
Рассказывать, какие есть кэши, что такое Result Cache, как он сделан в Oracle и в других базах данных не очень интересно и довольно шаблонно. Но все приобретает совершенно другие краски, когда речь идет о конкретных примерах. Александр Токарев (shtock) построил свой доклад на Highload++ 2017 исходя из кейсов. И именно опираясь на кейсы, рассказал, когда может быть удобен самодельный кэш, в чем боль server-side Result Cache и как заменить его клиентским, и вообще вывел ряд полезных советов по настройке Result Cache в Oracle.
О спикере: Александр Токарев работает в компании DataArt и занимается вопросами, связанными с базами данных как в части построения систем «с нуля», так и оптимизации имеющихся.
Начнем с нескольких риторических вопросов. Вы работали с Oracle Result Cache? Вы верите, что Oracle — это база данных, удобная на все случаи? По опыту Александра большинство людей на последний вопрос отвечает отрицательно, на сто суровых прагматиков приходится один мечтатель. Но благодаря его вере двигается прогресс.
Кстати, у Oracle уже 14 баз данных — пока 14 — что будет в будущем, неизвестно.
Как уже говорилось, все проблемы и решения будут проиллюстрированы конкретным кейсами. Это будет два кейса из проектов DataArt, и один сторонний пример.
Database caches
Начнем с того, какие в базах данных есть кэши. Тут все понятно:
Причем Result cache, по большому счету, используется только в Oracle. Он когда-то был в MySQL, но потом его героически выпилили. В PostgreSQL его тоже нет, он присутствует в том или ином виде только в стороннем продукте pgpool.
Кейс 1. Хранилище ретейлера

Выше схема продукта, который был у нас на сопровождении — хранилище (Oracle 11, 20 Tb, 300 пользователей), и в нём какой-то тоскливый отчёт, в котором на 5000 строк данных было 350 уникальных товаров. Получение его занимало около 20 минут, и пользователи печалились.
В этом отчете есть SELECT, JOIN’ы и функция. Функция как функция, все бы хорошо, только она рассчитывает загадочный параметр, который называется «величина трансфертного ценообразования», работает 0,2 с — вроде ни о чем, но вызывается она столько раз, сколько строк в таблице. В этой функции 400 строк SQL+PL/SQL, а т.к. продукт на поддержке, менять её боязно.
По этой же причине нельзя было использовать result_cache.

Чтобы решить проблему, используем стандартный подход с hand-made кэшированием: первые 3 блока схемы оставляем, как было, нашу функцию sku_detail() просто переименовываем в sku_full() и объявляем ассоциативный массив, где соответственно:
Делаем очевидную функцию cache(sku): если в нашем ассоциативном массиве нет такого id, запускается наша функция, результат помещается в кэш, сохраняется и возвращается. Соответственно, если такой id есть, то всего этого не происходит. Фактически мы получили on demand cache.
Таким образом, мы свели количество вызовов функции к тому количеству, которое на самом деле надо. Время обработки отчета уменьшилось до 4 минут, всем пользователям стало хорошо.
Hand-made Cache Memory
Недостатки и достоинства данной системы понятны из этой большой умной картинки, к которой мы будем много обращаться — это архитектура памяти.
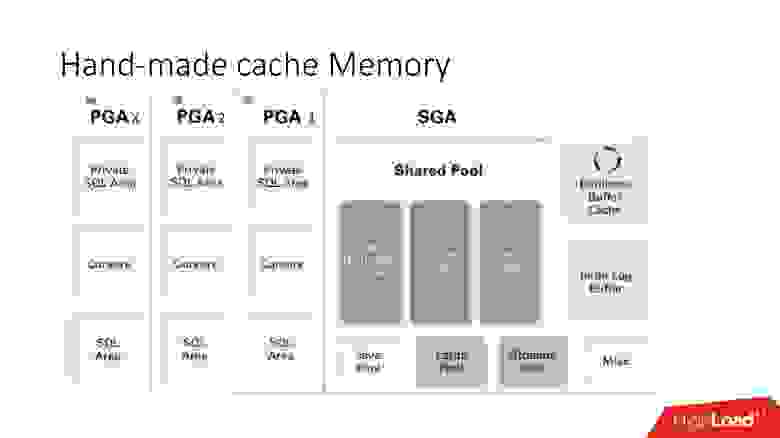
Важно понимать, в какой из областей памяти расположены коллекции. Помещаются они в область памяти, которая называется PGA. Program global area инстанциируется на каждое подключение к базе данных. Именно это определяет достоинства и недостатки, поскольку больше подключений — больше памяти, а память дорогая, серверная, админы нежные.

Существуют и другие варианты hand-made кэшей на основе materialized views, temporary tables, но от них идёт большая нагрузка на систему ввода-вывода, поэтому здесь мы их не рассматриваем. Они более применимы для других баз данных, в которых обычно подобные проблемы решаются тем, что хранимая процедура материализуется в какую-нибудь промежуточную таблицу и до обращения к тяжелому запросу данные берутся из нее. И только, если там не нашлось нужного, то вызывается исходный запрос.

Выше иллюстрация этого такого подхода к задаче кэширования для получения списка сопутствующих товаров в MsSQL. В целом, подход относительно похож, но работает не в памяти БД как в части получения данных, так и первичного заполнения, за счёт этого может быть медленнее.
В общем, самодельные result_cache активно используются, но иным подходом к реализации данной задачи является in-database result_cache. Его и как не получилось quick win мы рассмотрим далее.
Кейс 2. Обработка финансовой документации
Итак, наш второй случай.

Это система полуавтоматизированной обработки финансовой документации — тоскливый enterprise с классической архитектурой, которая включает в себя:
Одна из множества задач этой системы — это расчет рекомендаций.

Есть документы, для каждого нераспознанного автоматически системой показателя предлагается набор показателей либо из предыдущих документов клиента, либо из похожей индустрии, либо по похожей доходности, при этом показатель сравнивается с распознанным значением, чтобы не предложить лишнее. Что важно, документы многоязычные.
Пользователь выбирает нужное значение и повторяет операцию для каждой пустой строчки.
Упрощённо эта задача состоит в следующем: поступают документы в виде key-value пар от разных систем распознавания, причем где-то параметры распознаны, а где-то нет. Надо сделать так, чтобы в итоге пользователи обработали документы и все значения стали распознаны. Рекомендация как раз нацелена на упрощения этой задачи и учитывает:
На самом деле это порядка 12 весьма сложных правил.
Изначальные допущения:
Никакого highload вообще — все скучно.
Итак, наступает время релиза. Произошел Code freeze, Java все боятся трогать, а на обработку документа уходит минимум 5 минут.
В команду разработки баз данных приходят с просьбой о помощи. Конечно, ведь, если что-то тормозит в JVM, то само собой, надо менять или чинить базу данных.

Мы изучили документы и поняли, что в key-value парах довольно часто повторяются значения — по 5-10 раз. Соответственно, решили использовать базу данных, чтобы кешировать, потому что она уже протестирована.
Мы решили использовать Oracle server-side Result Cache, потому что:
Oracle Result Cache
Result cache — технология от Oracle по кэшированию результатов — обладает следующими свойствами:
Как его включить?
Способ № 1

Очень просто — указать инструкцию result_cache. На слайде видно, что появился идентификатор результата. Соответственно, при первом выполнении запроса, база данных произведет какую-то работу, при последующем исполнении в данном случае никакая работа не нужна. Все хорошо.
Способ № 2

Второй способ позволяет разработчикам приложений ничего не делать — это так называемые аннотации. Мы для таблицы указываем галочку, что запрос к ней должен помещаться в result_cache. Соответственно, никакого hint нет, приложение не трогаем, а все уже в result_cache.
Чтобы он закэшировался, все таблицы, участвующие в запросе, должны иметь аннотацию result_cache.
Dependency Tracking
Есть соответствующие представления, в которых можно посмотреть, какие есть зависимости.

На примере выше запрос JOIN какая-то таблица, в которой одна зависимость. Почему? Потому, что Oracle определяет dependency не просто синтаксическим анализом, а осуществляет его по результатам плана выполнения работы.
В данном случае выбран такой план, потому что используется только одна таблица, и на самом деле таблица jobs связана с таблицой employees через foreign key constraint. Если мы уберем foreign key constraint, который позволяет сделать это преобразование join elimination, то мы увидим две зависимости, потому что так поменяется план.
Oracle не отслеживает то, что не надо отслеживать.
В PL/SQL dependency работает в run-time, чтобы можно было использовать динамический SQL и прочие вещи делать.

Обратите внимание, что кэшировать можно не только весь запрос целиком, можно кэшировать inline view как в виде with, так и в виде from. Предположим, для чего-то одного нам нужен кэш, а другое лучше бы читать из базы данных, чтобы ее не напрягать. Мы берем inline view, опять объявляем как result_cache и видим — идет кэширование только по одной части, а за второй мы каждый раз обращаемся к базе данных.

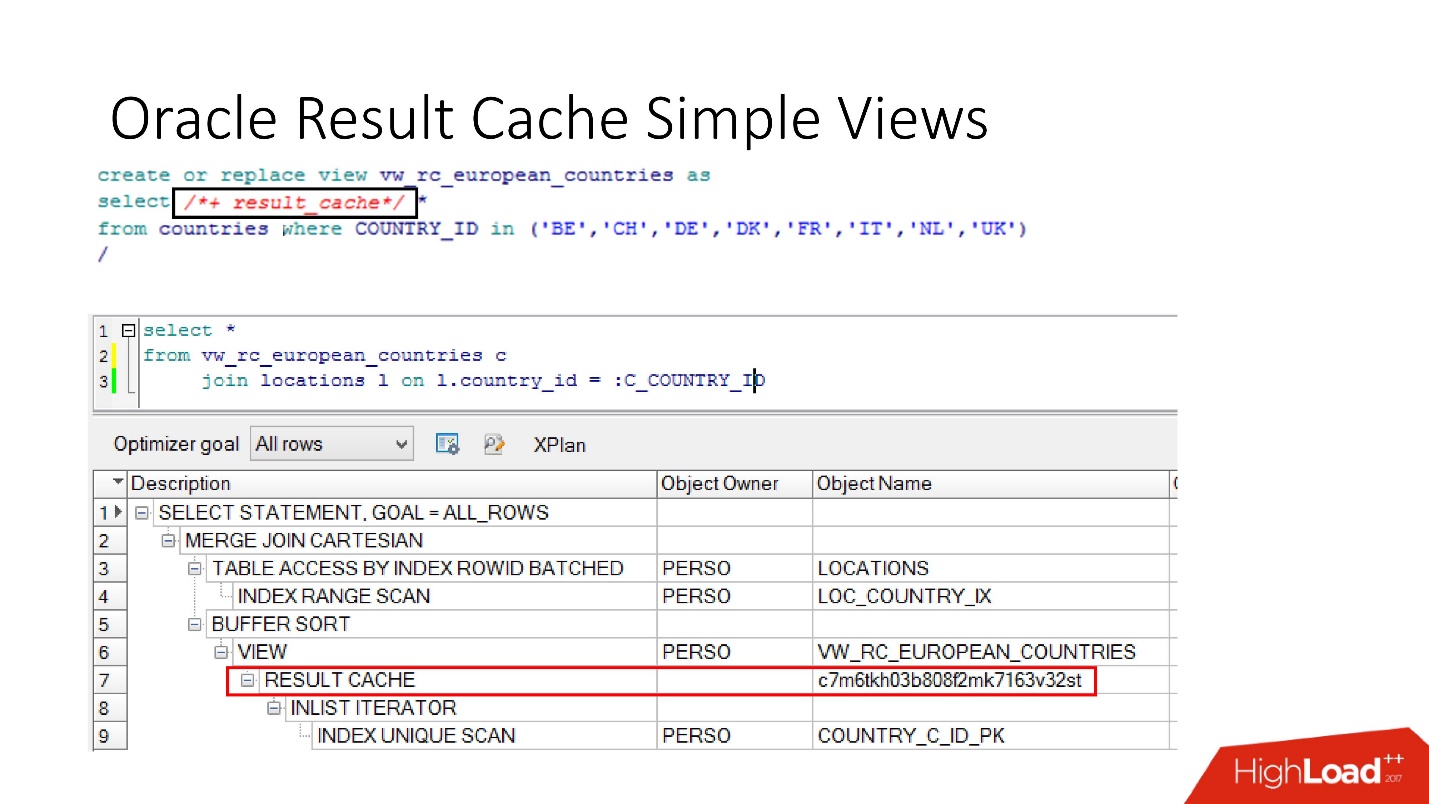
И, наконец, в базах данных тоже есть инкапсуляция, хотя в это никто не верит. Мы берем view, ставим в нем result_cache, и наши программисты даже не догадываются, что оно закэшировано. Ниже мы видим, что на самом деле только одна его часть работает.

Инвалидация
Итак, посмотрим когда же Oracle инвалидирует result_cache.Статус Published показывает текущее состояние валидности кэша. Когда запрос к result_cache, как я уже говорил, в базе данных нет никаких работ

Когда мы сделали апдейт, статус все равно Published, потому что апдейт не закоммитился и другие сессии должны видеть старый result_cache. Это та самая пресловутая консистентность по чтению.
Но в текущей сессии мы увидим, что нагрузка пошла, так как именно в этой сессии кэш игнорируется. Это вполне разумно, сделаем commit — результат станет Invalid, все работает само.

Казалось бы — мечта! Dependency считаются правильно — просто в зависимости от запроса. Но нет, вскрылся ряд нюансов. Oracle производит инвалидации и в ряде неочевидных случаев:
Еще есть такой антипаттерн про result_cache, когда разработчики, услышав, что есть такая классная вещь, думают: «О, есть хранилище! Сейчас возьмем какой-нибудь запрос, который на 2-3 партициях работает — на текущей дате и на предыдущей, пометим его как result_cache, и он будет всегда браться из памяти!»
Но когда меняют патрицию задним числом, весь кэш слетает, потому что на самом деле единица отслеживания dependency в result_cache — это всегда таблица, и не знаю, будут ли когда-нибудь партиции или не будут.
Мы подумали и решили, что пойдем в продакшен рекомендательной системы с такими вещами:
Все проверили, провели performance-тесты, время обработки — 30 с. Все замечательно, идем в продакшен!
Накатили — ушли спать. Приходим с утра. Видим письмо: «Распознавание занимает минимум 20 минут, сессии зависают». Почему они зависают? Каким образом 30 секунд превратились в 20 минут?
Стали разбираться, смотреть в базу данных:
Проведя внутреннее расследование, мы выяснили, что Java-разработчики делают распознавание в 3 потока.
Мы расстроились — 5-кратная нагрузка, падение, деградация, причем даже при таких параметрах такого проседания не должно было быть.
Очевидно, надо разбираться.
Мониторинг

Для мониторинга у нас есть две ключевых вещи:
MEMORY_REPORT — это вариации на тему, они нам не понадобятся.
Oracle — волшебный! Есть великолепная документация, но она рассчитана на тех, кто переходит с других баз данных, чтобы они читали и думали, что Oracle — это очень круто! А вот вся информация по result_cache лежит только на support.

Есть нюанс, который состоит в том что, как только мы обращаемся к этим объектам, чтобы разрешить проблему, мы ее усугубляем, окончательно закапывая себя! До Oracle12.2, до патча которой вышел в октябре прошлого года, эти запросы делают result_cache недоступным на статус и на запись до тех пор, пока они полностью не посчитаются.

Итак, воспользовавшись представлением v$result_cache_objects, мы выяснили, что в списке закэшированных объектов тысячи записей — намного больше, чем мы ожидали. Причем, это были объекты из каких-то не наших запросов по странным таблицам — маленькие таблички, и запросы last_modified_date. Очевидно, кто-то натравил на нашу базу ETL.
Перед тем как идти ругаться на разработчиков ETL, мы проверили, что для этих таблиц включена опция result_cache force, и вспомнили, что мы сами её включили, так как некоторые из этих данных часто требовались приложению и кэширование было уместно.

А получилось, что все эти запросы просто берут и вымывают наш кэш. К счастью, у разработчиков была возможность повлиять на ETL в продакшене, поэтому мы смогли изменить result_cache, чтобы исключить эти ежеминутные запросы.
Как вы думаете, полегчало? — Не полегчало! Количество кэшируемых объектов уменьшилось, а потом снова выросло до 12000. Мы продолжили изучать, что же ещё кэшируется, так как скорость не менялась.

Смотрим — куча запросов, и такие умные, но все непонятные. Хотя тот, кто работал с Oracle 12, знает, что DS SVC — это адаптивная статистика. Она нужна для улучшения производительности, но когда есть result_cache, она оказывается, его убивает, потому что происходит конкуренция. Это само собой, написано только на support.
Мы знали, как устроен workload и понимали, что в нашем случае адаптивная статистика не особо радикально улучшит наши планы. Поэтому мы героически ее отключили — результат, как и написано в секретном мануале — 10 минут на документ. Неплохо, но еще недостаточно.
Защелки
Конкуренция между result_cache и DS SVC возникает из-за того, что в Oracle есть защелки (latches) — легковесные маленькие блокировочки.

Не вдаваясь в детали, как они работают, пытаемся поставить именованную защелку несколько раз — не получилось — Oracle берет и засыпает
Тот, кто в теме, может сказать, что в result_cache ставится по две защелки на каждый блок при fetch. Это детали. В result_cache есть два вида защелок:
1. Защелка на тот период, пока мы записываем в result_cache данные.

То есть если у вас запрос работает 8 с, на период этих 8 с другие такие же запросы (ключевое слово «такие же») не смогут ничего сделать, потому что они ждут, пока данные запишутся в result_cache. Другие запросы запишутся, но подождут блокировку только на первую строчку. Сколько им придется ждать, неизвестно, это недокументированный параметр result_cache_timeout. После этого они начинают как бы игнорировать result_cache, и работают медленно. Правда, как только блокировка с последней строчки при помещении снялась, они автоматом начинают снова работать с result_cache.
2. Второй тип блокировок — на получение из result_cache тоже с 1-й строчки по последнюю.
Но так как fetch происходит из мгновенной памяти, то они снимаются очень быстро.

Обязательно надо иметь в виду, что, когда DBA видит в базе данных защелки, он начинает говорить: «Защелки! Wait time — все пропало! » И тут начинается самая интересная игра: убеди DBA, что wait time от защелок на самом деле несравненно меньше, чем время повторения запроса.

Как показывает наш опыт, наши измерения, защелки на result_cache занимают 10% от самих запросов.

Это агрегированная статистика. То, что все плохо, можно понять по тому, что забит кэш. Еще одно подтверждение — Proper results are deleted. То есть кэш перезатирается. Вроде бы, мы умные и всегда считаем размеры памяти — взяли размер строчек нашего кэшируемого результата для нашей рекомендации, умножили на количество строк, и что-то пошло не так.

На support мы нашли 2 бага, которые говорят, что при переполнении result_cache происходит деградация производительности. И это тоже исправили в том самом секретном патче.
Секрет в том, что память выделяется блоками. В нашем случае, конечно, еще добавилось то, что workload вырос в 5 раз. Поэтому при расчете память не надо умножать на ширину ваших данных, а умножайте на размер блока, и тогда будет счастье.
Что еще можно настроить?
Параметров море: есть документированные и недокументированные параметры. На самом деле, нам не нужны все эти параметры.

По факту достаточно 4 параметров:
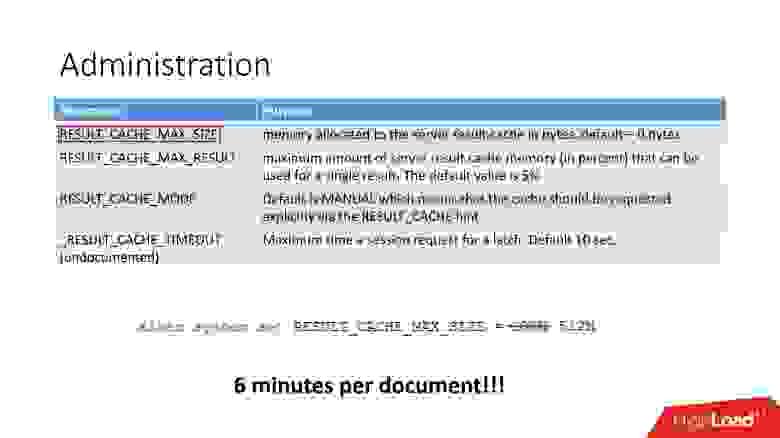
Нам хватило даже одного — размер кэша. После того, как мы заменили 100 Мб на 512Мб, время обработки документа сократилось до 6 минут.
Все равно копаем дальше, вдруг есть еще что-нибудь странное. Например, Invalidation Count = 10000.
Не ошибается тот, кто ничего не делает. Путём неких изысканий мы обнаружили, что отключен job обновления рекомендаций, что приводило к постоянному обновлению данных. Соответственно, кэш постоянно инвалидировался. Мы запустили job с часовым интервалом, как и было задумано, что автоматически отключило постоянное обновление таблицы.
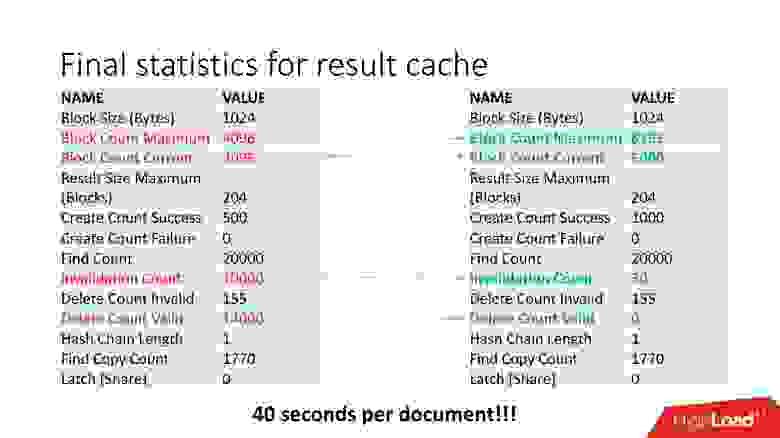
Всегда есть свободное место, invalid только в момент пересчета кэша, и удаления данных нет. При пятикратном увеличении нагрузки мы получили скорость обработки документа 40 с.
Самое важное, чтобы кэш не переполнялся. Пока мы все это изучали, мы обнаружили кучу недокументированных фишек, которые есть в ядре Oracle. Они великолепны!

SHELFLIVE — параметр, который позволяет обеспечить read-consistent умирание кэша, то есть кэшируемый запрос умрет через 10 с, и кэш почистится. Этот параметр был встроен в новую версию приложения. Важно, что кэш так же удаляется, если было изменение данных.
Есть еще более интересная опция — SNAPSHOT. Она удобна, если факт изменения не критичен для кэша, нет необходимости в сохранении read-consistent и нет защелок — тогда изменения данных не будут инвалидировать кэш.
Ограничения понятны:

Result cache inside Oracle
Result_cache — это фишка Oracle Core. Она используется на самом деле в куче всего, все, что связано с job использует result_cache (кстати, выделен тот секретный hint, где мы это обнаружили) и везде, что связано с APEX.

Все, что связано с Dynamic sampling и с адаптивной статистикой, то есть все, что делает ваше предсказание более правильным, работает на result_cache.

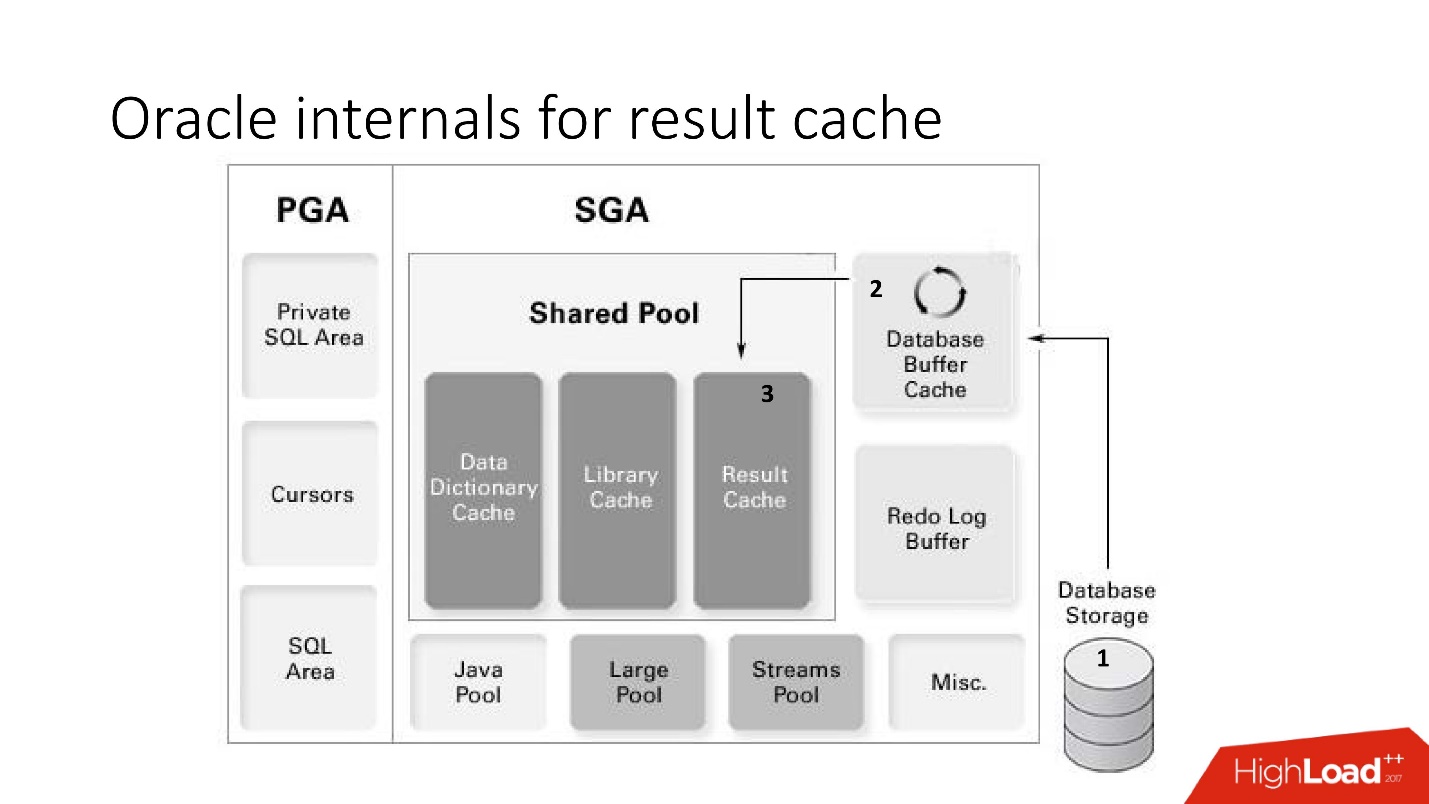
Oracle internals for result cache
Вернемся к схеме памяти и кратко подытожим работу result_cache:
Плюсы:
Минусы:
Мы не одиноки!
Из всего сказанного может возникнуть ощущение, что мы такие криворукие. Но посмотрите в support Oracle, например, за 29 сентября 2017 г.: новая версия Oracle E-Business suite падает по причине result_cache, потому что они решили ее ускорить.

Однако, нам интересен не сам факт наличия проблем, а способы их не допустить. В дебрях интернета я нашел очень познавательное письмо службе support одной из ведущих российских облачных систем расчета лояльности, в которой произошел сбой, и система была недоступна суммарно час.

Драматическое увеличение времени выдачи из кэша во время наката патчей произошло в следствие:
Однако, тесты багов написаны так хитро, что в них фактически явно говорится, что в v_result_cache_objects есть ошибка.

Чтобы справиться с проблемой, эта компания сделала примерно то же самое, что и мы: увеличили размер кэша и кое-что отключили. Для меня лично интересно, как они это сделали, потому что отключить можно тремя способами:
Какой отсюда можно сделать вывод?
Как мы заметили, основная проблема кэшей на сервере — это расход дорогой серверной памяти. У Oracle есть третье, заключительное решение.
Client side result cache

Схема его устройства изображена на выше, это главные компоненты БД и драйвер.
При первом обращении client-side Result Cache идет в базу данных, которая предварительным образом настроена, получает размер клиентского кэша из базы данных и инстанциирует у себя на клиенте этот кэш разово при первом подключении. Кэшируемый запрос первый раз обращается к базе данных, и записывает данные в кэш. Остальные потоки запрашивают общий кэш драйвера, тем самым экономя память и ресурсы сервера. Кстати, иногда в зависимости от нагрузки драйвер присылает в БД статистику по использованию кэша, которую потом можно будет посмотреть.
Интересен вопрос, как происходит инвалидация?
Есть два режима инвалидации, которые заточены на параметр Invalidation lag. Это то, сколько Oracle позволяет кэшу на драйвере быть не консистентным.
Первый режим используется, когда запросы идут часто и не наступает Invalidation lag. В таком случае поток пойдёт в базу данных, обновит кэши и считает данные из него.

Если Invalidation lag не прошел, то любой некэшируемый запрос, обращаясь к базе данных, кроме результатов запроса приносит список инвалидных объектов. Соответственно они помечаются в кэше как инвалидные, и все работает как на картинке из первого сценария.
Во втором случае, если прошло больше времени, чем Invalidation lag, то сам клиентский result_cache идет в базу данных и говорит: «А дай-ка мне список изменений!» То есть он сам в себе поддерживает свое адекватное состояние.
Сконфигурировать client-side Result Cache очень просто. Есть 2 параметра:

С точки зрения разработчика приложений клиентский кэш особо не отличается от серверного, также вписали hint result_cache. Если он был, то он просто начнет использоваться клиентский — что на .Net, что на Java.

Сделав 10 итераций запроса, я получил следующее.

Первое обращение — создание, далее 9 обращений к кэшу. В таблице отмечено, что память тоже выделяется блоками. Еще обратите внимание на SELECT — он не очень интуитивный. Я, если честно, до того, как начал с этим разбираться, даже не знал, что есть такое представление
Достоинства клиентского кэширования:
Недостатки:
На support, который мы всегда используем, когда работаем с result_cache, я нашел всего лишь 5 багов. Это говорит о том, что, скорее всего, это мало кому нужно.
Итак, сводим в кучу все, что сказано выше.
Hand-made cache
Плохие сценарии:
Хорошие сценарии:
Server side Result cache
Плохие сценарии:
Хорошие сценарии:
Client side Result cache
Плохие сценарии:
Хорошие сценарии:
Выводы
Я считаю, что мой рассказ про боль Server side Result cache, поэтому выводы таковы:
О спикере: Александр Токарев работает в компании DataArt и занимается вопросами, связанными с базами данных как в части построения систем «с нуля», так и оптимизации имеющихся.
Начнем с нескольких риторических вопросов. Вы работали с Oracle Result Cache? Вы верите, что Oracle — это база данных, удобная на все случаи? По опыту Александра большинство людей на последний вопрос отвечает отрицательно, на сто суровых прагматиков приходится один мечтатель. Но благодаря его вере двигается прогресс.
Кстати, у Oracle уже 14 баз данных — пока 14 — что будет в будущем, неизвестно.
Как уже говорилось, все проблемы и решения будут проиллюстрированы конкретным кейсами. Это будет два кейса из проектов DataArt, и один сторонний пример.
Database caches
Начнем с того, какие в базах данных есть кэши. Тут все понятно:
- Buffer cache — кэш данных — cache for data pages/data blocks;
- Statement cache — кэш операторов и их планов — cache of queries plan;
- Result cache — кэш результатов строк — rows from queries;
- OS cache — кэш операционной системы.
Причем Result cache, по большому счету, используется только в Oracle. Он когда-то был в MySQL, но потом его героически выпилили. В PostgreSQL его тоже нет, он присутствует в том или ином виде только в стороннем продукте pgpool.
Кейс 1. Хранилище ретейлера
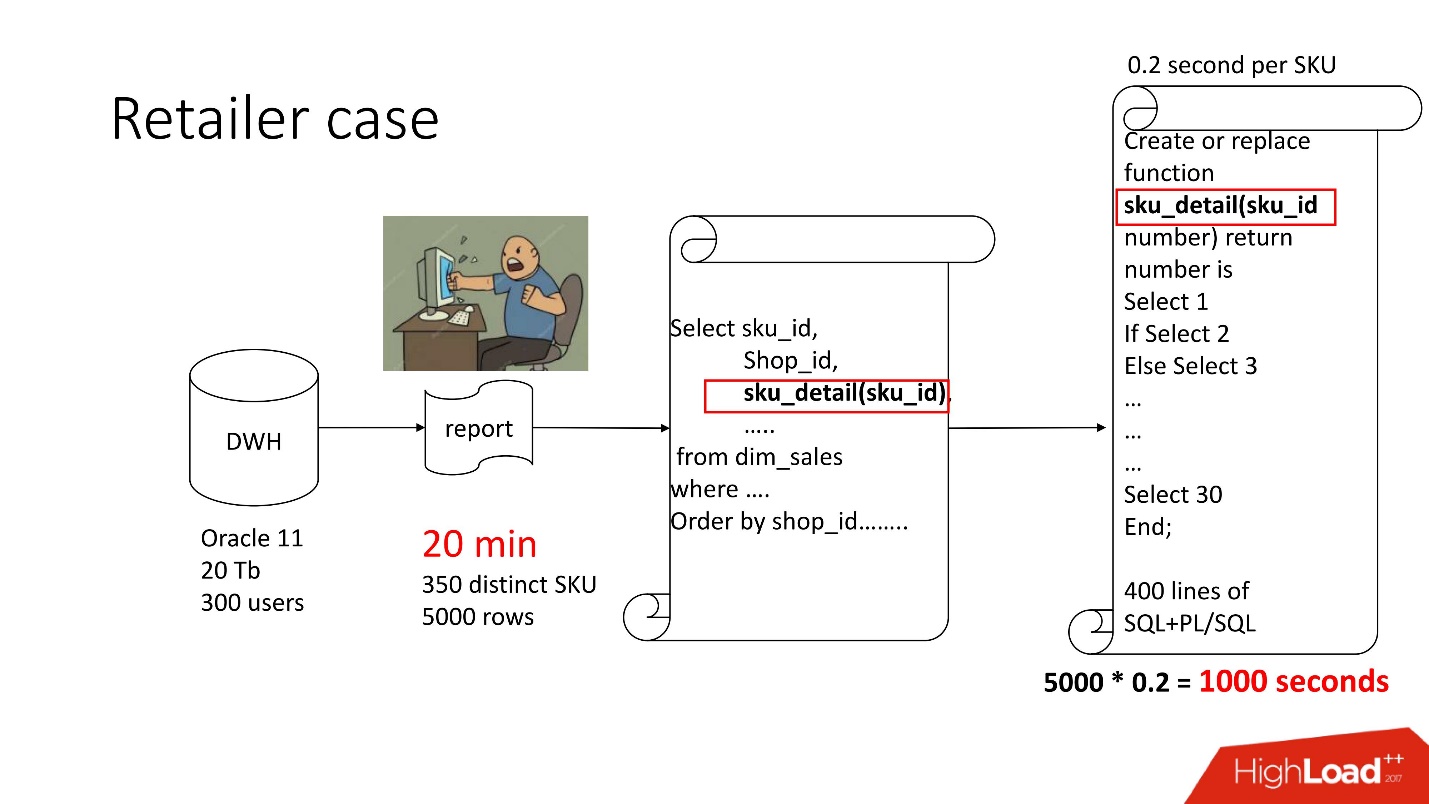
Выше схема продукта, который был у нас на сопровождении — хранилище (Oracle 11, 20 Tb, 300 пользователей), и в нём какой-то тоскливый отчёт, в котором на 5000 строк данных было 350 уникальных товаров. Получение его занимало около 20 минут, и пользователи печалились.
Презентация этого доклада, как и всех остальных, размещена на сайте конференции Highload++.
В этом отчете есть SELECT, JOIN’ы и функция. Функция как функция, все бы хорошо, только она рассчитывает загадочный параметр, который называется «величина трансфертного ценообразования», работает 0,2 с — вроде ни о чем, но вызывается она столько раз, сколько строк в таблице. В этой функции 400 строк SQL+PL/SQL, а т.к. продукт на поддержке, менять её боязно.
По этой же причине нельзя было использовать result_cache.
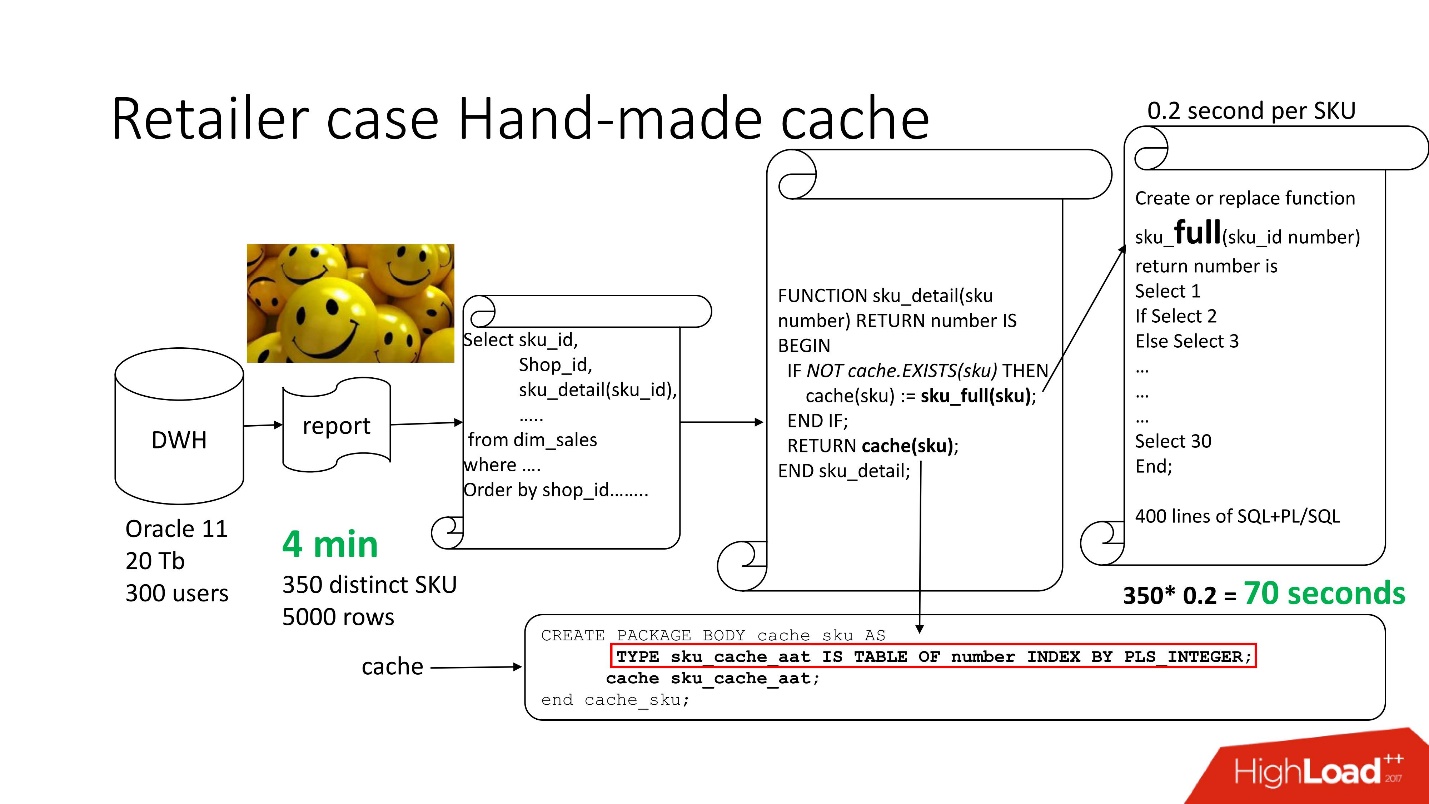
Чтобы решить проблему, используем стандартный подход с hand-made кэшированием: первые 3 блока схемы оставляем, как было, нашу функцию sku_detail() просто переименовываем в sku_full() и объявляем ассоциативный массив, где соответственно:
- ключи — это наши SKU (товарные позиции),
- значения — это рассчитанная цена трансферного преобразования.
Делаем очевидную функцию cache(sku): если в нашем ассоциативном массиве нет такого id, запускается наша функция, результат помещается в кэш, сохраняется и возвращается. Соответственно, если такой id есть, то всего этого не происходит. Фактически мы получили on demand cache.
Таким образом, мы свели количество вызовов функции к тому количеству, которое на самом деле надо. Время обработки отчета уменьшилось до 4 минут, всем пользователям стало хорошо.
Hand-made Cache Memory
Недостатки и достоинства данной системы понятны из этой большой умной картинки, к которой мы будем много обращаться — это архитектура памяти.
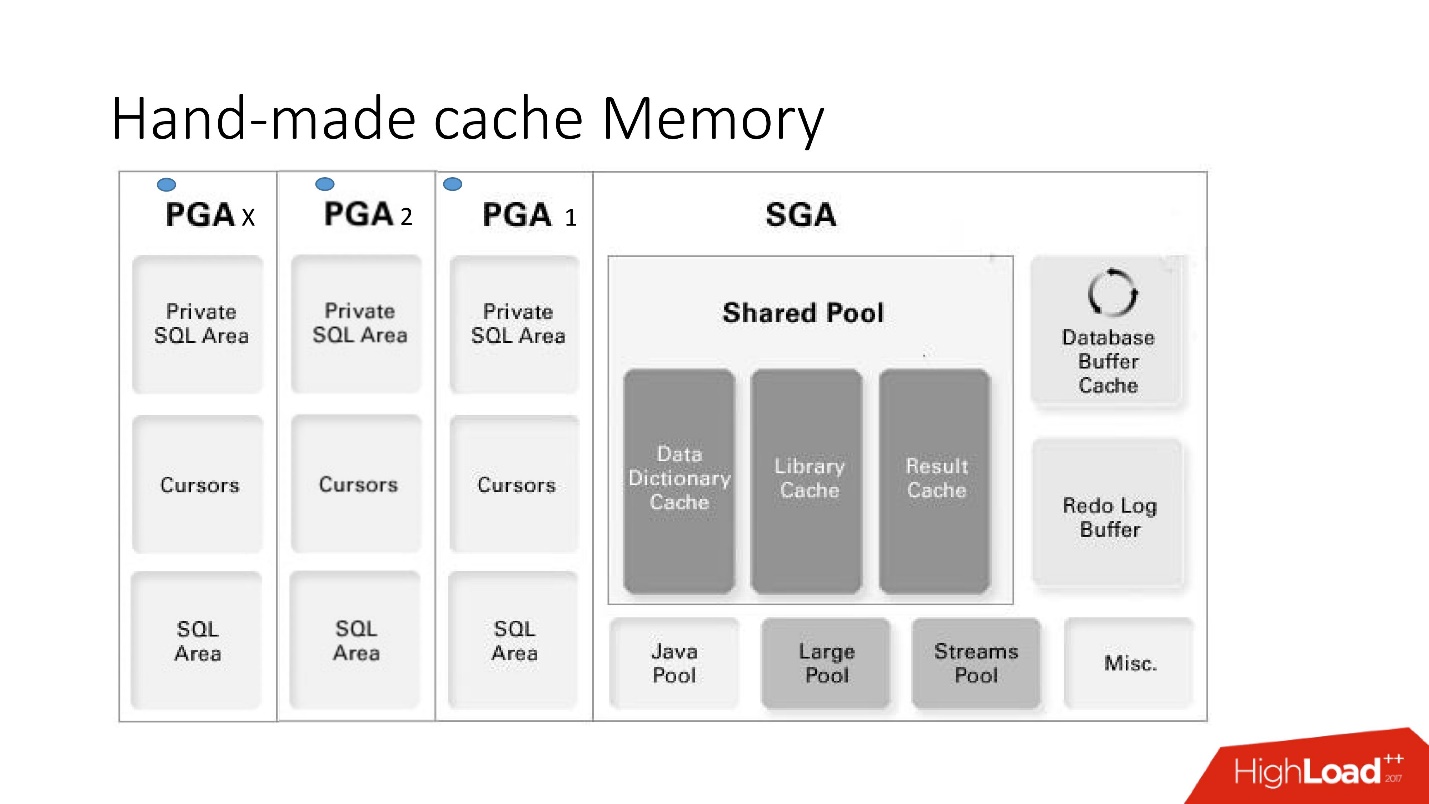
Важно понимать, в какой из областей памяти расположены коллекции. Помещаются они в область памяти, которая называется PGA. Program global area инстанциируется на каждое подключение к базе данных. Именно это определяет достоинства и недостатки, поскольку больше подключений — больше памяти, а память дорогая, серверная, админы нежные.

- Плюсы: все работает очень быстро, очень легко делается, конфигурировать не надо, нет никаких заморочек с межпроцессным задействованием.
- Минусы понятны: если в проекте запрещена хранимая логика их невозможно использовать, нет механизма автоматической инвалидации и так как память на кэш выделяется в рамках одной сессии БД, а не экземпляра, то её потребление завышено. Более того, в случае с вариантом использования connection pool необходимо не забывать сбрасывать кэши, если для каждой сессии кэширование должно быть разное.
Существуют и другие варианты hand-made кэшей на основе materialized views, temporary tables, но от них идёт большая нагрузка на систему ввода-вывода, поэтому здесь мы их не рассматриваем. Они более применимы для других баз данных, в которых обычно подобные проблемы решаются тем, что хранимая процедура материализуется в какую-нибудь промежуточную таблицу и до обращения к тяжелому запросу данные берутся из нее. И только, если там не нашлось нужного, то вызывается исходный запрос.

Выше иллюстрация этого такого подхода к задаче кэширования для получения списка сопутствующих товаров в MsSQL. В целом, подход относительно похож, но работает не в памяти БД как в части получения данных, так и первичного заполнения, за счёт этого может быть медленнее.
В общем, самодельные result_cache активно используются, но иным подходом к реализации данной задачи является in-database result_cache. Его и как не получилось quick win мы рассмотрим далее.
Кейс 2. Обработка финансовой документации
Итак, наш второй случай.
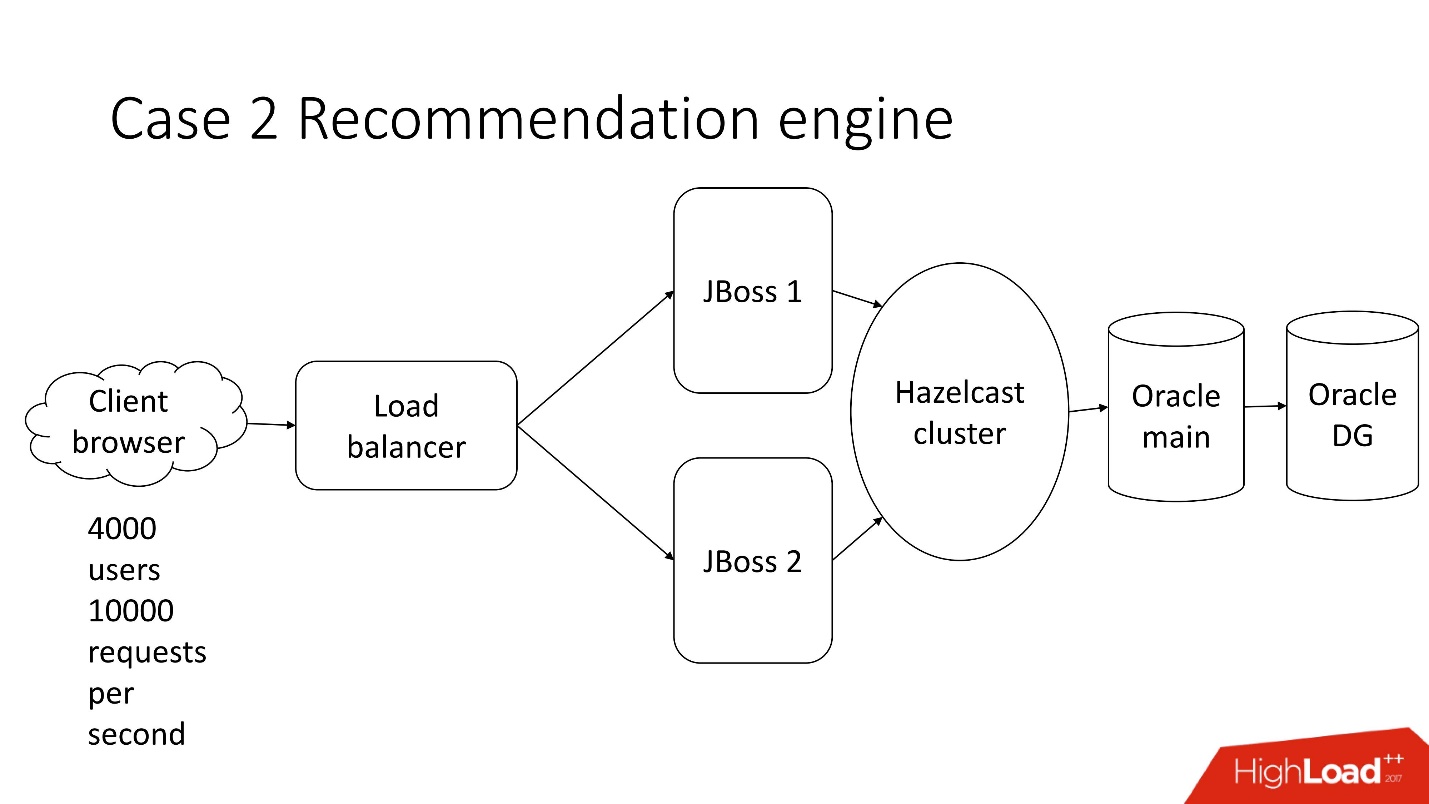
Это система полуавтоматизированной обработки финансовой документации — тоскливый enterprise с классической архитектурой, которая включает в себя:
- тонкий клиент;
- 4000 пользователей, которые живут в разных частях земного шара;
- балансировщик;
- 2 JBoss для расчёта бизнес-логики;
- in-memory cluster;
- основной Oracle;
- резервный экземпляр Oracle.
Одна из множества задач этой системы — это расчет рекомендаций.

Есть документы, для каждого нераспознанного автоматически системой показателя предлагается набор показателей либо из предыдущих документов клиента, либо из похожей индустрии, либо по похожей доходности, при этом показатель сравнивается с распознанным значением, чтобы не предложить лишнее. Что важно, документы многоязычные.
Пользователь выбирает нужное значение и повторяет операцию для каждой пустой строчки.
Упрощённо эта задача состоит в следующем: поступают документы в виде key-value пар от разных систем распознавания, причем где-то параметры распознаны, а где-то нет. Надо сделать так, чтобы в итоге пользователи обработали документы и все значения стали распознаны. Рекомендация как раз нацелена на упрощения этой задачи и учитывает:
- Мультиязычность — порядка 30 языков. Для каждого языка свой стемминг, синонимы и другие особенности.
- Предыдущие данные этого клиента, или, в случае их отсутствия, данные клиента из такой же индустрии или похожего по прибыли клиента.
На самом деле это порядка 12 весьма сложных правил.
Изначальные допущения:
- Не больше 100 пользователей одновременно;
- 2-3 колонки для распознавания;
- 100 строчек.
Никакого highload вообще — все скучно.
Итак, наступает время релиза. Произошел Code freeze, Java все боятся трогать, а на обработку документа уходит минимум 5 минут.
В команду разработки баз данных приходят с просьбой о помощи. Конечно, ведь, если что-то тормозит в JVM, то само собой, надо менять или чинить базу данных.

Мы изучили документы и поняли, что в key-value парах довольно часто повторяются значения — по 5-10 раз. Соответственно, решили использовать базу данных, чтобы кешировать, потому что она уже протестирована.
Мы решили использовать Oracle server-side Result Cache, потому что:
- возможности по оптимизации SQL исчерпаны, потому что там используется Oracle full text search engine;
- будет использоваться кэш для повторяющихся параметров;
- большинство данных для рекомендаций пересчитываются раз в час, так как используют полнотекстовый индекс;
- PL/SQL запрещен.
Oracle Result Cache
Result cache — технология от Oracle по кэшированию результатов — обладает следующими свойствами:
- это область памяти, в которой шарятся все результаты запросов;
- read consistent, и происходит автоматическая его инвалидация;
- требуется минимальное количество изменений в приложении. Можно сделать так, что приложение вообще не потребуется менять;
- бонус — можно кэшировать логику PL/SQL, но она у нас запрещена.
Как его включить?
Способ № 1
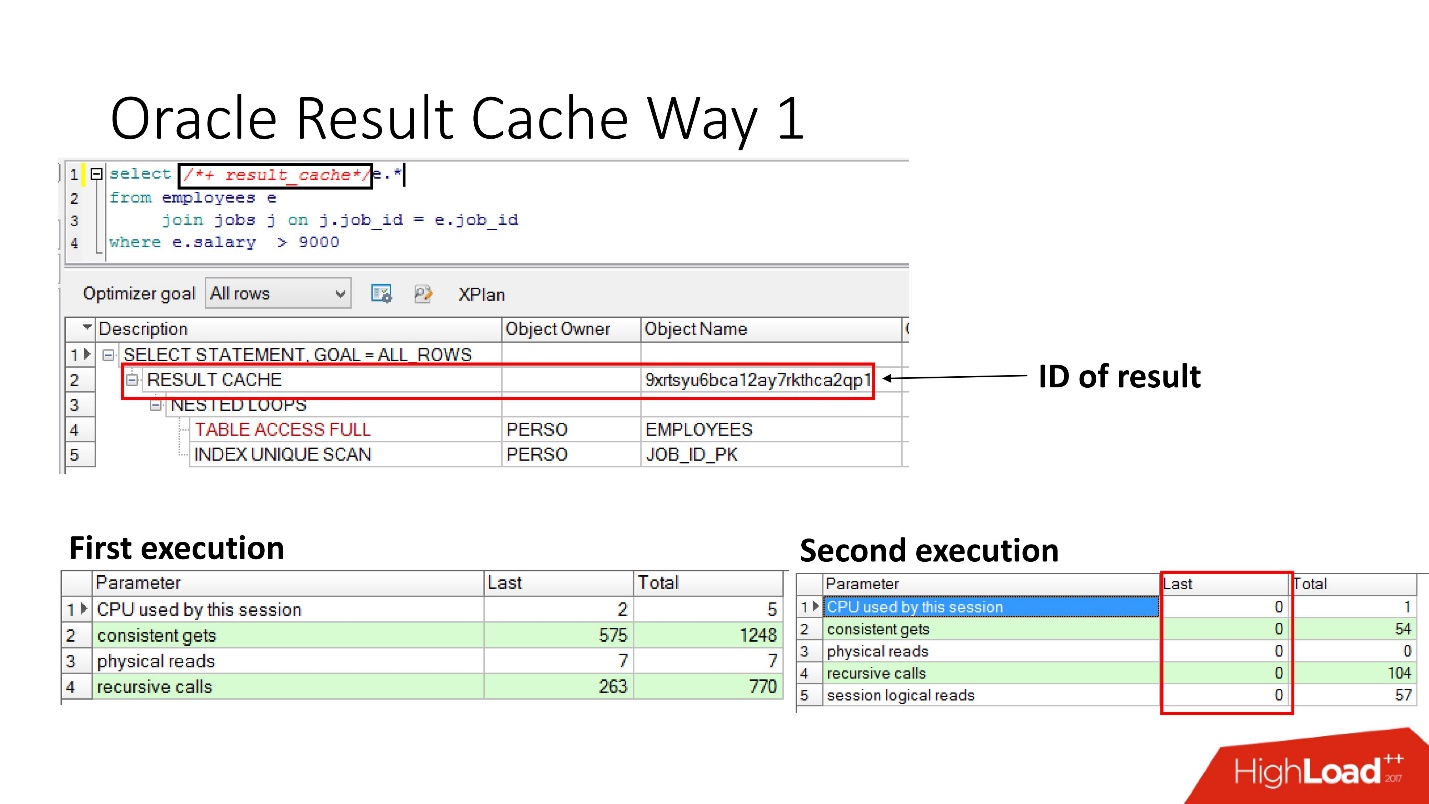
Очень просто — указать инструкцию result_cache. На слайде видно, что появился идентификатор результата. Соответственно, при первом выполнении запроса, база данных произведет какую-то работу, при последующем исполнении в данном случае никакая работа не нужна. Все хорошо.
Способ № 2
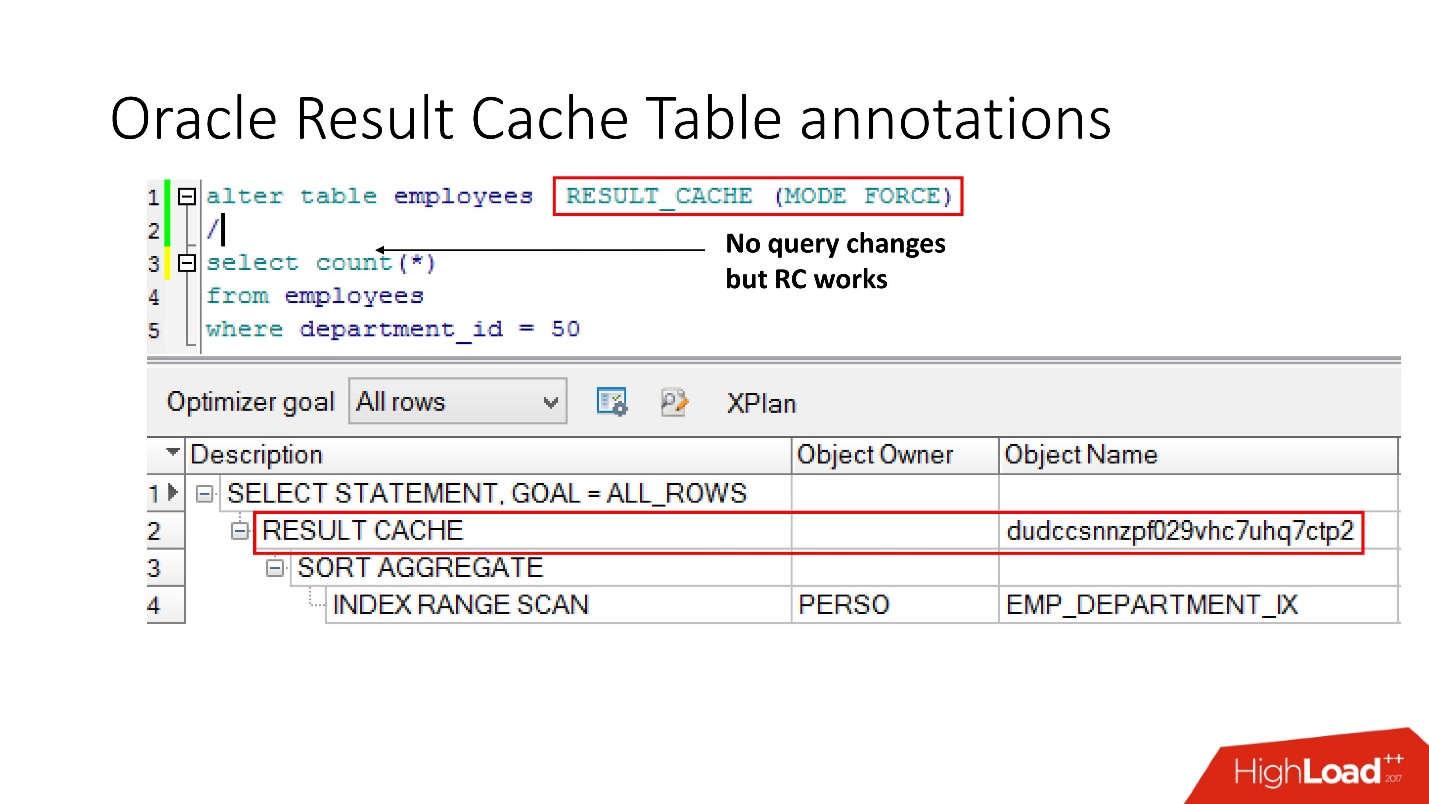
Второй способ позволяет разработчикам приложений ничего не делать — это так называемые аннотации. Мы для таблицы указываем галочку, что запрос к ней должен помещаться в result_cache. Соответственно, никакого hint нет, приложение не трогаем, а все уже в result_cache.
Кстати, как вы думаете, если запрос обращается к двум таблицам, одна из которых помечена как result_cache, а вторая — нет, закэшируется ли результат такого запроса?
Ответ — нет, вообще никак.
Чтобы он закэшировался, все таблицы, участвующие в запросе, должны иметь аннотацию result_cache.
Dependency Tracking
Есть соответствующие представления, в которых можно посмотреть, какие есть зависимости.
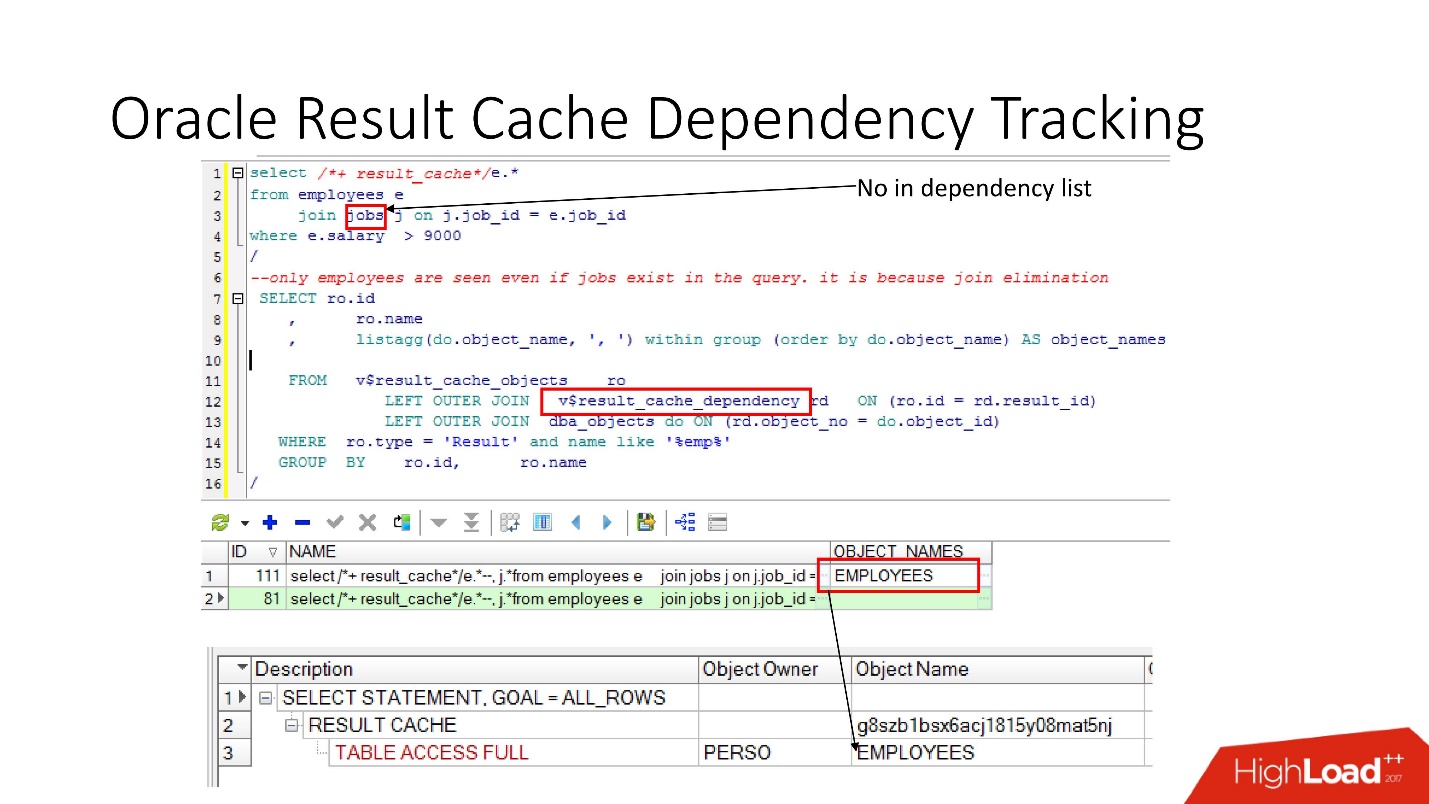
На примере выше запрос JOIN какая-то таблица, в которой одна зависимость. Почему? Потому, что Oracle определяет dependency не просто синтаксическим анализом, а осуществляет его по результатам плана выполнения работы.
В данном случае выбран такой план, потому что используется только одна таблица, и на самом деле таблица jobs связана с таблицой employees через foreign key constraint. Если мы уберем foreign key constraint, который позволяет сделать это преобразование join elimination, то мы увидим две зависимости, потому что так поменяется план.
Oracle не отслеживает то, что не надо отслеживать.
В PL/SQL dependency работает в run-time, чтобы можно было использовать динамический SQL и прочие вещи делать.
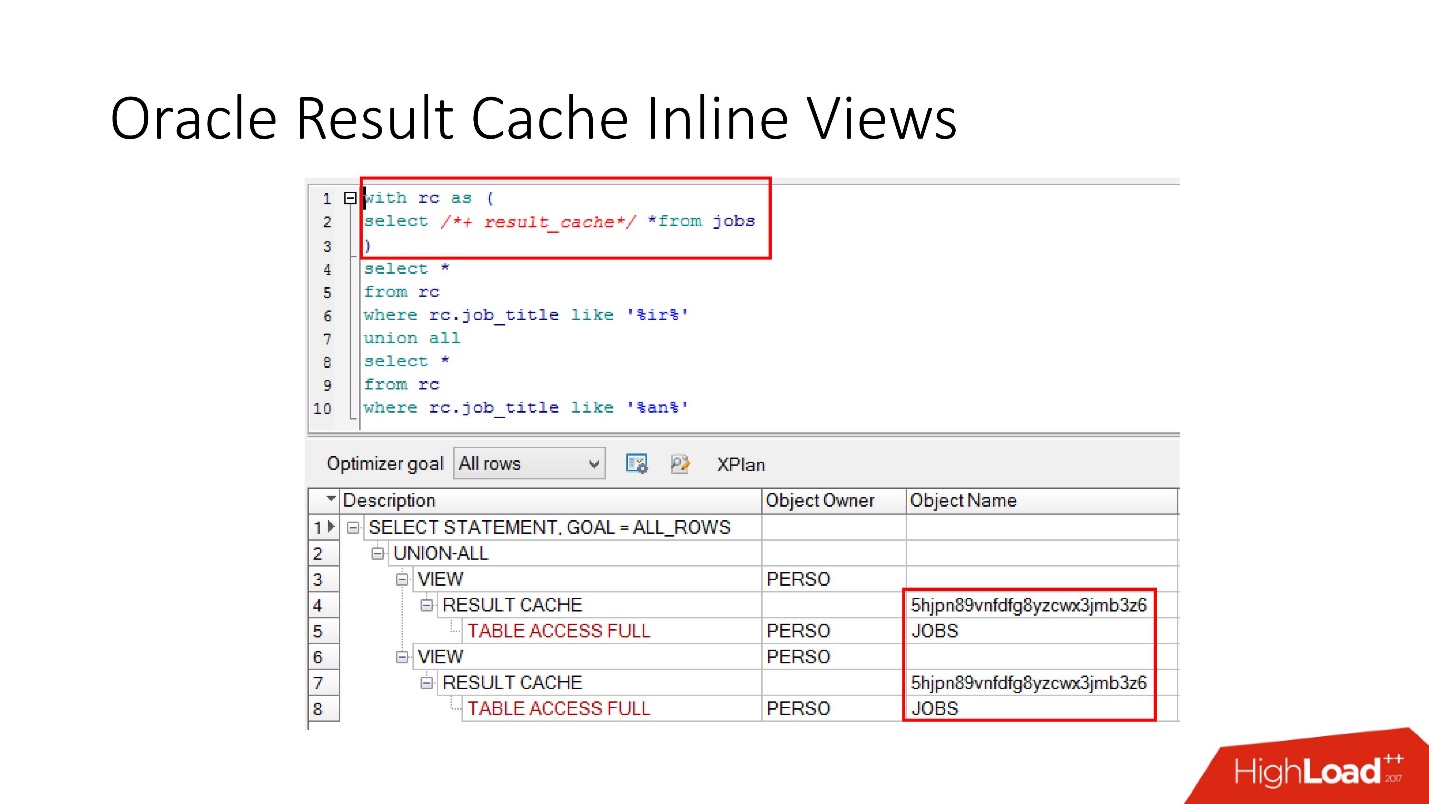
Обратите внимание, что кэшировать можно не только весь запрос целиком, можно кэшировать inline view как в виде with, так и в виде from. Предположим, для чего-то одного нам нужен кэш, а другое лучше бы читать из базы данных, чтобы ее не напрягать. Мы берем inline view, опять объявляем как result_cache и видим — идет кэширование только по одной части, а за второй мы каждый раз обращаемся к базе данных.
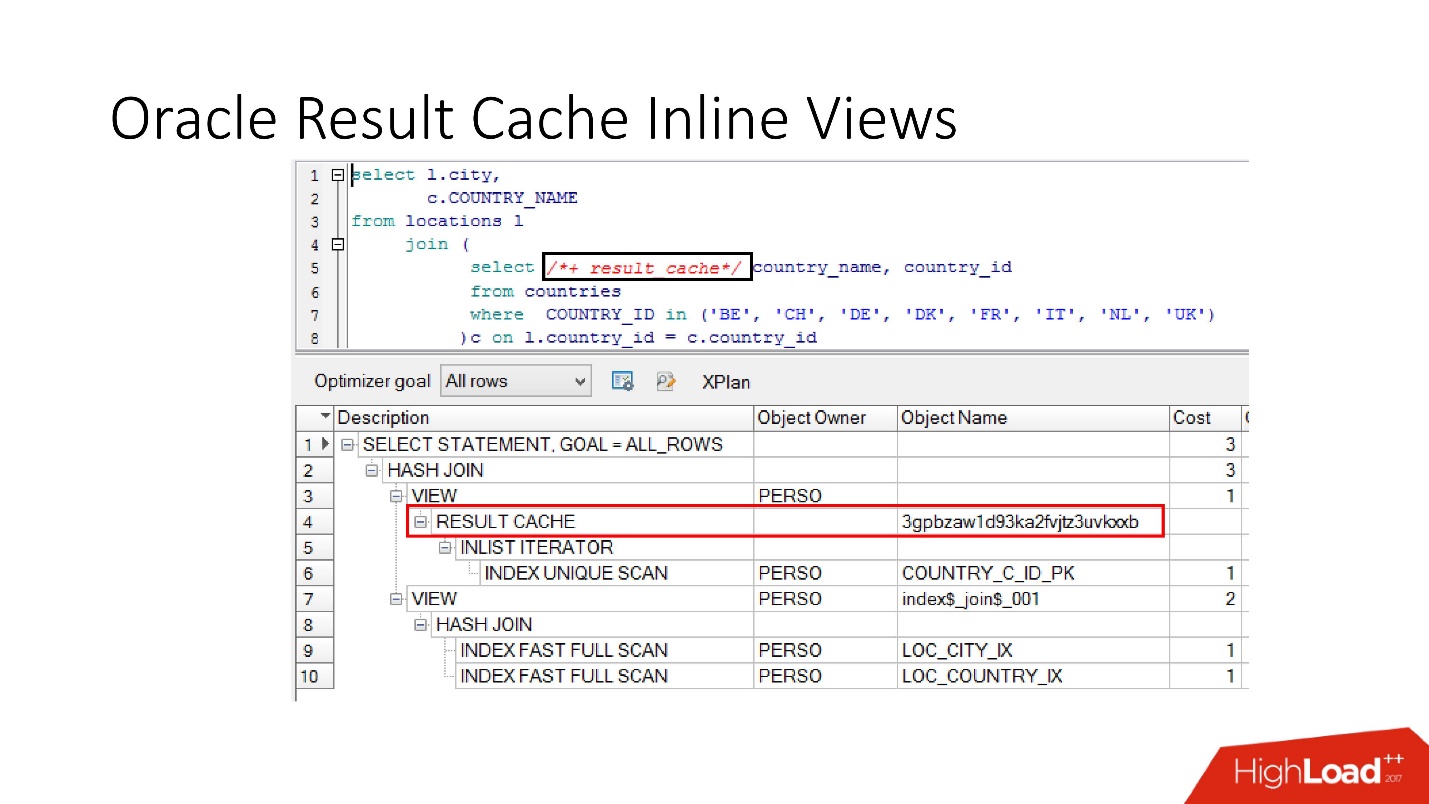
И, наконец, в базах данных тоже есть инкапсуляция, хотя в это никто не верит. Мы берем view, ставим в нем result_cache, и наши программисты даже не догадываются, что оно закэшировано. Ниже мы видим, что на самом деле только одна его часть работает.
Инвалидация
Итак, посмотрим когда же Oracle инвалидирует result_cache.Статус Published показывает текущее состояние валидности кэша. Когда запрос к result_cache, как я уже говорил, в базе данных нет никаких работ
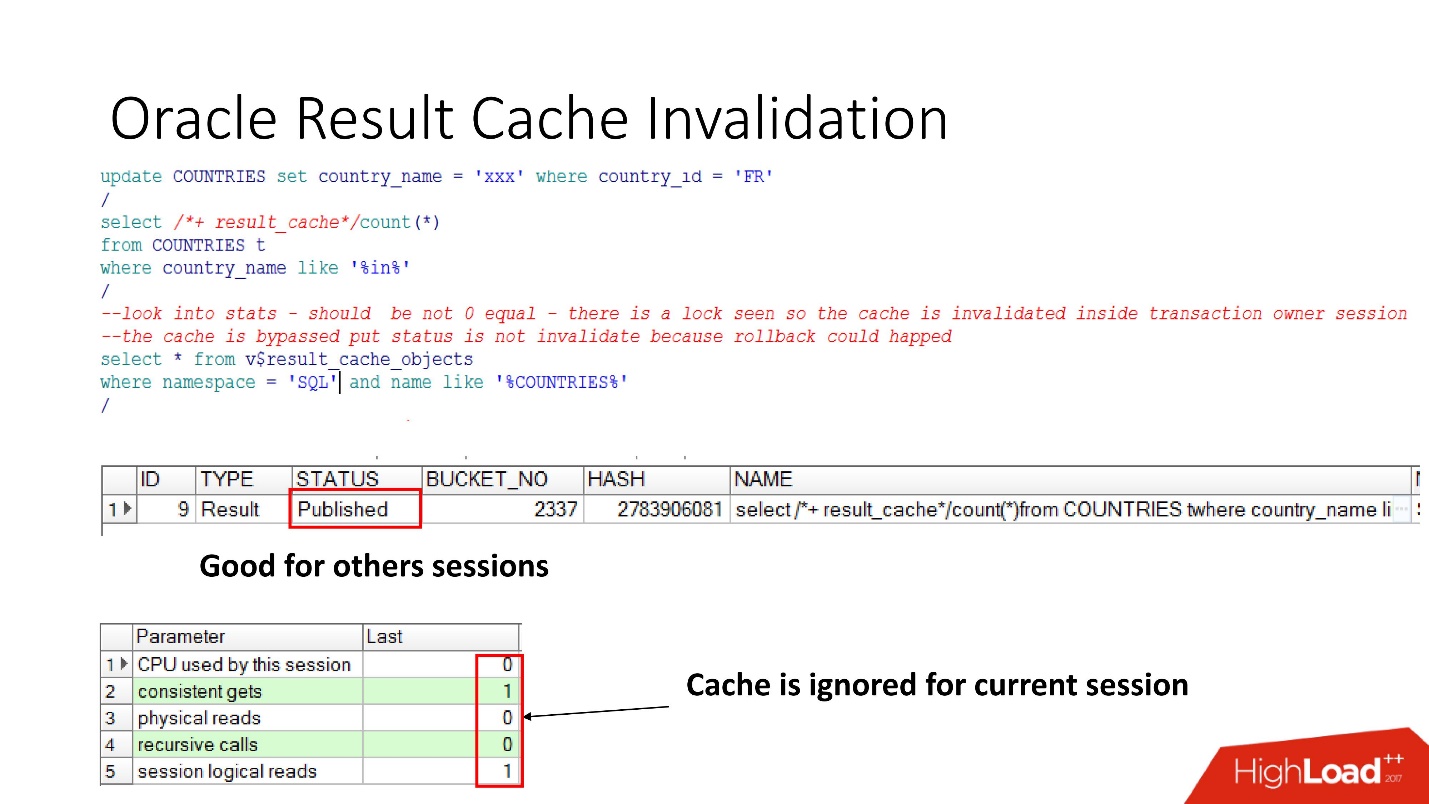
Когда мы сделали апдейт, статус все равно Published, потому что апдейт не закоммитился и другие сессии должны видеть старый result_cache. Это та самая пресловутая консистентность по чтению.
Но в текущей сессии мы увидим, что нагрузка пошла, так как именно в этой сессии кэш игнорируется. Это вполне разумно, сделаем commit — результат станет Invalid, все работает само.

Казалось бы — мечта! Dependency считаются правильно — просто в зависимости от запроса. Но нет, вскрылся ряд нюансов. Oracle производит инвалидации и в ряде неочевидных случаев:
- При любом вызове SELECT FOR UPDATE зависимости слетают.
- Если в таблице есть неиндексированные внешние ключи, и произошел апдейт по таблице, помеченной result_cache, который вообще ничего не затронул, но при этом что-то поменялось в родительской таблице, кэш тоже станет невалидным.
- Это самое интересное, что максимально портит жизнь — если есть какой-то неудачный апдейт по таблице, помеченной как result_cache, ничего не отработало, но потом в этой же транзакции применили любые другие изменения, которые как-то повлияли на первую таблицу, то все равно result_cache сбросится.
Еще есть такой антипаттерн про result_cache, когда разработчики, услышав, что есть такая классная вещь, думают: «О, есть хранилище! Сейчас возьмем какой-нибудь запрос, который на 2-3 партициях работает — на текущей дате и на предыдущей, пометим его как result_cache, и он будет всегда браться из памяти!»
Но когда меняют патрицию задним числом, весь кэш слетает, потому что на самом деле единица отслеживания dependency в result_cache — это всегда таблица, и не знаю, будут ли когда-нибудь партиции или не будут.
Мы подумали и решили, что пойдем в продакшен рекомендательной системы с такими вещами:
- Мы не будем кэшировать все наши таблицы, возьмем только нужные.
- Поставим result_cache для long-running query.
Все проверили, провели performance-тесты, время обработки — 30 с. Все замечательно, идем в продакшен!
Накатили — ушли спать. Приходим с утра. Видим письмо: «Распознавание занимает минимум 20 минут, сессии зависают». Почему они зависают? Каким образом 30 секунд превратились в 20 минут?
Стали разбираться, смотреть в базу данных:
- активных сессий — 400;
- в среднем строчек в документе для распознавания — 500;
- колонок минимум — 5-8;
- количество сессий в базе данных всегда равно количеству application пользователя, умноженное на 3! А result_cache не любит частого к нему обращение.
Проведя внутреннее расследование, мы выяснили, что Java-разработчики делают распознавание в 3 потока.
Мы расстроились — 5-кратная нагрузка, падение, деградация, причем даже при таких параметрах такого проседания не должно было быть.
Очевидно, надо разбираться.
Мониторинг

Для мониторинга у нас есть две ключевых вещи:
- V$RESULT_CACHE_OBJECTS — список всех объектов;
- V$RESULT_CACHE_STATISTICS — агрегатная статистика result_cache в целом.
MEMORY_REPORT — это вариации на тему, они нам не понадобятся.
Oracle — волшебный! Есть великолепная документация, но она рассчитана на тех, кто переходит с других баз данных, чтобы они читали и думали, что Oracle — это очень круто! А вот вся информация по result_cache лежит только на support.

Есть нюанс, который состоит в том что, как только мы обращаемся к этим объектам, чтобы разрешить проблему, мы ее усугубляем, окончательно закапывая себя! До Oracle12.2, до патча которой вышел в октябре прошлого года, эти запросы делают result_cache недоступным на статус и на запись до тех пор, пока они полностью не посчитаются.
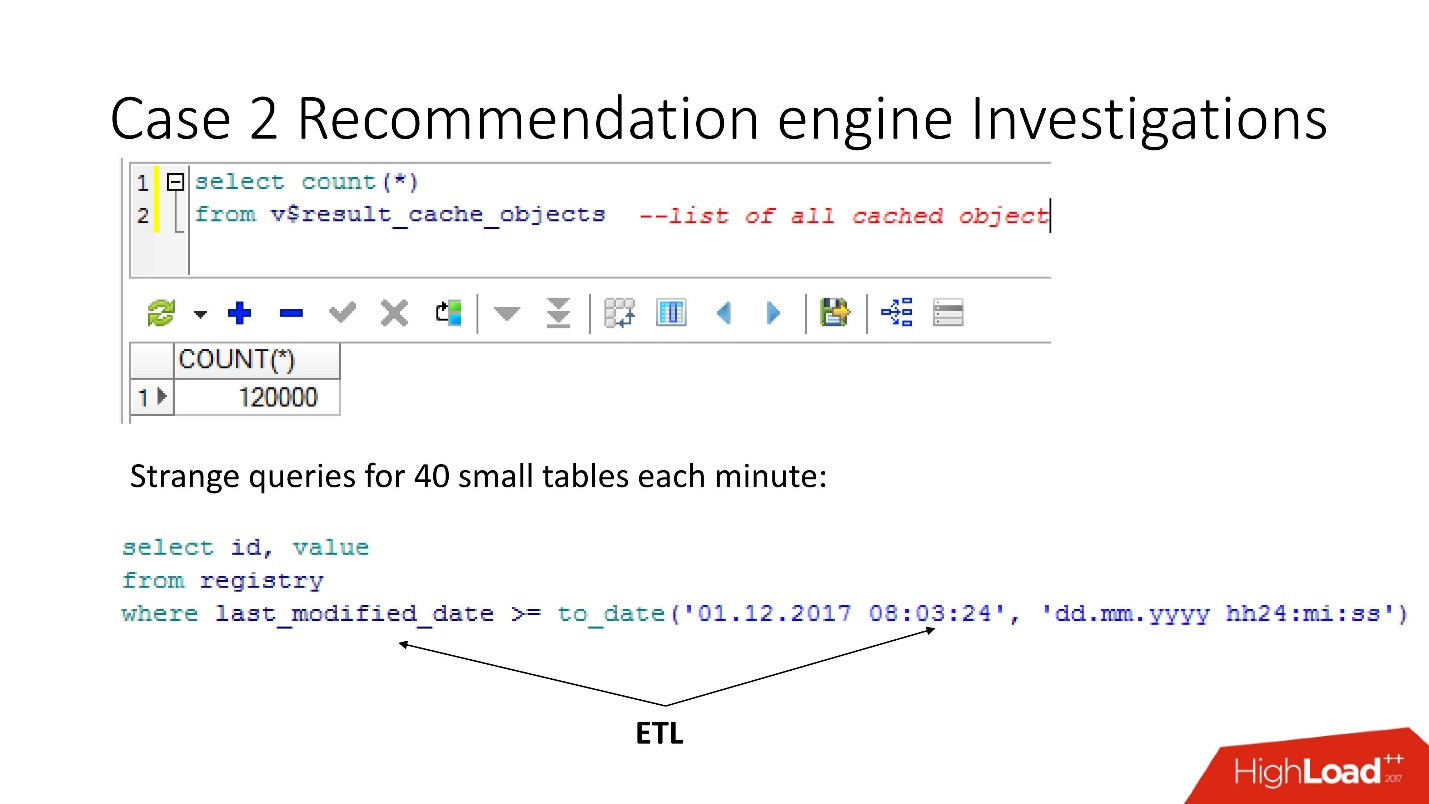
Итак, воспользовавшись представлением v$result_cache_objects, мы выяснили, что в списке закэшированных объектов тысячи записей — намного больше, чем мы ожидали. Причем, это были объекты из каких-то не наших запросов по странным таблицам — маленькие таблички, и запросы last_modified_date. Очевидно, кто-то натравил на нашу базу ETL.
Перед тем как идти ругаться на разработчиков ETL, мы проверили, что для этих таблиц включена опция result_cache force, и вспомнили, что мы сами её включили, так как некоторые из этих данных часто требовались приложению и кэширование было уместно.
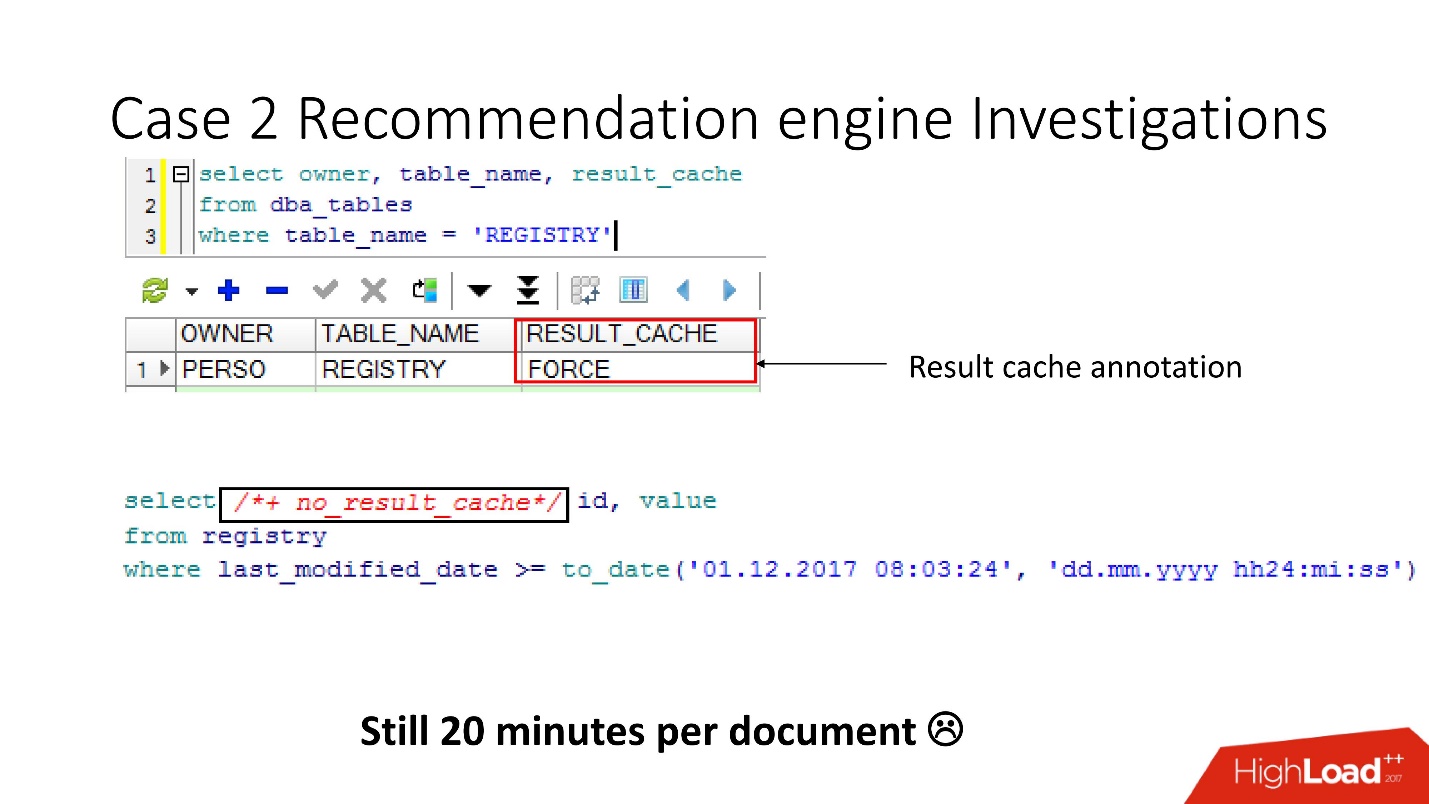
А получилось, что все эти запросы просто берут и вымывают наш кэш. К счастью, у разработчиков была возможность повлиять на ETL в продакшене, поэтому мы смогли изменить result_cache, чтобы исключить эти ежеминутные запросы.
Как вы думаете, полегчало? — Не полегчало! Количество кэшируемых объектов уменьшилось, а потом снова выросло до 12000. Мы продолжили изучать, что же ещё кэшируется, так как скорость не менялась.

Смотрим — куча запросов, и такие умные, но все непонятные. Хотя тот, кто работал с Oracle 12, знает, что DS SVC — это адаптивная статистика. Она нужна для улучшения производительности, но когда есть result_cache, она оказывается, его убивает, потому что происходит конкуренция. Это само собой, написано только на support.
Мы знали, как устроен workload и понимали, что в нашем случае адаптивная статистика не особо радикально улучшит наши планы. Поэтому мы героически ее отключили — результат, как и написано в секретном мануале — 10 минут на документ. Неплохо, но еще недостаточно.
Защелки
Конкуренция между result_cache и DS SVC возникает из-за того, что в Oracle есть защелки (latches) — легковесные маленькие блокировочки.

Не вдаваясь в детали, как они работают, пытаемся поставить именованную защелку несколько раз — не получилось — Oracle берет и засыпает
Тот, кто в теме, может сказать, что в result_cache ставится по две защелки на каждый блок при fetch. Это детали. В result_cache есть два вида защелок:
1. Защелка на тот период, пока мы записываем в result_cache данные.

То есть если у вас запрос работает 8 с, на период этих 8 с другие такие же запросы (ключевое слово «такие же») не смогут ничего сделать, потому что они ждут, пока данные запишутся в result_cache. Другие запросы запишутся, но подождут блокировку только на первую строчку. Сколько им придется ждать, неизвестно, это недокументированный параметр result_cache_timeout. После этого они начинают как бы игнорировать result_cache, и работают медленно. Правда, как только блокировка с последней строчки при помещении снялась, они автоматом начинают снова работать с result_cache.
2. Второй тип блокировок — на получение из result_cache тоже с 1-й строчки по последнюю.
Но так как fetch происходит из мгновенной памяти, то они снимаются очень быстро.

Обязательно надо иметь в виду, что, когда DBA видит в базе данных защелки, он начинает говорить: «Защелки! Wait time — все пропало! » И тут начинается самая интересная игра: убеди DBA, что wait time от защелок на самом деле несравненно меньше, чем время повторения запроса.

Как показывает наш опыт, наши измерения, защелки на result_cache занимают 10% от самих запросов.
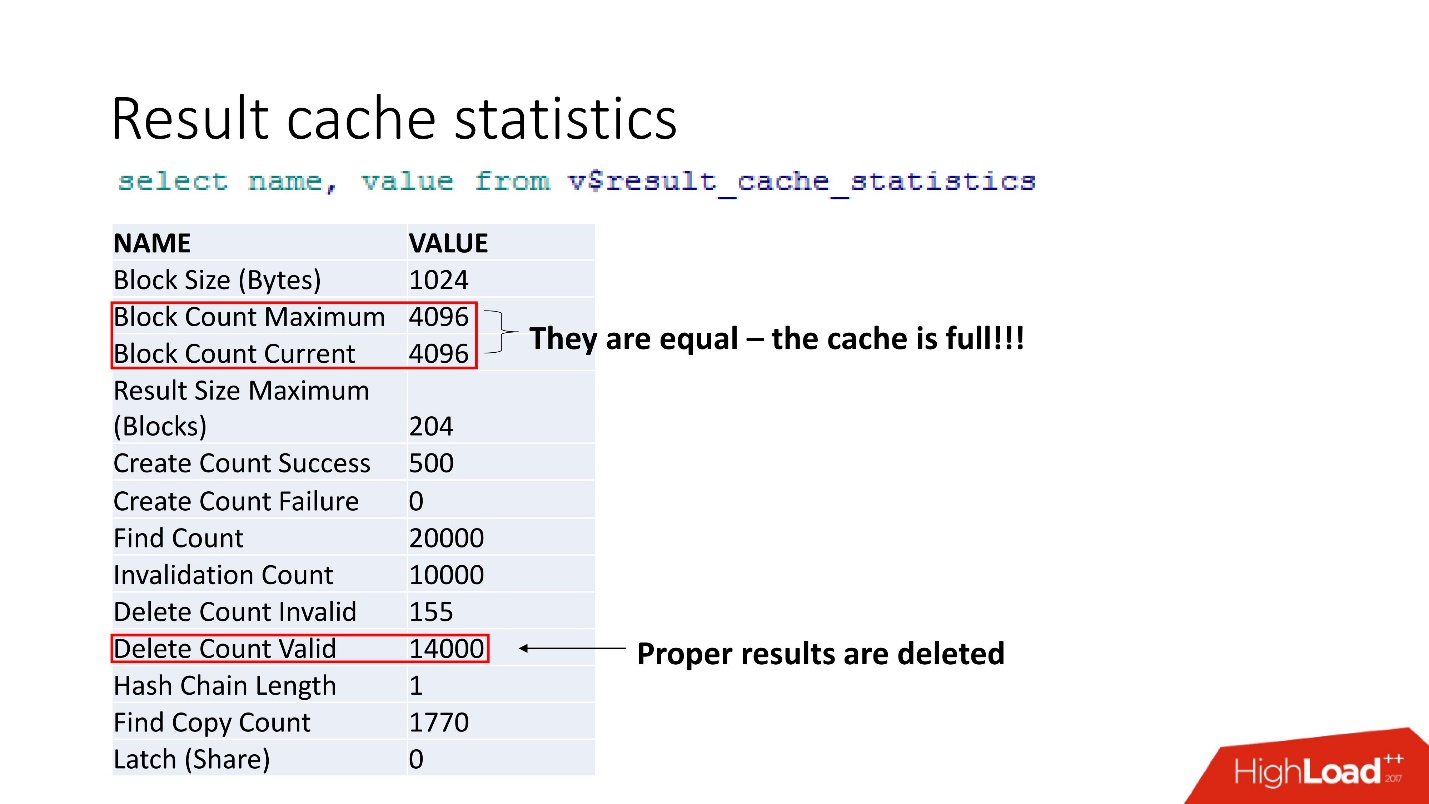
Это агрегированная статистика. То, что все плохо, можно понять по тому, что забит кэш. Еще одно подтверждение — Proper results are deleted. То есть кэш перезатирается. Вроде бы, мы умные и всегда считаем размеры памяти — взяли размер строчек нашего кэшируемого результата для нашей рекомендации, умножили на количество строк, и что-то пошло не так.

На support мы нашли 2 бага, которые говорят, что при переполнении result_cache происходит деградация производительности. И это тоже исправили в том самом секретном патче.
Секрет в том, что память выделяется блоками. В нашем случае, конечно, еще добавилось то, что workload вырос в 5 раз. Поэтому при расчете память не надо умножать на ширину ваших данных, а умножайте на размер блока, и тогда будет счастье.
Что еще можно настроить?
Параметров море: есть документированные и недокументированные параметры. На самом деле, нам не нужны все эти параметры.
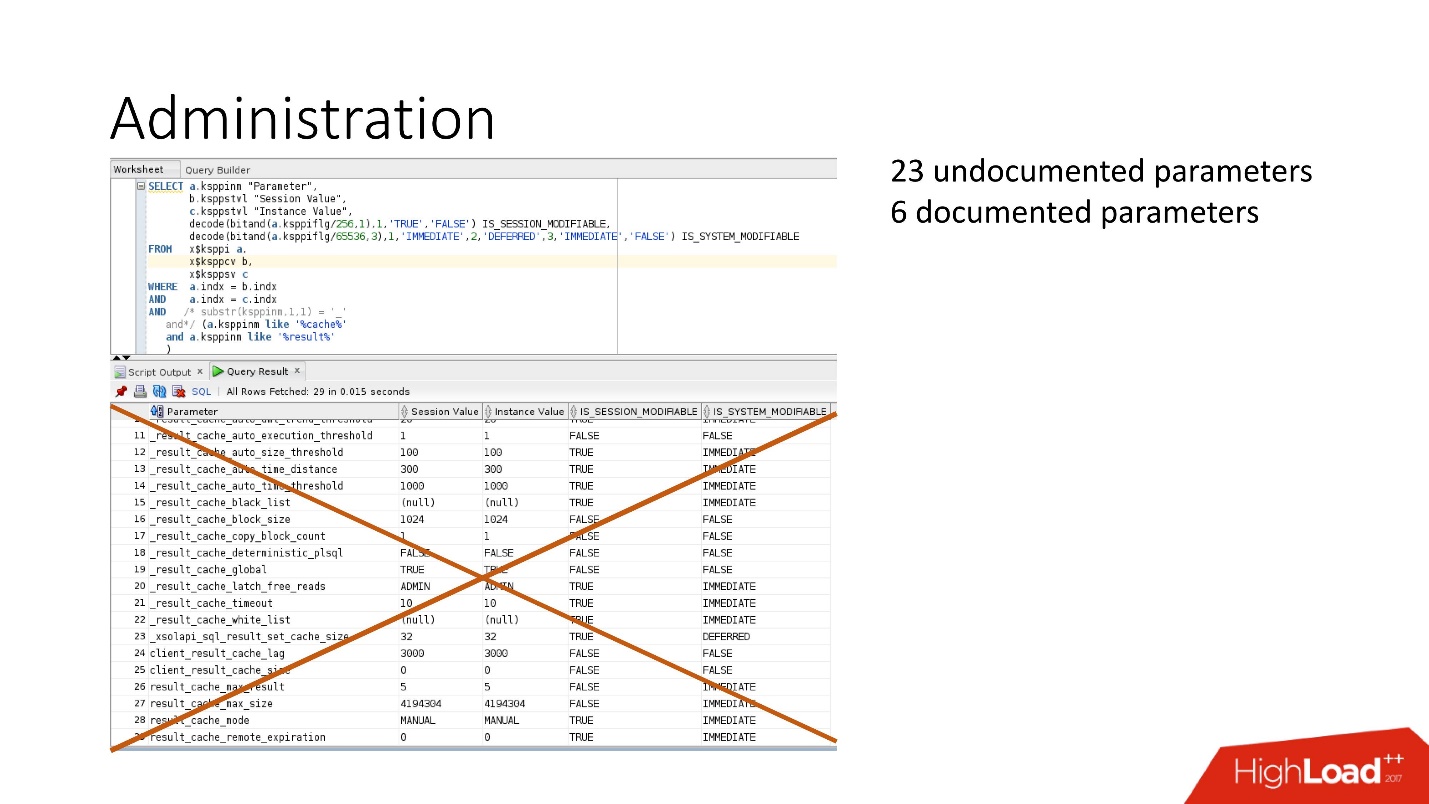
По факту достаточно 4 параметров:
- RESULT_CACHE_MAX_SIZE;
- RESULT_CACHE_MAX_RESULT;
- RESULT_CACHE_MODE;
- _RESULT_CACHE_MAX_TIMEOUT.
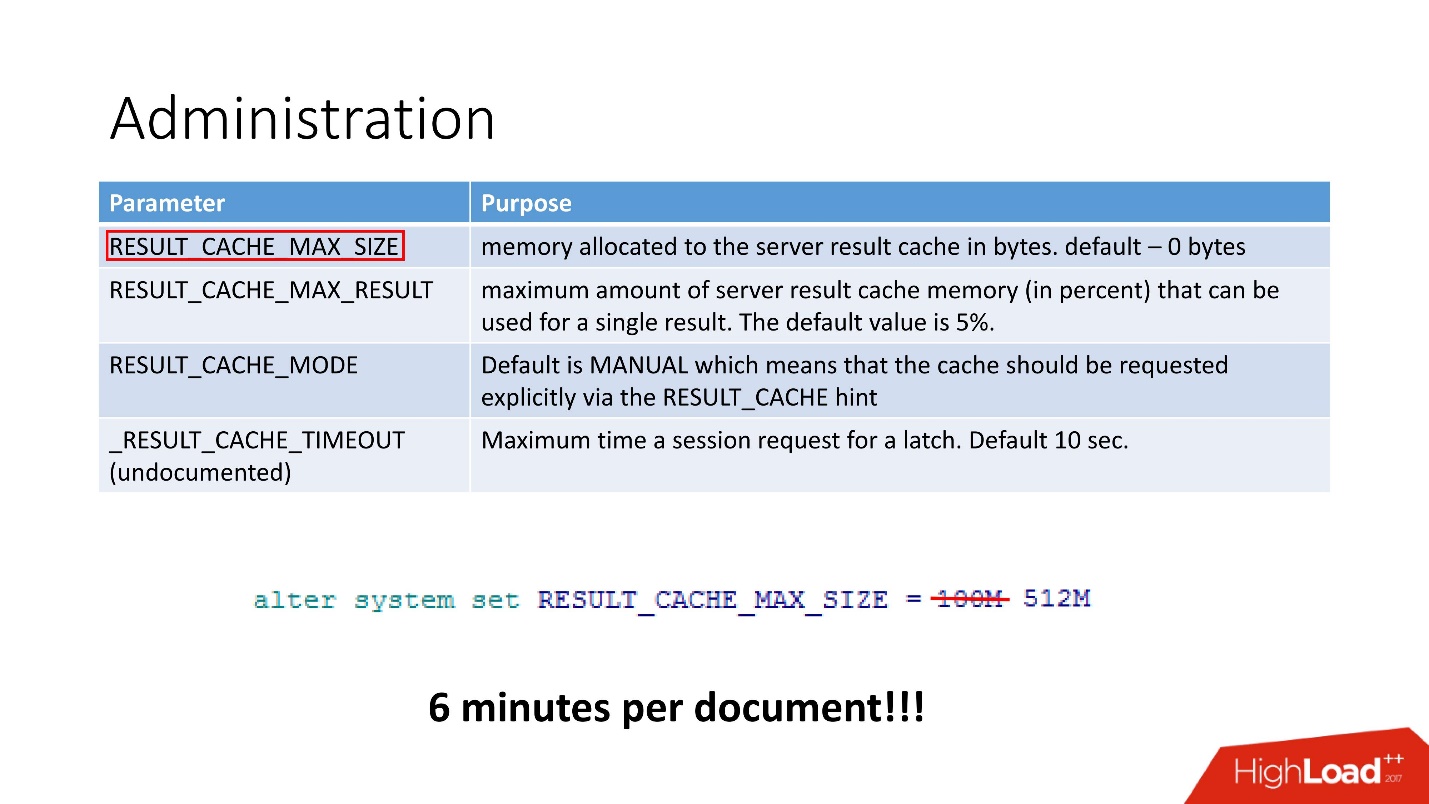
Нам хватило даже одного — размер кэша. После того, как мы заменили 100 Мб на 512Мб, время обработки документа сократилось до 6 минут.
Все равно копаем дальше, вдруг есть еще что-нибудь странное. Например, Invalidation Count = 10000.
Не ошибается тот, кто ничего не делает. Путём неких изысканий мы обнаружили, что отключен job обновления рекомендаций, что приводило к постоянному обновлению данных. Соответственно, кэш постоянно инвалидировался. Мы запустили job с часовым интервалом, как и было задумано, что автоматически отключило постоянное обновление таблицы.
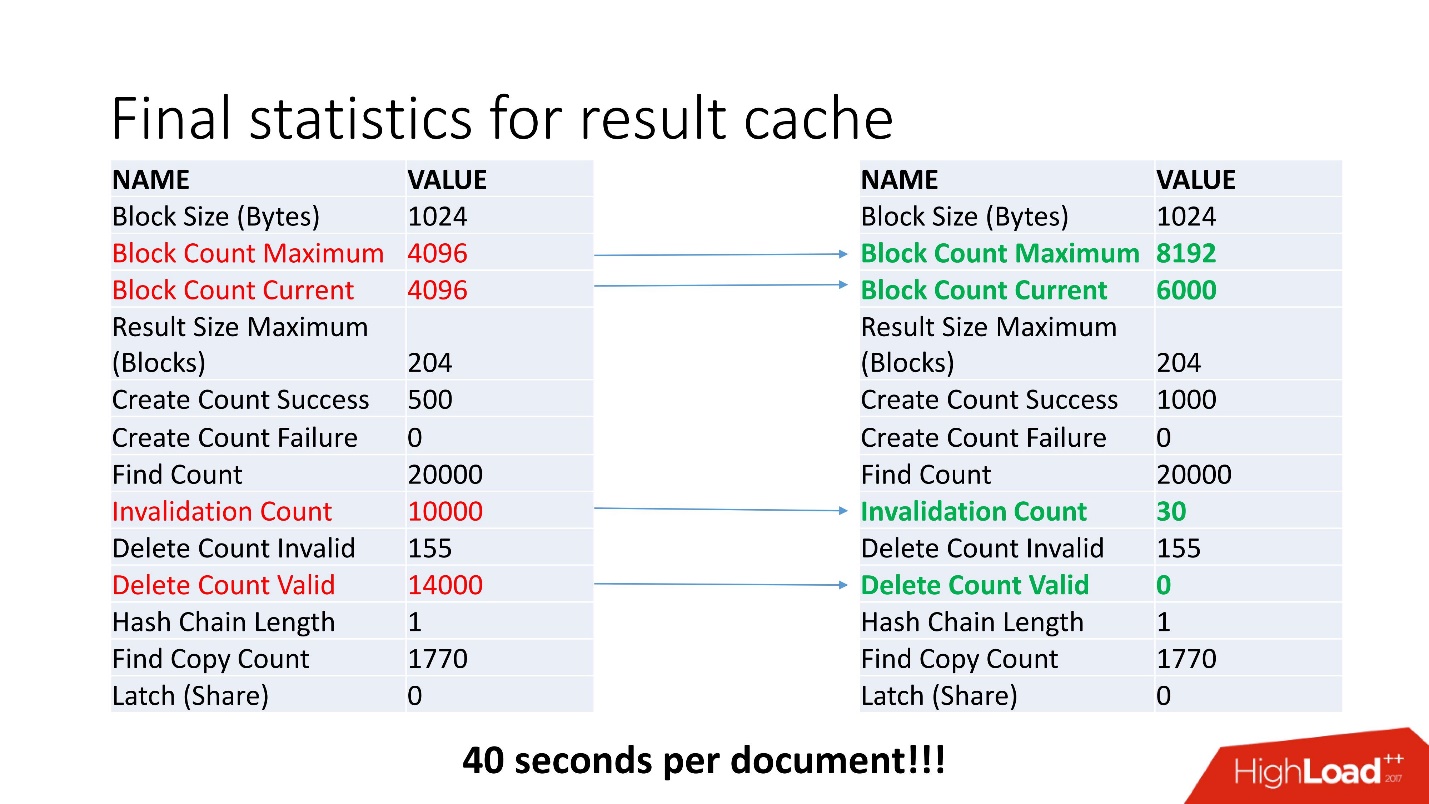
Всегда есть свободное место, invalid только в момент пересчета кэша, и удаления данных нет. При пятикратном увеличении нагрузки мы получили скорость обработки документа 40 с.
Самое важное, чтобы кэш не переполнялся. Пока мы все это изучали, мы обнаружили кучу недокументированных фишек, которые есть в ядре Oracle. Они великолепны!

SHELFLIVE — параметр, который позволяет обеспечить read-consistent умирание кэша, то есть кэшируемый запрос умрет через 10 с, и кэш почистится. Этот параметр был встроен в новую версию приложения. Важно, что кэш так же удаляется, если было изменение данных.
Есть еще более интересная опция — SNAPSHOT. Она удобна, если факт изменения не критичен для кэша, нет необходимости в сохранении read-consistent и нет защелок — тогда изменения данных не будут инвалидировать кэш.
Ограничения понятны:

- Словари — нет возможности кэширования объектов в схеме SYS.
- Нельзя кэшировать временные и внешние таблицы. Важно, что по факту можно, и Oracle явно это не ограничивает, но это приводит к тому, что можно увидеть содержимое временных таблиц других пользователей. Более того, Oracle декларирует, что это исправлено, но в 12.2 до сих данная проблема есть. Кстати, про external таблицы почему-то тоже написано в support, в официальной документации нет.
- Нельзя использовать недетерминированные sql и pl/sql функции: current_date, current_time и пр. Есть секретный ход, как обойти ограничения с current_time, потому что всегда же хочется кэшировать данные за текущую дату.
- Нельзя использовать конвейерные функции.
- Входные и выходные параметры кэша должны быть простых типов данных, то есть никаких CLOB, BLOB и пр.
Result cache inside Oracle
Result_cache — это фишка Oracle Core. Она используется на самом деле в куче всего, все, что связано с job использует result_cache (кстати, выделен тот секретный hint, где мы это обнаружили) и везде, что связано с APEX.

Все, что связано с Dynamic sampling и с адаптивной статистикой, то есть все, что делает ваше предсказание более правильным, работает на result_cache.

Oracle internals for result cache
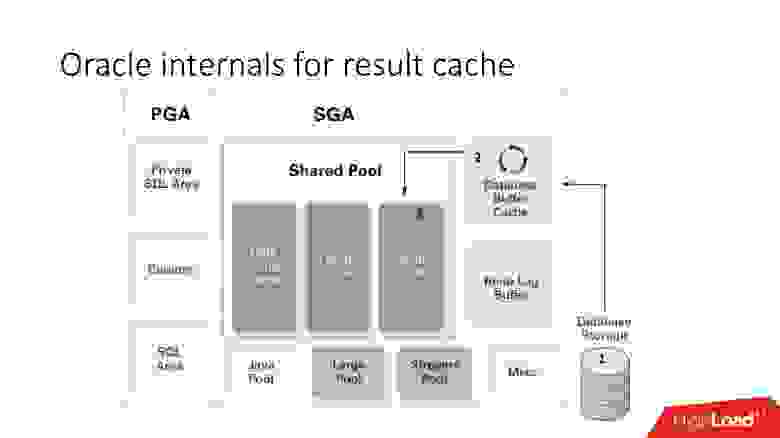
Вернемся к схеме памяти и кратко подытожим работу result_cache:
- данные при запросе попадают с уровня хранения (storage) в буферный кэш;
- данные из буферного кэша попадают в область памяти result_cache;
- result_cache находится в shared pool.
Плюсы:
- Минимальное влияние на код приложения.
- Не надо заморачиваться на хранимую логику в базе данных и read-consistent.
- Result_cache, как мы убедились, довольно быстр.
Минусы:
- Дорогая память базы данных.
- Может привести к деградации производительности, если неправильно настроить кэш.
Мы не одиноки!
Из всего сказанного может возникнуть ощущение, что мы такие криворукие. Но посмотрите в support Oracle, например, за 29 сентября 2017 г.: новая версия Oracle E-Business suite падает по причине result_cache, потому что они решили ее ускорить.

Однако, нам интересен не сам факт наличия проблем, а способы их не допустить. В дебрях интернета я нашел очень познавательное письмо службе support одной из ведущих российских облачных систем расчета лояльности, в которой произошел сбой, и система была недоступна суммарно час.

Драматическое увеличение времени выдачи из кэша во время наката патчей произошло в следствие:
- блокировки из-за неправильно рассчитанного размера кэша;
- и, возможно, блокировок, например, в v$result_cache_memory или dbms_result_cache.memory_report, так как баг по ним не закрыт.
Однако, тесты багов написаны так хитро, что в них фактически явно говорится, что в v_result_cache_objects есть ошибка.
Не читайте документацию, читайте support note — везде на support написано, что будет плохо.

Чтобы справиться с проблемой, эта компания сделала примерно то же самое, что и мы: увеличили размер кэша и кое-что отключили. Для меня лично интересно, как они это сделали, потому что отключить можно тремя способами:
- убрать hint result_cache;
- выставить hint no result_cache;
- использовать black_list, то есть, не меняя приложение, запретить кэшировать что-либо.
Какой отсюда можно сделать вывод?
- Всегда перед тем, как что-то накатить, посчитайте, как это отразится на использовании памяти;
- Отключите кэш на период загрузки, то есть быстренько отключили, налили и включили. Лучше, чтобы система чуть-чуть потормозила, но заработала, чем потом легла.
Как мы заметили, основная проблема кэшей на сервере — это расход дорогой серверной памяти. У Oracle есть третье, заключительное решение.
Client side result cache

Схема его устройства изображена на выше, это главные компоненты БД и драйвер.
При первом обращении client-side Result Cache идет в базу данных, которая предварительным образом настроена, получает размер клиентского кэша из базы данных и инстанциирует у себя на клиенте этот кэш разово при первом подключении. Кэшируемый запрос первый раз обращается к базе данных, и записывает данные в кэш. Остальные потоки запрашивают общий кэш драйвера, тем самым экономя память и ресурсы сервера. Кстати, иногда в зависимости от нагрузки драйвер присылает в БД статистику по использованию кэша, которую потом можно будет посмотреть.
Интересен вопрос, как происходит инвалидация?
Есть два режима инвалидации, которые заточены на параметр Invalidation lag. Это то, сколько Oracle позволяет кэшу на драйвере быть не консистентным.
Первый режим используется, когда запросы идут часто и не наступает Invalidation lag. В таком случае поток пойдёт в базу данных, обновит кэши и считает данные из него.
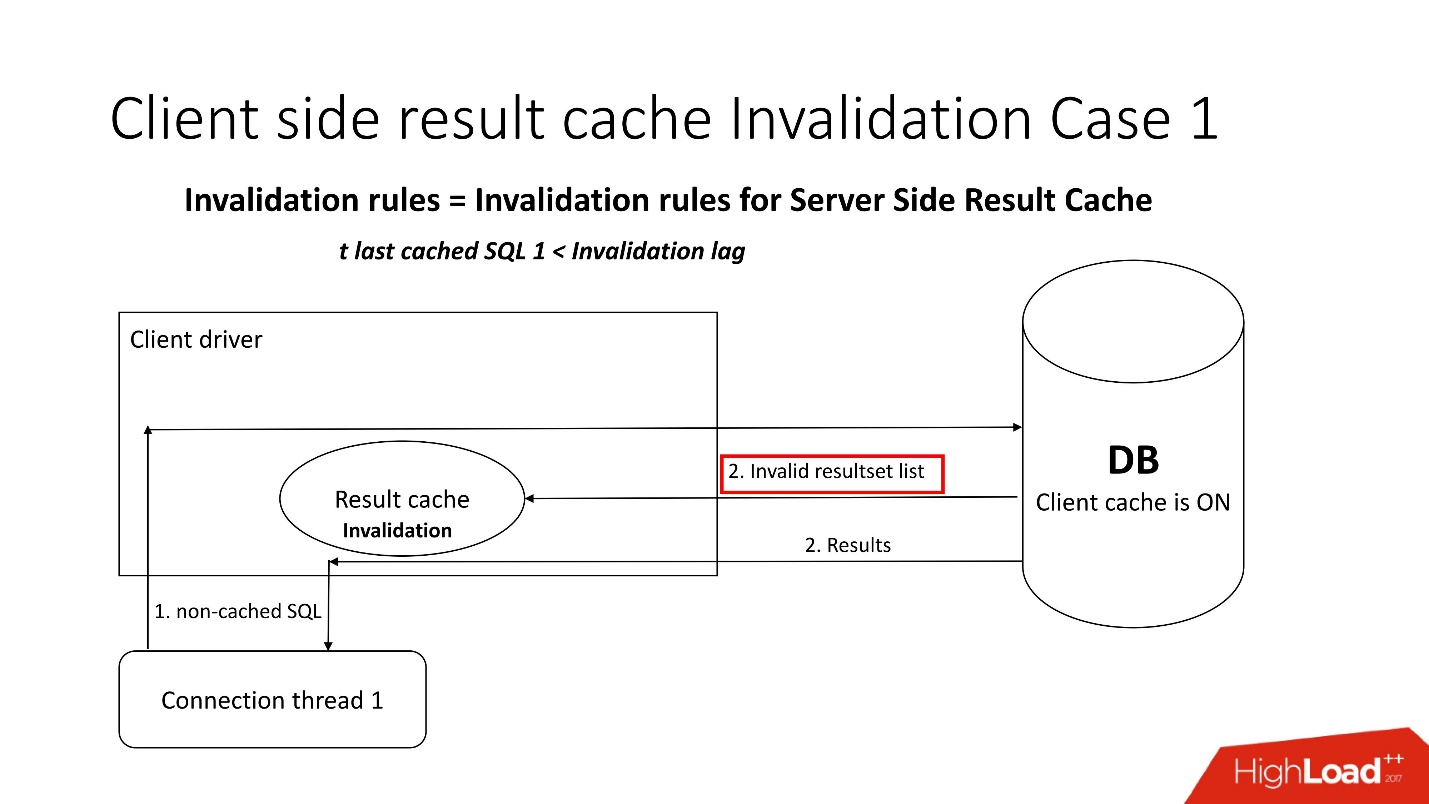
Если Invalidation lag не прошел, то любой некэшируемый запрос, обращаясь к базе данных, кроме результатов запроса приносит список инвалидных объектов. Соответственно они помечаются в кэше как инвалидные, и все работает как на картинке из первого сценария.
Во втором случае, если прошло больше времени, чем Invalidation lag, то сам клиентский result_cache идет в базу данных и говорит: «А дай-ка мне список изменений!» То есть он сам в себе поддерживает свое адекватное состояние.
Сконфигурировать client-side Result Cache очень просто. Есть 2 параметра:
- CLIENT_RESULT_CACHE_LAG —величина отставания кэша;
- CLIENT_RESULT_CACHE_SIZE — размер (минимальный 32 Кб, максимальный — 2 Гб).

С точки зрения разработчика приложений клиентский кэш особо не отличается от серверного, также вписали hint result_cache. Если он был, то он просто начнет использоваться клиентский — что на .Net, что на Java.

Сделав 10 итераций запроса, я получил следующее.

Первое обращение — создание, далее 9 обращений к кэшу. В таблице отмечено, что память тоже выделяется блоками. Еще обратите внимание на SELECT — он не очень интуитивный. Я, если честно, до того, как начал с этим разбираться, даже не знал, что есть такое представление
GV$SESSION_CONNECT_INFO. Почему Oracle не вынес это прямо в данную таблицу (а это таблица, а не view) я понять не смог. Но именно поэтому я считаю, что эта функциональность не очень востребована, хотя, как мне кажется, очень полезна.Достоинства клиентского кэширования:
- дешевая клиентская память;
- доступны любые драйвера —JDBC, .NET и т.д.;
- минимальное влияние в код приложения.
- Сокращение нагрузки на CPU, ввод/вывод и вообще базу данных;
- не надо учить и использовать всякие умные кэширующие слои и API;
- нет защелок.
Недостатки:
- согласованность по чтению с задержкой — в принципе, сейчас это тренд;
- нужен Oracle OCI client;
- ограничение 2Гб на cклиент, но в целом 2 Гб — это очень много;
- Лично для меня ключевое ограничение — это мало информации о production.
На support, который мы всегда используем, когда работаем с result_cache, я нашел всего лишь 5 багов. Это говорит о том, что, скорее всего, это мало кому нужно.
Итак, сводим в кучу все, что сказано выше.
Hand-made cache
Плохие сценарии:
- Мгновенное изменение — если после изменения данных кэш должен мгновенно стать неактуальным. Для самодельных кэшей тяжело создать корректную инвалидацию в случае изменения объектов, на которых они построены.
- Если использование хранимой в БД логики запрещено политиками разработки.
Хорошие сценарии:
- Есть сильная команда разработчиков БД.
- Реализована PL/SQL логика.
- Есть ограничения, которые не позволяют использовать другие техники кэширования.
Server side Result cache
Плохие сценарии:
- Очень много различных результатов, которые просто вымоют весь кэш;
- Запросы занимают больше времени, чем _RESULT_CACHE_TIMEOUT или этот параметр настроен неверно.
- В кэш загружаются результаты из очень больших сессий параллельными потоками.
Хорошие сценарии:
- Разумное количество кэшируемых результатов.
- Относительно небольшие наборы данных (200–300 строк).
- Достаточно дорогой SQL, иначе все время уйдет на защелки.
- Более или менее статичные таблицы.
- Есть DBA, который в случае чего придет и всех спасет.
Client side Result cache
Плохие сценарии:
- Когда возникает та самая проблема мгновенной инвалидации.
- Требуются thin drivers.
Хорошие сценарии:
- Есть нормальная команда разработки среднего слоя.
- Уже используется много SQL без использования внешнего кэширующего слоя, который можно легко подключить.
- Есть ограничения на железки.
Выводы
Я считаю, что мой рассказ про боль Server side Result cache, поэтому выводы таковы:
- Всегда оценивайте размер памяти правильно с учётом с учётом количества запросов, а не количества результатов, т.е.: блоков, APEX, job, адаптивной статистики и пр.
- Не бойтесь использовать параметры автоматического вымывания из кэша (snapshot + shelflife).
- Не перегружайте кэш запросами во время загрузки больших объемов данных, отключайте result_cache перед этим. Прогревайте кэш.
- Убедитесь, что _result_cache_timeout соответствует вашим ожиданиям.
- НИКОГДА не используйте FORCE для всей базы данных. Нужна база данных в памяти — используйте специализированное in-memory решение.
- Проверяйте, адекватно ли используется опция FORCE для отдельных таблиц, чтобы не вышло, как у нас со сторонним ETL.
- Решите, так ли хороша адаптивная статистика, как ее описывает Oracle (_optimizer_ads_use_result_cache = false).
Highload++ Siberia уже в следующий понедельник, расписание готово и опубликовано на сайте. В тему этой статьи есть несколько докладов:
- Александр Макаров (ГК ЦФТ) продемонстрирует метод выявления узких мест в работе серверной части ПО на примере БД Oracle.
- Иван Шаров и Константин Полуэктов расскажут, какие проблемы возникают при миграциях продукта на новые версии базы данных Oracle, а также обещают дать рекомендации по организации и проведению подобных работ.
- Николай Голов расскажет, как без распределенных транзакций и жесткой связности обеспечить целостность данных в микросервисной архитектуре.
Встретимся в Новосибирске!
