
Всем привет! Меня зовут Филипп Бочаров, я руководитель центра мониторинга и наблюдаемости в МТС Digital. Мы с командой делаем платформу Наблюдаемости – это набор сервисов, который позволяет сделать работу других продуктов МТС прозрачной и понятной. Сегодня я расскажу про распределенную трассировку экосистемы МТС.
Давайте вместе спроектируем коммунальную систему, в которой соберем распределенную трассировку всей нашей экосистемы. Отмасштабируем ее от 0 до 50 тысяч документов в секунду и посмотрим, как меняется наша архитектура, откуда берутся потери и пиковые нагрузки, какие есть пределы и ограничения. В общем, постараемся выжить под нагрузкой!

Зачем вообще трассировать экосистему?
Чтобы ответить на этот вопрос, посмотрим на саму экосистему. В МТС это:
400+ цифровых продуктов;
гетерогенность IT-ландшафта;
экосистема и взаимосвязь продуктов.
Продукты написаны на разных языках. Есть legacy, есть решения с нуля. Продукты не изолированы и когда они взаимодействуют друг с другом на ландшафте возникают длинные интеграционные цепочки. При добавлении нового продукта экосистема дополнительно усложняется.
Представьте, что пользователь хочет перевести вам деньги за оформление подписки на услугу. В вашей экосистеме за это отвечают 4 продукта: A, B, C, D. Они разработаны разными продуктовыми командами на разных стеках.

Между продуктом A и B постоянно возникает таймаут, B не отвечает продукту A на запрос. При этом B не виноват, потому что зависит от сервиса C. Там возникает какая-то ошибка и постоянные повторные попытки выполнить запрос. В итоге пользователь никак не может оформить свою подписку. Тот, кто отвечает за такую систему, очень хотел бы автоматически увидеть, что с ней происходит, когда пользователь оформляет подписку.
К счастью, что-то подобное нам может дать распределенная трассировка. Это иерархическая древовидная структура данных, которая описывает, как интеграционный процесс выполнялся в экосистеме.

Это дерево называется трейсом, а каждая его строка (шаг) спаном. У спана есть и более понятное название. Первый спан — HTTP Get/dispatch. Он соответствует Get-запросу к методу dispatch.
Мы всегда знаем, какой сервис породил наш спан. В этой структуре есть сервисы: frontend, customer, mysql. Но это не главное. Главное, что у каждого спана есть тайминг. Мы всегда знаем, сколько времени выполнялся шаг (таймлайны справа на картинке). Если на этапе какого-то шага что-то пошло не так, мы видим признак ошибки в спанах. В последнем шаге обращения к Redis как раз содержится ошибка.
Все это делает распределенную трассировку идеальной структурой данных для проведения локализации дефектов. По этой картинке мы можем понять, какой продукт, какой сервис, и даже какой метод виноват в том, что наша система либо слишком долго работает, либо вообще не выполняет какой-то интеграционный процесс.
Надеюсь, что сумел убедить вас в полезности распределенной трассировки. Теперь давайте подумаем, какую систему будем делать.
Что хотим получить?
Нам нужна end-to-end-трассировка всей экосистемы от первого продукта до последнего, но этого мало. Мы хотим понимать, насколько она качественна в целом и как работают отдельные продукты. Для этого нужны метрики производительности всей экосистемы, продукта и даже отдельного процесса (APM-метрики).
локализация дефектов: end-to-end-трассировка;
контроль качества: метрики производительности (APM);
низкие затраты продуктов: модель Platform.
У нас 400 продуктов, чтобы их подключение было дешевым – будем делать его по модели PaaS. Начнем, конечно, с выбора стека.
Что в стеке?
Когда мы с командой начинали работу над платформой, у нас не было возможности запереться на год и проанализировать все доступные опенсорсные и вендорские решения в области APM. Поэтому мы сделали ограниченный RnD, по результатам которого выбрали два компонента: Jaeger (опенсорс-система распределенной трассировки) и Elasticsearch – как хранилище трейсов Jaeger.

Почему Jaeger?
простота доработки благодаря простому исходному коду;
открытые стандарты: OpenTracing (раньше) и OpenTelemetry (сейчас) позволяли абстрагироваться от реализации;
поддержка множества бэкендов давала надежду, что если не сложится с Elasticsearch, всегда можно будет мигрировать на другой бэкенд.
Почему Elasticsearch?
единое хранилище для логов и трассировки, все трейсы и логи в одной системе;
возможности визуализации Kibana;
опыт использования в компании, у нас уже были обученные инженеры.
Стартовая архитектура
Посмотрим на самую минимальную стартовую архитектуру на этих компонентах. У нас будет PaaS-часть, которую для простоты развернем на одном хосте в Docker compose:

Jaeger-коллектор — сервис, который собирает распределенную трассировку по HTTPS и умеет ее записывать в Elasticsearch;
Jaeger UI для работы с трейсами;
Kibana для создания дашбордов по распределенной трассировке и сбора аналитики.
На стороне продукта (нашего потребителя) будет приложение, которое инструментировано OpenTelemetry или OpenTracing, и оно отписывает нам распределенную трассировку.
На этом этапе можно принять важное архитектурное решение, которое поможет нам в будущем. Мы разделим поток трассировки от продуктивных и тестовых стендов. То есть создадим два PaaS: PROD и STAGE. Это даст снижение нагрузки на PROD на 10% и возможность тестировать на STAGE перед PROD. Уменьшится вероятность что-то не то залить на наш продуктивный стенд. Кроме этого, мы сможем тестировать все наши изменения на реальных данных с тестовых стендов.
После этого можно заняться непосредственно метриками.
APM-метрики в Kibana
Самый простой и дешевый способ вычислять APM-метрики — это сделать дашборд в Kibana. Мы берем индекс с распределенной трассировкой, находим спаны, которые нам интересны, и группируем по определенным признакам. Например, по названию сервиса, контроллера и метода.

Дальше для каждой группы считаем количество вызовов и перцентиль длительности. APM-метрики считаются прямо по сырым данным в режиме онлайн — наши пользователи счастливы! До тех пор, пока мы не начинаем нагружать систему и подключать к ней реальные продукты.
Нагрузка в 3000 спанов в секунду
Давайте подадим маленькую нагрузку в 3000 спанов в секунду:

Примем за аксиому, что на один сетевой вызов в трассировке обычно приходится 2 спана. Первый спан соответствует исходящему запросу, а второй входящему. У продукта с микросервисной архитектурой из 10 сервисов, один запрос будет порождать примерно 20 спанов. Нагружая такой продукт 150 запросами в секунду, мы получим поток в 3000 спанов/секунду в нашу сторону. Это очень мало и один продукт спокойно обеспечит такой трафик. Но даже на таком небольшом трафике мы начинаем терять спаны.
Потеря спанов
С этого момента мы постоянно будем что-то терять. Речь о том, как сделать процент потерь приемлемым. Одно дело — терять 10 спанов из 100, другое — 10 из миллиарда. Внутри Jaeger-коллектора, который принимает спаны, есть буфер конечного размера. Если попытаться записать в него больше, чем нужно, Jaeger попытается переложить батчами из буфера в Elasticsearch, а когда не успеет, отвергнет спаны. Поэтому, если Jaeger-коллектор не справляется с нагрузкой, можно сделать 2 Jaeger-коллектора:

Тогда нагрузка равномерно распределяется по ним, буфер не переполняется и все успешно записывается в Elasticsearch. Но операцию придется делать на каждые 3000 спанов нагрузки. Поэтому Docker Compose нужно заменить на нормальный Kubernetes, чтобы масштабировать на кластере до бесконечности.
Кроме этого, мы не хотим узнавать о проблемах от наших пользователей, поэтому настраиваем мониторинг на метрику количество отвергнутых спанов, которые Jaeger-коллектор сам прекрасно отдает в формате Prometheus.
Так мы справляемся с 3000 спанов в секунду!
Нагрузка в 15000 спанов в секунду
Теперь представим, что платформа стала популярной и нагрузка выросла в 5 раз. Тут начинаются проблемы: пользователь жалуется, что у него дерево разваливается на части, или отображается только половина, или трейса нет совсем. Начинает не выдерживать одна-единственная нода Elasticsearch, её нужно превращать в нормальный кластер и масштабировать его.

Для этого, во-первых, нужно увеличить количество hot-нод — нод, которые хранят новые данные на быстрых SSD дисках и количество primary-шардов. Индекс Elasticsearch состоит из шардов (кусочков). Если мы хотим вести запись параллельно, допустим, на 5 нод, нужно сделать 5 primary-шардов, чтобы каждый лежал на своей ноде.
Во-вторых, ввести ingest-ноды. Они не хранят данные, а занимаются чисто предобработкой документов перед вставкой, берут на себя часть нагрузки и увеличивают производительность нашего кластера. После этого настроим мониторинг: место на диске data-нод, количество шардов на каждой ноде и состояние пула потоков.
Эти шаги касаются масштабирования Elasticsearch на запись. Но мы хотим, чтобы наши APM-дашборды работали быстро в Kibana, поэтому делаем масштабирование на чтение. Здесь примерно та же логика. Увеличиваем количество hot- и warm-нод. Увеличиваем количество реплик вместо primary-шардов. То есть копий данных, которые будут лежать на разных нодах, чтобы можно было параллельно читать с нескольких нод. И вводим coordinating-ноды. Они тоже не хранят данные, но участвуют в обработке запросов на чтение — принимают соединения и соединяют кусочки ответов в один большой.
Также настраиваем мониторинг: перцентиль времени выполнения запросов, срабатывание circuit breaker и аномалии сборки мусора (jvm).
Теперь кластер может принять 15000 спанов в секунду, но потери продолжаются.
Пиковые нагрузки
Мы смотрим на нагрузку и понимаем, что 15000 спанов/секунду — это «средняя температура по больнице». На самом деле в наших данных есть пики.

Они возникают по тысяче причин — кто-то запустил тяжелый батч, у кого-то очередь разгребается. Эти пики кратковременные, но их достаточно много, чтобы опять забить буферы Jaeger-коллекторов, очередь на вставку Elasticsearch — и начать терять наши спаны.
Чтобы сглаживать пики нагрузки, нужно куда-то класть избыточный трафик перед записью в Elasticsearch. Для этого добавим в нашу архитектуру Kafka.
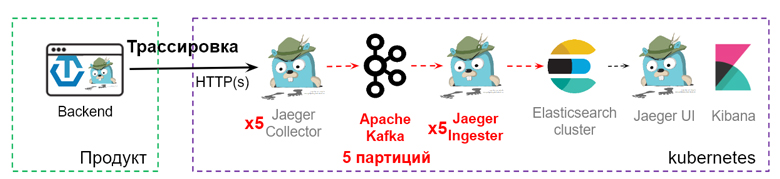
Она используется как промежуточный буфер. Jaeger-коллектор записывает данные в Kafka, а сервис Jaeger Ingester разгребает очередь. Чтобы это масштабировать, создадим дополнительные партиции в Kafka — параллельные очереди. Так же мы увеличим количество Ingester и коллекторов для чтения данных.
Если возникает кратковременный пик нагрузки, просто растет очередь в Kafka, а Jaeger Ingester разгребает данные со скоростью 15 000 спанов/с. Если нагрузка системы больше 15 000, начинает расти очередь. В этом нет ничего страшного, данные могут полежать там какое-то время. Но из-за этого появляется отставание обработки в Kafka, так называемый лаг. Это наш главный индикатор, на который мы будем настраивать мониторинг. Когда пик нагрузки спадает, очередь разгребается, и мы снова продолжаем работать без отставаний. Но что делать, если пики нагрузки не уходят?
Если пики превращаются в долговременные – это нештатный режим работы.

Надо помнить, что наша система – коммунальная. Когда потребитель с проблемой заваливает нас распределенной трассировкой, это влияет на каждого нашего потребителя. Поэтому нужен механизм, который позволит понять, с какого IP-адреса идет поток трассировки и что делать с потребителем, чтобы он не мешал остальным.
К счастью, в распределенной трассировке есть IP-адрес, с которого она была записана, поэтому такой дашборд сделать довольно легко. В случае аварийных ситуаций мы просто берем ТОП-10 IP-адресов, с которых идет трафик, и действуем по принципу «сначала стреляй – потом спрашивай»:

Блокируем аномальный трафик с IP.
Берем IP-адрес и заносим его в сетевую политику Kubernetes. Блокируем трафик по этому IP-адресу и снимаем влияние, которое он оказывает на всех потребителей.
Разбираемся с командой продукта.
Потом разбираемся, кому принадлежит IP-адрес, почему это случилось. Программная это ошибка или авария на продукте.
Но потери данных возникают не только на серверной части. Из самой архитектуры системы трассировки следует, что данные могут теряться и на клиенте.
Потери спанов на клиенте
У вас есть приложение, оно инструментировано. Внутри него есть буфер, куда кладется сгенерированная распределенная трассировка. Если ее больше, чем ваше приложение может отправить, то у вас новые данные начинают заменять старые, то есть данные теряются. Можно играться с параметрами — увеличивать размер буфера, частоту сброса. Но все это помогает до определенного момента. Наиболее продуктивная схема — использование агента.

Агент — это отдельный процесс, который ставится на той же машине, что и ваше приложение, и, допустим, по UDP забирает трассировку. Потом уже более крупными батчами используя gRPC, отправляет ее в сторону бэкенда. Это самая производительная схема. А самое главное – более наблюдаемая. У Jaeger-агента тоже есть метрики дропов, и можно отслеживать, дропаются спаны или нет.
Нагрузка в 30000 спанов в секунду
Когда скорость превышает 15000 спанов/секунду – у нас неожиданно замедляется аналитика.

Если раньше пользователи с помощью наших дашбордов в Kibana могли за месяц посмотреть какие-то APM-метрики по всей системе, то теперь мы получаем жалобы, что метрики притормаживают даже за сутки. А все из-за того, что стало больше данных, объем хранения трассировки приближается к терабайту в сутки.
Хранение трассировки
Можно поиграть с тем, как мы эту трассировку храним. Разбить индекс не по дню, а, допустим, по 6 часов или по 150 GB. Использовать алгоритм сжатия DEFLATE вместо LZ46 (опция index.codec = best_compression). Это на 20% сожмет трассировку.

Но это не поможет решить проблему полностью. Если нагрузка вырастет, проблема вернется. Поэтому необходимо кардинальное решение.
Потоковый расчет метрик
Есть два варианта: либо залить проблему железом и масштабировать Elasticsearch-кластер (а это довольно дорого), либо исключить его из этого процесса. Сделаем так, чтобы Elasticsearch вообще не участвовал в расчете APM-метрик. Так в нашей схеме появится еще одна ветка обработки распределенной трассировки — сервис Stream Metrics service.

Он будет пропускать через себя каждый спан распределенной трассировки. Смотреть, к чему он относится, например, к SQL-запросу или запросу к веб-приложению, и вычислять соответствующую метрику, например количество SQL-запросов или длительность веб-запроса. После этого Stream Metrics service положит ее в хранилище, оптимизированное для метрик, и дальше можно строить дашборды в той же самой Grafana. Мы для этого используем Victoria Metrics.
Эта схема хороша тем, что она дешевая. Elasticsearch не обрабатывает запросы, все происходит до него, параллельно. Схема хорошо масштабируется. Можно наделать десятки инстансов Stream Metrics, и они будут прекрасно считать наши метрики. При этом мы не будем использовать сырые данные для того, чтобы их вычислять, а можем хранить их годами — Victoria Metrics очень компактна.

Это пример дашбордов, которые мы можем получить. Первый график — это перцентиль времени выполнения ключевых методов. Второй график — тепловая карта — агрегация по всему продукту, показывающая насколько быстро он отвечает на запросы. Это все можно посчитать по распределенной трассировке.
Конечно, что-то может пойти не так.
Следим за cardinality метрик
Чтобы этого не случилось, надо следить за мощностью множества метрик, которые вы получите. Например, вы решили сделать метрику action_duration_ms, которая показывает время работы каждого метода вашего API. Вы хотите считать ее в каких-то разрезах, и у каждого из них будут уникальные значения.
 будет равно 36000.")
Если разрезы выбрать неправильно, например, задать слишком большое количество уникальных значений, можно «положить» хранилище. Так у нас произошло с Prometheus. Например, вы сделали разрез по userID (идентификатору пользователя), получилось более миллиона пользователей и приложение «взорвалось». Поэтому мы заменили его на Victoria Metrics.
Нагрузка 50 000 спанов в секунду
Мы подошли к страшной черте:

Это чуть меньше, чем наша реальная нагрузка на проде. Здесь у нас полностью отвалилась вся аналитика в Elasticsearch. Мы, вроде бы, уже вытащили из Elasticsearch все APM-метрики, но наши пользователи продолжали слать кастомные запросы к распределенной трассировке, используя для этого подмножество SQL, которое умеет выполнять Elasticsearch.

В этом моменте мы поняли, что нам нужно хранилище, которое позволит выполнять такие аналитические запросы, и выбрали ClickHouse.
Уже первые эксперименты показали, что с ним:
Jaeger UI отвечает на 20% быстрее;
хранение распределенной трассировки в 2-4 раза компактнее;
аналитические запросы на порядок быстрее и работают полноценно.
Пример довольно сложного SQL-запроса, который отлично работает в ClickHouse и который невозможно сделать в Elasticsearch, потому что там не поддерживаются подзапросы, джойны и многое другое.

Через вложенный SQL-запрос (обведен пунктиром) мы находим трейсы с операцией OrderFulfillment%. Дальше для каждого из них находим длительность — время от первого до последнего спана. Наконец, в самом внешнем запросе считаем перцентиль этой длительности. Таким SQL-запросом получается посчитать метрики не для отдельных спанов, а для всего трейса. В Elasticsearch это сделать не получится.
Кажется, мы решили все проблемы. Больше нет никаких ограничений — берем любую систему и подключаем к нашей платформе. Конечно, это не так. У нас есть свои ограничения и пределы, и мы столкнулись с продуктом, который не смогли подключить.
Пределы и ограничения
У нас есть продукт, который обрабатывает переключения абонентов между вышками. Как только телефон переключается от одной вышки к другой, генерируется событие, которое проходит через этот продукт. Там поток в несколько миллионов событий в секунду. Все это проходит через большой кластер Kafka.
Давайте подумаем, что будет, если мы захотим трассировать, как этот продукт отдал событие какому-то другому продукту. На один сетевой вызов у нас приходится 2 спана, получается передача контекста трассировки: + 16 МБ/c к трафику через Kafka и + 2000000 спанов/с в нашу сторону. Это в разы больше цифры, о которой мы до этого говорили. Понятно, что мы этого не выдержим.
Из таких кейсов у нас родилось эмпирическое правило:
Мы используем 100% сбор распределенной трассировки без сэмплирования для продуктов,
у которых меньше 10000 RPS.
Наверное, на этом можно было бы закончить статью, но наши проблемы не закончились.
Длина и сложность трейса
Дело в том, что мы подключаем все новые и новые продукты, наше дерево растет, и пользователям становится некомфортно с ним работать.

Дерево длиной до 10000 спанов еще более-менее нормальное. Оно быстро работает, люди могут в нем что-то найти. От 10000 до 100000 уже начинаются проблемы. Интерфейс Jaeger тормозит, и просто ориентироваться в 100000 спанов очень сложно. Если ещё больше — что-то найти уже просто невозможно. Если думаете, что 100000 спанов – это какие-то монструозные процессы, то спешу сообщить у нас было и побольше. Например, трейс длиной в миллион спанов. Конечно, это некая аномалия, пограничное значение, но оно реально у нас встречалось. У него могут быть следующие причины:
длительные процессы с логикой переповторов;
бесконечные «зомби-процессы»;
обработка крупных батчей данных;
ошибки инструментирования: «склеивание» нескольких трейсов в один.
Представьте сложный интеграционный процесс, который работает по принципу: проверил условие, если оно не выполнилось – заснул на 10 секунд. Потом проснулся, снова проверил условие, опять заснул. Если такой процесс существует месяц, то он каждые 10 секунд описывает кусочек трассировки и запросто нагенерирует миллион, а то и десять миллионов спанов.
Чтобы как-то справиться с этой ситуацией, мы придумали процесс сокращения длины трейса. Он, конечно, работает только в случаях, если это не аномальная ситуация, а просто команда реализовала слишком подробную трассировку.
Метод борьбы со слишком большими трейсами
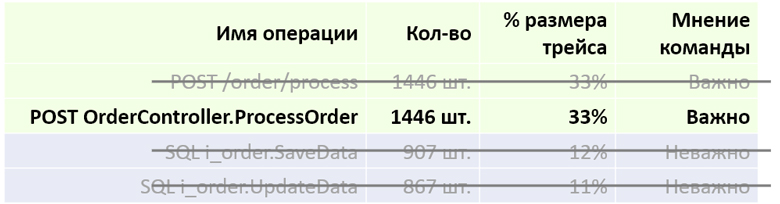
Мы берем трейс и группируем по названию операции. Получается отсортированная по количеству таблица, показывающая сколько раз подобный спан встречается в нашем дереве.

Обратите внимание, что первые два спана имеют одинаковое количество вхождений в дерево (1446). Это значит, что они соответствуют одному событию (входящему запросу). Первый спан соответствует просто по запросу, второй — тому, какой action выбрал наш фреймворк, чтобы этот запрос обработать.
Мы берем и объединяем одинаковые события:

Можно превратить их в один спан, как-то скомбинировать название, чтобы не потерять никакую информацию. Таким образом мы сразу обрезаем наш трейс по длине.
Кроме этого, бывают не важные для диагностики спаны. Чтобы их найти, лучше всего пообщаться с продуктовой командой. Они скажут, что, например, SaveData — это второстепенная хранимая процедура. И для локализации не очень важно, вызывается она или нет, можно вообще вычеркнуть эти спаны из дерева.
Так нам удавалось сократить до 40% спанов в нашем дереве:
Вроде бы все победили — нагрузку, длину трейса, но в какой-то момент вы заходите в Jaeger и видите в спанах номера кредиток, телефонов, паспортные данные, и хватаетесь за голову.
Конфиденциальные данные
Вы вроде хотели сделать общее средство диагностики дефектов, доступное всем инженерам вашей компании, а в распределенной трассировке появились конфиденциальные данные, которые должны видеть не все. Возникает когнитивный диссонанс — чтобы его решить, нужно вводить разграничение прав доступа.

В Jaeger нет никаких значений «из коробки», которые привязывают трейс к определенному продукту. Поэтому ему надо помочь. Мы попросили продуктовые команды при подключении добавлять два специализированных тега в нашу распределенную трассировку: productID и tenantID.

Это идентификаторы из нашего корпоративного каталога, которые привязывают спан к определенному продукту и системе. Так мы понимаем, с кем имеем дело, и можем раздавать доступы. Первое, что приходит на ум — просто вырезать из трассировки данные сервисов и продуктов, которые не доступны инженеру.

К сожалению, это плохое решение, потому что трейс развалится на части, потеряет причинно-следственную связь и проводить локализацию станет невозможно. Гораздо более правильный подход – сокрытие самих тегов.
Мы еще на уровне бэкенда Jaeger UI можем понять, у какого инженера к каким данным не должно быть доступа. И вырезать из тегов или закрыть звездочками все нестандартные теги, которые не генерируются «из коробки» Jaeger.

Так наше дерево сохранит форму, а инженер сможет понять, какой продукт в каком месте работал, и проведет локализацию.
Выводы
Давайте еще раз вспомним, что нам помогло на этом длинном пути:
разделение тестовых и продуктивных зон (мы создали два контура STAGE и PROD), что снизило нагрузку и позволило лучше тестировать релизы;
нужно отслеживать неправильное использование трассировки, так как это может порождать слишком длинные трейсы и паразитную нагрузку. Поэтому надо четко понимать для чего необходимы средства диагностики, best practices, а иногда просто работать с командами;
нужно работать с продуктовыми командами над балансом информативности и размером трейсов. Это вытекает из второго пункта. Распределенная трассировка — это не тот инструмент, который просто отдал командам и всё само заработает;
нужны стандарты, периодическое взаимодействие с командами, чтобы помогать им сделать трейс достаточно подробным для диагностики, но настолько коротким, чтобы в этом дереве можно было что-то найти.
Надеемся, что информация из этой статьи вам пригодится, а вопросы ждем в комментариях. Удачи!
Уже совсем скоро начнется очередная конференция Saint HighLoad++ Главное событие для разработчиков высоконагруженных систем пройдет 22 и 23 сентября 2022 в Санкт-Петербурге. Подробное расписание, программа и билеты по ссылке.
