Комментарии 77
Не везде согласен с методологией, но сейчас ну совсем нет времени погружаться в детали, однако ещё в 2017 году я рассказывал (https://www.youtube.com/watch?v=I1LpqbzZmLM) почему таргечусь в ES3. Тогда, ради геттеров и сеттеров я быстро поднялся на ES5, и всё ещё моя рекомендация использовать все плюшки через Typescript и таргетиться в es5.
Господа минусующее, вот без обид, но может кто-нибудь привести такой пример кода на ESNext который будучи странспилен в таргет ES5 будет медленнее? До сих пор я не видел ни одного такого примера. Почему если новая модная штука не даёт выигрыша в производительности стоит посылать её клиенту? Развитие языка это хорошо и правильно, конструкции новые многие удобные, но почему не оттранспилить их в более быстрое представление?
В Typescript в угоду скорости используют вообще локальные переменные в скоупе, чтобы не обращаться к свойствам объектов, огребая миллион проблем, получая вот такой замечательный файл на 2.7 мегабайта кода и 2.5 тысячи функций в одном файле https://github.com/microsoft/TypeScript/blob/main/src/compiler/checker.ts
И они не могут от этого уйти по причине производительности компилятора, я делал автоматизированный рефактор этого кода https://github.com/microsoft/TypeScript/issues/17861 и ребята гоняли тесты, производительность просела. С тех времён в тайпскрипте выразительные средства улучшились, и такой рефактор можно сделать красивее. Но они продолжают платить часами, днями и уже вероятно годами своих разработчиков за комфорт пользователя этого компилятора.
Я не понимаю программистов которые в угоду моде заставляют расплачиваться пользователя, а потом тут появляются треды на 1000 комментов что софт дерьмо. Да он дерьмо ели его дерьмово делать.
может кто-нибудь привести такой пример кода на ESNext который будучи странспилен в таргет ES5 будет медленнее? До сих пор я не видел ни одного такого примера.
https://perf.js.hyoo.ru/#!bench=71gc0c_i1yal9
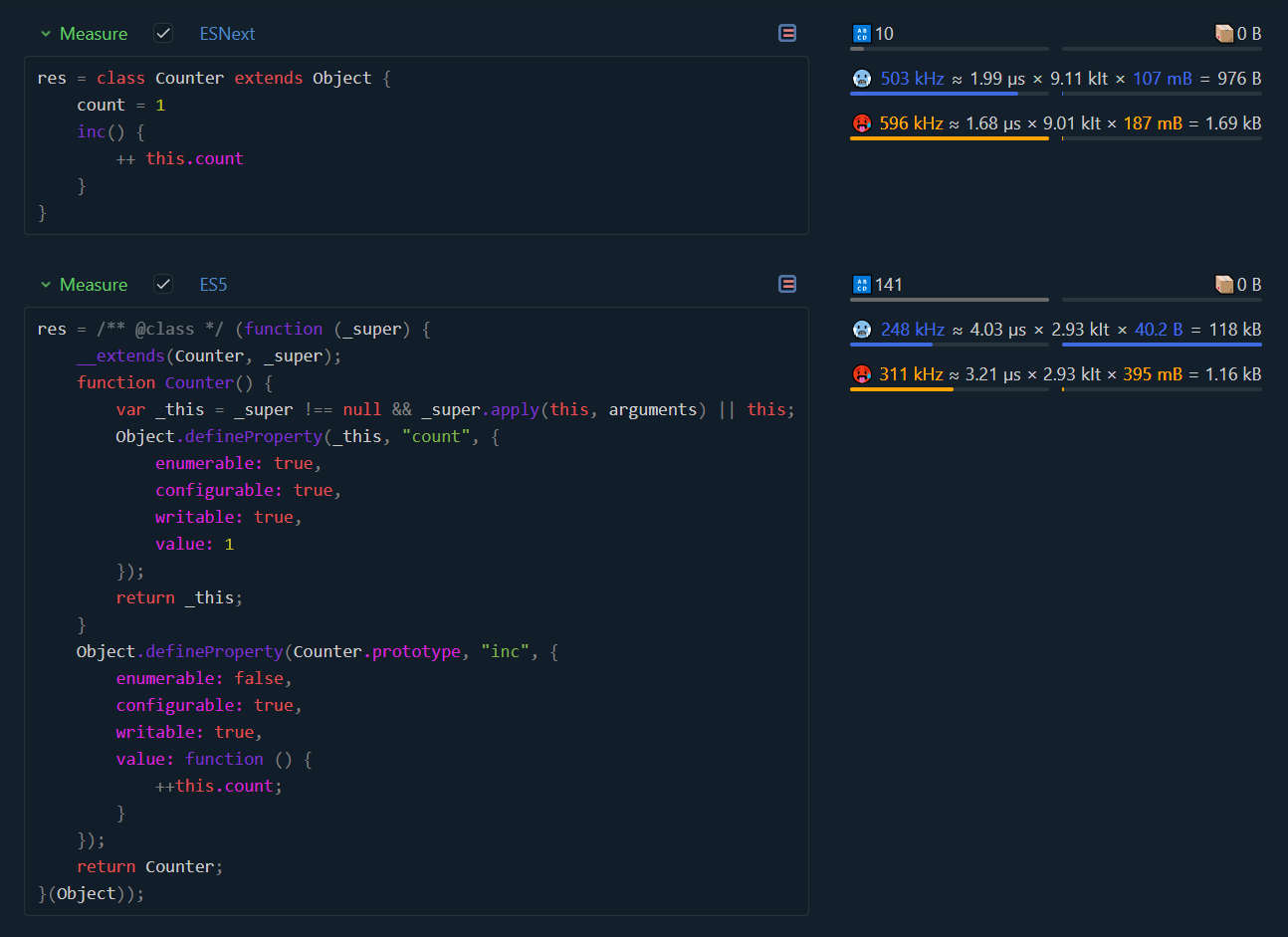
Чёт я ничерта не понял как этот тест работает, там inc никто не дёргает, вы проверяете скорость конструирования объектов? Дальнейшее рассмотрю из этого предположения. По коду у меня два вопроса по существу, зачем вы явно написали extends Object, это же бессмысленная ересь, и второе, синтаксис объявления полей который вы применили значительно замедляет этот странный бенчмарк.
Я добавил к вашему бенчмарку немного дополнительных тестов, применив транспилер Typescript, а вы, похоже, применяли babel (тут могу ошибаться, но он любит через defineProperty объявлять, и я абсолютно не понимаю зачем это делать)
https://perf.js.hyoo.ru/#!bench=ww1cau_g81ws7
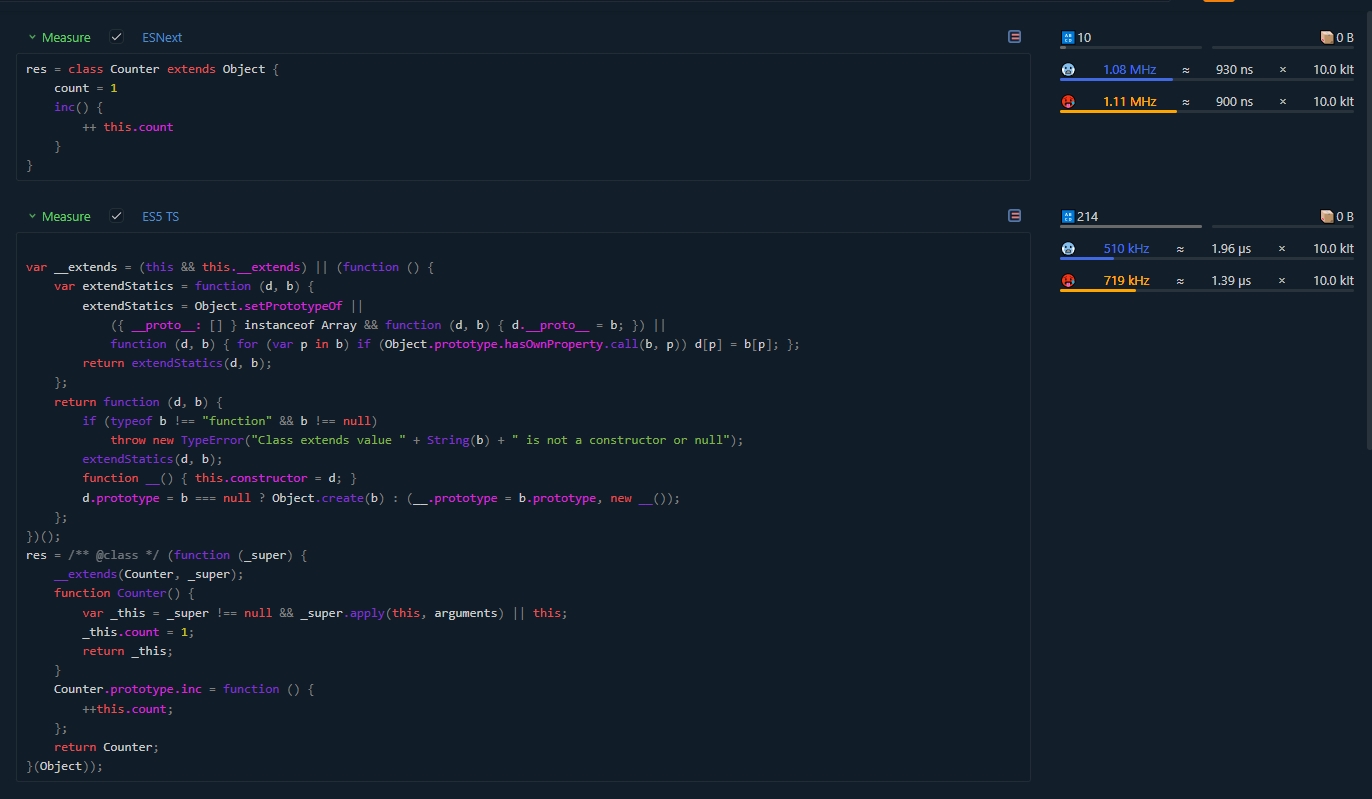

Выводы которые я вижу:
Бессмысленное наследование Object очень портит результат в всех случаях.
Объявления поля класса современным синтаксисом просаживает производительность вдвое
Таки да, в 2023 году мы видим что наконец обычное объявление Class стало таки быстрее. Но поле всё портит.
И тут интересно что когда я в 2017 году таки перешёл на ES5 (2009) прошло 8 лет с принятия стандарта, сегодня в 2023 прошло 7 лет с момента принятия es6(2015) в котором появились классы. И вот, наконец они быстры. Что интересно ни https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Classes/Public_class_fields ни https://github.com/tc39/proposal-class-fields не говорят в какой стандарт попали эти фичи. Но очередной раз я вижу как новый функционал в стандарте, даже спустя несколько лет после принятия тормозит. Должно пройти лет 7-10 чтобы он стал быстрым, и то не всегда.
Таким образом я признаю, что действительно есть конструкция из ES6 быстрее ES5, и возможно действительно сегодня уже стоит таргетиться в ES6. Но не свежее. И дело не только в тормозах, но и в том что в мире ещё осталось значительное количество клиентов на 32bit windows 7 которые сидят на старом хроме. Зависит от масштаба вашего бизнеса, но если у вас миллионы пользователей и монетизация ненулевая то выясняется что просто саппорт старых браузеров, достигаемой одной строчкой в виде таргета компилятора приносит существенное количество денег. И в идеале можно по userAgent отдать два разных билда, но на такое изврат даже я не готов.
P.S. а ещё что-то сломалось, вот тут https://perf.js.hyoo.ru/#!bench=twmjin_o4c5nl
Объявления поля класса современным синтаксисом просаживает производительность вдвое
Не всё так страшно. Ну OK, создание класса с полем стало занимать микросекунду вместо 600 наносекунд. Обратите внимание - класса, а не экземпляра класса. Это действие, которое обычно происходит только один раз в самом начале выполнения приложения (и поэтому надо смотреть на холодный замер).
Сколько классов может быть в современном жирном приложении, загружаемом в браузер? Если взять с потолка число в тысячу классов - с новым синтаксисом потребуется целая миллисекунда вместо 600 микросекунд. Даже если на старых компьютерах скорость выполнения в десятки раз медленнее - разница в скорости всё равно будет в десятках миллисекунд. Думаю, эта разница маловата, чтобы оправдать отказ от нового синтаксиса.
Интереснее было бы побенчмаркать создание экземпляров этих разных классов и вызов методов. Вы могли бы это сделать?
К сожалению снова погружаться в бенчмаркинг я не готов потому что нужно очень тщательно вновь разбираться в методологии предложенного инструмента и гонять множество тестов, это займёт несколько дней, у меня их нет. Тогда в 2017 на подготовку доклада ушло около 60 рабочих часов при том что я уже знал примерно что показывать. А сейчас я вообще в другом технологическом стеке и иногда вытираю слезу вспоминая простой и понятный мир js и превосходный typescript
Вы и сами легко можете это сделать: https://perf.js.hyoo.ru/#!bench=ovgci8_vzub6j

Что интересно ни https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Classes/Public_class_fields ни https://github.com/tc39/proposal-class-fields не говорят в какой стандарт попали эти фичи.
kangax говорит, что поля попали в стандарт 2022, хотя в браузерах есть в каком-то виде уже несколько лет, возможно отключенные по умолчанию. я проверил, в стандарте 2021 полей еще нет.
И тут интересно что когда я в 2017 году таки перешёл на ES5 (2009) прошло 8 лет с принятия стандарта, сегодня в 2023 прошло 7 лет с момента принятия es6(2015) в котором появились классы. И вот, наконец они быстры.
Да, есть такая проблема. Многое новые языковые фичи сначала были реализованы как сахар поверх существующего языка, то есть буквально в коде на JS или вообще на специальном языке Torque, который движок выполнял "под капотом". Только потом, постепенно, самый часто используемый код оптимизировался, переводился на C++. Но успел образоваться замкнутый круг: разработчики не использовали условный bind, потому что рукописный полифилл заметно быстрее, а браузеры не оптимизировали bind, потому что его никто не использует.
да, согласен что происходит именно это. Вопрос, зачем тогда тащить этит функционал в сам js, а не сосредоточиться только на его скорости и функционал который действительно даёт новые возможности типа тех же символов. Я за подход когда можно всё затакивать в typescrip или сделать диалект поверх babel, а сам низкойровневый js не раздувать.
Или вообще подвинуть JS, и приделать, наконец к WebAssembly доступ к Web API. После уже можно выдохнуть с облегчением и переписать все на раст /ш
А то получается комическая ситуация. Байткод, созданный для браузера может рулить полноценной операционной системой (см. WASI), но рулить браузером — нини, только через прослойки на JS и постоянную де/сериализацию всего туда-обратно
зачем вы явно написали extends Object, это же бессмысленная ересь
Большинство реальных классов от кого-нибудь наследуются.
Отладчик в Хроме показывает содержимое Symbol.toStringTag только для экзмепляров унаследованного класса.
вы, похоже, применяли babel (тут могу ошибаться, но он любит через defineProperty объявлять, и я абсолютно не понимаю зачем это делать)
Просто настройте TypeScript для совместимости с ESNext.
что-то сломалось, вот тут https://perf.js.hyoo.ru/#!bench=twmjin_o4c5nl
Что сломалось?
Не понимаю почему вас минусуют. Тем более без аргументов.
таргетиться в es5
Так просто бандл же больше будет если так делать.
Имхо все эти бенчмарки это конечно прикольно но на глаз никакой разницы между производительностью кода что с es3 что с es2020 не будет.
Ну конечно кроме редчайших 0.1% исключений где разница будет.
Результат неожиданный, но железно воспроизводимый. var, быстрее.
На моём Chrome "железной воспроизводимости" не получилось - результат 1, результат 2, результат 3. Что-то с настройками, или просто тест такой, что в моей системе он заглушается шумом?
Предполагаю, что да.
Попробуйте залочить все ядра на одну частоту, отключить C-State'ы и установить план питания на макс. производительность.
С настройками всё нормально. Если в бенчмарке для фронтенда, чтобы увидеть стабильную разницу, нужно играться с настройками железа - проблема не в настройках (99% пользователей этого не будут делать), а в самом бенчмарке, который пытается найти микроскопические отличия, легко съедаемые шумом и потому в большинстве случаев незаметные пользователю.
Что на третьем рисунке изображено?
Статья опасная на мой взгляд. Новички в JS могут пойти в излишнюю оптимизацию вместо того, чтобы думать головой. Возьмут за основу раздел про if/else/switch или array.filter().map() и будут сувать куда не поподя эти правила "оптимизации". А ещё var быстрее let и const...
Выводы из серии:
Я не пишу на Java.
Вы тоже прекращайте.
Статья опасная на мой взгляд
Так ведь любые знания опасны, мало ли как их будут использовать новички )
По-моему, статья норм, если промотивирует людей, которые никогда особо не задумывались о цене разных идиом, тестировать различные подходы в критичных по производительности местах.
Не всё, что в материале написано, будет работать в реальном коде прямо как на графиках – рантайм-оптимизация вообще очень тёмная и не всегда предсказуемая магия – но знать про масштабы этой магии под капотом точно не лишне.
А ещё var быстрее let и const
Это давняя история, с рождения. Есть, условно, базовая реализация var, очень давно и хорошо оптимизированная, и она поверх обмазана дополнительными ограничениями и механиками. Они не бесплатные.
Лиса быстрее, но она теперь падает регулярно. Я не уходил с Лисы до последнего, пока не стала падать.
Лиса с сотнями вкладок (знаю, это не лучшая практика, но у меня отложенные на почитать потом страницы так и висят в виде вкладок, упорядоченных в папочки расширением Sidebery), 26 расширений, открыта практически круглосуточно. Судя по данным about:crashes, которые подтверждаются личными воспоминаниями, за 2022 год она вылетала 3 раза. ЧЯДНТ?
Честно говоря я удивлён, что люди ещё ловят краши без внешних форс мажоров. Мои "краши" обычно выглядит как kil -9 в сторону процесса или жёсткое отключение питания.
Хотя я уже давно не пользовался 32-битными версиями.
Спасибо, даже не знал про эту вкладку. До недавнего падала вполне себе успешно, особенно в DevTools и при разработке всяких тяжёлых штук. Вот не далече как вчера пытался попрофайлить один фриз - колом вставала вкладка и у FF, и у хрома, висит, висит, а потом "а чо-та ничо не работает, давайте эту вкладку просто убьём". Т.е. технически FF не падает, но и сайтег не работает) ООМ, скорее всего, тоже не каждый раз посчитает, как и ситуации аля "сожрало 100% проца, всё висит, пришлось ресетнуть". Маппинг на отладочные штуки собранные через webpack на мою память никогда нормально не работал, ну т.е. он работает до первого изменения, а потом новые маппинги не подтягиваются, дебаж как хочешь.
Ну и пришлось выкосить всё кроме vimium, instapaper.
При этом переходить на хром всё равно не вариант, там бесит примерно всё, особенно отсутствие нормального Reader View

Исходных данных мало. Пишу свой опыт: FF 109 x64 (последний ESR релиз, может другой номер), Win7 SP1 x64, 3 дополнения, более ста вкладак. FF падала раза 4. Скорее всего на каких то определенных сайтах "текут" вкладки. Сам пока не вычислил
0 падений за последние, наверное, года 3. Всегда использую последнюю официальную версию, ОС Ubuntu 22, постоянно открыто 30 - 40 вкладок, куча закладок, куча дополнений интегрировано.
extensions

За последние лет 7 довелось поработать на различных домашних / служебных компах - 3 ноутбука, 4 десктопа.
Везде не было никаких падений, кроме одного рабочего десктопа, который мне дали 6 лет назад. Вот прям регулярно валилась Лиса именно на нём, по несколько раз за день.
Залез в БИОС, поигрался с настройками ОЗУ - тут же прекратила падать. Вот как рукой сняло проблему и потом за ещё год работы на этой машине по 5 дней в неделю по 8 часов - ни единого падения.
Из чего я для себя сделал вывод, что проблема хардварная: из-за кривых настроек БИОСа память начинает давать ошибки, к которым Лиса очень чувствительна. Не зря на серверах используется ECC-память (error-correcting code memory, память с коррекцией ошибок).
Придя домой, решил воспроизвести проблему на своём домашнем десктопе. Залез в БИОС и разогнал память выше указанного дефолтного значения 3000 МГц до 3200 МГц. Винда запускается, вроде бы всё нормально работает, а Лиса начинает падать каждые несколько минут. Вернул частоту к привычным 3000 МГц - стабильно работает до сих пор.
Так что смотрите, что у вас с памятью в компе, не разогнана ли чрезмерно, не барахлит ли питание. Если есть в БИОСе возможность управлять разгоном, то снизьте частоту / добавьте напруги / увеличьте тайминги.
Может вашу проблему уже пофиксили) https://hacks.mozilla.org/2022/11/improving-firefox-stability-with-this-one-weird-trick/
А у меня на ноутбуке линукс минт и фаерфокс. И почему-то фаерфокс при прокрутке плиток видео на ютубе, когда они подгружаются начинает дико тормозить. Решил на оперу перейти.
Ещё был релиз, который ронял видеодрайвер Intel при воспроизведении видео, но это тоже починили за месяц. И, зная качество видеодрайвера Intel, я не уверен, что это вина Firefox.
Ради производительности, циклы
for, лучше переделать вforEach, чтобы хром не отставал.
https://perf.js.hyoo.ru/#!bench=9w6t4a_4y41db
Хром

Лис

---
Трюк с
IndexOfбыстрее и на лисе, и на хроме. Используйте трюк сIndexOf
https://perf.js.hyoo.ru/#!bench=dn90ur_6qawpe
Хром

Лис

---
Я перепроверял, это не ошибка. Неявный каст стринги в инт практически бесплатный у лисы.
https://perf.js.hyoo.ru/#!bench=q4euna_ln9xk8
Хром

Лис

---
Я не пишу на JS.
Спасибо за полезные советы.
Простите за глупый вопрос, а что нарисовано на графиках? Каковы единицы измерения?
Результат неожиданный, но железно воспроизводимый. var, быстрее.
Вполне ожиданный: varу не нужно создавать скоуп, в котором будут объявлены переменные, потому что он уже есть. Поэтому, да, во вложенных циклах высокопроизводительного кода лучше всё-таки сделать var.
микробенчмарки? :) в этом надо разбираться прежде чем такие тесты лепить. для начала я не вижу среднеквадратичной ошибки в результатах. вопрос прогрева, отключения турбобуста на процессоре и т.д. тоже актуально.
Есть ли у переменной оверхед?
Во-первых, у меня ни на Intel ни на M1 не воспроизводится - отличия результатов находятся в пределах естественного разброса результатов бенчмарка, и в разных запусках рандомно лидирует разный вариант. Для проверки можно в одном бенчмарке сделать несколько тестов с одним и тем же количеством локальных переменных - между ними тоже будут заметные отличия.
Во-вторых, если проанализировать результат автора (кстати, было бы не лишним указать погрешность измерений, которую показал бенчмарк):
один
varи триmapдля массива на 65535 элементов занимают 1/345 секунды (345 ops/sec)три
varи триmapдля массива на 65535 элементов занимают 1/319 секунды (319 ops/sec)
v + 3*m = 1/345
3*v + 3*m = 1/319
где v - длительность (оверхед) одного var, m - длительность одного map массива из 65535 элементов
Получим v ≈ 118мс, m ≈ 927мс, то есть, утрируя, объявить девять лишних var - всё равно что обработать массив на 65 тысяч элементов? Объявление лишней промежуточной переменной не может быть настолько заметным. Кажется, этот бенчмарк измеряет что-то совсем другое.
Есть ли разница между var, let, const или их отсутствием?
Во-первых, не могу воспроизвести результат на Intel и M1 ни на бенчмарке автора, ни на своём. Самым быстрым в Firefox оказывается рандомно то const то вообще sloppy, а самый медленный результат отстаёт от него всего на 7-8 процентов.
Если посмотреть на код бенчмарка
var g = { e: [] }
g.o = function(x) { g.e.push(...[1,2,3]) }
g.o()
то можно увидеть, что он пытается измерять множество вещей одновременно: инициализацию переменной, создание объекта, создание функции, вызов функции, spread operator, garbage collector в рандомные моменты времени, и много чего ещё. То есть на одно создание переменной приходится три чтения и много других операций. Даже если автор прав и корректные результаты показывает только его бенчмарк, то результат применим только в ситуации, когда каждая переменная читается всего несколько раз и потом выбрасывается. И даже в такой ситуации замена const на var даст ускорение всего лишь во втором знаке после запятой - с 21463673 ops/sec до 21843333 ops/sec, то есть экономию в 0.81 наносекунды на одно выполнение вышеприведённого кода. Потребуются миллиарды итераций, чтобы суммарная разница достигла заметной глазу пользователя величины.
Конечно, теоретически разница не может равна нулю:
letв местах использования должен выполнять проверки на temporal dead zone и на область видимости, из-за этого он всегда немного медленнее, чемvarconstдолжен выполнять проверки на область видимости и на temporal dead zone; как только константа будет проинициализирована, проверку на temporal dead zone можно больше не выполнять
Но в приведённом бенчмарке я вижу, что вся разница тонет в шумах.
В итоге ответ на вопрос "увижу ли я профит от использования var" сильно зависит от конкретного кода и от конкретной версии движка. Например, в Fastify поглядели на бенчмарки и позволили себе в большинстве мест заменить var на const и let - в свежих версиях Node.js разницы в скорости не видно.
Поэтому на практике о такой мелочи можно не задумываться.
P.S. Кстати, раз уж упомянул Fastify - полезно посмотреть на пулл-реквесты с оптимизациями производительности раз два
Совершенно верно... Вообще очень странные тесты...
В конкретном случае - var vs let vs const vs sloppy там по большей части вообще измеряется spreading array mutations & push (+ память/кэш всех уровней, + GC, + тому подобное), но никак не заявленное в названии теста.
Если переписать тест хотя бы без вызова push и spread-op (что справедливо ибо объявленная g всё равно immutable), всё очень сильно изменится (и соответственно возможно var будет быстрее только лишь sloppy, проигрывая и let и const):
- g.o = function(x) { g.e.push(...[1,2,3]) }
+ g.o = function(x) { g.e.push }"Возможно" - потому что оверхед собственно измерения и соответственно шумы и погрешности будут много выше той незначительной разницы (если она вообще есть в SpiderMonkey или V8 при компиляции в браузере).<img src="боромир-мим.jpg"/> Нельзя просто взять и померить разницу в скорости var vs let vs const в JS в браузере, просто потому что там нет подходящего быстрого инструмента (цикла) для измерений, так чтобы при компиляции var, let или const результат не вырождался тупо в константное выражение, посчитанное на стадии компиляции цикла.
Т.е. даже что-то подобное нижеследующему вряд ли покажет ту разницу реально (и те +13ms или +173ms ниже тупо не являются какими-либо флуктуациями опять же из-за огромного overhead сверху):
// 1e9 итераций, const vs var:
(() => { const x = 1, X = {f: function() {return x}}; var v = 0; performance.mark('m1'); for (let i = 1e9; i > 0; i--) { v += X.f()+X.f()+X.f()+X.f()+X.f(); } performance.mark('m2'); })(); performance.measure('test', 'm1', 'm2')
► PerformanceMeasure {..., duration: 1057}
(() => { var x = 1, X = {f: function() {return x}}; var v = 0; performance.mark('m1'); for (let i = 1e9; i > 0; i--) { v += X.f()+X.f()+X.f()+X.f()+X.f(); } performance.mark('m2'); })(); performance.measure('test', 'm1', 'm2')
► PerformanceMeasure {..., duration: 1070}
// 1e10 итераций, const vs var:
(() => { const x = 1, X = {f: function() {return x}}; var v = 0; performance.mark('m1'); for (let i = 1e10; i > 0; i--) { v += X.f()+X.f()+X.f()+X.f()+X.f(); } performance.mark('m2'); })(); performance.measure('test', 'm1', 'm2')
► PerformanceMeasure {..., duration: 13077.5}
(() => { var x = 1, X = {f: function() {return x}}; var v = 0; performance.mark('m1'); for (let i = 1e10; i > 0; i--) { v += X.f()+X.f()+X.f()+X.f()+X.f(); } performance.mark('m2'); })(); performance.measure('test', 'm1', 'm2')
► PerformanceMeasure {..., duration: 13250.1}Разница от 20% до 30% в зависимости от runtime.
Условия воспроизведения не синтетический тест, а любой обьемный проект, например google docs.
Дело в том, что Вы и так понимаете, что разница происходит в ситуации когда рантайм должен проверять tdz. И если проводить тест, на сферическом коне в вакууме, то разница видна в пользу var, но она несущественна. И при єтом все сильно меняется когда Ваш проект наполняется тысячями идентификтарово которые используются в пределах до 10 000 раз в рамках одной функции (планка оптимизации кода для v8).
Вы тут же почувствуете ту самую разницу в 20-30% процентов которую захотите иметь. Тот же гугло докс до сих пор собирается только с варами именно по єтой причине.
Если Вам интересны детали вплоть до машинного кода который выдает оптимизатор v8 найдите на ютубе ведео: почему все неправильно используют var let и const за моим авторством. Где вплоть до машинного кода демонстрируется почему и когда єто все имеет значение.
Спасибо за видео, было интересно. Но есть несколько "но":
в показанном на видео бенчмарке время окончания измеряется после
console.log()- это добавляет в результат измерения шум, лучше так не делать (опять же, погрешность измерений никак не считается, и это плохо)в тесте видна разница в скорости выполнения неоптимизированного кода всего около 5%, а не 20-30%
И чтобы не сбивать с толку неопытных джунов, стоит ещё раз подчеркнуть, что измеренная разница в скорости в 5% (и предполагаемая в наихудшем случае разница в 20-30 процентов) достигается только в довольно необычных условиях - как вы упомянули, должны быть многие тысячи идентификаторов, и код должен выполняться интерпретатором, то есть он не должен стать горячим, чтобы не включился оптимизатор. Как только за дело берётся TurboFan - разница в лучшем случае пропадает и для let и для const, в худшем - становится намного менее заметной, особенно в абсолютных величинах. Об этом хорошо написал Benedikt Meurer.
У меня есть пример, когда в большом проекте на Node.js (если собрать только наш код без стандартных библиотек в один неминифицированный бандл - более 20 мегабайт) перевели весь код с var на let и const. Там уже существовала отлаженная инфраструктура контроля производительности, которая использовалась для проверок пулл-реквестов и релизов на незамедление скорости. Так вот, она не показала статистически значимых изменений в скорости выполнения.
Про console.log: вероятно Вы что то не так поняли, потому, что я никогда ничего не измеряю за пределами сферы вопроса, не говоря уже о том, чтобы включать в тест стороннее апи типа консоле лог. То есть я подчеркиваю, если Вы увидели где-то, консоле лог как фактор влияющий на тест, то Вы либо непоняли суть теста, либо смотрели не тот тест.
В тесте связанного с var let и const разница выше погрешности, может быть видна ТОЛЬКО В СЛУЧАЕ неоптимизированного кода. В случае оптимизированного кода, разницы нет и быть не может - єтот код оптимизирован. То есть Вы ошиблись в понимании того, что я показывал.
А именно, я показывал, что в случае кода, который не получит оптимизации от v8, разница в производительности между let и var около 20%. С учетом того, что в большом проекте таких идентификаторов сотни тысяч, єто не єкономия на спичках, а рельный прирост в производительности 20%. И привожу пример живой проек гугло докс, где таких идентификаторов миллионы.
И, что самое главное для моего теста, он не зависит от архитектуры, и почти не зависит от рантайма (v8 или coreJs etc...) поскольку, не нужно даже понимать что-то в архитектуре js рантайма, или вообще в программировании, чтобы понять - дополнительная логика стоит ресурсов, и гарантированно больших ресурсов, когда єта логика дублирует ту что была прежде: как let дублирует var но в рамках не свойственной для интерпретируемых языков структуре, которую обозвали декларативной.
Поймите, Вы не со мной спорите. Вы спорите с формальной логикой, где чтото, что имеет базу не может быть быстрее базы. И, что самое главное, когєа вы аппелируете к тому, что єта база мизерна с точки зрения затрат (єкономия на спичках) вам приводят в пример реальный, работающий с приемлемой производительностью очень сложный проект (гугло докс), где никаких лет и конст нет. И выпелины они именно в угоду производительности. Потому что в проекте где сотни тысяч деклараций, єкономия на спичках, становится равна миллионам.
Сомневаетесь? Возьмите реакт, и замените все лет и консты на вары, после чего замерьте. Будете удивлены.
Да, Вы правы в той части, что подобные рассуждения без разжовывания до молекулы, будут очень вредны для большинства. И я целиком с єтим согласен. Но именно за єто и все мои реплики - JS очень сложен для проффесионального использования. И статитьи подобной єтой крайне вредны, особенно в той форме в которой существует топикстартер.
Меня попросили даже разобрать примеры из статьи на видео, что я частично и сделаю, чтобы показать, насколько далек автор статьи, от того, чтобы иметь право хотя-бы думать о том, чтобы делать те выводы которые он сделал в своем материале.
Вы смотрите на говнокод (42к глобальных переменных в гуглдоксе), думая, что это великий замысел, в то время как это просто лютый легаси. Я несколько лет назад делал свой гуглдокс, который в 2-3 раза быстрее оригинала и в 1.5 жрёт меньше памяти. Глянул сколько там во всём бандле объявлений переменных - чуть больше тысячи. Ни о каких 10к и тем более "сотен тысяч деклараций", тем более в одной функции и речи быть не может. На действительно больших проектах узкие места вообще не в этом месте, а в эффективности использования памяти, в максимальном отсечении ненужных вычислений, и в асимптотике алгоритмов. Никакие замены let на var и class на function не дадут волшебным образом не то, что 20%, но даже 0.001%.
Про console.log: вероятно Вы что то не так поняли, потому, что я никогда ничего не измеряю за пределами сферы вопроса, не говоря уже о том, чтобы включать в тест стороннее апи типа консоле лог. То есть я подчеркиваю, если Вы увидели где-то, консоле лог как фактор влияющий на тест, то Вы либо непоняли суть теста, либо смотрели не тот тест.
Штош, вот скриншоты



Это код бенчмарка из того самого видео https://youtu.be/msrbSSZQApI?t=1808, где вы показываете разницу в 5% скорости между var и let/const при выполнении неоптимизированного кода. Между двумя замерами performance.now() есть вывод в консоль. Суть теста я понимаю, и ещё раз напомню своё замечание:
в показанном на видео бенчмарке время окончания измеряется после console.log() - это добавляет в результат измерения шум
Далее.
То есть Вы ошиблись в понимании того, что я показывал. А именно, я показывал, что в случае кода, который не получит оптимизации от v8, разница в производительности между let и var около 20%. С учетом того, что в большом проекте таких идентификаторов сотни тысяч, єто не єкономия на спичках, а рельный прирост в производительности 20%.
Просто внимательно перечитайте мой комментарий - я пишу ровно о том же:
измеренная разница в скорости в 5% (и предполагаемая в наихудшем случае разница в 20-30 процентов) достигается только в довольно необычных условиях - как вы упомянули, должны быть многие тысячи идентификаторов, и код должен выполняться интерпретатором, то есть он не должен стать горячим, чтобы не включился оптимизатор. Как только за дело берётся TurboFan - разница в лучшем случае пропадает и для let и для const, в худшем - становится намного менее заметной, особенно в абсолютных величинах.
Далее.
И привожу пример живой проек гугло докс, где таких идентификаторов миллионы.
На странице с открытым документом Google Docs насчитал в исходниках всего около 65000 объявлений переменных через var (var a, b, c считал за три объявления переменных). Не вижу миллионы. Считал var поиском по подстроке, список имён в одном var считал регуляркой, поэтому мог ошибиться, но не на два порядка (вместо миллионов насчитал десятки тысяч).
Сомневаетесь? Возьмите реакт, и замените все лет и консты на вары, после чего замерьте. Будете удивлены.
В предыдущем комментарии уже написал, что разницы в своём проекте не заметил.
Преобразование строки в число
Прямо классика
TL;DR: Бенчмарк показывает фантастические результаты в Firefox только потому, что оптимизатор понимает: на вход всегда поступает одна и та же строка, отсутствуют вызовы функций с заранее неизвестными сайд-эффектами, а результат преобразования нигде не используется, значит все вычисления можно выбросить.
Более правильный бенчмарк с минимальной попыткой подсунуть разные числа и хоть как-то использовать результат преобразования сразу возвращает с небес (1E+09 ops/sec) на землю.
В чём смысл этой статьи? Сравнивать хром и лису только чтобы заключить "Я не пишу на JS и вам не советую"? Где нормальный вывод?
Допустим. А что дальше? Лиса может быть и быстрее и лучше и даже лучше оптимизированее. Только ею пользоваться невозможно. Пишут свои веб стандарты которым на остальные все равно, ui тупит как в 2005 или хуже, по тестам на хабре же - сливает ещё больше данных чем хром.
по тестам на хабре же - сливает ещё больше данных чем хром.
Можно ссылку на такие тесты?
к сожалению, того теста о котором я говорю, я сейчас уже не найду, ибо дело было в пределах 21-22 годов. В попытках найти нашел другую, хоть и намного менее конкретную статью но не менее занимательную. https://habr.com/ru/company/brave/blog/551588/
Одна цифра в 2700 запросов и целый абзац с детальным списком отправляемой инфы уже говорит о "защищенности" и "приватности" "самого приватного и безопасного браузера". Нашел бы оригинальную статью о которой говорил - с радостью, отправил бы.
Пишут свои веб стандарты
Вы как то перепутали сторону, свои веб стандарты пишет гугл. А весь интернет радостно поддакивает. Вот только с адблоком прокол вышел.
ui тупит как в 2005 или хуже
Тут вообще без комментариев.
Эти стандарты как минимум принимаются на широком уровне - оно и хорошо. Времена, когда один браузер умел одно, другой другое, третий ни того ни того а четвертый, извиняюсь, в песочнице жевал свои слюни - уже должны были давно пройти. Мы не в нулевых. Или хотя бы не при Медведеве. И гугл сделал очень многое для создания этой унификации. Но вместо этого у нас досих-пор 27 стандартов и половина из них легаси которая непонятно почему еще живет и орёт о уважении к себе.
Если вы занимались разработкой сайтов, не используя новомодных технологий вроде вебпака или прочей лабуды, которая за вас 8\10 проблем решает, то вы должны знать насколько лиса капризна. Отсутствующие кодеки видео банально, другие именования вещей вроде стилей или тех самых кодеков при ручном указывании, даже изменить полоску прокрутки - целое событие над которым надо посидеть что бы оно заработало. Свои стандарты, вроде добавления сайтами в нативное меню кнопок. Вопрос зачем и почему. А потом приходит некто и спрашивает "ой а почему у меня кнопочки нету" после лисы. Свои апи в js, часть которых либо во всем остальном мире депрекейтед либо вообще оффициально не поддерживается (какой нибудь XPConnect , например, если мне не подводит память он все еще поддерживается в лисе или mozGetUserMedia условный. И да, ничего против обратной совместимости я не имею но не настолько)
Если вы работали на средне-слабом \ старом железе в лисе, то вы знаете как безбожно она может тупить. Начиная от интерфейса который банально виснет от первого пука, заканчивая нагрузкой процессора при более десятка открытых вкладок. Не всегда и не во всех случаях но такое бывает время от времени. На хроме же - кроме потребления памяти на моей памяти ничего не было. Даже что бы заставить хром зависнуть - надо постараться. Хром еще с 2012-2014 когда я с ним впервые познакомился - летал. Для лисы же, для достижения подобной скорости и удобства, потребовался громкий релиз квантум (или как он там называется?). Однако на счет последнего я утерждать не берусь - слышал по осколкам. Как сейчас обстоят дела - врать не буду - не знаю - однако еще пару лет назад лично на моем опыте было в десяток раз больше проблем чем потенциальных плюсов.
Кстати, по этому скорее беглому тесту нежели статье, потребление лисы далеко не самое эталонное в сравнение с каким нибудь хромом, несмотря на данную статью: https://habr.com/ru/post/589923/
Если же не работали с сайтами или у вас никогда не было ничего древнего и бородатого старше чем на 5 лет - вам видимо просто очень повезло. К счастью или же нет.
Альтернатива нужна. Но учитывая текущие реалии и масштабы горя, это крайне трудоёмкий или даже непосильный без всемасштабного движа процесс. И лиса хоть и пытается быть в тренде, проигрывает не просто так и не просто из за бытия в тени большого брата гугла.
И гугл сделал очень многое для создания этой унификации. Но вместо этого у нас досих-пор 27 стандартов и половина из них легаси которая непонятно почему еще живет и орёт о уважении к себе.А, это тот самый гугл, который придумал API Shadow DOM v0, реализовал его в Chromium, потом объявил его deprecated и разработал Shadow DOM v1?
Все остальные браузеры, при этом, Shadow DOM v0 пропустили вообще.
Вы же в курсе, что firefox это не лиса?
https://facts.museum/3181#:~:text=Название браузера Mozilla Firefox не,малой панды в малой форме.
У них даже на логотипе лиса...
они сами не поняли, что имели ввиду - https://support.mozilla.org/en-US/questions/988854
но именно firefox - это не лиса, а красная панда
Логотип Firefox конечно все более минималистичен с каждой новой версией, но как минимум первые десять лет на нем отчетливо узнается слева лиса, а справа огонь. Причем там даже пигментация морды прорисована, а так же характерные щеки, острые длинные рыжие уши, тонкие рыжие лапы, длинная морда, острый нос, хвост без полос и т.д. и т.п. Т.е. полное совпадение с тем, как выглядит обычная лиса, и полная противоположность тому, как выглядит красная панда.
{kind=link}
{kind=link}
{kind=link}
А если на логотипе лиса и огонь, то значит назван он в честь лисы и огня. Более того, он чисто исторически был сначала Phoenix, потом Firebird, а потом bird поменяли на fox, а fire всегда был центральной темой логотипа.
А вы в курсе, что морская свинка не имеет никакого отношения ни к морю, ни к свиньям?
Сижу на Firefox ESR 32-bit. Памяти ест меньше, тормоза или нестабильности - исключительно редко.
Единственное, что "сломалось" на каком-то из обновлений, так это Web UI торрент-клиента transmission (кнопки и меню не работают, в Edge при этом норм).
К сервису measurethat, и к тем тестам, которые на нем пишут, вопросы возникали уже не раз. И некоторые Ваши тесты не исключение.
Но тест "Инициализация массива", это просто уже яркий пример того, что нужно задумываться.
По вашему тесту получается что, вместо того, чтобы просто создать массив и пройтись по нему один раз циклом, я сначала вызову метод "fill()", который внутри пройдет по нему циклом и заполнит "undefined", потом вызову "map(initializer)", который под капотом создаст новый массив и снова пройдет циклом заполняя его результатами функции "initializer". И вот это вот все будет работать в хроме быстрее В ВОСЕМЬ РАЗ (998 / 127)? Серьезно?
На сколько мне известно, когда хром видит в коде стандартный цикл "for(...) {...}", он может оптимизировать код внутри блока так, как если бы это был код внутри функции, т.е. если нет сайд-эффектов, то он может полностью выпилить весь код в блоке. Но сам цикл он оставляет и будет его итерировать, т.к. это стандартная статическая языковая конструкция и она "невыпиливаемая". (Простой пример, написать "for(;true;);", и браузер успешно намертво зависнет).
Когда вы тестируете "new Array(times).fill().map(initializer)", ваш массив никуда не возвращается и нигде больше не используется и для хрома, после оптимизации, является "мертвым", а далее вы вызываете встроенные в движок методы массива, который для хрома уже не более чем "мусор". И передаете функцию "initializer", которая не имеет сайд-эффектов и ее даже необязательно вызывать.
Оптимизация)
На деле же, все это будет работать раза в 4 медленнее.
Добро пожаловать в реальный мир)))
const times = 65535
function initializer(val, z) {
const i = z % 5 | 0
return (z % 3 | 0) == 0 ? i === 0 ? 'fizzbuzz' : 'fizz' : i === 0 ? 'buzz' : z
}
function test_for() {
// Bench for
let b1
console.time('bench for')
for (let j = 0; j < 1000; j++) {
b1 = new Array(times)
for (let i = 0; i < times; i++) {
b1[i] = initializer(b1[i], i)
}
}
console.timeEnd('bench for')
// console.log([b1])
return b1
}
function test_map() {
// Bench fill map
let b2
console.time('bench map')
for (let j = 0; j < 1000; j++) {
b2 = new Array(times).fill().map(initializer)
}
console.timeEnd('bench map')
// console.log([b2])
return b2
}
setTimeout(test_for), setTimeout(test_map)
setTimeout(test_for), setTimeout(test_map)
setTimeout(test_for), setTimeout(test_map)
setTimeout(test_for), setTimeout(test_map)
/*
bench for: 568.27294921875 ms
bench map: 1711.642822265625 ms
bench for: 594.904052734375 ms
bench map: 1728.125732421875 ms
bench for: 478.802978515625 ms
bench map: 1684.43798828125 ms
bench for: 474.054931640625 ms
bench map: 1763.044189453125 ms
*/
.
Поддерживаю.
Для теста:
▍ Итерация по массиву
Имеем результат на моем компьютере: for i x 153 ops/sec ±0.28% (63 runs sampled) в хроме и for i x 11,522 ops/sec ±0.51% (62 runs sampled) в firefox
Открываем консольку, запускаем
var array = new Array(65535).fill(0);
var q = 0;
var t1 = performance.now();
for (var repeat = 0; repeat < 100; repeat++) {
for (var i = 0; i < array.length; i++) {
q = array[i] * array[i];
}
}
console.log(performance.now() - t1); Ожидания:
Хром: ~800ms (100 iterations * 153 it/sec)
Firefox: ~ 1ms (100 iterations * 11 522 it / sec)
Реальность:
Хром: 14.5ms
Firefox: 3799ms
(Изначальный тест был с сотней повторов, но фаирфокс так вообще не умеет).
Вывод: я знаю что запустить такой тест в консоли бессмысленно, консоль может выполняться без jit, быть непрогретой и тому подобное, но результаты консоли слишком сильно расходятся с результата бенчмарка, причем для хрома в 60 раз в пользу консоли, для FF в несколько тысяч раз в сторону бенчмарка. Короче: весь бенчмарк показывает близкие к случайным числам, поэтому никакие выводы на его основе делать я бы тоже не стал.
Да согласен, потому что бенчмарки так не пишутся.
Но проблема в том, что люди прочитав статью, могут это все принять за чистую монету, и потом пойдут все свои циклы "for" на "map" или "forEach" переписывать, думая что у них после этого перфоманс в 8 раз взлетит. Хотя в действительности так не будет.
Действительность:
const arr = new Array(65536).fill(0)
function callback(v, k, a) {
a[k] = v + k
}
function test_for() {
console.time('bench for')
for (let j = 0; j < 1000; j++) {
for (let i = 0; i < arr.length; i++) callback(arr[i], i, arr)
}
console.timeEnd('bench for')
}
function test_forEach() {
console.time('bench forEach')
for (let j = 0; j < 1000; j++) {
arr.forEach(callback)
}
console.timeEnd('bench forEach')
}
setTimeout(test_for), setTimeout(test_forEach)
setTimeout(test_for), setTimeout(test_forEach)
setTimeout(test_for), setTimeout(test_forEach)
setTimeout(test_for), setTimeout(test_forEach)
setTimeout(test_for), setTimeout(test_forEach)
setTimeout(test_for), setTimeout(test_forEach)
setTimeout(test_for), setTimeout(test_forEach)
setTimeout(test_for), setTimeout(test_forEach)
setTimeout(() => { console.log(arr) }, 100)
// РЕЗУЛЬТАТ:
/*
bench for: 478.824951171875 ms
bench forEach: 973.968994140625 ms
bench for: 471.277099609375 ms
bench forEach: 934.132080078125 ms
bench for: 124.044921875 ms
bench forEach: 924.15087890625 ms
bench for: 128.7451171875 ms
bench forEach: 929.00927734375 ms
bench for: 123.68798828125 ms
bench forEach: 919.563232421875 ms
bench for: 123.55908203125 ms
bench forEach: 150.320068359375 ms
bench for: 123.626953125 ms
bench forEach: 148.734130859375 ms
bench for: 124.884033203125 ms
bench forEach: 148.5390625 ms
*/Такие бенчмарки не то что бесполезные, даже вредные. Лучше бы скрыть статью и забыть о ней, меньше вреда будет.
ыбло бы неплохо привести единицы измерения на графиках, и комментарий вроде "меньше - лучше" и "больше - лучше", а то неочевидно, кто кого уделал.
Статья ужасна — практически во всех тестах допущены грубейшие ошибки, полностью вводящие читателей в заблуждение (особенно в конце — это наихудшие тесты, которые я видел в своей жизни).
Начнём с начала:
Есть ли у переменной оверхед?
Во-первых, код, хоть и даёт одинаковый результат, но код неидентичен, т.к. в первом варианте мы проходимся по новым массивам, а в остальных по исходному.
Большинство времени в этом тесте тратится на создание массива, его заполнение и проход по нему, т.к. в нём аж 65 тыс элементов, а переменная всего лишь одна. Из-за этого отличия должны быть в пределах погрешности. Если у вас есть отличия, должна быть разгадка. Дело явно не в просто "создании переменной". Найдите эту разгадку и расскажите читателям, но не вводите читателей в заблуждение. Скорее всего разгадка в первом пункте, т.к. мы проходимся по разным массивам.
Есть ли разница между var, let, const или их отсутствием?
Во-первых, переменная "g" является частью потенциального замыкания. Т.е. мы тестируем не разницу между const, let и var, а разницу между ними в сочетании с потенциальным замыканием. Потенциальные замыкания — очень сложная тема в Javascript, и здесь крайне желательно очень глубокое понимание языка, а также таких общих вещей, как организация стека вызовов функций, регистры процессора, принципы работы компиляторов, принципы компиляции и оптимизации переменных и т.д.
Такие вещи нужно тестировать в цикле, особенно если код у вас действительно в каждом тесте компилировался заново (в чём я сомневаюсь). В противном случае Вы рискуете получить просто время компиляции. Если цель была показать именно это, то нужно было явно это указать. Но нам в первую очередь важно не время компиляции кода, а время исполнения тех строк кода, которые могут быть вызваны многократно, т.к. чем больше они вызываются, тем больше они влияют на производительность. Основное влияние оказывают многократно вызывающиеся строки. В Вашем же тесте строка вызывалась только один раз, из-за чего она не получила должные оптимизации, которые были бы при многократном вызове. Вы должны знать, что количество вызовов влияет на оптимизацию в Javascript.
Если мы используем const, с большой вероятностью мы создадим переменную один раз, а читать её будем много раз. В Вашем тесте такой сценарий не учитывается.
Bounce pattern, Switch case, длинная тернарка
У Вас вышло, что Chrome позволяет вызвать функцию bounce 15 млрд раз в секунду. Если Вы смогли на каком-то из тестов получить более 5 млрд операций в секунду на частоте 5 ГГц, то Вы должны отдельно объяснить это, т.к. обычно это невозможно. Например, Вы можете сказать, что это благодаря векторным инструкциям, которые позволяют делать сразу много операций за такт. Но скорее всего Ваши тесты просто некорректны, и, поскольку Вы вычисляете одно и тоже, да ещё и игнорируете результат, Ваши вычисления опускаются или сокращаются. В итоге Вы хотели потестить switch case vs if, а в реальности потестили совсем другое. К switch case это никакого отношения не имеет.
Там, где Вы запускали один раз, таких гигантских значений нет. Но Ваша проблема опять же в том, что Вы тестируете на одинаковых значениях, что позволяет убрать лишние вычисления. Такие тесты не дают представления о скорости работы if / switch case. +Как я говорил выше, запускать один раз — не лучшая идея.
Инициализация массива
Ужасный тест. Здесь в двух вариантах Вы делаете чтение пропущенных элементов массива. Это абсолютно отдельная тема. Другими словами, Вы тестировали абсолютно не то, что указано в заголовке, вводя читателей в заблуждение. Кроме того, это является антипаттерном — обычно мы не читаем отсутствующие элементы массива, а вначале инициализируем массив. Другими словами, такого кода нужно избегать. Глупо тестировать код, которого не должно быть в продакшене.
Конкатенация массивов
reduce у Вас имеет квадратичную сложность вместо линейной, непонятно, зачем включать сюда такой тест. Вы хотели доказать, что квадратичная сложность хуже линейной? Тогда нужно было явно упомянуть это.
Если Вы увидели, что "reduce forEach push" быстрее, чем "forEach forEach push", стоило упомянуть, что, возможно, это связано с потенциальным замыканием.
flat даже в Firefox работает значительно медленее. Либо эту функцию ещё просто не успели прооптимизировать, либо в её спецификацию входит что-то такое, что заставляет её работать медленнее. Нужно добавлять такие комментарии в статью, предварительно посмотрев доки flat().
Итерация по массиву
Вы тестировали не итерацию по массиву, а именно создание массива. Это совсем разные вещи с разной производительностью. Не вводите читателей в заблуждение.
Содержит ли строка значение
Простите, но в Вашем тесте Firefox выдал 32 млрд операций в секунду, при том что у Вас процессор на частоте 5 ГГц (хотя эти 32 млрд можно пооптимайзить). А разгадка как всегда в том, что Вы по факту запускаете одинаковый код, и Firefox просто тупо заменяет его на результат вычислений. Как только Вы начинаете добавлять вариативность или немного модифицируете код, производительность indexOf внезапно вместо 1 млрд запусков в секунду начинает быть такой же, как и у других методов, которые Вы привели. Никакой магии в реализации indexOf нет.
Такая же ошибка есть и практически во всех остальных тестах.
Преобразование строки в число
Абсолютно такая же ошибка. Firefox в данном тесте убирает это преобразование и просто сразу подставляет ответ. Никакого 1 млрд преобразований в секунду нет.
Запомните: тесты должны запускаться на разных данных, а результаты вычислений хоть в каком-то виде должны использоваться в конце, например, выводиться в консоль. Если этого не сделать, оптимизатор может просто вырезать лишний код или сразу подставить результат вычислений на этапе компиляции или оптимизации функции. Вы должны убедиться, что оптимизатор не может вырезать лишний код.
Лисичка похорошела
Вы лишь показали, что Firefox иногда может вырезать лишний код, если одно и то же зачем-то запускается миллиард раз (т.е. в случаях, когда проводятся бесполезные вычисления). Это не идёт в плюс Firefox. У Firefox'а есть бесконечное количество других плюсов, которые делают его лучшим браузером, но Javascript-движок — не один из них.
JS сделан за неделю на коленке
Этот вывод основан на неверных тестах, из которых Вы сделали вывод, что многие вещи сильно недооптимизированы, а можно было лучше.
Впрочем, некоторые новые возможности языка действительно могут работать медленнее старых. Это не повод их не использовать, т.к. обычно это лишь вопрос времени. Тем не менее, если у Вас есть какой-то очень загруженный кусок кода, то именно в этом куске действительно можно проверить языковые конструкции на предмет скорости, и проверить именно текущую скорость, а не ту, которая будет через сколько-то лет. Но это касается только действительно загруженных мест.
А по поводу статьи — поскольку каждый раздел статьи вводит читателей в заблуждение, я советую скрыть статью.
Итог из прочитанного. Даже на 9900К js тормозит и его нужно подкостыливать. Спасибо за бенчмарки.

Миллиарды транзисторов обслуживают лишнюю тормозную прослойку в виде js.
Js, трюки, наблюдения, бенчмарки и как Лиса уничтожает Хром. Я протестировал всё, что вам было лень