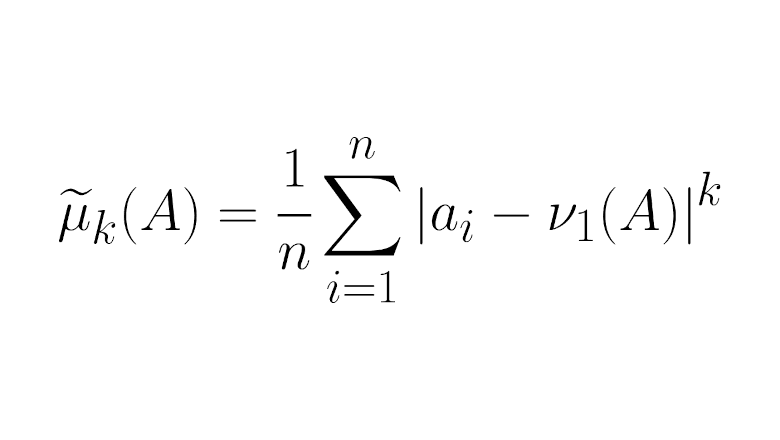
В честь 30-летия OCR мы продолжаем вспоминать, как появились первые отечественные технологии распознавания текста. На прошлой неделе мы рассказали про самую первую такую программу – OCR Tiger, предназначавшуюся для оцифровки книг с целью их дальнейшего переиздания.
Сегодня речь пойдёт про другую OCR-систему – CuneiForm. Она была более продвинутой и умела гораздо больше: распознавала символы различных алфавитов на основе латиницы и кириллицы для европейских языков и языков стран СНГ, работала со смешанными русско-английскими текстами. Самое главное – CuneiForm отличалась огромной по меркам того времени скоростью: 1 страницу она распознавала примерно за 10 секунд. Разберемся, какие алгоритмы использовались в OCR, где применялась CuneiForm и какое дальнейшее развитие получили системы распознавания.