Мониторинг многопоточных приложений Node.JS
7 мин
В этой статье мы разберем особенности мониторинга многопоточного Node.JS приложения на примере нашего коллектора для сервиса мониторинга и анализа логов серверов PostgreSQL.


'Buffers: shared hit=123 read=456, local hit=789' мы хотим как можно быстрее получить JSON такого формата:{
"shared-hit" : 123
, "shared-read" : 456
, "local-hit" : 789
}
CREATE TABLE task AS
SELECT
id
, (random() * 100)::integer person -- всего 100 сотрудников
, least(trunc(-ln(random()) / ln(2)), 10)::integer priority -- каждый следующий приоритет в 2 раза менее вероятен
FROM
generate_series(1, 1e5) id; -- 100K задач
CREATE INDEX ON task(person, priority);
EXISTS — вот с самого простого варианта и начнем:SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
);


EXPLAIN, но с некоторыми странными узлами — вы знаете, куда идти.


EXPLAIN [ANALYZE].
JOIN и предложим альтернативный вариант решения на ней той же задачи.

«Отличие enterprise [решения] от всего остального — он всегда идёт от запросов бизнеса и решает какую-то бизнес-задачу.» [src]Вот и давайте посмотрим, какие именно прикладные задачи и как можно решить с помощью PostgreSQL и сократить время анализа данных с нескольких секунд на бизнес-логике до десятков миллисекунд, умея эффективно применять следующие алгоритмы непосредственно внутри SQL-запроса:
EXPLAIN (ANALYZE, BUFFERS) ... — любимый инструмент познания особенностей работы этой СУБД, то новые полезные «фишки» нашего сервиса визуализации и анализа планов explain.tensor.ru наверняка пригодятся вам в этом нелегком деле.


Программист ставит себе на тумбочку перед сном два стакана. Один с водой — на случай, если захочет ночью пить. А второй пустой — на случай, если не захочет.Давайте разбираться — когда сортировка в запросе точно не нужна и несет с собой потерю производительности, когда от нее можно относительно дешево избавиться, а когда сделать из нескольких — одну.


WITH RECURSIVE появилась еще в незапамятные времена версии 8.4, но до сих пор можно регулярно встретить потенциально-уязвимые «беззащитные» запросы. Как избавить себя от проблем подобного рода?WITH TIES из стандарта SQL:2008:OFFSET start { ROW | ROWS }
FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } { ONLY | WITH TIES }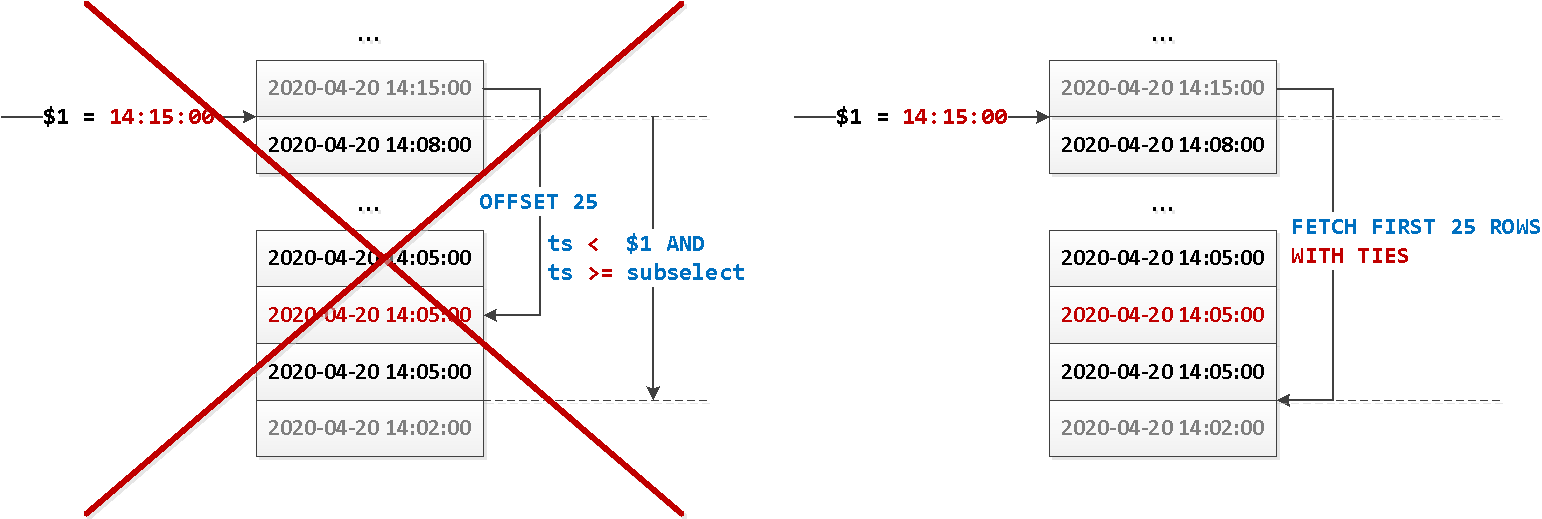


ORDER BY dt, id или ORDER BY dt DESC, id DESC.ORDER BY dt, id DESC? Но второй индекс мы создавать не хотим — ведь это замедление вставки и лишний объем в базе.(dt, id)?

С транскриптом первой части, посвященной типовым проблемам производительности запросов и их решениям, можно ознакомиться в статье «Рецепты для хворающих SQL-запросов».


Более полно о принципах работы сервиса можно посмотреть в видео доклада и прочитать в статье «Массовая оптимизация запросов PostgreSQL».