Привет, Хабр! Это снова Ольга Пешина, эксперт по развитию новых технологий в АО «Северсталь-Инфоком». Прокачивая телеметрию нашего гигантского металлургического комбината, мы хотим оперировать полученными с агрегатов данными не только в режиме реального времени (“что-то сломалось, надо чинить”), но и построить модель предиктивной аналитики отказов оборудования (“скоро там-то будет проблема, надо заранее принять меры”).
Я расскажу, как мы набивали шишки на попытках внедрить предиктивные ремонты, что из запланированного нам удалось, а что – нет и почему.
Звучит волшебно – всегда знать, в какой момент выйдет из строя каждый валок или подшипник, планировать обслуживание по состоянию, минимизировать переобслуживание и складские запасы запчастей, выйти в ноль по аварийным остановкам.
Всякая новая технология движется через цикл хайпа: чрезмерные ожидания сменяются глубоким разочарованием, после которого наступает осознание реальных возможностей и ограничений. В 2017-2020 годах прошли через этот путь и мы.

Как мы это видели: триггер инновации
Ещё в 2014 году, когда принималось решение о развитии службы мониторинга состояния оборудования (СМСО), мы понимали, что увеличение количества собираемой с агрегатов информации увеличит сложность её обработки. Оборудование модернизируется, оснащается стационарными системами мониторинга, создаются новые производственные линии – всё это добавляет объекты мониторинга ситуационному центру.
На старте в СМСО передавались данные с 500 датчиков. Сейчас их 12 000, а к 2025 году будет больше 100 000. При этом, например, одна установка непрерывной разливки стали создаёт более 50 Гб данных за месяц только с самых критичных узлов.


Созданный в 2017 году Data Lake накапливал эти данные, что также приближало нас к идее использования машинного обучения для помощи аналитикам ситуационного центра. Параллельно с этим по каждому оборудованию в SAP ERP хранится информация о плановых и неплановых простоях; осмотрах, ремонтах и профилактических работах.
Итого: у нас есть данные о состоянии агрегатов и об операциях, которые с ними проводили в каждый момент времени. Логично попробовать найти зависимости и построить на них модель предиктивной аналитики отказов оборудования.
Были и другие причины перейти от превентивных ремонтов к предиктивным, к ремонтам по состоянию. Например, переобслуживание оборудования: мы регулярно меняем валки, подшипники и так далее. Но на этих валках, например, можно было ещё несколько дней работать.


Если проводить ТО не по регламенту, а когда мы понимаем, что остаточный срок службы конкретного оборудования заканчивается, можно повысить производительность, качественно планировать запасы запчастей.
Кроме того, появляется возможность более качественно планировать загрузку ремонтного персонала. Сейчас у нас постоянно, 24/7 наготове множество ремонтных бригад: они выполняют регламентные работы и обходы. В случае аварии они всё бросают и бегут тушить пожар. До простоя не доводим, быстро производим замену – как пит-стоп – и сразу запускаем.
От вершины хайпа к пропасти разочарования
В 2017-2018 годах методы машинного обучения вознеслись на вершину хайпа. Весь мир говорил о больших данных, которые теперь новая нефть, о том, как нейронные сети сами находят взаимосвязи и предсказывают ситуации, как помогают достигать невиданных эффектов, повышая производительность и снижая простои.
К нам косяками потянулись представители разных компаний с красивыми презентациями: мол, искусственный интеллект будет думать за вас, вам не придётся хранить запасы запчастей, вы сможете покупать под потребность, а не складировать и ждать, когда понадобятся. Вы повысите производительность, минимизируете простои, снизите затраты на ремонты в целом.
Обещания заманчивые, да и парни с презентациями – приятные, внушающие доверие, из больших компаний с хорошей репутацией или достаточно именитых российских университетов. И у нас вроде бы есть всё, что надо: собираются данные с агрегатов, мы понимаем, что происходит с оборудованием, есть на чём обучать модели и делать выводы.
Но некоторые вопросы оставались без ответа. Как, например, это будет работать в комплексе? Хорошо, мы понимаем, что происходит с агрегатом. А как привязать к этому товарно-материальные ценности, складские запасы, планирование персонала? Возьмём, к примеру, валок. Собираем с него информацию – по вибрации, скорости вращения и другим параметрам. На основании этих данных можем предсказать, когда его заклинит. Но как это всё увязать с огромной системой производственного планирования?
И всё же, вдохновившись этими историями, мы решили попробовать. Выбрали в качестве первого агрегата высокотехнологичный и самый производительный стан горячей прокатки – стан-2000. Это километрового размера критичный агрегат, остановка которого приводит к серьёзным потерям. Он катает разный сортамент под разной нагрузкой на переделы – вариативность состояний корректной работы его частей высокая.

Эффекты при переходе от превентивного обслуживания к предиктивному невероятно вкусные. Со Стана-2000 собирается 1800 параметров в СМСО. За ним пристально следят – по нему накоплен огромный массив информации по операциям текущего обслуживания и ремонта (ТОиР).
В рамках пилотов мы пытались создать модель предсказания отказов чистовой группы клетей (это такая часть прокатного стана) в партнёрстве с несколькими компаниями и университетами. И каждый раз результат не удовлетворял производство – точность получаемых моделей была катастрофически низкой.

Для получения точной модели нужен датасет по крайней мере из пары сотен однотипных отказов на каждом виде нагрузки на стан. Но, очевидно, на таком критичном агрегате мы не допускаем одинаковых аварий, и данных для обучения просто не было в необходимых количествах.
В итоге мы пришли к тому, что при больших затратах на эксперименты мы не получали результата, который можно применять в работе. У нас есть внутренний регламент: на MVP стараемся тратить не более трёх месяцев. Если видим, что всё идёт хорошо, но времени не хватает, продолжаем работу.
Кто-то из подрядчиков сдавался сразу, кто-то хотел больше времени. Некоторые даже обвиняли в своих неудачах нас: мол, данные у вас какие-то недостоверные. В итоге 2018 год ушёл практически полностью на эти пилоты. Казалось, выбраться из пропасти разочарования невозможно… Это сильно демотивировало всех участников.
Очередные парни с красивыми презентациями уже не воспринимались всерьёз. Всем новичкам говорили: если не скажете, почему вы лучше всех остальных компаний, в чём ваш инновационный подход – не будем даже начинать разговор.
Увы, ничего нового мы не услышали. Большие компании так и не принесли ни одного работающего решения.
В это время в Северсталь-Диджитал
Параллельно над аналогичными проектами работали и наши дата-сайентисты из подразделения Северсталь-Диджитал, которое работает напрямую с Data Lake. И с ними у нас как раз получилось несколько рабочих моделей.
Сначала создали модель по заклиниванию роликов отводящего рольганга. Это важный элемент: если ролик заклинивает – останавливаем прокат, теряем много денег. Нейросеть – обычный классификатор – натаскивали на поломку. Входной вектор – несколько десятков чисел, ничего сложного. Смотрели на скорость и сравнивали её со скоростью стоящих рядом роликов. Если есть отклонения, значит что-то не то.
Модель выкатили в СМСО и сказали: как только она срабатывает – поднимайте на уши ремонтников, пусть бегут менять ролик. Первое время было много ложных срабатываний, около 50%. Само собой, ремонтники недовольны: мы вскакиваем, бежим – а там всё нормально. Ну прямо «Петя и волк».
Надо сказать, что протяжённость стана – полтора километра. Причём ремонтники не сидят-ждут у самого стана: там шумно и опасно. По сигналу им надо бросить выполняемую работу, взять инструменты, прибежать к ролику, который сработал, убедиться что всё в порядке, вернуться… А тут, например, опять что-то срабатывает!
До этого практиковались регулярные обходы: несколько раз за смену ремонтники проходят, осматривают все ролики. Если всё нормально – выполняют следующие сменные задания. Вызовы внесли хаос в эту размеренную рутину, и ребята стали забивать на сигналы ИИ. В конце концов на очередное срабатывание модели никто не отреагировал. Ролик заклинило, случился простой. Ремонтники объясняют, что до этого модель пять раз подряд выдавала ложный сигнал: «В шестой раз мы просто не пошли, а он, собака, взял и сломался… В общем, такой процент попаданий нас не устраивает».
В итоге придумали сделать простой интерфейс, чтобы служба СМСО (инженеры, а не ремонтники, которые бегают на вызов) могла доучивать модель. Элементарное решение: каждое срабатывание классифицируется как правильное или ложное.
Сделали красивую кнопку, начали дообучать модель… И тут случилась модернизация оборудования, в результате которой убрали те самые проблемные ролики. История совершила полный круг, мы оказались в исходной точке.
С другой стороны, мы выявили проблемы, которые случаются на типовых узлах регулярно, и отработали создание прогнозных моделей. И получили действительно потрясающие результаты. К примеру, наша модель свела к нулю случаи заклинивания роликов отводящего рольганга уже в первый год использования.

Склон просветления: интеллектуальный мониторинг
Некоторое время мы довольствовались предсказаниями отказов там, где было на чём обучить математическую модель. Например, прогнозирование перегрева подшипников шестеренных клетей даже при точности в 50%, позволило сократить число случаев в 3 раза и уменьшить общее время простоя с 5-6 часов в год до 1,5 часов. Но всё-таки хотелось большего – знать о потенциальных проблемах сложных критичных узлов не за часы и минуты, а за дни и недели, чтобы качественно планировать производственный процесс и остановки на обслуживание.
Тем временем появилась информация об успешных внедрениях систем предиктивной диагностики. Наши представители из Дирекции по ремонтам побывали с референс-визитом у бразильских коллег в Gerdau и убедились, что SmartSignal, инструмент мониторинга от General Electric, довольно круто контролирует все площадки.
Сейчас в системе у бразильцев 650 критичных агрегатов, и продолжают добавлять новые. А работает всего семь аналитиков – и только в дневную смену. Дело в том, что SmartSignal работает именно так, как мы изначально хотели: предсказывает отклонения за недели. То есть всегда можно заранее спланировать остановку, количество аварийных простоев стремится к нулю.
Работает предиктивная диагностика по иному принципу – математическая модель обучается не на отказах, а на правильной работе оборудования в различных режимах. Именно этой стратегии предсказания придерживаются, например, хозяева кошек: они не пытаются диагностировать, чем именно заболело животное, а просто подмечают, что оно ведёт себя не как обычно. То есть что модель нормального кота не работает. И это позволяет понять, что есть какая-то проблема.
Классическая система мониторинга работает по принципу «следим за параметром, если он выходит за пределы уставки – сигнализируем». А интеллектуальный мониторинг смотрит за набором параметров по узлу и анализирует их коллективное поведение. На основании текущего значения набора данных с датчиков матмодель предсказывает следующее значение. Если факт отличается от предсказания, загорается алерт.
Проблема, однако, в том, что у одного агрегата бывает много режимов работы. Когда модель срабатывает на вибрацию, повышение температуры или нагрузки – вполне возможно, что сейчас идёт некий процесс, для которого эти параметры являются нормой. По аналогии: если у кошки повысилась температура – это не значит, что она болеет, возможно, просто на дворе март.
SmartSignal как раз-таки всё это учитывает, работает с привязкой к технологическому процессу, с пониманием текущей нагрузки на оборудование. Для этого модели в ПО обучают на разных режимах работы. Каждый режим соответствует определённой прокатке. Если появляются отклонения, которые не характерны для данного процесса – надо поднимать людей, разбираться.
SmartSignal предлагает определённые шаблоны, уже прописанные уравнения некоего сферического прокатного стана в вакууме. Остаётся в эти уравнения подставить наши данные и дообучить нейросеть уже применительно к нашему оборудованию.
General Electric продают лицензии именно на эти виртуальные шаблоны, которые дообучаются на данных клиента: шаблон прокатного стана, редуктора, эксгаустера и так далее. Клиенту остаётся загрузить свои данные через пользовательский интерфейс. Происходит некая магия, и на выходе мы получаем цифрового двойника нашего оборудования. Без сложной математики и больших трудозатрат с нашей стороны.
Когда у нас есть этот цифровой двойник, который обучен нормальной работе, на него натягиваются «диагностические правила». То есть мы понимаем, что при таком режиме работы у нас должны быть такие-то показания температуры, вибрации, тока… Если какой-то из показателей выбивается, срабатывает алерт.
Допустим, мы хотим понять, есть ли у нас проблема с охлаждением двигателя. Тогда мы анализируем в комплексе показания десяти датчиков: температуры подшипников приводной и неприводной стороны, температуры обмотки двигателя на трёх фазах, а также их расчетные значения.
Дальше на умный мониторинг вешают шаблоны с диагностическими правилами, которые вдобавок к алертам, полученным на предыдущем шаге, с некоторой вероятностью рекомендуют провести детальную диагностику частей оборудования. Так и получается система предиктивной диагностики.
Да, система не предсказывает конкретные отказы каждого отдельно взятого подшипника. Но она даёт знать о том, что есть развивающаяся проблема, задолго до классической системы мониторинга. Плюс рекомендует, на какие узлы нужно посмотреть в первую очередь.
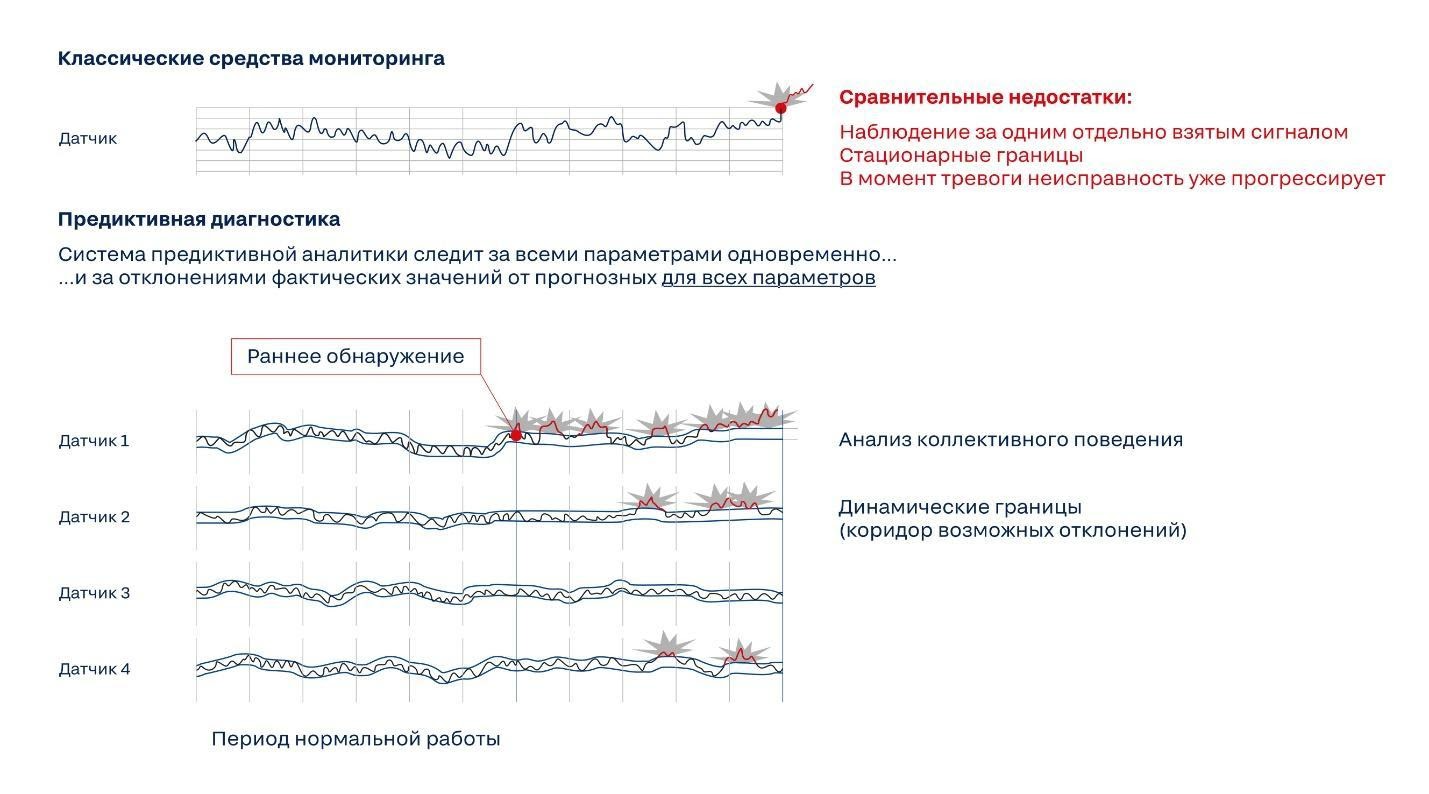
Выход на плато продуктивности
Для пилотирования софта SmartSignal мы выбрали нагнетатель конвертерных газов и установку непрерывной разливки стали (УНРС).

В процессе MVP дообучили стандартные шаблоны под наши агрегаты. На полученных цифровых моделях выполняли симуляции работы системы: загружали ретроспективные данные СМСО и сравнивали полученные предупреждения с событиями, произошедшими в этот период.
Результаты оказались вдохновляющими. Например, локальные проблемы с подшипниками на нагнетателе конвертерных газов в SmartSignal мы видим за 5-7 дней до того, как срабатывает система классического мониторинга. А про загрязнение форсуночного охлаждения УНРС система предупреждает за 20 дней до того, как давление превысило предупредительную границу. Это хороший запас времени для проведения диагностики и планирования очистки ротора.
И ещё интересный момент – в период теста не случилось ложноположительных срабатываний. Сложно делать далекоидущие выводы – данные у нас пока только за полгода, – но сам факт уже впечатляет.
Пока осталась нерешённой проблема «человеческого фактора», из-за которой случается примерно 80% поломок. Ремонтировали – забыли внутри гаечный ключ. Неудачно повернулись – оборвали провод. А такие ситуации не предскажешь никаким ИИ.
Но мы верим, что системой предиктивного планирования можно подстраховаться и от таких ситуаций. Если заранее планировать ремонты, то и влияние человеческого фактора можно минимизировать.
Что будет дальше
Сейчас мы в процессе выбора: параллельно с GE появилось несколько компаний с похожими решениями. Предварительно собираемся заняться прокатными станами. Через тендер выберем компанию для пилота, дальше будем принимать решение о тиражировании – если достигнем ожидаемых эффектов. Параллельно попытаемся сделать что-то собственными силами.
В общем, что-то получилось, что-то нет, а что-то еще только предстоит оценить. Но мы продолжаем осуществлять нашу мечту по переходу на искусственный интеллект, предсказывающий процессы ТОиР, и скоро поделимся новыми кейсами. А пока хотим узнать о вашем опыте: хабравчане, а вы какие шишки набивали в предиктивных ремонтах?
