

В Debian теперь нет iptables. Во всяком случае, по умолчанию.
Узнал я об этом, когда на Debian 11 ввёл команду iptables и получил “command not found”. Сильно удивился и стал читать документацию. Оказалось, теперь нужно использовать nftables.
Хорошие новости: одна утилита nft заменяет четыре прежних — iptables, ip6tables, ebtables и arptables.
Плохие новости: документация (man nft) содержит больше 3 тысяч строк.
Чтобы вам не пришлось всё это читать, я написал небольшое руководство по переходу с iptables на nftables. Точнее, краткое практическое пособие по основам nftables. Без углубления в теорию и сложные места. С примерами.
Предисловие (TL;DR)
Для облегчения перехода можно конвертировать правила iptables в nftables с помощью утилит iptables-translate, iptables-restore-translate, iptables-nft-restore и т.п. Утилиты находятся в пакете iptables, который нужно установить дополнительно.
После чего возьмём какую-нибудь команду и пропустим её через iptables-translate. Например, из такой команды:
iptables -A INPUT -i eth0 -p tcp --dport 80 -j DROPполучится вот такая:
nft add rule ip filter INPUT iifname "eth0" tcp dport 80 counter dropКазалось бы, всё очень просто, и переход на nftables не доставит никаких проблем. Запускаем преобразованную команду, и … она не работает!!!
А вот почему она не работает — об этом вы узнаете
Первое правило nftables — никаких правил
В nftables нет обязательных предопределённых таблиц, как в iptables. Вы сами создаёте нужные вам таблицы. И называете их, как хотите.
Вероятно, самое заметное отличие nftables от iptables — наличие иерархической структуры: правила группируются в цепочки, цепочки группируются в таблицы. Внешне это всё слегка напоминает JSON. И неудивительно, что экспорт в JSON имеется (команда nft -j list ruleset).
Конечно, в iptables тоже есть таблицы и цепочки, но они не выделяются настолько явно. Посмотрите, как выглядит файл конфигурации nftables:
flush ruleset
define wan_if = eth0
define lan_if = eth1
define admin_ip = 203.0.113.15
table ip filter {
set blocked_services {
type inet_service
elements = { 22, 23 }
}
chain input_wan {
ip saddr $admin_ip tcp dport ssh accept
tcp dport @blocked_services drop
}
chain input_lan {
icmp type echo-request limit rate 5/second accept
ip protocol . th dport vmap { tcp . 22 : accept, udp . 53 : accept, \
tcp . 53 : accept, udp . 67 : accept}
}
chain input {
type filter hook input priority 0; policy drop;
ct state vmap { established : accept, related : accept, invalid : drop }
iifname vmap { lo : accept, $wan_if : jump input_wan, \
$lan_if : jump input_lan }
}
chain forward {
type filter hook forward priority 0; policy drop;
ct state vmap { established : accept, related : accept, invalid : drop }
iif $lan_if accept
}
chain postrouting {
type nat hook postrouting priority srcnat; policy accept;
masquerade comment "Masquerading rule example"
}
}
Действующие правила показываются в таком же формате. Чтобы их увидеть, используется команда nft list ruleset. И эта же команда позволяет сохранить правила в файл:
# echo "flush ruleset" > /etc/nftables.conf
# nft -s list ruleset >> /etc/nftables.conf
Впоследствии правила можно загрузить:
# nft -f /etc/nftables.conf
Внимание! Загружаемые из файла правила добавляются к уже работающим, а не заменяют их полностью. Чтобы начать «с чистого листа», первой строкой файла вписывают команду полной очистки (flush ruleset).
Можно также хранить правила в разных файлах, собирая их вместе с помощью include. И как вы заметили — можно использовать define.
Синтаксис командной строки
Конечно, вводить многострочные конструкции в командной строке неудобно. Поэтому для управления файерволом используется обычный синтаксис примерно такого вида:
nft <команда> <объект> <путь к объекту> <параметры>Команда — add, insert, delete, replace, rename, list, flush…
Объект — table, chain, rule, set, ruleset…
Путь к объекту зависит от типа. Например, у таблицы это <семейство> <название>.
У правила — гораздо длиннее: <семейство таблицы> <название таблицы> <название цепочки>. А иногда ещё добавляются handle или index (будут описаны дальше).
Параметры зависят от типа объекта. Для правила это условие отбора пакетов и действие, применяемое к отобранным пакетам.
Допустим, нужно заблокировать доступ к ssh и telnet. Для этого используем такую команду:
# nft insert rule inet filter input iif eth0 tcp dport { ssh, telnet } dropКак видите, она состоит из простых, понятных частей:
вставить (insert) правило (rule) в семейство таблиц inet, таблицу filter, цепочку input;
запретить (drop) прохождение пакетов, вошедших через интерфейс (iif) eth0, имеющих тип протокола tcp и направляющихся к сервисам ssh или telnet
Примечание: номера портов для сервисов берутся из файла /etc/services
Теперь, чтобы удалить это правило, на него как-то нужно сослаться. Для этого существуют хэндлы (handle), которые можно увидеть, добавив опцию «a» в команду просмотра правил. Кстати, необязательно смотреть все правила (nft -a list ruleset). Можно глянуть только нужную таблицу или цепочку:
# nft -a list chain ip filter inputРезультат:
chain input { # handle 1
type filter hook input priority 0; policy drop;
iif "eth0" tcp dport { 22, 23 } drop # handle 4
ct state vmap { established : accept, related : accept, \
invalid : drop } # handle 2
iifname vmap { lo : accept, $wan_if : jump input_wan, \
$lan_if : jump input_lan } # handle 3
}
Соответственно, удаление правила выглядит так:
# nft delete rule inet filter input handle 3Учтите: в каждой таблице своя нумерация хэндлов, не зависящая от других таблиц. Если сейчас добавить ещё одну таблицу — у неё будут свои handle 1, handle 2 и т.д. Благодаря этому, сделанные в какой-либо таблице изменения не влияют на нумерацию в других таблицах.
Порядок обработки правил
Если таблицы и цепочки мы добавляем сами — как файервол поймёт, в каком порядке применять правила? Очень просто: он обрабатывает пакеты с учётом семейства таблиц и хуков цепочек. Вот как на этой картинке:
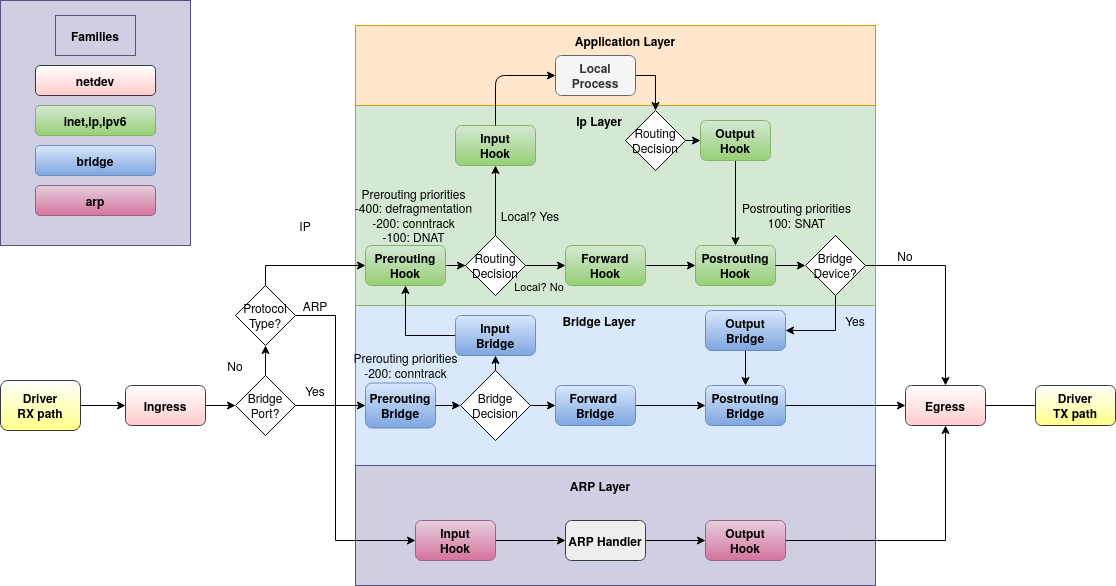
Таблицы могут быть одного из 6-ти семейств (families):
ip — для обработки пакетов IPv4
ip6 — IPv6
inet — обрабатывает сразу и IPv4 и IPv6 (чтобы не дублировать одинаковые правила)
arp — пакеты протокола ARP
bridge — пакеты, проходящие через мост
netdev — для обработки «сырых» данных, поступающих из сетевого интерфейса (или передающихся в него)
Цепочки получают на вход пакеты из хуков (цветные прямоугольники на картинке). Для ip/ip6/inet предусмотрены хуки prerouting, input, forward, output и postrouting.
У цепочки есть приоритет. Чем он ниже (может быть отрицательным), тем раньше обрабатывается цепочка. Обратите внимание на хук prerouting в зелёной части картинки — там это видно.
Чтобы не запоминать числа, для указания приоритета можно использовать зарезервированные слова. Самые используемые – dstnat (приоритет = -100), filter (0), srcnat (100).
Теперь рассмотрим основные части nftables подробнее.
Таблицы (tables)
Синтаксис:
{add | create} table [family] table [{ flags flags; }]
{delete | list | flush} table [family] table
list tables [family]
delete table [family] handle handle
Поскольку таблиц изначально нет, их нужно создать до того, как создавать цепочки и правила.
Именно поэтому не сработало правило после iptables-translate — для него не нашлось таблицы и цепочки.
По умолчанию (если не указана family) считается, что таблица относится к семейству ip.
У таблицы может быть единственный флаг — dormant, который позволяет временно отключить таблицу (вместе во всем её содержимым):
# nft add table filter {flags dormant \;}Включить обратно:
# nft add table filterПримечание: если команда вводится в командной строке — нужно ставить бэкслэш перед точкой с запятой.
Цепочки (chains)
Синтаксис:
{add | create} chain [family] table chain [{ type type hook hook [device device] priority priority; [policy policy ;] }]
{delete | list | flush} chain [family] table chain
list chains [family]
delete chain [family] table handle handle
rename chain [family] table chain newname
Цепочки бывают базовые (base) и обычные (regular). Базовая цепочка получает пакеты из хука, с которым она связана. А обычная цепочка — это просто контейнер для группировки правил. Чтобы сработали её правила, нужно выполнить на неё явный переход.
Пример в начале статьи содержит обычные цепочки input_wan и input_lan, а также базовые цепочки input, forward и postrouting.
Для базовой цепочки кроме хука и приоритета нужно указать тип:
- filter — стандартный тип, может применяться в любом семействе для любого хука
- nat — используется для NAT. В цепочке обрабатывается только первый пакет соединения, все остальные отправляются «по натоптанной дорожке» через conntrack
- route — применяется в хуке output для маркировки пакетов
Также можно указать policy (действие по умолчанию). Т.е., что делать с пакетами, добравшимися до конца цепочки — drop или accept. Если не указано — подразумевается accept.
Пример добавления цепочки:
# nft add chain inet filter output { type filter hook output priority 0 \;
policy accept \; }
Переход на обычную цепочку может выполняться одной из двух команд — jump или goto. Отличие состоит в поведении после возврата из обычной цепочки. После jump продолжается обработка пакетов по всей цепочке, после goto сразу срабатывает действие по умолчанию.
Пример:
table ip filter {
chain input { # handle 1
type filter hook input priority 0; policy accept;
ip saddr 1.1.1.1 ip daddr 2.2.2.2 tcp sport 111 \
tcp dport 222 jump other-chain # handle 3
ip saddr 1.1.1.1 ip daddr 2.2.2.2 tcp sport 111 \
tcp dport 222 accept # handle 4
}
chain other-chain { # handle 2
counter packets 8 bytes 2020 # handle 5
}
}Пакет, для которого в handle 3 сработало условие, пойдёт на обработку в цепочку other-chain, а после возврата из неё — продолжит обрабатываться в правиле handle 4.
Если вместо jump будет использовано goto — после возврата из other-chain сработает действие по умолчанию (в этом примере — policy accept).
Из вызванной цепочки можно выйти досрочно с помощью действия return. При этом вызывающая цепочка продолжит выполняться со следующего правила (аналогично jump). Использование return в базовой цепочке вызывает срабатывание действия по умолчанию.
Правила (rules)
Синтаксис:
{add | insert} rule [family] table chain [handle handle | index index] statement… [comment comment]
replace rule [family] table chain handle handle statement … [comment comment]
delete rule [family] table chain handle handle
Правила можно добавлять и вставлять не только по хэндлу, но и по индексу («вставить перед 5-м правилом»). Правило, на которое ссылается index, должно существовать (то есть, в пустую цепочку вставить по индексу не получится).
Правила можно комментировать:
# nft insert rule inet filter output index 3 tcp dport 2300-2400 drop
comment \"Block games ports\"Заодно здесь показано, как можно использовать интервалы. Для адресов они тоже работают: 192.168.50.15-192.168.50.82. Их также можно применять в множествах, словарях и т.п. (с флагом interval для именованных).
Множества (sets)
Синтаксис:
add set [family] table set { type type | typeof expression; [flags flags ;] [timeout timeout ;] [gc-interval gc-interval ;] [elements = { element[, ...] } ;] [size size ;] [policy policy ;] [auto-merge ;] }
{delete | list | flush} set [family] table set
list sets [family]
delete set [family] table handle handle
{add | delete} element [family] table set{ element[, ...] }
Множества бывают двух типов — анонимные и именованные. Анонимные — пишутся в фигурных скобках прямо в строке с правилом:
# nft add rule filter input ip saddr { 10.0.0.0/8, 192.168.0.0/16 } dropТакое множество можно изменить, только изменив правило целиком.
А вот именованные множества можно менять независимо от правил:
# nft add set inet filter blocked_services { type inet_service \; }
# nft add element inet filter blocked_services { ssh, telnet }
# nft insert rule inet filter input iif eth0 tcp dport @blocked_services drop
# nft delete element inet filter blocked_services { 22 }Чтобы в правиле сослаться на множество, нужно указать его имя с префиксом "@".
Возможные типы элементов у множеств: ipv4_addr, ipv6_addr, ether_addr, inet_proto, inet_service, mark, ifname.
Элементы можно добавлять сразу при объявлении множества:
# nft add set ip filter two_addresses {type ipv4_addr \; flags timeout \;
elements={192.168.1.1 timeout 10s, 192.168.1.2 timeout 30s} \;}Также здесь можно увидеть, как указать собственный таймаут для каждого элемента.
Если множество сохранено в файле, для объявления элементов можно использовать define:
define CDN_EDGE = {
192.168.1.1,
192.168.1.2,
192.168.1.3,
10.0.0.0/8
}
define CDN_MONITORS = {
192.168.1.10,
192.168.1.20
}
define CDN = {
$CDN_EDGE,
$CDN_MONITORS
}
tcp dport { http, https } ip saddr $CDN acceptФлаги во множествах бывают такие: constant, dynamic, interval, timeout. Можно указывать несколько флагов через запятую.
Если указать timeout — элемент будет находиться во множестве заданное время, после чего автоматически удалится.
Флаг dynamic используется, если элементы формируются на основе информации из проходящих пакетов (packet path).
Можете поэкспериментировать и посмотреть, как оно работает. Для этого удобно использовать ICMP и пинговать целевой компьютер с соседней машины. Допустим, возьмём вот такую комбинацию:
# nft add chain inet filter ping_chain {type filter hook input priority 0\;}
# nft add set inet filter ping_set { type ipv4_addr\; flags dynamic , timeout\;
timeout 30s\;}
# nft add rule inet filter ping_chain icmp type echo-request add @ping_set
{ ip saddr limit rate over 5/minute } dropЗдесь при приходе первого же пакета icmp в множество ping_set будет добавлен элемент, описанный в фигурных скобках. А когда у элемента сработает условие «rate over 5/minute» (превышена скорость 5 пакетов в минуту) — выполнится описанное в правиле действие (drop). В развёрнутом виде это выглядит так:
set ping_set {
type ipv4_addr
size 65535
flags dynamic,timeout
timeout 30s
elements = { 192.168.16.1 limit rate over 5/minute timeout 30s expires 25s664ms }
}
chain ping_chain {
type filter hook input priority filter; policy accept;
icmp type echo-request add @ping_set { ip saddr limit rate over 5/minute } drop
}На первый взгляд кажется, что пройдёт 5 пингов, и всё остановится. Затем на 30-й секунде элемент удалится, и опять всё пойдёт по новой. Однако, алгоритм ограничения скорости (здесь используется «token bucket») работает по-другому.
Получается вот такое пингование (смотрите на icmp_seq):
PING 192.168.16.201 (192.168.16.201) 56(84) bytes of data.
64 bytes from 192.168.16.201: icmp_seq=1 ttl=64 time=0.568 ms
64 bytes from 192.168.16.201: icmp_seq=2 ttl=64 time=0.328 ms
64 bytes from 192.168.16.201: icmp_seq=3 ttl=64 time=0.367 ms
64 bytes from 192.168.16.201: icmp_seq=4 ttl=64 time=0.456 ms
64 bytes from 192.168.16.201: icmp_seq=5 ttl=64 time=0.319 ms
64 bytes from 192.168.16.201: icmp_seq=13 ttl=64 time=0.369 ms
64 bytes from 192.168.16.201: icmp_seq=25 ttl=64 time=0.339 ms
На 30-й секунде элемент удаляется, и цикл повторяется — 31,32,33,34,35,43,55.
То есть, первые 5 пингов проскакивают без задержки, затем срабатывает ограничение rate over 5/minute и пакеты начинают отбрасываться. Но через 12 секунд (1 минута / 5 = 12с) первый прошедший пакет удалится из виртуальной «корзины с токенами» и освободит место для прохода следующего пакета. И через 12 секунд — ещё один.
Разумеется, блокировка ICMP мало кому интересна. Обычно это используется для защиты ssh. Прямо в документации есть такой пример:
# nft add set ip filter blackhole { type ipv4_addr\; flags dynamic\; timeout 1m\;
size 65536\; }
# nft add set ip filter flood { type ipv4_addr\; flags dynamic\; timeout 10s\;
size 128000\; }
# nft add rule ip filter input meta iifname \"internal\" accept
# nft add rule ip filter input ip saddr @blackhole counter drop
# nft add rule ip filter input tcp flags syn tcp dport ssh \
add @flood { ip saddr limit rate over 10/second } \
add @blackhole { ip saddr } drop
Здесь сделан интересный «финт ушами», который заключается в том, что сделано два множества с разными таймаутами. Первое детектирует превышение скорости пакетов, а действием у него назначено добавление элемента во второе множество, которое и используется непосредственно для блокировки.
Хотя, на мой взгляд, вместо add для blackhole лучше использовать update. Разница в том, что update при каждом вызове перезапускает таймаут элемента. Таким образом, блокировка будет действовать непрерывно, пока первое множество будет детектировать флуд и обновлять таймауты второго множества. А в примере из документации блокировка каждую минуту ненадолго снимается.
Словари (maps)
Синтаксис:
add map [family] table map { type type | typeof expression [flags flags ;] [elements = { element[, ...] } ;] [size size ;] [policy policy ;] }
{delete | list | flush} map [family] table map
list maps [family]
Словари похожи на множества, только хранят пары ключ-значение. Бывают анонимными и именованными. Анонимный:
# nft add rule ip nat prerouting dnat to tcp dport map { 80: 192.168.1.100,
443 : 192.168.1.101 }Именованный:
# nft add map nat port_to_ip { type inet_service: ipv4_addr\; }
# nft add element nat port_to_ip { 80 : 192.168.1.100, 443 : 192.168.1.101 }
Для использования в правилах именованные словари нужно предварять префиксом «@»:
# nft add rule ip nat postrouting snat to tcp dport map @port_to_ip
И, разумеется, элементы именованных словарей можно добавлять и удалять.
Словари действий (verdict maps)
Это вариант словарей, где в качестве значения используется действие (verdict). Действие может быть таким: accept, drop, queue, continue, return, jump, goto.
Пример правила c анонимным verdict map:
# nft add rule inet filter input ip protocol vmap { tcp : jump tcp_chain ,
udp : jump udp_chain , icmp : drop }
Пример с именованным:
# nft add map filter my_vmap { type ipv4_addr : verdict \; }
# nft add element filter my_vmap { 192.168.0.10 : drop, 192.168.0.11 : accept }
# nft add rule filter input ip saddr vmap @my_vmap
Обратите внимание: в правиле перед ключевым словом vmap нужно указать, что будет использоваться в качестве ключа (здесь — ip saddr). Этот ключ должен иметь тип значения, совпадающий с указанным в определении словаря (в этом примере — type ipv4_addr). Для ipv4_addr в качестве ключей могут быть ip saddr, ip daddr, arp saddr ip, ct original ip daddr и пр. Все возможные варианты описаны вот здесь.
Условия отбора пакетов
▍ Конкатенации (сoncatenations)
Позволяют использовать несколько условий одновременно (логическое И):
# nft add rule ip filter input ip saddr . ip daddr . ip protocol
{ 1.1.1.1 . 2.2.2.2 . tcp, 1.1.1.1 . 3.3.3.3 . udp} accept
Правило сработает, если ip saddr == 1.1.1.1 И ip daddr == 2.2.2.2 И ip protocol == tcp
Конкатенации можно применять в словарях:
# nft add rule ip nat prerouting dnat to ip saddr . tcp dport map
{ 1.1.1.1 . 80 : 192.168.1.100, 2.2.2.2 . 443 : 192.168.1.101 }
И в verdict maps:
# nft add map filter whitelist { type ipv4_addr . inet_service : verdict \; }
# nft add rule filter input ip saddr . tcp dport vmap @whitelist
# nft add element filter whitelist { 1.2.3.4 . 22 : accept}
▍ Payload expressions (отбор пакетов на основе содержимого)
Это те условия, которые отбирают пакеты на основе информации, содержащейся в самих пакетах. Например, порт назначения, адрес источника, тип протокола и т.п.
Условий очень много, поэтому я приведу только их список. Впрочем, во многих случаях их назначение понятно из названия. Если нет — всегда можно посмотреть в документации.
ether {daddr | saddr | type}
vlan {id | dei | pcp | type}
arp {htype | ptype | hlen | plen | operation | saddr { ip | ether } | daddr { ip | ether }
ip {version | hdrlength | dscp | ecn | length | id | frag-off | ttl | protocol | checksum | saddr | daddr }
icmp {type | code | checksum | id | sequence | gateway | mtu}
igmp {type | mrt | checksum | group}
ip6 {version | dscp | ecn | flowlabel | length | nexthdr | hoplimit | saddr | daddr}
icmpv6 {type | code | checksum | parameter-problem | packet-too-big | id | sequence | max-delay}
tcp {sport | dport | sequence | ackseq | doff | reserved | flags | window | checksum | urgptr}
udp {sport | dport | length | checksum}
udplite {sport | dport | checksum}
sctp {sport | dport | vtag | checksum}
sctp chunk CHUNK [ FIELD ]
dccp {sport | dport | type}
ah {nexthdr | hdrlength | reserved | spi | sequence} # Authentication header
esp {spi | sequence} # Encrypted security payload header
comp {nexthdr | flags | cpi} # IPComp header
▍ RAW payload expression (отбор на основе «сырых» данных)
Это условие, которое выбирает из пакета указанное количество бит, начиная с заданного смещения. Бывает полезным, если нужно сопоставить данные, для которых ещё нет готового шаблона. Т.к. у пакетов разных протоколов по заданному смещению находятся разные данные, сначала нужно отобрать подходящие пакеты (в примере ниже — с помощью meta l4proto).
Синтаксис выглядит так:
@base,offset,length
Например, выберем пакеты протоколов TCP и UDP, идущие на заданные порты:
# nft add rule filter input meta l4proto {tcp, udp} @th,16,16 { 53, 80 }
впрочем, для этих протоколов есть готовые шаблоны, так что писать можно проще:
# nft add rule filter input meta l4proto { tcp, udp } th dport { 53, 80 } accept
Поскольку TCP и UDP – протоколы транспортного уровня, в качестве base здесь используется заголовок транспортного уровня (transport header => th).
Для протоколов сетевого уровня (например, IPv4 и IPv6) используются заголовки сетевого уровня (network header => nh).
А Ethernet, PPP и PPPoE – это канальный уровень. Для них применяется ll (т.к. link layer).
▍ Метаусловия (meta expression)
Метаусловия позволяют фильтровать пакеты на основе метаданных. То есть, на основе таких данных, которые не содержатся в самом пакете, но каким-либо образом с ним связаны — порт, через который вошёл пакет; номер процессора, обрабатывающего пакет; UID исходного сокета и прочее. Метаусловия бывают двух типов. У одних ключевое слово meta обязательно, у других — нет:
meta {length | nfproto | l4proto | protocol | priority}
[meta] {mark | iif | iifname | iiftype | oif | oifname | oiftype | skuid | skgid |
nftrace | rtclassid | ibrname | obrname | pkttype | cpu | iifgroup | oifgroup |
cgroup | random | ipsec | iifkind | oifkind | time | hour | day }
▍ Conntrack (connection tracking system)
Система conntrack хранит множество метаданных, по которым можно отбирать пакеты. Соответствующее условие выглядит таким образом:
ct { l3proto | protocol | expiration | state | original saddr | original daddr |
original proto-src | original proto-dst | reply saddr | reply daddr |
reply proto-src | reply proto-dst | status | mark | id }
Вероятно, наиболее используемое условие при работе с conntrack — ct state. Которое может иметь значения new, established, related, invalid, untracked.
Остальные возможности conntrack используются гораздо реже. Даже не буду их описывать. А вот несколько примеров c conntrack лишними не будут.
Разрешить не более 10 соединений с портом tcp/22 (ssh):
table inet connlimit_demo {
chain ssh_in {
type filter hook input priority filter; policy drop;
tcp dport 22 ct count 10 accept
}
}
Счётчик открытых соединений HTTPS:
table inet filter {
set https {
type ipv4_addr;
flags dynamic;
size 65536;
timeout 60m;
}
chain input {
type filter hook input priority filter;
ct state new tcp dport 443 update @https { ip saddr counter }
}
}
Следующее правило разрешает только 20 соединений с каждого адреса. Для каждого адреса IPv4 во множестве my_connlimit будет создан элемент со счётчиком. Когда счётчик достигнет нуля — элемент удалится, поэтому флаг timeout здесь не нужен.
table ip my_filter_table {
set my_connlimit {
type ipv4_addr
size 65535
flags dynamic
}
chain my_output_chain {
type filter hook output priority filter; policy accept;
ct state new add @my_connlimit { ip daddr ct count over 20 } counter drop
}
}
При описании множеств уже был пример, как ограничивать скорость пакетов. Это можно делать и с помощью conntrack:
# nft add rule my_table my_chain tcp dport 22 ct state new
add @my_set { ip saddr limit rate 10/second } accept
Пустить пакеты в обход conntrack:
# nft add table my_table
# nft add chain my_table prerouting { type filter hook prerouting
priority -300 \; }
# nft add rule my_table prerouting tcp dport { 80, 443 } notrack
Учёт и ограничения
▍ Квоты (quotas)
Считают проходящий трафик и срабатывают, когда достигнуто (over) или не достигнуто (until) указанное значение. Пример анонимной квоты:
table inet anon_quota_demo {
chain IN {
type filter hook input priority filter; policy drop;
udp dport 5060 quota until 100 mbytes accept
}
}
В этом примере на UDP порт 5060 можно будет передать только 100 МБ данных
Пример именованных квот:
table inet quota_demo {
quota q_until_sip { until 100 mbytes }
quota q_over_http { over 500 mbytes }
chain IN {
type filter hook input priority filter; policy drop;
udp dport 5060 quota name "q_until_sip" accept
tcp dport 80 quota name "q_over_http" drop
tcp dport { 80, 443 } accept
}
}
Здесь на порт SIP (udp/5060) пройдёт не больше 100 МБ, на http — не больше 500, на https — без ограничений, всё остальное блокируется. Обратите внимание на два варианта использования квот — until + accept и over + drop.
Именованные квоты (в отличие от анонимных) можно сбрасывать:
# nft reset quota inet quota_demo q_until_sip
Или все квоты файервола:
# nft reset quotas
▍ Лимиты (limits)
Используются для ограничения скорости в пакетах или байтах за единицу времени.
Пример:
table inet limit_demo {
limit lim_400ppm { rate 400/minute }
limit lim_1kbps { rate over 1024 bytes/second burst 512 bytes }
chain IN {
type filter hook input priority filter; policy drop;
meta l4proto icmp limit name "lim_400ppm" accept
tcp dport 25 limit name "lim_1kbps" accept
}
}
Здесь для ICMP установлен лимит 400 пакетов в минуту, для SMTP (TCP порт 25) — 1 кбайт/с.
При этом первые 512 байт на SMTP проскакивают без ограничения скорости (burst).
Весь остальной трафик блокируется политикой по умолчанию.
Можно уместить ограничение в одном правиле:
# nft add rule filter input icmp type echo-request limit rate over 10/second drop
Здесь отбрасываются пакеты, которые не влезают в лимит 10 пакетов в секунду.
Аналогично и с объёмом трафика:
# nft add rule filter input limit rate over 10 mbytes/second drop
Если не использовать over – правила применятся к тем пакетам, которые влезают в ограничение. Например:
# nft add rule filter input limit rate 10 mbytes/second accept
В этом правиле будет принят трафик, влезающий в 10 МБ/с. Всё, что превысит этот лимит – пойдёт на обработку в следующие правила или в политику по умолчанию.
Разумеется, burst здесь тоже возможен:
# nft add rule filter input limit rate 10 mbytes/second burst 9000 kbytes accept
Используя хук ingress в семействе netdev можно ограничить трафик на самом входе в систему. Например, уменьшим поступление широковещательного трафика:
# nft add rule netdev filter ingress pkttype broadcast limit rate
over 10/second drop
▍ Счётчики (counters)
Счётчики учитывают одновременно количество пакетов и байт. Анонимный счётчик:
# nft insert rule inet filter input ip protocol tcp counter
Посмотреть результаты можно с помощью list:
# nft list chain inet filter input
Результат:
table inet filter {
chain input {
type filter hook input priority filter; policy accept;
ip protocol tcp counter packets 331 bytes 21560
…
Такие счётчики можно просто добавлять к любому правилу с помощью слова counter:
# nft add rule inet filter input tcp dport 22 counter accept
Именованные счётчики:
table inet named_counter_demo {
counter cnt_http {
}
counter cnt_smtp {
}
chain IN {
type filter hook input priority filter; policy drop;
tcp dport 25 counter name cnt_smtp
tcp dport 80 counter name cnt_http
tcp dport 443 counter name cnt_http
}
}
Посмотреть результаты по всему файерволу, таблице или одному правилу:
# nft list counters
# nft list counters table inet named_counter_demo
# nft list counter inet named_counter_demo cnt_http
Сбросить счётчики – такой же синтаксис, только вместо list – reset.
Разная мелочёвка, примеры
▍ Маскарадинг (Masquerading)
# echo "1" >/proc/sys/net/ipv4/ip_forward
# nft add table ip nat
# nft add chain ip nat postrouting { type nat hook postrouting priority 100 \; }
# nft add rule nat postrouting masquerade
В развёрнутом виде:
table ip nat {
chain postrouting {
type nat hook postrouting priority srcnat; policy accept;
masquerade
}
}
▍ Source NAT, Destination NAT
# nft add table nat
# nft add chain nat postrouting { type nat hook postrouting priority snat \; }
# nft add rule nat postrouting ip saddr 192.168.1.0/24 oif eth0 snat to 1.2.3.4
Это правило направит трафик с сети 192.168.1.0/24 на интерфейс eth0. Выходящие с интерфейса пакеты получат исходящий адрес 1.2.3.4
# nft add table nat
# nft add chain nat prerouting { type nat hook prerouting priority dnat \; }
# nft add rule nat prerouting iif eth0 tcp dport { 80, 443 } dnat to 192.168.1.120
Это правило перенаправит входящий трафик для портов 80 и 443 на хост 192.168.1.120
▍ Редирект (redirect)
Перенаправление входящего трафика на другой порт этого же хоста
# nft add table nat
# nft add chain nat prerouting { type nat hook prerouting priority dstnat \; }
# nft add rule nat prerouting tcp dport 80 redirect to 8080
Исходящий трафик также можно редиректить:
# nft add rule nat output tcp dport 53 redirect to 10053
▍ Логгирование
Пишет информацию о пакетах в системный лог (/var/log/syslog). Примеры:
# nft add rule inet filter input tcp dport 22 ct state new \
log flags all prefix \"New SSH connection: \" accept
# nft add rule inet filter input meta pkttype broadcast \
log prefix \"Broadcast \"
# nft add rule inet filter input ether daddr 01:00:0c:cc:cc:cc \
log level info prefix \"Cisco Discovery Protocol \"
▍ Балансировка нагрузки (load balancing)
Обычный round-robin (равномерное распределение):
# nft add rule nat prerouting dnat to numgen inc mod 2 map { \
0 : 192.168.10.100, \
1 : 192.168.20.200 }
Распределение с разными весами:
# nft add rule nat prerouting dnat to numgen inc mod 10 map { \
0-7 : 192.168.10.100, \
8-9 : 192.168.20.200 }
Переход на цепочку, со случайным распределением и разными весами:
# nft add rule nat prerouting numgen random mod 100 vmap \
{ 0-69 : jump chain1, 70-99 : jump chain2 }
Итого
На мой взгляд, nftables получился удобнее, чем iptables. У него простой понятный синтаксис без многочисленных опций с дефисами. Иерархическая структура конфига. Свобода в формировании таблиц и цепочек.
Конечно, статья не описывает всех возможностей nftables. Это, скорее, шпаргалка по мотивам документации. Для более подробного изучения темы можно почитать следующие материалы:

