
Привет, Хабр! Меня зовут Александр Сухочев, я занимаюсь машинным обучением и руковожу командой рекомендаций и развития сервисов ВКонтакте. Сегодня хочу поделиться нашим опытом и результатами внедрения контекстных многоруких бандитов для рекомендации контента на примере игр и стикеров.

Статья состоит из четырёх частей, переходите сразу ко второй или третьей, если знакомы с проблематикой, или читайте по порядку, чтобы составить полную картину:
Введение расскажет о том, какие бывают подходы к построению рекомендательных систем и при чём здесь многорукие бандиты — это раздел для тех, кто раньше не был знаком с данным подходом.
Основные алгоритмы решения задачи многорукого бандита: эпсилон-жадный подход, сэмплирование Томпсона, Upper Confidence Bound.
Алгоритм контекстных многоруких бандитов — о контекстных многоруких бандитах и способе их обучения в частном случае, который мы использовали в нашем решении.
Заметки о практической реализации — о тонкостях внедрения, бизнес-требованиях и результатах на примере сервиса рекомендации игр и стикеров.
Введение
Верхнеуровнево обычная рекомендательная система выглядит следующим образом:
у нас есть история взаимодействия пользователя
 и контента
и контента  ;
;исходя из задач бизнеса, некоторые из видов взаимодействия считаются положительными, а некоторые отрицательными. То есть каждой паре взаимодействия
 мы ставим в соответствие ответ
мы ставим в соответствие ответ  , а также опционально вес
, а также опционально вес  характеризующий значимость данного примера. Здесь стоит отметить, что парой взаимодействия могут стать пользователь и единица контента, которые на самом деле никак не связаны. Такая необходимость появляется, когда не хватает отрицательных сигналов;
характеризующий значимость данного примера. Здесь стоит отметить, что парой взаимодействия могут стать пользователь и единица контента, которые на самом деле никак не связаны. Такая необходимость появляется, когда не хватает отрицательных сигналов;каждой паре
 ставятся в соответствие признаки
ставятся в соответствие признаки  это могут быть как описания пользователя или контента, так и просто их id (например, в случае коллаборативной фильтрации);
это могут быть как описания пользователя или контента, так и просто их id (например, в случае коллаборативной фильтрации);наша задача — на основе
 и
и  научить модель понимать, у каких новых пар пользователей и единиц контента в будущем есть шанс положительно провзаимодействовать.
научить модель понимать, у каких новых пар пользователей и единиц контента в будущем есть шанс положительно провзаимодействовать.
Что не так с «классическими» ML-рекомендациями?
Рекомендации, основанные только на опыте предыдущего взаимодействия пользователей с контентом и не байесовском частотном подходе к обучению (например, различные алгоритмы, основанные на матричных факторизациях, бустингах и т. д.), могут быть качественными, но есть недостатки, с которыми в рамках данных подходов сложно бороться:
Алгоритмы учатся на истории, на формирование которой сами же и повлияли. Однако этот факт нигде не учитывается и может приводить к нежелательным смещениям в обучении.
Усложняется поиск ниши для потенциально качественного, но самобытного контента.
В рекомендациях в основном показывается контент на темы, которые когда-то интересовали пользователя, а новые темы платформа не предлагает.
Непонятно, что делать с перманентным появлением на платформе нового контента, который потенциально может быть качественным и достойным большой аудитории. Крайним случаем является запуск новой платформы рекомендаций или появление на сайте нового типа контента. Тогда в нашем распоряжении вообще нет никакой истории взаимодействия, на которой можно учиться.
Все они требуют решения, но последние три могут особенно повлиять на отношение пользователей к сервису. Мы точно не хотим тратить время и нервы пользователей на новый и не обязательно качественный и (или) подходящий им контент.
В литературе такая проблема называется exploitation-exploration trade-off:
с одной стороны, мы хотим получить пользу от рекомендательной системы, применяя уже имеющиеся знания — это exploitation;
с другой стороны, действуя таким «жадным» образом, мы будем медленно получать новые знания, которые потенциально могли бы помочь нам извлекать ещё больше пользы в будущем. Поэтому хотелось бы иногда рисковать и пробовать новые паттерны поведения, предлагать новый контент или рекомендовать контент нестандартной для него группе пользователей — это exploration.
Что за бандиты такие, многорукие?
В машинном обучении задача о многоруком бандите — это задача о грамотном комбинировании exploration и exploitation. Своё название она получила из-за сходства с игрой в казино:
игрок приходит в казино со слот-машинами (также известными как однорукие бандиты) и, естественно, хочет выиграть как можно больше;
слот-машина с некоторой вероятностью выдаёт фиксированный выигрыш на каждую попытку игрока дёрнуть за ручку автомата, но у каждого однорукого бандита своя вероятность выигрыша;
достоверно известно, что есть однорукий бандит с вероятностью получения выигрыша, ради которой есть смысл его искать;
таким образом, цель игрока — как можно быстрее найти наиболее выгодного однорукого бандита и играть в него.
")
Так как одноруких бандитов много, то обычно говорят, что мы имеем дело с одним многоруким бандитом, каждой ручкой которого является ручка однорукого бандита.
В прикладных задачах каждая ручка многорукого бандита представляет собой не выбор очередной слот-машины, а выбор действия из какого-то дискретного множества действий, которое должно максимизировать бизнес-метрику. Действия и метрики разнятся в зависимости от области и задачи. Например, в рекомендациях действием может быть как показ пользователю какой-то конкретной единицы контента, так и выбор верхнеуровневого принципа, по которому мы в данный момент будем генерировать рекомендации для пользователя.
Задача состоит в том, чтобы как можно быстрее идентифицировать эффективную стратегию и затем придерживаться её.
Основные алгоритмы решения задачи о многоруком бандите
Чтобы разобрать алгоритмы, сначала формализуем задачу. Существуют разные модели, но в общем случае задачу о многоруких бандитах можно изобразить в виде схемы:
")
Есть агент (online decision algorithm), среда (system) и потенциально бесконечная последовательность итераций взаимодействия агента и среды, пронумерованная индексом t. На каждом t-ом шаге агент принимает решение совершить действие  , среда в ответ на это действие выдаёт ответ
, среда в ответ на это действие выдаёт ответ  , который напрямую или опосредованно через функцию
, который напрямую или опосредованно через функцию  характеризует выигрыш агента.
характеризует выигрыш агента.
В общем случае сигнал  носит стохастический (недетерминированный) характер. Можно говорить, что действие агента
носит стохастический (недетерминированный) характер. Можно говорить, что действие агента  на t-ом шаге задаёт вероятностное распределение на ответ
на t-ом шаге задаёт вероятностное распределение на ответ  , из которого конкретная реализация ответа
, из которого конкретная реализация ответа  получается случайным сэмплированием (то есть берутся частные реализации случайной величины). Далее на основе вновь совершённого действия
получается случайным сэмплированием (то есть берутся частные реализации случайной величины). Далее на основе вновь совершённого действия  и полученного сигнала
и полученного сигнала  мы обновляем приближения
мы обновляем приближения  параметров
параметров  модели зависимости ответов среды от совершённых действий (блок supervised learning на диаграмме). В дальнейшем ради краткости будем этот элемент называть моделью среды. Далее на основе очередных приближений алгоритм принятия решения о совершении тех или иных действий (optimizer) выдаёт следующий шаг
модели зависимости ответов среды от совершённых действий (блок supervised learning на диаграмме). В дальнейшем ради краткости будем этот элемент называть моделью среды. Далее на основе очередных приближений алгоритм принятия решения о совершении тех или иных действий (optimizer) выдаёт следующий шаг  , который нужно совершить. Так выглядит каждая итерация взаимодействия агента со средой.
, который нужно совершить. Так выглядит каждая итерация взаимодействия агента со средой.
Задача о казино является, пожалуй, одним из простейших примеров задачи о многоруком бандите, а именно — задачей о бернуллиевском многоруком бандите. В этой задаче модель зависимости ответов среды от совершённых действий представляет собой набор из K распределений Бернулли: по одному распределению на ручку  . Каждое k-ое распределение Бернулли представляет собой распределение случайной величины, которая может принимать значение, равное единице (выигрыш) с вероятностью
. Каждое k-ое распределение Бернулли представляет собой распределение случайной величины, которая может принимать значение, равное единице (выигрыш) с вероятностью  и нулю (проигрыш) с вероятностью
и нулю (проигрыш) с вероятностью  . Набор таких
. Набор таких  и является параметрами данной модели.
и является параметрами данной модели.
Несмотря на простоту, с помощью такой модели можно решать прикладные задачи, и на её примере мы разберём основные подходы к решению задачи о многоруком бандите. Далее обозначим её недостатки и возможные усложнения, которые позволяют от них избавиться.
Эпсилон-жадный подход
Самым простым подходом является эпсилон-жадный алгоритм. В общем виде он работает следующим образом:
мы с вероятностью
 выбираем ручку бандита, у которой на основе уже полученных данных наибольший средний выигрыш, а с вероятностью
выбираем ручку бандита, у которой на основе уже полученных данных наибольший средний выигрыш, а с вероятностью  — случайную ручку;
— случайную ручку;обновляем математические ожидания выигрыша у всех ручек;
повторяем с первого пункта.
К задаче бернуллиевских бандитов этот подход применяется тривиальным образом:
для каждой ручки считаем отношение количества выигрышей к количеству попыток;
с вероятностью
 пробуем ручку с максимальным отношением — это exploitation, а с вероятностью
пробуем ручку с максимальным отношением — это exploitation, а с вероятностью  пробуем случайную ручку — и реализуем exploration;
пробуем случайную ручку — и реализуем exploration;получая новые данные, обновляем отношения.
Недостаток этого подхода состоит в нерациональном exploration. По мере поступления данных нам становится понятно, что какие-то ручки более перспективны для исследования, чем другие. Однако они всё равно получают одинаковые шансы быть рекомендованными пользователю на очередной итерации exploration.
Для наглядности давайте представим, что хотим рекомендовать фотографии кошек.

По прошествии какого-то времени мы собрали следующие данные: первая набрала 2 000 лайков и 100 000 просмотров, вторая ни одного лайка и всего 10 просмотров, третья — 1 лайк и 10 000 просмотров. Лайки мы здесь считаем за те самые выигрыши, а просмотры за попытки.
На стадии exploitation будет выбран первый кот — как наиболее перспективный на основе текущей информации.
Теперь поговорим про exploration. Вторая фотография набрала меньше лайков как в абсолютных величинах, так и в отношении к количеству просмотров, чем третья. Однако на основе количества этих самых просмотров мы можем выдвинуть предположение, что исследование востребованности второй фотографии более перспективно, а невостребованность третьей для рекомендаций уже весьма вероятна. При эпсилон-жадном подходе обе картинки будут получать одинаковые шансы быть рекомендованными пользователю на этапе exploration.
Конечно, с такой неоптимальностью можно попробовать побороться различными эвристиками, вроде условий на количество просмотров и отношение количества выигрышей к количеству попыток. Но это ненадёжно.
Байесовский теоретический минимум
Для дальнейшего рассмотрения принципов работы многоруких бандитов нам нужен способ обучения моделей, который позволит:
В потоковом режиме (то есть без сохранения обучающей выборки в памяти и постоянного её переиспользования) комбинировать новые данные с уже имеющимися у нас представлениями о среде, получая новую, более точную модель среды.
Получать не просто точечные оценки параметров модели, но и их вероятностное распределение, которое ещё и помогает понять, насколько мы уверены в текущих оценках.
Этим требованиям удовлетворяет байесовский подход. Весь его смысл можно выразить одной небольшой формулой — собственно формулой Байеса:

Чтобы разговор был более предметным, сразу вместо абстрактных A и B подставим актуальные для машинного обучения с учителем понятия A = Y|X (ответы модели при условии факторов) и  (параметры модели машинного обучения). Получим:
(параметры модели машинного обучения). Получим:

где  — текущие представления о модели, выраженные в виде плотности распределения параметров этой модели и построенные на основе предыдущих данных и базовых априорных представлений (либо только априорных представлений, если данных ещё не было). Этот множитель в литературе называется априорным распределением.
— текущие представления о модели, выраженные в виде плотности распределения параметров этой модели и построенные на основе предыдущих данных и базовых априорных представлений (либо только априорных представлений, если данных ещё не было). Этот множитель в литературе называется априорным распределением.
 несёт в себе информацию о вновь полученных данных в виде их функции правдоподобия. Этот множитель так и называется в литературе — правдоподобие.
несёт в себе информацию о вновь полученных данных в виде их функции правдоподобия. Этот множитель так и называется в литературе — правдоподобие.
 — наши обновлённые представления о модели, полученные на основе старой модели и новых данных. В литературе этот множитель называется апостериорным распределением.
— наши обновлённые представления о модели, полученные на основе старой модели и новых данных. В литературе этот множитель называется апостериорным распределением.
Сомножитель  нужен для нормализации.
нужен для нормализации.
Если его убрать, то  нельзя рассматривать как плотность распределения параметров, так как интеграл по ней не будет суммироваться в единицу.
нельзя рассматривать как плотность распределения параметров, так как интеграл по ней не будет суммироваться в единицу.
Иногда нормализующий множитель удаётся вычислить аналитически, в этом случае будем говорить, что проводим байесовский вывод. Однако, за исключением простейших случаев, вычислить его аналитически крайне сложно или попросту невозможно. Численное же вычисление может быть весьма трудоёмким и тогда пытаются приблизить апостериорное распределение  каким-нибудь распределением
каким-нибудь распределением  , с которым удобнее работать: оценивать плотность, брать сэмплы, избегая затруднительных подсчётов нормализующих констант. Этот подход называется приближённым вариационным выводом.
, с которым удобнее работать: оценивать плотность, брать сэмплы, избегая затруднительных подсчётов нормализующих констант. Этот подход называется приближённым вариационным выводом.
На практике используются оба эти способа, их применение мы и рассмотрим в дальнейшем в этой статье. Также возможно использовать Марковские цепи и метод Монте-Карло, но в многоруких бандитах их используют очень редко, поэтому на них останавливаться не будем.
Рассмотрим, как выводится апостериорное распределение в задаче бернуллиевских бандитов посредством аналитического подсчёта нормализующей константы, то есть проведем байесовский вывод. Здесь у нас нет никаких факторов, описывающих контекст, поэтому вместо Y|X рассмотрим просто Y.
Напомню, что параметр  — это совокупность параметров
— это совокупность параметров  , каждый из которых в данном случае обозначает вероятность получить награду при использовании k-ой ручки и таким образом задаёт следующую плотность распределения данных:
, каждый из которых в данном случае обозначает вероятность получить награду при использовании k-ой ручки и таким образом задаёт следующую плотность распределения данных:
![p(Y_k| \theta_k) = \prod_i p(y_{ki}|\theta_k) = \prod_i \big( \theta_k^{[y_{ki} = 1]} \cdot (1 - \theta_k)^{[y_{ki} = 0]} \big) \\= \theta_k ^ {\sum_i [y_{ki} = 1]} \cdot (1 - \theta_k) ^ {\sum_i [y_{ki} = 0]}.](https://habrastorage.org/getpro/habr/upload_files/f07/8ae/741/f078ae7410057233b4d1ca1e9609b992.svg)
Здесь  — ответы только на попытках использовать k-ую ручку;
— ответы только на попытках использовать k-ую ручку;  — ответ на i-ой итерации использования k-ой ручки;
— ответ на i-ой итерации использования k-ой ручки; ![[x]](https://habrastorage.org/getpro/habr/upload_files/855/80c/0d1/85580c0d1bf68e934874b0fa8f4172a2.svg) — это функция, принимающая значение 1, когда
— это функция, принимающая значение 1, когда  истинно, и 0, когда ложно.
истинно, и 0, когда ложно.
За априорное распределение уже самих параметров  возьмём бета-распределение:
возьмём бета-распределение:

Здесь  и
и  — параметры k-ого бета-распределения (то есть параметры распределения параметра
— параметры k-ого бета-распределения (то есть параметры распределения параметра  ).
).  — бета-функция, конкретный вид которой в данном случае не важен.
— бета-функция, конкретный вид которой в данном случае не важен.
Среди всех семейств распределений мы выбрали именно семейство бета-распределений, потому что:
оно задаёт распределение величины на отрезке от 0 до 1 (а
 как раз может принимать только значения из данного отрезка);
как раз может принимать только значения из данного отрезка);если использовать такое априорное распределение, то апостериорное распределение вычисляется аналитически (покажу далее).

Обновление апостериорного распределения при поступлении новых данных проводится очень просто, на самом деле апостериорное распределение, как и априорное, здесь является бета-распределением и имеет параметры
![\alpha^{new}_k=\sum_i [y_{ki} = 1] + \alpha_k\ \text{и}\ \beta^{new}_k= \sum_i [y_{ki} = 0] + \beta_k.](https://habrastorage.org/getpro/habr/upload_files/f92/fa4/986/f92fa49860aab9c55e13e4948befec2a.svg)
То есть апостериорное распределение вычисляется аналитически и поэтому крайне быстро.
Краткое доказательство этого факта.
![p(\theta|Y_k) = \frac {\color{green}{p(Y_k|\theta_k)} \color{blue}{p(\theta_k)}} {\int p(Y_k|\theta_k) p(\theta_k) d \theta_k} = \color{green}{\theta_k ^ {\sum_i [y_{ki} = 1]} \cdot (1 - \theta_k) ^ {\sum_i [y_{ki} = 0]}} \color{blue}{\frac{\theta_k ^ {\alpha_k - 1} \cdot (1 - \theta_k) ^ {\beta_k - 1}}{B(\alpha_k, \beta_k)}}\color{black}{C}](https://habrastorage.org/getpro/habr/upload_files/6d3/3b6/987/6d33b6987eb0e40eab938bb44478a6a2.svg)
Здесь  , но его можно не считать, потому что наше апостериорное распределение будет иметь вид
, но его можно не считать, потому что наше апостериорное распределение будет иметь вид
![p(\theta_k|Y_k) = \frac{\theta_k ^ {\sum_i [y_{ki} = 1] + \alpha_k - 1} \cdot (1 - \theta_k) ^ {\sum_i [y_{ki} = 0] + \beta_k - 1}}{C'},](https://habrastorage.org/getpro/habr/upload_files/3f3/5e9/151/3f35e91511224d11448fbefa31b8100f.svg)
то есть с точностью до константы апостериорное распределение напоминает бета-распределение. Только теперь вместо  стоит
стоит ![\Sigma_i [y_{ki} = 1] + \alpha_k](https://habrastorage.org/getpro/habr/upload_files/4f6/8d4/3a9/4f68d43a949e9bc245f456ac50c9f01c.svg) , а вместо
, а вместо  стоит
стоит ![\Sigma_i [y_{ki}=0] + \beta_k](https://habrastorage.org/getpro/habr/upload_files/bb0/07b/52c/bb007b52c02b0eddebbe5196c257dfb3.svg) .
.
Таким образом мы легко можем восстановить нормализующую константу
![C'=B(\Sigma_i [y_{ki} = 1] + \alpha_k,](https://habrastorage.org/getpro/habr/upload_files/b3b/910/1b9/b3b9101b9607d374a06224e2e134a20a.svg)
![\Sigma_i [y_{ki} = 0] + \beta_k)](https://habrastorage.org/getpro/habr/upload_files/02a/3ea/4a0/02a3ea4a02b89a828da0a62bea537121.svg) — просто возьмём из определения бета-распределения с обновлёнными параметрами.
— просто возьмём из определения бета-распределения с обновлёнными параметрами.
Замечание. В случае, если априорное и апостериорное распределения принадлежат одному семейству, как здесь, говорят, что априорное распределение сопряжено распределению правдоподобия. С такими парами сопряжённых распределений, как было показано выше, легко работать, но часто бывает сложно подобрать априорное распределение, которое было бы сопряжено правдоподобию.
Сэмплирование Томпсона
В общем виде сэмплирование Томпсона работает следующим образом:
из текущего апостериорного распределения параметров среды
 сэмплируем их значения;
сэмплируем их значения;считая результаты сэмплирования за истинные значения параметров среды, выбираем действие, при котором математическое ожидание выигрыша наибольшее;
получив новые данные, пересчитываем обновлённое апостериорное распределение параметров
 , считая предыдущее апостериорное распределение за априорное;
, считая предыдущее апостериорное распределение за априорное;повторяем всё с первого пункта.
Применительно к задаче бернуллиевских бандитов этот алгоритм выглядит следующим образом. Среда описывается набором параметров  (по одному на каждую k-ую ручку), каждый такой параметр имеет априорное бета-распределение. На каждой итерации мы:
(по одному на каждую k-ую ручку), каждый такой параметр имеет априорное бета-распределение. На каждой итерации мы:
из каждого бета-распределения параметров
 наших ручек сэмплируем их значение
наших ручек сэмплируем их значение  ;
;просэмплированные значения
 считаем за вероятность той или иной ручки принести выигрыш, таким образом, оптимальным действием является
считаем за вероятность той или иной ручки принести выигрыш, таким образом, оптимальным действием является  ;
;получив новую информацию от среды в ответ на наши действия, пересчитываем значения бета-распределения параметров по схеме, описанной выше;
повторяем всё с первого пункта.
Сэмплирование Томпсона реализует гораздо более грамотную стратегию exploration-exploitation trade-off. Интуитивно её можно понять так: когда мы сэмплируем  из распределений
из распределений  , то наибольшие значения получаются либо из распределений с большим математическим ожиданием (в этом случае мы ближе к exploitation), либо из распределений с большой дисперсией (в этом случае мы ближе к exploration).
, то наибольшие значения получаются либо из распределений с большим математическим ожиданием (в этом случае мы ближе к exploitation), либо из распределений с большой дисперсией (в этом случае мы ближе к exploration).
Если объяснять на котах, то в ситуации, описанной выше, при подобном подходе скорее всего будут выбраны:
либо первая картинка, у которой
 (считаем, что априорное значение
(считаем, что априорное значение  ),
),  (считаем, что априорное значение
(считаем, что априорное значение  ), а следовательно, математическое ожидание равно
), а следовательно, математическое ожидание равно
(по формуле мат. ожидания бета-распределения). Такое математическое ожидание располагает наше бета-распределение фотографии первого кота правее всех остальных бета-распределений.
либо вторая фотография, у которой
 , а следовательно, дисперсия будет равна
, а следовательно, дисперсия будет равна
При такой относительно большой дисперсии вероятность появления больших значений
 велика.
велика.
Третья же картинка будет иметь весьма небольшие шансы быть выбранной, так как у неё и небольшое математическое ожидание 
и небольшая дисперсия 
В статьях же алгоритмы принятия решений, частным случаем которых является задача о многоруком бандите, обычно оцениваются с помощью

где T — число итераций принятия решений, t — номер итерации,  — математическое ожидание случайной величины
— математическое ожидание случайной величины  при условии совершения оптимального действия
при условии совершения оптимального действия  ,
,  — математическое ожидание случайной величины
— математическое ожидание случайной величины  при условии совершённого нашим алгоритмом действия
при условии совершённого нашим алгоритмом действия  .
.
Например, в этой работе эмпирически на множестве примеров проведено сравнение сэмплирования Томпсона с эпсилон-жадным алгоритмом с использованием  .
.
Upper Confidence Bound
Ещё одним популярным алгоритмом решения задачи о многоруком бандите является алгоритм Upper Confidence Bound (UCB). Кратко его смысл состоит в том, чтобы на каждом этапе выбирать ручку с наибольшей взвешенной суммой математического ожидания выигрыша и слагаемого, отвечающего за неуверенность прогноза.

Такой принцип выбора действий на каждом шаге интуитивно похож на принцип в сэмплировании Томпсона. Для UCB-алгоритма есть теоретические оценки производительности (regret), но более подробно мы его разбирать не будем, так как на практике в условиях побатчевого обновления параметров среды и генерации контента алгоритм сэмплирования Томпсона позволил нам проводить больший exploration.
Алгоритм контекстных многоруких бандитов
На практике редко одно действие лучше другого при любом раскладе, обычно очень многое зависит от контекста. В рекомендательных системах таким контекстом, который необходимо учитывать, обычно являются признаки пользователя.
Наивный подход
Самый простой способ учесть контекст — разделить признаковое пространство пользователя на отдельные ячейки разбиением по значениям признаков и считать «бандитские» статистики в каждой такой ячейке.
Ниже на иллюстрации пространство пользователя нарезано на ячейки, в которые помещаются те случаи взаимодействия пользователя с контентом, когда пользователь имел признаковое описание, соответствующее данной ячейке.

Кружки обозначают взаимодействия пользователя с контентом в истории. Для простоты берём пока только два фактора: пол и возраст.
Далее в каждой ячейке независимо от других на основе данных пересчитывается свой набор из k бета-распределений параметров  . Можно сказать и наоборот: для каждой ручки мы считаем M бета-распределений, где M — количество ячеек.
. Можно сказать и наоборот: для каждой ручки мы считаем M бета-распределений, где M — количество ячеек.


Таким образом, вместо K распределений в случае, когда мы не учитываем контекст, нам приходится рассматривать и пересчитывать K*M распределений.
Этот подход имеет несколько недостатков:
непонятно, как корректно разбивать пространство по признакам
(в примере выше разбиение по возрасту можно сделать экспертно или на основе принятой классификации, но если добавить, например, тематические описания пользователя, то задача станет сложнее);когда мы увеличиваем количество учитываемых признаков, мы бьём пространство на большее количество ячеек и в каждой ячейке остаётся меньше прецедентов для обучения.
Логистическая регрессия + вариационный вывод
Пришло время глобально поменять модель среды. Если раньше вероятность бинарного выигрыша при использовании k-ой ручки зависела от одного параметра  , то сейчас мы вводим для каждой ручки вектор параметров
, то сейчас мы вводим для каждой ручки вектор параметров  . Пусть контекст характеризуется вектором признаков
. Пусть контекст характеризуется вектором признаков  , тогда вероятность выиграть при использовании k-ой ручки будет равна
, тогда вероятность выиграть при использовании k-ой ручки будет равна

где сигмоида гарантирует, что значение, которое мы получаем от модели будет между 0 и 1.
Правдоподобие для каждой k-ой ручки будет считаться также отдельно и будет выглядеть как:

Здесь  — ответы только на попытках использовать k-ую ручку,
— ответы только на попытках использовать k-ую ручку,  — ответ на i-ой итерации использования k-ой ручки,
— ответ на i-ой итерации использования k-ой ручки,  — контекст на i-ой итерации использования k-ой ручки.
— контекст на i-ой итерации использования k-ой ручки.
В данном случае уже сложно подобрать априорное распределение, которое бы сопрягалось с распределением правдоподобия и позволяло аналитически вычислять апостериорное распределение.
Поэтому в качестве априорного распределения возьмём просто самое популярное — многомерное нормальное распределение:

а апостериорное распределение получим с помощью приближённого вариационного вывода, а именно аппроксимации Лапласа.
Этот подход состоит в том, что если мы имеем дело с унимодальным дважды дифференцируемым распределением, в котором весомая часть вероятностной массы сосредоточена вокруг моды, то может быть разумно такое распределение приблизить нормальным распределением.

Математическим ожиданием этого приближения будет мода апостериорного распределения, которую можно легко найти любым алгоритмом оптимизации:  , где
, где 
Ковариационная матрица приближённого апостериорного распределения находится по формуле:

Вывод формул под спойлером.
Hidden text
Нам нужно найти 
Рассмотрим отдельно числитель  то есть
то есть
 и его логарифм
и его логарифм

После того как найдём  , можно будет представить
, можно будет представить  в окрестности этой точки с помощью формулы Тейлора до второго порядка.
в окрестности этой точки с помощью формулы Тейлора до второго порядка.

т. к.  — экстремум
— экстремум  .
.
Таким образом, мы получаем:

Возьмём экспоненту от обеих частей, получим:

Это ненормализованный вид аппроксимации апостериорного распределения. Здесь первый сомножитель  — всего лишь константа относительно
— всего лишь константа относительно  , сейчас он нам не так интересен. Второй сомножитель
, сейчас он нам не так интересен. Второй сомножитель

можно привести к виду сомножителя-экспоненты

из формулы плотности многомерного нормального распределения:

для этого нужно провести замену  ,
, 
Пользуясь этой аналогией и зная нормализующую константу для сомножителя-экспоненты из формулы плотности нормального распределения

можно найти нормализующую константу и для  :
:

В итоге получаем, что:

где  , а
, а 
Получили формулу пересчёта апостериорного распределения.
Заметки о практической реализации и наши результаты
Мы применили метод многоруких контекстных бандитов с лапласовской аппроксимацией и сэмплированием Томпсона для продвижения игр и стикеров на второй вкладке.

В обеих задачах ручками многоруких бандитов были рекомендуемые объекты.
Контекст принятия решений
Контекстом были признаки пользователя: пол, возраст и признаки интересов.
Остановимся подробнее на интересах. Они, с одной стороны, крайне важны, так как наиболее явно характеризуют пользователя, с другой — есть определённые ограничения на их применение.
Во-первых, признаки должны быть довольно небольшими по размеру, потому что в формуле пересчёта  нужно инвертировать матрицу с длиной стороны, равной количеству признаков. Во-вторых, темы в этих признаках должны быть закодированы в явном виде, без всяких запутанностей, которые свойственны эмбеддингам, потому что далее они подаются на вход не нейронной сети, а обычной логистической регрессии.
нужно инвертировать матрицу с длиной стороны, равной количеству признаков. Во-вторых, темы в этих признаках должны быть закодированы в явном виде, без всяких запутанностей, которые свойственны эмбеддингам, потому что далее они подаются на вход не нейронной сети, а обычной логистической регрессии.
Как вариант, можно проводить тематическое моделирование пользователя, в котором пользователь является документом, а группы, на которые он подписан, словами. Но мы избрали другой подход.
Дело в том, что у нас в распоряжении были качественные эмбеддинги сообществ, полученные в ходе решения задачи их рекомендаций и хорошо описывающие их тематику. Мы кластеризовали сообщества в этом пространстве эмбеддингов с помощью адаптивного EM-алгоритма с ограничением на количество кластеров. Получились достаточно хорошо интерпретируемые кластеры. Например, ниже представлены примеры из кластера про IT и популярную науку.
Далее мы разложили пользователя по принадлежности к кластерам групп и это разложение использовали как признаки интересов пользователя.
Что считать положительными и отрицательными взаимодействиями?
Рекомендации стикеров и игр в мобильных приложениях показываются пользователю в виде горизонтального скролл-виджета на вкладке «Сервисы».

Если дело касается стикеров, то кандидаты на положительный сигнал — это просмотр всех стикеров в наборе и покупка набора.
Для игр положительным сигналом можно считать тап по игре с последующим проведением в ней какого-то значимого времени (чтобы убирать кликбейт или мисклики) и добавление этой игры в любимые.
С отрицательными сигналами всё интереснее, так как явно пользователь их обычно не даёт. Но считать неудачными просто все рекомендации, с которыми пользователь не провзаимодействовал, не стоит, потому что он мог их просто не заметить (тем более это легко в скролл-виджете, в котором изначально не показываются все объекты).
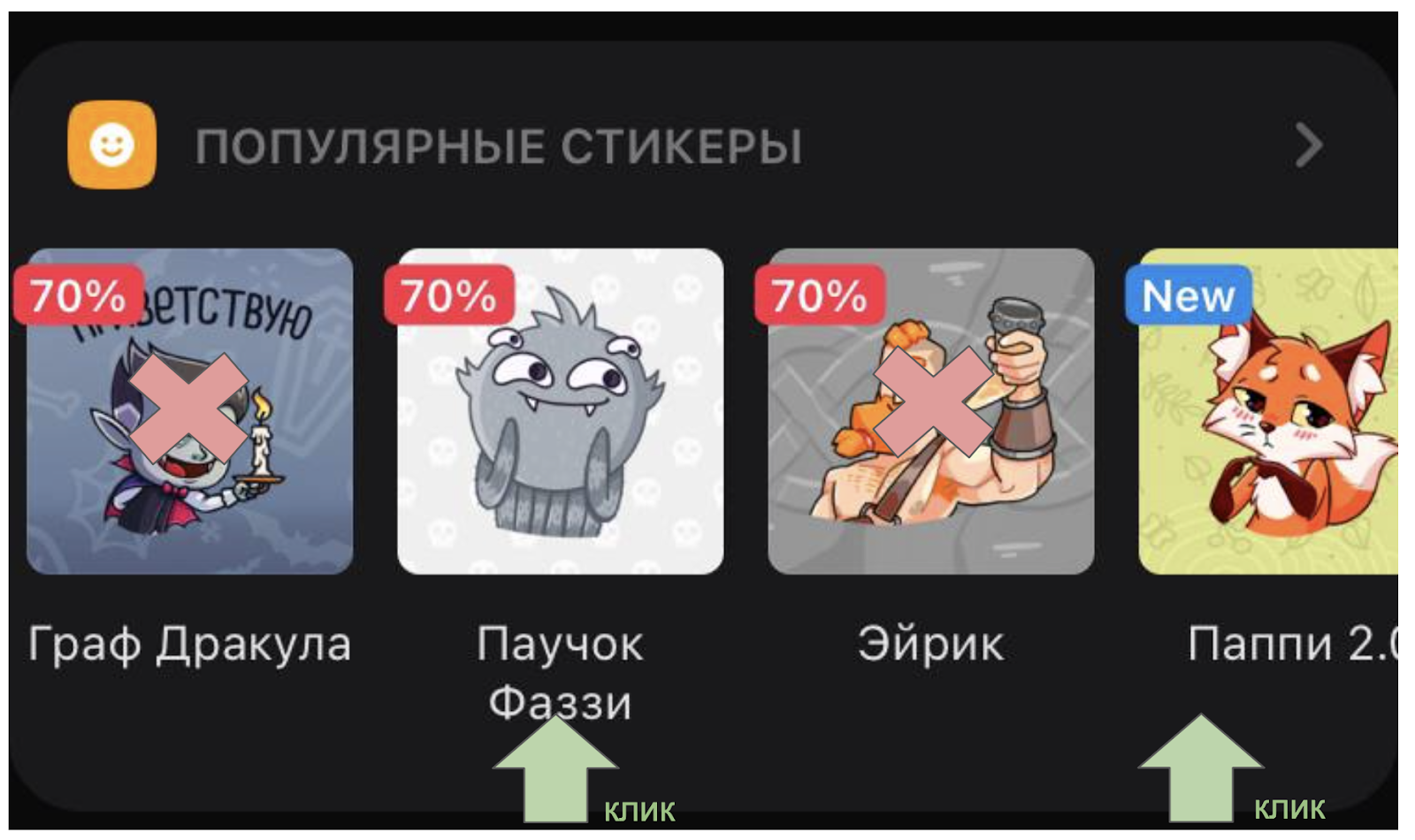
Мы решили считать, что взаимодействие носило отрицательный характер в том случае, когда пользователь точно увидел рекомендуемый объект и при этом сознательно не проявил к нему интереса. Для этого в качестве примеров отрицательного взаимодействия мы берём все объекты в горизонтальных скролл-виджетах, которые расположены слева от объекта, нажатого пользователем. На рисунке ниже такими примерами отрицательных взаимодействий являются «Граф Дракула» и «Эйрик».
Разная значимость сигналов
Естественно, не все положительные действия равнозначны: просмотр набора стикеров и его покупка — не одно и то же. При этом отрицательные взаимодействия в нашей постановке дают не такой явный сигнал, как положительные. Хотелось бы учитывать и те, и другие действия и желательно в рамках одной модели. Мы решили эту задачу назначением весов определённым видам сигналов. В формуле правдоподобия множители возводятся в степень, равную весу соответствующего сигнала:

Квазислучайное сэмплирование
Эксперименты показали, что новые объекты до равноправного участия в сэмплировании Томпсона стоит сначала порекомендовать квазислучайно.
Это значит, что мы не просто случайно выбираем момент, когда поместить в рекомендации новый объект, а делаем это таким образом, чтобы он был порекомендован в как можно более разнообразных контекстах. Это позволяет лучше понять, где этот объект будет впоследствии более востребованным, и обеспечить ему хороший старт.
Существует много способов квазислучайного сэмплирования. Самым популярным, пожалуй, является квазислучайное сэмплирование на основе последовательности Соболя. Мы же используем самописный сэмплер.
Результаты
Первым делом мы протестировали алгоритм на играх на Android. Сравнивали качество классических ML-рекомендаций с подмешанными «бандитскими» рекомендациями против чистых классических ML-рекомендаций с помощью A/B-теста.
Сначала метрики в тестовой группе незначительно упали относительно контроля, но через две недели начали уверенно расти. Через два месяца эффект составил +8% установок игр, +2% запусков, после чего мы раскатили новые рекомендации на всю аудиторию. Результаты на стикерах против классических ML-рекомендаций дали +5% к выручке от их продажи.
В обоих случаях большее количество объектов — игр и стикеров — начали получать внимание пользователей.
Сейчас внедряем этот подход в рекомендации других сущностей, а также разрабатываем новые подходы для случаев, когда фидбэк приходит не сразу (reinforcement learning решения) и когда мы всё-таки хотим не ограничиваться небольшим количеством факторов, а использовать всю доступную информацию по максимуму (deep learning модификации наподобие описанной в этой статье).
У нас много разных ML-проектов, они интересные, сложные и высоконагруженные. И если при мысли о возможности учить свои reinforcement learning алгоритмы в реальном времени на огромном количестве пользователей с помощью внушительных вычислительных мощностей VK у вас загораются глаза, если вы любите математику, то самое время нам познакомиться. Буквально через пару дней (2 и 3 июля) будет проходить VK Weekend Offer для ML- и RecSys-разработчиков. Помимо нашей команды, там будут и другие с не менее интересными проектами. Если не успеете на Weekend Offer, то позже можно отправить отклик здесь.
