В нашем СБИС, как и в любой другой системе работы с документами, по мере накопления данных у пользователей возникает желание их "поискать".
Но, поскольку люди — не компьютеры, то и ищут они примерно как "что-то там такое было от Иванова или от Ивановского… нет, не то, раньше, еще раньше… вот оно!"
 То есть технически верное решение — это префиксный полнотекстовый поиск с ранжированием результатов по дате.
То есть технически верное решение — это префиксный полнотекстовый поиск с ранжированием результатов по дате.
Но разработчику это грозит жуткими проблемами — ведь для FTS-поиска в PostgreSQL используются «пространственные» типы индексов GIN и GiST, которые не предусматривают «подсовывания» дополнительных данных, кроме текстового вектора.
Остается только грустно вычитывать все записи по совпадению префикса (тысячи их!) и сортировать или, наоборот, идти по индексу даты и фильтровать все встречающиеся записи на совпадение префикса, пока не найдем подходящие (как скоро найдется «абракадабра»?..).
И то, и другое не особо приятно для производительности запроса. Или что-то все же можно придумать для быстрого поиска?
Сначала сгенерируем наши «тексты-на-дату»:
Попробуем накатить индекс и для FTS, и для сортировки по дате — вдруг да помогут:
Будем искать все документы, содержащие слова, начинающиеся на

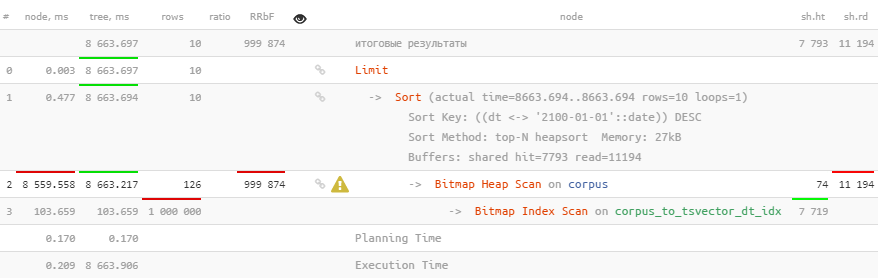
Ну… он, конечно, используется, но занимает это больше 8 секунд, что явно не то, что мы хотели бы потратить на поиск 126 записей.
Может, если добавить сортировку по дате и искать только последние 10 записей — станет лучше?

Но нет, просто сверху добавилась сортировка.
Но ведь есть же отличное расширение
Увы, это не помогает примерно никак.
Но отчаиваться рано! Посмотрим на список встроенных классов операторов GiST — оператор расстояния
Так давайте попробуем перевести нашу задачу «в плоскость» — нашим использующимся для поиска парам

Конечно, наш поиск будет не вполне полнотекстовым, в том смысле, что нельзя задавать условие для нескольких слов одновременно. Но уж префиксным-то точно будет!
Сформируем вспомогательную таблицу-словарь:
В нашем примере на 1M «текстов» пришлось 4.8M «слов».
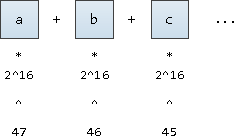
Чтобы перевести слово в его «координату», представим что это число, записанное в системе счисления с основанием
Можно было бы начинать и с 63-й позиции, это даст нам значения чуть меньше
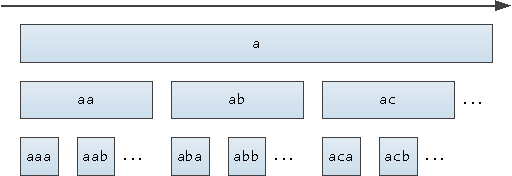
Получается, что на координатной оси все слова окажутся упорядочены:

Теперь у нас на руках
Оператор

Ну и выбрать мы все-таки хотели сами тексты-документы, а не их ключевые слова, поэтому нам понадобится давно забытый индекс:
Доработаем запрос:
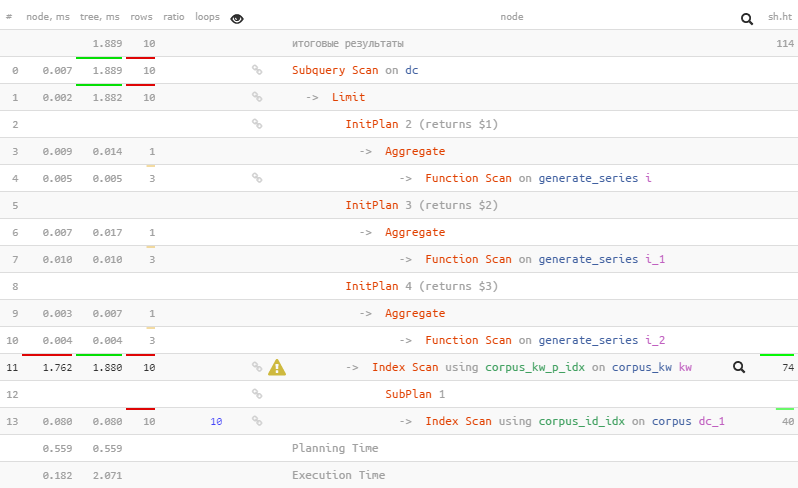
Нам немного добавили возникшие
Ничто не дается бесплатно:
242 MB «текстов» превратились в 1.1GB «поискового индекса».
Но ведь в
Мелочь — а приятно. Помогло не слишком сильно, но все-таки 10% объема удалось отыграть.
Но, поскольку люди — не компьютеры, то и ищут они примерно как "что-то там такое было от Иванова или от Ивановского… нет, не то, раньше, еще раньше… вот оно!"
Но разработчику это грозит жуткими проблемами — ведь для FTS-поиска в PostgreSQL используются «пространственные» типы индексов GIN и GiST, которые не предусматривают «подсовывания» дополнительных данных, кроме текстового вектора.
Остается только грустно вычитывать все записи по совпадению префикса (тысячи их!) и сортировать или, наоборот, идти по индексу даты и фильтровать все встречающиеся записи на совпадение префикса, пока не найдем подходящие (как скоро найдется «абракадабра»?..).
И то, и другое не особо приятно для производительности запроса. Или что-то все же можно придумать для быстрого поиска?
Сначала сгенерируем наши «тексты-на-дату»:
CREATE TABLE corpus AS SELECT id , dt , str FROM ( SELECT id::integer , now()::date - (random() * 1e3)::integer dt -- дата где-то за последние 3 года , (random() * 1e2 + 1)::integer len -- длина "текста" до 100 FROM generate_series(1, 1e6) id -- 1M записей ) X , LATERAL( SELECT string_agg( CASE WHEN random() < 1e-1 THEN ' ' -- 10% на пробел ELSE chr((random() * 25 + ascii('a'))::integer) END , '') str FROM generate_series(1, len) ) Y;
Наивный подход #1: gist + btree
Попробуем накатить индекс и для FTS, и для сортировки по дате — вдруг да помогут:
CREATE INDEX ON corpus(dt); CREATE INDEX ON corpus USING gist(to_tsvector('simple', str));
Будем искать все документы, содержащие слова, начинающиеся на
'abc...'. И, для начала, проверим, что таких документов достаточно немного, и FTS-индекс используется нормально:SELECT * FROM corpus WHERE to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*');
Ну… он, конечно, используется, но занимает это больше 8 секунд, что явно не то, что мы хотели бы потратить на поиск 126 записей.
Может, если добавить сортировку по дате и искать только последние 10 записей — станет лучше?
SELECT * FROM corpus WHERE to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*') ORDER BY dt DESC LIMIT 10;
Но нет, просто сверху добавилась сортировка.
Наивный подход #2: btree_gist
Но ведь есть же отличное расширение
btree_gist, которое позволяет «подсунуть» скалярное значение в GiST-индекс, что должно нам дать возможность сразу использовать индексную сортировку с помощью оператора расстояния <->, который можно использовать для kNN-поисков:CREATE EXTENSION btree_gist; CREATE INDEX ON corpus USING gist(to_tsvector('simple', str), dt);
SELECT * FROM corpus WHERE to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*') ORDER BY dt <-> '2100-01-01'::date DESC -- сортировка по "расстоянию" от даты далеко в будущем LIMIT 10;
Увы, это не помогает примерно никак.
Геометрия в помощь!
Но отчаиваться рано! Посмотрим на список встроенных классов операторов GiST — оператор расстояния
<-> доступен только для «геометрических» circle_ops, point_ops, poly_ops, а с версии PostgreSQL 13 — и для box_ops.Так давайте попробуем перевести нашу задачу «в плоскость» — нашим использующимся для поиска парам
(слово, дата) присвоим координаты некоторых точек, чтобы «префиксные» слова и недалеко отстоящие даты находились как можно ближе:Разбиваем текст на слова
Конечно, наш поиск будет не вполне полнотекстовым, в том смысле, что нельзя задавать условие для нескольких слов одновременно. Но уж префиксным-то точно будет!
Сформируем вспомогательную таблицу-словарь:
CREATE TABLE corpus_kw AS SELECT id , dt , kw FROM corpus , LATERAL ( SELECT kw FROM regexp_split_to_table(lower(str), E'[^\\-a-zа-я0-9]+', 'i') kw WHERE length(kw) > 1 ) T;
В нашем примере на 1M «текстов» пришлось 4.8M «слов».
Укладываем слова
Чтобы перевести слово в его «координату», представим что это число, записанное в системе счисления с основанием
2^16 (ведь UNICODE-символы мы тоже хотим поддержать). Только записывать мы его будем начиная с фиксированной 47-й позиции:Можно было бы начинать и с 63-й позиции, это даст нам значения чуть меньше
1E+308, предельных для double precision, но тогда возникнет переполнение при построении индекса.Получается, что на координатной оси все слова окажутся упорядочены:
ALTER TABLE corpus_kw ADD COLUMN p point; UPDATE corpus_kw SET p = point( ( SELECT sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1))) FROM generate_series(1, length(kw)) i ) , extract('epoch' from dt) ); CREATE INDEX ON corpus_kw USING gist(p);
Формируем поисковый запрос
WITH src AS ( SELECT point( ( -- копипасту можно вынести в функцию SELECT sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1))) FROM generate_series(1, length(kw)) i ) , extract('epoch' from dt) ) ps FROM (VALUES('abc', '2100-01-01'::date)) T(kw, dt) -- поисковый запрос ) SELECT * , src.ps <-> kw.p d FROM corpus_kw kw , src ORDER BY d LIMIT 10;
Теперь у нас на руках
id искомых документов, уже отсортированных в нужном порядке — и заняло это меньше 2ms, в 4000 раз быстрее!Небольшая ложка дегтя
Оператор
<-> ничего не знает про наше упорядочение по двум осям, поэтому искомые наши данные находятся лишь в одной из правых четвертей, в зависимости от необходимой сортировки по дате:Ну и выбрать мы все-таки хотели сами тексты-документы, а не их ключевые слова, поэтому нам понадобится давно забытый индекс:
CREATE UNIQUE INDEX ON corpus(id);
Доработаем запрос:
WITH src AS ( SELECT point( ( SELECT sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1))) FROM generate_series(1, length(kw)) i ) , extract('epoch' from dt) ) ps FROM (VALUES('abc', '2100-01-01'::date)) T(kw, dt) -- поисковый запрос ) , dc AS ( SELECT ( SELECT dc FROM corpus dc WHERE id = kw.id ) FROM corpus_kw kw , src WHERE p[0] >= ps[0] AND -- kw >= ... p[1] <= ps[1] -- dt DESC ORDER BY src.ps <-> kw.p LIMIT 10 ) SELECT (dc).* FROM dc;
Нам немного добавили возникшие
InitPlan с вычислением константных x/y, но все равно мы уложились в те же 2 мс!Ложка дегтя #2
Ничто не дается бесплатно:
SELECT relname, pg_size_pretty(pg_total_relation_size(oid)) FROM pg_class WHERE relname LIKE 'corpus%';
corpus | 242 MB -- исходный набор текстов corpus_id_idx | 21 MB -- это его PK corpus_to_tsvector_idx | 51 MB -- "традиционный" FTS-индекс corpus_kw | 705 MB -- ключевые слова с датами corpus_kw_p_idx | 403 MB -- GiST-индекс по геометрическим "проекциям"
242 MB «текстов» превратились в 1.1GB «поискового индекса».
Но ведь в
corpus_kw лежат дата и само слово, которые мы в самом-то поиске уже никак не использовали — так давайте их удалим:ALTER TABLE corpus_kw DROP COLUMN kw , DROP COLUMN dt; VACUUM FULL corpus_kw;
corpus_kw | 641 MB -- только id и point
Мелочь — а приятно. Помогло не слишком сильно, но все-таки 10% объема удалось отыграть.

