают друг друга по цепочке, поэтому нужно уделять особое внимание предотвращению повисания операций, не допуская накопления задержек.
Вероятно, вам в голову сразу пришла идея применения небольших таймаутов (fine grade timeouts) для каждого вызова сервиса. Но проблема в том, что вы не можете знать, какое значение таймаута будет подходящим, потому что есть ситуации, когда сетевые отказы и другие возникающие проблемы влияют только на одну-две операции. В этом случае вы, вероятно, не захотите отклонить эти запросы из-за того, что некоторые из них завершаются по таймауту.
Можно сказать, что применение парадигмы «быстрого сбоя» в микросервисах посредством таймаутов является антипаттерном, которого следует избегать. Вместо таймаутов можете применять шаблон circuit-breaker, который зависит от статистики успешных/сбойных операций.
Переборки используются в кораблестроении для разделения корабля на секции, чтобы каждая секция могла быть задраена в случае пробоя корпуса.
Принцип переборок можно применить в разработке ПО для разделения ресурсов, чтобы защитить их от исчерпания. Например, если у нас есть два типа операций, которые взаимодействуют с одним инстансом базы данных, имеющим ограничение по количеству подключений, то можно использовать два пула подключений вместо одного общего. В результате такого разделения «клиент—ресурс» операция, которая инициирует таймаут или будет злоупотреблять пулом, не повлияет на работу других операций.
Одной из главных причин гибели «Титаника» была неудачная конструкция переборок, при которой вода могла по палубам переливаться в другие отсеки, заполняя весь корпус.
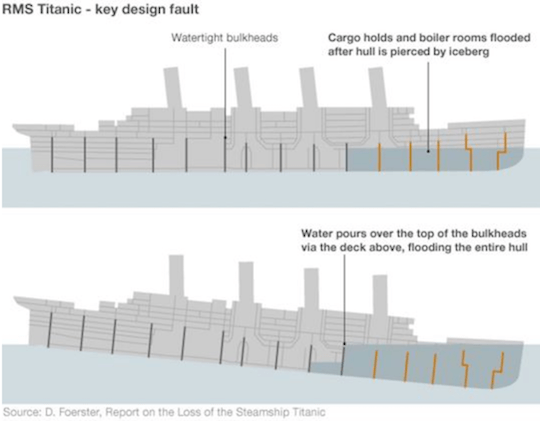
Переборки на «Титанике» (они не сработали).
Таймауты можно использовать для ограничения продолжительности операций. Они могут предотвратить подвисание операций и поддерживать реагирование системы на ваши действия. Использование в микросервисной архитектуре статичных, тонко настраиваемых таймаутов является антипаттерном, поскольку речь идёт о высокодинамичной среде, в которой практически невозможно подобрать подходящие временные ограничения, хорошо работающие в любых ситуациях.
Вместо использования маленьких статичных таймаутов, зависящих от транзакций, для обработки ошибок можно использовать автоматы замыкания (circuit breakers). Действие этих программных механизмов аналогично одноимённым электротехническим устройствам. С помощью автоматов замыкания вы можете защитить ресурсы и помочь им восстановиться. Они могут быть очень полезны в распределённых системах, где повторяющийся сбой может стать причиной лавинообразного эффекта, который положит всю систему.
Автомат замыкания открывается, когда в течение короткого времени несколько раз возникает ошибка определённого типа. Открытый автомат предотвращает передачу запросов — как реальный автомат прерывает электрическую цепь и не даёт току течь по проводам. Автоматы замыкания обычно закрываются через определённое время, давая сервисам передышку для восстановления.
Помните, что не все ошибки должны инициировать автомат замыкания. Например, вы наверняка захотите пропустить ошибки на стороне клиента вроде запросов с кодами 4хх, но при этом отреагировать на серверные сбои с кодами 5хх. Некоторые автоматы замыкания могут находиться в полуоткрытом состоянии. Это означает, что сервис отправляет первый запрос для проверки доступности системы, а остальные запросы отсекаются. Если первый запрос прошёл удачно, автомат переходит в закрытое состояние и не препятствует течению трафика. В противном случае автомат остаётся открытым.
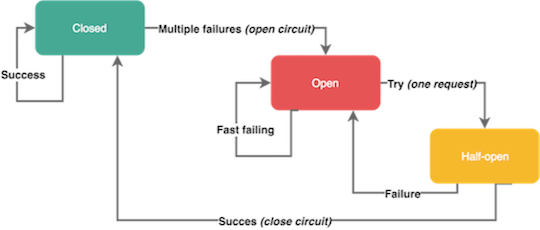
Автомат замыкания.
Вы должны постоянно проверять поведение своей системы в условиях распространённых проблем, чтобы удостовериться, что ваши сервисы могут пережить различные сбои. Почаще проводите тестирования, чтобы ваша команда была готова к инцидентам.
Вы можете воспользоваться внешним сервисом, который идентифицирует группы инстансов и случайным образом прерывает работу одного из участников группы. Так вы будете готовы к сбою одиночного инстанса. А можете перекрывать целые регионы, чтобы эмулировать сбой у облачного провайдера.
Одно из самых популярных решений — инструмент проверки на отказоустойчивость ChaosMonkey.
Реализация и поддержание работы надёжного сервиса — задача непростая. Она требует больших усилий и стоит немалых денег.
У надёжности есть разные уровни и аспекты, так что важно найти решение, лучше всего подходящее для вашей команды. Сделайте надёжность одним из факторов в процессе принятия бизнес-решений и выделите на это достаточно денег и времени.
Микросервисная архитектура благодаря точно определённым границам сервисов позволяет изолировать сбои. Однако, как и в любой распределённой системе, здесь выше вероятность проблем на уровне сети, оборудования или приложений. Как следствие зависимости сервисов, любой компонент может оказаться временно недоступен для пользователей. Чтобы минимизировать влияние частичных сбоев, нам нужно построить устойчивые к ним сервисы, которые могут корректно реагировать на определённые типы проблем.
В этой статье представлены самые распространённые методики и архитектурные шаблоны для построения и оперирования высокодоступной микросервисной системой.
Если вы не знакомы с шаблонами, упомянутыми здесь, то вовсе не обязательно, что вы что-то делаете неправильно. Построение надёжной системы всегда требует дополнительных вложений.
Риск микросервисной архитектуры
При такой архитектуре логика приложения переносится на сервисы, а для взаимодействия между ними используется сетевой уровень. Взаимодействие по сети, а не через вызовы внутри памяти, повышает задержку и сложность системы, которой требуется кооперация многочисленных физических и логических компонентов. А рост сложности распределённой системы ведёт к тому, что растут шансы возникновения определённых сетевых сбоев.
Одним из главных преимуществ микросервисной архитектуры по сравнению с монолитной является то, что команды могут независимо друг от друга проектировать, разрабатывать и развёртывать сервисы. Они полностью управляют всем жизненным циклом своих сервисов. Это также означает, что у команд нет контроля над зависимостями сервисов, поскольку обычно этим заведуют другие люди. При использовании микросервисной архитектуры нужно помнить, что сервисы провайдера могут быть временно недоступны из-за косячных релизов, конфигураций и различных изменений, поскольку это зависит не от разработчиков, и компоненты меняются независимо друг от друга.
Постепенная деградация обслуживания
Одной из наиболее привлекательных сторон микросервисной архитектуры является возможность изолировать сбои, и за счёт того, что компоненты сбоят отдельно друг от друга, можно добиться постепенной деградации обслуживания (graceful service degradation). Например, при сбое приложения, позволяющего делиться фотографиями, пользователи, вероятно, не смогут загружать новые изображения, но смогут просматривать, редактироваться и делиться уже имеющимися фотографиями.
Раздельные сбои микросервисов (в теории).
Тем не менее, в большинстве случаев трудно реализовать такой вид постепенной деградации обслуживания, потому что приложения в распределённых системах зависят друг от друга, и вам нужно применить несколько разных видов логики обработки отказов (некоторые из них мы рассмотрим ниже), чтобы приготовиться ко временным затруднениям и сбоям.

Без логики обработки сбоев сервисы зависят друг от друга и сбоят все вместе.
Управление изменениями
Команда обеспечения надёжности Google обнаружила, что около 70% сбоев вызваны изменениями в живых системах. Меняя что-то в своей системе — развёртывая новую версию кода или меняя какую-то конфигурацию, — вы рискуете вызвать сбой или внести новые баги.
В микросервисной архитектуре сервисы зависят друг от друга. Поэтому нужно минимизировать сбои и ограничивать их негативное влияние. Чтобы справляться с проблемами, вызванными изменениями, вы можете реализовать стратегии управления изменениями и автоматические откаты.
Например, внося изменения, постепенно применяйте их к подмножеству своих инстансов, отслеживайте и автоматически откатывайте развёртывание, если замечаете ухудшение ключевых метрик.
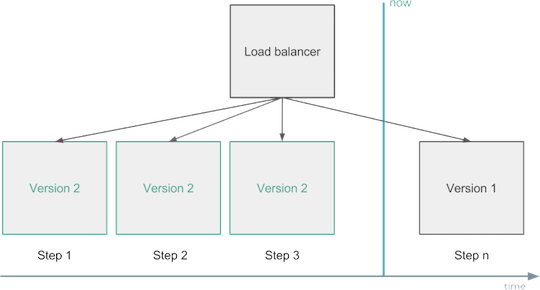
Управление изменениями — Rolling Deployment.
Другим решением может быть использование двух production-сред. Всегда развёртывайте только в одной из них, и применяйте к ней балансировщик нагрузки только убедившись, что новая версия работает так, как ожидалось. Это называется «сине-зелёное» или «чёрно-красное» развёртывание.
Откат кода — это не беда. Нельзя оставлять в production сломанный код и потом ломать голову над тем, что же пошло не так. Всегда откатывайте изменения при необходимости. Чем раньше, тем лучше.
Проверка работоспособности (Health-check) и балансировка нагрузки
Инстансы постоянно запускаются, перезапускаются и останавливаются из-за сбоев, развёртываний или автомасштабирования. И поэтому становятся временно или постоянно недоступны. Чтобы избежать подобных проблем, ваш балансировщик должен исключать сбойные инстансы из ротации, если они не могут обслуживать клиентов или другие подсистемы.
Работоспособность инстансов приложений можно определить посредством внешнего наблюдения. Вы можете делать это с помощью регулярных вызовов конечной точки
GET /health или через автоматическую отправку отчётов. Современные решения по обнаружению сервисов (service discovery) постоянно собирают с инстансов информацию о работоспособности и конфигурируют балансировщики, чтобы пускать трафик только на полноценно работающие компоненты. Самовосстановление (Self-healing)
«Реанимировать» приложение можно с помощью самовосстановления. Говорить об этом механизме можно в том случае, если приложение выполняет необходимые действия по выходу из сбойного состояния. В большинстве случаев самовосстановление реализуется внешней системой, отслеживающей работостопособность инстансов и перезапускающей их, если они в течение определённого периода находятся в состоянии сбоя. Самовосстановление зачастую бывает очень полезно, но в некоторых ситуациях оно может доставить проблемы за счёт постоянного перезапуска приложения. Это возможно, если приложение не может сообщить о положительном состоянии из-за перегрузки или таймаутов при подключении к базе данных.
Может быть непросто реализовать продвинутый механизм самолечения, который будет готов к деликатным ситуациям вроде потери подключения к базе данных. В этом случае вам нужна дополнительная логика, которая будет обрабатывать крайние случаи и дать внешней системе знать, что не нужно немедленно перезапускать инстанс.
Отказоустойчивое кэширование (Failover caching)
Обычно сервисы сбоят из-за проблем с сетью и изменений в системе. Однако большинство сбоев являются временными благодаря механизмам самовосстановления и продвинутой балансировке. И нам нужно найти решение, позволяющее сервисам работать во время таких происшествий. Тут может помочь отказоустойчивое кэширование, которое будет предоставлять приложениям нужные данные.
Отказоустойчивые кэши обычно используют два разных срока действия. Более короткий говорит о том, как долго вы можете использовать кэш в обычной ситуации, а более длинный — как долго вы можете использовать кэшированные данные в ходе сбоя.
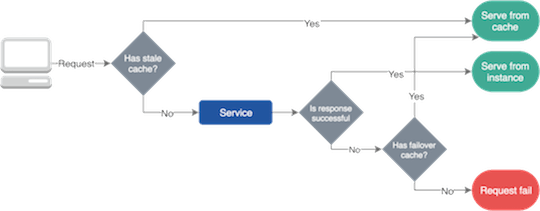
Отказоустойчивое кэширование.
Важно упомянуть, что вы можете использовать отказоустойчивое кэширование только тогда, когда лучше устаревшие данные, чем ничего.
Для настройки обычного и отказоустойчивого кэша вы можете воспользоваться стандартными заголовками ответов в HTTP.
Например, с помощью заголовка
max-age можно задать время, в течение которого ресурс будет считаться свежим. А с помощью заголовка stale-if-error — как долго ресурс будет предоставляться из кэша в случае сбоя.Современные CDN и балансировщики предоставляют различные схемы кэширования и отказоустойчивости, но вы можете также создать общую библиотеку для своей компании, содержащую стандартные решения обеспечения надёжности.
Логика повторения (Retry Logic)
Бывают ситуации, когда мы не можем кэшировать данные, или когда нам нужно внести в них изменения, но наши операции сбоят. Тогда можно попробовать повторить наши действия, если есть шанс, что ресурсы восстановятся некоторое время спустя, или если наш балансировщик шлёт наши запросы на рабочий инстанс.
Будьте осторожны с добавлением логики повтора в ваши приложения и клиенты, потому что большое количество повторов может ухудшить ситуацию или даже помешать приложениям восстановиться.
В распределённой системе повторы в микросервисной структуре могут сгенерировать многочисленные ответы или другие повторы, что создаст каскадный эффект. Для минимизации влияния повторов ограничивайте их количество и используйте экспоненциальный алгоритм отсрочки, чтобы каждый раз увеличивать задержку между повторами, пока не достигнете предела.
Поскольку повтор инициируется клиентом (браузером, другим микросервисом и так далее), который не знает, была ли операция сбойной до или после обработки запроса, приложение должно уметь обрабатывать идемпотентность. Например, когда вы повторяете операцию покупки, то вы не должны дублировать взимание средств с покупателя. Вам поможет использования уникального ключа идемпотентности для каждой транзакции.
Ограничение скорости и Load Shedder’ы
Ограничение скорости — это методика определения количества запросов, которые могут быть приняты или обработаны конкретным потребителем или приложением в течение определённого времени. С помощью ограничения скорости мы можем, к примеру, отфильтровывать наших потребителей и микросервисы, из-за которых возникают всплески трафика. Или можем удостовериться, что приложение не будет перегружено, пока на помощь не придёт автомасштабирование.
Также вы можете ограничивать низкоприоритетный трафик, чтобы выделить больше ресурсов на критически важные транзакции.
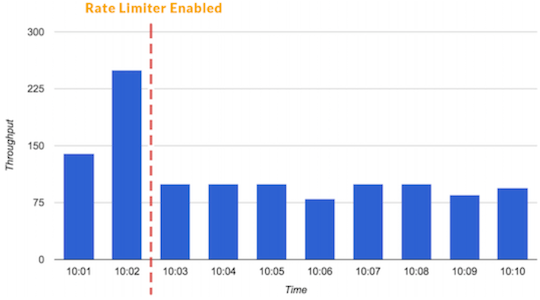
Ограничитель скорости может предотвращать всплески трафика.
Другой вид ограничителя скорости называется ограничитель одновременных запросов (concurrent request limiter). Он может быть полезен, когда у вас есть «дорогие» конечные точки, которые не рекомендуется вызывать больше определённого количества раз, если вы хотите обслуживать трафик.
Чтобы у вас всегда хватало ресурсов для обслуживания критически важных транзакций, используйте fleet usage load shedder. Он удерживает часть ресурсов для высокоприоритетных запросов и не позволяет низкоприоритетным транзакциям их использовать. Load shedder принимает свои решения на основе общего состояния системы, а не размера одиночного пользовательского запроса. Также LS’ы помогут вашей системе восстановиться, поскольку они обеспечивают работу ключевой функциональности в ходе инцидента.
Почитать подробнее об ограничителях скорости и load shedder’ах можно в этой статье: https://stripe.com/blog/rate-limiters.
Сбоить быстро и раздельно
В микросервисной архитектуре нужно подготовить свои сервисы сбоить быстро и раздельно. Чтобы изолировать проблемы на уровне сервисов, мы можем использовать шаблон bulkhead.
Быстрый сбой компонентов нужен потому, что мы не хотим ждать, пока закончатся таймауты сломанных инстансов. Ничто так не раздражает, как зависший запрос и не отвечающий на ваши действия интерфейс. Это не только потерянные ресурсы, но и испорченный пользовательский опыт. Сервисы вызывают друг друга по цепочке, поэтому нужно уделять особое внимание предотвращению повисания операций, не допуская накопления задержек.
Вероятно, вам в голову сразу пришла идея применения небольших таймаутов (fine grade timeouts) для каждого вызова сервиса. Но проблема в том, что вы не можете знать, какое значение таймаута будет подходящим, потому что есть ситуации, когда сетевые отказы и другие возникающие проблемы влияют только на одну-две операции. В этом случае вы, вероятно, не захотите отклонить эти запросы из-за того, что некоторые из них завершаются по таймауту.
Можно сказать, что применение парадигмы «быстрого сбоя» в микросервисах посредством таймаутов является антипаттерном, которого следует избегать. Вместо таймаутов можете применять шаблон circuit-breaker, который зависит от статистики успешных/сбойных операций.
Переборки
Переборки используются в кораблестроении для разделения корабля на секции, чтобы каждая секция могла быть задраена в случае пробоя корпуса.
Принцип переборок можно применить в разработке ПО для разделения ресурсов, чтобы защитить их от исчерпания. Например, если у нас есть два типа операций, которые взаимодействуют с одним инстансом базы данных, имеющим ограничение по количеству подключений, то можно использовать два пула подключений вместо одного общего. В результате такого разделения «клиент—ресурс» операция, которая инициирует таймаут или будет злоупотреблять пулом, не повлияет на работу других операций.
Одной из главных причин гибели «Титаника» была неудачная конструкция переборок, при которой вода могла по палубам переливаться в другие отсеки, заполняя весь корпус.
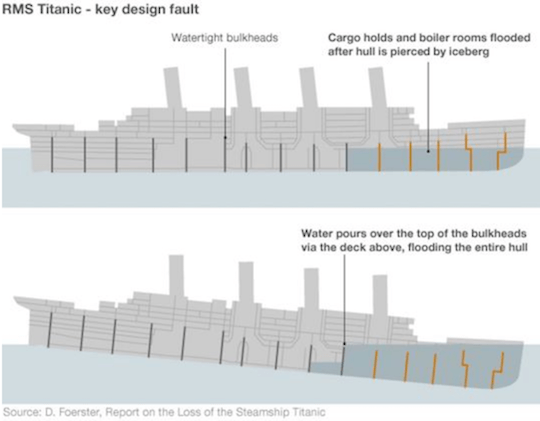
Переборки на «Титанике» (они не сработали).
Автоматы замыкания (Circuit Breakers)
Таймауты можно использовать для ограничения продолжительности операций. Они могут предотвратить подвисание операций и поддерживать реагирование системы на ваши действия. Использование в микросервисной архитектуре статичных, тонко настраиваемых таймаутов является антипаттерном, поскольку речь идёт о высокодинамичной среде, в которой практически невозможно подобрать подходящие временные ограничения, хорошо работающие в любых ситуациях.
Вместо использования маленьких статичных таймаутов, зависящих от транзакций, для обработки ошибок можно использовать автоматы замыкания (circuit breakers). Действие этих программных механизмов аналогично одноимённым электротехническим устройствам. С помощью автоматов замыкания вы можете защитить ресурсы и помочь им восстановиться. Они могут быть очень полезны в распределённых системах, где повторяющийся сбой может стать причиной лавинообразного эффекта, который положит всю систему.
Автомат замыкания открывается, когда в течение короткого времени несколько раз возникает ошибка определённого типа. Открытый автомат предотвращает передачу запросов — как реальный автомат прерывает электрическую цепь и не даёт току течь по проводам. Автоматы замыкания обычно закрываются через определённое время, давая сервисам передышку для восстановления.
Помните, что не все ошибки должны инициировать автомат замыкания. Например, вы наверняка захотите пропустить ошибки на стороне клиента вроде запросов с кодами 4хх, но при этом отреагировать на серверные сбои с кодами 5хх. Некоторые автоматы замыкания могут находиться в полуоткрытом состоянии. Это означает, что сервис отправляет первый запрос для проверки доступности системы, а остальные запросы отсекаются. Если первый запрос прошёл удачно, автомат переходит в закрытое состояние и не препятствует течению трафика. В противном случае автомат остаётся открытым.
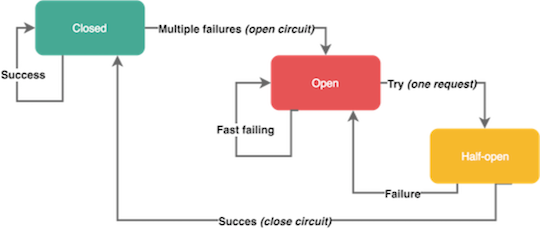
Автомат замыкания.
Проверка на сбои
Вы должны постоянно проверять поведение своей системы в условиях распространённых проблем, чтобы удостовериться, что ваши сервисы могут пережить различные сбои. Почаще проводите тестирования, чтобы ваша команда была готова к инцидентам.
Вы можете воспользоваться внешним сервисом, который идентифицирует группы инстансов и случайным образом прерывает работу одного из участников группы. Так вы будете готовы к сбою одиночного инстанса. А можете перекрывать целые регионы, чтобы эмулировать сбой у облачного провайдера.
Одно из самых популярных решений — инструмент проверки на отказоустойчивость ChaosMonkey.
Заключение
Реализация и поддержание работы надёжного сервиса — задача непростая. Она требует больших усилий и стоит немалых денег.
У надёжности есть разные уровни и аспекты, так что важно найти решение, лучше всего подходящее для вашей команды. Сделайте надёжность одним из факторов в процессе принятия бизнес-решений и выделите на это достаточно денег и времени.
Ключевые выводы
- Для динамических сред и распределённых систем — вроде микросервисов — характерен повышенный риск сбоев.
- Сервисы должны сбоить раздельно, чтобы обеспечивалась плавная деградация обслуживания и не рушился пользовательский опыт.
- 70% сбоев вызваны изменениями, так что не нужно стесняться отката кода.
- Сбои должны проходить быстро и раздельно. У команд нет контроля над зависимостями их сервисов.
- Архитектурные шаблоны и методики вроде кэширования, переборок, автоматов замыканий и ограничителей скорости помогают создавать надёжные микросервисы.
