Ничто так не раздражает, как заставший врасплох телефонный звонок с неизвестного номера. В наш век мессенджеров и общения перепиской зловеще мерцающий на экране смартфона незнакомый номер телефона может стать причиной как минимум небольшого волнения. Вдвойне бесит, когда звонок поступает не только внезапно (вот такие они, эти звонки), но еще и в неудобное для тебя время. Например, когда ты еще толком не успел проснуться или наоборот, уже вовсю заглядываешься на такую манящую после долгого дня постель. Какие-то деловые звонки по выходным, после девяти вечера или ночью — вообще за гранью добра и зла.

Кстати, обо мне. Меня зовут Наташа, я работаю в Skyeng на позиции Data Scientist и вовлечена в разработку различных продуктов компании. Почему я заговорила о внезапных звонках? Общение голосом с клиентам, которые только хотят начать или по какой-то причине резко прервали обучение — часть модели работы в компании. Звонки помогают вовлечь и вернуть людей в процесс изучения языка, либо напрямую узнать, что же пошло не так. Одна из моих последних задач — анализ работы нашего колл-центра. Я помогла им подобрать оптимальное время для выхода на контакт со студентами по всей России и СНГ: потому что звонки в случайное время суток никто не любит, а бесить собственных пользователей — последнее дело.
Настроение людей в ходе таких звонков для нас крайне важно, потому что оно напрямую влияет на конверсию. Так что давайте я расскажу подробнее о том, как Skyeng звонит студентам и какую прогнозную модель я построила для того, чтобы нашим клиентам было хорошо и комфортно, а мы вышли на показатели конверсии в 60-70%.
Угадать удобное для конкретного человека время звонка физически невозможно, если вы конечно не экстрасенс. Хвала прогрессу, для выявления подобных закономерностей придумали статистику, в модель которой плюс-минус будет укладываться подавляющее большинство пользователей.
В ходе анализа записей нашей CRM, в которой ведется учет деятельности колл-центра, гипотеза о деловых звонках вне рабочего времени и необходимости следовать здравому смыслу лишь подтвердились. Так выяснилось, что лучше всего звонить людям в период с понедельника по четверг, с 10 до 18 часов (внезапно!). Именно в этот временной промежуток люди охотнее всего идут на контакт и звонок продолжается более 15 секунд, то есть считается нами успешным.
Для начала мы решили определить влияние человеческого фактора на конверсию, то есть посмотреть на успехи операторов колл-центра:
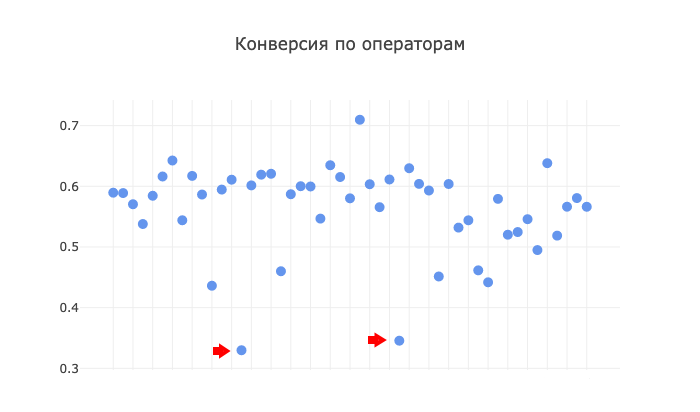
Не надо быть сыщиком, чтобы увидеть два «якоря» на этом графике. Эти две аномалии — операторы с какой-то чрезвычайно низкой эффективностью работы. Что мы делаем с аномальными данными, природа которых кроется, вероятнее всего, в человеческом факторе? Я считаю, что мы подобные данные вовсе исключаем из модели для достижения последующей чистоты и точности результата. Что я, собственно, и сделала. Ну в самом деле, эти два оператора, точнее их результаты, настолько выбиваются из общей картины по колл-центру, что я абсолютно уверена в том, что дело не рабочем процессе, а в самих сотрудниках. Возможно, они новички, что также дает нам повод их исключить.
А вот данные шести других операторов с конверсией ниже 0,5 в модели остаются. Я считаю, что идеальных ситуаций, как и людей, быть не может, так что эти шестеро сбалансируют наши дальнейшие расчеты на фоне остальной выборки из пятидесяти сотрудников.
С часовыми поясами у нас сложилась непростая ситуация. Сейчас мы собираем достаточное количество информации, чтобы определять, откуда студент и когда ему лучше всего звонить. Но так было далеко не всегда. Именно эти пласты старой, но все еще рабочей информации и создавали ряд неудобств как для наших пользователей, так и для операторов колл-центра. Для обработки этих старых данных я написала отдельное вычисление зоны пользователя на основе других косвенных данных (по номеру телефона, региону и информации об использовании нашего приложения).
Если начать копать в статистику CRM глубже, то можно получить еще целый пласт полезной информации для создания эффективной модели. Для начала я построила график конверсии по дням недели, чтобы подтвердить свое первоначальное предположение о том, что звонить лучше в будние дни, кроме пятницы. Собственно, мои предположения оказались верны:

Такое разделение на Москву, Питер и прочие города было сделано именно из-за сомнений в плане определения часового пояса. За нулевой день у нас взят понедельник, соответственно шестой — воскресенье. На графике выше четко видно, насколько сильно проседает конверсия по регионам в выходные дни, что подтверждает гипотезу о проблеме с часовыми поясами, на которые ориентировались операторы колл-центра.
Москва и Питер держатся чуть лучше. Возможно, потому что жители этих городов привыкли к более высокому темпу жизни. Но даже при всем стоицизме москвичей и обитателей города над Невой, цифры говорят, что «нечего звонить с пятницы по воскресенье».
Нижняя граница нашего целевого показателя в 0,6 достигается только однажды — в понедельник, что удивительно, так как принято считать, что этот день самый тяжелый и какие-либо побочные вопросы по понедельникам люди решают неохотно, так как сосредоточены на возвращении в рабочий ритм после выходных. Нет, нет и еще раз нет — цифры не лгут. Дальше по неделе мы идем более-менее ровно, а спад начинается только к четвергу.
Еще интереснее выглядит картина при разложении звонков по часам:

Обратите внимание на сильный хвост слева для регионов. Скорее всего, эти звонки были сделаны в неприемлемое время из-за некорректно определенного часового пояса
А теперь посмотрим на конверсию некоторых дней недели:

Вот данные за наш день-чемпион «понедельник». В начале графика «регионы» выбиваются вперед. Примерно к полудню ситуация выравнивается. Кстати, обратите внимание на симметричное движение нашего графика на отметках 15 и 16 часов; что столицы, что регионы показывают абсолютно одинаковое движение в это время.
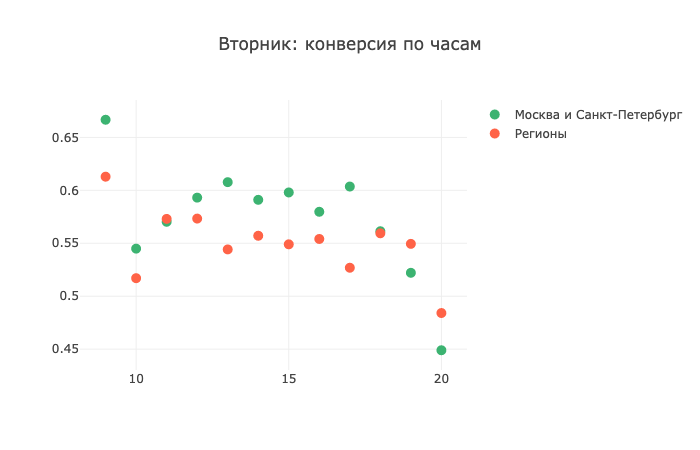
Но вот уже во вторник ситуация начинает меняться:
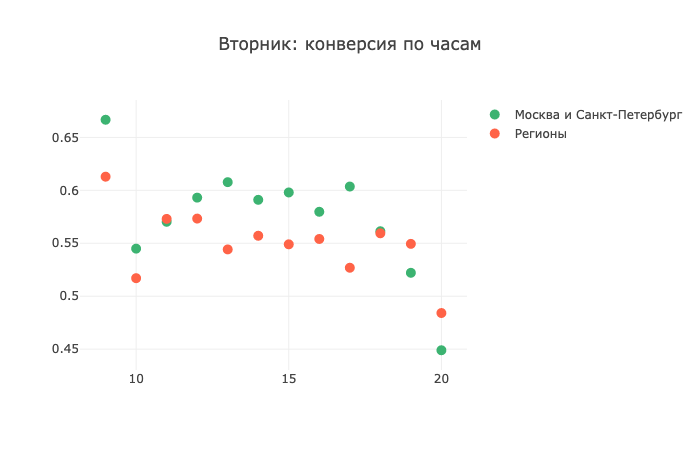
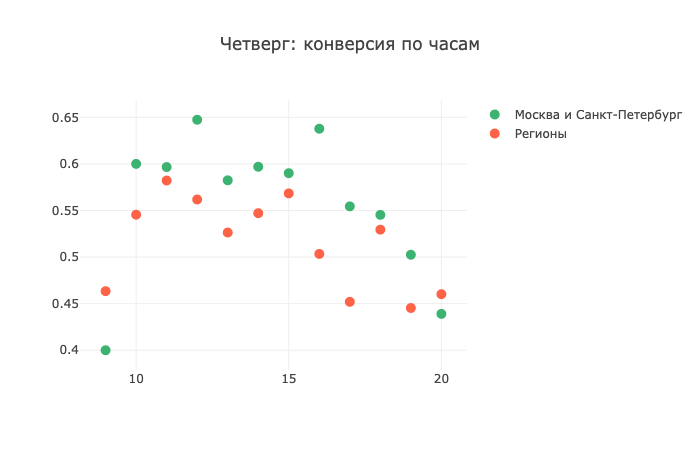
А в четверг регионы показывают свое нежелание отвечать на звонки:

Помните, я говорила, что звонки в выходные дни — это зло? В целом, статистическая картина подтверждает мои слова, но есть одно «но». Короче, смотрите сами:
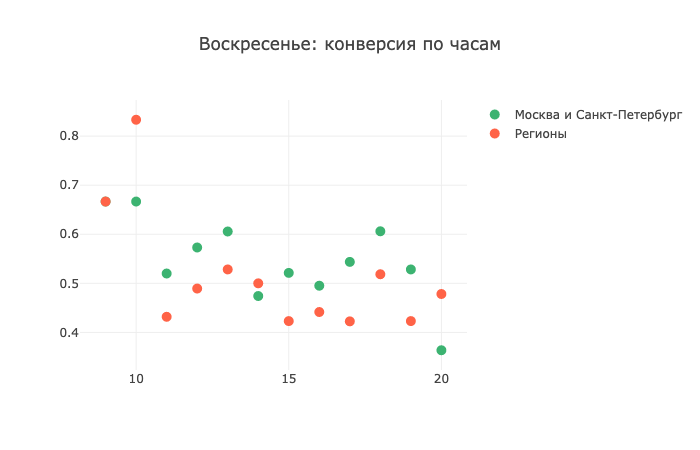
В 9-10 утра по регионам конверсия просто зашкаливает! А уже в 11 утра — еле-еле отрывается от отметки в 0,4, то есть проседает вдвое. У меня нет идей, как это так работает и почему происходит, так что своими теориями можно будет поделиться в комментариях, я бы с удовольствием ознакомилась.
Если обобщить все данные, то можно вывести следующие правила для «удачного» звонка:
Собственно, все укладывается в рамки здравого смысла. По будням с понедельника по четверг — звонить до пяти-шести часов вечера, а в пятницу после полудня решать какие-либо вопросы уже практически невозможно. Немного «плавает» статистика по выходным с упором на вторую половину дня, ну и плюс выбивается из общей картины ранее упоминаемый аномальный пик в 10 утра воскресенья. А так все стабильно.
Прежде чем перейти к построению модели для колл-центра, надо было сделать несколько выводов. Первое — все зависит от времени звонка. Но тут у нас начинаются проблемы.
Единственное, что мы можем отследить — это регион регистрации номера телефона, а уже от этой информации мы отталкиваемся при построении работы колл-центра. Но очень часто возникают ситуации, при которых мы не можем точно определить из какого региона указанный номер.
Именно это, а не какая-то выдуманная леность регионов и приводит к тому, что общие показатели конверсии пользователей за пределами МКАД и КАД проседают относительно столиц. Что мы можем сделать в этой ситуации?
Второй момент особенно важен. Именно такие несовпадения и снижают общий показатель конверсии, а еще бесят клиентов.
Но перейдем к построению модели. Вот общий список признаков, который я выделила как имеющие значение:
Изначально признаков было около ста, но расчеты и тесты показали, что они никак не влияют на конечный результат, так что они были исключены как неинформативные (например, интенсивность уроков, пол ученика, его уровень и так далее). В качестве модели бинарной классификации использовалась библиотека градиентного бустинга на деревьях решений CatBoost.
А вот качество моей модели (на контрольной выборке):
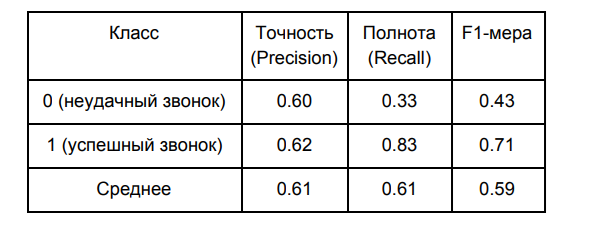
Данные результаты были получены для границы разделения классов, равной 0,5 — это значение по умолчанию. Определим оптимальную границу разделения классов на основании ROC-кривых (receiver operating characteristic).
Для этого построим зависимость таких характеристик как полнота и специфичность в зависимости от различных значений границы, разделяющей классы:
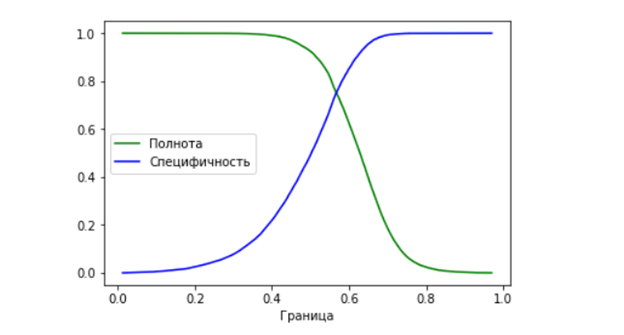
Оптимальное значение границы будет там, где мы получаем одновременно максимально высокие значения полноты и специфичности (то есть в данном случае там, где пересекаются графики). Для полученной модели оптимальная граница получилась 0,56717.
Качество модели с оптимальной границей выглядит следующим образом:

В нашей ситуации нам была важнее точность модели, нежели ее полнота. Именно повышенная точность позволяет нам сократить количество false-positive прогнозов, то есть позволяет нам уменьшить количество ситуаций, когда мы ждали успешного звонка, а он оказался неудачным.
Если резюмировать механизм работы модели:
Так, теперь операторы колл-центра имеют спрогнозированные данные по вероятности дозвона для каждого пользователя, причем на каждый час и день недели. Если звонок не срочный, то оператор может подобрать наиболее оптимальный слот на неделе, а в крайнем случае — если звонок откладывать уже нельзя — самый удачный момент текущего рабочего дня.
Конечно же, после внедрения моей модели надо будет выдержать паузу, а потом проделать всю эту работу заново, но уже с новыми данными. Я могу делать какие-то абстрактные выкладки бесконечно, считать вероятности и добавлять новые переменные в модель, но пока живая статистика не подтвердит мою правоту — закрывать этот вопрос рано.
Если вам понравилось, через некоторое время вернусь уже с новыми данными, полученными после внедрения моей модели прогнозирования.

Кстати, обо мне. Меня зовут Наташа, я работаю в Skyeng на позиции Data Scientist и вовлечена в разработку различных продуктов компании. Почему я заговорила о внезапных звонках? Общение голосом с клиентам, которые только хотят начать или по какой-то причине резко прервали обучение — часть модели работы в компании. Звонки помогают вовлечь и вернуть людей в процесс изучения языка, либо напрямую узнать, что же пошло не так. Одна из моих последних задач — анализ работы нашего колл-центра. Я помогла им подобрать оптимальное время для выхода на контакт со студентами по всей России и СНГ: потому что звонки в случайное время суток никто не любит, а бесить собственных пользователей — последнее дело.
Настроение людей в ходе таких звонков для нас крайне важно, потому что оно напрямую влияет на конверсию. Так что давайте я расскажу подробнее о том, как Skyeng звонит студентам и какую прогнозную модель я построила для того, чтобы нашим клиентам было хорошо и комфортно, а мы вышли на показатели конверсии в 60-70%.
Угадать удобное для конкретного человека время звонка физически невозможно, если вы конечно не экстрасенс. Хвала прогрессу, для выявления подобных закономерностей придумали статистику, в модель которой плюс-минус будет укладываться подавляющее большинство пользователей.
В ходе анализа записей нашей CRM, в которой ведется учет деятельности колл-центра, гипотеза о деловых звонках вне рабочего времени и необходимости следовать здравому смыслу лишь подтвердились. Так выяснилось, что лучше всего звонить людям в период с понедельника по четверг, с 10 до 18 часов (внезапно!). Именно в этот временной промежуток люди охотнее всего идут на контакт и звонок продолжается более 15 секунд, то есть считается нами успешным.
Для начала мы решили определить влияние человеческого фактора на конверсию, то есть посмотреть на успехи операторов колл-центра:
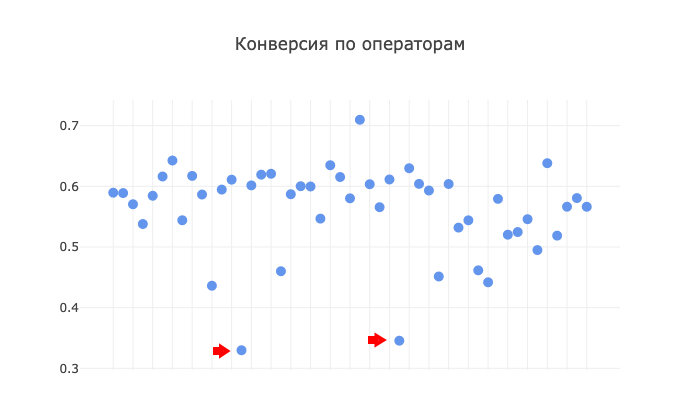
Не надо быть сыщиком, чтобы увидеть два «якоря» на этом графике. Эти две аномалии — операторы с какой-то чрезвычайно низкой эффективностью работы. Что мы делаем с аномальными данными, природа которых кроется, вероятнее всего, в человеческом факторе? Я считаю, что мы подобные данные вовсе исключаем из модели для достижения последующей чистоты и точности результата. Что я, собственно, и сделала. Ну в самом деле, эти два оператора, точнее их результаты, настолько выбиваются из общей картины по колл-центру, что я абсолютно уверена в том, что дело не рабочем процессе, а в самих сотрудниках. Возможно, они новички, что также дает нам повод их исключить.
А вот данные шести других операторов с конверсией ниже 0,5 в модели остаются. Я считаю, что идеальных ситуаций, как и людей, быть не может, так что эти шестеро сбалансируют наши дальнейшие расчеты на фоне остальной выборки из пятидесяти сотрудников.
Часовые пояса, регионы и дни недели
С часовыми поясами у нас сложилась непростая ситуация. Сейчас мы собираем достаточное количество информации, чтобы определять, откуда студент и когда ему лучше всего звонить. Но так было далеко не всегда. Именно эти пласты старой, но все еще рабочей информации и создавали ряд неудобств как для наших пользователей, так и для операторов колл-центра. Для обработки этих старых данных я написала отдельное вычисление зоны пользователя на основе других косвенных данных (по номеру телефона, региону и информации об использовании нашего приложения).
Если начать копать в статистику CRM глубже, то можно получить еще целый пласт полезной информации для создания эффективной модели. Для начала я построила график конверсии по дням недели, чтобы подтвердить свое первоначальное предположение о том, что звонить лучше в будние дни, кроме пятницы. Собственно, мои предположения оказались верны:
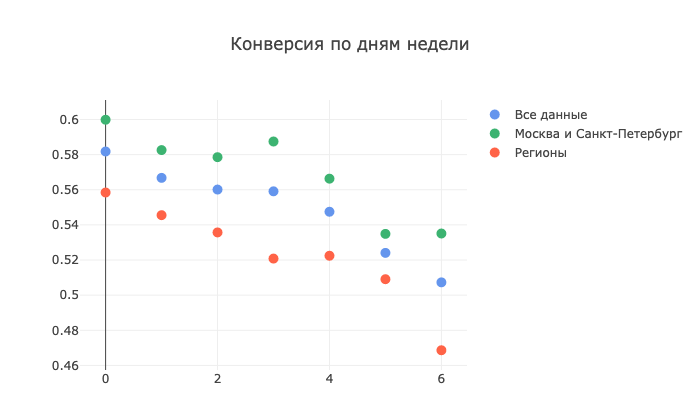
Такое разделение на Москву, Питер и прочие города было сделано именно из-за сомнений в плане определения часового пояса. За нулевой день у нас взят понедельник, соответственно шестой — воскресенье. На графике выше четко видно, насколько сильно проседает конверсия по регионам в выходные дни, что подтверждает гипотезу о проблеме с часовыми поясами, на которые ориентировались операторы колл-центра.
Москва и Питер держатся чуть лучше. Возможно, потому что жители этих городов привыкли к более высокому темпу жизни. Но даже при всем стоицизме москвичей и обитателей города над Невой, цифры говорят, что «нечего звонить с пятницы по воскресенье».
Нижняя граница нашего целевого показателя в 0,6 достигается только однажды — в понедельник, что удивительно, так как принято считать, что этот день самый тяжелый и какие-либо побочные вопросы по понедельникам люди решают неохотно, так как сосредоточены на возвращении в рабочий ритм после выходных. Нет, нет и еще раз нет — цифры не лгут. Дальше по неделе мы идем более-менее ровно, а спад начинается только к четвергу.
Еще интереснее выглядит картина при разложении звонков по часам:
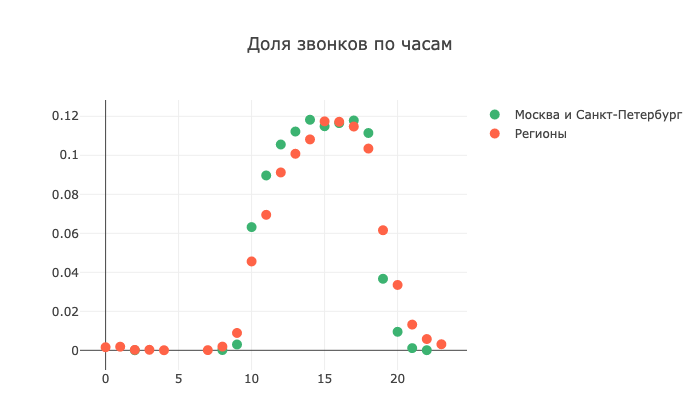
Обратите внимание на сильный хвост слева для регионов. Скорее всего, эти звонки были сделаны в неприемлемое время из-за некорректно определенного часового пояса
А теперь посмотрим на конверсию некоторых дней недели:
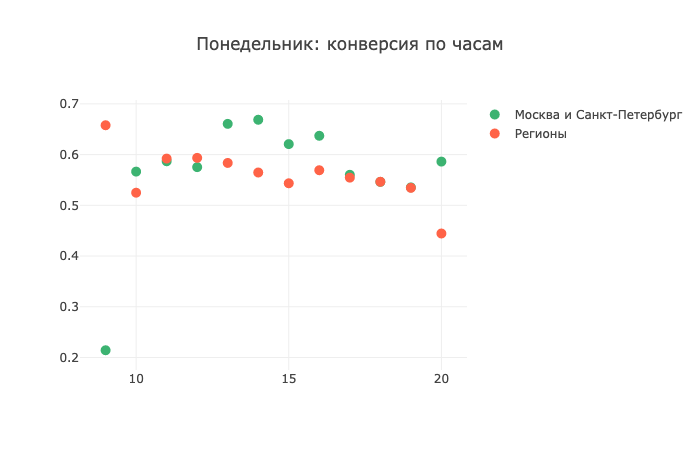
Вот данные за наш день-чемпион «понедельник». В начале графика «регионы» выбиваются вперед. Примерно к полудню ситуация выравнивается. Кстати, обратите внимание на симметричное движение нашего графика на отметках 15 и 16 часов; что столицы, что регионы показывают абсолютно одинаковое движение в это время.
Но вот уже во вторник ситуация начинает меняться:
А в четверг регионы показывают свое нежелание отвечать на звонки:
Помните, я говорила, что звонки в выходные дни — это зло? В целом, статистическая картина подтверждает мои слова, но есть одно «но». Короче, смотрите сами:
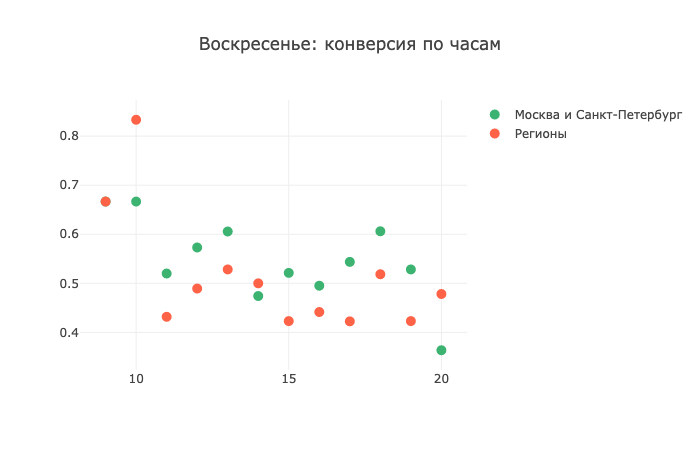
В 9-10 утра по регионам конверсия просто зашкаливает! А уже в 11 утра — еле-еле отрывается от отметки в 0,4, то есть проседает вдвое. У меня нет идей, как это так работает и почему происходит, так что своими теориями можно будет поделиться в комментариях, я бы с удовольствием ознакомилась.
Если обобщить все данные, то можно вывести следующие правила для «удачного» звонка:
- понедельник: с 13 до 17;
- вторник: с 12 до 18;
- среда: с 11 до 12 и с 15 до 17;
- четверг: с 10 до 17;
- пятница: с 10 до 12;
- суббота: с 16 до 18;
- воскресенье: с 13 до 14 и с 18 до 19.
Собственно, все укладывается в рамки здравого смысла. По будням с понедельника по четверг — звонить до пяти-шести часов вечера, а в пятницу после полудня решать какие-либо вопросы уже практически невозможно. Немного «плавает» статистика по выходным с упором на вторую половину дня, ну и плюс выбивается из общей картины ранее упоминаемый аномальный пик в 10 утра воскресенья. А так все стабильно.
Что я со всем этим сделала и какую модель построила
Прежде чем перейти к построению модели для колл-центра, надо было сделать несколько выводов. Первое — все зависит от времени звонка. Но тут у нас начинаются проблемы.
Единственное, что мы можем отследить — это регион регистрации номера телефона, а уже от этой информации мы отталкиваемся при построении работы колл-центра. Но очень часто возникают ситуации, при которых мы не можем точно определить из какого региона указанный номер.
Именно это, а не какая-то выдуманная леность регионов и приводит к тому, что общие показатели конверсии пользователей за пределами МКАД и КАД проседают относительно столиц. Что мы можем сделать в этой ситуации?
- Придерживаться выявленных «горячих» зон для звонков в регионы, если у нас недостаточно данных.
- Нам надо искать инструменты более точного определения местоположения пользователя, чтобы не тревожить его пустыми звонками.
Второй момент особенно важен. Именно такие несовпадения и снижают общий показатель конверсии, а еще бесят клиентов.
Но перейдем к построению модели. Вот общий список признаков, который я выделила как имеющие значение:
- hour — час звонка (категориальный признак от 0 до 23).
- weekday — день недели (категориальный признак от 0 до 6).
- age — возраст ученика.
- lifetime — время жизни ученика (в уроках) на момент звонка.
- app_hour_{k} — суточная сезонность использования приложения. Определяется для каждого часа k как доля действий в приложении в этот час (k=0,..., 23) от общего количества действий в приложении.
- app_weekday_{k} — недельная сезонность использования приложения. Определяется для каждого дня недели k как доля действий в приложении в этот день недели (k=0,..., 6) от общего количества действий в приложении.
- class_hour_{k} — суточная сезонность уроков. Определяется для каждого часа k как доля уроков в этот час (k=0,..., 23) от общего количества уроков.
- class_weekday_{k} — недельная сезонность использования приложения. Определяется для каждого дня недели k как доля уроков в этот день недели (k=0,..., 6) от общего количества уроков.
- is_ru — 1 если страна ученика Россия и 0 если нет.
- last_payment_amount — сумма последней оплаты.
- days_last_lesson — количество дней с последнего урока (в случае отсутствия последнего урока заменяем числом -100).
- days_last_payment — количество дней с последней оплаты (в случае отсутствия последней оплаты заменяем числом -100).
Изначально признаков было около ста, но расчеты и тесты показали, что они никак не влияют на конечный результат, так что они были исключены как неинформативные (например, интенсивность уроков, пол ученика, его уровень и так далее). В качестве модели бинарной классификации использовалась библиотека градиентного бустинга на деревьях решений CatBoost.
А вот качество моей модели (на контрольной выборке):
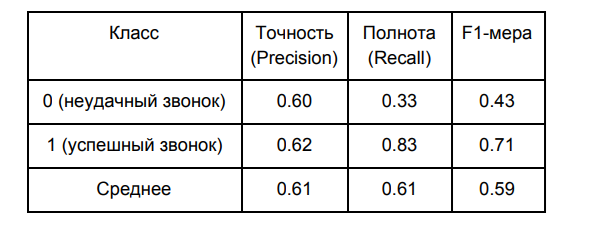
Данные результаты были получены для границы разделения классов, равной 0,5 — это значение по умолчанию. Определим оптимальную границу разделения классов на основании ROC-кривых (receiver operating characteristic).
Для этого построим зависимость таких характеристик как полнота и специфичность в зависимости от различных значений границы, разделяющей классы:
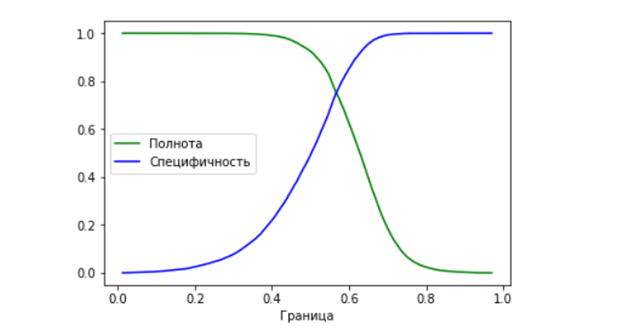
Оптимальное значение границы будет там, где мы получаем одновременно максимально высокие значения полноты и специфичности (то есть в данном случае там, где пересекаются графики). Для полученной модели оптимальная граница получилась 0,56717.
Качество модели с оптимальной границей выглядит следующим образом:
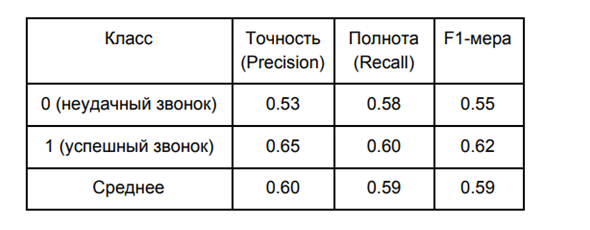
В нашей ситуации нам была важнее точность модели, нежели ее полнота. Именно повышенная точность позволяет нам сократить количество false-positive прогнозов, то есть позволяет нам уменьшить количество ситуаций, когда мы ждали успешного звонка, а он оказался неудачным.
Если резюмировать механизм работы модели:
- для каждого часа суток и дня недели по каждому ученику рассчитывается вероятность дозвона с учетом его характеристик и его локального времени;
- для дальнейшего сохранения выбирается время с 9 до 20 часов для каждого дня недели (время выбирается в соответствии с часовым поясом ученика);
- перед сохранением время сдвигается на московское время, так как дозвон будет осуществляться именно в московском часовом поясе;
- результаты сохраняются в БД.
Так, теперь операторы колл-центра имеют спрогнозированные данные по вероятности дозвона для каждого пользователя, причем на каждый час и день недели. Если звонок не срочный, то оператор может подобрать наиболее оптимальный слот на неделе, а в крайнем случае — если звонок откладывать уже нельзя — самый удачный момент текущего рабочего дня.
Конечно же, после внедрения моей модели надо будет выдержать паузу, а потом проделать всю эту работу заново, но уже с новыми данными. Я могу делать какие-то абстрактные выкладки бесконечно, считать вероятности и добавлять новые переменные в модель, но пока живая статистика не подтвердит мою правоту — закрывать этот вопрос рано.
Если вам понравилось, через некоторое время вернусь уже с новыми данными, полученными после внедрения моей модели прогнозирования.
