
Если вы администрируете виртуальную инфраструктуру на базе VMware vSphere (или любого другого стека технологий), то наверняка часто слышите от пользователей жалобы: «Виртуальная машина работает медленно!». В этом цикле статей разберу метрики производительности и расскажу, что и почему «тормозит» и как сделать так, чтобы не «тормозило».
Буду рассматривать следующие аспекты производительности виртуальных машин:
- CPU,
- RAM,
- DISK,
- Network.
Начну с CPU.
Для анализа производительности нам понадобятся:
- vCenter Performance Counters – счетчики производительности, графики которых можно посмотреть через vSphere Client. Информация по данным счетчикам доступна в любой версии клиента (“толстый” клиент на C#, web-клиент на Flex и web-клиент на HTML5). В данных статьях мы будем использовать скриншоты из С#-клиента, только потому, что они лучше смотрятся в миниатюре:)
- ESXTOP – утилита, которая запускается из командной строки ESXi. С ее помощью можно получить значения счетчиков производительности в реальном времени или выгрузить эти значения за определенный период в .csv файл для дальнейшего анализа. Далее расскажу про этот инструмент подробнее и приведу несколько полезных ссылок на документацию и статьи по теме.
Немного теории

В ESXi за работу каждого vCPU (ядра виртуальной машины) отвечает отдельный процесс – world в терминологии VMware. Также есть служебные процессы, но с точки зрения анализа производительности ВМ они менее интересны.
Процесс в ESXi может находиться в одном из четырех состояний:
- Run – процесс выполняет какую-то полезную работу.
- Wait – процесс не выполняет никакой работы (idle) либо ждет ввода/вывода.
- Costop – состояние, которое возникает в многоядерных виртуальных машинах. Оно возникает, когда планировщик CPU гипервизора (ESXi CPU Scheduler) не может запланировать одновременное исполнение на физических ядрах сервера всех активных ядер виртуальной машины. В физическом мире все ядра процессора работают параллельно, гостевая ОС внутри ВМ рассчитывает на аналогичное поведение, поэтому гипервизору приходится замедлять ядра ВМ, у которых есть возможность закончить такт быстрее. В современных версиях ESXi планировщик CPU использует механизм, который называется relaxed co-scheduling: гипервизор считает разрыв между самым «быстрым» и самым “медленным" ядром виртуальной машины (skew). Если разрыв превышает определенный порог, «быстрое» ядро переходит в состояние costop. Если ядра ВМ проводят много времени в этом состоянии, это может вызвать проблемы с производительностью.
- Ready – процесс переходит в данное состояние, когда у гипервизора нет возможности выделить ресурсы для его исполнения. Высокие значения ready могут вызвать проблемы с производительностью ВМ.
Основные счетчики производительности CPU виртуальной машины
CPU Usage, %. Показывает процент использования CPU за заданный период.

Как анализировать? Если ВМ стабильно использует CPU на 90% или есть пики до 100%, то у нас проблемы. Проблемы могут выражаться не только в «медленной» работе приложения внутри ВМ, но и в недоступности ВМ по сети. Если система мониторинга показывает, что ВМ периодически отваливается, обратите внимание на пики на графике CPU Usage.
Есть стандартный Аlarm, который показывает загрузку CPU виртуальной машины:
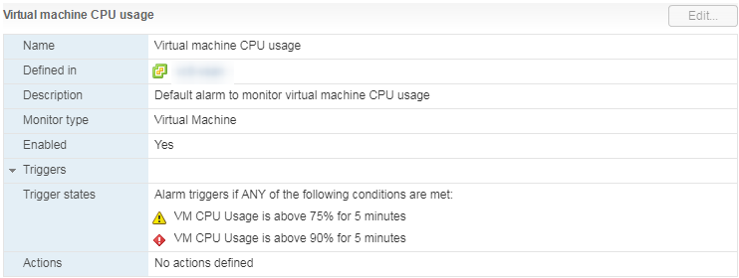
Что делать? Если у ВМ постоянно зашкаливает CPU Usage, то можно задуматься об увеличении количества vCPU (к сожалению, это не всегда помогает) или переносе ВМ на сервер с более производительными процессорами.
CPU Usage in Mhz
В графиках на vCenter Usage в % можно посмотреть только по всей виртуальной машине, графиков по отдельным ядрам нет (в Esxtop значения в % по ядрам есть). По каждому ядру можно посмотреть Usage in MHz.
Как анализировать? Бывает, что приложение не оптимизировано под многоядерную архитектуру: использует на 100% только одно ядро, а остальные простаивают без нагрузки. Например, при дефолтных настройках бэкапа MS SQL запускает процесс только на одном ядре. В итоге резервное копирование тормозит не из-за медленной скорости дисков (именно на это изначально пожаловался пользователь), а из-за того, что не справляется процессор. Проблема была решена изменением параметров: резервное копирование стало запускаться параллельно в несколько файлов (соответственно, в несколько процессов).

Пример неравномерной нагрузки ядер.
Также бывает ситуация (как на графике выше), когда ядра нагружены неравномерно и на некоторых из них есть пики в 100%. Как и при загрузке только одного ядра, alarm по CPU Usage не сработает (он по всей ВМ), но проблемы с производительностью будут.
Что делать? Если ПО в виртуальной машине нагружает ядра неравномерно (использует только одно ядро или часть ядер), нет смысла увеличивать их количество. В таком случае лучше переместить ВМ на сервер с более производительными процессорами.
Также можно попробовать проверить настройки энергопотребления в BIOS сервера. Многие администраторы включают в BIOS режим High Performance и тем самым отключают технологии энергосбережения C-states и P-states. В современных процессорах Intel используется технология Turbo Boost, которая увеличивает частоту отдельных ядер процессора за счет других ядер. Но она работает только при включенных технологиях энергосбережения. Если мы их отключаем, то процессор не может уменьшить энергопотребление ядер, которые не нагружены.
VMware рекомендует не отключать технологии энергосбережения на серверах, а выбирать режимы, которые максимально отдают управление энергопотреблением гипервизору. При этом в настройках энергопотребления гипервизора нужно выбрать High Performance.
Если у вас в инфраструктуре отдельные ВМ (или ядра ВМ) требуют повышенную частоту CPU, корректная настройка энергопотребления может значительно улучшить их производительность.

CPU Ready (Readiness)
Если ядро ВМ (vCPU) находится в состоянии Ready, оно не выполняет полезную работу. Такое состояние возникает, когда гипервизор не находит свободное физическое ядро, на которое можно назначить процесс vCPU виртуальной машины.
Как анализировать? Обычно если ядра виртуальной машины находятся в состоянии Ready больше 10% времени, то вы заметите проблемы с производительностью. Проще говоря, больше 10% времени ВМ ждет доступности физических ресурсов.
В vCenter можно посмотреть 2 счетчика, связанных с CPU Ready:
- Readiness,
- Ready.
Значения обоих счетчиков можно посмотреть как по всей ВМ, так и по отдельным ядрам.
Readiness показывает значение сразу в процентах, но только в Real-time (данные за последний час, интервал измерений 20 секунд). Этот счетчик лучше использовать только для поиска проблем «по горячим следам».
Значения счетчика Ready можно посмотреть также в исторической перспективе. Это полезно для установления закономерностей и для более глубокого анализа проблемы. Например, если у виртуальной машины начинаются проблемы с производительностью в какое-то определенное время, можно сопоставить интервалы повешенного значения CPU Ready с общей нагрузкой на сервер, где данная ВМ работает, и принять меры по снижению нагрузки (если DRS не справился).
Ready в отличие от Readiness показывается не в процентах, а миллисекундах. Это счетчик типа Summation, то есть он показывает, сколько времени за период измерения ядро ВМ находилось в состоянии Ready. Перевести данное значение в проценты можно по несложной формуле:
(CPU ready summation value / (chart default update interval in seconds * 1000)) * 100 = CPU ready %
Например, для ВМ на графике ниже пиковое значение Ready на всю виртуальную машину получится следующим:

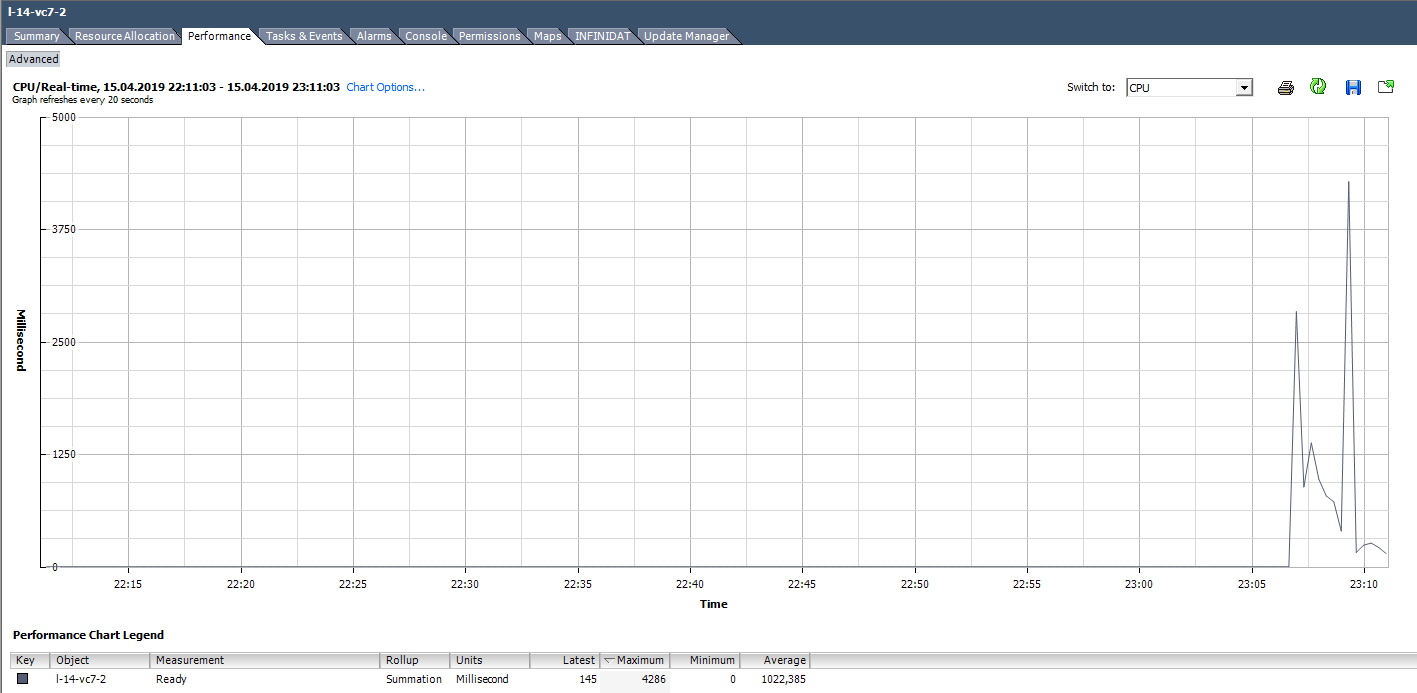
При подсчете значения Ready в процентах стоит обращать внимание на два момента:
- Значение Ready по всей ВМ – это сумма Ready по ядрам.
- Интервал измерения. Для Real-time – это 20 секунд, а, например, на дневных графиках – это 300 секунд.
При активном траблшутинге эти простые моменты можно легко упустить и потратить ценное время на решение несуществующих проблем.
Рассчитаем Ready на основе данных из графика ниже. (324474/(20*1000))*100 = 1622% на всю ВМ. Если смотреть по ядрам получится уже не так страшно: 1622/64 = 25% на ядро. В данном случае обнаружить подвох довольно просто: значение Ready нереалистичное. Но если речь идет о 10–20% на всю ВМ с несколькими ядрами, то по каждому ядру значение может быть в пределах нормы.

Что делать? Высокое значение Ready говорит о том, что серверу не хватает ресурсов процессора для нормальной работы виртуальных машин. В такой ситуации остается только уменьшить переподписку по процессору (vCPU:pCPU). Очевидно, этого можно добиться, уменьшив параметры существующих ВМ или путем миграции части ВМ на другие серверы.
Co-stop
Как анализировать? Данный счетчик также имеет тип Summation и переводится в проценты аналогично Ready:
(CPU co-stop summation value / (chart default update interval in seconds * 1000)) * 100 = CPU co-stop %
Здесь также нужно обращать внимание на количество ядер на ВМ и на интервал измерения.
В состоянии сostop ядро не выполняет полезную работу. При правильном подборе размера ВМ и нормальной нагрузке на сервер счетчик со-stop должен быть близок к нулю.

В данном случае нагрузка явно ненормальная:)
Что делать? Если на одном гипервизоре работают несколько ВМ с большим количеством ядер и есть переподписка по CPU, то счетчик co-stop может вырасти, что приведет к проблемам с производительностью данных ВМ.
Также co-stop вырастет, если для активных ядер одной ВМ используются треды на одном физическом ядре сервера со включенным hyper-treading. Такая ситуация может возникнуть, например, если у ВМ больше ядер, чем физически есть на сервере, где она работает, или если для ВМ включена настройка «preferHT». Про эту настройку можно прочитать здесь.
Чтобы избежать проблем с производительностью ВМ из-за высокого сo-stop, выбирайте размер ВМ в соответствии с рекомендациями производителя ПО, которое работает на этой ВМ, и с возможностями физического сервера, где работает ВМ.
Не добавляйте ядра про запас, это может вызвать проблемы с производительностью не только самой ВМ, но и ее соседей по серверу.
Другие полезные метрики CPU
Run – сколько времени (мс) за период измерения vCPU находился в состоянии RUN, то есть собственно выполнял полезную работу.
Idle – сколько времени (мс) за период измерения vCPU находился в состоянии бездействия. Высокие значения Idle – это не проблема, просто vCPU было «нечего делать».
Wait – сколько времени (мс) за период измерения vCPU находился в состоянии Wait. Так как в данный счетчик включается IDLE, высокие значения Wait также не говорят о наличии проблемы. А вот если при высоком Wait IDLE низкий, значит ВМ ждала завершения операций ввода/вывода, а это, в свою очередь, может говорить о наличии проблемы с производительностью жесткого диска или каких-либо виртуальных устройств ВМ.
Max limited – сколько времени (мс) за период измерения vCPU находился в состоянии Ready из-за установленного лимита по ресурсам. Если производительность необъяснимо низкая, то полезно проверить значение данного счетчика и лимит по CPU в настройках ВМ. У ВМ действительно могут оказаться выставлены лимиты, о которых вы не знаете. Например, так происходит, когда ВМ была склонирована из шаблона, на котором был установлен лимит по CPU.
Swap wait – сколько времени за период измерения vCPU ждал операции с VMkernel Swap. Если значения данного счетчика выше нуля, то у ВМ точно есть проблемы с производительностью. Подробнее про SWAP поговорим в статье про счетчики оперативной памяти.
ESXTOP
Если счетчики производительности в vCenter хороши для анализа исторических данных, то оперативный анализ проблемы лучше производить в ESXTOP. Здесь все значения представлены в готовом виде (не нужно ничего переводить), а минимальный период измерения 2 секунды.
Экран ESXTOP по CPU вызывается клавишей «c» и выглядит следующим образом:

Для удобства можно оставить только процессы виртуальных машин, нажав Shift-V.
Чтобы посмотреть метрики по отдельным ядрам ВМ, нажмите «e» и вбейте GID интересующей ВМ (30919 на скриншоте ниже):
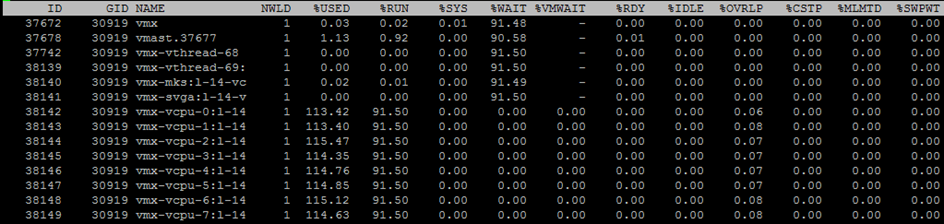
Кратко пройдусь по столбцам, которые представлены по умолчанию. Дополнительные столбцы можно добавить, нажав «f».
NWLD (Number of Worlds) – количество процессов в группе. Чтобы раскрыть группу и увидеть метрики для каждого процесса (например, для каждого ядра многоядерной ВМ), нажмите “e”. Если в группе больше одного процесса, то значения метрик для группы равны сумме метрик для отдельных процессов.
%USED – сколько циклов CPU сервера использует процесс или группа процессов.
%RUN – сколько времени за период измерения процесс находился в состоянии RUN, т.е. выполнял полезную работу. Отличается от %USED тем, что не учитывает hyper-threading, frequency scaling и время, затраченное на системные задачи (%SYS).
%SYS – время, затраченное на системные задачи, например: обработку прерываний, ввода/вывода, работу сети и пр. Значение может быть высоким, если на ВМ большой ввод/вывод.
%OVRLP – сколько времени физическое ядро, на котором выполняется процесс ВМ, потратило на задачи других процессов.
Данные метрики соотносятся между собой следующим образом:
%USED = %RUN + %SYS — %OVRLP.
Обычно метрика %USED является более информативной.
%WAIT – сколько времени за период измерения процесс находился в состоянии Wait. Включает IDLE.
%IDLE – сколько времени за период измерения процесс находился в состоянии IDLE.
%SWPWT – сколько времени за период измерения vCPU ждал операции с VMkernel Swap.
%VMWAIT – сколько времени за период измерения vCPU находилось в состояния ожидания события (обычно ввода/вывода). Аналогичного счетчика нет в vCenter. Высокие значения говорят о проблемах с вводом/выводом на ВМ.
%WAIT = %VMWAIT + %IDLE + %SWPWT.
Если ВМ не использует VMkernel Swap, то при анализе проблем с производительностью целесообразно смотреть на %VMWAIT, так как данная метрика не учитывает время, когда ВМ ничего не делала (%IDLE).
%RDY – сколько времени за период измерения процесс находился в состоянии Ready.
%CSTP – сколько времени за период измерения процесс находился в состоянии сostop.
%MLMTD – сколько времени за период измерения vCPU находился в состоянии Ready из-за установленного лимита по ресурсам.
%WAIT + %RDY + %CSTP + %RUN = 100% – ядро ВМ все время находится в каком-то из этих четырех состояний.
CPU на гипервизоре
В vCenter есть также счетчики производительности CPU для гипервизора, но они не представляют из себя ничего интересного – это просто сумма счетчиков по всем ВМ на сервере.
Удобнее всего смотреть состояние CPU на сервере на вкладке Summary:

Для сервера, как и для виртуальной машины, есть стандартный Alarm:
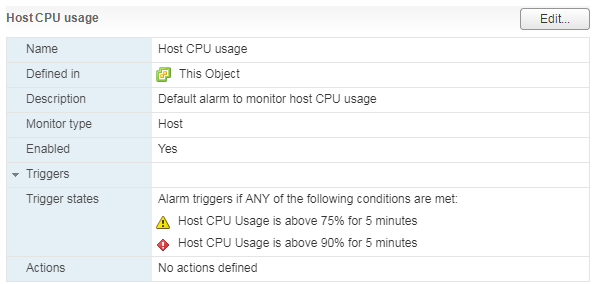
При высокой нагрузке на CPU сервера у ВМ, работающих на нем, начинаются проблемы с производительностью.
В ESXTOP данные о загрузке CPU сервера представлены в верхней части экрана. Помимо стандартного CPU load, который малоинформативен для гипервизоров, есть еще три метрики:
CORE UTIL(%) – загрузка ядра физического сервера. Данный счетчик показывает, сколько времени за период измерения ядро выполняло работу.
PCPU UTIL(%) – если включен hyper-threading, то на каждое физическое ядро приходится два потока (PCPU). Данная метрика показывает, сколько времени каждый поток выполнял работу.
PCPU USED(%) – то же, что PCPU UTIL(%), но учитывает frequency scaling (либо снижение частоты ядра в целях энергосбережения, либо повышение частоты ядра за счет технологии Turbo Boost) и hyper-threading.
PCPU_USED% = PCPU_UTIL% * эффективную частоту ядра / номинальную частоту ядра.

На этом скриншоте для некоторых ядер из-за работы Turbo Boost’а значение USED больше 100%, так как частота ядра выше номинальной.
Пара слов о том, как учитывается hyper-threading. Если процессы исполняются 100% времени на обоих потоках физического ядра сервера, при этом ядро работает на номинальной частоте, то:
- CORE UTIL для ядра будет 100%,
- PCPU UTIL для обоих потоков будет 100%,
- PCPU USED для обоих потоков будет 50%.
Если оба потока не работали 100% времени за период измерения, то в те периоды, когда потоки работали параллельно, PCPU USED для ядер делится пополам.
В ESXTOP также есть экран с параметрами энергопотребления CPU сервера. Здесь можно посмотреть, используются ли сервером технологии энергосбережения: C-states и P-states. Вызывается клавишей «p»:

Стандартные проблемы производительности CPU
Напоследок пробегусь по типичным причинам возникновения проблем с производительностью CPU ВМ и дам короткие советы их решению:
Не хватает тактовой частоты ядра. Если нет возможности перевести ВМ на более производительные ядра, можно попробовать изменить настройки энергопотребления, чтобы Turbo Boost работал эффективнее.
Неправильный сайзинг ВМ (слишком много/мало ядер). Если поставить мало ядер, будет высокая загрузка CPU ВМ. Если много, словите высокий co-stop.
Большая переподписка по CPU на сервере. Если на ВМ высокий Ready, снизьте переподписку по CPU.
Неправильная NUMA-топология на больших ВМ. NUMA-топология, которую видит ВМ (vNUMA), должна соответствовать NUMA-топологии сервера (pNUMA). Про диагностику и возможные варианты решения данной проблемы написано, например, в книге «VMware vSphere 6.5 Host Resources Deep Dive». Если не хотите углубляться и у вас нет лицензионных ограничений по ОС, установленной на ВМ, делайте на ВМ много виртуальных сокетов по одному ядру. Много не потеряете :)
На этом про CPU у меня все. Задавайте вопросы. В следующей части расскажу про оперативную память.
Полезные ссылки
http://virtual-red-dot.info/vm-cpu-counters-vsphere/
https://kb.vmware.com/kb/1017926
http://www.yellow-bricks.com/2012/07/17/why-is-wait-so-high/
https://communities.vmware.com/docs/DOC-9279
https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/performance/whats-new-vsphere65-perf.pdf
https://pages.rubrik.com/host-resources-deep-dive_request.html
https://kb.vmware.com/kb/1017926
http://www.yellow-bricks.com/2012/07/17/why-is-wait-so-high/
https://communities.vmware.com/docs/DOC-9279
https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/performance/whats-new-vsphere65-perf.pdf
https://pages.rubrik.com/host-resources-deep-dive_request.html
