
Необходимость мониторинга должна быть очевидна практически для любой компании, однако я не раз сталкивался с примерами, когда к такому выводу ребята приходили только после падения продакшна. Причем нередко команда узнавала об этом уже постфактум — от своего генерального директора, которому на недоступность проекта пожаловались его друзья, решившие вдруг взглянуть на стартап. И вот он в гневе звонит членам команды с вопросом даже не «почему все упало», а почему он об этом знает, а они — нет. И тут им в голову приходит мысль, а почему бы не настроить мониторинг? Казалось бы, что может быть проще…
Нам, например, круглосуточно требуется мониторить более 46 000 метрик на более чем 500 серверах в 6 дата-центрах и 4 странах, а DAU игры War Robots стабильно переваливает за 1 500 000 человек.
Но правильный, настоящий мониторинг пишется кровью системного администратора и разработчика. Каждый кейс, каждый факап и даже внутренние процессы, включая количества тонера в картридже принтера, должны быть описаны сценарием мониторинга. Я решил немного рассказать о том, с чем мы столкнулись при организации этого процесса, а также как выстроили работу сисадминов, снизив количество дежурств и улучшив их качество. При этом упор будет сделан на подходе к мониторингу, тогда как настройка той или иной системы легко гуглится и без посторонней помощи.
Для начала несколько кейсов из прошлого. Помню был случай, когда какой-то Java-процесс по API отдавал 200 и пустое тело. Процесс висел, порт был открыт и соединения телнетом принимал. Но при этом любой http-запрос от внутренних сервисов к API тоже отдавал 200 и пустое тело. И казалось бы — сервис есть, порт отвечает, а данных не отдаёт. Поэтому мы теперь везде, где возможно, проверяем особый URL, который не нагружает сервис, но привязан к его работе и в случае, если всё хорошо, отдаёт 200, а в теле — результат работы. Ошибкой в нашем случае будет либо ответ, отличный от 200, либо любое несоответствие ожидаемому формату.
В другой раз проблема была со связанностью нод в кластере, когда одна нода могла не видеть кого-то из кластера, а все остальные считали, что всё в порядке. Разработчики базы данных тогда объяснили у себя это багом. Но нам от этого легче не стало и результатом приобретенного опыта стало добавление новых мониторинг-метрик. С каждого узла кластера мы стали собирать данные о количестве узлов в состоянии DOWN. И в случае, если это значение больше 0, — на конкретном хосте выполняется скрипт, который в отдельную метрику записывает адрес хоста, с которым пропала связанность.
Также после определенной ситуации мы стали мониторить DNS-резолвы с сервера на сервер. Это был случай, когда в игре возникли проблемы, но мониторинг сработал только на следствие. Чтобы разобраться в причинах, пришлось немного покопаться. Как выяснилось в итоге, часть хостов начали неправильно разрешать некоторые наши DNS-имена. Поэтому сейчас у нас есть специальный механизм, который проверяет разрешение имен. В случае проблемы срабатывает триггер и затем все критически важные имена заносятся в hosts-файл. Это позволяет получить минимальный даун тайм и возможность спокойно разобраться в причинах проблемы.
Инструменты
Чем именно мониторить — вопрос важный и очень хороший. Когда-то у нас замечательно справлялись несколько Nagios-серверов на стеке thruk + nconf + munin. Но когда сервера начали добавляться по 50 штук в месяц, а сервисы по 300 в неделю — нагиосы и мунины перестали справляться с нагрузкой и отвечать нашим представлениям об автоматизации.
В итоге, как бы не было больно, нам пришлось переезжать на Zabbix. И дело тут не только в разности подходов Zabbix и Nagios, но и в огромном количестве кастомных метрик, которые нам пришлось переписывать. А также в отсутствии возможности проверить самые критические части в боевых условиях на Заббиксе, ведь мы не стали бы вызывать их искусственно.
Зато переезд дал нам единый интерфейс конфигурации и управления, API для регистрации серверов и присвоения им в автоматическом режиме темплейта, графики из коробки, более продвинутую систему Zabbix Proxy и, если нам совсем уж чего-то не хватало — можно было использовать Zabbix Sender.
В идеале новый сервер должен автоматически регистрироваться в системе мониторинга и на него, исходя из его hostname, присваиваться соответствующий шаблон (пример «хорошего» хостнейма: web1.ios.ru.prod.example.com). Добавление пачки серверов тоже не должно быть головной болью.
В нашем случае существует полная корреляция между всеми группами хостов во всех системах инфраструктуры. Мы добавляем сервера специально написанной ролью Ansible, которая вызовом API Zabbix добавляет хост в заббикс. Потом присваивает ему хост-группу и темплейт согласно его группе во FreeIPA и Ansiblе. Однако вопросы автоматизации — тема отдельной большой статьи.
Помимо заббикса у нас также трудится амазоновский CloudWatch, остатки нагиоса и еще пара вещей.
Как аккумулировать все уведомления в одном месте, чтобы не бегать по пяти разным статус страницам? Для нас откровением стал PagerDuty — в нем мы настроили график дежурств и эскалационные политики. Для отправки данных в PD мы использовали стандартные модули для Zabbix и CloudWatch, а также написали свои модули для отправки необходимых нам данных, остатков нагиоса и нескольких специфических мест. Очень порадовал их API — он целиком покрывает все стандартные требования.
Также неплохо себя показала Grafana, дополнительно прикрученная к стандартным заббиксовым графикам.

Хороший триггер, плохой триггер
Отдельно хочется отметить, что не стоит увлекаться и слать уведомления по каждому существующему триггеру, если вы не хотите постоянно просыпаться из-за «ложных» срабатываний. В исключительных случаях, если вы знаете, что сервис может выдавать одну ошибку в час и это для вас является нормой, то можно агрегировать ошибки за дельту времени. Таким образом можно минимизировать ложные срабатывания системы мониторинга, отсылая уведомление о проблеме, например, только в случае возникновения трех и более ошибок в течение 15 минут.
Тем не менее ничего не должно ускользнуть от всевидящего ока мониторинга.
Мониторить требуется и показатели софта, и процессы взаимодействия между сервисами — например, коннект к базе данных не с сервера базы данных, а с сервера приложения, который непосредственно этим коннектом пользуется.
Если у вас есть хардварный рейд — ставьте CLI-утилиты и добавляйте в мониторинг состояние вашего RAID-массива. Если вы знаете критическое (для пользователя) время загрузки страницы и ее размер — мониторьте и это. Если у вас свой внутренний протокол — требуйте от разработчиков дать вам Status Page (и всегда требуйте разъяснений за каждую метрику, лучше — с описанием в wiki проекта) или предоставить инструментарий для самостоятельных тестов закрытого протокола внутренней разработки.
Плохая, непонятная метрика: All systems state — OK.
Хорошая метрика: Server to server query time — OK (under 2 sec).
Также хочется вспомнить про типы уведомлений info, warn и crit. Вы можете описать все, что хотите, триггером info — будете получать по этой метрике статистику, видеть график и, возможно, в какой-то момент поймете, что вам требуется добавить на эту метрику трешхолд на warn и crit. Или сможете определить в ретроспективе, когда у вас начали расти показатели по этой метрике. Но значения warn и crit должны быть для вас очень прозрачны и понятны. По сути, каждое их ложное срабатывание — это потеря 15 минут времени.
Как не доводить проблему до абсурда
Важно понимать так же не только, по каким критериям мы шлем нотификации, но и кому. Это могут быть разные линии тех поддержки или разработчики и админы. В некоторых особо критичных случаях можно даже генеральному директору прислать уведомление, но, конечно же, не стоит до этого доводить.
Раньше у нас дежурили по два админа каждые две ночи. В результате четыре человека стабильно не высыпались, а качество как работы, так и дежурств постепенно падало. Грамотное построение эскалационной политики позволило не только улучшить качество работы, но и снизить количество дежурств и сверхурочных часов дежурных сисадминов.
Сейчас каждый админ дежурит сутки через трое. В целом эскалационная политика в нашем случае выглядит следующим образом:
- при срабатывании триггера дежурному админу отправляются оповещения: на почту и через PagerDuty — в Slack, смской, push-уведомлением и звоноком от робота;
- в случае отсутствия реакции через 30 минут проблема эскалируется на всю команду всеми доступными способами нотификации;
- если вся команда не отвечает в течение 20 минут — эскалация происходит на начальника отдела;
- если и он подзабил на звонок от системы — через 10 минут звоним техническому директору.
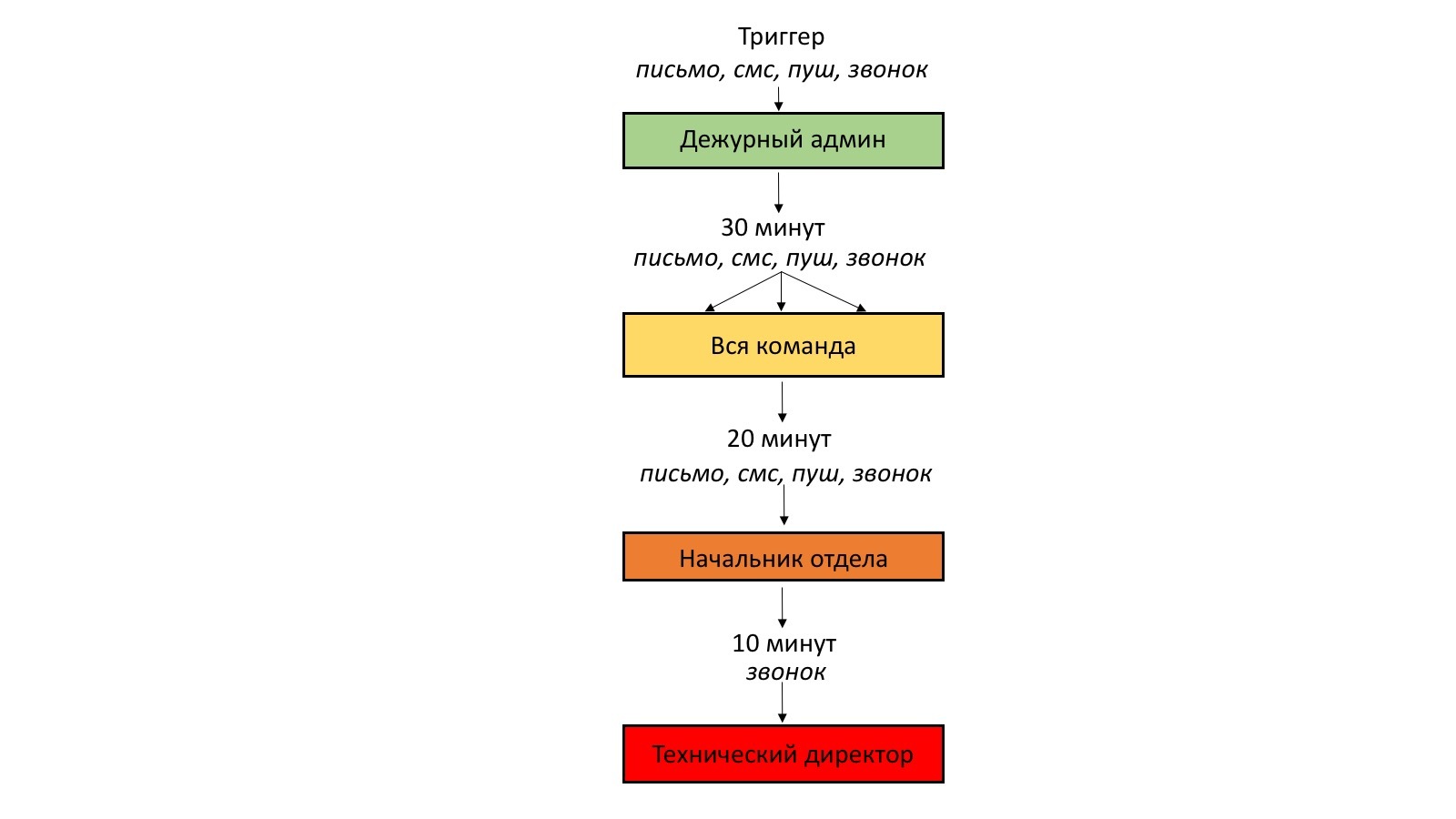
Справедливости ради стоит отметить, что дальше второго шага у нас ни разу не доходило.
При этом у нас всего 2 серверных админа, а 2 хелпдеска достаточно квалифицированы, чтобы решить простейшие проблемы, которые могут возникать с серверной инфраструктурой — например, рестартануть/ребутнуть сервер или выполнить трейсы и составить тикет в дата-центр.
Мониторинг на опережение
Пару слов о превентивной настройке мониторинга ключевых нововведений.
Еще до релиза каждой новой фичи, разработчики подготавливают и передают нашему отделу документацию по критическим метрикам, требующим внимания со стороны мониторинга. На основании этих данных настраиваются информационные метрики для определения дальнейших боевых (продакшн) метрик.
Документация в обязательном порядке содержит в себе, что означает каждая метрика, как она влияет на соседние параметры и порядок действий в случае нотификации по пороговому значению. Например, перед введением клановых сервисов была добавлена метрика процента фейлов при запросах к ним.
Уроки географии
К вопросу географического расположения сервера мониторинга требуется подходить очень осознанно. Яркий пример того, как делать НЕ надо (но многие продолжают совершать эту ошибку), — располагать сервер мониторинга в том же дата-центре, где и сервера, которые он будет отслеживать. В этом случае, если в даун уходит весь дц, вы снова узнаете об этом только от своего генерального директора.
Ещё одна распространённая ошибка: размещать мониторинг в той же стране что и сервера, если основной доход приносят пользователи другой страны. При таком сценарии мониторинг, располагающийся, например, в Берлине, будет показывать, что в Германии все хорошо, в то время как пользователи из США будут испытывать сетевые задержки в случае просадки производительности международных коммуникаций тех сетей, что у вас используются. Но вы об этом опять же ничего не узнаете и на стендапе с утра на вопрос, почему вчера на графиках просели платежи и все ли было хорошо с серверами, будете уныло разводить руками.
Если говорить более конкретно, то у нас имеется центральный сервер, к которому подключаются отдельные прокси, находящиеся в конкретном регионе. Каждый прокси собирает данные и отправляет их центральному серверу. Мониторинг важных и географически зависимых сервисов осуществляется либо кастомными юзерпараметрами с каждого заинтересованного хоста, либо с каждого прокси-сервера. Это и даёт нам чёткое понимание географических проблем.
Мониторинг мониторинга и не только
Но не следует ограничиваться мониторингом исключительно внешних вещей. Мониторинг внутренних процессов так же важен. Независимо от того, говорим ли мы о количестве тонера в картридже принтера или о количестве зарегистрированных (билд) агентов в вашей системе CI/CD. Каждый допущенный факап внутренней инфраструктуры ведет к парализации работы того или иного отдела.
Мониторить также полезно количество Wi-Fi клиентов, подключенных к точке доступа, загруженность основного и резервного каналов офисного интернета. Например, у нас более 300 Wi-Fi устройств, одновременно подключенных в корпоративную сеть и генерирующих трафик. И без мониторинга было бы очень тяжело заранее ставить дополнительные точки доступа там, где это необходимо.
Мониторинг Wi-Fi точек, в частности, однажды помог нам решить проблему с тестированием игры. Отдел QA стал жаловаться на высокий пинг в игре и именно мониторинг позволил выяснить, что большинство тестировщиков, по определенным причинам, подключались к одной и той же точке Wi-Fi, в то время как остальные точки оставались свободными.
Тестовые и стейджинговые сервера должны быть покрыты мониторингом не в меньшей степени чем продакшн. Наши разработчики всегда сверяют графики мониторинга до и после релиза новых фич, различных маркетинговых компаний и их эффекта на общую нагрузку системы.
Ну и конечно же не будем забывать про мониторинг мониторинга. В случае падения сервера мониторинга не исключены форс-мажорные ситуации, о которых вы не знаете, потому что сервер мониторинга недоступен. В нашем случае есть специально написанный сервис, который независимо от основного заббикса проверят состояние и доступность заббикс-серверов и заббикс-прокси.
