
Привет, Хабр! Меня зовут Евгений Некрасов, я программист-исследователь в Mail.Ru Group. Сегодня я расскажу о своем решении соревнования по анализу данных Dstl Satellite Imagery Feature Detection, которое было посвящено сегментации спутниковых изображений. В этом соревновании я использовал относительно простой поход к моделированию и занял 7 место из 419 команд. Под катом — рассказ, как мне это удалось.
Сразу дам некоторые вводные, в январе 2017 года я стал счастливым обладателем топового GPU NVIDIA GeForce GTX 1080, и это открыло для меня возможность опробовать свои теоретические знания в Deep Learning на реальных практических задачах. Мой выбор пал на соревнование от Dstl на платформе Kaggle. Эта задача привлекла меня, во-первых, необычностью данных — спутниковые изображения мультиспектральные, во-вторых, возможностью получить ценный практический опыт в такой важной области, как обработка спутниковых изображений. В этой статье рассказ будет в первую очередь о техниках анализа данных и машинном обучении. Тем не менее было бы неправильно полностью игнорировать технические подробности, поэтому кратко скажу, что весь код я писал на Python3 и использовал следующие библиотеки: numpy, scipy, pandas, skimage, tifffile, shapely, keras with TensorFlow backend.
Постановка задачи
Данные
Организаторы предоставили изображения 450 фрагментов поверхности земли 1x1 км. Эти фрагменты были из одного региона нашей планеты. Каждый фрагмент был отснят четырьмя сенсорами спутника WorldView3: RGB-сенсором, панхроматическим сенсором, мультиспектральным сенсором и инфракрасным сенсором SWIR. RGB- и панхроматический сенсоры соответственно выдают обычные цветные и черно-белые изображения. Что снимают мультиспектральный и SWIR сенсоры показано на рис. 1. Таким образом, для каждого фрагмента было дано 4 TIFF-файла, причем они различались как по пространственному разрешению, так и по динамическому диапазону, характеристики изображений приведены в таблице 1. Из этих 450 фрагментов 25 были в тренировочном наборе, к ним была предоставлена разметка (сегментация изображений, выполненная специалистами) по 10 классам объектов в векторном формате WKT или GeoJSON. Остальные 425 изображений составляли тестовый набор, для них нужно было построить аналогичную разметку по 10 классам в формате WKT.
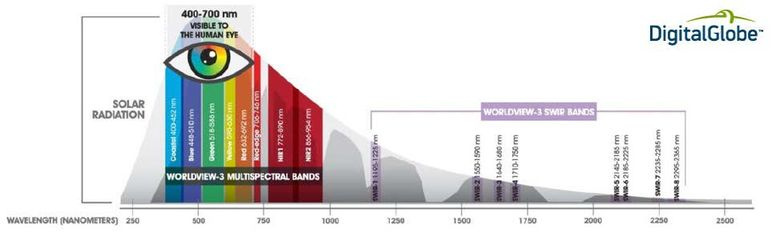
Рисунок 1. Спектральные диапазоны мультиспектрального сенсора и SWIR сенсора

Таблица 1. Характеристика данных с сенсоров спутника WorldView3
Теперь подробнее о 10 классах объектов, это были:
- Buildings (здания).
- Misc. Manmade structures (искусственные сооружения, в основном, заборы)
- Road (асфальтированные автомобильные дороги).
- Track (грунтовые дороги).
- Trees (деревья).
- Crops (сельскохозяйственные поля).
- Waterway (реки).
- Standing water (небольшие водоемы).
- Vehicle Large (грузовики).
- Vehicle Small (легковые автомобили).
Распределение площадей этих классов было очень неравномерным по тренировочной разметке (рис. 2). Для наглядности привожу пример RGB-изображения из тренировочного набора (рис. 3) и его разметку (рис. 4).
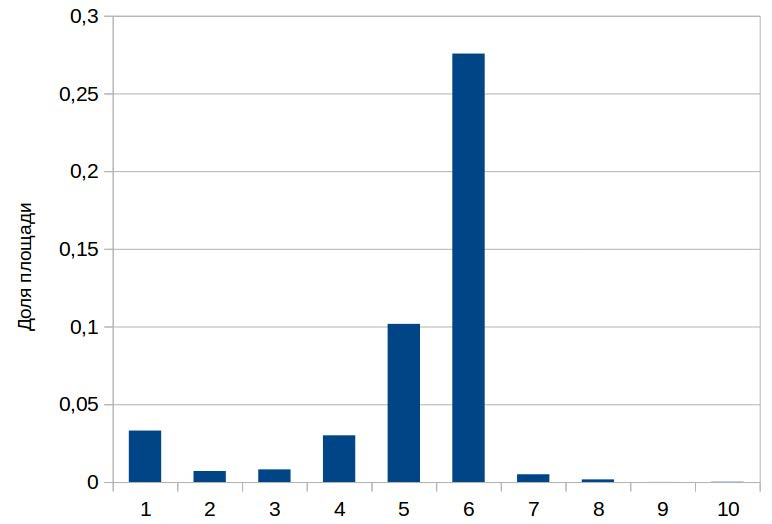
Рисунок 2. Гистограмма долей площадей классов объектов относительно общей площади фрагмента поверхности земли. 1 — Buildings, 2 — Misc. Manmade structures, 3 — Road, 4 — Track, 5 — Trees, 6 — Crops, 7 — Waterway, 8 — Standing water, 9 — Vehicle Large, 10 — Vehicle Small

Рисунок 3. Пример RGB-изображения из тренировочного набора
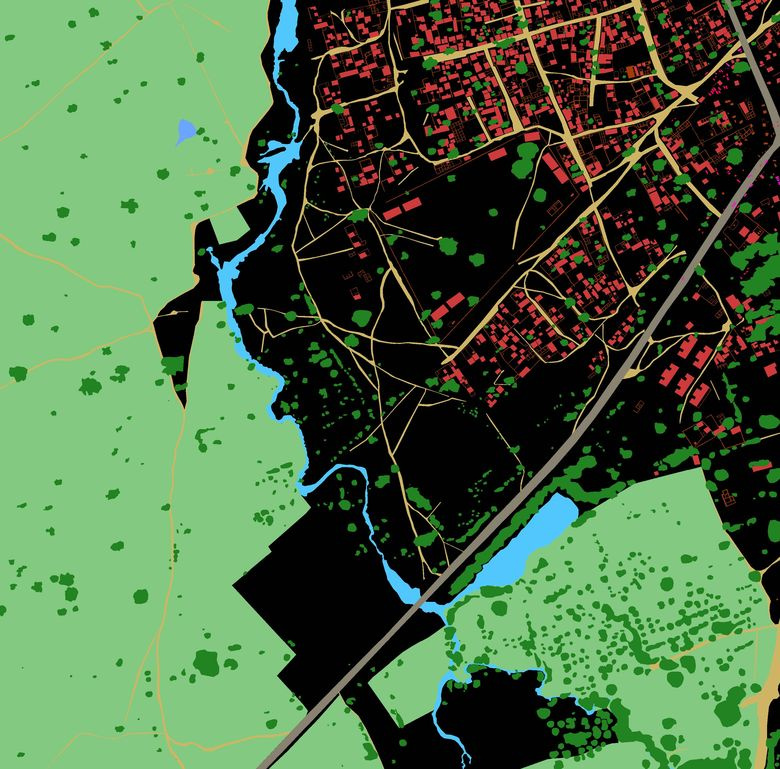
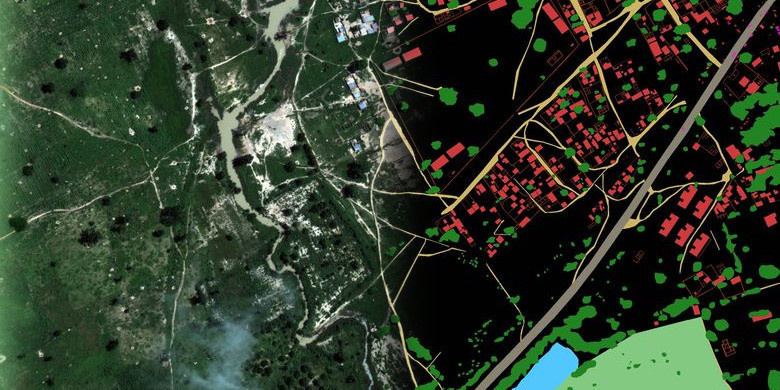
Рисунок 4. Пример разметки из тренировочного набора. Красный — Buildings, оранжевый — Misc. Manmade structures, серый — Road, желтый — Track, темно-зеленый — Trees, светло-зеленый — Crops, голубой — Waterway, синий — Standing water, фиолетовый — Vehicle Large, розовый — Vehicle Small
Метрикой качества в соревновании являлся Jaccard (рис. 5), усредненный по всем 10 классам. Организаторы оценивали качество решений и определяли победителей исключительно по этой метрике, причем для финальной оценки, которая стала известна только после завершения соревнования, организаторы использовали 81% тестовых изображений (Private leaderboard), оставшиеся 19% тестовых изображений составляли Public leaderboard и позволяли участникам мгновенно получать предварительную оценку качества своих решений.

Рисунок 5. Иллюстрация метрики Jaccard
Решение задачи
Препроцессинг
Сначала нужно привести данные к виду, пригодному для моделирования. Препроцессинг я делал так: все четыре спутниковых снимка масштабировал к размеру RGB-изображения (~3300x3300 пикселей), так как у него наиболее высокое пространственное разрешение. Далее каждое изображение нормировал на максимум динамического диапазона, чтобы значения яркости пикселей лежали строго в диапазоне [0, 1], и затем объединял в единое 20-канальное изображение. Векторную разметку я проецировал в растровые бинарные маски, которые по размеру соответствовали 20-канальному изображению. Преобразования векторной разметки в растровые маски и обратно я выполнял с помощью библиотек skimage и shapely.
Моделирование
После проведения препроцессинга мы получаем сформулированную задачу сегментации изображений: тренировочный набор состоит из 25 20-канальных изображений, к этим изображениям есть попиксельная разметка по 10 классам, тестовый набор состоит из 425 20-канальных изображений, для которых надо построить аналогичные бинарные маски, которые потом можно легко перевести в векторную разметку в формате WKT — это то, что хотят получить организаторы.
Для задачи сегментации изображений одна из лучших моделей — это сверточная нейронная сеть архитектуры U-net. U-net по структуре очень похожа на автоэнкодер, но с одним отличием: у нее есть соединение соответствующих по размеру частей энкодера и декодера. Автоэнкодерная часть формирует высокоуровневое представление об изображении, а соединения позволяют сети эффективно сегментировать мелкие детали.
Я использовал две U-net подобные искусственные нейронные сети практически идентичной архитектуры (рис. 6). Первая нейронная сеть (2с) была заточена под сегментацию двух крайне редких классов — Vehicle Large и Vehicle Small (рис. 2). Вторая нейронная сеть (7с) заточена под все остальные классы, причем Waterway и Standing water я объединил в один класс, и этому есть две причины: во-первых, по сути, Waterway и Standing water это один класс — вода, во-вторых, водоемов в тренировочном наборе крайне мало, поэтому выучить между ними разницу с нуля искусственной нейронной сети практически нереально, куда лучше разделать уже предсказанные водоемы на два класса.
Вход обоих нейронных сетей был 160 на 160 пикселей. Магическое число 160x160 я получил следующим образом: чем больше поле зрения искусственной нейронной сети, тем лучше нейронная сеть может понять контекст в котором находятся наблюдаемые объекты, однако с увеличением нейронной сети возрастает сложность модели и соответственно время на обучение и предсказание. Я посмотрел глазами спутниковые изображения через поля зрения различных размеров и понял, что поле зрения 160x160 достаточный минимум для понимания контекста в этой задаче.
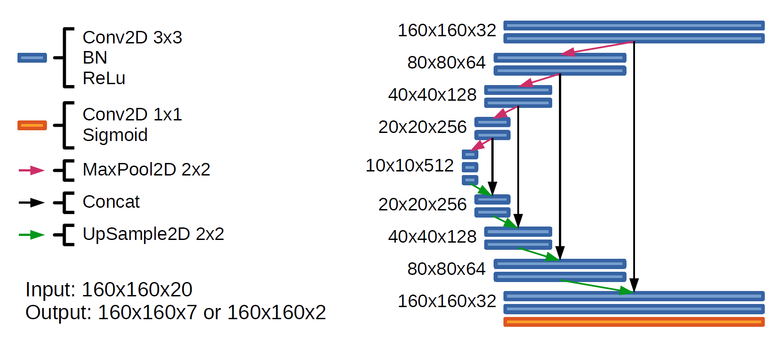
Рисунок 6. Архитектура нейронных сетей 2с и 7c. В последнем слое 7с имела на выходе 7 каналов, а 2с — 2 канала
Тренировка нейросетей
С тренировкой нейронных сетей в этой задаче не все так просто, ведь в тренировочном наборе всего 25 изображений — это всего порядка 10 тысяч не пересекающихся фрагментов изображения (кропов) 160x160 пикселей, что очень мало и не позволяет полностью реализовать потенциал сетей 2с и 7с. Поэтому я использовал техники, которые позволяют решить проблему малого количества тренировочных данных — это обучение с частичным привлечением учителя (semi-supervised learning) и расширение обучающего множества (data augmentation). Для обучения обоих сетей я использовал бинарную кросс-энтропию в качестве функции потерь, то есть обучал сети предсказывать вероятность наличия объектов в каждом пикселе, и оптимизировал веса нейронных сетей оптимизатором Adam. В процессе тренировки обоих нейронных сетей я использовал обучение на так называемых вращательных кропах — фрагментах изображения 160x160 пикселей, вырезанных из изображения со случайными смещениями и поворотами на случайный угол (рис. 7). Это позволяет расширить обучающее множество за счет нашего априорного знания о вращательной инвариантности спутниковых изображений, то есть если мы повернем спутниковое изображение на произвольный угол, то мы получим валидное спутниковое изображение.
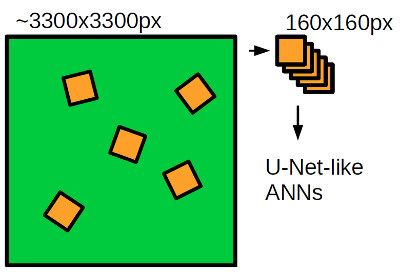
Рисунок 7. Схема сэмплирования вращательных кропов
Начну рассказ процедуры тренировки с сети 2с. Классы автомобилей и грузовиков очень редкие, поэтому сначала я обучал нейронную сеть на 200 тысячах вращательных кропов с таким сэмплированием, чтобы автомобиль или грузовик присутствовал в кропе с вероятностью примерно 50 %. Это нужно было для того, чтобы нейронная сеть получила представление о том, что представляет собой автомобиль или грузовик. Далее дообучал нейронную сеть на 700 тысячах вращательных кропов со случайным сэмплированием, чтобы сеть сформировала адекватное представление о всём датасете в целом.
Для сети 7с я использовал более сложный подход, применив обучение с частичным привлечением учителя. Дело в том, что хотя в нашем распоряжении только 25 размеченных спутниковых изображений, всего нам дано 450 спутниковых изображений, и весь этот набор можно использовать для того, чтобы нейронная сеть смогла выучить представление о том, что представляют собой спутниковые изображения в целом. Я построил автоэнкодер, который по структуре соответствует сети 7с и обучил его на 600 тысячах обычных кропов из всех 450 изображений. Затем я перенёс веса энкодерной части обученного автоэнкодера в нейронную сеть 7с и зафиксировал их. Обучил сеть на 400 тысячах вращательных кропов. Отпустил веса энкодерной части и дообучил нейронную сеть еще на 600 тысячах вращательных кропов.
Предсказание
Чтобы выполнить предсказание я проходил по изображению «скользящим окном», то есть вырезал из изображения фрагменты 160x160 пикселей, на них выполнял предсказания нейронными сетями 2с и 7с и собирал из этих фрагментов исходное изображение. Там, где это было возможно, я использовал для реконструкции только центральную часть предсказанного нейронной сетью кропа (рис. 8), так как на краях качество предсказания, скорее всего, ниже. Проход «скользящим окном» я выполнял с каждого угла изображения, затем усреднял предсказания и получал итоговые предсказания вероятностей каждого класса объектов в каждой точке изображения.
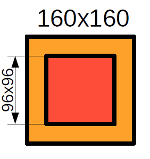
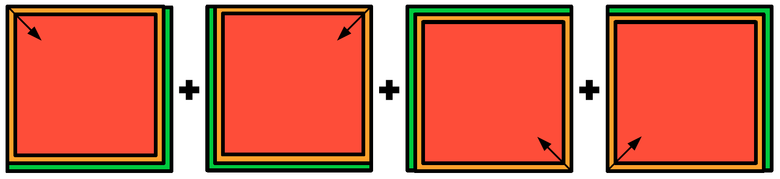
Рисунок 8. Схема получения предсказания. Красный — предсказания из центральной области кропа, желтый — предсказания из краевой области кропа, зеленый — предсказания нет
Однако нам нужны не вероятности, а бинарные маски. Самый простой способ их построения: провести дискретизацию по порогу 0.5. Но я использовал более продвинутый метод: выполнил предсказание на тренировочном наборе изображений, а затем максимизировал Jaccard на всем тренировочном наборе относительно порога дискретизации. В результате получились значения, которые часто значительно отличались от 0.5 (таблица 2). У читателя может возникнуть вопрос: а не будет ли здесь переобучения. Нейронные сети были обучены на вращательных кропах, а те, что подаются в нейронную сеть на этапе предсказания, могли попасть в обучающий набор с очень небольшой вероятностью, поэтому это более-менее адекватный подход.
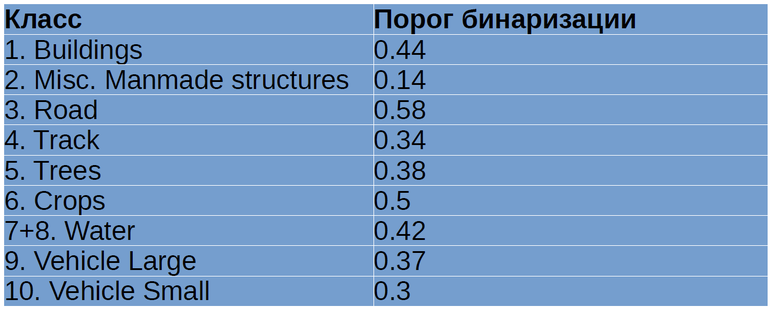
Таблица 2. Значения порогов дискретизации для различных классов объектов
В формировании предсказания водоемов я также воспользовался моделью предсказания воды Владимира Осина, которую он выложил в открытый доступ на форуме соревнования. Она очень простая, основана на Canopy Chlorophyl Content Index (CCCI). Индекс считается как комбинация интенсивности некоторых каналов и позволяет по порогу эффективно сегментировать воду. Я объединил свои предсказания водоемов с результатами работы модели Владимира Осина, так как это по сути очень разные модели, и в результате их объединение дало видимое повышение качества сегментации водоемов.
Далее нужно было разделить предсказанную воду на классы Waterway и Standing Water. Тут я использовал классические методы компьютерного зрения и априорные знания об отличиях рек и небольших прудов. Для каждой области воды считал параметры, которые должны быть эффективны в разделении этих типов водоемов:
- площадь (реки обычно больше прудов по площади);
- эллиптичность (реки вытянутые, пруды близки к окружности);
- касание границ фотографии (реки обычно длиннее 1 км, а следовательно пересекают границы фотографии, вероятность оказаться на границе фотографии для пруда невелика).
Далее из этих параметров делал линейную комбинацию и по порогу разделял классы воды.
Итак, теперь у нас есть бинарные маски для всех 10 классов, задача решена. Далее оставались только выполнить технические процедуры, нужно было векторизовать полученные бинарные маски и сохранить их в формате WKT. Привожу пример изображения из тестового набора (рис. 9) и его сегментацию моделью (рис. 10).

Рисунок 9. Пример RGB-изображения из тестового набора
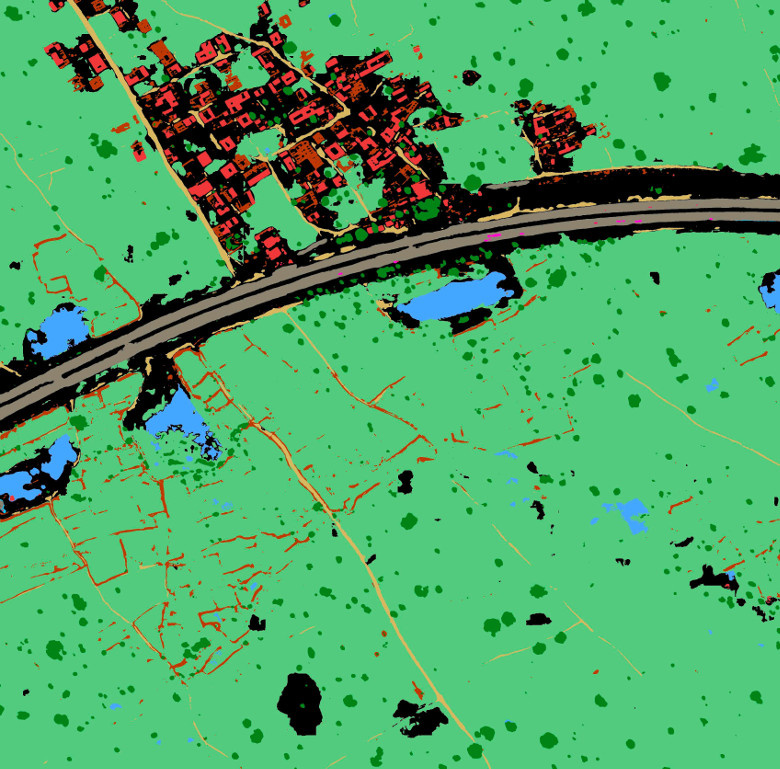
Рисунок 10. Пример предсказания модели на изображении из тестового набора. Красный — Buildings, оранжевый — Misc. Manmade structures, серый — Road, желтый — Track, темно-зеленый — Trees, светло-зеленый — Crops, голубой — Waterway, синий — Standing water, фиолетовый — Vehicle Large, розовый — Vehicle Small
Заключение
Описанное решение выдает Public Score 0.51725, Private Score 0.43897, и это 7 место по результатам соревнования. Вот ключевые элементы решения, которые позволили мне добиться таких высоких результатов:
- Архитектура U-Net, сейчас это state of art для сегментации изображений.
- Использование методик, которые позволили эффективно работать в условиях малого количества тренировочных данных. Это обучение на вращательных кропах и использование тестовых изображений в процессе обучения нейронных сетей.
- Применение классических методов компьютерного зрения и априорных знаний для разделения классов водоемов.
Это далеко не полный перечень идей и подходов, которые работали в этом соревновании, еще можно подчерпнуть много интересных идей из топовых опубликованных решений:
- решение команды Владимира Игловикова и Сергея Мушинского (3 место)
- решение команды Романа Соловьева и Артура Кузина (2 место)
- решение Kyle Lee (1 место)
Спасибо за внимание.
