
Привет, Хабр! Меня зовут Миша Трифонов, я head of frontend в компании Cloud.ru и основатель сообщества TeamSnack. Поделюсь опытом, кейсами, решениями за 3,5 года работы в направлении микрофронтов.
Статья будет полезна как для тех, кто мало пользовался микрофронтами, так и для гуру микрофронтов. Расскажу, что это такое, покажу преимущества их внедрения и научу продавать ценность этого процесса бизнесу. Еще расскажу про трудности: технология требует ресурсов и усилий.

3,5 года назад…
У нас росла команда. Когда работал один человек, он перформил с одной эффективностью. Когда стало четыре человека, мы ожидали, что эффективность повысится в четыре раза. Но команда росла, а эффективность падала.

Цель 1: Быстро масштабировать команду, не теряя эффективности
Мы проанализировали и поняли, что команды, взаимодействуя друг с другом, начинают тратить время: на релизные циклы, взаимодействие, merge-конфликты. Нужно было это нивелировать. Решили использовать микрофронты. Эта технология позволяет разрезать один сайт на несколько разных.
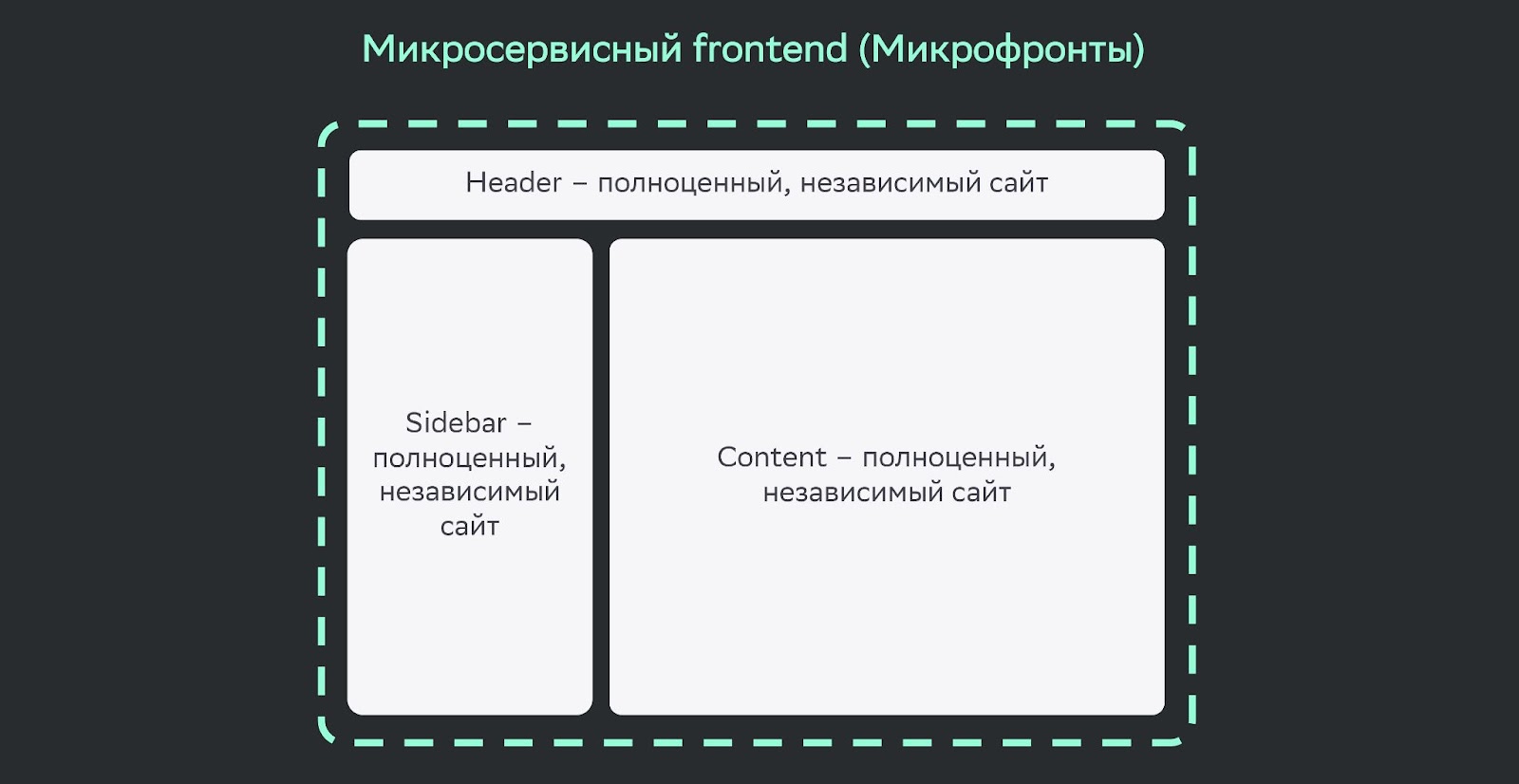
Эти сайты будут независимы друг от друга. Каждая команда и человек смогут работать только со своим сайтом, не затрагивая другие. Так им не нужно будет тратить время на взаимодействие и согласования.
Можно внедрить continuous delivery — быстрый запуск в продакшн. Также за счет частичной доставки техдолга можно ускорить саму работу с техдолгом.
Целый год мы внедряли, улучшали, и наша гипотеза оправдалась. Команда выросла в 2 раза. При этом приложение и его функциональность выросла на 700%. Эффективность на одного человека выросла в 3,5 раза.
На второй год мы взялись за стандартные проблемы внедрения микросервисов. Про это есть целый доклад — «9 стандартных вопросов, с которыми ты столкнешься, внедряя микросервисы». Эти девять вопросов придется решить в любом случае, неважно, вы в начале пути или в середине:

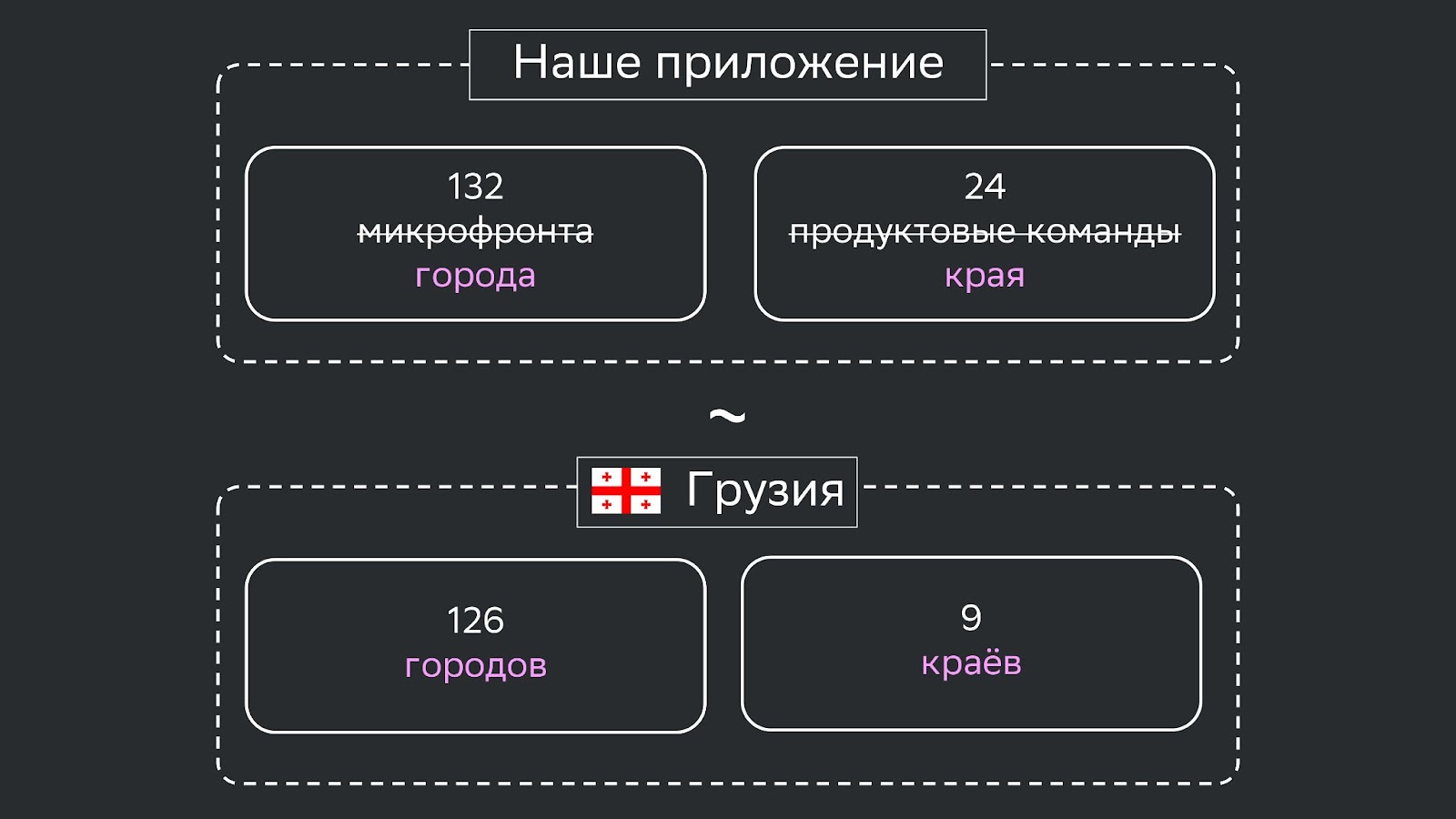
На третий год наше приложение стало очень большим: 132 микрофронта, 24 продуктовые команды, не взаимодействующие друг с другом, и 59 frontend-разработчиков.
Это настолько много, что можно сравнить с Грузией. Каждый микрофронт — один город. То есть у нас 132 города — в Грузии 126 городов, у нас 24 края — в Грузии 9 краев. Представьте, что будет, если Грузия отдаст всё управление в города. Будет раздрай, хаос, анархия, паника.
Напомню, что микрофронты — это такая технология, где каждый сайт работает отдельно. На своем сайте каждый может делать всё, что хочет. Он никак не ограничен. У одних React, у других Angular или Vue.
Микросервисы позволяют изолировать команды друг от друга. Они действительно не пересекаются. Каждый работает со своим кусочком: continuous delivery, частичная доставка техдолга. Но у изолированности есть минусы: из-за того, что никто не зависит друг от друга, каждый начинает делать свое. Кто в лес, кто по дрова. Не видно багов, тяжело отслеживать чистоту кода и так далее.
Цель 2: Сохранить плюсы изолированности, а минусы нивелировать или автоматизировать их проверку
Когда страны начинают образовываться, первое, что они делают: пишут конституцию и законы. Вот мы и начали внедрять стандарты. Нужно было сделать так, чтобы 59 разработчиков договорились.
Создаем стандарты
Для этого мы применили технологию по методу Котера. Есть доклад на эту тему.
Происходит это так: один разработчик создает стандарт и становится его овнером. Он может делать, что хочет без ограничений. Дальше он попадает в малую группу, состоящую из трех-пяти разработчиков, демонстрирует свой стандарт, собирает обратную связь. В итоге получается, что все пять человек разделяют этот стандарт. Потому что разработчик не уходит, пока с остальными не договорится.
Получается эффективный стандарт, который идет в массы. В массах или больших группах уже не договариваются об изменении стандарта, а только собирают и учитывают фидбек. В результате наши уникальные стандарты разработали сами разработчики снизу, а не сверху. Они сами договорились. Никого ни к чему не принуждали.

Назначаем ответственных
Но если написать стандарты, ничего не изменится. Как в разных странах назначают главу города, так мы должны назначить ответственного за каждый микрофронт: с кого спрашивать про эти стандарты.
Это было нелегко. Ниже граф поиска ответственного по одному из сервисов. Есть сервисы, где всё легко, а есть сервисы полу-legacy, и найти ответственных нужно еще постараться.
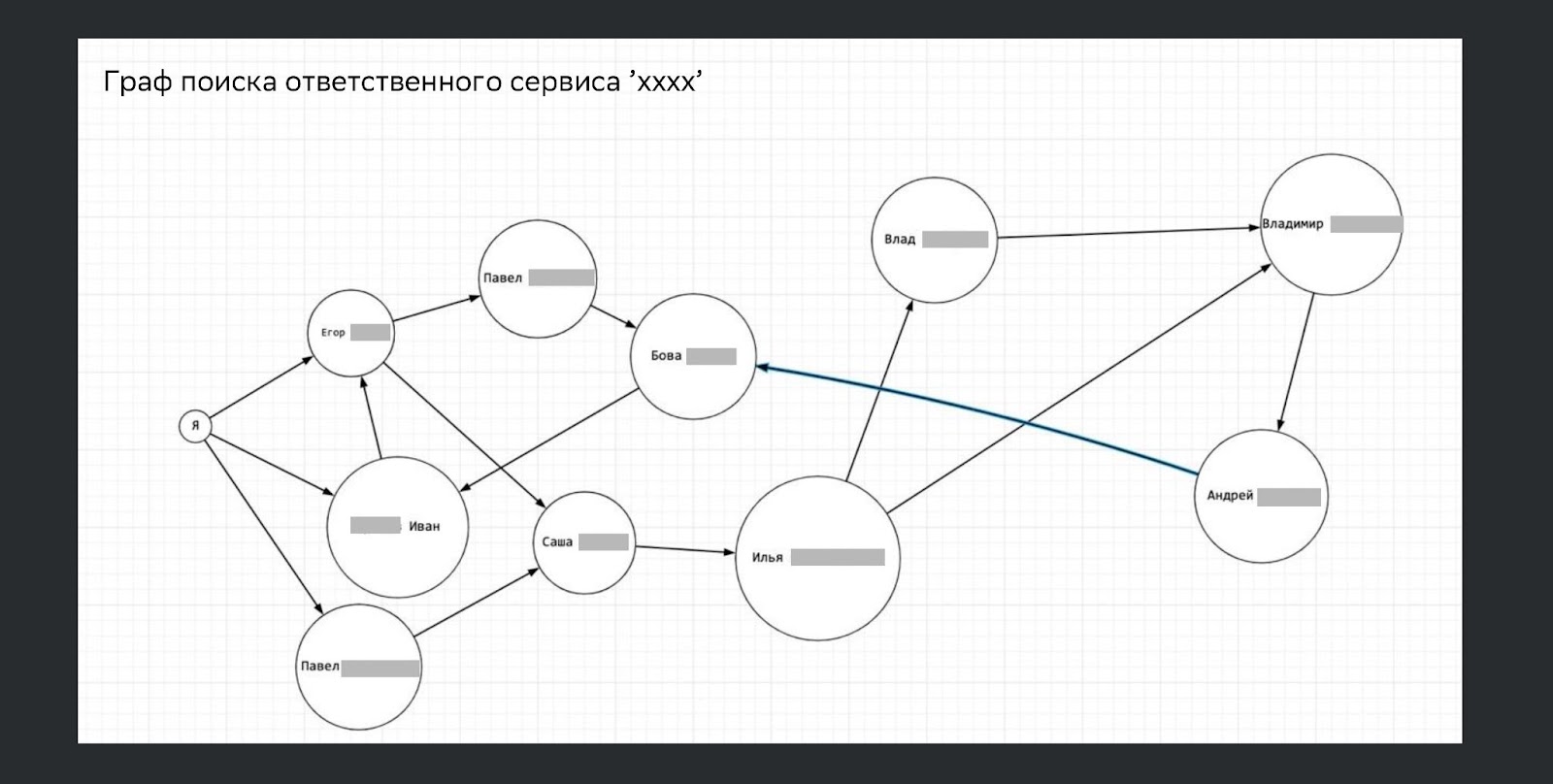
В итоге круг все-таки замкнулся. Назначили стандарты, ответственных, но в приложении ничего не изменилось.
Внедряем стандарты
Дальше мы начали самый большой и тяжелый процесс — внедрение.
Если не отслеживать зависимости:
рассыплется интерфейс, он будет не консистентный;
разработчики начнут тратить больше времени из-за legacy, UI-китов или legacy-обновлений зависимостей, чтобы приступить к бизнес-фиче;
могут появиться баги, потому что разработчики устраняют баги у себя в сервисах, а дальше их не обновляют и живут с ними дальше;
увеличивается риск bus factor, потому что расширяется стек технологий;
возникают риски с платными лицензиями. Бывают истории, когда open source перестает быть open source, и компании могут потерять большие деньги. Особенно этот риск актуален для крупного энтерпрайза;
возникают зловредные зависимости. У нас были ситуации, когда компьютеры ломались из-за open source-проектов.
Что с этим делать?
Создать black-лист с зависимостями.
Проверять и анализировать лицензии на пайплайне.
Обновлять все зависимости один раз в спринт, а глобальные один раз в год, как мы делаем в начале квартала. Так мы увидим все отклонения от техстека.
Проверяем black-листы и лицензии

У Gitlab есть личное развесистое rest API, которым можно пользоваться. Можно выгрузить весь список проектов, потом собрать оттуда все package.json, где видны зависимости. В этих зависимостях можно проверить, что есть в black-листе.
Но есть маленький нюанс. Мы думали, возьмем не только package.json, package.log или только package.log и посмотрим лицензии в одноименной графе. Но это не работает, потому что графа появляется не везде. Лучше использовать NPM View через child-процессы. Это можно вызвать в JS.
Итак, нужно постоянно обновлять зависимости, большие библиотеки вроде React, поднимать ноды раз в спринт в начале квартала. Но часто отсутствует мотивация этим заниматься.
Поэтому самое первое, что нужно сделать — продать ценность этого обновления.
Продаем ценность выполнения техдолга менеджеру и разработчику
Менеджерам можно объяснить, что техдолг есть всегда и с ним нужно работать. Если сейчас этого не делать, то в один момент не получится разрабатывать дальше, придется переделывать всё приложение. Мы столкнулись с подобным кейсом.
Менеджеры могут управлять техдолгом за счет того, что делают это постоянно. Если закладывать на это время, техдолг не выстрелит и всё будет прозрачно.
Чтобы продать ценность обновления разработчику, мы пообещали ему максимально упростить задачу: улучшили DX, дали инструменты для контроля обновлений. Что важно, предоставили легальное время для устранения зависимостей и работы с техдолгом. Чтобы разработчик не работал ночами, а у него было специально выделенное время для решения поставленной задачи.
Здесь важно, чтобы менеджер и разработчик приняли работу с техдолгом и согласились на нее. Бывают кейсы, когда это не работает. Например, невозможно объяснить важность работы менеджеру. Тогда можно сделать предложение только разработчику, ведь он сам планирует свое время. Он может закладывать в тайминг работу с техдолгом и не говорить об этом менеджеру. Таким способом тоже можно решить ситуацию.
Если разработчик не хочет решать проблему, а менеджер согласился, нужно написать автоматическую постановку этой задачи в Jira или где-то еще. Так у разработчика действительно будет время на ее выполнение.
Используем инструменты для контроля
Мы обещали разработчикам, что они будут видеть все обновления. Для этого есть бот Renovate. Он ходит по всем репозиториям, видит, какие зависимости протухли, предлагает их обновить и делает MR в репозиторий.
Итак, мы дали разработчику время, поставили таску в Jira, сделали MR’ы, чтобы видеть обновления, но все равно ничего не обновлялось. Потому что он залил обновления в мастер, но до прода еще не докатилось. В этом случае нужна внешняя мотивация.
Так появилась диспетчерская. Есть команда со своими репозиториями и пункты соблюдения стандартов. Есть общий процент, процент соблюдения стандартов командой и конкретный процент. Например, в auth можно посмотреть, что он составляет 67%.
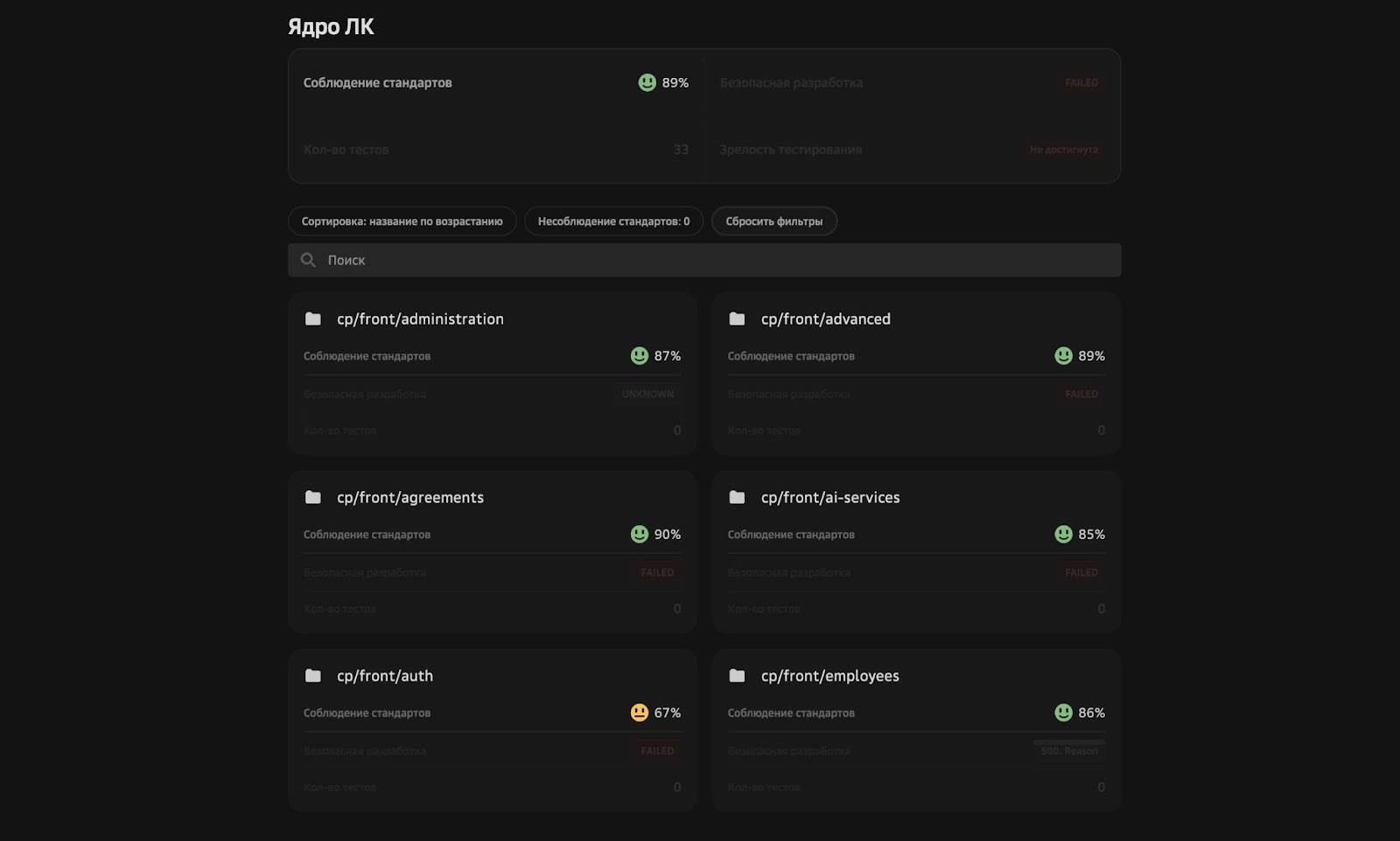
Если провалиться, все смогут понять, что идет не так:
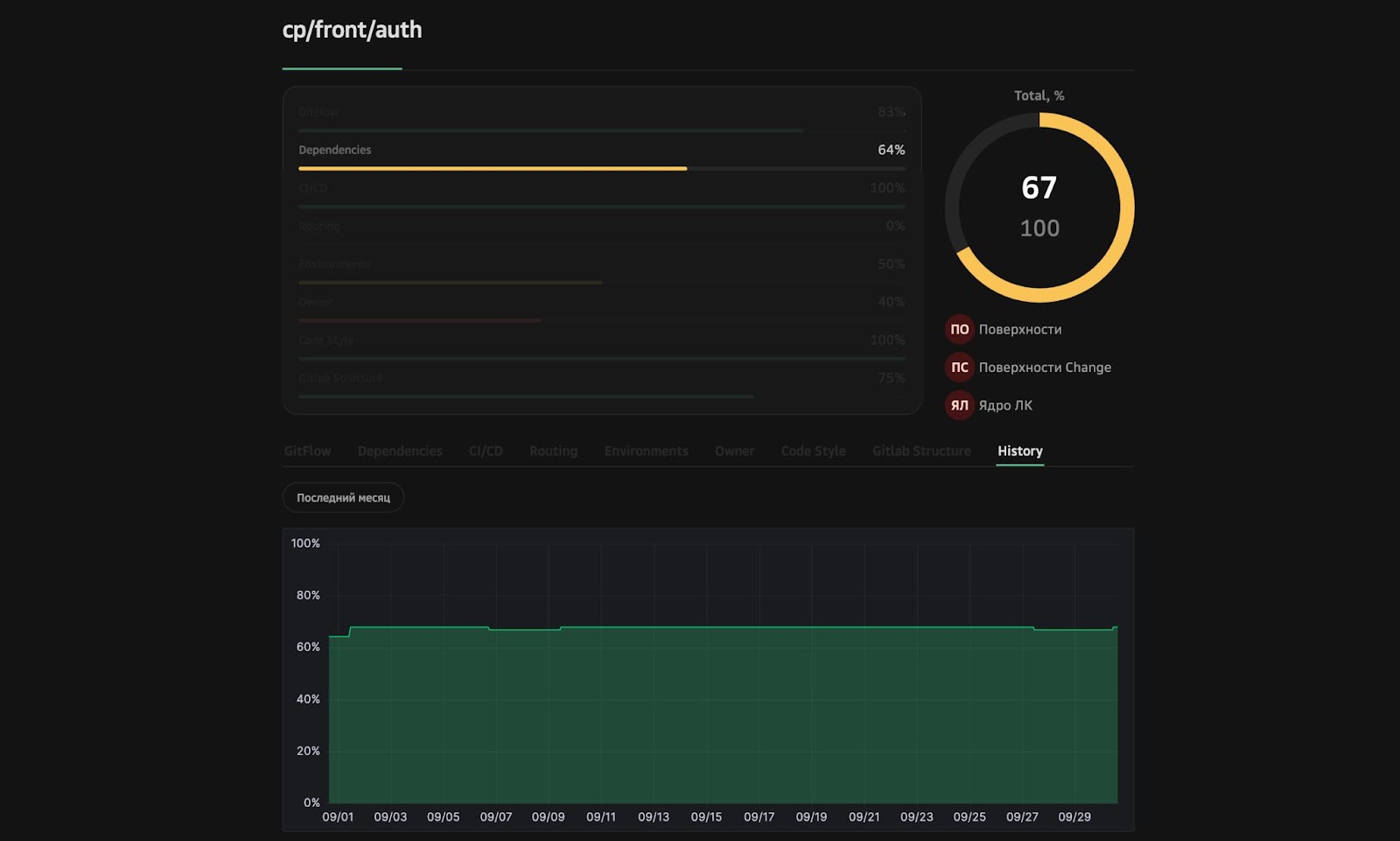
Если стандарты долго не соблюдаются, есть график, где видны зависимости, и можно посмотреть, что с ними не так. С этим инструментом процессы контролирует сам разработчик, техлид, менеджер. Все могут увидеть, как обстоят дела.
Проверяем, что разработчики соблюдают требования
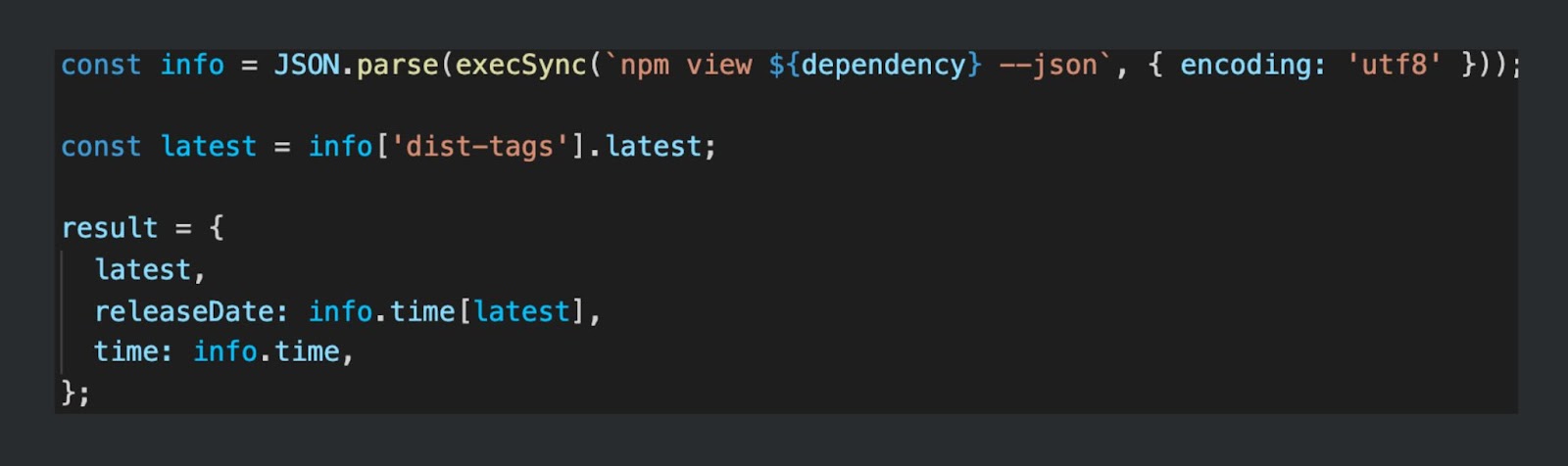
С помощью Gitlab API собираем список репозиториев, а в package.json получаем версию и берем NPM View. Там есть последняя зависимость, а в package.json через NPM View видно последнюю версию и дату ее выхода. Сравниваем эти два показателя и понимаем, как давно обновлялись. Мы договаривались делать это раз в спринт, поэтому у нас есть месяц, чтобы обновиться. В коде это выглядит примерно так:

Мы видим, что нужно обновить deps. Также есть зависимости, которые уже не используются deprecated. Еще можно посмотреть preview packages или установку renovate.
Мы обещали разработчикам, что облегчим им задачу. Поэтому на Post Install есть скрипт, показывающий список зависимостей, которые стоит обновить.

После внедрения многие стали отслеживать ситуацию, но не все. Все равно находились люди, которые ничего не соблюдали.
Работаем с окружением
Мы работаем с зависимостями package.json, а еще у нас есть environments, установленные непосредственно у разработчика на компьютере. Это NPM, нода, за которым тоже надо следить. Ведь если нода у разработчика не соответствует ноде на CI/CD, возникнут баги. У разработчика локально будет все работать, а на проде — нет. Для этого есть инструмент Solidarity. Он проверяет, какая нода установлена у разработчика. Инструмент показывает, что не так, что нужно проверить и куда перейти.
Настраиваем репозиторий
К нам начали приходить люди и говорить, что у них не так настроен репозиторий. Мы быстро растем и от этого часто появляются новые репозитории, соответственно, возникает разница в настройках.
Чтобы выйти из положения, можно дать все овнерство одному-двум сотрудникам, которые станут отцами репозиториев. Власть — это хорошо, но ведь эти двое могут уйти в отпуск, и все останутся без прав. Поэтому хочется систему, не завязанную на персонале и работающую без людей.
У Gitlab API можно отслеживать вообще всё — default branch трек, merge-метод. Мы вынесли отдельно отслеживание Gitlab API. Разработчик может создать удобный метод, если некоторые процессы не подходят, и их стоит поменять. Эти изменения мы будем видеть в диспетчерской.

Проверяем стилизацию кода
Я понял, что code style — это вкусовщина, и у каждой команды он будет свой. Как только мы начали этим заниматься, пошли в ESLint-документацию. Она обширная, и в ней можно настроить практически всё. Поэтому любое правило стоит сначала проверить через документацию: а можно ли это настроить.
Есть одно дополнение, которое стало для нас открытием — плагин ESLint Boundaries. Он позволяет занести структуру проекта в ESLint. Стандартизировать структуру проекта можно с помощью правил. Залить их и настроить — с помощью Boundaries. В итоге всё заработает.
Результат
Мы проделали большую работу. В итоге инноваторы, быстро принимающие изменения (3%), и ранние адаптеры (47%), которые раньше всех привыкают к изменениям, стали соблюдать стандарты. Оставшиеся — 34% поздних адаптеров и 16% скептиков не приняли изменения.
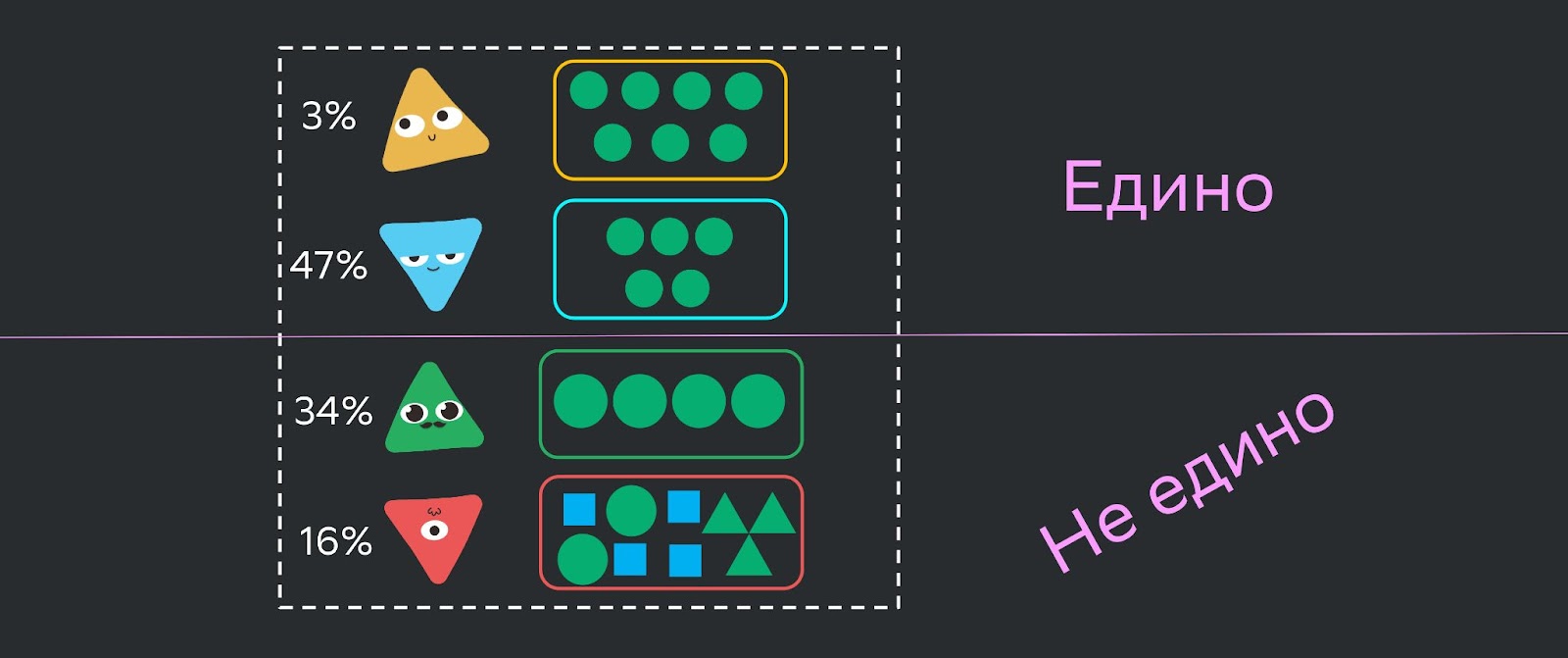
Поэтому мы придумали еще один путь принятия изменений, об этом расскажу в другой раз.
Итоги
Хочу сказать спасибо команде Cloud.ru, мы проделали большой путь. Три года назад мы поставили себе цель быстро масштабировать команду, не теряя эффективности. Эту цель мы выполнили при росте с двух до 59 разработчиков. Не испытываем архитектурных проблем и не мешаем друг другу, так как построили масштабированную микросервисную архитектуру.
Нивелировать минусы изолированности получилось не до конца, работа еще идет. Возможно, поделюсь, как мы реализовали эту цель до конца в следующем году.
Посмотреть выступление Миши Трифонова на FrontendConf 2023:
