
Всем привет! Меня зовут Николай Первухин, я Senior Java Developer в Райффайзенбанке. В последнее время я активно занимаюсь BPM-системами Camunda и Zeebe (основа Camunda-cloud). Если вы, как и я, с ходу не можете ответить на вопрос, кто быстрее — Camunda или Zeebe, насколько, и в каких случаях они могут тормозить, — то вам будет очень интересно прочитать эту статью.
В этом материале я попытаюсь оценить производительность систем Camunda и Zeebe с различными параметрами, коснусь классических систем по workflow — Apache Camel и Spring Integration, а также постараюсь предложить гибридное решение для повышения производительности.
Часто со стороны бизнеса можно услышать вопрос, что будет, если поток данных возрастет — справится ли наша система с этим. Вот и мне стало интересно, так что давайте немного поэкспериментируем на простом workflow: сделаем несколько действий и осуществим rest-вызов в каждом из них.
Вызывать будем статический тестовый файл test.json с содержимым: {}, который будет выдавать локальный nginx.
Немного об оборудовании: в моем распоряжении 4х ядерный Intel(R) Core(TM) i7-4770K CPU @ 3.50GHz, SSD диск и 24Gb памяти.
Итак, наши кандидаты:
Apache-camel — чемпион, проверенный временем
Признаюсь, это вообще не BPM. Но этот фреймворк настолько популярен, что стоит начать рассказ для человека, который не в теме BPMN, и его глаза вспыхивают пониманием — это же про Apache Camel! Действительно, задачу он решает похожую, поэтому давайте рассмотрим его с должным уважением.
Вот воркфлоу, который будем исполнять:
camelContext.addRoutes(new RouteBuilder() {
@Override
public void configure() throws Exception {
from("direct:tuneBPMN")
.bean("restExecutorService", "doRestRequest")
.bean("restExecutorService", "doRestRequest");
}
});Будем производить тестовый REST-вызов:
public void doRestRequest() {
final String result = restTemplate.getForObject(restRequestUrl + "?v=" + random.nextLong(), String.class);
logger.debug(result);
}
random.nextLong поможет препятствовать кешированию запросов. Ссылка проекта на gitlab
Spring Integration — часть большого брата
С ростом популярности Spring / Spring boot значимость Apache Camel снижается в сторону Spring Integration. Фреймворк тоже не BPM, но нам важны референтные значения для сравнения производительности. Для лучшей схожести с BPMN мы будем использовать описание воркфлоу (контекста) в виде xml, сделаем два канала и два сервис активатора:
<int:channel id="channelStart"/>
<int:channel id="channelAfterRestA"/>
<int:gateway default-request-channel="channelStart"
service-interface="net.pervukhin.purespringintegration.integrationcomponent.StarterGateway"/>
<int:service-activator
input-channel="channelStart"
output-channel="channelAfterRestA"
ref="restServiceActivator"
method="restA"/>
<int:service-activator
input-channel="channelAfterRestA"
ref="restServiceActivator"
method="restB"/>Camunda — надежный, как DasAuto
Пока рассмотрим самый быстрый вариант Camunda — мы отключим историю вообще, и будем использовать in-memory h2 базу данных.
Наш «сложный» процесс выглядит так:

Код для RestDelegate достаточно прост:
@Component
public class RestDelegate implements JavaDelegate {
private static final Logger logger = LoggerFactory.getLogger(RestDelegate.class);
private static final Random random = new Random();
...
@Override
public void execute(DelegateExecution execution) throws Exception {
final String result = restTemplate.getForObject(restRequestUrl + "?v=" + random.nextLong(), String.class);
logger.debug(result);
}
}
Ссылка проекта на gitlab. Для работы активируем профиль h2mem.
Zeebe — движок для высоких нагрузок
Zeebe появился относительно недавно: первый стабильный релиз, пригодный для использования, вышел в 2019. В отличие от Camunda, он использует не транзакционную, а распределенную базу rockdb под капотом.
По заявлению Бернда Рюкера, увеличение производительности в ней достигается путем создания дополнительных инстансов в кластере. Интересное было выступление, кстати.
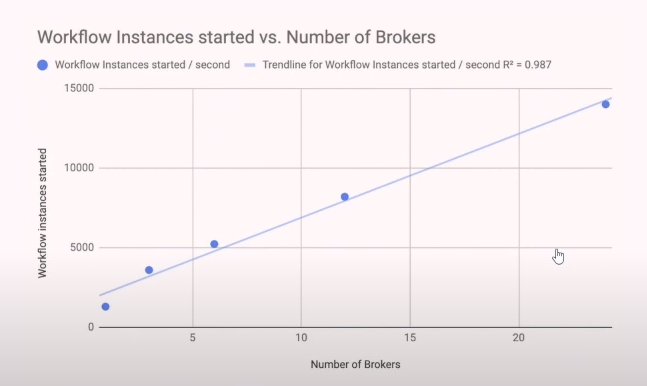
Судя по графику, при одном инcтансе результаты должны быть в пределе 1 тыс. процессов в секунду.
Будем использовать данный процесс:
Наш воркер:
@ZeebeWorker(type = "restJob")
public void handleJob(JobClient jobClient, ActivatedJob activatedJob) {
final String result = restTemplate.getForObject(restRequestUrl + "?v=" + random.nextLong(), String.class);
logger.debug(result);
..
jobClient.newCompleteCommand(activatedJob.getKey())
.variables(new HashMap<>())
.send()
.join();
}
Запуск инстанса будем производить через docker:
docker run -d --name zeebe -e ZEEBE_BROKER_CLUSTER_PARTITIONSCOUNT=24 -p 26500:26500 camunda/zeebeЕсли вам потребуется вынести папку с данными, используйте параметр:
-v ваша_локальная_папка_с_данными:/usr/local/zeebe/dataНебольшой тюнинг (в рамках 1 иснтанса):
ZEEBE_BROKER_CLUSTER_PARTITIONSCOUNT — число партиций кластера (по умолчанию это 1) определяет, на какое количество частей или папок разбивать rockdb для дальнейшей синхронизации. В зависимости от скорости работы SSD или жесткого диска, можно подобрать лучший параметр. В данном случае устанавливается 24, потому что дальнейшее увеличение дает скорее ухудшение.
При этом два дополнительных параметра не оказывают большую роль, так как процесс относительно простой:
ZEEBE_BROKER_THREADS_CPUTHREADCOUNT (2)— количество потоков на вычисления.
ZEEBE_BROKER_THREADS_IOTHREADCOUNT (2)— количество потоков для ввода/вывода.
Мы ставим их по умолчанию. Клиент для Zeebe с воркером можно найти на gitlab.
Даем нагрузку
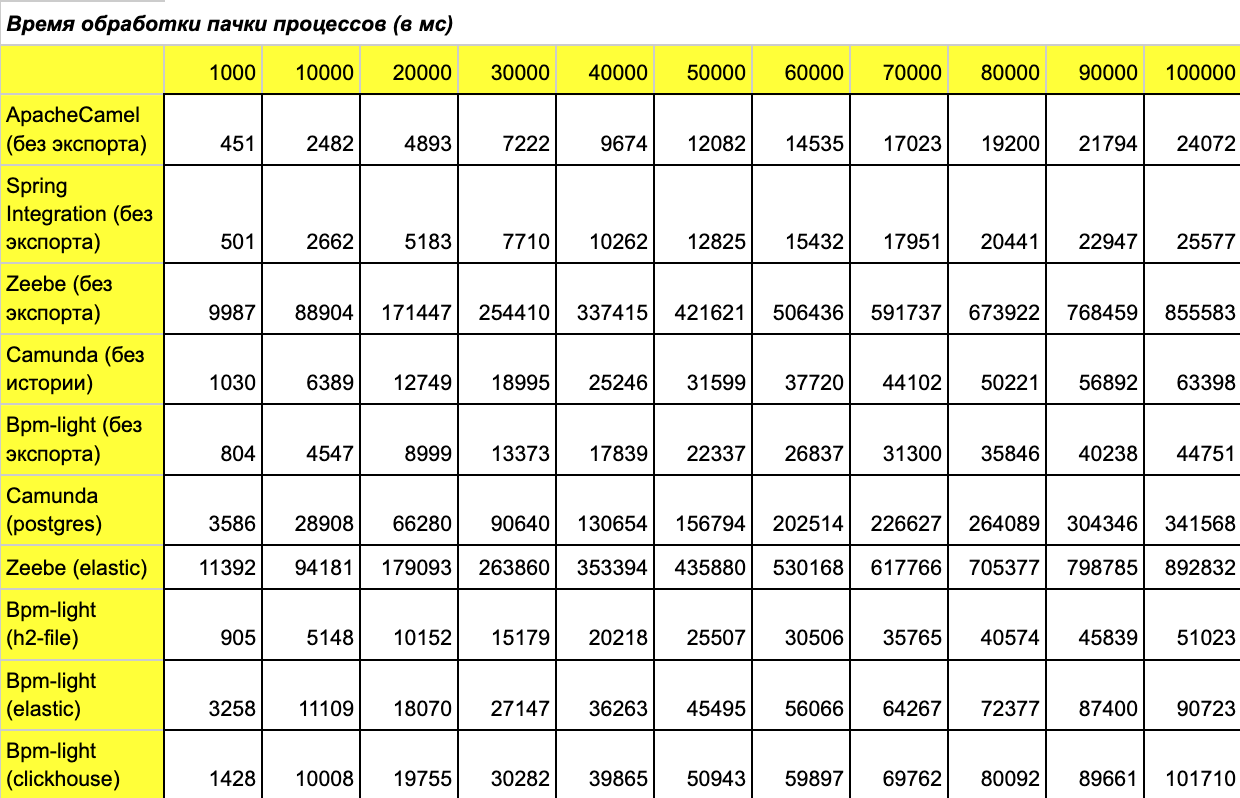
Для замера нагрузки будет произведен запуск 100 тыс. процессов, при этом с интервалом 10 тыс. мы планируем замерять время выполнения. Прошу простить меня за неточность, но начало отсчета будем фиксировать не с 0, а с 1 тыс. процессов. Это важно, чтобы оценить, насколько быстро происходит прогрев системы. Результат нагрузки:
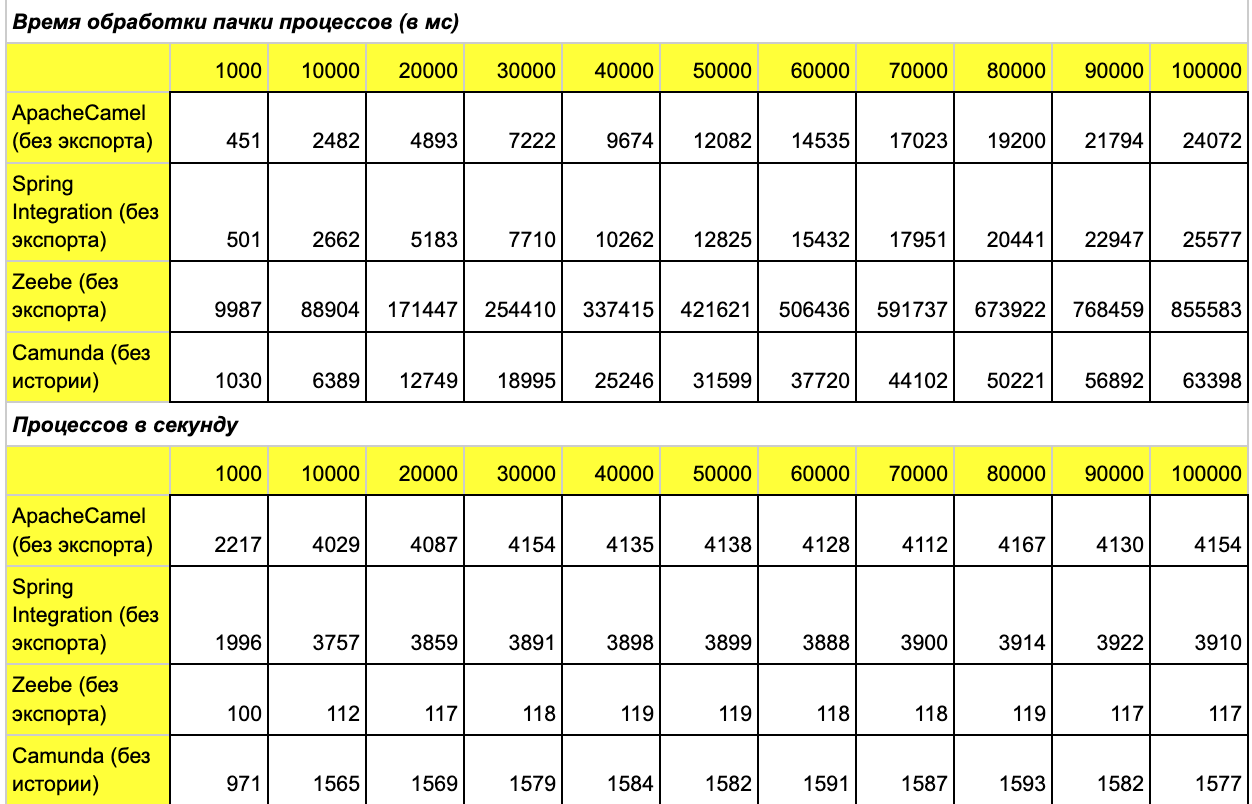

Объясню полученные результаты:
Apache Camel и Spring Integration вне конкуренции, когда сложность процесса небольшая и нет изменчивости. Так что +100 очков команде Apache Camel, они даже немного обошли Spring Integration. Здесь было важно показать, что условные 4,2 тыс. процессов — наилучший возможный результат на 1 инстансе.
Camunda без истории и in-memory показывает достаточно хорошую производительность.
Zeebe даже без экспорта на одном инстансе более чем скромен — как и ожидалось.
Все вышеописанные результаты получены при полном отсутствии логирования — это как раз тот случай, когда нам не требуется контролировать результаты.
Логирование, экспортирование
Теперь нам требуется посмотреть, как проходил процесс, какие таски запускались и какие были переменные. В этом случае мы должны включить логирование процесса — или экспортирование, говоря в терминах Zeebe.
Camunda
Camunda поддерживает транзакционные SQL-базы. Канонической для Camunda базой является PostgreSQL — это наиболее частый случай использования, которую будем использовать в нашем эксперименте.
Базу данных подключаем в виде готового докер контейнера, тут все стандартно:
docker run -d --name postgres -e POSTGRES_PASSWORD=postgres -p 5432:5432 postgresЕсли требуется вынести папку с данными, используйте параметр:
-v ваша_локальная_папка_с_данными:/var/lib/postgresql/dataДальше мы переключаем профиль в pure-camunda на PostgreSQL.
Zeebe
В Zeebe подключаем готовый экспортер для ElasticSearch. Данные из Elastic потом можно увидеть в Zeebe:Operate (аналог Camunda Cockpit). Подключаем ElasticSearch тоже через docker-контейнер. Для простоты мы будем использовать сеть рабочей машины, чтобы Zeebe и ElasticSearch могли общаться напрямую.
docker run -d --name elastic --network host -e "discovery.type=single-node" elasticsearch:7.14.2 Если требуется вынести папку с данными, используйте параметр:
-v ваша_локальная_папка_с_данными:/usr/share/elasticsearch/dataВ самом Zeebe подключаем стандартный экспортер в ElasticSearch:
docker run -d --name zeebe --network host -e
ZEEBE_BROKER_EXPORTERS_ELASTICSEARCH_CLASSNAME=io.camunda.zeebe.exporter.ElasticsearchExporter -e
ZEEBE_BROKER_EXPORTERS_ELASTICSEARCH_ARGS_URL=http://localhost:9200 -e
ZEEBE_BROKER_EXPORTERS_ELASTICSEARCH_ARGS_BULK_SIZE=1000 -e
ZEEBE_BROKER_CLUSTER_PARTITIONSCOUNT=24 camunda/zeebe
Из новых параметров среды:
ZEEBE_BROKER_EXPORTERS_ELASTICSEARCH_CLASSNAME— тип экспортераZEEBE_BROKER_EXPORTERS_ELASTICSEARCH_ARGS_URL— адрес ElasticSearchZEEBE_BROKER_EXPORTERS_ELASTICSEARCH_ARGS_BULK_SIZE— размер пачки экспортируемых сообщений
А вот и результаты:
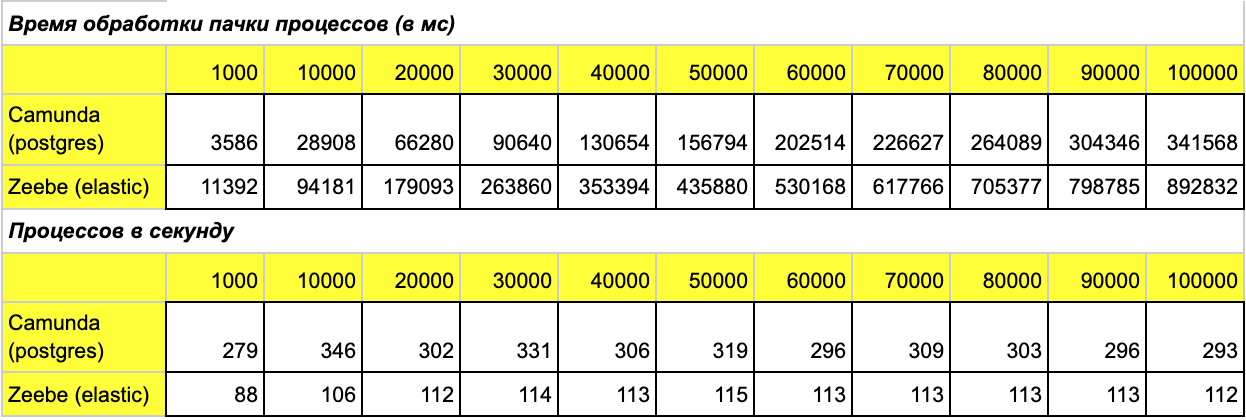

Объясню полученные результаты:
Результат с Camunda изменился сильно, ухудшение почти в три раза. Более того, идет деградирование с увеличением данных в базе. Это связано, в основном, с ребилдом индексов, которые Camunda активно использует.
А вот у Zeebe значения почти не изменились — экспорт оказал минимальное влияние на время исполнения. Результат скромный, но стабильный.
Экспортируемые данные накапливаются и отправляются в систему хранения пачками по таймеру, либо по мере накопления такой пачки. Здесь достигается двойной эффект:
Экспорт вынесен отдельно от процессинга. Если данные вдруг перестанут экспортироваться — процессинг все равно идет своим чередом.
Добавление данных большими объемами (batch mode) почти в любых системах хранения эффективнее, чем по одной записи.
Создание гибрида bpm-light
Давайте подумаем, как создать гибридную систему, чтобы она была:
Такая же масштабируемая, как Zeebe
Быстрая как in-memory Camunda. Лучше быстрее, чем Apache Camel, но это мечты :)
С возможностью экспорта данных, чтобы визуально было видно, как отработал процесс.
Помните, как в фильме «Марсианин» снимали с ракеты все ненужное?

Избавляемся от тяжелых компонентов, оставляем только движок Camunda.
В состав pom включаем компоненты:
Spring boot, spring data и web-services
Только модуль движка Camunda:
docker run -d --name zeebe --network host -e
ZEEBE_BROKER_EXPORTERS_ELASTICSEARCH_CLASSNAME=io.camunda.zeebe.exporter.ElasticsearchExporter -e
ZEEBE_BROKER_EXPORTERS_ELASTICSEARCH_ARGS_URL=http://localhost:9200 -e
ZEEBE_BROKER_EXPORTERS_ELASTICSEARCH_ARGS_BULK_SIZE=1000 -e
ZEEBE_BROKER_CLUSTER_PARTITIONSCOUNT=24 camunda/zeebeДрайверы баз данных h2, clickhouse
Средство развертывания базы flyway
Из интересного (надеюсь):
Конфигурация движка Camunda. Используем StandaloneInMemProcessEngineConfiguration — думаю, название говорит само за себя:
@Bean
public ProcessEngine processEngine(@Autowired RestDelegate restDelegate,
@Autowired ExporterRegistryService exporterRegistryService) {
final StandaloneInMemProcessEngineConfiguration config = new StandaloneInMemProcessEngineConfiguration();
// используем полное логирование процесса, full — включая переменные
config.setHistory("full");
config.setDatabaseSchemaUpdate("create");
// отключаем сбор метрик
config.setMetricsEnabled(false);
config.setDbMetricsReporterActivate(false);
// Добавление бина делегата
config.setBeans(new HashMap<>());
config.getBeans().put("restDelegate", restDelegate);
// Обработчик событий процесса (старт процесса, этапы процесса, конец процесса, изменение переменных и тп)
config.setHistoryEventHandler(new CustomHistoryHandler(exporterRegistryService));
config.setIdGenerator(new StrongUuidGenerator());
return config.buildProcessEngine();
}
Разрабатываем свой собственный регистратор исторических событий CustomHistoryHandler:
@Override
public void handleEvent(HistoryEvent historyEvent) {
if (historyEvent.getClass().equals(HistoricProcessInstanceEventEntity.class)) {
final HistoricProcessInstanceEventEntity event = (HistoricProcessInstanceEventEntity) historyEvent;
// логируем начало и окончание процесса
if ("start".equals(event.getEventType())) {
exporterRegistryService.registerStartProcess(event.getStartTime(), event.getProcessDefinitionKey(),
event.getProcessDefinitionId(), event.getBusinessKey(), event.getProcessInstanceId(),
event.getSuperProcessInstanceId());
return;
}
if ("end".equals(event.getEventType())) {
exporterRegistryService.registerEndProcess(event.getEndTime(), event.getProcessDefinitionKey(),
event.getProcessDefinitionId(), event.getBusinessKey(), event.getProcessInstanceId(),
event.getSuperProcessInstanceId());
return;
}
}
Аналогично перехватываем начало и завершение задач в процессе, а также создание и изменение переменных. Здесь очень важным моментом является, что метод полностью подменяет сохранение исторических данных — это значит, что в памяти исторические данные мы больше не храним.
Идею с экспортером данных честно позаимствуем у Zeebe. Будем накапливать события в LinkedBlockingQueue.
// Накапливаем события в LinkedBlockingQueue по каждому типу событий
public void export(ExportRecordType type, ExportRecord exportRecord) {
if (enabled) {
if (! this.exportLog.containsKey(type)) {
this.exportLog.put(type, new LinkedBlockingQueue<>());
}
this.exportLog.get(type).add(exportRecord);
// в случае переполнения пачки, мы запускаем запись в систему хранения
if (this.exportLog.get(type).size() >= this.batchSize) {
flush(type);
}
}
}
// Полная запись всех накопленных событий в систему хранения
private void flushBatchTask() {
fullFlush();
scheduleFlushBatchTask();
}
private void fullFlush() {
exportLog.entrySet().stream()
.forEach( x -> {
if (x.getValue() != null && ! x.getValue().isEmpty()) {
flush(x.getKey());
}
});
}
// Создаем отложенное событие запуска по таймеру
private void scheduleFlushBatchTask() {
executor.schedule(this::flushBatchTask, interval, TimeUnit.SECONDS);
}
// Запускаем непосредственный слив данных в систему хранения
private void flush(ExportRecordType type) {
if (! isRunning) {
isRunning = true;
exporter.export(type, exportLog.get(type));
isRunning = false;
} else {
logger.debug("Слишком большая нагрузка, экспорт не успевает");
}
}
Метод *.export вынесен как интерфейс для поддержки различных систем хранения. Так было сделано в Zeebe, мы же просто позаимствуем этот принцип. Переключать систему можно профилем spring-boot.
Для эксперимента я сделал три различных экспортера:
В каноническую базу данных H2. На ней легко тестировать, не требует установки
В ElasticSearch. Наверное, это один из самых быстрых индексаторов json-данных, который можно рассматривать как быстрое и масштабируемое хранилище
В Clickhouse. Эта база данных прекрасно себя зарекомендовала при быстрой вставке больших массивов данных, по описанию — то, что нам нужно.
Рассмотрим на примере h2:
@Override
public void export(ExportRecordType exportRecordType, BlockingQueue<ExportRecord> records) {
..
// определяем команду sql для вставки или изменений данных и набор параметров
switch (exportRecordType) {
..
case PROCESS:
queryString = "insert into PROCESS "
+ "(CREATED, PROCESSDEFINITIONKEY, PROCESSDEFINITIONID, BUSINESSKEY, PROCESSINSTANCEID, "
+ "SUPERPROCESSINSTANCEID, LIFECYCLETYPE,ENDDATE) values ";
valuesString = "(?,?,?,?,?,?,?,?)";
break;
..
}
// вычитываем данные из LinkedBlockingQueue и создаем один большой запрос с параметрами
while (! records.isEmpty()) {
final ExportRecord recordElement = records.poll();
itemsAdded++;
switch (exportRecordType) {
..
case PROCESS:
Process process = (Process) recordElement;
parameters.add(process.getDate());
parameters.add(process.getProcessDefinitionKey());
parameters.add(process.getProcessDefinitionId());
parameters.add(process.getBusinessKey());
parameters.add(process.getProcessInstanceId());
parameters.add(process.getSuperProcessInstanceId());
parameters.add(process.getLifecycleType().name());
parameters.add(process.getEndDate());
break;
..
}
}
if (itemsAdded > 0 && ! parameters.isEmpty()) {
String query = queryString + (valuesString + ",").repeat(itemsAdded);
query = query.substring(0, query.length() - 1);
execute(query, parameters);
}
}
Сам же метод execute добавляет параметры в jdbc-запрос в зависимости от типа и выполняет запрос:
private void execute(String query, List<Object> parameters) {
try (PreparedStatement statement = databaseConnectionService.getConnection()
.prepareStatement(query)) {
for (int i=0; i<parameters.size(); i++) {
if (parameters.get(i) instanceof String) {
statement.setString(i+1, String.valueOf(parameters.get(i)));
}
if (parameters.get(i) instanceof Long) {
statement.setLong(i+1, (Long) parameters.get(i));
}
..
if (parameters.get(i) == null) {
statement.setString(i+1, null);
}
}
// выполняем запрос
statement.execute();
} catch (Exception ex) {
logger.error(ex.getMessage(), ex);
}
}
Фронт у системы тоже должен быть. Для этого создадим rest-api и различные методы извлечения данных для каждой системы хранения.
Фронт сделан минималистично, он позволяет:
Просматривать и устанавливать новые bpmn-процессы
Смотреть активные и завершенные инстансы
Видеть путь прохождения инстанса, все переменные и тайминги по каждой из задач.
Проект фронта использует jsf primefaces и bpmn.io для рендеринга самих процессов.
Если интересно, то можно ознакомиться с исходным кодом здесь:
Вернемся к нагрузке и дадим такую же нагрузку на этот проект для каждого из методов хранения:
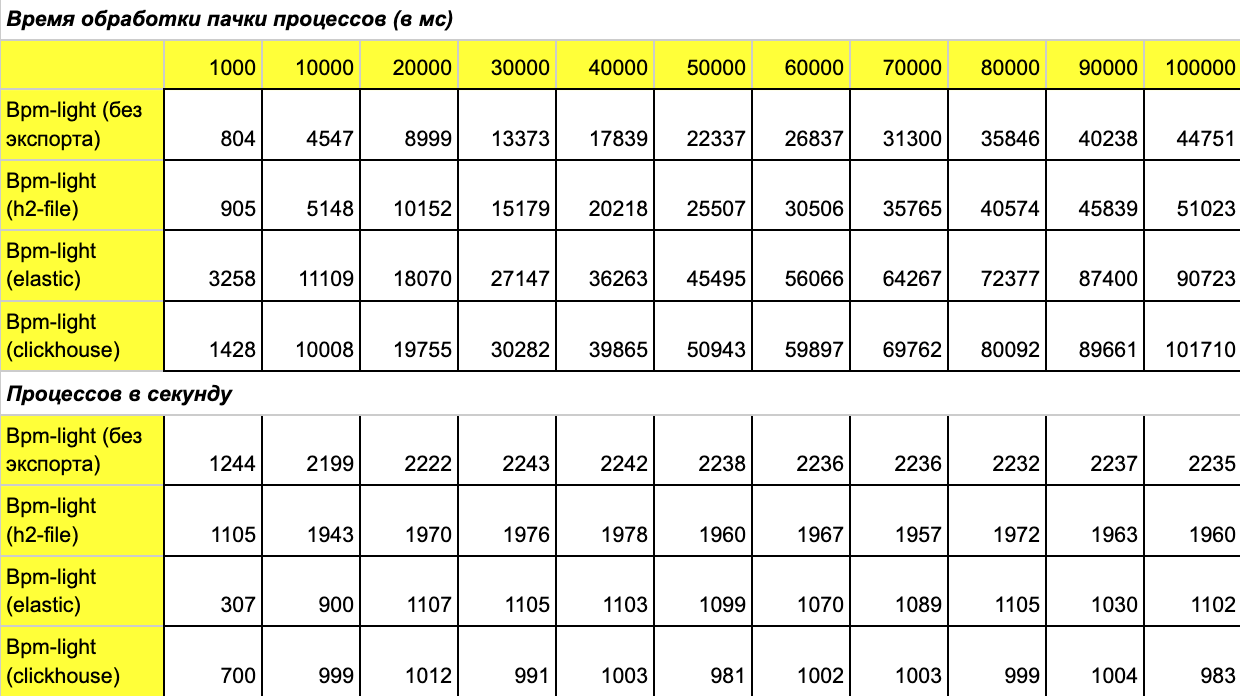

Результаты:
На удивление прекрасно показал себя Elastic, неожиданно обогнав Clickhouse. Результаты h2 тоже впечатлили бы, если бы не одно большое но: без индексов на такой базе выборки начинают тупить уже после 5 тыс. процессов, да и фронт уже перестает отвечать. В общем, это хорошая база для тестов, но не для реальной жизни.
Важной отличительной частью такого подхода является то, что такой гибрид можно запустить в большом количестве инстансов и поставить за распределителем нагрузки (eureka, nginx и тп). Получится, что вы сможете без каких-либо ограничений горизонтально масштабировать решение.
Главный минус — неперсистентность активных инстансов. Сами процессы идут в оперативной памяти. В случае аварийной перезагрузки исторические данные по работающим экземплярам могут не успеть экспортироваться в хранилище данных.
Итоги


Итак, пришло время ответить на вопросы в начале статьи:
Кто быстрее — Camunda или Zeebe?
При равных условиях выигрывает Camunda. Но при марафоне с нарастанием базы рано или поздно Camunda упирается в деградацию и начинает замедляться. Zeebe из коробки с дефолтными настройками показывает очень скромные результаты, зато практически не имеет пределов для масштабирования.
А насколько, и в каких случаях?
При равных условиях в виде отсутствия экспорта и истории, Camunda почти в 15 раз быстрее, чем Zeebe. При подключении истории производительность Camunda резко падает — почти в три раза, а эффективный метод экспортирования данных у Zeebe такой просадки не дает.
Для совсем небольших процессов без необходимости хранить историю шагов даже Camunda не является целесообразной. В этих случаях лучше выбрать Apache Camel или Spring Integration — такое решение получится как минимум в два раза быстрее.
Zeebe нужна для совсем крупных задач и высоконагруженных процессов (коротких и нагруженных вычислениями), чтобы быть экономически целесообразным. Для обеспечения высокой производительности требуется кластер с большим количеством инстансов и быстрыми дисками.
В случае, когда бюджет ограничен, но есть желание получить скорость и масштабируемость, лучше создать аналогичный гибрид — отучить Camunda от использования классической базы данных.
За счет чего может тормозить?
Camunda тормозит из-за своей архитектуры — транзакционная запись каждого действия в базу данных. Это крутая фича, она позволяет при возникновении ошибок процессу откатываться на нужный этап, но это совсем не про hi-load.
Zeebe тормозит из-за своего ядра — распределенной базы данных rockdb. Для нее нужны очень быстрые диски и большое количество партиций и инстансов.
Коллеги, а как вы оптимизируете производительность Camunda и Zeebe? Поделитесь в комментариях!
