Сегодня я поделюсь некоторыми полезными архитектурными решениями, которые возникли в процессе развития нашего инструмента массового анализа производительности серверов PostgeSQL, и которые помогают нам сейчас «умещать» полноценный мониторинг и анализ более тысячи хостов в то же «железо», которого сначала едва хватало для одной сотни.

Напомню некоторые вводные:
Именно про последний пункт — как все это можно доставить в PostgreSQL-хранилище, и поговорим. В нашем случае таких данных кратно больше, чем исходных — статистика нагрузки в разрезе конкретного приложения и шаблона плана, потребление ресурсов и вычисление производных проблем с точностью до отдельного узла плана, мониторинг блокировок и многое другое.
Существует две основные модели получения логов или каких-то других постоянно приходящих метрик:
У каждой из этих моделей есть положительные и отрицательные стороны.
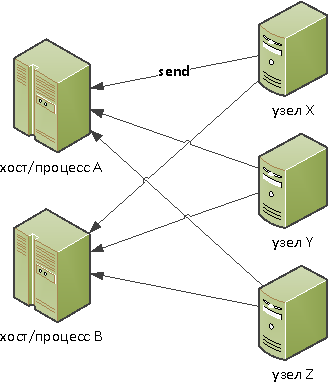
Инициатором взаимодействия выступает наблюдаемый узел:
… выгоден, если:

Пример: приемник оператора ОФД, получающий чеки от каждой клиентской кассы.
… вызывает проблемы:
Инициатором выступает конкретный хост/процесс/поток коллектора, который «привязывает» узел к себе и самостоятельно извлекает данные из «цели»:

… выгоден, если:

Пример: загрузчик/анализатор торгов в разрезе каждой торговой площадки.
… вызывает проблемы:
Поскольку наша модель нагрузки при мониторинге PostgreSQL явно тяготела к pull-алгоритму, а ресурсов одного процесса и ядра современного CPU нам вполне достаточно на один источник, мы остановились именно на нем.
Наше общение с сервером предусматривало очень много сетевых операций и работы со слабоформатированными текстовыми строками, поэтому в качестве ядра коллектора идеально зашел JavaScript в его серверной инкарнации в виде Node.js.
Самым простым решением для получения данных из лога сервера оказалось «зеркалирование» всего лог-файла в консоль с помощью простой linux-команды

Поэтому, сидя на второй стороне SSH-коннекта, коллектор получает «на вход» полную копию всего лог-трафика. А если надо — дозапрашивает у сервера расширенную системную информацию о текущем состоянии дел.
Основных причин две:
В принципе, в качестве СУБД для хранения разобранных из лога данных можно было бы использовать и другие решения, но объем поступающей информации в 150-200GB/сутки оставляет не слишком большое поле для маневра. Поэтому в качестве хранилища мы выбрали тоже PostgreSQL.
— PostgreSQL для хранения логов? Seriously?
— Во-первых, там далеко не только и не столько логи, сколько различные аналитические представления. Во-вторых, «вы просто не умеете их готовить!» :)

Этот момент субъективен и сильно зависит от вашего «железа», но мы для себя вынесли следующие принципы для настройки хоста PostgreSQL под активную запись.
Настройки файловой системы
Наиболее сильно влияющий на производительность записи момент — [не]правильное монтирование раздела данных. Мы выбрали следующие правила:
см. PostgreSQL File System Tuning
Выбор оптимального I/O scheduler
По умолчанию, у многих дистрибутивов в качестве планировщика ввода-вывода выбран
см. PostgreSQL vs. I/O schedulers (cfq, noop and deadline)
Уменьшение размера «грязного» кэша
Параметр
На большинстве дистрибутивов он равен 10%, в CentOS — 5%. Это значит, что при общем объеме памяти на сервере в 16GB, система может попытаться записать на диск разово более 850MB — в результате возникает пиковая нагрузка по IOps.
Экспериментальным путем уменьшаем, пока не начнут сглаживаться пики записи. По опыту, чтобы не образовывалось пиков, размер должен быть меньше максимальной пропускной способности носителя (в IOps), умноженной на размер страницы памяти. То есть, например, для 7K IOps (~7000 x 4096) — около 28MB.
см. Настройка параметров ядра Linux для оптимизации PostgreSQL
Настройки в postgresql.conf
Какие параметры стоит посмотреть-покрутить для ускорения записи. Тут все сугубо индивидуально, поэтому приведу только некоторые соображения на тему:
Часть статей про оптимизацию физического хранения данных я уже публиковал:
А вот про различные ключи в данных — еще не было. Про них и расскажу.
Foreign Keys — это зло для нагруженных по записи систем. На самом деле, это «костыли», которые не позволяют нерадивому программисту записать в базу то, чего там якобы не должно быть.
Многие разработчики привыкли, что логически связанные бизнес-сущности на уровне описания таблиц БД обязательно должны быть повязаны через FK. Но это не так!
Конечно, этот момент очень сильно зависит от целей, которые вы ставите, записывая данные в базу. Если вы не банк (а если и банк — то не процессинг!), то необходимость FK в heavy-write базе под большим вопросом.
«Технически» каждый FK при вставке записи делает отдельный SELECT из таблицы, на которую ссылается. Теперь посмотрите на таблицу, куда вы активно пишете, где у вас висят 2-3 FK, и оцените, стоит ли для вашей конкретной задачи обеспечение вроде-как-целостности падения производительности в 3-4 раза… Или логической связи по значению — достаточно? Мы вот у себя все FK — убрали.
UUID Keys — это добро. Поскольку крайне мала вероятность коллизии генерируемых в разных несвязанных точках UUID, то эту нагрузку (по генерации неких суррогатных ID) можно смело убрать с БД на «потребителя». Использование UUID — это правило хорошего тона в связанных несинхронизирующихся распределенных системах.
Естественные ключи — это тоже добро, даже если они состоят из нескольких полей. Бояться надо не составных ключей, а лишнего суррогатного PK-поля и индекса по нему в нагруженной таблице, без которых можно легко обойтись.
При этом никто не запрещает комбинировать подходы. К примеру, у нас «пакету» последовательных записей лога, относящихся к одной исходной транзакции, присваивается суррогатный UUID (поскольку естественного ключа просто нет), но в качестве PK используется пара
PostgreSQL, как и OC, «не любит», когда в него пишут данные громадными пакетами (типа

Тут надо отметить основное преимущество, которое мы получили при такой схеме чтения и записи логов — в нашей базе «факты» становятся доступны для анализа практически в режиме online, спустя единицы секунд.
Вроде все уже хорошо. Где же «грабли» в предыдущей схеме? Начнем с простого…
Одна из больших бед нагруженных систем — это избыточная синхронизация каких-то операций того не требующих. Иногда «потому что не заметили», иногда «так было проще», но рано или поздно приходится от нее избавляться.
Добиться этого достаточно просто. У нас на мониторинг было заведено уже почти 1000 серверов, каждый обрабатывается отдельным логическим потоком, а каждый поток сбрасывает накопленную информацию для отправки в базу с определенной периодичностью, примерно так:
Проблема тут кроется ровно в том, что все потоки стартуют примерно в одно время, поэтому моменты отправки у них почти всегда совпадают «до точки».

К счастью, правится это достаточно легко — добавлением «случайной» разбежки по времени как для момента старта, так и для интервала:

Такой способ позволяет статистически «размазать» нагрузку на запись, превратив ее в практически равномерную.
Одного ядра процессора на всю нашу нагрузку явно не хватит, но тут нам поможет модуль cluster, который позволяет легко управлять созданием дочерних процессов и общаться с ними через IPC.
Теперь у нас на 16 ядер процессора 16 дочерних процессов — и это хорошо, мы можем использовать весь CPU! Но в каждом процессе мы пишем в 16 целевых табличек, а когда приходит пиковая нагрузка — открываем еще и дополнительные COPY-каналы. То есть на базе постоянно 256+ активно пишущих потоков… ой! На дисковой производительности такой хаос сказывается ни разу не хорошо, и на базе начало подгорать.
Особенно печально это сказывалось при попытке записать какие-то общие словари — например, одинаковый текст запроса, пришедший с разных узлов — ненужные блокировки, ожидания…
«Перевернем» ситуацию — то есть пусть дочерние процессы по-прежнему собирают, обрабатывают информацию со своих источников, но не пишут в базу! Вместо этого пусть они отправляют по IPC сообщение в master, а он уже пишет что-куда надо:
Кто сразу увидел проблему в схеме предыдущего абзаца — молодец. Кроется она ровно в том моменте, что master — это тоже процесс с ограниченными ресурсами. Поэтому в какой-то момент мы обнаружили, что подгорать начало уже у него — банально перестал справляться с перекладыванием всех-всех потоков в базу, поскольку тоже ограничен ресурсами одного ядра CPU. В результате, мы оставили большую часть наименее нагруженных «словарных» потоков писаться через master, а наиболее нагруженные, но не требующие дополнительной обработки — вернули в worker'ы:

Но даже одного узла недостаточно, чтобы обслужить всю имеющуюся нагрузку — пора подумать о линейном масштабировании. Решением стал автобалансирующийся по нагрузке мультиколлектор с координатором во главе.

Каждый master сбрасывает ему текущую нагрузку всех своих worker'ов, а в ответ получает рекомендации, мониторинг какого узла стоит передать на другой worker или даже на другой коллектор. Про алгоритмы такой балансировки будет отдельная статья.
Следующий правильный вопрос — что делать с потоками на запись, когда приходит внезапная пиковая нагрузка.
Ведь мы не можем открывать все новые и новые соединения к базе бесконечно — неэффективно это, да и не поможет. Банальное решение — давайте ограничим, чтобы у нас было не более 16 одновременно активных потоков на каждую из целевых таблиц. Но что делать с данными, которые мы все равно «не успели» записать?..
Если этот «всплеск» нагрузки именно пиковый, то есть кратковременный, то мы можем временно сохранить данные в очереди в памяти самого коллектора. Как только какой-то канал до базы освобождается — извлекаем запись из очереди и отправляем в поток.
Да, это требует от коллектора иметь некоторый буфер для хранения очередей, но он достаточно невелик и оперативно освобождается:
Внимательный читатель, посмотрев на предыдущую картинку снова озадачился «а что же будет, когда память совсем кончится?..» Тут вариантов уже немного — кем-то придется пожертвовать.
Но не все записи, которые мы хотим доставить в базу, «одинаково полезны». В наших интересах записать их как можно больше, количественно. В этом нам поможет примитивная «экспоненциальная приоритезация» по размеру записываемой строки:
Соответственно, при записи в канал мы всегда начинаем черпать с «младших» очередей — просто каждая отдельная строка там короче, и сможем отправить их количественно больше:
Теперь вернемся на два шага назад. К тому моменту, когда решили оставить максимум 16 потоков в адрес одной таблицы. Если целевая таблица — «потоковая», то есть записи никак не коррелируют между собой — все хорошо. Максимум — у нас будут «физические» блокировки на дисковом уровне.
Но если это таблица агрегатов или вовсе «словарик», то при попытках записи из разных потоков строк с одинаковым PK мы будем получать ожидание на блокировке, а то и deadlock. Грустно…
Но ведь что-куда писать — определяем мы сами! Ключевой момент — не пытаться писать один PK из разных мест.
То есть при проходе очереди сразу смотрим, не пишет ли уже какой-то поток в ту же таблицу (мы же помним, что они у нас все в общем адресном пространстве одного процесса) такой PK. Если нет — берем себе и записываем в in-memory-словарик «за собой», если уже чей-то — подкладываем ему в очередь.
При завершении транзакции просто «вычищаем» из словарика закрепление «за собой».
Во-первых, при LRU практически всегда «первые» соединения и обслуживающие их процессы PostgreSQL работают все время. Это значит, что ОС гораздо реже переключает их между ядрами CPU, минимизируя простои.

Во-вторых, если вы практически все время работаете с одними и теми же процессами на стороне сервера, резко снижаются шансы, что какие-то два процесса окажутся активны одновременно — соответственно, уменьшается пиковая нагрузка на CPU в целом (серая область на втором графике слева) и падает LA, поскольку своей очереди ждут уже меньше процессов.

На этом пока все на сегодня.
И напомню, что с помощью explain.tensor.ru вы можете посмотреть различные варианты визуализации плана выполнения запроса, которые помогут вам наглядно увидеть проблемные места.

Intro
Напомню некоторые вводные:
- мы строим сервис, который получает информацию из логов серверов PostgreSQL
- собирая логи, мы хотим что-то с ними делать (парсить, анализировать, запрашивать дополнительную информацию) в режиме онлайн
- все собранное и «наанализированное» надо куда-то сохранить
Именно про последний пункт — как все это можно доставить в PostgreSQL-хранилище, и поговорим. В нашем случае таких данных кратно больше, чем исходных — статистика нагрузки в разрезе конкретного приложения и шаблона плана, потребление ресурсов и вычисление производных проблем с точностью до отдельного узла плана, мониторинг блокировок и многое другое.
Более полно о принципах работы сервиса можно посмотреть в видео доклада и прочитать в статье «Массовая оптимизация запросов PostgreSQL».
push vs pull
Существует две основные модели получения логов или каких-то других постоянно приходящих метрик:
- push — на сервисе множество равноправных приемников, на наблюдаемых серверах — некий локальный агент, периодически сбрасывающий накопленную информацию в сервис
- pull — на сервисе каждый процесс/поток/корутина/… обрабатывает информацию только от одного «своего» источника, получение данных с которого инициирует сам
У каждой из этих моделей есть положительные и отрицательные стороны.
push
Инициатором взаимодействия выступает наблюдаемый узел:

… выгоден, если:
- у вас очень много источников (сотни тысяч)
- нагрузка на них не сильно разнится между собой и не превосходит ~1rps
- какая-то сложная обработка не нужна

Пример: приемник оператора ОФД, получающий чеки от каждой клиентской кассы.
… вызывает проблемы:
- блокировки/deadlock при попытках записи словарей/аналитики/агрегатов в разрезе объекта мониторинга из разных потоков
- худшая утилизация кэша каждого процесса БЛ/подключения к БД — например, одно и то же подключение к базе должно сначала написать в одну таблицу или сегмент индекса, и сразу же — в другую
- необходим специальный агент, размещаемый на каждом источнике, что увеличивает нагрузку на него
- большие издержки при сетевом взаимодействии — заголовками приходится «обвязывать» отправку каждого пакета, а не всего соединения с источником в целом
pull
Инициатором выступает конкретный хост/процесс/поток коллектора, который «привязывает» узел к себе и самостоятельно извлекает данные из «цели»:

… выгоден, если:
- у вас немного источников (сотни-тысячи)
- нагрузка от них есть почти всегда, иногда доходит до 1Krps
- требуется сложная обработка с сегментацией по источнику

Пример: загрузчик/анализатор торгов в разрезе каждой торговой площадки.
… вызывает проблемы:
- ограничение ресурсов на обработку одного источника одним процессом (ядром CPU), поскольку ее никак не «размазать» по двум получателям
- необходим координатор, динамически перераспределяющий нагрузку от источников по существующим процессам/потокам/ресурсам
Поскольку наша модель нагрузки при мониторинге PostgreSQL явно тяготела к pull-алгоритму, а ресурсов одного процесса и ядра современного CPU нам вполне достаточно на один источник, мы остановились именно на нем.
Тянем-потянем логи
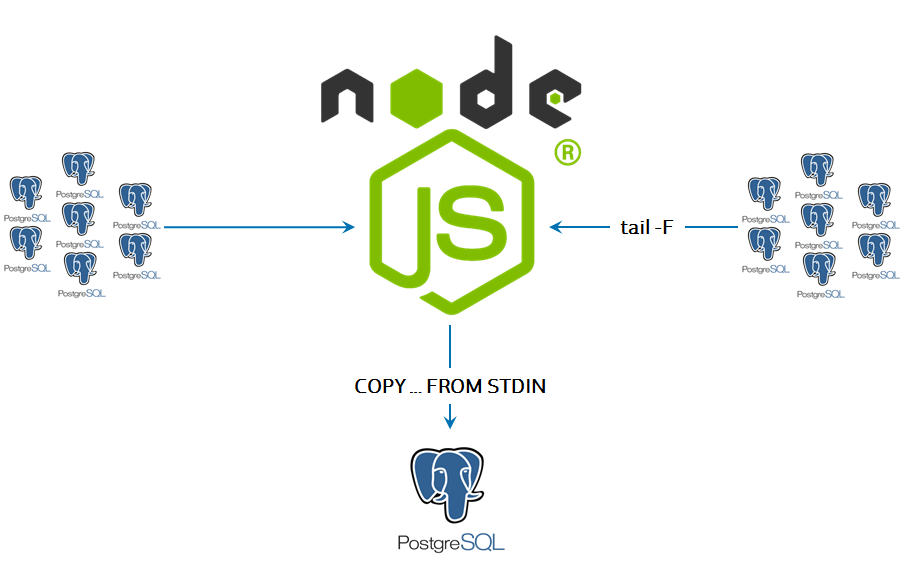
Наше общение с сервером предусматривало очень много сетевых операций и работы со слабоформатированными текстовыми строками, поэтому в качестве ядра коллектора идеально зашел JavaScript в его серверной инкарнации в виде Node.js.
Самым простым решением для получения данных из лога сервера оказалось «зеркалирование» всего лог-файла в консоль с помощью простой linux-команды
tail -F <current.log>. Только консоль у нас не простая, а виртуальная — внутри натянутого по протоколу SSH защищенного соединения с сервером.
Поэтому, сидя на второй стороне SSH-коннекта, коллектор получает «на вход» полную копию всего лог-трафика. А если надо — дозапрашивает у сервера расширенную системную информацию о текущем состоянии дел.
Почему не syslog
Основных причин две:
syslogработает по push-модели, поэтому невозможно оперативно управлять нагрузкой обработки генерируемого им потока в точке приема. То есть если какая-то пара хостов внезапно начала «сыпать» тысячами планов медленных запросов, то развести их обработку по разным узлам крайне сложно.
Под обработкой тут подразумевается не столько «тупой» прием/парсинг лога, сколько разбор планов и вычисление реальной ресурсоемкости каждого из узлов.- При мониторинге PostgreSQL, в любом случае, возникает периодическая необходимость оперативного обращения к конкретной БД для получения «слепка» блокировок как только информация о них возникла в логе и расширенной информации об участвующих объектах (relation/page/tuple/...).
Подробнее о решении этой задачи можно прочитать в статье «DBA: в погоне за пролетающими блокировками».
Настройка базы-приемника
В принципе, в качестве СУБД для хранения разобранных из лога данных можно было бы использовать и другие решения, но объем поступающей информации в 150-200GB/сутки оставляет не слишком большое поле для маневра. Поэтому в качестве хранилища мы выбрали тоже PostgreSQL.
— PostgreSQL для хранения логов? Seriously?
— Во-первых, там далеко не только и не столько логи, сколько различные аналитические представления. Во-вторых, «вы просто не умеете их готовить!» :)

Настройки сервера
Этот момент субъективен и сильно зависит от вашего «железа», но мы для себя вынесли следующие принципы для настройки хоста PostgreSQL под активную запись.
Настройки файловой системы
Наиболее сильно влияющий на производительность записи момент — [не]правильное монтирование раздела данных. Мы выбрали следующие правила:
- каталог PGDATA монтируется (если речь идет о ext4) с параметрами
noatime,nodiratime,barrier=0,errors=remount-ro,data=writeback,nobh - каталог PGDATA/pg_stat_tmp выносится на
tmpfs - каталог PGDATA/pg_wal выносится на другой носитель, если это разумно
см. PostgreSQL File System Tuning
Выбор оптимального I/O scheduler
По умолчанию, у многих дистрибутивов в качестве планировщика ввода-вывода выбран
cfq, заточенный под «десктопное» использование, в RedHat и CentOS — noop. Но для нас полезнее оказался deadline.см. PostgreSQL vs. I/O schedulers (cfq, noop and deadline)
Уменьшение размера «грязного» кэша
Параметр
vm.dirty_background_bytes задает размер кэша в байтах, при достижении которого, система начинает фоновый процесс его сброса на диск. Есть аналогичный, но взаимоисключающий параметр vm.dirty_background_ratio — он задает это же значение в процентах от общего объема памяти — по умолчанию, задан именно он, а не "...bytes".На большинстве дистрибутивов он равен 10%, в CentOS — 5%. Это значит, что при общем объеме памяти на сервере в 16GB, система может попытаться записать на диск разово более 850MB — в результате возникает пиковая нагрузка по IOps.
Экспериментальным путем уменьшаем, пока не начнут сглаживаться пики записи. По опыту, чтобы не образовывалось пиков, размер должен быть меньше максимальной пропускной способности носителя (в IOps), умноженной на размер страницы памяти. То есть, например, для 7K IOps (~7000 x 4096) — около 28MB.
см. Настройка параметров ядра Linux для оптимизации PostgreSQL
Настройки в postgresql.conf
Какие параметры стоит посмотреть-покрутить для ускорения записи. Тут все сугубо индивидуально, поэтому приведу только некоторые соображения на тему:
shared_buffers— стоит сделать поменьше, так как при таргетированной записи особо пересекающихся «общих» данных у процессов не возникаетsynchronous_commit = off— можете выключить ожидание записи коммита всегда, если доверяете батарейке своего RAID-контроллераfsync— если данные ну совсем некритичны, можно попробовать выключить — «в пределе» можно получить даже in-memory DB
Структура таблиц БД
Часть статей про оптимизацию физического хранения данных я уже публиковал:
- про секционирование таблиц — «Пишем в PostgreSQL на субсветовой: 1 host, 1 day, 1TB»
- про настройку TOAST — «Экономим копеечку на больших объемах в PostgreSQL»
А вот про различные ключи в данных — еще не было. Про них и расскажу.
Foreign Keys — это зло для нагруженных по записи систем. На самом деле, это «костыли», которые не позволяют нерадивому программисту записать в базу то, чего там якобы не должно быть.
Многие разработчики привыкли, что логически связанные бизнес-сущности на уровне описания таблиц БД обязательно должны быть повязаны через FK. Но это не так!
Конечно, этот момент очень сильно зависит от целей, которые вы ставите, записывая данные в базу. Если вы не банк (а если и банк — то не процессинг!), то необходимость FK в heavy-write базе под большим вопросом.
«Технически» каждый FK при вставке записи делает отдельный SELECT из таблицы, на которую ссылается. Теперь посмотрите на таблицу, куда вы активно пишете, где у вас висят 2-3 FK, и оцените, стоит ли для вашей конкретной задачи обеспечение вроде-как-целостности падения производительности в 3-4 раза… Или логической связи по значению — достаточно? Мы вот у себя все FK — убрали.
UUID Keys — это добро. Поскольку крайне мала вероятность коллизии генерируемых в разных несвязанных точках UUID, то эту нагрузку (по генерации неких суррогатных ID) можно смело убрать с БД на «потребителя». Использование UUID — это правило хорошего тона в связанных несинхронизирующихся распределенных системах.
Про другие варианты уникальных идентификаторов в PostgreSQL можно почитать в статье «PostgreSQL Antipatterns: уникальные идентификаторы».
Естественные ключи — это тоже добро, даже если они состоят из нескольких полей. Бояться надо не составных ключей, а лишнего суррогатного PK-поля и индекса по нему в нагруженной таблице, без которых можно легко обойтись.
При этом никто не запрещает комбинировать подходы. К примеру, у нас «пакету» последовательных записей лога, относящихся к одной исходной транзакции, присваивается суррогатный UUID (поскольку естественного ключа просто нет), но в качестве PK используется пара
(pack::uuid, recno::int2), где recno — это «естественный» порядковый номер записи в рамках пакета.«Бесконечные» COPY-потоки
PostgreSQL, как и OC, «не любит», когда в него пишут данные громадными пакетами (типа
INSERT на 1000 строк). А вот к сбалансированным потокам записи (через COPY) относится гораздо более терпимо. Но их надо уметь очень аккуратно готовить.
- Поскольку на предыдущем этапе мы убрали все FK, то теперь мы можем информацию о самом
packи набор связанных с нимreсordписать в произвольном порядке, асинхронно. Наиболее эффективно в этом случае держать на каждую целевую таблицу постоянно активныйCOPY-канал. - Чтобы другие работающие с базой процессы не висели долго в потенциальных блокировках, да и вообще, отправленные в канал данные стали «видны», транзакцию (а для этого —
COPY-канал) надо периодически закрывать и переоткрывать снова. Как показала практика, оптимально для нас — примерно раз в 100мс, но тут все сильно зависит от конкретной нагрузки. - Строки, отправляемые в канал, не стоит буферизировать. Вообще. Потому что это заведомо вызывает некий пик по носителю.
С другой стороны, писать в канал больше, чем он может «переварить» на стороне сервера, смысла тоже нет. Потому что это вызовет пиковую запись на диск большого накопленного буфера, что приведет к блокировкам всех других пишущих процессов. - В этом плане, у node-pg, драйвера PostgreSQL для Node.js, очень удобное API — вызов
stream.write(data)наCOPY-канале вернетtrue, если запись успешно обработана сервером, илиfalse, если возникла буферизация.
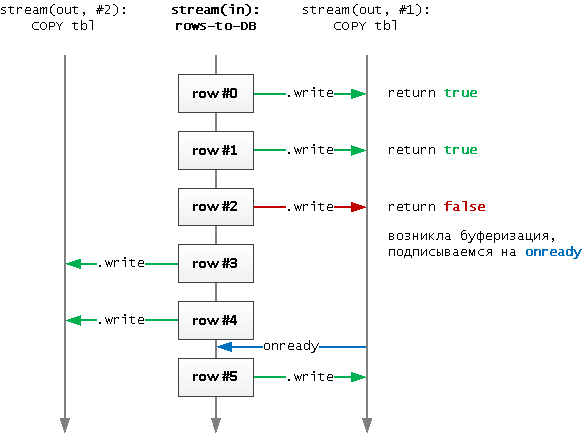
Таким образом, мы сразу понимаем, когда конкретного стрима уже «не хватает», и пора порождать в пуле каналов новыйCOPYк той же таблице. - Выбор очередного
COPY-канала из пула происходит по алгоритму LRU среди всех «незанятых». Что позволяет оперативно избавляться от ставших избыточными каналов после спада пиковой активности.


Тут надо отметить основное преимущество, которое мы получили при такой схеме чтения и записи логов — в нашей базе «факты» становятся доступны для анализа практически в режиме online, спустя единицы секунд.
Доработка напильником
Вроде все уже хорошо. Где же «грабли» в предыдущей схеме? Начнем с простого…
Избыточная синхронизация
Одна из больших бед нагруженных систем — это избыточная синхронизация каких-то операций того не требующих. Иногда «потому что не заметили», иногда «так было проще», но рано или поздно приходится от нее избавляться.
Добиться этого достаточно просто. У нас на мониторинг было заведено уже почти 1000 серверов, каждый обрабатывается отдельным логическим потоком, а каждый поток сбрасывает накопленную информацию для отправки в базу с определенной периодичностью, примерно так:
setInterval(writeDB, interval)Проблема тут кроется ровно в том, что все потоки стартуют примерно в одно время, поэтому моменты отправки у них почти всегда совпадают «до точки».

К счастью, правится это достаточно легко — добавлением «случайной» разбежки по времени как для момента старта, так и для интервала:
setInterval(writeDB, interval * (1 + 0.1 * (Math.random() - 0.5)))
Такой способ позволяет статистически «размазать» нагрузку на запись, превратив ее в практически равномерную.
Масштабирование по CPU cores
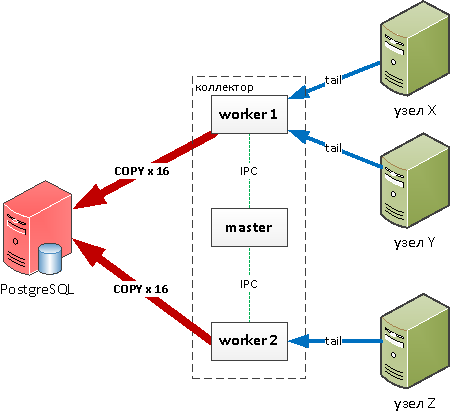
Одного ядра процессора на всю нашу нагрузку явно не хватит, но тут нам поможет модуль cluster, который позволяет легко управлять созданием дочерних процессов и общаться с ними через IPC.
Теперь у нас на 16 ядер процессора 16 дочерних процессов — и это хорошо, мы можем использовать весь CPU! Но в каждом процессе мы пишем в 16 целевых табличек, а когда приходит пиковая нагрузка — открываем еще и дополнительные COPY-каналы. То есть на базе постоянно 256+ активно пишущих потоков… ой! На дисковой производительности такой хаос сказывается ни разу не хорошо, и на базе начало подгорать.
Особенно печально это сказывалось при попытке записать какие-то общие словари — например, одинаковый текст запроса, пришедший с разных узлов — ненужные блокировки, ожидания…

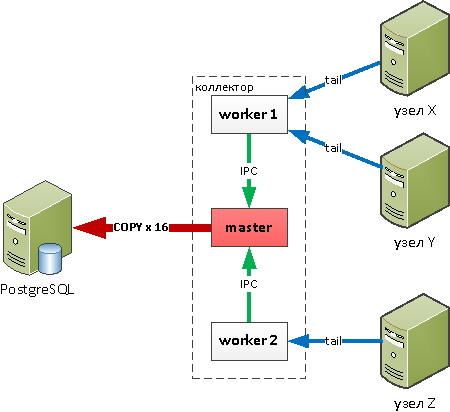
«Перевернем» ситуацию — то есть пусть дочерние процессы по-прежнему собирают, обрабатывают информацию со своих источников, но не пишут в базу! Вместо этого пусть они отправляют по IPC сообщение в master, а он уже пишет что-куда надо:

Кто сразу увидел проблему в схеме предыдущего абзаца — молодец. Кроется она ровно в том моменте, что master — это тоже процесс с ограниченными ресурсами. Поэтому в какой-то момент мы обнаружили, что подгорать начало уже у него — банально перестал справляться с перекладыванием всех-всех потоков в базу, поскольку тоже ограничен ресурсами одного ядра CPU. В результате, мы оставили большую часть наименее нагруженных «словарных» потоков писаться через master, а наиболее нагруженные, но не требующие дополнительной обработки — вернули в worker'ы:

Мультиколлектор
Но даже одного узла недостаточно, чтобы обслужить всю имеющуюся нагрузку — пора подумать о линейном масштабировании. Решением стал автобалансирующийся по нагрузке мультиколлектор с координатором во главе.

Каждый master сбрасывает ему текущую нагрузку всех своих worker'ов, а в ответ получает рекомендации, мониторинг какого узла стоит передать на другой worker или даже на другой коллектор. Про алгоритмы такой балансировки будет отдельная статья.
Ограничение пулинга и очереди
Следующий правильный вопрос — что делать с потоками на запись, когда приходит внезапная пиковая нагрузка.
Ведь мы не можем открывать все новые и новые соединения к базе бесконечно — неэффективно это, да и не поможет. Банальное решение — давайте ограничим, чтобы у нас было не более 16 одновременно активных потоков на каждую из целевых таблиц. Но что делать с данными, которые мы все равно «не успели» записать?..
Если этот «всплеск» нагрузки именно пиковый, то есть кратковременный, то мы можем временно сохранить данные в очереди в памяти самого коллектора. Как только какой-то канал до базы освобождается — извлекаем запись из очереди и отправляем в поток.
Да, это требует от коллектора иметь некоторый буфер для хранения очередей, но он достаточно невелик и оперативно освобождается:

Приоритеты очередей
Внимательный читатель, посмотрев на предыдущую картинку снова озадачился «а что же будет, когда память совсем кончится?..» Тут вариантов уже немного — кем-то придется пожертвовать.
Но не все записи, которые мы хотим доставить в базу, «одинаково полезны». В наших интересах записать их как можно больше, количественно. В этом нам поможет примитивная «экспоненциальная приоритезация» по размеру записываемой строки:
let priority = Math.trunc(Math.log2(line.length));
queue[priority].push(line);Соответственно, при записи в канал мы всегда начинаем черпать с «младших» очередей — просто каждая отдельная строка там короче, и сможем отправить их количественно больше:
let qkeys = Object.keys(queue);
qkeys.sort((x, y) => x.valueOf() - y.valueOf()); // ключи-то - текстовые!
Побеждаем блокировки
Теперь вернемся на два шага назад. К тому моменту, когда решили оставить максимум 16 потоков в адрес одной таблицы. Если целевая таблица — «потоковая», то есть записи никак не коррелируют между собой — все хорошо. Максимум — у нас будут «физические» блокировки на дисковом уровне.
Но если это таблица агрегатов или вовсе «словарик», то при попытках записи из разных потоков строк с одинаковым PK мы будем получать ожидание на блокировке, а то и deadlock. Грустно…
Но ведь что-куда писать — определяем мы сами! Ключевой момент — не пытаться писать один PK из разных мест.
То есть при проходе очереди сразу смотрим, не пишет ли уже какой-то поток в ту же таблицу (мы же помним, что они у нас все в общем адресном пространстве одного процесса) такой PK. Если нет — берем себе и записываем в in-memory-словарик «за собой», если уже чей-то — подкладываем ему в очередь.
При завершении транзакции просто «вычищаем» из словарика закрепление «за собой».
Немного пруфов
Во-первых, при LRU практически всегда «первые» соединения и обслуживающие их процессы PostgreSQL работают все время. Это значит, что ОС гораздо реже переключает их между ядрами CPU, минимизируя простои.

Во-вторых, если вы практически все время работаете с одними и теми же процессами на стороне сервера, резко снижаются шансы, что какие-то два процесса окажутся активны одновременно — соответственно, уменьшается пиковая нагрузка на CPU в целом (серая область на втором графике слева) и падает LA, поскольку своей очереди ждут уже меньше процессов.

На этом пока все на сегодня.
И напомню, что с помощью explain.tensor.ru вы можете посмотреть различные варианты визуализации плана выполнения запроса, которые помогут вам наглядно увидеть проблемные места.
