
Материал, перевод которого мы сегодня публикуем, посвящён особенностям сетевого взаимодействия подов Kubernetes. Он предназначен для тех, у кого уже есть некоторый опыт работы с Kubernetes. Если вы пока не очень хорошо разбираетесь в Kubernetes, то вам, вероятно, прежде чем читать этот материал, полезно будет взглянуть на это руководство по Kubernetes, где работа с данной платформой рассматривается в расчёте на начинающих.

Что такое под (pod) Kubernetes? Под — это сущность, которая состоит из одного или нескольких контейнеров, размещённых на одном хосте и настроенных на совместное использование ресурсов сетевого стека и других ресурсов наподобие томов. Поды — это базовые строительные блоки, из которых построены приложения, работающие на платформе Kubernetes. Поды совместно используют сетевой стек. На практике это означает, что все контейнеры, входящие в состав пода, могут взаимодействовать друг с другом через

Контейнер Docker, запущенный на локальной машине
Если рассмотреть эту схему сверху вниз, то окажется, что здесь имеется физический сетевой интерфейс
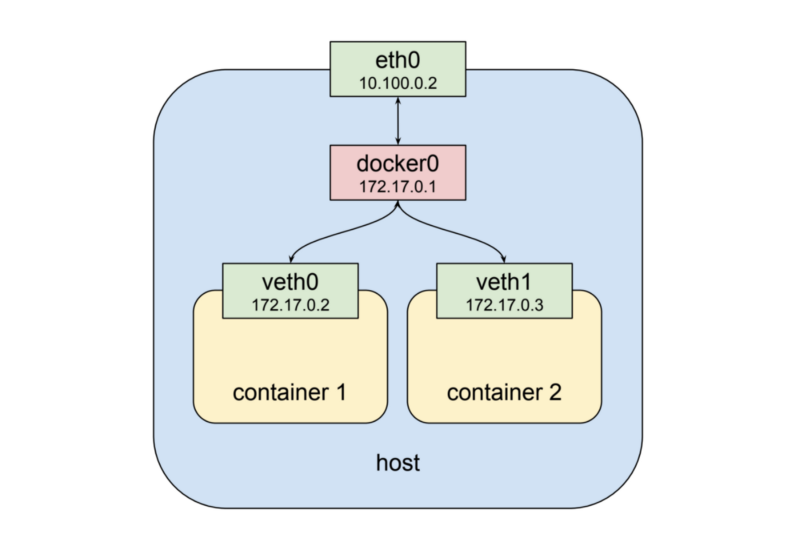
Два контейнера Docker, запущенные на локальной машине
Как можно видеть на вышеприведённой схеме, второму контейнеру назначается новый виртуальный сетевой интерфейс
Всё это хорошо, но это не описывает пока то, что мы, в применении к подам Kubernetes, называем «разделяемым сетевым стеком». К счастью, пространства имён отличаются большой гибкостью. Docker может запустить контейнер, и, вместо того, чтобы создавать для него новый виртуальный сетевой интерфейс, сделать так, чтобы он использовал бы, совместно с другими контейнерами, существующий интерфейс. При таком подходе нам придётся изменить вышеприведённую схему так, как показано ниже.
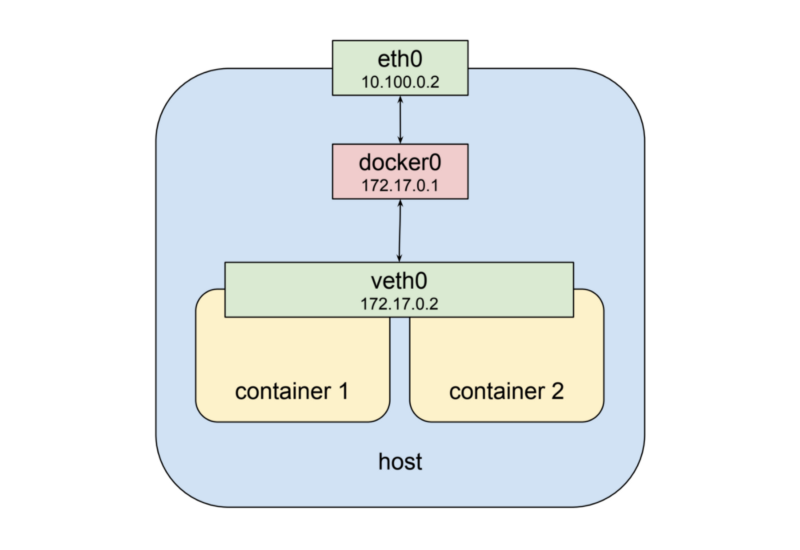
Контейнеры используют общий сетевой интерфейс
Теперь второй контейнер взаимодействует с уже существующим интерфейсом
Kubernetes реализует этот паттерн, создавая для каждого пода специальный контейнер, единственной целью которого является предоставление сетевого интерфейса для других контейнеров пода. Если подключиться к узлу кластера Kubernetes, которому назначен конкретный под, по

Контейнеры в гипотетическом поде
Один под, полный контейнеров, это строительный блок некоей системы, но пока ещё не сама эта система. В основе архитектуры Kubernetes лежит требование, в соответствии с которым у подов должна быть возможность взаимодействовать с другими подами вне зависимости от того, выполняются ли они на одном и том же компьютере или на разных машинах. Для того чтобы узнать о том, как всё это устроено, нам нужно перейти на более высокий уровень абстракции и поговорить о том, как в кластере Kubernetes работают узлы. Здесь мы затронем тему сетевой маршрутизации и маршрутов. Данной темы в материалах, подобных этому, нередко избегают, считая её слишком сложной. Непросто найти понятное и не слишком длинное руководство по IP-маршрутизации, но если вам хочется взглянуть на краткий обзор этой проблемы — можете взглянуть на этот материал.
Кластер Kubernetes состоит из одного узла или из большего количества узлов. Узел — это хост-система, физическая или виртуальная, которая содержит разные программные средства и их зависимости (речь идёт, в основном, о Docker), а также несколько системных компонентов Kubernetes. Узел подключён к сети, что позволяет ему обмениваться данными с другими узлами кластера. Вот как может выглядеть простой кластер, состоящий из двух узлов.

Простой кластер, состоящий из двух узлов
Если кластер, о котором идёт речь, работает в облачной среде наподобие GCP или AWS, то эта схема довольно точно передаёт сущность используемой по умолчанию для отдельных проектов сетевой архитектуры. В демонстрационных целях в данном примере использована частная сеть
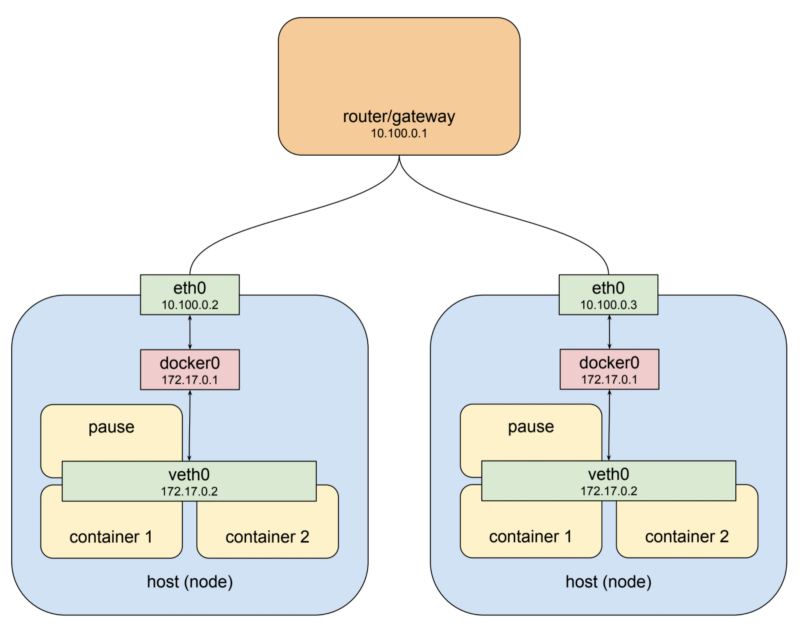
Поды и узлы
Хост, расположенный слева на этой схеме, имеет интерфейс
У хоста, изображённого на схеме справа, имеется физический интерфейс
Платформа Kubernetes даёт нам решение этой проблемы, состоящее из двух шагов. Во-первых, эта платформа назначает общее адресное пространство для мостов в каждом узле и затем назначает мостам адреса, находящиеся в этом пространстве, основываясь на том, в каком узле находится мост. Во-вторых, Kubernetes добавляет правила маршрутизации в шлюз, находящийся, в нашем случае, по адресу
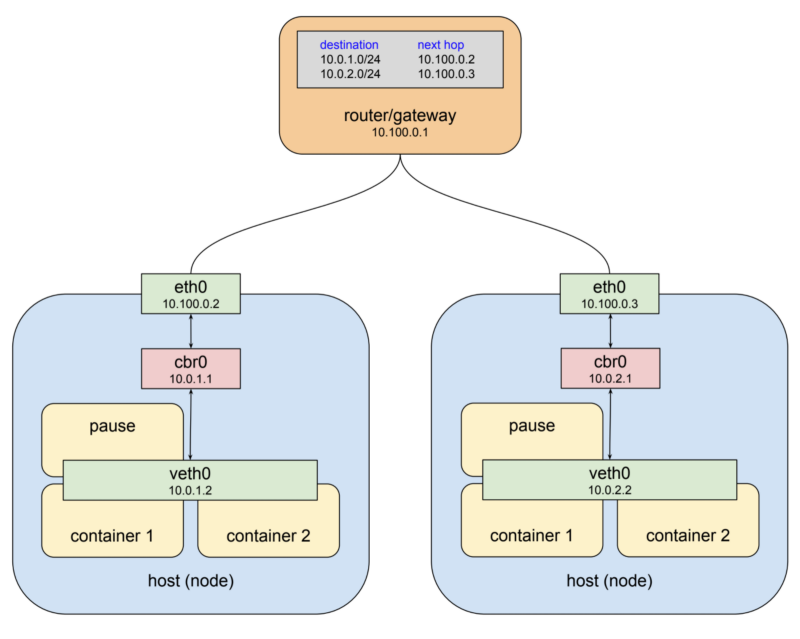
Сеть подов
Тут сразу бросается в глаза то, что имена мостов изменены с
В целом же можно отметить, что вам, обычно, не придётся размышлять о том, как именно работает сеть подов. Когда под обменивается данными с другим подом, чаще всего это происходит посредством сервисов Kubernetes. Это — нечто вроде программно определяемых прокси. Но сетевые адреса подов появляются в логах. В некоторых ситуациях, в частности, при отладке, вам может понадобиться явным образом задавать правила маршрутизации в сетях подов. Например, трафик, покидающий под Kubernetes, привязанный к любому адресу в диапазоне 10.0.0.0/8, не обрабатывается по умолчанию с помощью NAT. Поэтому если вы взаимодействуете с сервисами, находящимися в другой частной сети, имеющей тот же диапазон адресов, вам может понадобиться настроить правила маршрутизации, которые позволят организовать правильную доставку пакетов.
Сегодня мы поговорили о подах Kubernetes и об особенностях их сетевого взаимодействия. Надеемся, этот материал поможет вам сделать правильные шаги в направлении реализации сложных сценариев взаимодействия подов в сетях Kubernetes.
Уважаемые читатели! Эта статья является первым материалом цикла, посвящённого сетям Kubernetes. Вторая часть этого цикла уже переведена. Мы размышляем о том, нужно ли переводить третью часть. Просим вас высказаться об этом в комментариях.

Поды
Что такое под (pod) Kubernetes? Под — это сущность, которая состоит из одного или нескольких контейнеров, размещённых на одном хосте и настроенных на совместное использование ресурсов сетевого стека и других ресурсов наподобие томов. Поды — это базовые строительные блоки, из которых построены приложения, работающие на платформе Kubernetes. Поды совместно используют сетевой стек. На практике это означает, что все контейнеры, входящие в состав пода, могут взаимодействовать друг с другом через
localhost. Если в поде есть контейнер, в котором выполняется nginx, прослушивающий порт 80, и ещё один контейнер, в котором выполняется scrapyd, то этот контейнер может обратиться к первому контейнеру по адресу http://localhost:80. Выглядит это не так уж и сложно. Зададимся теперь вопросом о том, как это, на самом деле, работает. Взглянем на типичную ситуацию, когда контейнер Docker запускают на локальной машине.Контейнер Docker, запущенный на локальной машине
Если рассмотреть эту схему сверху вниз, то окажется, что здесь имеется физический сетевой интерфейс
eth0. К нему присоединён мост docker0, а к мосту присоединён виртуальный сетевой интерфейс veth0. Обратите внимание на то, что интерфейсы docker0 и veth0 находятся в одной и той же сети, в данном примере это 172.17.0.0/24. В этой сети интерфейсу docker0 назначен IP-адрес 172.17.0.1, этот интерфейс является шлюзом по умолчанию для интерфейса veth0, которому назначен адрес 172.17.0.2. Из-за особенностей настройки сетевых пространств имён при запуске контейнера процессы внутри контейнера видят только интерфейс veth0 и взаимодействуют с внешним миром через интерфейсы docker0 и eth0. Теперь запустим второй контейнер.Два контейнера Docker, запущенные на локальной машине
Как можно видеть на вышеприведённой схеме, второму контейнеру назначается новый виртуальный сетевой интерфейс
veth1, который подключён к тому же самому мосту, что и первый контейнер — к docker0. Это — довольно сжатое описание того, что происходит на самом деле. Кроме того, надо отметить, что соединение между контейнером и мостом устанавливается благодаря паре связанных виртуальных интерфейсов Ethernet, один из которых находится в пространстве имён контейнера, а другой — в пространстве имён корневой сети. Подробности об этом можно найти здесь.Всё это хорошо, но это не описывает пока то, что мы, в применении к подам Kubernetes, называем «разделяемым сетевым стеком». К счастью, пространства имён отличаются большой гибкостью. Docker может запустить контейнер, и, вместо того, чтобы создавать для него новый виртуальный сетевой интерфейс, сделать так, чтобы он использовал бы, совместно с другими контейнерами, существующий интерфейс. При таком подходе нам придётся изменить вышеприведённую схему так, как показано ниже.
Контейнеры используют общий сетевой интерфейс
Теперь второй контейнер взаимодействует с уже существующим интерфейсом
veth0, а не со своим собственным интерфейсом veth1, как это было в предыдущем примере. Применение такой схемы ведёт к нескольким следствиям. Для начала, теперь можно сказать, что оба контейнера видны извне по одному адресу — 172.17.0.2, а внутри каждый из них может обращаться к портам на localhost, открытым другим контейнером. Кроме того, это означает, что эти контейнеры не могут открывать одни и те же порты. Это, конечно, ограничение, но оно не отличается от аналогичного ограничения, действующего в ситуации, когда на одном и том же хосте работают несколько процессов, открывающих порты. При таком подходе набор процессов получает все преимущества, связанные с выполнением этих процессов в контейнерах, такие, как слабая связанность и изоляция, но, в то же время, процессы могут организовывать совместную работу в простейшем из существующих сетевых окружений.Kubernetes реализует этот паттерн, создавая для каждого пода специальный контейнер, единственной целью которого является предоставление сетевого интерфейса для других контейнеров пода. Если подключиться к узлу кластера Kubernetes, которому назначен конкретный под, по
ssh, и выполните команду docker ps, то вы увидите как минимум один контейнер, запущенный с командой pause. Эта команда приостанавливает текущий процесс до поступления сигнала SIGTERM. Такие контейнеры совершенно ничего не делают, они находятся в «спящем» состоянии и ожидают получения этого сигнала. Несмотря на то, что «приостановленные» контейнеры ничего не делают, они являются, так сказать, «сердцем» пода, предоставляя другим контейнерам виртуальный сетевой интерфейс, которым они могут пользоваться для взаимодействия друг с другом или с внешним миром. В результате оказывается, что в гипотетической среде, напоминающей под, наша предыдущая схема выглядела бы так, как показано ниже.Контейнеры в гипотетическом поде
Сеть подов
Один под, полный контейнеров, это строительный блок некоей системы, но пока ещё не сама эта система. В основе архитектуры Kubernetes лежит требование, в соответствии с которым у подов должна быть возможность взаимодействовать с другими подами вне зависимости от того, выполняются ли они на одном и том же компьютере или на разных машинах. Для того чтобы узнать о том, как всё это устроено, нам нужно перейти на более высокий уровень абстракции и поговорить о том, как в кластере Kubernetes работают узлы. Здесь мы затронем тему сетевой маршрутизации и маршрутов. Данной темы в материалах, подобных этому, нередко избегают, считая её слишком сложной. Непросто найти понятное и не слишком длинное руководство по IP-маршрутизации, но если вам хочется взглянуть на краткий обзор этой проблемы — можете взглянуть на этот материал.
Кластер Kubernetes состоит из одного узла или из большего количества узлов. Узел — это хост-система, физическая или виртуальная, которая содержит разные программные средства и их зависимости (речь идёт, в основном, о Docker), а также несколько системных компонентов Kubernetes. Узел подключён к сети, что позволяет ему обмениваться данными с другими узлами кластера. Вот как может выглядеть простой кластер, состоящий из двух узлов.
Простой кластер, состоящий из двух узлов
Если кластер, о котором идёт речь, работает в облачной среде наподобие GCP или AWS, то эта схема довольно точно передаёт сущность используемой по умолчанию для отдельных проектов сетевой архитектуры. В демонстрационных целях в данном примере использована частная сеть
10.100.0.0/24. В результате маршрутизатору назначен адрес 10.100.0.1, а двум узлам — адреса 10.100.0.2 и 10.100.0.3. При использовании такой архитектуры каждый из узлов может взаимодействовать с другим с использованием своего сетевого интерфейса eth0. Теперь давайте вспомним о том, что под, запущенный на хосте, находится не в этой частной сети. Он подключён к мосту в совершенно другой сети. Это — виртуальная сеть, которая существует только в пределах конкретного узла. Для того чтобы было понятнее, давайте перерисуем предыдущую схему, добавив на неё то, что выше мы называли гипотетическим подом.Поды и узлы
Хост, расположенный слева на этой схеме, имеет интерфейс
eht0 с адресом 10.100.0.2, шлюзом по умолчанию для которого является маршрутизатор с адресом 10.100.0.1. К этому интерфейсу подключён мост docker0 с адресом 172.17.0.1, а к нему, через виртуальный интерфейс veth0 с адресом 172.17.0.2, подключено то, что мы тут называем подом. Интерфейс veth0 был создан в приостановленном контейнере. Он видим во всех трёх контейнерах посредством разделяемого сетевого стека. Из-за того, что локальные правила маршрутизации настроены при создании моста, любой пакет, поступающий на eth0 и имеющий целевой адрес 172.17.0.2, будет перенаправлен мосту, который перешлёт его на виртуальный интерфейс veth0. Пока всё это выглядит вполне прилично. Если известно, что на обсуждаемом нами хосте есть под с адресом 172.17.0.2, то мы можем добавить правило в настройки маршрутизатора, описывающее то, что следующим переходом для этого адреса является 10.100.0.2, после чего пакеты оттуда должны перенаправляться на veth0. Превосходно. Теперь давайте взглянем на другой хост.У хоста, изображённого на схеме справа, имеется физический интерфейс
eth0 с адресом 10.100.0.3. Он использует тот же самый шлюз по умолчанию — 10.100.0.1, и, опять же, подключён к мосту docker0 с адресом 172.17.0.1. Тут возникает ощущение, что всё идёт не так уж и хорошо. Этот адрес, на самом деле, может и отличаться от того, который используется на хосте, расположенном слева. Адреса мостов тут сделаны одинаковыми для того, чтобы продемонстрировать наихудший из возможных вариантов развития событий, который, например, может проявиться, если вы только что установили Docker и позволили ему работать так, как ему заблагорассудится. Но если даже сети, о которых идёт речь, различаются, наш пример высвечивает более глубокую проблему, которая заключается в том, что узлы обычно ничего не знают о том, какие частные адреса назначены мостам, находящимся в других узлах. А нам об этом нужно знать — для того, чтобы иметь возможность отправлять этим мостам пакеты и быть уверенными в том, что они придут туда, куда нужно. Очевидно, что тут нужна некая сущность, которая позволяет обеспечивать правильную настройку адресов в разных узлах.Платформа Kubernetes даёт нам решение этой проблемы, состоящее из двух шагов. Во-первых, эта платформа назначает общее адресное пространство для мостов в каждом узле и затем назначает мостам адреса, находящиеся в этом пространстве, основываясь на том, в каком узле находится мост. Во-вторых, Kubernetes добавляет правила маршрутизации в шлюз, находящийся, в нашем случае, по адресу
10.100.0.1. Эти правила определяют правила маршрутизации пакетов, предназначенных для каждого из мостов. То есть, описывают то, через какой физический интерфейс eth0 можно связаться с каждым из мостов. Подобную комбинацию виртуальных сетевых интерфейсов, мостов и правил маршрутизации обычно называют оверлейной сетью. Говоря о Kubernetes, я обычно называю эту сеть «сетью подов», так как это — оверлейная сеть, которая позволяет подам, расположенным в разных узлах, взаимодействовать друг с другом. Вот как будет выглядеть предыдущая схема после того, как за дело возьмутся механизмы Kubernetes.Сеть подов
Тут сразу бросается в глаза то, что имена мостов изменены с
docker0 на cbr0. Kubernetes не использует стандартные мосты Docker. То, что мы тут назвали cbr — это сокращение от «custom bridge», то есть, речь идёт о неких особых мостах. Я не готов привести полный список отличий запуска контейнеров Docker в подах от их запуска на обычных компьютерах, но то, о чём мы тут говорим, является одним из важных подобных отличий. Кроме того, надо обратить внимание на то, что адресное пространство, назначенное мостам в этом примере — это 10.0.0.0/14. Этот адрес взят из одного из наших staging-кластеров, который развёрнут на платформе Google Cloud, так что выше приведён вполне реальный пример сети подов. Вашему кластеру может быть назначен совершенно другой диапазон адресов. К сожалению, в настоящий момент нет возможности получить сведения об этих адресах с использованием утилиты kubectl, но, например, если вы пользуетесь GCP, вы можете выполнить команду вида gcloud container clusters describe <cluster> и взглянуть на свойство clusterIpv4Cidr.В целом же можно отметить, что вам, обычно, не придётся размышлять о том, как именно работает сеть подов. Когда под обменивается данными с другим подом, чаще всего это происходит посредством сервисов Kubernetes. Это — нечто вроде программно определяемых прокси. Но сетевые адреса подов появляются в логах. В некоторых ситуациях, в частности, при отладке, вам может понадобиться явным образом задавать правила маршрутизации в сетях подов. Например, трафик, покидающий под Kubernetes, привязанный к любому адресу в диапазоне 10.0.0.0/8, не обрабатывается по умолчанию с помощью NAT. Поэтому если вы взаимодействуете с сервисами, находящимися в другой частной сети, имеющей тот же диапазон адресов, вам может понадобиться настроить правила маршрутизации, которые позволят организовать правильную доставку пакетов.
Итоги
Сегодня мы поговорили о подах Kubernetes и об особенностях их сетевого взаимодействия. Надеемся, этот материал поможет вам сделать правильные шаги в направлении реализации сложных сценариев взаимодействия подов в сетях Kubernetes.
Уважаемые читатели! Эта статья является первым материалом цикла, посвящённого сетям Kubernetes. Вторая часть этого цикла уже переведена. Мы размышляем о том, нужно ли переводить третью часть. Просим вас высказаться об этом в комментариях.
