Первая часть — разбор самой холиварной задачи из четырёх:
Под катом условие задач, история их появления, а также разбор первой задачи и статистика её правильных решений среди участников конференции.
Другие публикации серии: Часть 2, Часть 3, Часть 4.
Коллега за десять дней до конференции пришёл с предложением подготовить задачи для розыгрыша призов, где топовыми призами стали бы несколько книг Effective Java от Джошуа Блоха (последнее третье издание). Под такие призы нужны соответствующие задачи. И так, вызов принят.
Для начала определимся, что мы хотим получить:
Так я решился подготовить задачи про перформанс в следующем виде:
Комментарий ко всем задачам:
Предполагается, что код запускается в HotSpot 64-bit VM (JRE 1.8.0_161). В выбранной версии JRE нет ничего специфического, кроме того, что она одна из последних и уже у меня стояла — разумеется, что все задачи я должен был заранее проверить.
Неявно предполагается, что код запускается на многоядерном железе с архитектурой intel 64 (x86-64). Возможно, стоило это указать явно, но и дополнительные условия могли ввести в заблуждение. При этом, если пояснение к ответу в задаче учитывало специфику другого железа, то решение бы засчитывалось.
«foreach — это быстро», «Стримы тормозят», «Параллельно значит быстро» частенько доносилось из обсуждений Stream API, которому вот уже стукнет 4 года (если считать с даты публичного релиза Java 8). Так и яподдался пошёл на провокацию:
Очевидный неправильный ответ: 3 вариант самый быстрый.
У многих сработал триггер «Параллельно значит быстро» и они попали в ловушку с
Фрагмент исходного кода
На практике это означает, что никакой выгоды от параллельного выполнения мы не получим независимо от размеров списка
Ниже бенчмарк для сравнения обычного последовательного и параллельного
Понятно, что при однопоточном исполнении блокировка никуда не девается. Но виртуальная машина может поступать достаточно хитро, а именно не делать настоящую (на уровне OS) блокировку, а ограничиваться так называемой biased locking, если отсутствует contention на ресурсе.
Можем отключить biased locking и посмотреть, что получится:
Ожидаемо просела производительность обычного
Как и ожидалось, эффект от biased locking наступил только спустя 6 секунд с начала выполнения бенчмарка — это видно по разнице во времени выполнения третьей и четвёртой прогревочной итерации.
Теперь пришло время разобраться, что быстрее:
В действительности, накладные расходы на итерирование намного меньше, чем накладные расходы на вызов метода
И становится интереснее: разница между
Дело в том, что накладные расходы на создание
Так выглядит
Так выглядит код
Как видим, разница в коде не существенная (циклы for внутри методов): дальше в дело вступает JIT-компилятор. Андрей apangin помог разобраться в чём тут дело:
Действительно, попробуем заменить
Всё вернулось на круги своя, а как уж тут отработал JIT — совсем другая история.
1. Какой же в итоге правильный ответ? методы 1 и 2 в задаче дают незначительно отличающиеся результаты, а метод 3 значительно уступает в производительности.
2. В качестве правильно ответа принимались альтернативные варианты, что 1 быстрее 2 и 2 быстрее 1, если это было верно аргументировано.
3. Личный вывод: кроличья нора оказывается всегда глубже, чем думаешь.
Код бенчмарков можно взять на github: jbreak2018-forEach-perf-tests.
Из 32 сданных вариантов было 8 правильных и 5 частично правильных. Ещё 7 человек попали в
Ниже в комментариях уже обсуждался потенциальный эксплойт, использующий 0-day уязвимость, связанную с произвольными реализациями
Спасибо Тагиру lany, реализовавшему вариант подобного эксплойта (в его статье код эксплойта, подробное описание и примеры).
Следующую часть постараюсь подготовить на следующих выходных.
UPD. Другие публикации серии: Часть 2, Часть 3, Часть 4.
void forEach(List<Integer> values, PrintStream ps) {
values.forEach(ps::println);
}
void forEach(List<Integer> values, PrintStream ps) {
values.stream().forEach(ps::println);
}
void forEach(List<Integer> values, PrintStream ps) {
values.parallelStream().forEach(ps::println);
}
Под катом условие задач, история их появления, а также разбор первой задачи и статистика её правильных решений среди участников конференции.
Другие публикации серии: Часть 2, Часть 3, Часть 4.
Предисловие
Коллега за десять дней до конференции пришёл с предложением подготовить задачи для розыгрыша призов, где топовыми призами стали бы несколько книг Effective Java от Джошуа Блоха (последнее третье издание). Под такие призы нужны соответствующие задачи. И так, вызов принят.
Для начала определимся, что мы хотим получить:
- задачи должны быть на код (я не мастер придумывать логические задачи, а брать готовые не хотелось)
- в задачах должен быть очевидный неправильный ответ
- задачи не должны быть все простыми или все сложными
- если закодить задачу, то это не должно дать 100% ответа, но может помочь в поиске верного решения
- в идеале задачи должны «зацепить», чтобы после конференции было желание докопаться до истины.
Так я решился подготовить задачи про перформанс в следующем виде:
- несколько вариантов алгоритмов, делающих что-то похожее
- требуется упорядочить их по скорости работы
- и объяснить, почему алгоритмы упорядочены именно таким образом.
Задачи
Как выглядело условие задачи в печатном виде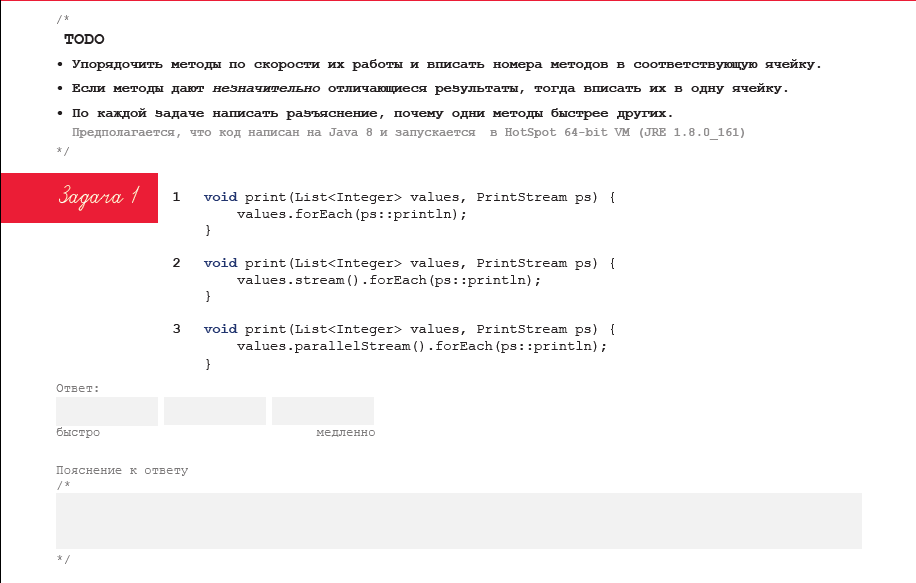

Комментарий ко всем задачам:
- Упорядочить методы по скорости их работы и вписать номера методов в соответствующую ячейку.
- Если методы дают незначительно отличающиеся результаты, тогда вписать их в одну ячейку.
- По каждой задаче написать разъяснение, почему одни методы быстрее других.
Задача №1
void forEach(List<Integer> values, PrintStream ps) {
values.forEach(ps::println);
}
void forEach(List<Integer> values, PrintStream ps) {
values.stream().forEach(ps::println);
}
void forEach(List<Integer> values, PrintStream ps) {
values.parallelStream().forEach(ps::println);
}
Задача №2
String format(String user, String grade, String company, String message) {
return String.format(
"Он, %s, придумал такие %s задачи. Приду на стенд %s и скажу ему %s",
user, grade, company, message);
}
String format(String user, String grade, String company, String message) {
return "Он, " + user
+ ", придумал такие " + grade
+ " задачи. Приду на стенд " + company
+ " и скажу ему " + message;
}
String format(String user, String grade, String company, String message) {
return new StringBuilder("Он, ")
.append(user)
.append(", придумал такие ")
.append(grade)
.append(" задачи. Приду на стенд ")
.append(company)
.append(" и скажу ему ")
.append(message)
.toString();
}
Задача №3
public static double compute(
double x1, double y1, double z1,
double x2, double y2, double z2) {
double x = y1 * z2 - z1 * y2;
double y = z1 * x2 - x1 * z2;
double z = x1 * y2 - y1 * x2;
return x * x + y * y + z * z;
}
public static double compute(
double x1, double y1, double z1,
double x2, double y2, double z2) {
Vector v1 = new Vector(x1, y1, z1);
Vector v2 = new Vector(x2, y2, z2);
return v1.crossProduct(v2).squared();
}
public final static class Vector {
private final double x, y, z;
public Vector(double x, double y, double z) {
this.x = x; this.y = y; this.z = z;
}
public double squared() {
return x * x + y * y + z * z;
}
public Vector crossProduct(Vector v) {
return new Vector(
y * v.z - z * v.y,
z * v.x - x * v.z,
x * v.y - y * v.x);
}
}
Задача №4
public double octaPow(double a) {
return Math.pow(a, 8);
}
public double octaPow(double a) {
return a * a * a * a * a * a * a * a;
}
public double octaPow(double a) {
return Math.pow(Math.pow(Math.pow(a, 2), 2), 2);
}
public double octaPow(double a) {
a *= a; a *= a; return a * a;
}
Предполагается, что код запускается в HotSpot 64-bit VM (JRE 1.8.0_161). В выбранной версии JRE нет ничего специфического, кроме того, что она одна из последних и уже у меня стояла — разумеется, что все задачи я должен был заранее проверить.
Неявно предполагается, что код запускается на многоядерном железе с архитектурой intel 64 (x86-64). Возможно, стоило это указать явно, но и дополнительные условия могли ввести в заблуждение. При этом, если пояснение к ответу в задаче учитывало специфику другого железа, то решение бы засчитывалось.
Задача №1
«foreach — это быстро», «Стримы тормозят», «Параллельно значит быстро» частенько доносилось из обсуждений Stream API, которому вот уже стукнет 4 года (если считать с даты публичного релиза Java 8). Так и я
void forEach(List<Integer> values, PrintStream ps) {
values.forEach(ps::println);
}
void forEach(List<Integer> values, PrintStream ps) {
values.stream().forEach(ps::println);
}
void forEach(List<Integer> values, PrintStream ps) {
values.parallelStream().forEach(ps::println);
}
Было ошибкой не указать явную реализациюList, например,ArrayList. Участники конференции подходили уточнить, о каких реализациях списка идёт речь. Поскольку все бенчмарки были проведены для двух стандартных реализацийArrayListиLinkedList, то решать задачу предлагалось в этих условиях.
Очевидный неправильный ответ: 3 вариант самый быстрый.
У многих сработал триггер «Параллельно значит быстро» и они попали в ловушку с
PrintStream.Фрагмент исходного кода
PrintStream: public void println(Object x) {
String s = String.valueOf(x);
synchronized (this) {
print(s);
newLine();
}
}
На практике это означает, что никакой выгоды от параллельного выполнения мы не получим независимо от размеров списка
values. Напротив, мы получим деградацию производительности, так как виртуальной машине придётся постоянно разруливать множественные блокировки на PrintStream.List.stream().forEach() vs List.parallelStream().forEach()
Ниже бенчмарк для сравнения обычного последовательного и параллельного
Stream.Бенчмарк
package ru.gnkoshelev.jbreak2018.perf_tests.for_each;
@Fork(value = 1, warmups = 0)
@Warmup(iterations = 5, time = 2_000, timeUnit = TimeUnit.MILLISECONDS)
@Measurement(iterations = 10, time = 2_000, timeUnit = TimeUnit.MILLISECONDS)
@OutputTimeUnit(value = TimeUnit.MICROSECONDS)
@BenchmarkMode(Mode.AverageTime)
public class StreamDefaultBenchmark {
static int N = 1000;
static List<Integer> values;
static {
Random rand = new Random(12345);
int size = N;
values = new ArrayList<>();
for (int i = 0; i < size; i++) {
values.add(rand.nextInt());
}
}
@State(value = Scope.Benchmark)
public static class PrintStreamHolder {
PrintStream ps;
@Setup(value = Level.Iteration)
public void setup() {
ps = new PrintStream(new NullOutputStream());
}
}
@Benchmark
public void forEachStreamBenchmark(PrintStreamHolder psh) {
forEachStream(values, psh.ps);
}
@Benchmark
public void forEachParallelStreamBenchmark(PrintStreamHolder psh) {
forEachParallelStream(values, psh.ps);
}
public void forEachStream(List<Integer> values, PrintStream ps) {
values.stream().forEach(ps::println);
}
public void forEachParallelStream(List<Integer> values, PrintStream ps) {
values.parallelStream().forEach(ps::println);
}
}
Результаты
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.StreamDefaultBenchmark.forEachParallelStreamBenchmark
# Run progress: 0,00% complete, ETA 00:01:00
# Fork: 1 of 1
# Warmup Iteration 1: 905,302 us/op
# Warmup Iteration 2: 876,525 us/op
# Warmup Iteration 3: 921,153 us/op
# Warmup Iteration 4: 898,899 us/op
# Warmup Iteration 5: 873,496 us/op
Iteration 1: 920,439 us/op
Iteration 2: 894,216 us/op
Iteration 3: 917,930 us/op
Iteration 4: 906,970 us/op
Iteration 5: 929,685 us/op
Iteration 6: 883,136 us/op
Iteration 7: 883,996 us/op
Iteration 8: 882,597 us/op
Iteration 9: 921,612 us/op
Iteration 10: 885,576 us/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.StreamDefaultBenchmark.forEachParallelStreamBenchmark":
902,616 ±(99.9%) 28,296 us/op [Average]
(min, avg, max) = (882,597, 902,616, 929,685), stdev = 18,716
CI (99.9%): [874,320, 930,911] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.StreamDefaultBenchmark.forEachStreamBenchmark
# Run progress: 50,00% complete, ETA 00:00:30
# Fork: 1 of 1
# Warmup Iteration 1: 285,837 us/op
# Warmup Iteration 2: 265,208 us/op
# Warmup Iteration 3: 157,321 us/op
# Warmup Iteration 4: 157,447 us/op
# Warmup Iteration 5: 157,689 us/op
Iteration 1: 157,192 us/op
Iteration 2: 161,511 us/op
Iteration 3: 161,464 us/op
Iteration 4: 156,948 us/op
Iteration 5: 158,526 us/op
Iteration 6: 163,035 us/op
Iteration 7: 159,140 us/op
Iteration 8: 158,476 us/op
Iteration 9: 158,884 us/op
Iteration 10: 159,072 us/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.StreamDefaultBenchmark.forEachStreamBenchmark":
159,425 ±(99.9%) 2,976 us/op [Average]
(min, avg, max) = (156,948, 159,425, 163,035), stdev = 1,969
CI (99.9%): [156,448, 162,401] (assumes normal distribution)
# Run complete. Total time: 00:01:00
Benchmark Mode Cnt Score Error Units
StreamDefaultBenchmark.forEachParallelStreamBenchmark avgt 10 902,616 ± 28,296 us/op
StreamDefaultBenchmark.forEachStreamBenchmark avgt 10 159,425 ± 2,976 us/op
Понятно, что при однопоточном исполнении блокировка никуда не девается. Но виртуальная машина может поступать достаточно хитро, а именно не делать настоящую (на уровне OS) блокировку, а ограничиваться так называемой biased locking, если отсутствует contention на ресурсе.
Можем отключить biased locking и посмотреть, что получится:
Бенчмарк без biased locking
package ru.gnkoshelev.jbreak2018.perf_tests.for_each;
@Fork(value = 1, warmups = 0, jvmArgsAppend = "-XX:-UseBiasedLocking")
@Warmup(iterations = 5, time = 2_000, timeUnit = TimeUnit.MILLISECONDS)
@Measurement(iterations = 10, time = 2_000, timeUnit = TimeUnit.MILLISECONDS)
@OutputTimeUnit(value = TimeUnit.MICROSECONDS)
@BenchmarkMode(Mode.AverageTime)
public class StreamWithoutBiasedLockingBenchmark {
static int N = 1000;
static List<Integer> values;
static {
Random rand = new Random(12345);
int size = N;
values = new ArrayList<>();
for (int i = 0; i < size; i++) {
values.add(rand.nextInt());
}
}
@State(value = Scope.Benchmark)
public static class PrintStreamHolder {
PrintStream ps;
@Setup(value = Level.Iteration)
public void setup() {
ps = new PrintStream(new NullOutputStream());
}
}
@Benchmark
public void forEachStreamBenchmark(PrintStreamHolder psh) {
forEachStream(values, psh.ps);
}
@Benchmark
public void forEachParallelStreamBenchmark(PrintStreamHolder psh) {
forEachParallelStream(values, psh.ps);
}
public void forEachStream(List<Integer> values, PrintStream ps) {
values.stream().forEach(ps::println);
}
public void forEachParallelStream(List<Integer> values, PrintStream ps) {
values.parallelStream().forEach(ps::println);
}
}
Результаты
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: -XX:-UseBiasedLocking
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.StreamWithoutBiasedLockingBenchmark.forEachParallelStreamBenchmark
# Run progress: 0,00% complete, ETA 00:01:00
# Fork: 1 of 1
# Warmup Iteration 1: 754,310 us/op
# Warmup Iteration 2: 723,277 us/op
# Warmup Iteration 3: 682,845 us/op
# Warmup Iteration 4: 696,635 us/op
# Warmup Iteration 5: 690,811 us/op
Iteration 1: 702,129 us/op
Iteration 2: 729,542 us/op
Iteration 3: 689,514 us/op
Iteration 4: 716,482 us/op
Iteration 5: 734,766 us/op
Iteration 6: 684,455 us/op
Iteration 7: 682,483 us/op
Iteration 8: 706,857 us/op
Iteration 9: 690,011 us/op
Iteration 10: 694,427 us/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.StreamWithoutBiasedLockingBenchmark.forEachParallelStreamBenchmark":
703,067 ±(99.9%) 28,058 us/op [Average]
(min, avg, max) = (682,483, 703,067, 734,766), stdev = 18,559
CI (99.9%): [675,008, 731,125] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: -XX:-UseBiasedLocking
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.StreamWithoutBiasedLockingBenchmark.forEachStreamBenchmark
# Run progress: 50,00% complete, ETA 00:00:30
# Fork: 1 of 1
# Warmup Iteration 1: 271,938 us/op
# Warmup Iteration 2: 258,261 us/op
# Warmup Iteration 3: 257,976 us/op
# Warmup Iteration 4: 256,103 us/op
# Warmup Iteration 5: 255,863 us/op
Iteration 1: 266,376 us/op
Iteration 2: 258,158 us/op
Iteration 3: 278,038 us/op
Iteration 4: 271,354 us/op
Iteration 5: 256,021 us/op
Iteration 6: 254,590 us/op
Iteration 7: 254,944 us/op
Iteration 8: 255,525 us/op
Iteration 9: 256,339 us/op
Iteration 10: 257,311 us/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.StreamWithoutBiasedLockingBenchmark.forEachStreamBenchmark":
260,866 ±(99.9%) 12,366 us/op [Average]
(min, avg, max) = (254,590, 260,866, 278,038), stdev = 8,180
CI (99.9%): [248,499, 273,232] (assumes normal distribution)
# Run complete. Total time: 00:01:00
Benchmark Mode Cnt Score Error Units
StreamWithoutBiasedLockingBenchmark.forEachParallelStreamBenchmark avgt 10 703,067 ± 28,058 us/op
StreamWithoutBiasedLockingBenchmark.forEachStreamBenchmark avgt 10 260,866 ± 12,366 us/op
Ожидаемо просела производительность обычного
ArrayList.forEach(). При этом по прогревочным итерациям в предыдущем бенчмарке заметно ускорение, начиная с третьей итерации, — это не случайность. Дело в том, что по умолчанию biased locking включается спустя 4000 мс с момента запуска виртуальной машины. Это значение можно потюнить и посмотреть, что получится:Бенчмарк c увеличенным временем включения biased locking
package ru.gnkoshelev.jbreak2018.perf_tests.for_each;
@Fork(value = 1, warmups = 0, jvmArgsAppend = "-XX:BiasedLockingStartupDelay=6000")
@Warmup(iterations = 5, time = 2_000, timeUnit = TimeUnit.MILLISECONDS)
@Measurement(iterations = 10, time = 2_000, timeUnit = TimeUnit.MILLISECONDS)
@OutputTimeUnit(value = TimeUnit.MICROSECONDS)
@BenchmarkMode(Mode.AverageTime)
public class StreamWithNewBiasedLockingStartupDelayBenchmark {
static int N = 1000;
static List<Integer> values;
static {
Random rand = new Random(12345);
int size = N;
values = new ArrayList<>();
for (int i = 0; i < size; i++) {
values.add(rand.nextInt());
}
}
@State(value = Scope.Benchmark)
public static class PrintStreamHolder {
PrintStream ps;
@Setup(value = Level.Iteration)
public void setup() {
ps = new PrintStream(new NullOutputStream());
}
}
@Benchmark
public void forEachStreamBenchmark(PrintStreamHolder psh) {
forEachStream(values, psh.ps);
}
@Benchmark
public void forEachParallelStreamBenchmark(PrintStreamHolder psh) {
forEachParallelStream(values, psh.ps);
}
public void forEachStream(List<Integer> values, PrintStream ps) {
values.stream().forEach(ps::println);
}
public void forEachParallelStream(List<Integer> values, PrintStream ps) {
values.parallelStream().forEach(ps::println);
}
}
Результаты
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: -XX:BiasedLockingStartupDelay=6000
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.StreamWithNewBiasedLockingStartupDelayBenchmark.forEachParallelStreamBenchmark
# Run progress: 0,00% complete, ETA 00:01:00
# Fork: 1 of 1
# Warmup Iteration 1: 954,533 us/op
# Warmup Iteration 2: 866,854 us/op
# Warmup Iteration 3: 907,109 us/op
# Warmup Iteration 4: 914,717 us/op
# Warmup Iteration 5: 924,102 us/op
Iteration 1: 912,619 us/op
Iteration 2: 947,812 us/op
Iteration 3: 925,730 us/op
Iteration 4: 933,807 us/op
Iteration 5: 935,927 us/op
Iteration 6: 852,369 us/op
Iteration 7: 882,498 us/op
Iteration 8: 852,625 us/op
Iteration 9: 898,787 us/op
Iteration 10: 1150,831 us/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.StreamWithNewBiasedLockingStartupDelayBenchmark.forEachParallelStreamBenchmark":
929,301 ±(99.9%) 128,179 us/op [Average]
(min, avg, max) = (852,369, 929,301, 1150,831), stdev = 84,783
CI (99.9%): [801,121, 1057,480] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: -XX:BiasedLockingStartupDelay=6000
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.StreamWithNewBiasedLockingStartupDelayBenchmark.forEachStreamBenchmark
# Run progress: 50,00% complete, ETA 00:00:30
# Fork: 1 of 1
# Warmup Iteration 1: 346,853 us/op
# Warmup Iteration 2: 280,643 us/op
# Warmup Iteration 3: 264,425 us/op
# Warmup Iteration 4: 169,200 us/op
# Warmup Iteration 5: 167,981 us/op
Iteration 1: 171,230 us/op
Iteration 2: 169,891 us/op
Iteration 3: 169,124 us/op
Iteration 4: 167,938 us/op
Iteration 5: 167,471 us/op
Iteration 6: 176,187 us/op
Iteration 7: 171,791 us/op
Iteration 8: 170,127 us/op
Iteration 9: 169,563 us/op
Iteration 10: 169,062 us/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.StreamWithNewBiasedLockingStartupDelayBenchmark.forEachStreamBenchmark":
170,238 ±(99.9%) 3,736 us/op [Average]
(min, avg, max) = (167,471, 170,238, 176,187), stdev = 2,471
CI (99.9%): [166,503, 173,974] (assumes normal distribution)
# Run complete. Total time: 00:01:00
Benchmark Mode Cnt Score Error Units
StreamWithNewBiasedLockingStartupDelayBenchmark.forEachParallelStreamBenchmark avgt 10 929,301 ± 128,179 us/op
StreamWithNewBiasedLockingStartupDelayBenchmark.forEachStreamBenchmark avgt 10 170,238 ± 3,736 us/op
Как и ожидалось, эффект от biased locking наступил только спустя 6 секунд с начала выполнения бенчмарка — это видно по разнице во времени выполнения третьей и четвёртой прогревочной итерации.
List.forEach() vs List.stream().forEach()
Теперь пришло время разобраться, что быстрее:
List.forEach() или List.stream().forEach(). Правильный ответ «зависит от». На результат влияет размер списка, тип списка, возможность применения инлайнинга и других оптимизаций JIT-компилятором. Возможно, нам удастся выявить общее правило. Ниже результат для ArrayList:Бенчмарк
package ru.gnkoshelev.jbreak2018.perf_tests.for_each;
@Fork(value = 1, warmups = 0)
@Warmup(iterations = 5, time = 2_000, timeUnit = TimeUnit.MILLISECONDS)
@Measurement(iterations = 10, time = 2_000, timeUnit = TimeUnit.MILLISECONDS)
@OutputTimeUnit(value = TimeUnit.MICROSECONDS)
@BenchmarkMode(Mode.AverageTime)
@State(Scope.Benchmark)
public class ArrayListVsStreamBenchmark {
@Param(value = {"1", "10", "100", "1000", "10000"})
public int N;
private List<Integer> values;
@Setup
public void setup() {
Random rand = new Random(12345);
int size = N;
values = new ArrayList<>();
for (int i = 0; i < size; i++) {
values.add(rand.nextInt());
}
}
@State(value = Scope.Benchmark)
public static class PrintStreamHolder {
PrintStream ps;
@Setup(value = Level.Iteration)
public void setup() {
ps = new PrintStream(new NullOutputStream());
}
}
@Benchmark
public void forEachListBenchmark(PrintStreamHolder psh) {
forEachList(values, psh.ps);
}
@Benchmark
public void forEachStreamBenchmark(PrintStreamHolder psh) {
forEachStream(values, psh.ps);
}
public void forEachList(List<Integer> values, PrintStream ps) {
values.forEach(ps::println);
}
public void forEachStream(List<Integer> values, PrintStream ps) {
values.stream().forEach(ps::println);
}
}
Результаты
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachListBenchmark
# Parameters: (N = 1)
# Run progress: 0,00% complete, ETA 00:05:00
# Fork: 1 of 1
# Warmup Iteration 1: 0,288 us/op
# Warmup Iteration 2: 0,277 us/op
# Warmup Iteration 3: 0,178 us/op
# Warmup Iteration 4: 0,177 us/op
# Warmup Iteration 5: 0,178 us/op
Iteration 1: 0,177 us/op
Iteration 2: 0,178 us/op
Iteration 3: 0,178 us/op
Iteration 4: 0,178 us/op
Iteration 5: 0,178 us/op
Iteration 6: 0,178 us/op
Iteration 7: 0,178 us/op
Iteration 8: 0,179 us/op
Iteration 9: 0,178 us/op
Iteration 10: 0,180 us/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachListBenchmark":
0,178 ±(99.9%) 0,001 us/op [Average]
(min, avg, max) = (0,177, 0,178, 0,180), stdev = 0,001
CI (99.9%): [0,177, 0,179] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachListBenchmark
# Parameters: (N = 10)
# Run progress: 10,00% complete, ETA 00:04:33
# Fork: 1 of 1
# Warmup Iteration 1: 2,933 us/op
# Warmup Iteration 2: 2,839 us/op
# Warmup Iteration 3: 1,661 us/op
# Warmup Iteration 4: 1,675 us/op
# Warmup Iteration 5: 1,674 us/op
Iteration 1: 1,682 us/op
Iteration 2: 1,653 us/op
Iteration 3: 1,658 us/op
Iteration 4: 1,656 us/op
Iteration 5: 1,659 us/op
Iteration 6: 1,655 us/op
Iteration 7: 1,656 us/op
Iteration 8: 1,657 us/op
Iteration 9: 1,661 us/op
Iteration 10: 1,660 us/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachListBenchmark":
1,660 ±(99.9%) 0,013 us/op [Average]
(min, avg, max) = (1,653, 1,660, 1,682), stdev = 0,008
CI (99.9%): [1,647, 1,672] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachListBenchmark
# Parameters: (N = 100)
# Run progress: 20,00% complete, ETA 00:04:02
# Fork: 1 of 1
# Warmup Iteration 1: 27,633 us/op
# Warmup Iteration 2: 27,184 us/op
# Warmup Iteration 3: 15,046 us/op
# Warmup Iteration 4: 15,064 us/op
# Warmup Iteration 5: 15,060 us/op
Iteration 1: 15,039 us/op
Iteration 2: 15,057 us/op
Iteration 3: 15,065 us/op
Iteration 4: 15,062 us/op
Iteration 5: 15,086 us/op
Iteration 6: 15,060 us/op
Iteration 7: 15,110 us/op
Iteration 8: 15,070 us/op
Iteration 9: 15,111 us/op
Iteration 10: 15,079 us/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachListBenchmark":
15,074 ±(99.9%) 0,035 us/op [Average]
(min, avg, max) = (15,039, 15,074, 15,111), stdev = 0,023
CI (99.9%): [15,039, 15,109] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachListBenchmark
# Parameters: (N = 1000)
# Run progress: 30,00% complete, ETA 00:03:32
# Fork: 1 of 1
# Warmup Iteration 1: 291,532 us/op
# Warmup Iteration 2: 267,136 us/op
# Warmup Iteration 3: 170,432 us/op
# Warmup Iteration 4: 170,388 us/op
# Warmup Iteration 5: 169,797 us/op
Iteration 1: 170,036 us/op
Iteration 2: 176,614 us/op
Iteration 3: 176,396 us/op
Iteration 4: 175,895 us/op
Iteration 5: 176,984 us/op
Iteration 6: 172,085 us/op
Iteration 7: 170,193 us/op
Iteration 8: 171,333 us/op
Iteration 9: 170,293 us/op
Iteration 10: 171,006 us/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachListBenchmark":
173,084 ±(99.9%) 4,518 us/op [Average]
(min, avg, max) = (170,036, 173,084, 176,984), stdev = 2,988
CI (99.9%): [168,566, 177,601] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachListBenchmark
# Parameters: (N = 10000)
# Run progress: 40,00% complete, ETA 00:03:01
# Fork: 1 of 1
# Warmup Iteration 1: 2890,241 us/op
# Warmup Iteration 2: 2784,740 us/op
# Warmup Iteration 3: 1725,390 us/op
# Warmup Iteration 4: 1726,138 us/op
# Warmup Iteration 5: 1733,212 us/op
Iteration 1: 1726,084 us/op
Iteration 2: 1712,973 us/op
Iteration 3: 1715,916 us/op
Iteration 4: 1750,530 us/op
Iteration 5: 1721,900 us/op
Iteration 6: 1711,158 us/op
Iteration 7: 1709,659 us/op
Iteration 8: 1726,751 us/op
Iteration 9: 1737,237 us/op
Iteration 10: 1734,220 us/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachListBenchmark":
1724,643 ±(99.9%) 19,861 us/op [Average]
(min, avg, max) = (1709,659, 1724,643, 1750,530), stdev = 13,137
CI (99.9%): [1704,782, 1744,504] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachStreamBenchmark
# Parameters: (N = 1)
# Run progress: 50,00% complete, ETA 00:02:31
# Fork: 1 of 1
# Warmup Iteration 1: 0,301 us/op
# Warmup Iteration 2: 0,289 us/op
# Warmup Iteration 3: 0,181 us/op
# Warmup Iteration 4: 0,180 us/op
# Warmup Iteration 5: 0,181 us/op
Iteration 1: 0,179 us/op
Iteration 2: 0,178 us/op
Iteration 3: 0,179 us/op
Iteration 4: 0,180 us/op
Iteration 5: 0,179 us/op
Iteration 6: 0,179 us/op
Iteration 7: 0,180 us/op
Iteration 8: 0,179 us/op
Iteration 9: 0,180 us/op
Iteration 10: 0,180 us/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachStreamBenchmark":
0,179 ±(99.9%) 0,001 us/op [Average]
(min, avg, max) = (0,178, 0,179, 0,180), stdev = 0,001
CI (99.9%): [0,178, 0,180] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachStreamBenchmark
# Parameters: (N = 10)
# Run progress: 60,00% complete, ETA 00:02:01
# Fork: 1 of 1
# Warmup Iteration 1: 2,660 us/op
# Warmup Iteration 2: 2,551 us/op
# Warmup Iteration 3: 1,558 us/op
# Warmup Iteration 4: 1,563 us/op
# Warmup Iteration 5: 1,563 us/op
Iteration 1: 1,557 us/op
Iteration 2: 1,553 us/op
Iteration 3: 1,567 us/op
Iteration 4: 1,555 us/op
Iteration 5: 1,569 us/op
Iteration 6: 1,570 us/op
Iteration 7: 1,562 us/op
Iteration 8: 1,561 us/op
Iteration 9: 1,564 us/op
Iteration 10: 1,580 us/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachStreamBenchmark":
1,564 ±(99.9%) 0,012 us/op [Average]
(min, avg, max) = (1,553, 1,564, 1,580), stdev = 0,008
CI (99.9%): [1,552, 1,576] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachStreamBenchmark
# Parameters: (N = 100)
# Run progress: 70,00% complete, ETA 00:01:30
# Fork: 1 of 1
# Warmup Iteration 1: 27,754 us/op
# Warmup Iteration 2: 26,859 us/op
# Warmup Iteration 3: 16,456 us/op
# Warmup Iteration 4: 16,548 us/op
# Warmup Iteration 5: 16,432 us/op
Iteration 1: 16,399 us/op
Iteration 2: 16,480 us/op
Iteration 3: 16,517 us/op
Iteration 4: 16,458 us/op
Iteration 5: 16,395 us/op
Iteration 6: 16,471 us/op
Iteration 7: 16,595 us/op
Iteration 8: 16,585 us/op
Iteration 9: 16,460 us/op
Iteration 10: 16,435 us/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachStreamBenchmark":
16,479 ±(99.9%) 0,104 us/op [Average]
(min, avg, max) = (16,395, 16,479, 16,595), stdev = 0,069
CI (99.9%): [16,376, 16,583] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachStreamBenchmark
# Parameters: (N = 1000)
# Run progress: 80,00% complete, ETA 00:01:00
# Fork: 1 of 1
# Warmup Iteration 1: 291,695 us/op
# Warmup Iteration 2: 282,896 us/op
# Warmup Iteration 3: 185,443 us/op
# Warmup Iteration 4: 187,851 us/op
# Warmup Iteration 5: 184,393 us/op
Iteration 1: 184,584 us/op
Iteration 2: 185,349 us/op
Iteration 3: 184,803 us/op
Iteration 4: 184,394 us/op
Iteration 5: 185,371 us/op
Iteration 6: 186,735 us/op
Iteration 7: 185,945 us/op
Iteration 8: 188,592 us/op
Iteration 9: 186,581 us/op
Iteration 10: 187,908 us/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachStreamBenchmark":
186,026 ±(99.9%) 2,142 us/op [Average]
(min, avg, max) = (184,394, 186,026, 188,592), stdev = 1,417
CI (99.9%): [183,884, 188,168] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachStreamBenchmark
# Parameters: (N = 10000)
# Run progress: 90,00% complete, ETA 00:00:30
# Fork: 1 of 1
# Warmup Iteration 1: 2896,624 us/op
# Warmup Iteration 2: 2816,471 us/op
# Warmup Iteration 3: 1732,597 us/op
# Warmup Iteration 4: 1798,371 us/op
# Warmup Iteration 5: 1758,489 us/op
Iteration 1: 1615,213 us/op
Iteration 2: 1518,388 us/op
Iteration 3: 1513,955 us/op
Iteration 4: 1520,570 us/op
Iteration 5: 1525,072 us/op
Iteration 6: 1527,055 us/op
Iteration 7: 1547,707 us/op
Iteration 8: 1532,163 us/op
Iteration 9: 1519,474 us/op
Iteration 10: 1529,969 us/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.ArrayListVsStreamBenchmark.forEachStreamBenchmark":
1534,957 ±(99.9%) 44,959 us/op [Average]
(min, avg, max) = (1513,955, 1534,957, 1615,213), stdev = 29,737
CI (99.9%): [1489,998, 1579,915] (assumes normal distribution)
# Run complete. Total time: 00:05:03
Benchmark (N) Mode Cnt Score Error Units
ArrayListVsStreamBenchmark.forEachListBenchmark 1 avgt 10 0,178 ± 0,001 us/op
ArrayListVsStreamBenchmark.forEachListBenchmark 10 avgt 10 1,660 ± 0,013 us/op
ArrayListVsStreamBenchmark.forEachListBenchmark 100 avgt 10 15,074 ± 0,035 us/op
ArrayListVsStreamBenchmark.forEachListBenchmark 1000 avgt 10 173,084 ± 4,518 us/op
ArrayListVsStreamBenchmark.forEachListBenchmark 10000 avgt 10 1724,643 ± 19,861 us/op
ArrayListVsStreamBenchmark.forEachStreamBenchmark 1 avgt 10 0,179 ± 0,001 us/op
ArrayListVsStreamBenchmark.forEachStreamBenchmark 10 avgt 10 1,564 ± 0,012 us/op
ArrayListVsStreamBenchmark.forEachStreamBenchmark 100 avgt 10 16,479 ± 0,104 us/op
ArrayListVsStreamBenchmark.forEachStreamBenchmark 1000 avgt 10 186,026 ± 2,142 us/op
ArrayListVsStreamBenchmark.forEachStreamBenchmark 10000 avgt 10 1534,957 ± 44,959 us/op
В действительности, накладные расходы на итерирование намного меньше, чем накладные расходы на вызов метода
PrintStream.println(). Чтобы убедиться в этом, достаточно заменить вызов метода PrintStrim.println() на вызов Blackhole.consume() (последний гарантирует, что JIT-компилятор не выпилит ставшую бесполезной часть кода и итерирование отработает). Обратите внимание, что результат уже не в микросекундах, а в наносекундах!Бенчмарк с Blackhole.consume()
package ru.gnkoshelev.jbreak2018.perf_tests.for_each;
@Fork(value = 1, warmups = 0)
@Warmup(iterations = 5, time = 2_000, timeUnit = TimeUnit.MILLISECONDS)
@Measurement(iterations = 10, time = 2_000, timeUnit = TimeUnit.MILLISECONDS)
@OutputTimeUnit(value = TimeUnit.NANOSECONDS)
@BenchmarkMode(Mode.AverageTime)
@State(Scope.Benchmark)
public class BlackholeConsumingBenchmark {
@Param(value = {"1", "10", "100", "1000", "10000"})
public int N;
private List<Integer> values;
@Setup
public void setup() {
Random rand = new Random(12345);
int size = N;
values = new ArrayList<>();
for (int i = 0; i < size; i++) {
values.add(rand.nextInt());
}
}
@Benchmark
public void forEachListBenchmark(Blackhole bh) {
forEachList(values, bh);
}
@Benchmark
public void forEachStreamBenchmark(Blackhole bh) {
forEachStream(values, bh);
}
public void forEachList(List<Integer> values, Blackhole bh) {
values.forEach(bh::consume);
}
public void forEachStream(List<Integer> values, Blackhole bh) {
values.stream().forEach(bh::consume);
}
}
Результаты
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachListBenchmark
# Parameters: (N = 1)
# Run progress: 0,00% complete, ETA 00:05:00
# Fork: 1 of 1
# Warmup Iteration 1: 6,866 ns/op
# Warmup Iteration 2: 6,865 ns/op
# Warmup Iteration 3: 6,528 ns/op
# Warmup Iteration 4: 6,524 ns/op
# Warmup Iteration 5: 6,521 ns/op
Iteration 1: 6,519 ns/op
Iteration 2: 6,542 ns/op
Iteration 3: 6,608 ns/op
Iteration 4: 6,590 ns/op
Iteration 5: 6,678 ns/op
Iteration 6: 6,658 ns/op
Iteration 7: 6,756 ns/op
Iteration 8: 6,933 ns/op
Iteration 9: 6,939 ns/op
Iteration 10: 6,811 ns/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachListBenchmark":
6,703 ±(99.9%) 0,230 ns/op [Average]
(min, avg, max) = (6,519, 6,703, 6,939), stdev = 0,152
CI (99.9%): [6,474, 6,933] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachListBenchmark
# Parameters: (N = 10)
# Run progress: 10,00% complete, ETA 00:04:32
# Fork: 1 of 1
# Warmup Iteration 1: 51,655 ns/op
# Warmup Iteration 2: 50,507 ns/op
# Warmup Iteration 3: 50,309 ns/op
# Warmup Iteration 4: 50,886 ns/op
# Warmup Iteration 5: 50,068 ns/op
Iteration 1: 51,218 ns/op
Iteration 2: 50,108 ns/op
Iteration 3: 52,343 ns/op
Iteration 4: 50,745 ns/op
Iteration 5: 51,461 ns/op
Iteration 6: 50,366 ns/op
Iteration 7: 49,976 ns/op
Iteration 8: 50,623 ns/op
Iteration 9: 50,223 ns/op
Iteration 10: 50,125 ns/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachListBenchmark":
50,719 ±(99.9%) 1,138 ns/op [Average]
(min, avg, max) = (49,976, 50,719, 52,343), stdev = 0,753
CI (99.9%): [49,581, 51,857] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachListBenchmark
# Parameters: (N = 100)
# Run progress: 20,00% complete, ETA 00:04:02
# Fork: 1 of 1
# Warmup Iteration 1: 574,874 ns/op
# Warmup Iteration 2: 557,543 ns/op
# Warmup Iteration 3: 557,260 ns/op
# Warmup Iteration 4: 556,273 ns/op
# Warmup Iteration 5: 556,025 ns/op
Iteration 1: 555,532 ns/op
Iteration 2: 558,421 ns/op
Iteration 3: 564,582 ns/op
Iteration 4: 573,368 ns/op
Iteration 5: 576,355 ns/op
Iteration 6: 562,087 ns/op
Iteration 7: 565,229 ns/op
Iteration 8: 574,557 ns/op
Iteration 9: 561,430 ns/op
Iteration 10: 574,486 ns/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachListBenchmark":
566,605 ±(99.9%) 11,369 ns/op [Average]
(min, avg, max) = (555,532, 566,605, 576,355), stdev = 7,520
CI (99.9%): [555,236, 577,974] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachListBenchmark
# Parameters: (N = 1000)
# Run progress: 30,00% complete, ETA 00:03:32
# Fork: 1 of 1
# Warmup Iteration 1: 4782,869 ns/op
# Warmup Iteration 2: 4920,389 ns/op
# Warmup Iteration 3: 4845,857 ns/op
# Warmup Iteration 4: 4847,470 ns/op
# Warmup Iteration 5: 4857,726 ns/op
Iteration 1: 4850,519 ns/op
Iteration 2: 4852,075 ns/op
Iteration 3: 4907,015 ns/op
Iteration 4: 4859,020 ns/op
Iteration 5: 4879,201 ns/op
Iteration 6: 4832,822 ns/op
Iteration 7: 4831,532 ns/op
Iteration 8: 4829,599 ns/op
Iteration 9: 4878,201 ns/op
Iteration 10: 4826,464 ns/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachListBenchmark":
4854,645 ±(99.9%) 40,238 ns/op [Average]
(min, avg, max) = (4826,464, 4854,645, 4907,015), stdev = 26,615
CI (99.9%): [4814,407, 4894,883] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachListBenchmark
# Parameters: (N = 10000)
# Run progress: 40,00% complete, ETA 00:03:01
# Fork: 1 of 1
# Warmup Iteration 1: 42925,340 ns/op
# Warmup Iteration 2: 47991,419 ns/op
# Warmup Iteration 3: 50854,318 ns/op
# Warmup Iteration 4: 51251,774 ns/op
# Warmup Iteration 5: 51756,902 ns/op
Iteration 1: 51102,960 ns/op
Iteration 2: 51420,802 ns/op
Iteration 3: 51744,142 ns/op
Iteration 4: 50985,401 ns/op
Iteration 5: 51125,197 ns/op
Iteration 6: 51223,229 ns/op
Iteration 7: 51424,190 ns/op
Iteration 8: 51457,326 ns/op
Iteration 9: 51410,258 ns/op
Iteration 10: 51419,014 ns/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachListBenchmark":
51331,252 ±(99.9%) 335,358 ns/op [Average]
(min, avg, max) = (50985,401, 51331,252, 51744,142), stdev = 221,819
CI (99.9%): [50995,894, 51666,610] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachStreamBenchmark
# Parameters: (N = 1)
# Run progress: 50,00% complete, ETA 00:02:31
# Fork: 1 of 1
# Warmup Iteration 1: 25,963 ns/op
# Warmup Iteration 2: 20,840 ns/op
# Warmup Iteration 3: 18,882 ns/op
# Warmup Iteration 4: 19,081 ns/op
# Warmup Iteration 5: 19,513 ns/op
Iteration 1: 19,411 ns/op
Iteration 2: 18,856 ns/op
Iteration 3: 19,049 ns/op
Iteration 4: 18,891 ns/op
Iteration 5: 19,136 ns/op
Iteration 6: 20,116 ns/op
Iteration 7: 19,490 ns/op
Iteration 8: 19,251 ns/op
Iteration 9: 19,767 ns/op
Iteration 10: 19,607 ns/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachStreamBenchmark":
19,357 ±(99.9%) 0,607 ns/op [Average]
(min, avg, max) = (18,856, 19,357, 20,116), stdev = 0,401
CI (99.9%): [18,751, 19,964] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachStreamBenchmark
# Parameters: (N = 10)
# Run progress: 60,00% complete, ETA 00:02:01
# Fork: 1 of 1
# Warmup Iteration 1: 59,828 ns/op
# Warmup Iteration 2: 52,901 ns/op
# Warmup Iteration 3: 44,941 ns/op
# Warmup Iteration 4: 44,833 ns/op
# Warmup Iteration 5: 44,962 ns/op
Iteration 1: 46,032 ns/op
Iteration 2: 45,802 ns/op
Iteration 3: 45,018 ns/op
Iteration 4: 45,704 ns/op
Iteration 5: 45,788 ns/op
Iteration 6: 46,674 ns/op
Iteration 7: 46,588 ns/op
Iteration 8: 48,083 ns/op
Iteration 9: 46,862 ns/op
Iteration 10: 47,087 ns/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachStreamBenchmark":
46,364 ±(99.9%) 1,321 ns/op [Average]
(min, avg, max) = (45,018, 46,364, 48,083), stdev = 0,874
CI (99.9%): [45,042, 47,685] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachStreamBenchmark
# Parameters: (N = 100)
# Run progress: 70,00% complete, ETA 00:01:31
# Fork: 1 of 1
# Warmup Iteration 1: 382,038 ns/op
# Warmup Iteration 2: 347,846 ns/op
# Warmup Iteration 3: 337,712 ns/op
# Warmup Iteration 4: 335,078 ns/op
# Warmup Iteration 5: 344,895 ns/op
Iteration 1: 329,577 ns/op
Iteration 2: 328,436 ns/op
Iteration 3: 329,517 ns/op
Iteration 4: 330,736 ns/op
Iteration 5: 335,464 ns/op
Iteration 6: 338,727 ns/op
Iteration 7: 330,996 ns/op
Iteration 8: 330,809 ns/op
Iteration 9: 329,599 ns/op
Iteration 10: 330,580 ns/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachStreamBenchmark":
331,444 ±(99.9%) 4,800 ns/op [Average]
(min, avg, max) = (328,436, 331,444, 338,727), stdev = 3,175
CI (99.9%): [326,645, 336,244] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachStreamBenchmark
# Parameters: (N = 1000)
# Run progress: 80,00% complete, ETA 00:01:00
# Fork: 1 of 1
# Warmup Iteration 1: 3734,819 ns/op
# Warmup Iteration 2: 3534,547 ns/op
# Warmup Iteration 3: 3201,812 ns/op
# Warmup Iteration 4: 3151,474 ns/op
# Warmup Iteration 5: 3136,897 ns/op
Iteration 1: 3138,505 ns/op
Iteration 2: 3137,993 ns/op
Iteration 3: 3141,723 ns/op
Iteration 4: 3225,711 ns/op
Iteration 5: 3127,945 ns/op
Iteration 6: 3129,312 ns/op
Iteration 7: 3141,355 ns/op
Iteration 8: 3137,377 ns/op
Iteration 9: 3149,419 ns/op
Iteration 10: 3243,662 ns/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachStreamBenchmark":
3157,300 ±(99.9%) 62,671 ns/op [Average]
(min, avg, max) = (3127,945, 3157,300, 3243,662), stdev = 41,453
CI (99.9%): [3094,629, 3219,972] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachStreamBenchmark
# Parameters: (N = 10000)
# Run progress: 90,00% complete, ETA 00:00:30
# Fork: 1 of 1
# Warmup Iteration 1: 45988,758 ns/op
# Warmup Iteration 2: 45331,295 ns/op
# Warmup Iteration 3: 38213,299 ns/op
# Warmup Iteration 4: 31233,461 ns/op
# Warmup Iteration 5: 31321,451 ns/op
Iteration 1: 31470,793 ns/op
Iteration 2: 32267,081 ns/op
Iteration 3: 31619,772 ns/op
Iteration 4: 32155,094 ns/op
Iteration 5: 31304,547 ns/op
Iteration 6: 31484,244 ns/op
Iteration 7: 31709,801 ns/op
Iteration 8: 31297,118 ns/op
Iteration 9: 31305,782 ns/op
Iteration 10: 31320,821 ns/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.BlackholeConsumingBenchmark.forEachStreamBenchmark":
31593,505 ±(99.9%) 537,786 ns/op [Average]
(min, avg, max) = (31297,118, 31593,505, 32267,081), stdev = 355,712
CI (99.9%): [31055,719, 32131,292] (assumes normal distribution)
# Run complete. Total time: 00:05:03
Benchmark (N) Mode Cnt Score Error Units
BlackholeConsumingBenchmark.forEachListBenchmark 1 avgt 10 6,703 ± 0,230 ns/op
BlackholeConsumingBenchmark.forEachListBenchmark 10 avgt 10 50,719 ± 1,138 ns/op
BlackholeConsumingBenchmark.forEachListBenchmark 100 avgt 10 566,605 ± 11,369 ns/op
BlackholeConsumingBenchmark.forEachListBenchmark 1000 avgt 10 4854,645 ± 40,238 ns/op
BlackholeConsumingBenchmark.forEachListBenchmark 10000 avgt 10 51331,252 ± 335,358 ns/op
BlackholeConsumingBenchmark.forEachStreamBenchmark 1 avgt 10 19,357 ± 0,607 ns/op
BlackholeConsumingBenchmark.forEachStreamBenchmark 10 avgt 10 46,364 ± 1,321 ns/op
BlackholeConsumingBenchmark.forEachStreamBenchmark 100 avgt 10 331,444 ± 4,800 ns/op
BlackholeConsumingBenchmark.forEachStreamBenchmark 1000 avgt 10 3157,300 ± 62,671 ns/op
BlackholeConsumingBenchmark.forEachStreamBenchmark 10000 avgt 10 31593,505 ± 537,786 ns/op
И становится интереснее: разница между
ArrayList.forEach() и ArrayList.stream().forEach() получилась достаточно большой на длинных списках. Более того, прогрев никак не ускоряет ArrayList.forEach(), тогда как ArrayList.stream().forEach() заметно ускоряется.Дело в том, что накладные расходы на создание
Stream оказывают влияние лишь на списках малого размера. В дальнейшем всё сводится к непосредственному итерированию.Так выглядит
ArrayList.forEach(): public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int expectedModCount = modCount;
@SuppressWarnings("unchecked")
final E[] elementData = (E[]) this.elementData;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
action.accept(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
Так выглядит код
ArrayList.ArrayListSpliterator.forEachRemaining(): public void forEachRemaining(Consumer<? super E> action) {
int i, hi, mc; // hoist accesses and checks from loop
ArrayList<E> lst; Object[] a;
if (action == null)
throw new NullPointerException();
if ((lst = list) != null && (a = lst.elementData) != null) {
if ((hi = fence) < 0) {
mc = lst.modCount;
hi = lst.size;
}
else
mc = expectedModCount;
if ((i = index) >= 0 && (index = hi) <= a.length) {
for (; i < hi; ++i) {
@SuppressWarnings("unchecked") E e = (E) a[i];
action.accept(e);
}
if (lst.modCount == mc)
return;
}
}
throw new ConcurrentModificationException();
}
Как видим, разница в коде не существенная (циклы for внутри методов): дальше в дело вступает JIT-компилятор. Андрей apangin помог разобраться в чём тут дело:
Blackhole.consume() не инлайнится и JIT-компилятор не может как следует оптимизировать код: в итоге остаётся и чтение поля modCount, и проверка границ массива.Действительно, попробуем заменить
Blackhole.consume() на свой самопальный метод:Бенчмарк с другим потребителем значений
package ru.gnkoshelev.jbreak2018.perf_tests.for_each;
@Fork(value = 1, warmups = 0)
@Warmup(iterations = 5, time = 2_000, timeUnit = TimeUnit.MILLISECONDS)
@Measurement(iterations = 10, time = 2_000, timeUnit = TimeUnit.MILLISECONDS)
@OutputTimeUnit(value = TimeUnit.NANOSECONDS)
@BenchmarkMode(Mode.AverageTime)
@State(Scope.Benchmark)
public class TrickyConsumingBenchmark {
@Param(value = {"100", "10000"})
public int N;
private List<Integer> values;
@Setup
public void setup() {
Random rand = new Random(12345);
int size = N;
values = new ArrayList<>();
for (int i = 0; i < size; i++) {
values.add(rand.nextInt());
}
}
@Benchmark
public void forEachListBenchmark() {
forEachList(values);
}
@Benchmark
public void forEachStreamBenchmark() {
forEachStream(values);
}
public void forEachList(List<Integer> values) {
values.forEach(TrickyConsumer::consume);
}
public void forEachStream(List<Integer> values) {
values.stream().forEach(TrickyConsumer::consume);
}
public static class TrickyConsumer {
public static Integer value;
public static void consume(Integer value) {
if (! (value % 100 == 0)) {
TrickyConsumer.value = value;
}
}
}
}
Результаты
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.TrickyConsumingBenchmark.forEachListBenchmark
# Parameters: (N = 100)
# Run progress: 0,00% complete, ETA 00:02:00
# Fork: 1 of 1
# Warmup Iteration 1: 205,489 ns/op
# Warmup Iteration 2: 205,514 ns/op
# Warmup Iteration 3: 216,056 ns/op
# Warmup Iteration 4: 208,956 ns/op
# Warmup Iteration 5: 204,900 ns/op
Iteration 1: 205,535 ns/op
Iteration 2: 210,834 ns/op
Iteration 3: 206,050 ns/op
Iteration 4: 205,962 ns/op
Iteration 5: 205,285 ns/op
Iteration 6: 205,581 ns/op
Iteration 7: 204,991 ns/op
Iteration 8: 209,290 ns/op
Iteration 9: 203,927 ns/op
Iteration 10: 204,977 ns/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.TrickyConsumingBenchmark.forEachListBenchmark":
206,243 ±(99.9%) 3,222 ns/op [Average]
(min, avg, max) = (203,927, 206,243, 210,834), stdev = 2,131
CI (99.9%): [203,021, 209,465] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.TrickyConsumingBenchmark.forEachListBenchmark
# Parameters: (N = 10000)
# Run progress: 25,00% complete, ETA 00:01:30
# Fork: 1 of 1
# Warmup Iteration 1: 22733,300 ns/op
# Warmup Iteration 2: 22197,064 ns/op
# Warmup Iteration 3: 21640,616 ns/op
# Warmup Iteration 4: 21411,160 ns/op
# Warmup Iteration 5: 21702,499 ns/op
Iteration 1: 21921,831 ns/op
Iteration 2: 21970,321 ns/op
Iteration 3: 21409,419 ns/op
Iteration 4: 21171,131 ns/op
Iteration 5: 22011,961 ns/op
Iteration 6: 22063,926 ns/op
Iteration 7: 21825,015 ns/op
Iteration 8: 21820,783 ns/op
Iteration 9: 22089,657 ns/op
Iteration 10: 21626,934 ns/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.TrickyConsumingBenchmark.forEachListBenchmark":
21791,098 ±(99.9%) 456,511 ns/op [Average]
(min, avg, max) = (21171,131, 21791,098, 22089,657), stdev = 301,954
CI (99.9%): [21334,587, 22247,609] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.TrickyConsumingBenchmark.forEachStreamBenchmark
# Parameters: (N = 100)
# Run progress: 50,00% complete, ETA 00:01:00
# Fork: 1 of 1
# Warmup Iteration 1: 250,480 ns/op
# Warmup Iteration 2: 247,070 ns/op
# Warmup Iteration 3: 269,745 ns/op
# Warmup Iteration 4: 269,914 ns/op
# Warmup Iteration 5: 272,912 ns/op
Iteration 1: 269,779 ns/op
Iteration 2: 270,502 ns/op
Iteration 3: 269,128 ns/op
Iteration 4: 273,862 ns/op
Iteration 5: 275,447 ns/op
Iteration 6: 272,090 ns/op
Iteration 7: 271,189 ns/op
Iteration 8: 271,714 ns/op
Iteration 9: 269,121 ns/op
Iteration 10: 269,913 ns/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.TrickyConsumingBenchmark.forEachStreamBenchmark":
271,275 ±(99.9%) 3,144 ns/op [Average]
(min, avg, max) = (269,121, 271,275, 275,447), stdev = 2,079
CI (99.9%): [268,131, 274,418] (assumes normal distribution)
# JMH version: 1.20
# VM version: JDK 1.8.0_161, VM 25.161-b12
# VM invoker: C:\Program Files\Java\jre1.8.0_161\bin\java.exe
# VM options: <none>
# Warmup: 5 iterations, 2000 ms each
# Measurement: 10 iterations, 2000 ms each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: ru.gnkoshelev.jbreak2018.perf_tests.for_each.TrickyConsumingBenchmark.forEachStreamBenchmark
# Parameters: (N = 10000)
# Run progress: 75,00% complete, ETA 00:00:30
# Fork: 1 of 1
# Warmup Iteration 1: 22612,079 ns/op
# Warmup Iteration 2: 24943,260 ns/op
# Warmup Iteration 3: 23366,453 ns/op
# Warmup Iteration 4: 23445,251 ns/op
# Warmup Iteration 5: 23732,635 ns/op
Iteration 1: 23575,011 ns/op
Iteration 2: 23478,581 ns/op
Iteration 3: 23663,154 ns/op
Iteration 4: 23067,535 ns/op
Iteration 5: 23489,020 ns/op
Iteration 6: 23461,241 ns/op
Iteration 7: 23510,542 ns/op
Iteration 8: 23504,541 ns/op
Iteration 9: 24036,074 ns/op
Iteration 10: 24081,512 ns/op
Result "ru.gnkoshelev.jbreak2018.perf_tests.for_each.TrickyConsumingBenchmark.forEachStreamBenchmark":
23586,721 ±(99.9%) 442,736 ns/op [Average]
(min, avg, max) = (23067,535, 23586,721, 24081,512), stdev = 292,843
CI (99.9%): [23143,985, 24029,458] (assumes normal distribution)
# Run complete. Total time: 00:02:01
Benchmark (N) Mode Cnt Score Error Units
TrickyConsumingBenchmark.forEachListBenchmark 100 avgt 10 206,243 ± 3,222 ns/op
TrickyConsumingBenchmark.forEachListBenchmark 10000 avgt 10 21791,098 ± 456,511 ns/op
TrickyConsumingBenchmark.forEachStreamBenchmark 100 avgt 10 271,275 ± 3,144 ns/op
TrickyConsumingBenchmark.forEachStreamBenchmark 10000 avgt 10 23586,721 ± 442,736 ns/op
Всё вернулось на круги своя, а как уж тут отработал JIT — совсем другая история.
Выводы
1. Какой же в итоге правильный ответ? методы 1 и 2 в задаче дают незначительно отличающиеся результаты, а метод 3 значительно уступает в производительности.
2. В качестве правильно ответа принимались альтернативные варианты, что 1 быстрее 2 и 2 быстрее 1, если это было верно аргументировано.
3. Личный вывод: кроличья нора оказывается всегда глубже, чем думаешь.
Код бенчмарков можно взять на github: jbreak2018-forEach-perf-tests.
Статистика
Из 32 сданных вариантов было 8 правильных и 5 частично правильных. Ещё 7 человек попали в
PrintStream-ловушку, посчитав параллельный Stream самым быстрым. Никто не поверил в последовательные стримы и не выбрал вариант 2 в качестве самого быстрого.Дополнение
Ниже в комментариях уже обсуждался потенциальный эксплойт, использующий 0-day уязвимость, связанную с произвольными реализациями
List, от которой на конференции защищались в ручном режиме.Спасибо Тагиру lany, реализовавшему вариант подобного эксплойта (в его статье код эксплойта, подробное описание и примеры).
P.S.
Следующую часть постараюсь подготовить на следующих выходных.
UPD. Другие публикации серии: Часть 2, Часть 3, Часть 4.
