

Серверный узел с восемью GPU-ускорителями AMD Instinct MI325X (2,3 ТБ видеопамяти, 8×750 Вт)
Современные дата-центры уже не такие, как прежде. Раньше на типичный сервер поставили бы 144-ядерный CPU, много RAM и десяток HDD/SSD. Но теперь приоритеты меняются, в первую очередь из-за высокого спроса на машинное обучение (ML) и приложения LLM. Хотя аппетит к памяти только вырос, но процессоры нужны другие.
И крупным корпорациям, и маленьким компаниям нужно железо для обсчёта ИИ-приложений. Это GPU-ускорители, NPU (Neural Processing Unit) и TPU (Tensor Processing Unit), AI-чипы нового поколения. Нужны серверы с GPU. Открываются даже специализированные GPU-облака на растущем спросе.
Такой тренд виден и на потребительском рынке. Всё больше компаний хотят запускать ИИ у себя, поэтому ставят мейнфреймы прямо в офисе, как предки в 70-е годы. Даже на ПК и ноутбуках за последний квартал 14% проданных устройств было оснащено специализированной микросхемой с аппаратным ускорением AI.
Посмотрим, какое конкретно железо ставят на серверы и ПК.
▍ AMD и Nvidia
Например, AMD представила новый GPU-ускоритель для дата-центров Instinct MI325X, который станет доступен для заказа в конце 2024 года:

Сам процессор GPU здесь не отличается от предыдущей модели MI300X, зато память HBM3 заменили на более быструю и плотно упакованную HBM3E, что позволит выпустить ускорители с объёмом памяти до 288 ГБ, а локальная пропускная способность памяти достигает 6 ТБ/с.
Получается, что в типичном сервере на восемь ускорителей Instinct MI325X (как на КДПВ) будет 2,3 ТБ памяти. Этого достаточно для загрузки LLM с триллионом параметров на одном лишь серверном узле. А представьте, какие возможности у большого кластера!
Нужно заметить, что Nvidia тоже недавно обновила свой ускоритель H100 до H200, сделав апгрейд памяти с HBM3 на HBM3E:

Nvidia H200
Вот сравнительная таблица с характеристиками Nvidia для понимания, что сейчас ставят в дата-центрах для решения задач ML.
| H200 | H100 | A100 (80 ГБ) | |
| Ядра FP32 CUDA | 16896? | 16896 | 6912 |
| Тензорные ядра | 528? | 528 | 432 |
| Макс. частота | 1,83 ГГц? | 1,83 ГГц | 1,41 ГГц |
| Частота памяти | ~6,5 Гбит/с HBM3E | 5,24 Гбит/с HBM3 | 3,2 Гбит/с HBM2e |
| Шина памяти | 6144-bit | 5120-bit | 5120-bit |
| Пропускная способность памяти | 4,8 ТБ/с | 3,35 ТБ/с | 2 ТБ/с |
| VRAM | 141 ГБ | 80 ГБ | 80 ГБ |
| Вектор FP64 | 33,5 TFLOPS? | 33,5 TFLOPS | 9,7 TFLOPS |
| Тензор INT8 | 1979 TOPS? | 1979 TOPS | 624 TOPS |
| Тензор FP16 | 989 TFLOPS? | 989 TFLOPS | 312 TFLOPS |
| Тензор FP64 | 66,9 TFLOPS? | 66,9 TFLOPS | 19,5 TFLOPS |
| Межсоединения | NVLink 4 18 линий (900 ГБ/с) |
NVLink 4 18 линий (900 ГБ/с) |
NVLink 3 12 линий (600 ГБ/с) |
| GPU | GH100 (814 мм²) |
GH100 (814 мм²) |
GA100 (826 мм²) |
| Количество транзисторов | 80 млрд | 80 млрд | 54,2 млрд |
| TDP | 700 Вт | 700 Вт | 400 Вт |
| Техпроцесс | TSMC 4N | TSMC 4N | TSMC 7N |
| Интерфейс | SXM5 | SXM5 | SXM4 |
| Архитектура | Hopper | Hopper | Ampere |

Ну а флагманским продуктом Nvidia станет ускоритель Grace Blackwell Superchip (GB200), составленный из двух Blackwell GPU и 72-ядерного Grace CPU, он будет вдвое производительнее B200, а TDP вырастет до 2700 Вт.
Три основных производителя памяти уже поставляют (или анонсировали) стеки памяти HBM3E объёмом 36 ГБ, что на 50% больше, чем нынешние топовые стеки HBM3 на 24 ГБ. За счёт этого AMD и смогла увеличить максимальный объём памяти со 192 до 288 ГБ на одном ускорителе.

Нужно сказать, что память HBM3 сейчас в дефиците. Например, Micron продала весь выпуск до конца 2024 года (и большую часть 2025 г.).
Кроме более высокой плотности, HBM3E обеспечивает более высокую тактовую частоту памяти. Micron и SK hynix рассчитывают в конечном итоге продавать стеки с пропускной способностью 9,2 Гбит/с на контакт, а Samsung хочет выйти на 9,8 Гбит/с на контакт, что более чем на 50% превышает скорость передачи данных 6,4 Гбит/с в обычной HBM3. Однако пока неясно, когда мы увидим память на таких скоростях.
AMD пообещала каждый год выпускать новый GPU-ускоритель для дата-центров:

В ближайшие годы AMD запустит две новые архитектуры CDNA и соответствующие продукты Instinct в 2025 и 2026 гг. Серия MI350 на базе CDNA 4 выйдет в 2025 году, а за ней в 2026 году последует ещё более амбициозная серия MI400, основанная на архитектуре CDNA 'Next'.
Сравнительные характеристики ускорителей от AMD:
| MI325X | MI300X | MI250X | MI100 | |
| Вычислительные юниты | 304 | 304 | 2×110 | 120 |
| Матричные (тензорные) ядра | 1216 | 1216 | 2×440 | 480 |
| Потоковые процессоры | 19456 | 19456 | 2×7040 | 7680 |
| Макс. частота | 2100 МГц | 2100 МГц | 1700 МГц | 1502 МГц |
| Вектор FP64 | 81,7 TFLOPS | 81,7 TFLOPS | 47,9 TFLOPS | 11,5 TFLOPS |
| Вектор FP32 | 163,4 TFLOPS | 163,4 TFLOPS | 47,9 TFLOPS | 23,1 TFLOPS |
| Матрица FP64 | 163,4 TFLOPS | 163,4 TFLOPS | 95,7 TFLOPS | 11,5 TFLOPS |
| Матрица FP32 | 163,4 TFLOPS | 163,4 TFLOPS | 95,7 TFLOPS | 46,1 TFLOPS |
| Матрица FP16 | 1307,4 TFLOPS | 1307,4 TFLOPS | 383 TFLOPS | 184,6 TFLOPS |
| Матрица INT8 | 2614,9 TOPS | 2614,9 TOPS | 383 TOPS | 184,6 TOPS |
| Частота памяти | ~5,9 Гбит/с HBM3E | 5,2 Гбит/с HBM3 | 3,2 Гбит/с HBM2E | 2,4 Гбит/с HBM2 |
| Шина памяти | 8192-bit | 8192-bit | 8192-bit | 4096-bit |
| Пропускная способность памяти | 6 ТБ/с | 5,3 ТБ/с | 3,2 ТБ/с | 1,23 ТБ/с |
| VRAM | 288 ГБ (8×36 ГБ) |
192 ГБ (8×24 ГБ) |
128 ГБ (2×4×16 ГБ) |
32 ГБ (4×8 ГБ) |
| ECC | Да (Full) | Да (Full) | Да (Full) | Да (Full) |
| Каналы Infinity Fabric | 7 (896 ГБ/c) |
7 (896 ГБ/c) |
8 | 3 |
| TDP | 750 Вт | 750 Вт | 560 Вт | 300 Вт |
| GPU | 8x CDNA 3 XCD | 8x CDNA 3 XCD | 2x CDNA 2 GCD | CDNA 1 |
| Количество транзисторов | 153 млрд | 153 млрд | 2×29,1 млрд | 25,6 млрд |
| Техпроцесс | XCD: TSMC N5 IOD: TSMC N6 |
XCD: TSMC N5 IOD: TSMC N6 |
TSMC N6 | TSMC 7 нм |
| Архитектура | CDNA 3 | CDNA 3 | CDNA 2 | CDNA (1) |
| Форм-фактор | OAM | OAM | OAM | PCIe |
| Дата выпуска | IV кв. 2024 | 12/2023 | 11/2021 | 11/2020 |
▍ Google, Amazon и др.
Google, Amazon и некоторые другие корпорации разрабатывают специализированные TPU для собственных дата-центров. Например, Google занимается этим более десяти лет.

TPU — это интегральная схема специального назначения (ASIC), созданная для одной конкретной цели: выполнения уникальной матричной и векторной математики для построения и работы моделей ИИ.
Первый такой чип TPU v1 вышел в 2015 году и сразу стал хитом в разных подразделениях Google.
Инженеры предполагали, что сделают не более 10 000 таких чипов, но в итоге создали более 100 000 для поддержки различных проектов Google, включая рекламу, поиск, речевые проекты, AlphaGo и даже некоторые беспилотные автомобили.
За прошедшее с тех пор десятилетие TPU сменили несколько поколений, повысив производительность и эффективность, и теперь служат основой для ИИ почти во всех продуктах Google.
Сейчас в строю уже шестое поколение TPU под названием Trillium:

Кроме перечисленных компаний, серверные AI-процессоры собирается выпустить MediaTek по техпроцессу TSMC 3 нм. Они также разрабатывают AI-чипы для ПК в сотрудничестве с Nvidia (для конкуренции с линейкой ARM-процессоров Snapdragon X Elite.
MediaTek ориентируется скорее на средний и нижний сегменты AI-серверов (в отличие от Nvidia и AMD). Это очень перспективная ниша, в которой действуют ещё ряд стартапов.
▍ Микросхемы AI для ПК
Что касается AI-чипсетов для настольных компьютеров и ноутбуков, то здесь доминирует компания Apple c чипами M-серии (M3, M4), которые оснащены ускорителем Neural Engine. Она и внесла львиную долю в упомянутые 14% проданных компьютеров с аппаратным ускорением AI во II кв. 2024 года.
Весной также были представлены новые ARM-ноутбуки Copilot+ с процессорами Qualcomm Snapdragon X (аппаратное ускорение AI).
На платформе x86 компания Intel выпустила чипсеты Core Ultra (и плагины OpenVINO для использования нейросетей с аппаратным ускорением в GIMP и других программах), а компания AMD в июле — линейку процессоров Ryzen AI 300 для ноутбуков.

Ryzen AI 300
Ryzen AI 300 — первые процессоры с ядрами Zen 5. У них мощный интегрированный GPU, а также ядро Radeon с поддержкой RDNA 3.5 и до 16-ти вычислительных блоков в зависимости от модели.
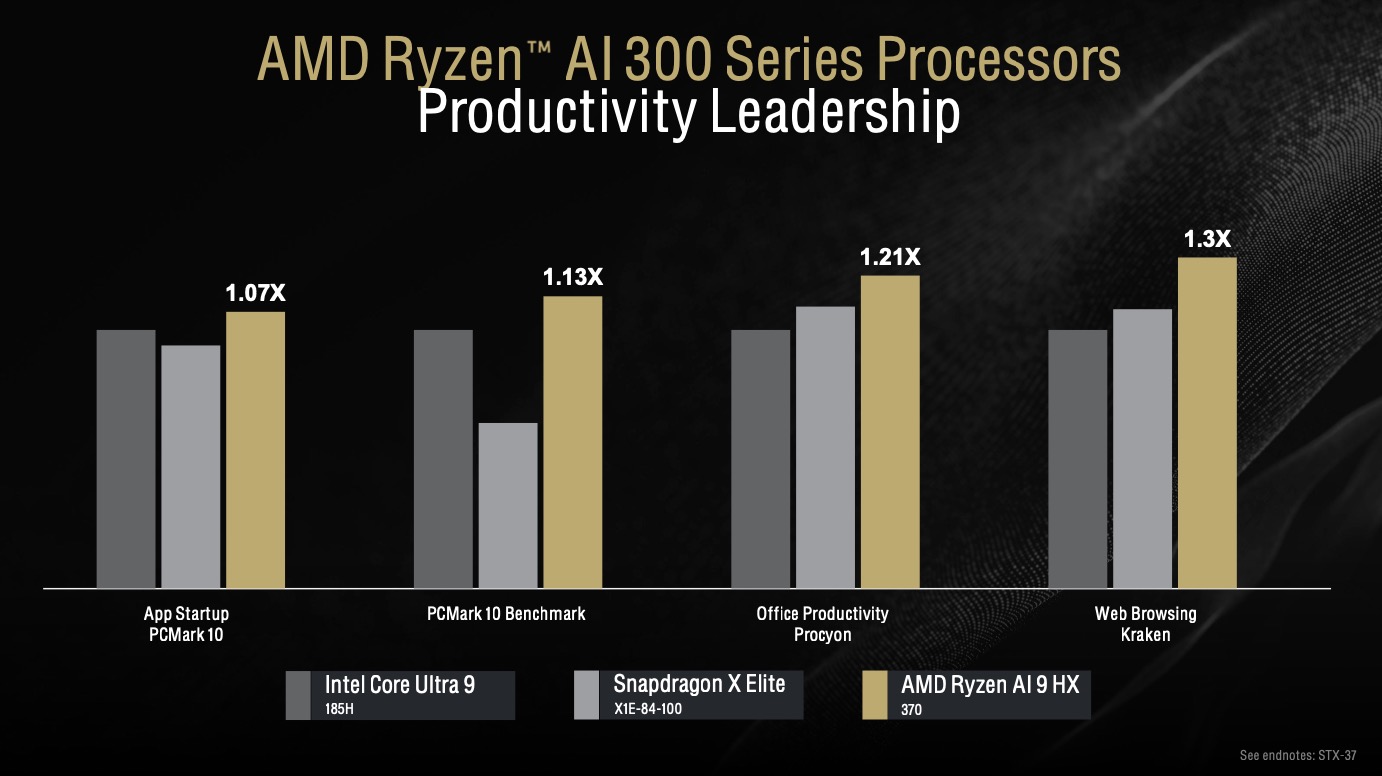
На выбор предлагается две модели: Ryzen AI 9 HX 370 и Ryzen AI 9 365, которые отличаются количеством ядер, тактовой частотой и возможностями интегрированного GPU. В обеих моделях установлен одинаковый NPU под названием Strix Point. По слухам, в будущем будет выпущено ещё несколько моделей:

Вероятно, Intel включит модуль NPU во все десктопные процессоры следующего поколения Arrow Lake. Говорят, что наступает «эра AI PC», хотя простые пользователи этому не очень рады, но в будущем ПК будет неполноценным без аппаратного ускорителя нейросетей.
Сейчас даже большие модели с 70 млрд параметров можно обучать на домашнем ПК с двумя стандартными GPU (3090 или 4090 по 24 ГБ каждая).
▍ Выводы
Таким образом, ИИ сейчас стал приоритетом номер один для производителей микросхем, в том числе Intel и AMD. Это справедливо и для рынка серверов, и для ноутбуков, и настольных ПК. Для рынка это просто манна небесная: все видят, что акции Nvidia выросли в десять раз за два года на волне популярности ИИ-вычислений. И все хотят присоединиться к пиршеству. Мировая индустрия микроэлектроники словно получила второе дыхание и снова стала развиваться семимильными шагами, что не может не радовать.
Примечание. Экспорт высокопроизводительных ускорителей запрещён в санкционные страны.
Telegram-канал со скидками, розыгрышами призов и новостями IT 💻

